
<p>【版权声明】博客内容由厦门大学数据库实验室拥有版权,未经允许,请勿转载!<br /> 讯享网
[返回Spark教程首页]
Hadoop 2.7分布式集群环境搭建已经分享了如何在本地搭建Hadoop集群;这篇博客分析下如何在Docker上搭建Hadoop集群;首先,我们需要在Ubuntu上安装Docker;
安装Docker,首先必须保证是64位Linux系统,其次内核版本必须大于3.10;我们可以用如下命令来检测Ubuntu内核版本:
讯享网
比如笔者电脑执行结果如下:
在安装Docker之前,首先需要先更新apt,安装CA证书,因为访问Docker用的是https协议;
讯享网
添加新的GPG key;
Ubuntu系统添加Docker源:
讯享网
更新apt包索引:
接着可以用如下方式验证下是否从正确的仓库拉取安装包:
讯享网
如果有类似于下面的输出,则说明从正确的仓库获取包;
接下来可以直接安装Docker,命令如下:
讯享网
等这个命令结束之后,Docker即安装成功;我们可以通过下面命令开启Docker服务:
然后我们也可以运行Docker官方提供的hello-world程序检测Docker安装运行成功:
讯享网
这个命令会输出一堆文字,其中有段文字是
则表示安装成功!
讯享网
添加当前用户到Docker用户组:
$USER表示当前用户名,例如,当前用户是hadoop,则把$USER替换成hadoop即可;然后注销,再次登录即可方便使用Docker了;
安装好Docker之后,接下来就要在Docker上安装Ubuntu,其实和安装其他镜像一样,只需运行一个命令足矣,如下:
讯享网
docker pull命令表示从Docker hub上拉取Ubuntu镜像到本地;这时可以在终端运行以下命令查看是否安装成功,
有如下输出则表示安装成功:
讯享网
docker images表示列出Docker上所有的镜像;镜像也是一堆文件,我们需要在Docker上开启这Ubuntu系统;在启动Ubuntu镜像时,需要先在个人文件下创建一个目录,用于向Docker内部的Ubuntu系统传输文件;命令如下:
然后再在Docker上运行Ubuntu系统;
讯享网
这里解析下这个命令参数:
* docker run 表示运行一个镜像;
* -i表示开启交互式;-t表示分配一个tty,可以理解为一个控制台;因此-it可以理解为在当前终端上与docker内部的ubuntu系统交互;
* -v 表示docker内部的ubuntu系统/root/build目录与本地/home/hadoop/build共享;这可以很方便将本地文件上传到Docker内部的Ubuntu系统;
* --name ubuntu 表示Ubuntu镜像启动名称,如果没有指定,那么Docker将会随机分配一个名字;
* ubuntu 表示docker run启动的镜像文件;
刚安装好的Ubuntu系统,是一个很纯净的系统,很多软件是没有安装的,所以我们需要先更新下Ubuntu系统的源以及安装一些必备的软件;
更新系统软件源
更新系统源命令如下:
安装vim
然后我们安装下经常会使用到的vim软件:
讯享网
安装sshd
接着安装sshd,因为在开启分布式Hadoop时,需要用到ssh连接slave:
然后运行如下脚本即可开启sshd服务器:
讯享网
但是这样的话,就需要每次在开启镜像时,都需要手动开启sshd服务,因此我们把这启动命令写进~/.bashrc文件,这样我们每次登录Ubuntu系统时,都能自动启动sshd服务;
在该文件中最后一行添加如下内容:
讯享网
配置sshd
安装好sshd之后,我们需要配置ssh无密码连接本地sshd服务,如下命令:
执行完上述命令之后,即可无密码访问本地sshd服务;
安装JDK
因为Hadoop有用到Java,因此还需要安装JDK;直接输入以下命令来安装JDK:
讯享网
这个命令会安装比较多的库,可能耗时比较长;等这个命令运行结束之后,即安装成功;然后我们需要配置环境变量,打开~/.bashrc文件,在最后输入如下内容;
接着执行如下命令使~/.bashrc生效即可;

讯享网
保存镜像文件
我们在Docker内部的容器做的修改是不会自动保存到镜像的,也就是说,我们把容器关闭,然后重新开启容器,则之前的设置会全部消失,因此我们需要保存当前的配置;为了达到复用配置信息,我们在每个步骤完成之后,都保存成一个新的镜像,然后开启保存的新镜像即可;首先我们要到这个网址注册一个账号https://hub.docker.com/;账号注册成功后,然后在终端输入以下信息:
然后会有如下提示信息,输出相应的用户名和密码即可:
讯享网
登录之后,即可输入以下命令保存修改后的容器为一个新的镜像;
查看当前ubuntu的镜像id,如下
讯享网
然后保存当前镜像为ubuntu/jdkinstalled,表示jdk安装成功的ubuntu版本,命令如下:
输出如下:
讯享网
最后输出所有镜像查看是否保存成功:
输出如下:
讯享网
以上命令意思如下:
1. docker ps查看当前运行的容器信息,目前只运行一个ubuntu容器;
2. docker commit保存fd1fc69d75a3(容器id)容器为一个新的镜像,镜像名称为ubuntu/jdkinstalled
3. docker images查看当前docker所有镜像,可以看到我们新添加的镜像ubuntu/jdkinstalled
安装好JDK之后,接下来,我们来安装Hadoop;我们开启保存的那份镜像ubuntu/jdkinstalled:
我们可以用如下命令查看开启的容器:
讯享网
输出如下:
ok,开启系统之后,我们把下载下来的Hadoop安装文件放到共享目录/home/hadoop/build下面,然后在Docker内部Ubuntu系统的/root/build目录即可获取到Hadoop安装文件;在Docker内部的Ubuntu系统安装Hadoop和本地安装一样,
讯享网
如果是单机版Hadoop,到这里已经安装完成了,可以运行如下命令测试下:
输出如下:
讯享网
接下来,我们来看下如何配置Hadoop集群;对一些文件的设置和之前教程一样,首先打开hadoop_env.sh文件,修改JAVA_HOME
接着打开core-site.xml,输入一下内容:
讯享网
然后再打开hdfs-site.xml输入以下内容:
接下来修改mapred-site.xml(复制mapred-site.xml.template,再修改文件名),输入以下内容:
讯享网
最后修改yarn-site.xml文件,输入以下内容:
到这里Hadoop集群配置就已经差不多了,我们先保存这个镜像,在其他终端输入如下命令:
讯享网
ok,接下来,我们在三个终端上开启三个容器运行ubuntu/hadoopinstalled镜像,分别表示Hadoop集群中的master,slave01和slave02;
接着配置master,slave01和slave02的地址信息,这样他们才能找到彼此,分别打开/etc/hosts可以查看本机的ip和主机名信息,最后得到三个ip和主机地址信息如下:
讯享网
最后把上述三个地址信息分别复制到master,slave01和slave02的/etc/hosts即可,我们可以用如下命令来检测下是否master是否可以连上slave01和slave02
到这里,我们还差最后一个配置就要完成hadoop集群配置了,打开master上的slaves文件,输入两个slave的主机名:
讯享网
ok,Hadoop集群已经配置完成,我们来启动集群;
在master终端上,首先进入/usr/local/hadoop,然后运行如下命令:
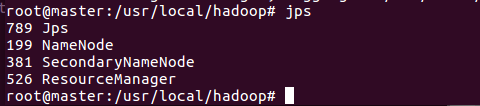
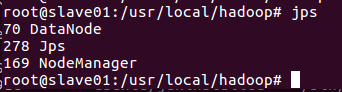
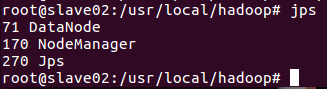
到目前为止,我们已经成功启动hadoop分布式集群,接下来,我们通过运行hadoop自带的grep实例来查看下如何在hadoop分布式集群运行程序;这里我们运行的实例是hadoop自带的grep
因为要用到hdfs,所以我们先在hdfs上创建一个目录:
讯享网
然后将/usr/local/hadoop/etc/hadoop/目录下的所有文件拷贝到hdfs上的目录:
然后通过ls命令查看下是否正确将文件上传到hdfs下:
讯享网
输出如下:
接下来,通过运行下面命令执行实例程序:
讯享网
过一会,等这个程序运行结束之后,就可以在hdfs上的output目录下查看到运行结果:
hdfs文件上的output目录下,输出程序正确的执行结果,hadoop分布式集群顺利执行grep程序;


版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/189669.html