
<svg xmlns="http://www.w3.org/2000/svg" style="display: none;"> <path stroke-linecap="round" d="M5,0 0,2.5 5,5z" id="raphael-marker-block" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></path> </svg> <p>本文会对NeRF整体的训练代码进行解析;(如果不训练,只是渲染的话,与训练的区别就是有无最后一步的计算loss并进行反向传播)<br /> 整体的代码流程如下:</p> 讯享网
- 参数设置——————confi_parser
- 数据加载——————load_llff_data…
- NeRF网络构建————create_nerf
- 仅渲染——————–render
- 构建raybatch tensor—–get_rays_np
- 渲染的核心过程———–render
- 计算loss——————img2mse
可以结合上一篇博客学习,代码和理论结合使用;
数据的处理、网络训练或者渲染中所用到的参数基本都在函数config_parser()里面进行了介绍,但是很多参数都是不太用得到的,每次只需要改的就是官方config中的各个txt文件中提及的那几个;
(1)数据读取_load_data()
输出:pose[3,5,N], bsd[2,N], images[h,w,c,N]
过程:读取要进行渲染的所有图片,进行pose的维度变换,并根据是否要进行下采样进行操作。下采样函数为_minify()
(2)数据后处理recenter_poses()
拿到上面的数据后,根据要求变换位姿,并将表示图像维度的N放到第0维;
紧接着进行边界和平移向量t的缩放;
recenter_poses():计算所有pose的均值,将所有pose做均值逆转换,简单来说就是重新定义世界坐标系,原点期望放在被测物体的中心
(3)render_path_spiral():生成用来渲染的螺旋路径的位姿
(4)函数load_llff_data最后的输出:
pose:[N,3,5],N为图像个数,3x5中,前3为旋转,第4列为t,第5列为[h,w,f]
images: [N,h,w,c]
bds:[2,N]采样深度范围
render_poses:螺旋路径的位姿
i_test:距离最小的id,作为测试
(5)网络构建前的数据预处理
上面得到的i_val作为验证,其余作为训练集;紧接着计算内参K;然后创建log路径,保存训练用的所有参数到args,复制config参数并保存
(1)位置编码get_embedder
对xyz以及view方向的都进行位置编码
输入:xyz三维或者view
输出:input_ch=63高维的特征或者对应view的27维
实现:对应公式
接下来输入网络深度和每层宽度,且输入宽度不是5d的5,而是位置编码后的通道数63
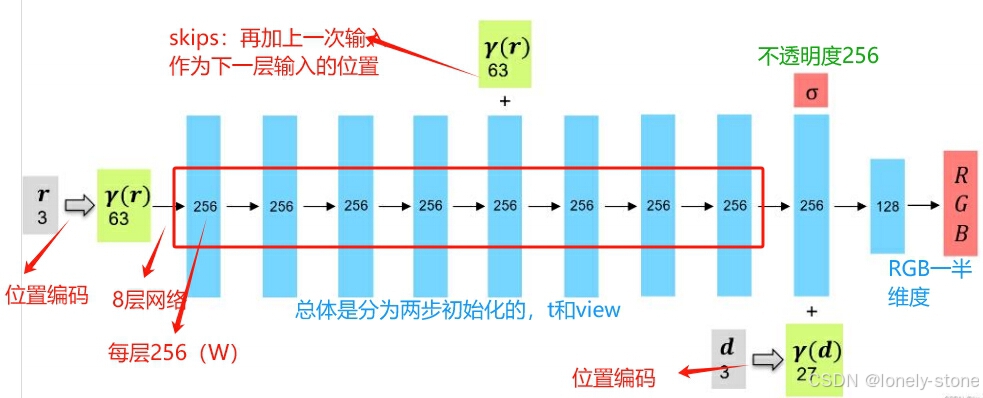
(2)模型初始化NeRF,实例化
输入:8层网络,每层设置的通道数为256,xyz对应的输入通道数63,view对应的输入27,再多一次输入的层序号skips
输出:feature_linear输出特征256维,不透明度alpha_linear256维,Rgb128为3通道rgb_linear
讯享网
上面是coarse网络,接下来refine网络也是类似,唯一的区别就是网络深度和每层的通道数不同(但好多时候其实也是一样的)
(3)模型批量处理数据函数
位置编码:embedded = embed_fn(inputs_flat)
以更小的patch-netchunk去跑网络前向:outputs_flat = batchify(fn, netchunk)(embedded)
将output进行reshape:[1024,64,4](这里面的4表示rgb+alpha)
(4)定义优化器Adam
optimizer = torch.optim.Adam(params=grad_vars, lr=args.lrate, betas=(0.9, 0.999))
加载已有模型参数,传递给优化器;加载已有模型
训练需要的参数:
create_nerf最后的输出:
讯享网
如果只是进行渲染,那运行到这里就调用render函数,完成后就return;(在后面的训练中,还是会执行这个函数)

然后把对应是属于训练图像的rays取出来为rays_rgb,并打乱顺序,使得随机取去训练的时候更鲁棒。接下来就是训练步骤中的核心,也就是渲染:
开始训练,进行迭代:
讯享网
在经过上述步骤拿到ray的信息后,开始调用render
讯享网
其中,在完成上面代码中注释的第2步以后,要开始进行fine网络需要的点采样,此时要遵循分层体积采样,可由上一篇博客中所述,需要评估这些采样点位置的coarse网络,计算每个采样点的权重,并进行归一化处理,得到概率密度函数;最后才能沿着每条射线对权重更大的点进行更精确的采样,具体过程由如下代码实现:
讯享网
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/187066.html