
<svg xmlns="http://www.w3.org/2000/svg" style="display: none;"> <path stroke-linecap="round" d="M5,0 0,2.5 5,5z" id="raphael-marker-block" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></path> </svg> <blockquote> 讯享网
对于图来说,有广度优先与深度优先遍历,那么两者如何使用递归与非递归方法实现?无向图、有向图有什么区别?图和树和森林有什么关联吗?
这几次作业都是要对递归、非递归进行区分
递归就是函数调用函数本身,运行起来就是函数嵌套函数,层层嵌套,所以函数调用、参数堆栈都是不小的开销,但是程序简单。
非递归就是不断地对参数入栈、出栈,省去了函数层层展开、层层调用的开销。虽然参数出入栈次数多了,但是一般都开辟固定的足够大的内存来一次性开辟、重复使用。
对于第三次作业来说,图的遍历是指从图中的任一顶点出发,对图中的所有顶点访问一次且只访问一次(访问一次,但不止用到一次)。
图的遍历操作和树的遍历操作功能相似(图去掉一些边,变成无环的,就变成树)(二叉树的前序,中序,后序遍历,本质上也可以认为是深度优先遍历、而二叉树的层序遍历,本质上也可以认为是广度优先遍历)。图的遍历是图的一种基本操作,图的许多其它操作都是建立在遍历操作的基础之上。

非递归实现BFS是最直接的方法,是一种分层的查找过程,每向前走一步可能访问一批顶点,不像深度优先搜索那样有往回退的情况,因此它不是一个递归的算法。
为了实现逐层的访问,算法必须借助一个辅助队列,以记忆正在访问的顶点的下一层顶点。
其实他本意就是,先遍历一个节点,然后遍历那个节点所连接的的周边节点,之后再一个结点一个结点的往外遍历,重复循环
广度优先遍历动图如下,每个节点的值即为它们的遍历顺序。所以广度优先遍历也叫层序遍历,先遍历第一层(节点 1),再遍历第二层(节点 2,3,4),第三层(5,6,7,8),第四层(9,10)。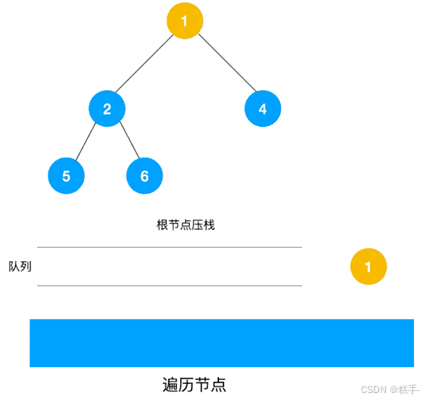 代码如下(完整):
代码如下(完整):
讯享网
运行结果
递归实现BFS需要一些额外的结构来模拟队列的行为。这通常涉及到一个辅助函数,该函数将处理当前层的所有节点,然后递归地对下一层进行处理。
主要思路是从图中一个未访问的顶点 V 开始,沿着一条路一直走到底,然后从这条路尽头的节点回退到上一个节点,再从另一条路开始走到底…,不断递归重复此过程,直到所有的顶点都遍历完成,它的特点是不撞南墙不回头,先走完一条路,再换一条路继续走。
具体遍历过程:首先我们从根节点 1 开始遍历,它相邻的节点有 2,3,4,先遍历节点 2,再遍历 2 的子节点 5,然后再遍历 5 的子节点 9。
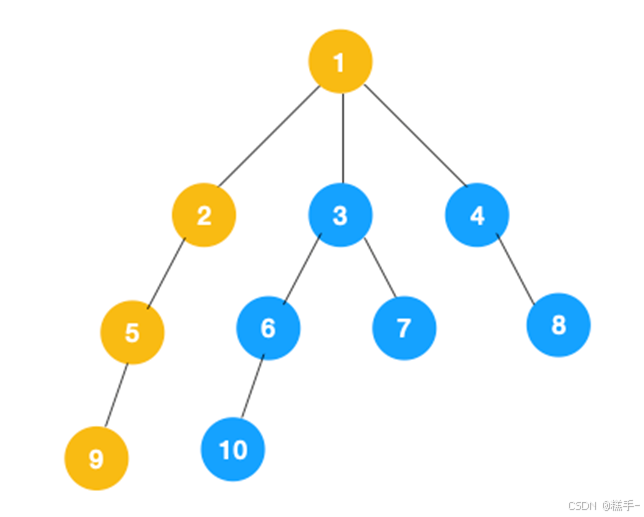
上图中一条路已经走到底了(9是叶子节点,再无可遍历的节点),此时就从 9 回退到上一个节点 5,看下节点 5 是否还有除 9 以外的节点,没有继续回退到 2,2 也没有除 5 以外的节点,回退到 1,1 有除 2 以外的节点 3、4,所以从节点 3 开始进行深度优先遍历,如下:
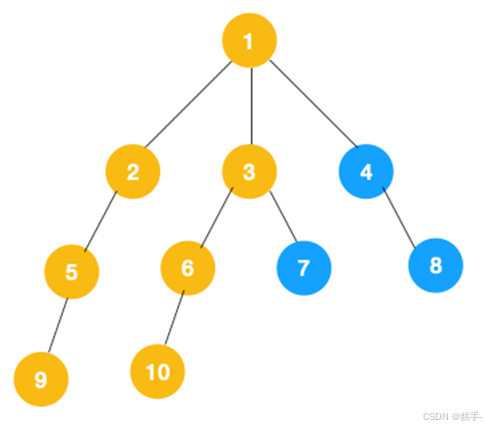
同理从 10 开始往上回溯到 6, 6 没有除 10 以外的子节点,再往上回溯,发现 3 有除 6 以外的子点 7,所以此时会遍历 7。
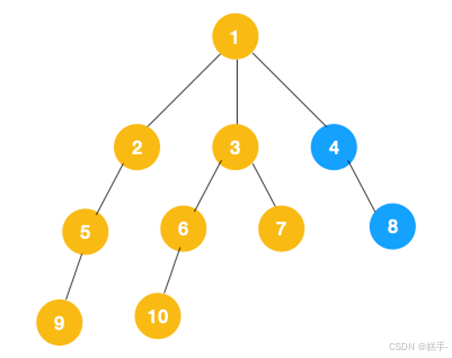
从 7 往上回溯到 3, 1,发现 1 还有节点 4 未遍历,所以此时沿着 4, 8 进行遍历,这样就遍历完成了。
完整的节点的遍历顺序如下(节点上的的蓝色数字代表):
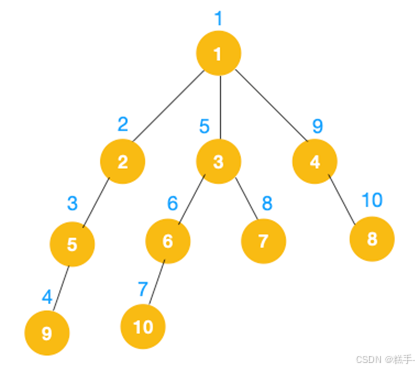

讯享网
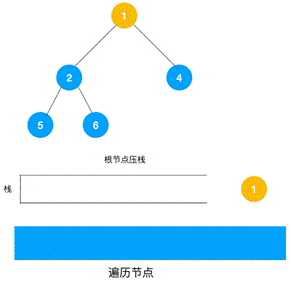
使用非递归方法实现深度优先遍历(DFS)通常涉及到使用栈来模拟递归过程
广度优先遍历(BFS)与深度优先遍历(DFS)的实现
- 广度优先遍历(BFS)
非递归实现:通常使用队列来实现。从源节点开始,将其入队,然后循环地从队列中取出节点,访问它,并将所有未访问的邻接节点入队,直到队列为空。
递归实现:不常见,因为BFS的本质是逐层遍历,递归不利于控制遍历的层级。但理论上可以通过递归模拟队列的行为,逐层递归访问邻接节点。 - 深度优先遍历(DFS)
递归实现:从源节点开始,访问它,然后递归地访问所有未访问的邻接节点。这是DFS最常见的实现方式。
非递归实现:使用栈来模拟递归过程。从源节点开始,将其压栈,然后循环地从栈中取出节点,访问它,并将所有未访问的邻接节点压栈,直到栈为空。
无向图与有向图的区别
边的方向:
无向图:边没有方向,即如果节点A与节点B之间有边,那么这条边可以看作是从A到B或从B到A。
有向图:边有方向,即如果节点A与节点B之间有一条从A指向B的边,那么这条边只能从A到B。
遍历差异:
在无向图中,DFS和BFS不需要区分边的方向。
在有向图中,DFS和BFS通常只考虑出边(从当前节点出发的边)。
3.图、树和森林的关联
树(Tree):
树是一种特殊的图,它是连通的且无环的。树中的节点称为顶点,连接顶点的边表示顶点之间的关系。树有一个特殊的节点称为根节点,其他所有节点都是根节点的后代。
树的深度优先遍历(DFS)和广度优先遍历(BFS)可以递归实现,因为树结构自然适合递归。
森林(Forest):
森林是树的集合,即多个不相交的树的组合。在森林中,每个树的连通分量都是独立的。
图与树的关系:
图可以包含树作为其子结构。例如,在一个连通的无向图中,如果移除某些边使其变成无环的,那么结果就是一个树。
图的遍历算法(如DFS和BFS)可以用于树的遍历,因为树是图的一种特殊形式。
图与森林的关系:
图可以分解为森林,森林可以看作是多个树的集合。在图的遍历中,如果图是连通的,那么它的DFS或BFS遍历会覆盖所有节点;如果图不是连通的,那么它的每个连通分量可以独立地进行DFS或BFS遍历,每个连通分量相当于一个树。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/180882.html