
本人学的疯狂Java讲义快速入门,但是想夯实基础知识 建议学习 Java核心技术卷一和卷二,将的很透彻,入门阶段也可以通过视频,可以提高学习效率,但是一定要自己动手写代码
疯狂java讲义
原因:国人写的,便于理解。而且非常全面,适合当工具书。
学习Java这门语言,我不建议看疯狂讲义这本书,没点基础的人看起来有点劝退的味道;而且自学的话,看书,说实话很多都看不懂,没有看视频实在,而且书本上面的代码基本上不全面,也不能看到代码的实现过程,对于思路也比较难懂
对于Java这个行业来说,想要达到找工作的水平,JavaSE的知识是重中之重,子啊学习过程中不仅要熟悉理论,还要动手敲代码,必须达到熟悉的地步;后面的知识全都是基于JavaSE的基础之上的,如果基础没有学好,后面的只会越来越困难;当你以后学出来了,进入企业的第一件事就是叫你敲代码,而不是站在旁边去指挥,所以,会敲代码才代表你会Java
除了这些,Java这门语言想要成功入行,你还需要有一定的项目经验,熟悉项目开发流程,这也是为什么那些培训结构都会要求大家去做完项目之后才去找工作,因为你有项目经验才会有进入面试的机会
学习Java的建议:
- 选择看视频,看完一套视频之后再去选择看书,这样才能够体现出书本的价值
- 多动手,不管你是看书还是看视频,动手敲代码才是最重要的
- 做笔记,一方面方便你复习,一方面能够帮助你熟悉知识点,也能够帮助你查缺补漏
- 多交流,不管是同学还是老师,初学者还是前辈,多去吸取他们的经验和优点
- 找个前辈指导,这样能够少花很多的时间,少走很多的弯路
Java学习路线:
第一阶段:Java基础语法
内容:运行环境、关键字、数据类型、运算符、方法、条件结构、循环结构、方法重载、数组
第二阶段:面向对象和封装
内容:面向对象、this、构造方法
第三阶段:Java语言高级
内容:常用API、继承和多态、集合、异常、多线程、网络编程、MySQL、JDBC
第四阶段:JavaWeb
内容:前端三剑客、XML、Tomcat、Servlet、HTTP、九大内置对象、JSP、EL、JSTL、Filter、Listener、Jquery、Ajax、JSON、Redis、Maven、BootStrap
第五阶段:基本框架SSM
疯狂java讲义零基础
内容:Spring、SpringMVC、MyBatis
第六阶段:高级框架
内容:Spring Boot、Git、Spring Security、Linux、Spring Cloud..........
学习Java多久才能够找到工作?
自学java,学多久可以自己找到工作?
学习Java常见的问题:
java学习中,能看懂代码,但是自己写不出来怎么办?
不请自来
两个版本的代码并不完全兼容,所以要根据自身需求选择图书版本进行学习。
第4版覆盖Java 9/8/7,在大多数生产环境中,出于系统稳定性和升级成本的考量,使用的Java版本多是7/8,如果为了快速与大厂的开发环境接轨,建议选择第4版。
第5版覆盖Java 11,和10~12不同,11是Java的一个大版本,如果作为一种编程语言从零开始学习,尽可能多地掌握Java语青的新特性,并且没有迫切的入职需求,建议入手第5版。
参考:https://fkjava.org/2019/04/01/java5/
有一点计算机基础的话,自己看菜鸟网站或者官方网站就可以自学。入门基本都很快,内容也很简单。
或者就看视频,在B站或者百度直接搜索视频。搜索JavaScript的视频就可以。网上有很多的教导视频。可以选择某一个大学的视频或者某个培训机构的视频,这样比较专业。
书是人类不可或缺的精神食粮。正如高尔基所言:书是人类进步的阶梯。借名人名言给大家推荐一些对Java学习有用的经典书籍,对程序员来说,我觉得**学习方式还是看书,看视频花费时间太长,而阅读博客则不够系统。
对Java初学者最好的方式就是找到一本经典的好书,然后啃完它。当然,我还是推荐大家有时间写写博客,毕竟好记性不如烂笔头,许多的工作经验,不记录会随着时间的推移也终究会被遗忘,看书也一样,看到重点动手去实践,动脑去思考,动手记录下来,哪些书适合初学者呢?下面和千锋广州小编一起来看看吧!

1、《Head First Java》Java入门书籍
《Head First Java》是本完整的面向对象(object-oriented,OO)程序设计和Java的学习指导。你会学会如何像个面向对象开发者一样去思考。但如果你真地想要好好地学习Java,你会需要《Head First Java》强烈推荐学习此书,非常适合初学者入门。
2、《Java从入门到精通》适合自学者 这本书主要针对Java基础,对于没有学过Java的人才说,是一个不错的选择。通过这本书,大家可以从零开始,慢慢来学习,而且实操很多,不会让你看到最后出现只会理论的情况。
3、《Thinking in Java》(中文名:《Java编程思想》)适合中级自学者和培训者
是所有Java程序员必备教科书。这本书不管是正在学习还是已经工作许多年的程序员,都可以从这本书中得到你想要的东西。这本书具有教材和工具书的作用,就像一本字典,想知道什么都可以从中查询。虽然这本书很好,但并不建议初学者学习,对于初学者难度较大。
4、《疯狂Java讲义》适合自学者看 内容比较项目化,实操方法很多,如果你想进行Java的深入学习,不妨看看这本书。
5、《Java核心技术》这本书分为两个部分,第一个部分讲的是基础知识,第二个部分讲的是高级特性。但是里面对Java的技术讲述大而全,几乎对语法和基础库讲的都很夯实,我觉得入门看这个很合适。
6、《Java开发实战经典》这本书比较适合自学者学习,里面有很多小案例,可以边学边练,巩固知识。[1]
不要走马观花的学,要学会如何使用,因为学Java最开始的目的不是就是用来使用的吗?技术学了不用,那么学不学有什么区别呢
作者:艾特程序员
链接地址:https://www.sohu.com/a/_
来源:搜狐
什么是文件上传?
文件上传就是把用户的信息保存起来。
为什么需要文件上传?
在用户注册的时候,可能需要用户提交照片。那么这张照片就应该要进行保存。
上传组件(工具)
为什么我们要使用上传工具?
为啥我们需要上传组件呢?当我们要获取客户端的数据,我们一般是通过getParameter()方法来获取的。
上传组件有两种
- FileUpload【操作比较复杂】
- SamrtUpload【操作比较简单】
开发步骤
- 创建解析器工厂对象【DiskFileItemFactory】
- 通过解析器工厂创建解析器【ServletFileUpload】
- 调用解析器方法解析request对象,得到所有上传的内容【list】
- 遍历list,判断每个对象是否是上传文件
- 如果是普通表单字段,得到字段名和字段值
- 如果是上传文件,调用InputSteam方法得到输入流,读取上传的数据
文件上传细节
- 如果上传文件的大小大于我们设定文件的大小,那么文件在上传的时候会使用临时文件保存上传数据。在上传完毕后,我们应该删除临时文件
- 上传文件的位置是不能在WEB服务器管理之下的,否则可能造成安全问题【其他人有可能通过手段来修改上传文件】
- 如果上传文件名相同,那么就会把原本的上传文件覆盖掉。我们要生成一个独一无二的文件名。
- 如果用户量很大,上传文件非常多。那么我们不应该在一个目录保存所有的上传文件,这样很可能造成磁盘奔溃了。所以我们要把上传的文件打散到不同的目录下。

这里有三本书推荐,视频教程+讲义,名师讲解,推荐大家看一下O(∩_∩)O
去看看
为初学者而著!
Java基础是初学者的起点,是帮助你从小白入门到精通必学基础课程!

B站最新录制Java300集>>> 适合准备入行开发的零基础员学习Java,基于最新JDK13、IDEA平台讲解的,视频中穿插多个实战项目。每一个知识点都讲解的通俗易懂,由浅入深。不仅适用于零基础的初学者,有经验的程序员也可做巩固学习。
配套学习:
给同学们带来全新的Java300集课程啦!java零基础小白自学Java必备优质教程_手把手图解学习Java,让学习成为一种享受_哔哩哔哩_bilibili
File类
File类是 IO 包中唯一代表磁盘文件本身的对象,File类定义了一些与平台无关的方法来操纵文件
File f = new File("d:/test/1.txt");
常用方法见 API
delete 方法删除由File对象的路径所表示 对磁盘文件或目录。如果删除的对象是目录,该目录中的内容必须为空。
节点流
我们将IO流类分为两个大类,节点流类和过滤流类(也叫处理流类)。
1. 程序用于直接操作目标设备所对应的类叫节点流类
2. 程序也可以通过一个间接流类去调用结点流类,以达到更加灵活方便地读写各种类型的数据,这个间接流类就是过滤流类(也叫处理流类)
InputStream 与 OutputStream (抽象类[字节流])
程序可以从中连续 读取字节 的对象叫输入流,用InputStream类完成
| int read() // 返回 -1 表示遇到流的末尾,结束 int read(byte[] b) //读入b.length个直接放入到b中并返回实际读入的字节数 int read(byte[] b,int off,int len) void close() //关闭,通知系统释放与这个流相关的资源 |
程序能向其中连续 写入字节 的对象叫输出流,用OutputStream类完成
| void write(int b) //将一个直接写到输入流 void write(byte[] b) //将整个直接数组写到输出流中 void write(byte[] b,int off,int len) // void flush() //彻底完成输出并清空缓冲区 void close() //关闭输出流 |
这里的输入输出是针对程序而言的,而非文件。
输入: 程序读取 输出:程序写出
将A文件的内容写入文件B中:
我们应该创建一个输入类来完成对A文件的操作,再创建一个输出类来完成对B文件的操作。
FileInputStream 与 FileOutputStream
这两个源节点用来操作磁盘文件,在创建一个FileInputStream对象时通过构造函数指定文件的路径和名字,当然这个文件应当是存在的和可读的。在创建一个FileOutputStream对象时指定文件如果存在将要被覆盖。
只能用来读取字节或字节数组!!!因此字符串需要使用getBytes()方法转为字节数组。
注:unicode是双字节的,而ASCII是单字节的。java中的字符默认使用unicode编码!
编程实现利用FileOutputStream类向文件写入一串字符,并用FileInputStream读出:
| public class FileStreamDemo { public static void main(String[] args) { File f = new File("Hello.txt"); //输出到文件中 try { FileOutputStream out = new FileOutputStream(f); byte buf[] = "hello,well".getBytes();//转成字节输出 out.write(buf); out.close(); } catch (Exception e) { e.printStackTrace(); } //从文件中读出显示到屏幕上 try { FileInputStream in = new FileInputStream(f); byte[] buff = new byte[1024]; int len = in.read(buff); System.out.println(new String(buff,0,len)); } catch (Exception e) { e.printStackTrace(); } } } |
为什么要 close ?
Java垃圾回收器只能管理程序中的类的实例对象,没法去管理系统产生的资源,所以程序要调用 close 方法,去通知系统去释放其自身产生的资源。
这两个类都只提供了对字节或字节数组进行读出的方法。对于字符串的读写,我们还需要进行额外的转换。
Reader和Writer
1. 抽象类,用于直接读取字符串文本
2. Java为字符文本(直接读取字符串)的输入输出专门提供的一套单独的类,其在处理字符串时简化了我们的编程。
对上面的程序进行如下的修改:—— 使用FileWriter 和 FileReader类来实现直接对字符串的读取:
| public class FileStreamDemo2 { public static void main(String[] args) { File f = new File("Hello.txt"); try { FileWriter out = new FileWriter(f); out.write("hello world,hahaha"); out.close(); } catch (Exception e) { e.printStackTrace(); } try { FileReader in = new FileReader(f); char[] buf = new char[1024]; int len = in.read(buf); System.out.println(new String(buf,0,len)); } catch (Exception e) { e.printStackTrace(); } } } |
FileReader的真正优势要结合包装流类才能体现出来!!
PipedInputStream 与 PipedOutputStream
一个PipeInputStream对象必须和一个PipedOutputStream对象进行连接而产生一个通信管道。
这两个类主要来完成线程之间的通信。 --- p 266
一个线程的PipedInputStream对象能够从另一个线程的PipedOutputStream对象中读取数据。
void connect(PipedOutputStream src)使此管道输入流连接到管道输出流 src。
JDK还提供了PipedWriter和PipedReader这两个类来用于字符串文本的管道通信。
使用管道流,可以实现各个程序模块之间的松耦合通信。
ByteArrayInputStream 与 ByteArrayOutputStream
1. 使用字节数组作为数据源
2. 作用:使用IO流的方式来完成对字节数组内容的读写
IO程序代码的复用
由于没有编码为 -1 的字符,所以OS使用 -1 作为硬盘上的每个文件的结尾标记
文本文件与二进制文件:
1. 如果一个文件专用于存储文本字符的数据,没有包含字符之外的其他数据,我们称之为文本文件
2. 除此之外的文件就是二进制文件
为了支持标准输入输出设备,Java定义了两个特殊的流对象:http://System.in 和 System.out
http://System.in 对应键盘,是InPutStream类型的,从键盘读取数据
System.out 对应屏幕,是PrintStream类型的
Scanner类
该类不属于IO类,而属于util类
它是一个可以用正则表达式来解析基本类型和字符串的简单文本扫描器
Scanner 使用分隔符模式将其输入分解为标记,默认情况下该分隔符模式与空白匹配。然后可以使用不同的next 方法将得到的标记转换为不同类型的值。
例如从键盘读取一行输入:
| <span style="font-size:14px;"> Scanner cin = new Scanner(System.in); String name = cin.nextLine();</span> |
过滤流与包装流:
--- 即中间类,为哦我们往IO设备中写入各种类型的数据提供了帮助
| DataOutputStream writeBoolean() writeShort() writeChar() writeInt() ...... |
程序 ---> 包装流类 ----> 节点流类 ---> 目标
输入包装类 -- see p273 的例子
输出包装类 --
包装流的使用:
DataOutputStream(OutputStream out) //将OutputStream包装为DataOutputStream
BufferedInputStream 与 BufferOutputStream
---缓冲流:对IO进行缓冲
利用缓冲流来进行改善性能
构造方法:
BufferedInputStream(InputStream in)
创建一个带有32直接缓冲区的缓冲流
BufferedInputStream(InputStream in, int size)
创建具有指定缓冲区大小的缓冲区
BufferedOutputStream(OutputStream out)
创建一个新的缓冲输出流,以将数据写入指定的底层输出流。
BufferedOutputStream(OutputStream out, int size)
创建一个新的缓冲输出流,以将具有指定缓冲区大小的数据写入指定的底层输出流。
DataInputStream 与 DataOutputStream
———— 提供了可读写各种基本数据类型数据的各种方法
DataOutputStream提供了3种写入字符串的方法:
1. writeBytes(String s)
2. writeChars(String s)
3. writeUTF(Strng s)
PrintStream类
提供了一系列的print和println方法,可以实现将基本数据类型的格式化成字符串输出。
构造函数:
| PrintStream(OutputStream out) PrintStream(OutputStream out, boolean autoflush) PrintStream(OutputStream out, boolean autoflush, String encoding) |
autoflush控制java在遇到换行符(\n)时是否自动清空缓冲区
Java的PrintStream对象具有多个重载的Print和Println方法
在Windows的文本换行是 “\r\n” 而Linux下的文本换行是“\n”
PrintWriter的println方法能根据不同的操作系统生成相应的换行符
PrintWriter类 -- 与PrintStream相对应
该类若设置autoFlush, 其会在使用了println方法后使用自动清空缓冲区
ObjectInputStream 与 ObjectOutputStream
用于存储和读取对象的输入输出流类。
给同学们带来全新的Java300集课程啦!java零基础小白自学Java必备优质教程_手把手图解学习Java,让学习成为一种享受_哔哩哔哩_bilibili

Lambda表达式
lambda简介
Lambda 表达式是 JDK8 的一个新特性,可以取代大部分的匿名内部类,写出更优雅的 Java 代码,尤其在集合的遍历和其他集合操作中,可以极大地优化代码结构。
JDK 也提供了大量的内置函数式接口供我们使用,使得 Lambda 表达式的运用更加方便、高效。
对接口的要求
虽然使用 Lambda 表达式可以对某些接口进行简单的实现,但并不是所有的接口都可以使用 Lambda 表达式来实现。Lambda 规定接口中只能有一个需要被实现的方法,不是规定接口中只能有一个方法,例如:可以有default修饰的方法。
@FunctionalInterface是一个标志注解,被修饰的接口中的抽象方法只能有一个。 这个注解往往会和 lambda 表达式一起出现。
lambda初体验
在传统的写法中,我们创建一个线程通常的写法是:
new Thread(new Runnable() { @Override public void run() { //业务代码 } }).start(); 使用lambda表达式时写法是:
讯享网 new Thread(()->{ //业务代码 }).start();
lambda语法
lambda表达式由组成三部分:
() -> { } // () 为参数列表 -> 为运算符(读作goes to) { } 为方法体由此可见lambda表达式简化了方法的修饰符,返回值,方法名
注:
1、所有参数都可以不写参数类型
2、只有一个参数时可省略(),方法体只有一条语句时可以省略{}
Lambda 表达式常用示例
- lambda 表达式引用方法
有时候我们不是必须要自己重写某个匿名内部类的方法,我们可以可以利用 lambda表达式的接口快速指向一个已经被实现的方法。
语法:
方法归属者::方法名 静态方法的归属者为类名,普通方法归属者为对象
讯享网public class Exe1 { public static void main(String[] args) { ReturnOneParam lambda1 = a -> doubleNum(a); System.out.println(lambda1.method(3)); //lambda2 引用了已经实现的 doubleNum 方法 此种用法在mybatisplus中用来构建sql语句时常用 ReturnOneParam lambda2 = Exe1::doubleNum; System.out.println(lambda2.method(3)); Exe1 exe = new Exe1(); //lambda4 引用了已经实现的 addTwo 方法 ReturnOneParam lambda4 = exe::addTwo; System.out.println(lambda4.method(2)); } / * 要求 * 1.参数数量和类型要与接口中定义的一致 * 2.返回值类型要与接口中定义的一致 */ public static int doubleNum(int a) { return a * 2; } public int addTwo(int a) { return a + 2; } }
- 构造方法的引用
一般我们需要声明接口,该接口作为对象的生成器,通过 类名::new 的方式来实例化对象,然后调用方法返回对象。
interface ItemCreatorBlankConstruct { Item getItem(); } interface ItemCreatorParamContruct { Item getItem(int id, String name, double price); } public class Exe2 { public static void main(String[] args) { ItemCreatorBlankConstruct creator = () -> new Item(); Item item = creator.getItem(); ItemCreatorBlankConstruct creator2 = Item::new; Item item2 = creator2.getItem(); ItemCreatorParamContruct creator3 = Item::new; Item item3 = creator3.getItem(112, "鼠标", 135.99); } }- lambda 表达式创建线程
我们以往都是通过创建 Thread 对象,然后通过匿名内部类重写 run() 方法,一提到匿名内部类我们就应该想到可以使用 lambda 表达式来简化线程的创建过程。
Thread t = new Thread(() -> { for (int i = 0; i < 10; i++) { System.out.println(2 + ":" + i); } }); t.start();- 遍历集合
我们可以调用集合的 public void forEach(Consumer<? super E> action) 方法,通过 lambda 表达式的方式遍历集合中的元素。以下是 Consumer 接口的方法以及遍历集合的操作。Consumer 接口是 jdk 为我们提供的一个函数式接口。
ArrayList<Integer> list = new ArrayList<>(); Collections.addAll(list, 1,2,3,4,5); //lambda表达式 方法引用 list.forEach(System.out::println); list.forEach(element -> { if (element % 2 == 0) { System.out.println(element); } });- 删除集合中的某个元素
我们通过public boolean removeIf(Predicate<? super E> filter)方法来删除集合中的某个元素,Predicate 也是 jdk 为我们提供的一个函数式接口,可以简化程序的编写。
ArrayList<Item> items = new ArrayList<>(); items.add(new Item(11, "小牙刷", 12.05 )); items.add(new Item(5, "日本马桶盖", 999.05 )); items.add(new Item(7, "格力空调", 888.88 )); items.add(new Item(17, "肥皂", 2.00 )); items.add(new Item(9, "冰箱", 4200.00 )); items.removeIf(ele -> ele.getId() == 7); //通过 foreach 遍历,查看是否已经删除 items.forEach(System.out::println);- 集合内元素的排序
在以前我们若要为集合内的元素排序,就必须调用 sort 方法,传入比较器匿名内部类重写 compare 方法,我们现在可以使用 lambda 表达式来简化代码。
ArrayList<Item> list = new ArrayList<>(); list.add(new Item(13, "背心", 7.80)); list.add(new Item(11, "半袖", 37.80)); list.add(new Item(14, "风衣", 139.80)); list.add(new Item(12, "秋裤", 55.33)); /* list.sort(new Comparator<Item>() { @Override public int compare(Item o1, Item o2) { return o1.getId() - o2.getId(); } }); */ list.sort((o1, o2) -> o1.getId() - o2.getId()); System.out.println(list);Lambda 表达式中的闭包问题
这个问题我们在匿名内部类中也会存在,如果我们把注释放开会报错,告诉我 num 值是 final 不能被改变。这里我们虽然没有标识 num 类型为 final,但是在编译期间虚拟机会帮我们加上 final 修饰关键字。
import java.util.function.Consumer; public class Main { public static void main(String[] args) { int num = 10; Consumer<String> consumer = ele -> { System.out.println(num); }; //num = num + 2; consumer.accept("hello"); } }接口增强
在1.8之前接口中只能有:静态常量,抽象方法。
在1.8之后接口中可以有:静态常量,抽象方法,默认方法,静态方法
默认方法
语法格式
interface 接口名{ 修饰符 default 返回值 方法名(){ //方法体 } }使用方式
1、接口的实现类直接调用接口的默认方法
2、子类重写接口的默认方法
静态方法
interface 接口名{ 修饰符 static 返回值 方法名(){ //方法体 } }使用方式:只能通过 接口名.方法名
注:默认方法可以被继承和重新,而静态方法都不能
函数式接口
由来:使用Lambda表达式的前提是有函数式接口,而Lambda表达式使用时不关心接口名,抽象方法名。只关心抽象方法的参数列表和返回值类型,因此为了更加方便的使用Lambda表达式,JDK提供了大量常用的函数式接口(java.util.function包下)
Supplier
无参有返回值,用于生产数据
@FunctionalInterface public interface Supplier<T> { / * Gets a result. * * @return a result */ T get(); }使用:
public static void main(String[] args) { fun1(()->{ int[] arr={10,22,78,3,56,43,29,75}; Arrays.sort(arr); return arr[arr.length-1]; }); } private static void fun1(Supplier<Integer> supplier){ Integer max = supplier.get(); System.err.println("max = "+max); }Consumer
有参无返回值,用于消费数据
@FunctionalInterface public interface Consumer<T> { / * Performs this operation on the given argument. * * @param t the input argument */ void accept(T t); }使用:
public static void main(String[] args) { fun1( msg->{ System.err.println(msg+" ---转换为大写--- "+msg.toUpperCase()); }); } private static void fun1(Consumer<String> consumer){ consumer.accept("consumer accept"); }默认方法andThen使用:(进行组合操作)
public static void main(String[] args) { fun1( msg->{ System.err.println(msg+" ---转换为大写--- "+msg.toUpperCase()); },msg2->{ System.err.println(msg2+" ---转换成小写--- "+msg2.toLowerCase()); }); } private static void fun1(Consumer<String> c1,Consumer<String> c2){ String str = "consumer accept"; c1.andThen(c2).accept(str); //c1先执行,执行完毕再执行c2 }Function
有参有返回值,根据一个类型的数据得到另一个类型的数据,前者称为前置条件,后者称为后置条件
public interface Function<T, R> { / * Applies this function to the given argument. * * @param t the function argument * @return the function result */ R apply(T t); }使用:
public static void main(String[] args) { fun1( msg->{ return Integer.parseInt(msg); }); } private static void fun1(Function<String,Integer> function){ System.err.println(function.apply("")); }默认方法andThen使用:(进行组合操作)同上
Predicate
@FunctionalInterface public interface Predicate<T> { / * Evaluates this predicate on the given argument. * * @param t the input argument * @return {@code true} if the input argument matches the predicate, * otherwise {@code false} */ boolean test(T t); }Stream流
什么是Stream?
Java8 中,Collection 新增了两个流方法,分别是 Stream() 和 parallelStream()
Java8 中添加了一个新的接口类 Stream,相当于高级版的 Iterator,它可以通过 Lambda 表达式对集合进行大批量数据操作,或 者各种非常便利、高效的聚合数据操作。

Stream流不是一种数据结构,不保存数据,而是对数据进行加工处理。Stream API能让我们快速完成很多复杂的操作,如筛选、切片、映射、查找、去重、统计、匹配和规约。
为什么要使用 Stream?
在 Java8 之前,我们通常是通过 for 循环或者 Iterator 迭代来重新排序合并数据,又或者通过重新定义 Collections.sorts 的 Comparator 方法来实现,这两种方式对于大数据量系统来说,效率并不是很理想。Stream 的聚合操作与数据库 SQL 的聚合操作 sorted、filter、map 等类似。我们在应用层就可以高效地实现类似数据库 SQL 的 聚合操作了,而在数据操作方面,Stream 不仅可以通过串行的方式实现数据操作,还可以通过并行的方式处理大批量数据,提高数据 的处理效率。

Stream流的获取方式
根据Collection
Collection中加入了default方法获取Stream流 List<String> list = new ArrayList<>(); list.stream(); Set<String> set = new HashSet<>(); set.stream(); Map<String,Object> map=new HashMap<>(); map.keySet().stream(); map.values().stream(); map.entrySet().stream();通过Stream的of方法
String[] s1={"aa","bb","cc"}; Stream.of(s1);Stream的常用方法
| 方法名 | 方法作用 | 返回值类型 | 方法种类 | 是否支持链式调用 |
|---|---|---|---|---|
| count | 统计个数 | long | 终结 | 否 |
| forEach | 遍历 | void | 终结 | 否 |
| filter | 过滤 | Stream | 函数拼接 | 是 |
| limit | 取用前几个 | Stream | 函数拼接 | 是 |
| skip | 跳过几个 | Stream | 函数拼接 | 是 |
| map | 映射 | Stream | 函数拼接 | 是 |
| concat | 组合 | Stream | 函数拼接 | 是 |
终结方法:返回值类型不再是Stream接口本身类型的方法,例如:forEach方法和count方法
非终结方法/延迟方法:返回值类型仍然是Stream接口自身类型的方法,除了终结方法都是延迟方法
注:
- Stream只能操作一次
- Stream返回的是新的流
- Stream不调用终结方法,中间的操作不会执行
forEach
void forEach(Consumer<? super T> action):逐一处理流中的元素(遍历流)
参数 Consumer<? super T> action : 函数式接口, 只有一个抽象方法:void accept(T t);
注意:
1.此方法并不保证元素的逐一消费动作在流中是有序执行的
2.Consumer 是一个消费接口(可以获取流中的元素进行遍历操作,输出出去),可以使用lambda表达式
public class Tests_forEach { public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("张三"); list.add("张三四"); list.add("王五"); list.add("赵六"); list.add("张三三"); list.add("周八"); // 函数模型:获取流 --> 逐一消费流中的元素 // 函数模型:获取流 --> 逐一消费流中的元素 list.stream().forEach(System.err::println); /* * 虽然方法名称叫做【forEach】,但是与for循环中的【for-each】昵称不同,该方法并不保证元素的逐一消费动作在流中是被有序执行的 * */ System.out.println("=========================="); // parallelStream()方法可以得到并行流 list.parallelStream().forEach((String name)->{ System.out.println(name); }); } }filter
Stream filter(Predicate<? super T> predicate); 过滤出满足条件的元素,将一个流转换为一个子集流
参数Predicate:函数式接口,抽象方法:boolean test(T t);
Predicate接口:是一个判断接口
public class Tests_filter { public static void main(String[] args) { // 获取stream流 Stream<String> stream = Stream.of("张三", "张三四", "王五", "赵六", "张三三", "周八"); // 需求:过滤处 stream.filter((String name)->{ return name.startsWith("张"); }).forEach((String name)->{ System.out.println(name); }); } }limit
public class Tests_limit { public static void main(String[] args) { // 获取stream流 Stream<String> stream = Stream.of("张三", "张三四", "王五", "赵六", "张三三", "周八"); // 需求:保留前3个元素 stream.limit(3).forEach((String name) -> { System.out.println(name); }); System.out.println("==========================="); // 如果流的获取长度 大于 流当前的长度,则不操作 stream.limit(10).forEach(name-> System.out.println(name)); // 异常: stream has already // been operated upon or closed 流已**作或关闭 Stream<String> stream1 = Stream.of("张三", "张三四", "王五", "赵六", "张三三", "周八"); stream1.limit(10).forEach(name-> System.out.println(name)); } }skip
public class Tests_skip { public static void main(String[] args) { // 获取stream流 Stream<String> stream = Stream.of("张三", "张三四", "王五", "赵六", "张三三", "周八"); // 需求:跳过前3个 stream.skip(3).forEach(name-> System.out.println(name)); } }map
在对集合进行操作的时候,我们经常会从某些对象中选择性的提取某些元素的值,就像编写sql一样,指定获取表 中特定的数据列
Stream map(Function<? super T, ? extends R> mapper);
参数 Function<T,R>:函数式接口,抽象方法: R apply(T t);
Function<T,R>:其实就是一个类型转换接口(T和R的类型可以一致,也可以不一致)
案例:获取所有学生的姓名,并形成一个新的集合
public class MapDemo { public static void main(String[] args) { //获取所有学生的姓名,并形成一个新的集合 ArrayList<Student> students = new ArrayList<>(); students.add(new Student(1,19,"张三","M",true)); students.add(new Student(1,18,"李四","M",false)); students.add(new Student(1,21,"王五","F",true)); students.add(new Student(1,20,"赵六","F",false)); List<String> collect = students.stream().map(Student::getName).collect(Collectors.toList()); collect.forEach(s -> System.out.print(s + " ")); } } //结果:张三 李四 王五 赵六sorted
sort可以对集合中的所有元素进行排序
List<Integer> sortLists = new ArrayList<>(); sortLists.add(1); sortLists.add(4); sortLists.add(6); sortLists.add(3); sortLists.add(2); List<Integer> afterSortLists = sortLists.stream().sorted((In1,In2)-> In1-In2).collect(Collectors.toList());concat
如果有两个流,希望合并成为一个流,那么可以使用 Stream 接口的静态方法 concat:
public static void main(String[] args) { Stream<String> original1 = Stream.of("Java", "C", "Python"); Stream<String> original2 = Stream.of("Hadoop", "Spark"); Stream<String> result = Stream.concat(original1, original2); result.forEach(System.out::println); }distinct
去除重复元素,这个方法是通过类的 equals 方法来判断两个元素是否相等的
注:基本类型可以直接去重,对于自定义类型需要重写hashcode和equals方法
public static void main(String[] args) { List<Integer> integers = Arrays.asList(1, 2, 3, 4, 4, 5, 5, 6, 7, 8, 2, 2, 2, 2); integers.stream().distinct().collect(Collectors.toList()); }reduce
如果将所有数据归纳为一个数据,可以使用reduce
String s = Stream.of("1", "2", "3", "4", "5", "6") // identity 是默认值 .reduce("0",(x, y) -> { System.out.println("x= "+x+" y= "+y); return x +y; }); System.out.println(s); / 输出结果: x= 0 y= 1 x= 01 y= 2 x= 012 y= 3 x= 0123 y= 4 x= 01234 y= 5 x= 012345 y= 6 0 */min/max
max,min可以寻找出流中最大或者最小的元素
List<String> maxLists = new ArrayList<>(); maxLists.add("a"); maxLists.add("b"); maxLists.add("c"); maxLists.add("d"); maxLists.add("e"); maxLists.add("f"); maxLists.add("hahaha"); int maxLength = maxLists.stream().mapToInt(s->s.length()).max().getAsInt(); System.out.println("字符串长度最长的长度为"+maxLength);match
有的时候,我们只需要判断集合中是否全部满足条件,或者判断集合中是否有满足条件的元素,这时候就可以使用match方法:
allMatch:Stream 中全部元素符合传入的 predicate,返回 true
anyMatch:Stream 中只要有一个元素符合传入的 predicate,返回 true
noneMatch:Stream 中没有一个元素符合传入的 predicate,返回 true
// 判断集合中没有有为‘c’的元素: List<String> matchList = new ArrayList<>(); matchList.add("a"); matchList.add("a"); matchList.add("c"); matchList.add("d"); boolean isExits = matchList.stream().anyMatch(s -> s.equals("c")); //判断集合中是否全不为空 List<String> matchList = new ArrayList<>(); matchList.add("a"); matchList.add(""); matchList.add("a"); matchList.add("c"); matchList.add("d"); boolean isNotEmpty = matchList.stream().noneMatch(s -> s.isEmpty());collect
Stream流中提供了一个方法,可以把流中的数据收集到单列集合中:
<R, A> R collect(Collector<? super T, A, R> collector); 把流中的数据收集到单列集合中
返回值类型是R。R指定为什么类型,就是收集到什么类型的集合
参数Collector<? super T, A, R>中的R类型,决定把流中的元素收集到哪个集合中
参数Collector如何得到 ?,可以使用 java.util.stream.Collectors工具类中的静态方法:
- public static Collector<T, ?, List> toList():转换为List集合
tatic Collector<T, ?, Set> toSet() :转换为Set集合
public class Tests { public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("张三"); list.add("张三四"); list.add("王五"); list.add("赵六"); list.add("张三三"); list.add("周八"); // 需求:过滤出姓张的并且长度为3的元素 Stream<String> stream1 = list.stream().filter(name -> name.startsWith("张")).filter(name -> name.length() == 3); // stream 收集到单列集合中 List<String> list1 = stream1.collect(Collectors.toList()); System.out.println(list1); // stream 收集到单列集合中 Set<String> set1 = stream1.collect(Collectors.toSet()); System.out.println(set1); // 将stream流中的元素转成Array数组对象 Object[] arr = stream1.toArray(); System.out.println(Arrays.toString(arr)) } }串行流/并行流
串行流:流默认使用的就是串行的,即按序执行
并行流:parallelStream是一个并行执行流,它通过默认的ForkJoinPool,提高多线程的任务速度。
获取并行流的两种方式:
//串行流转换为并行流 Stream<String> parallel = Stream.of("1", "2", "3", "4", "5", "6") .parallel(); //List接口直接获取并行流 Stream<Object> parallelStream = new ArrayList<Object>().parallelStream();注:并行流可能会有数据安全问题,应对业务逻辑加锁
Optional类
Optional 类是一个可以为null的容器对象。如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象。
Optional 是个容器:它可以保存类型T的值,或者仅仅保存null。Optional提供很多有用的方法,这样我们就不用显式进行空值检测。
Optional 类的引入很好的解决空指针异常。
public final class Optional<T> extends Object基本使用
Optional对象的创建方式
ofNullable:允许一个可能为空的对象
of:需要一个不为空的对象
这里需要自行判断,初始化的对象是否必然非空。
Optional常用方法
- empty:可以创建一个空的Optional对象
- get:直接获取Optional内部对象,但是不建议单独使用
- isPresent:判断内部对象是否为空,返回一个布尔值
- ifPresent:一样判断内部对象是否为空,如果不为空会执行lambda表达式
- filter:通过一定条件过滤对象
- flatMap:和map的区别为lambda入参的对象封装入了Optional
- orElse:如果值为空,返回一个对象
- orElseGet:如果值为空,执行一段lambda并返回一个对象
- orElseThrow:如果值为空,抛出一个异常
public static void main(String[] args) { Optional<String> op1 = Optional.of("nihao"); Optional<Object> op2 = Optional.empty(); //1、get()方法获取值,有值返回值,无值抛出NoSuchElementException 异常 System.out.println(op1.get()); //nihao System.out.println(op2.get()); //No value present //2、isPresent() 判断是否包含值,包含值返回true,不包含返回false // ifPresent(T->{...}) 如果存在值就执行Lambda表达式 System.out.println(op1.isPresent()); //true System.out.println(op2.isPresent()); //false //3、 orElse(T t) 如果调用对象包含值,就返回该值,否则返回t // orElseGet(Supplier s) 如果调用对象包含值,就返回该值,否则返回Lambda表达式的返回值 System.out.println(op1.orElse("hi")); //nihao System.out.println(op2.orElse("123")); //123 }新时间日期API
java 8通过发布新的Date-Time API进一步加强对日期与时间的处理。在旧版的java中,日期时间APi存在诸多问题。java 8引入的新的一系列API,对时间日期处理提供了更好的支持,清楚的定义了时间日期的一些概念,比如说,瞬时时间(Instant),持续时间(duration),日期(date),时间(time),时区(time-zone)以及时间段(Period)。同时,借鉴了Joda库的一些优点,比如将人和机器对时间日期的理解区分开的。
新时间常用类
jdk8中新增加了一套全新的日期时间API,这套API设计合理,并且是线程安全的。API位于java.time包下:
- LocalDate:表示日期,包含年月日,格式为2020-01-11。
- LocalTime:表示时间,包含时分秒,格式为11:07:03.580。
- LocalDateTime:表示日期和时间组合,包含年月日,时分秒,格式为2020-01-11T11:07:03.580
- DateTimeFormatter:日期时间格式化类
- Instant:时间戳,表示一个特定的时间瞬间
- Duration:用于计算两个时间(LocalTime,时分秒)的距离
- Period:用于计算2个日期(LocalDate,年月日)的距离
- ZoneDateTime:包含时区的时间
基本使用
时间获取
//获取当前日期 LocalDate currDate=LocalDate.now(); //指定日期 LocalDate noeDay=LocalDate.of(2020, 1, 11); //通过字符串指定日期 LocalDate towDay=LocalDate.parse("2020-01-11"); // 年 int year = currDate.getYear(); // 月 int month = currDate.getMonthValue(); // 一月的第几天 int day = currDate.getDayOfMonth(); // 一周的第几天 int week = currDate.getDayOfWeek().getValue();时间操作
// 时间比较(LocalDate重写了equals方法,让日期的比较也变得简单了。) System.out.println("比较两个日期是否相同:"+date1.equals(date2)); //true //isBefore在之前 boolean isBefore=LocalDate.parse("2020-01-11").isBefore(LocalDate.parse("2020-01-10")); //isAfter在之后 boolean isAfter=LocalDate.parse("2020-01-11").isAfter(LocalDate.parse("2020-01-10")); // 日期加减 System.out.println("当前时间"+LocalDate.now()); System.out.println("当前时间加1天"+LocalDate.now().plusDays(1)); System.out.println("当前时间加1月"+LocalDate.now().plusMonths(1)); System.out.println("当前时间加1年"+LocalDate.now().plusYears(1)); //LocalDate的atTime()方法或LocalTime的atDate()方法将LocalDate或LocalTime合并成一个LocalDateTime。 //LocalDateTime与LocalDate和LocalTime之间可以相互转化 LocalDateTime datetime4=LocalDate.now().atTime(LocalTime.now()); LocalDateTime datetime5=LocalTime.now().atDate(LocalDate.now()); //ZonedDateTime-创建时区时间。用于处理带时区的日期和时间。ZoneId表示不同的时区。大约有40不同的时区。 Set<String> allZoneIds=ZoneId.getAvailableZoneIds(); //创建时区: ZoneId zoneId=ZoneId.of("Asia/Shanghai"); //把LocalDateTime转换成特定的时区: ZonedDateTime zonedDateTime=ZonedDateTime.of(LocalDateTime.now(), zoneId); //获取当前时区 ZoneId z=ZoneId.systemDefault(); //获取日期时间: ZonedDateTime dd = ZonedDateTime.now(); ZonedDateTime date1 = ZonedDateTime.parse("2015-12-03T10:15:30+05:30[Asia/Shanghai]");日期格式化
java.time.format.DateTimeFormatter类下:
Java8对日期的格式化操作非常简单,首先看到上面的类大多都提供了parse方法,可以直接通过解析字符串得到对应的对象。
而日期和时间的格式化可通过LocalDateTime的format方法进行格式化。
LocalDateTime dateTime=LocalDateTime.now(); String str=dateTime.format(DateTimeFormatter.ISO_DATE_TIME); System.out.println(str); str = dateTime.format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")); System.out.println(str);可以使用DateTimeFormatter预置的格式,也可以通过DateTimeFormatter.ofPattern方法来指定格式。
计算时间差
可以使用以下类来计算日期时间差异:1.Period 2.Duration 3.ChronoUnit
//日期时间差 LocalDate today = LocalDate.now(); LocalDate birthDate = LocalDate.of(1993, Month.OCTOBER, 19); Period p = Period.between(birthDate, today); // birthDate - today System.out.printf("年龄 : %d 年 %d 月 %d 日", p.getYears(), p.getMonths(), p.getDays()); //时分秒时间差 Instant inst1 = Instant.now(); Instant inst2 = inst1.plus(Duration.ofSeconds(10)); System.out.println("Difference in milliseconds : " + Duration.between(inst1, inst2).toMillis()); System.out.println("Difference in seconds : " + Duration.between(inst1, inst2).getSeconds()); //ChronoUnit类可用于在单个时间单位内测量一段时间,例如天数或秒 LocalDate startDate = LocalDate.of(1993, Month.OCTOBER, 19); System.out.println("开始时间 : " + startDate); LocalDate endDate = LocalDate.of(2017, Month.JUNE, 16); System.out.println("结束时间 : " + endDate); long daysDiff = ChronoUnit.DAYS.between(startDate, endDate); System.out.println("两天之间的差在天数 : " + daysDiff);//两天之间的差在天数 : 8641节点流
节点流针对的是具体的数据源操作的流,比如正对文件操作的流,针对字符数组操作的流,针对管道操作的流,针对字符串操作的流, 因此节点流只能处理固定数据格式存储的数据,因此如果在网络编程中不知道对方传递的是什么格式的数据时使用比较困难。 具体有: FileInputStream /FileOutputStream FileReader / FileWriter ByteArrayInputStream / ByteArrayOutputStream ByteArrayReader / ByteArrayWriter PipedInputStream /PipedOutputStream PipedReader / PipedWriter StringReader / StringWriter包装流
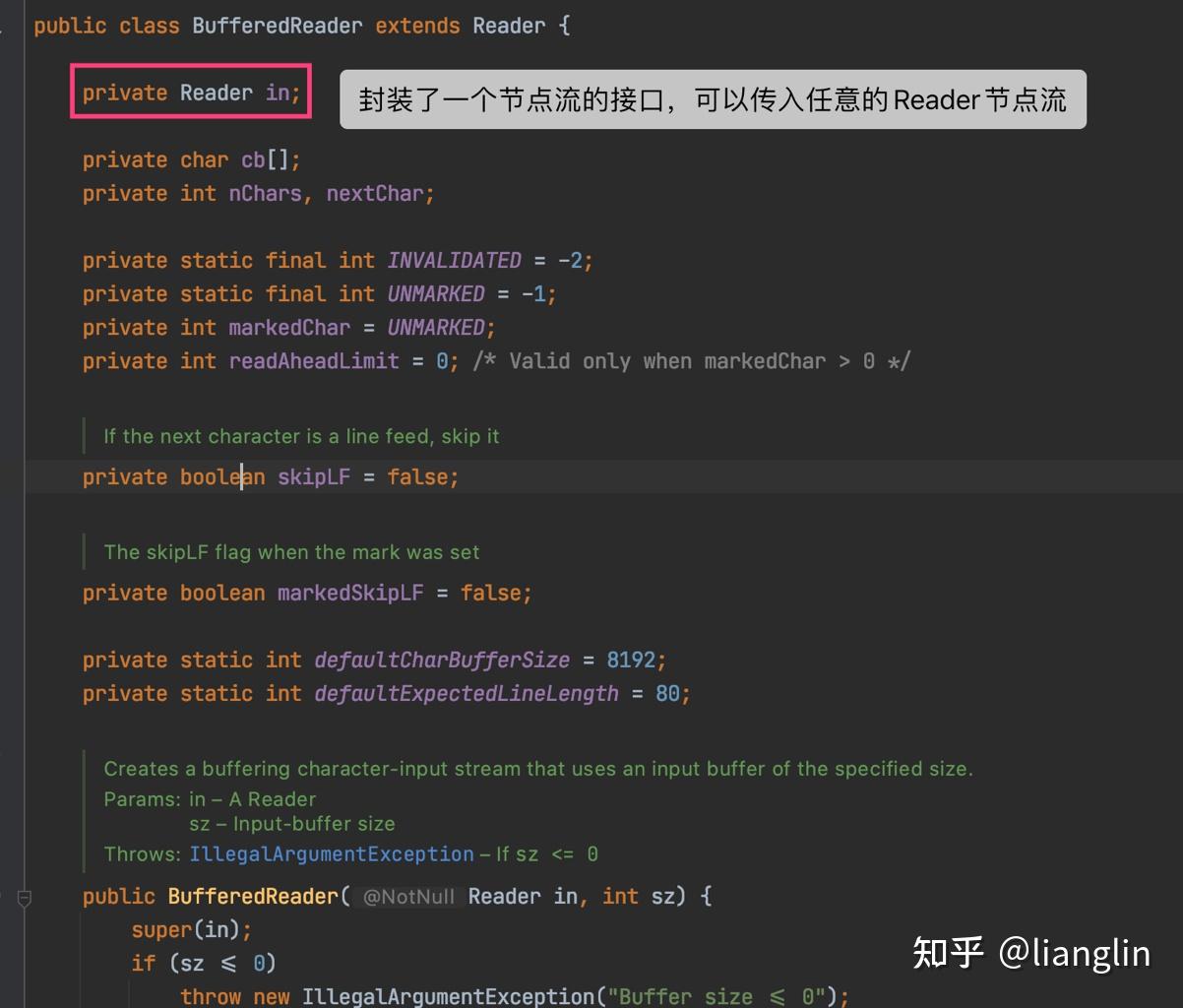
包装流实际上是对节点流的一种封装,性能比节点流更加强大,用到的是【装饰器设计模式】,包装流的强大的地方在于可以接受任意格式的节点 流数据,对于网络编程常用的是包装流来处理。 具体有 BufferedInputStream /BufferedOutputStream BufferedReader / BufferedWriter InputStreamReader /OutputStreamWriter ObjectInputStream /ObjectOutputStream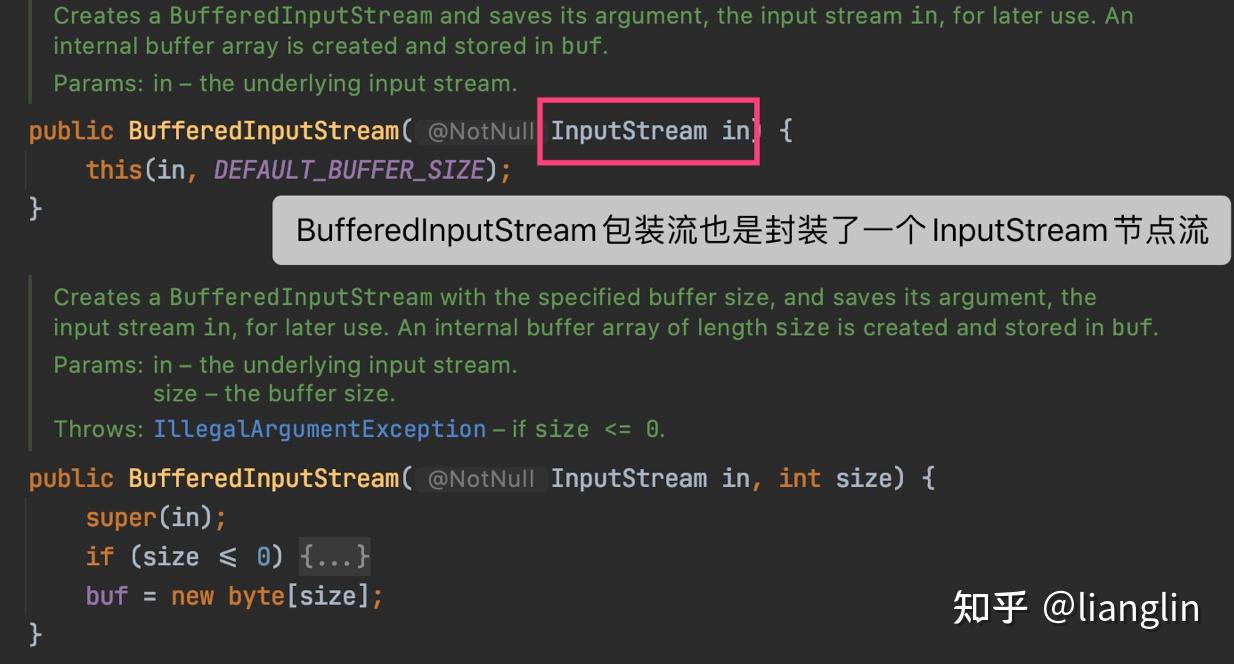
Java修饰注解的注解(元注解)
- @Target 设置目标范围
- @Retention 设置保持性
- @Documented 文档
- @Inherited 注解继承
- @Repeatable 此注解可以重复修饰
Java自带注解
- @SuppressWarning 压制警告,修饰变量 / 方法 / 构造函数 / 类等
- @SuppressWarning("unchecked") 忽略unchecked警告信息
- @SuppressWarning("deprecated") 忽略过时方法的警告信息
- @SuppressWarning({"unchecked", "deprecated"}) 忽略unchecked和过时方法的警告信息(JDK自规定了这两种)
- @Deprecated 描述某个方法或代码已过时,修饰类 / 类的元素 / 包
- @Override 重写方法标记,修饰方法
- @SafeVarargs 不会对不定项参数做危险操作
- @FunctionInterface 声明功能性接口
public static void main(String[] args) { int a = 5; Date d = new Date(); // 警告 System.out.println(d.getYear()); } // Date类中的getYear()函数 @Deprecated public int getYear() { return normalize().getYear() - 1900; }使用@SupperssWarning后
@SuppressWarnings("all") public static void main(String[] args) { int a = 5; Date d = new Date(); System.out.println(d.getYear()); }无任何警告
Java自定义注解
- 从JDK1.5引入,注解定义:扩展java.lang.annotation.Annotation注解接口
- 注解可以包括的类型
- 基本类型(int / short / long / float / double / byte / char / boolean)
- String
- Class
- enum类型
- 注解类型
- 有前面类型组成的数组
注解使用的位置
- @Target 可以限定位置
- 允许的位置
- 包 / 类 / 接口 / 方法 / 构造器 / 成员变量 / 局部变量 / 形参变量 / 类型参数
注解无参数
/ * @ClassName: Foo * @Author: Tang * @Date: 2021/6/4 15:01 */ public class Foo { @Test public static void m1() { } @Test public static void m2() { throw new RuntimeException("m2 function error"); } @Test public static void m3() { } @Test public static void m4() { throw new RuntimeException("m4 function error"); } @Test public static void m5() { } }注解测试
public class Demo1 { public static void main(String[] args)throws Exception { // 记录通过以及不同的个数 int pass = 0, failed = 0; String className = "exmple.com.demo8.Foo"; // 获取Foo类中的所有方法 for (Method m : Class.forName(className).getMethods()) { // 判断是否有@Test注解 if (m.isAnnotationPresent(Test.class)) { try { m.invoke(null); pass++; } catch (Throwable ex) { System.out.printf("测试: %s 失败: %s %n", m, ex.getCause()); } } } System.out.printf("通过: %d, 失败 %d%n", pass, failed); } } // 表示该注解会保留在class文件中 @Retention(RetentionPolicy.RUNTIME) // 表示该注解只会作用于方法上 @Target(ElementType.METHOD) @interface Test { }运行结果:
测试: public static void exmple.com.demo8.Foo.m4() 失败: java.lang.RuntimeException: m4 function error 测试: public static void exmple.com.demo8.Foo.m2() 失败: java.lang.RuntimeException: m2 function error 通过: 3, 失败 0
注解带参数
public class Foo { // 给a赋值 @SingleTest(1) public static void m1(int a) { if (a < 0) { throw new RuntimeException("m1 function parameter error"); } } // 等价于@SingleTest(-2) @SingleTest(value = -2) public static void m2(int b) { if (b < 0) { throw new RuntimeException("m2 function parameter error"); } } }注解测试
public class Demo2 { public static void main(String[] args) throws ClassNotFoundException { int pass = 0, failed = 0; String className = "exmple.com.demo8.Foo"; for (Method m : Class.forName(className).getMethods()) { // 判断是否有SingleTest注解 if (m.isAnnotationPresent(SingleTest.class)) { // 输出函数名 System.out.println(m.getName()); // 获取方法上的注解 SingleTest st = m.getAnnotation(SingleTest.class); try { // 将获取到的值赋值给方法的形参 m.invoke(null, st.value()); // 等价SingleTest.value() pass++; } catch (Throwable e) { System.out.printf("测试: %s 失败: %s %n", m, e.getCause()); failed++; } } } System.out.printf("通过: %d, 失败: %d%n", pass, failed); } } // 表示该注解会保留在class文件中 @Retention(RetentionPolicy.RUNTIME) // 表示该注解只能用于方法中 @Target(ElementType.METHOD) @interface SingleTest { // 定义一个int类型变量,默认值为0 // 与int a() default 0;等价 int value() default 0; }注解带多个参数时
// 表示该注解会保留在class文件中 @Retention(RetentionPolicy.RUNTIME) // 表示该注解只能用于方法中 @Target(ElementType.METHOD) @interface SingleTest { // 定义一个int类型变量,默认值为0 int a() default 0; int b() default 0; } // 使用注解时 @SingleTest(a = 1) public static void m1(int a) { if (a < 0) { throw new RuntimeException("m1 function parameter error"); } } @SingleTest(a = -2, b = 2) public static void m2(int a, int b) { if (b < 0) { throw new RuntimeException("m2 function parameter error"); } } // 反射机制给方法形参赋值时 m.invoke(null, st.a(), st.b()); // 等价于SingleTest.a()Java元注解
- @Target 设置目标范围
- @Retention 设置保持性
- @Inherited 注解继承
- @Repeatable 此注解可以重复修饰
- @Documented 文档
@Rentention注解
- 用来修饰其他注解的存在范围
- RetentionPolicy.SOURCE 注解仅存在源码,不在class文件中
- RetentionPolicy.CLASS 默认的保留策略。注解存在于.class文件中,当但不能被JVM加载,即不能使用反射获取到
- RetentionPolicy.RUNTIME 注解可以被JVM运行时访问到。通常情况下,可以结合反射来实现一些功能
@Target注解
- 限定注解作用于什么位置
- ElementType.ANNOTAION_TYPE (修饰注解)
- ElementType.CONSTRUCTOR
- ElementType.FIELD
- ElementType.LOCAL_VARIABLE (局部变量)
- ElementType.METHOD
- ElementType.PACKAGE
- ElementType.RARAMETER (参数)
- ElementType.TYPE (任何类型,即上面的类型都可以修饰)
@Inherited注解
- 让一个类和它的子类都包括某个注解
- 普通注解没有继承功能
public class Demo3 { public static void main(String[] args) throws ClassNotFoundException { Class c1 = Class.forName("exmple.com.demo8.MySupperClass1"); Class c2 = Class.forName("exmple.com.demo8.MySubClass1"); System.out.println("使用了@Inherited: "); System.out.println("父类: " + c1.getAnnotations().length); System.out.println("子类:" + c2.getAnnotations().length); System.out.println("没有使用@Inherited: "); Class c3 = Class.forName("exmple.com.demo8.MySupperClass2"); Class c4 = Class.forName("exmple.com.demo8.MySubClass2"); System.out.println("父类:" + c3.getAnnotations().length); System.out.println("子类:" + c4.getAnnotations().length); } } @Retention(RetentionPolicy.RUNTIME) @Inherited @interface MyAnnotation1 {} @MyAnnotation1 class MySupperClass1 {} class MySubClass1 extends MySupperClass1 {} @Retention(RetentionPolicy.RUNTIME) @interface MyAnnotation2 {} @MyAnnotation2 class MySupperClass2 {} class MySubClass2 extends MySupperClass2 {}运行结果
使用了@Inherited: 父类: 1 子类:1 没有使用@Inherited: 父类:1 子类:0
可以看出使用@Inherited可以使子类包含父类的注解
@Repleatable注解
- 自JDK1.8引入
- 表示被修饰的注解可以重复应用标注
- 需要定义注解和容器注解
public class Demo4 { public static void main(String[] args) throws ClassNotFoundException { String className = "exmple.com.demo8.Student"; // 获取目标对象的所有方法 for (Method m : Class.forName(className).getMethods()) { // 判断是否有容器注解 if (m.isAnnotationPresent(RepeatableAnnotations.class)) { RepeatableAnnotation[] annos = m.getAnnotationsByType(RepeatableAnnotation.class); for (RepeatableAnnotation anno : annos) { System.out.println(anno.a() + "," + anno.b() + "," + anno.c()); try { // 将获取到的值传递给方法形参 m.invoke(null, anno.a(), anno.b(), anno.c()); } catch (Throwable ex) { System.out.printf("测试: %s 失败: %s %n", m, ex.getCause()); } } } } } } class Student { @RepeatableAnnotation(a = 1, b = 2, c = 3) @RepeatableAnnotation(a = 1, b = 2, c = 4) public static void add(int a, int b, int c) { if (c != a + b) { throw new RuntimeException("add function error"); } } } @Retention(RetentionPolicy.RUNTIME) // 运行该注解可以重复标注 @Repeatable(RepeatableAnnotations.class) @interface RepeatableAnnotation { int a() default 0; int b() default 0; int c() default 0; } // 容器注解 @Retention(RetentionPolicy.RUNTIME) @interface RepeatableAnnotations { RepeatableAnnotation[] value(); }运行结果
1,2,3 1,2,4 测试: public static void exmple.com.demo8.Student.add(int,int,int) 失败: java.lang.RuntimeException: add function error
@Documented注解
指明这个注解可以被JavaDoc工具解析,形成帮助文档
IO流
概述
作用:传输数据
分类:
方式1、按照流向分类
输入流
输出流
方式2、按照传输的数据分类
字节流:传输的数据以字节(byte)为单位
字符流:传输的数据以字符(char)为单位
方式3、按功能分类
包装流:对传输的数据进行加工
节点流:直接从数据源到程序或从程序到指定位置
字节流:
体系:
InputStream:字节输入流
方法:int read():一次读取一个字节,返回值为读取到的字节,当返回值为-1时表示读取结束
int read(byte b[]):一次读取一组字节,读取带数组b中,返回值为本次读取到的长度,将读取到的数据从第0个位置开始存储
int rade(byte b[],int off,int len):一次读取一组字节,读取到数组b中,返回值为本次读取到的长度,将读取到的数据从第off个位置开始存储,存储len个;
void close():关闭流
OutputStream:字节输出流
方法:
void write(int b):一次写入一个字节
void write(byte b[]):一次写入一组字节
void write(byte b[],int off,int len):一次写入一组字节,从off位置开始,写入len个
void flish():冲刷流
void close():关闭流
文件流
作用:将数据写入到文件中或从文件中读取数据
FileInputStream:从文件中读取该数据
FileInOuttStream:将数据写入到文件中
注意:
FileOutputStream(文件地址):当文件不存在则创建一级文件,如果文件存在,则删除文件,再创建新文件
FileOutputStream(文件地址,是否追加):当文件不存在则创建一级文件,当二参为true如果文件存在,在原有基础上追加
内存流
作用:将数据写入到内存中,或从内存中读取数据
注意:默认内存大小为32b,自动扩容
ByteArrayInputStream
ByteArrayOutputStream
toByteArray():获取内存流中的数据
缓冲流
作用:提高代码的读写效率
注意:缓冲区默认大写8kb
BufferedInputstream
BufferedOutputstream
对象流
作用:读写对象
ObjectInputstream
Object readObject()
ObjectOutputstream
Object writeObject(Object obj);
注意:
1、读写的对象所属的类必须实现序列化接口(Serializable)
2、静态属性不参与序列化
3、瞬时属性不参与序列化(使用transient修饰的属性)
路径
相对路径:相对于当前文件的位置
.:当前路径
..:上一级路径
\:windows系统下的路径分隔符
相对于当前项目下
绝对路径:从盘符的根目录开始书写
经验
1、你会那些设计模式?
单例
工厂
生产者与消费者
监听者默认
2、是否使用过装饰者模式
使用过,所以的包装流都是装饰者模式
没有什么技术点,大家就是记忆,就是冲,把语法和单词都熟记于心,用起来才不会卡壳,多去敲代码,少幻想,多实践,什么东西不用都会锈,把键盘敲烂!!~!
- Java IO入门必读:新手进阶秘籍(一)
字节操作
字节输出流FileOutputStream
创建输出流对象
OutputStream 流对象是一个抽象类,不能实例化。所以,我们要找一个具体的子类 :FileOutputStream。 查看FileOutputStream的构造方法:
FileOutputStream(File file) FileOutputStream(String name) 创建字节输出流对象了做了几件事情:
- 调用系统功能去创建文件
- 创建字节输出流对象
- 把该字节输出流对象引用指向这个文件
public class OutputStreamDemo { public static void main(String[] args) throws IOException { OutputStream fos = new FileOutputStream("demo1.txt"); /* * 创建字节输出流对象了做了几件事情: * A:调用系统功能去创建文件 * B:创建fos对象 * C:把fos对象指向这个文件 */ //写数据 fos.write("hello,IO".getBytes()); fos.write("java".getBytes()); //释放资源 //关闭此文件输出流并释放与此流有关的所有系统资源。 fos.close(); /* * 为什么一定要close()呢? * A:让流对象变成垃圾,这样就可以被垃圾回收器回收了 * B:通知系统去释放跟该文件相关的资源 */ //java.io.IOException: Stream Closed //fos.write("java".getBytes()); } } - 为什么一定要close()呢?
- 让流对象变成垃圾,这样就可以被垃圾回收器回收了
- 通知系统去释放跟该文件相关的资源
写出数据
字节输出流操作步骤:
- 创建字节输出流对象
- 写数据
- 释放资源
FileOutputStream中的写出方法:
public void write(int b) //写一个字节 public void write(byte[] b) //写一个字节数组 public void write(byte[] b,int off,int len) //写一个字节数组的一部分 public class OutputStreamDemo2 { public static void main(String[] args) throws IOException { FileOutputStream fos = new FileOutputStream("demo2.txt"); // 调用write()方法 fos.write(97); //97 -- 底层二进制数据 -- 通过记事本打开 -- 找97对应的字符值 -- a //public void write(byte[] b):写一个字节数组 byte[] bys={98,99,100,101}; fos.write(bys); //public void write(byte[] b,int off,int len):写一个字节数组的一部分 fos.write(bys,1,3); //释放资源 fos.close(); } } 如何实现数据的换行?不同的系统针对不同的换行符号识别是不一样的?
windows:\r\n linux:\n Mac:\r public class OutputStreamDemo3 { public static void main(String[] args) throws IOException { // 创建一个向具有指定 name 的文件中写入数据的输出文件流。 // 如果第二个参数为 true,则将字节写入文件末尾处,而不是写入文件开始处。 FileOutputStream fos = new FileOutputStream("demo2.txt",true); // 写数据 for (int x = 0; x < 10; x++) { fos.write(("hello" + x).getBytes()); fos.write("\r\n".getBytes()); } //释放资源 fos.close(); } } 加入异常处理的字节输出流操作
public class OutputStreamDemo4 { public static void main(String[] args) throws IOException { FileOutputStream fos = null; try { fos = new FileOutputStream("demo1.txt"); fos.write("java".getBytes()); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { // 如果fos不是null,才需要close() if (fos != null) { // 为了保证close()一定会执行,就放到这里了 try { fos.close(); } catch (IOException e) { e.printStackTrace(); } } } } } 字节输入流FileInputStream
- 字节输入流操作步骤:
- 创建字节输入流对象
- 调用read()方法读取数据,并把数据显示在控制台
- 释放资源
- 读取数据的方式:
int read() //一次读取一个字节 int read(byte[] b) //一次读取一个字节数组 - 一次读取一个字节
public class InputStreamDemo { public static void main(String[] args) throws IOException { InputStream fis=new FileInputStream("demo1.txt"); int by = 0; // 读取,赋值,判断 while ((by = fis.read()) != -1) { System.out.print((char) by); } // 释放资源 fis.close(); } } - 一次读取一个字节数组
public class InputStreamDemo2 { public static void main(String[] args) throws IOException { FileInputStream fis=new FileInputStream("demo1.txt"); //数组的长度一般是1024或者1024的整数倍 byte[] bys = new byte[1024]; int len = 0; while ((len = fis.read(bys)) != -1) { System.out.print(new String(bys, 0, len)); } // 释放资源 fis.close(); } } 带缓冲区的字节流BufferedOutputStream
public class BufferedOutputStreamDemo { public static void main(String[] args) throws IOException { BufferedOutputStream bos=new BufferedOutputStream(new FileOutputStream("demo1.txt")); bos.write("hello".getBytes()); bos.close(); } } 带缓冲区的字节流BufferedInputStream
public class BufferedInputStreamDemo { public static void main(String[] args) throws IOException { BufferedInputStream bis=new BufferedInputStream(new FileInputStream("demo1.txt")); int by=-1; while((by=bis.read())!=-1){ System.out.print((char)by); } bis.close(); } } 复制文件
public class CopyFile { public static void main(String[] args) throws IOException { String strFile="国旗歌.mp4"; String destFile="demo3.mp4"; long start = System.currentTimeMillis(); //copyFile(strFile,destFile); //共耗时:75309毫秒 //copyFile2(strFile,destFile); //共耗时:153毫秒 //copyFile3(strFile,destFile);//共耗时:282毫秒 copyFile4(strFile,destFile);//共耗时:44毫秒 long end = System.currentTimeMillis(); System.out.println("共耗时:" + (end - start) + "毫秒"); } / * 基本字节流一次读写一个字节 */ public static void copyFile(String srcFile,String destFile) throws IOException { FileInputStream fis=new FileInputStream(srcFile); FileOutputStream fos=new FileOutputStream(destFile); int by=0; while((by=fis.read())!=-1){ fos.write(by); } fis.close(); fos.close(); } / * 基本字节流一次读写一个字节数组 */ public static void copyFile2(String srcFile,String destFile) throws IOException{ FileInputStream fis=new FileInputStream(srcFile); FileOutputStream fos=new FileOutputStream(destFile); int len=0; byte[] bys=new byte[1024]; while((len=fis.read(bys))!=-1){ fos.write(bys,0,len); } fis.close(); fos.close(); } / * 高效字节流一次读写一个字节 */ public static void copyFile3(String srcFile,String destFile) throws IOException{ BufferedInputStream bis=new BufferedInputStream(new FileInputStream(srcFile)); BufferedOutputStream bos=new BufferedOutputStream(new FileOutputStream(destFile)); int by=0; while((by=bis.read())!=-1){ bos.write(by); } bis.close(); bos.close(); } / * 高效字节流一次读写一个字节数组 */ public static void copyFile4(String srcFile,String destFile) throws IOException{ BufferedInputStream bis=new BufferedInputStream(new FileInputStream(srcFile)); BufferedOutputStream bos=new BufferedOutputStream(new FileOutputStream(destFile)); int len=0; byte[] bys=new byte[1024]; while((len=bis.read(bys))!=-1){ bos.write(bys,0,len); } bis.close(); bos.close(); } } 装饰者模式
Java I/O 使用了装饰者模式来实现。以 InputStream 为例,
- InputStream 是抽象组件;
- FileInputStream 是 InputStream 的子类,属于具体组件,提供了字节流的输入操作;
- FilterInputStream 属于抽象装饰者,装饰者用于装饰组件,为组件提供额外的功能。例如 BufferedInputStream 为 FileInputStream 提供缓存的功能。
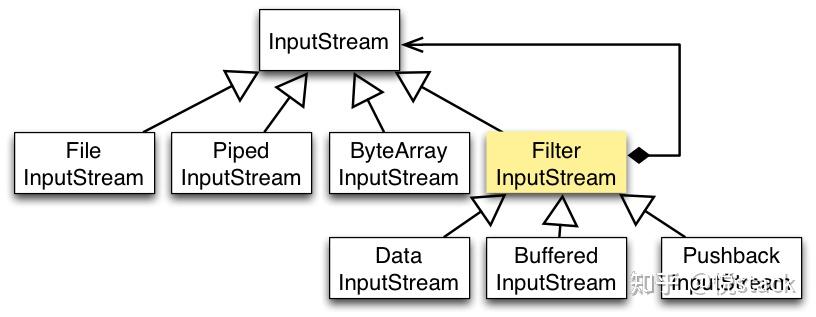
实例化一个具有缓存功能的字节流对象时,只需要在 FileInputStream 对象上再套一层 BufferedInputStream 对象即可。
FileInputStream fileInputStream = new FileInputStream(filePath); BufferedInputStream bufferedInputStream = new BufferedInputStream(fileInputStream); DataInputStream 装饰者提供了对更多数据类型进行输入的操作,比如 int、double 等基本类型。
对象操作
序列化 & 反序列化
如果我们需要持久化 Java 对象比如将 Java 对象保存在文件中,或者在网络传输 Java 对象,这些场景都需要用到序列化。
序列化就是将数据结构或对象转换成二进制字节流的过程。
反序列化将在序列化过程中所生成的二进制字节流转换成数据结构或者对象的过程。
- 序列化:ObjectOutputStream.writeObject()
- 反序列化:ObjectInputStream.readObject()
不会对静态变量进行序列化,因为序列化只是保存对象的状态,静态变量属于类的状态。
Serializable
序列化的类需要实现 Serializable 接口,它只是一个标准, 没有任何方法需要实现,但是如果不去实现它的话而进行序列化,会抛出异常。
/ * 序列化就是将一个对象转换成字节序列,方便存储和传输。 - 序列化:ObjectOutputStream.writeObject() - 反序列化:ObjectInputStream.readObject() */ public class SerializableDemo { public static void main(String[] args) throws IOException, ClassNotFoundException { String objectFile="demo6.txt"; //序列化 serialize(objectFile); //反序列化 deserialize(objectFile); } //序列化 public static void serialize(String objectFile) throws IOException { A a=new A(1,"aaa"); ObjectOutputStream objectOutputStream=new ObjectOutputStream(new FileOutputStream(objectFile)); //序列化 objectOutputStream.writeObject(a); objectOutputStream.close(); } //反序列化 public static void deserialize(String objectFile) throws IOException, ClassNotFoundException { ObjectInputStream objectInputStream=new ObjectInputStream(new FileInputStream(objectFile)); A a2=(A)objectInputStream.readObject(); System.out.println(a2); objectInputStream.close(); } private static class A implements Serializable { private int x; private String y; A(int x, String y) { this.x = x; this.y = y; } @Override public String toString() { return "x = " + x + " " + "y = " + y; } } } 输出结果:
x = 1 y = aaa transient
transient 关键字可以使一些属性不会被序列化。
ArrayList 中存储数据的数组 elementData 是用 transient 修饰的,因为这个数组是动态扩展的,并不是所有的空间都被使用,因此就不需要所有的内容都被序列化。通过重写序列化和反序列化方法,使得可以只序列化数组中有内容的那部分数据。
private static class A implements Serializable { private int x; private transient String y; //transient 关键字可以使一些属性不会被序列化。 A(int x, String y) { this.x = x; this.y = y; } @Override public String toString() { return "x = " + x + " " + "y = " + y; } } 输出结果:
x = 1 y = null 网络操作
Java 中的网络支持:
- InetAddress:用于表示网络上的硬件资源,即 IP 地址;
- URL:统一资源定位符;
- Sockets:使用 TCP 协议实现网络通信;
- Datagram:使用 UDP 协议实现网络通信。
InetAddress
没有公有的构造函数,只能通过静态方法来创建实例。
InetAddress.getByName(String host); InetAddress.getByAddress(byte[] address); public class NetDemo { public static void main(String[] args) throws UnknownHostException { // public static InetAddress getByName(String host) InetAddress address = InetAddress.getByName("LAPTOP-D9966H06"); //InetAddress address = InetAddress.getByName("223.3.108.211"); //InetAddress address = InetAddress.getByName("192.168.2.1"); // 获取两个东西:主机名,IP地址 // public String getHostName() String name = address.getHostName(); // public String getHostAddress() String ip = address.getHostAddress(); System.out.println(name + "---" + ip); } } URL
可以直接从 URL 中读取字节流数据。
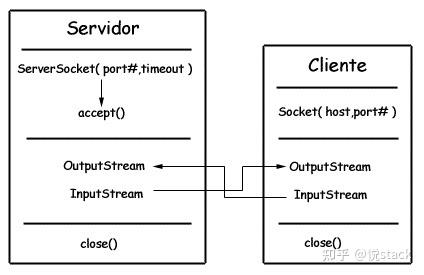
public static void main(String[] args) throws IOException { URL url = new URL("http://www.baidu.com"); /* 字节流 */ InputStream is = url.openStream(); /* 字符流 */ InputStreamReader isr = new InputStreamReader(is, "utf-8"); /* 提供缓存功能 */ BufferedReader br = new BufferedReader(isr); String line; while ((line = br.readLine()) != null) { System.out.println(line); } br.close(); } Sockets
- ServerSocket:服务器端类
- Socket:客户端类
- 服务器和客户端通过 InputStream 和 OutputStream 进行输入输出。
Datagram
- DatagramSocket:通信类
- DatagramPacket:数据包类
UDP协议
通信规则
- 将数据源和目的封装成数据包中,不需要建立连接;
- 每个数据报的大小在限制在64k;
- 因无连接,是不可靠协议;
- 不需要建立连接,速度快
UDP协议发送数据
- 创建发送端Socket对象
- 创建数据,并把数据打包
- 调用Socket对象的发送方法发送数据包
- 释放资源
public class SendDemo { public static void main(String[] args) throws IOException { //1. 创建发送端Socket对象 DatagramSocket ds=new DatagramSocket(); //2. 创建数据,并把数据打包 byte[] bys="hello".getBytes(); // 长度 int length = bys.length; // IP地址对象 InetAddress address = InetAddress.getByName("LAPTOP-D9966H06"); // 端口 int port = 10086; DatagramPacket dp = new DatagramPacket(bys, length, address, port); //3. 调用Socket对象的发送方法发送数据包 ds.send(dp); //4. 释放资源 ds.close(); } } UDP协议接收数据
- 创建接收端Socket对象
- 创建一个数据包(接收容器)
- 调用Socket对象的接收方法接收数据
- 解析数据包,并显示在控制台
- 释放资源
public class ReceiveDemo { public static void main(String[] args) throws IOException { //1. 创建接收端Socket对象 DatagramSocket ds=new DatagramSocket(10086); //2. 创建一个数据包(接收容器) byte[] bys=new byte[1024]; int length=bys.length; DatagramPacket dp=new DatagramPacket(bys,length); //3. 调用Socket对象的接收方法接收数据 //public void receive(DatagramPacket p) ds.receive(dp);//阻塞式 //4. 解析数据包,并显示在控制台 InetAddress inetAddress=dp.getAddress(); String ip=inetAddress.getHostAddress(); // public byte[] getData():获取数据缓冲区 // public int getLength():获取数据的实际长度 byte[] bys2 = dp.getData(); int len = dp.getLength(); String s = new String(bys2, 0, len); System.out.println(ip + "传递的数据是:" + s); //5. 释放资源 ds.close(); } } 使用UDP传输键盘录入的数据
- 接收端:
public class ReceiveDemo2 { public static void main(String[] args) throws IOException { DatagramSocket ds=new DatagramSocket(12345); while (true){ byte[] bys=new byte[1024]; DatagramPacket dp=new DatagramPacket(bys,bys.length); ds.receive(dp); //阻塞式 String ip=dp.getAddress().getHostAddress(); String s = new String(dp.getData(), 0, dp.getLength()); System.out.println(ip + "传递的数据是:" + s); } //接收端应该一直开着等待接收数据,不需要释放资源 //ds.close(); } } - 发送端:
public class SendDemo2 { public static void main(String[] args) throws IOException { DatagramSocket ds=new DatagramSocket(); //封装键盘录入数据 BufferedReader br=new BufferedReader(new InputStreamReader(System.in)); String line=null; while(true){ line=br.readLine(); if("-1".equals(line)){ break; } byte[] bys=line.getBytes(); DatagramPacket dp= new DatagramPacket(bys,bys.length,InetAddress.getByName("LAPTOP-D9966H06"),12345); ds.send(dp); } br.close(); //4. 释放资源 ds.close(); } } TCP协议
通信规则
- 建立连接,形成传输数据的通道;
- 在连接中进行大数据量传输;
- 通过三次握手完成连接,是可靠协议;
4.必须建立连接,效率会稍低
TCP协议发送数据
- 创建发送端的Socket对象:这一步如果成功,就说明连接已经建立成功了。
- 获取输出流,写数据
- 释放资源
public class ClientDemo { public static void main(String[] args) throws IOException { //1. 创建发送端的Socket对象:这一步如果成功,就说明连接已经建立成功了。 Socket socket=new Socket("LAPTOP-D9966H06",8888); //2. 获取输出流,写数据 OutputStream outputStream=socket.getOutputStream(); outputStream.write("hello".getBytes()); //3. 释放资源 socket.close(); } } TCP协议接收数据
- 创建接收端的Socket对象
- 监听客户端连接。返回一个对应的Socket对象
- 获取输入流,读取数据显示在控制台
- 释放资源
public class ServerDemo { public static void main(String[] args) throws IOException { //1. 创建接收端的Socket对象 ServerSocket serverSocket=new ServerSocket(8888); //2. 监听客户端连接。返回一个对应的Socket对象 Socket socket=serverSocket.accept(); //3. 获取输入流,读取数据显示在控制台 InputStream inputStream=socket.getInputStream(); byte[] bys = new byte[1024]; int len = inputStream.read(bys); // 阻塞式方法 String str = new String(bys, 0, len); String ip = socket.getInetAddress().getHostAddress(); System.out.println(ip + "---" + str); //4. 释放资源 socket.close(); } } - 注意:TCP通信中服务端也可以向客户端发送数据
public class ServerDemo2 { public static void main(String[] args) throws IOException { //1. 创建接收端的Socket对象 ServerSocket serverSocket=new ServerSocket(8888); //2. 监听客户端连接。返回一个对应的Socket对象 Socket socket=serverSocket.accept(); //3. 获取输入流,读取数据显示在控制台 InputStream inputStream=socket.getInputStream(); byte[] bys = new byte[1024]; int len = inputStream.read(bys); String str = new String(bys, 0, len); String ip = socket.getInetAddress().getHostAddress(); System.out.println(ip + "---" + str); //向客户端发送数据 OutputStream outputStream=socket.getOutputStream(); outputStream.write("数据已经收到".getBytes()); //4. 释放资源 socket.close(); } } public class ClientDemo2 { public static void main(String[] args) throws IOException { //1. 创建发送端的Socket对象:这一步如果成功,就说明连接已经建立成功了。 Socket socket=new Socket("LAPTOP-D9966H06",8888); //2. 获取输出流,写数据 OutputStream outputStream=socket.getOutputStream(); outputStream.write("hello".getBytes()); //从服务端获取反馈信息 InputStream inputStream=socket.getInputStream(); byte[] bys=new byte[1024]; int len=inputStream.read(bys); String reback=new String(bys,0,len); System.out.println("reback:"+reback); //3. 释放资源 socket.close(); } } 客户端键盘录入,服务器输出到控制台
- 服务端:
public class ServerDemo3 { public static void main(String[] args) throws IOException { //1. 创建接收端的Socket对象 ServerSocket serverSocket=new ServerSocket(8888); //2. 监听客户端连接。返回一个对应的Socket对象 Socket socket=serverSocket.accept(); //3. 获取输入流,读取数据显示在控制台 //这里对输入流要进行包装 InputStream inputStream=socket.getInputStream(); BufferedReader br=new BufferedReader(new InputStreamReader(inputStream)); String line=null; while((line=br.readLine())!=null){ System.out.println(line); } //4. 释放资源 socket.close(); } } - 客户端:
public class ClientDemo3 { public static void main(String[] args) throws IOException { //1. 创建发送端的Socket对象:这一步如果成功,就说明连接已经建立成功了。 Socket socket=new Socket("LAPTOP-D9966H06",8888); //键盘录入数据 BufferedReader br=new BufferedReader(new InputStreamReader(System.in)); //2. 获取输出流,写数据 //对输出流进行包装 OutputStream outputStream=socket.getOutputStream(); BufferedWriter bw=new BufferedWriter(new OutputStreamWriter(outputStream)); String line=null; while(true){ line=br.readLine(); if("-1".equals(line)){ break; } bw.write(line); bw.newLine(); bw.flush(); } //3. 释放资源 socket.close(); } }
链接:https://pan.baidu.com/s/1NPKHkDBafycerXdBfr1Wdg
提取码:0v8u
《疯狂Java讲义》是由李刚所著的一本Java编程教材。以下是该书的主要内容概要:
- Java语言基础: 介绍Java语言的基本语法、数据类型、运算符、流程控制等基础概念。
- 面向对象编程: 解释Java中的面向对象编程思想,包括类与对象、继承、多态、封装等。
- 异常处理: 讨论Java中的异常处理机制,如何使用try-catch语句捕获和处理异常。
- 集合框架: 介绍Java的集合框架,包括List、Set、Map等常用数据结构和算法。
- 多线程: 涵盖Java多线程编程的基础知识,包括线程的创建、同步、死锁等。
- 图形用户界面(GUI): 介绍Java中的Swing库,以及如何使用Swing创建图形用户界面。
- 网络编程: 讨论Java中的网络编程,包括Socket通信、HTTP通信等。
- 数据库编程: 涉及Java与数据库的交互,包括JDBC的使用和基本的SQL操作。
- Java EE技术: 简要介绍Java Enterprise Edition(Java EE)相关技术,如Servlet、JSP、EJB等。
- Spring框架: 概述Spring框架的基本概念和用法,包括依赖注入、AOP等。
- MyBatis和Hibernate: 介绍MyBatis和Hibernate这两个常用的持久化框架。
- JavaFX: 简要介绍JavaFX,用于创建富客户端应用程序的GUI工具包。
总体而言,这本书全面涵盖了Java编程的各个方面,从基础语法到高级应用,适合初学者学习Java编程语言以及对Java EE和一些流行框架有初步了解的读者。
本文记录Java8新特性Stream流式编程的使用
一、Stream流式操作简介
Stream流式操作,就是使用java.util.stream包下的API进行编程。
Stream不同于java的输入输出流,是实现对集合(Collection)的复杂操作。
可以实现查找、替换、过滤和映射数据等等操作。
二、Stream流式操作步骤
Stream流式操作主要有 3 个步骤,创建Stream对象、对数据源的数据进行处理的中间操作、产生结果的终止操作。
创建Stream对象
创建stream流对象有以下几种方式:
- 通过集合创建 Stream
- 通过数组创建 Stream
- 通过 Stream 的 of方法
中间操作
使用各种API对创建出来的Stream进行操作。
- filter
根据给定的条件过滤流中的元素。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5); List<Integer> evenNumbers = numbers.stream() .filter(num -> num % 2 == 0) .collect(Collectors.toList()); //[2, 4]2. map
将流中的每个元素映射为另一个元素,生成一个新的流。
List<String> names = Arrays.asList("Alice", "Bob", "Charlie"); List<Integer> nameLengths = names.stream() .map(String::length) //映射为长度 .collect(Collectors.toList()); // [5, 3, 7]3. sorted
对流中的元素进行排序。
List<Integer> numbers = Arrays.asList(3, 1, 4, 1, 5, 9, 2, 6, 5); List<Integer> sortedNumbers = numbers.stream() .sorted() .collect(Collectors.toList()); // [1, 1, 2, 3, 4, 5, 5, 6, 9]4. distinct
去除流中重复的元素。
List<Integer> numbers = Arrays.asList(1, 2, 2, 3, 3, 3, 4, 4, 4, 4); List<Integer> distinctNumbers = numbers.stream() .distinct() .collect(Collectors.toList());// [1, 2, 3, 4]5. limit
截取流中的前几个元素。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5); List<Integer> limitedNumbers = numbers.stream() .limit(3) .collect(Collectors.toList());// [1, 2, 3]6. skip
跳过流中的前几个元素。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5); List<Integer> skippedNumbers = numbers.stream() .skip(2) .collect(Collectors.toList());// [3, 4, 5]终止操作
Stream的终止操作用于触发流的计算(延迟执行)并得到最终的结果。
- forEach
对流中的每个元素执行指定的操作
List<String> names = Arrays.asList("Alice", "Bob", "Charlie"); names.stream() .forEach(System.out::println);//控制台输出每个字符串2. collect
将流中的元素收集到一个集合中。
List<String> names = Arrays.asList("Alice", "Bob", "Charlie"); List<String> collectedNames = names.stream() .collect(Collectors.toList());// 将流中的元素收集到List中3. count
返回流中元素的个数。
List<String> names = Arrays.asList("Alice", "Bob", "Charlie"); long count = names.stream() .count();// 返回3
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/1761.html