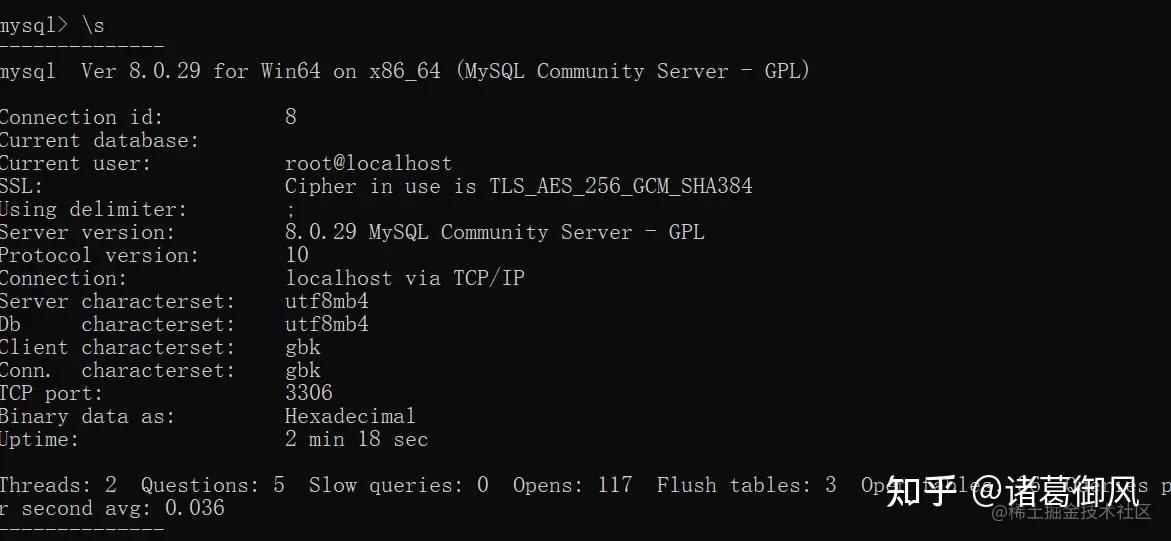
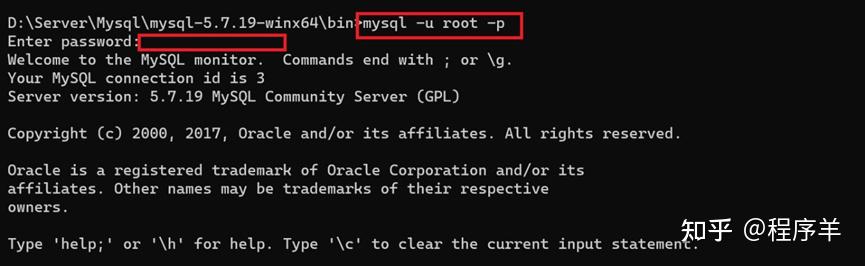
select /*+ SET_VAR(sort_buffer_size = 16M) / id from test order id ; insert /+ SET_VAR(foreign_key_checks=OFF) / into test(name) values(1);
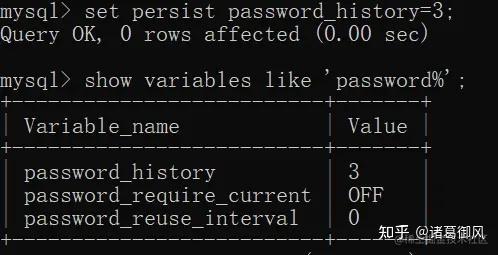
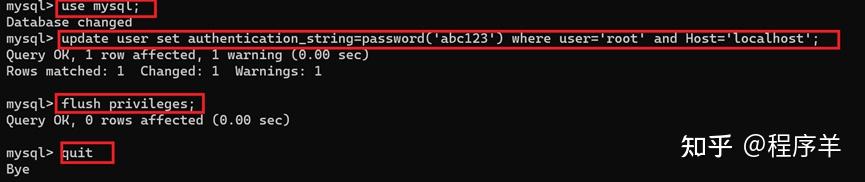
MySQL 8.0版本支持在线修改全局参数并持久化,通过加上PERSIST关键字,可以将修改的参数持久化到新的配置文件(mysqld-auto.cnf)中,重启MySQL时,可以从该配置文件获取到最新的配置参数。例如执行:
讯享网set PERSIST expire_logs_days=10 ;
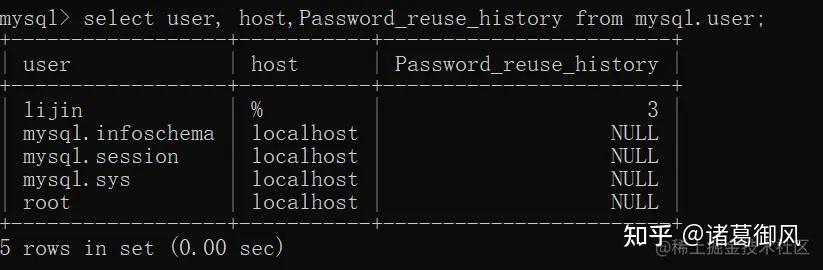
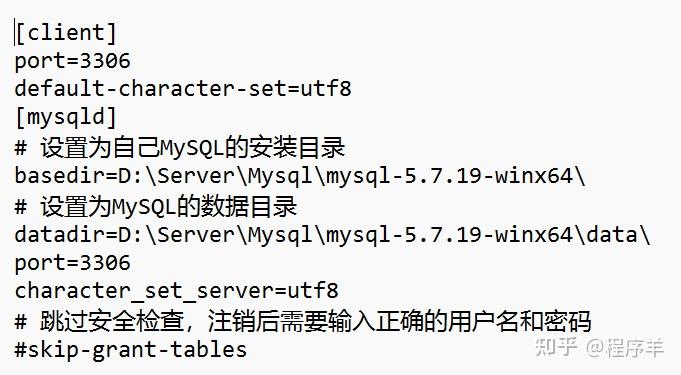
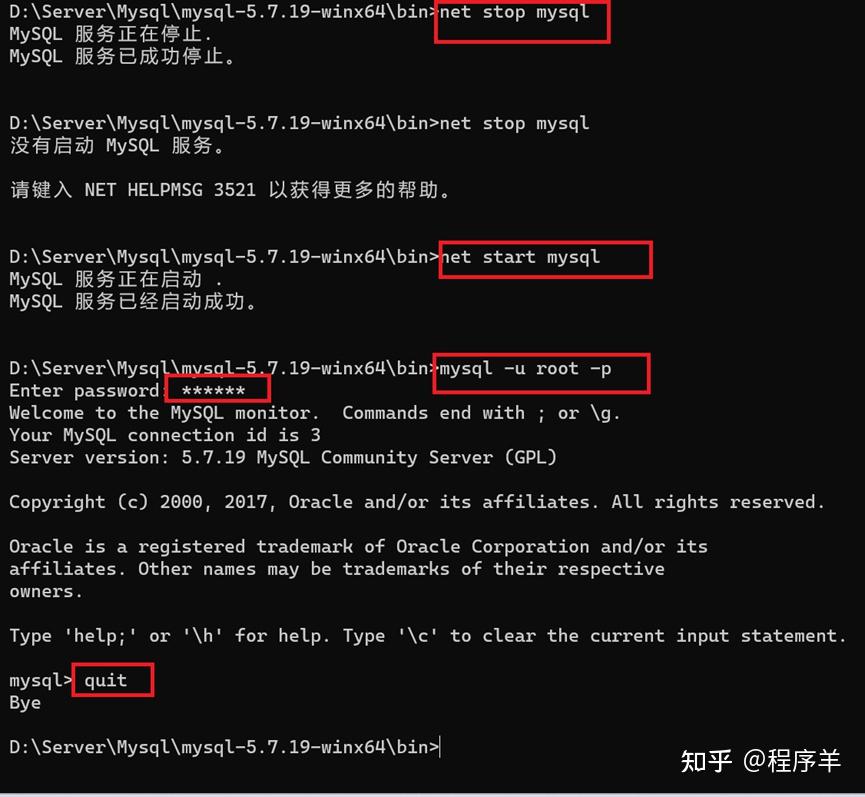
系统会在数据目录下生成一个包含json格式的 mysqld-auto.cnf 的文件,格式化后如下所示,当 my.cnf 和 mysqld-auto.cnf 同时存在时,后者具有更高优先级。select … for update,select … for share(8.0新增语法) 添加 NOWAIT、SKIP LOCKED语法,跳过锁等待,或者跳过锁定。在5.7及之前的版本,select…for update,如果获取不到锁,会一直等待,直到innodb_lock_wait_timeout超时。在8.0版本,通过添加nowait,skip locked语法,能够立即返回。如果查询的行已经加锁,那么nowait会立即报错返回,而skip locked也会立即返回,只是返回的结果中不包含被锁定的行。目的是为了兼容sql的标准语法,方便迁移mysql 5.7
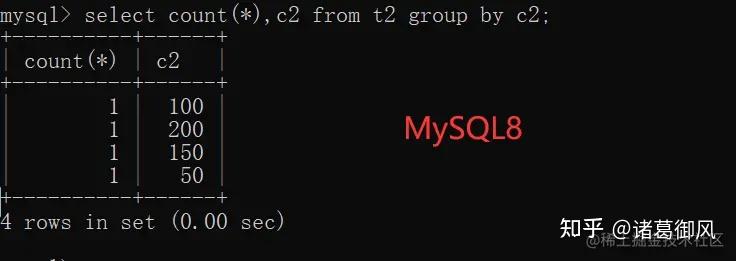
mysql> select count(),age from t5 group by age; +———-+——+ | count() | age | +———-+——+ | 1 | 25 | | 1 | 29 | | 1 | 32 | | 1 | 33 | | 1 | 35 | +———-+——+ 5 rows in set (0.00 sec)
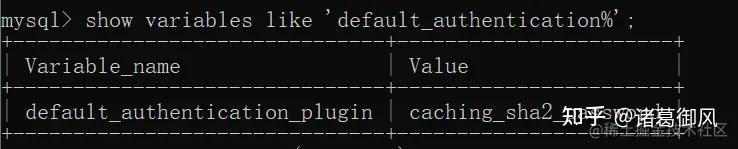
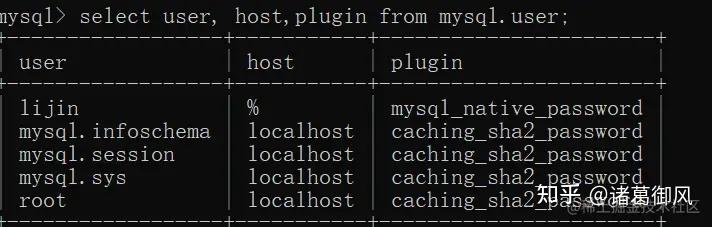
mysql 8.0
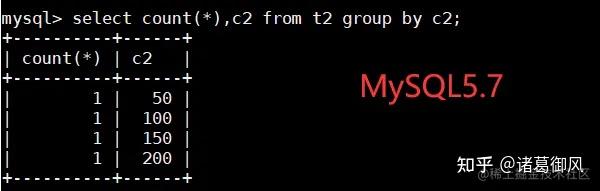
讯享网mysql> select count(),age from t5 group by age; +———-+——+ | count() | age | +———-+——+ | 1 | 25 | | 1 | 32 | | 1 | 35 | | 1 | 29 | | 1 | 33 | +———-+——+ 5 rows in set (0.00 sec)
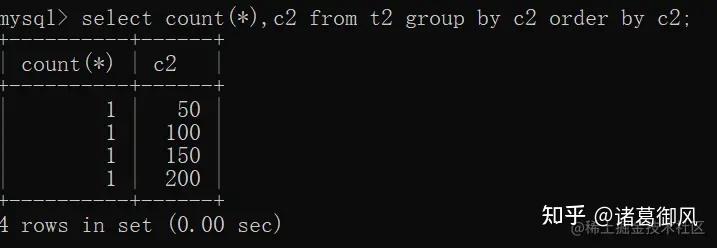
可以看到,MySQL5.7 在group by中对分组字段进行了隐式排序,而MySQL8.0取消了隐式排序。如果要添加排序的话,需要显示增加,比如 select count(),age from t5 group by age order by age;在8.0之前的版本,自增值是保存在内存中,自增主键AUTO_INCREMENT的值如果大于max(primary key)+1,在MySQL重启后,会重置AUTO_INCREMENT=max(primary key)+1。这种现象在某些情况下会导致业务主键冲突或者其他难以发现的问题。自增主键重启重置的问题很早就被发现(https://bugs.mysql.com/bug.php?id=199),一直到8.0才被解决。8.0版本将会对AUTO_INCREMENT值进行持久化,MySQL重启后,该值将不会改变。8.0开始,当前最大的自增计数器每当发生变化,值会被写入redo log中,并在每个检查点时候保存到private system table中。这一变化,对AUTO_INCREMENT值进行持久化,MySQL重启后,该值将不会改变。
MySQL server重启后不再取消AUTO_INCREMENT = N表选项的效果。如果将自增计数器初始化为特定值,或者将自动递增计数器值更改为更大的值,新的值被持久化,即使服务器重启。
只需将innodb_dedicated_server = ON 设置好,上面四个参数会自动调整,解决非专业人员安装数据库后默认初始化数据库参数默认值偏低的问题,让MySQL自适应的调整上面四个参数,前提是服务器是专用来给MySQL数据库的,如果还有其他软件或者资源或者多实例MySQL使用,不建议开启该参数,本文以MySQL8.0.19为例。那么按照什么规则调整呢?MySQL官方给出了相关参数调整规则如下:(1). innodb_buffer_pool_size自动调整规则:
说明:如果ROUND(buffer pool size)值小于2GB,那么innodb_log_files_in_group会强制设置为2。(4). innodb_flush_method自动调整规则:该参数调整规则直接引用官方文档的解释:The flush method is set to O_DIRECT_NO_FSYNC when innodb_dedicated_server is enabled. If the O_DIRECT_NO_FSYNC setting is not available, the default innodb_flush_method setting is used. 如果系统允许设置为O_DIRECT_NO_FSYNC;如果系统不允许,则设置为InnoDB默认的Flush method。
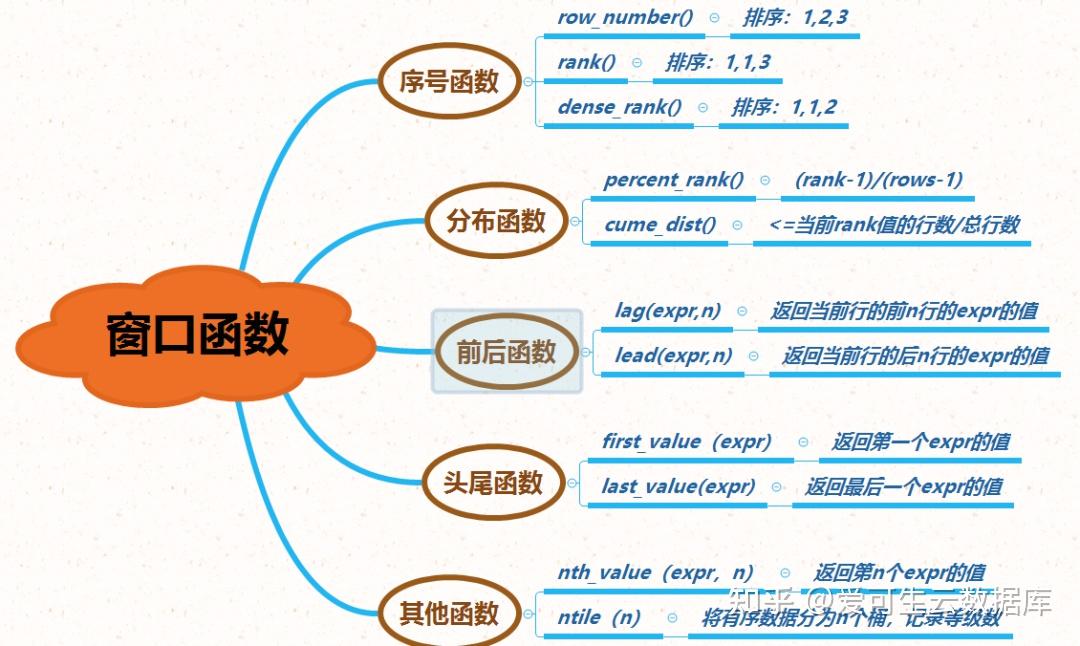
从 MySQL 8.0 开始,新增了一个叫窗口函数的概念。什么叫窗口?它可以理解为记录集合,窗口函数也就是在满足某种条件的记录集合上执行的特殊函数。对于每条记录都要在此窗口内执行函数,有的函数随着记录不同,窗口大小都是固定的,这种属于静态窗口;有的函数则相反,不同的记录对应着不同的窗口,这种动态变化的窗口叫滑动窗口。它可以用来实现若干新的查询方式。窗口函数与 SUM()、COUNT() 这种聚合函数类似,但它不会将多行查询结果合并为一行,而是将结果放回多行当中。即窗口函数不需要 GROUP BY。窗口函数内容太多,后期我会专门写一篇文章介绍窗口函数当遇到索引树损坏时,InnoDB会在redo日志中写入一个损坏标志,这会使损坏标志安全崩溃。InnoDB还将内存损坏标志数据写入每个检查点的私有系统表中。在恢复的过程中,InnoDB会从这两个位置读取损坏标志,并合并结果,然后将内存中的表和索引对象标记为损坏。InnoDB memcached插件支持批量get操作(在一个memcached查询中获取多个键值对)和范围查询。减少客户端和服务器之间的通信流量,在单个memcached查询中获取多个键、值对的功能可以提高读取性能。从 MySQL 8.0.12 开始(仅仅指InnoDB引擎),以下 ALTER TABLE 操作支持 ALGORITHM=INSTANT:
优化器能够感知到页是否存在缓冲池中。5.7其实已经开放接口,但是不对内存中的页进行统计,返回都是1.0。8.0版本对于读写皆有和高写负载的拿捏恰到好处。在集中的读写均有的负载情况下,我们观测到在4个用户并发的情况下,对于高负载,和5.7版本相比有着两倍性能的提高。在5.7上我们显著了提高了只读情况下的性能,8.0则显著提高了读写负载的可扩展性。为MySQL提升了硬件性能的利用率,其改进是基于重新设计了InnoDB写入Redo日志的方法。对比之前用户线程之前互相争抢着写入其数据变更,在新的Redo日志解决方案中,现在Redo日志由于其写入和刷缓存的操作都有专用的线程来处理。用户线程之间不在持有Redo写入相关的锁,整个Redo处理过程都是时间驱动。8.0版本允许马力全开的使用存储设备,比如使用英特尔奥腾闪存盘的时候,我们可以在IO敏感的负载情况下获得1百万的采样 QPS(这里说的IO敏感是指不在IBP中,且必须从二级存储设备中获取)。这个改观是由于我们摆脱了 file_system_mutex全局锁的争用。Better Performance upon High Contention Loads (“hot rows”)8.0版本显著地提升了高争用负载下的性能。高争用负载通常发生在许多事务争用同一行数据的锁,导致了事务等待队列的产生。在实际情景中,负载并不是平稳的,负载可能在特定的时间内爆发(80/20法则)。8.0版本针对短时间的爆发负载无论在每秒处理的事务数(换句话,延迟)还是95%延迟上都处理的更好。对于终端用户来说体现在更好的硬件资源利用率(效率)上。因为系统需要尽量使用榨尽硬件性能,才可以提供更高的平均负载。通过加上PERSIST关键字,可以将修改的参数持久化到新的配置文件(mysqld-auto.cnf)中,重启MySQL时,可以从该配置文件获取到最新的配置参数。系统会在数据目录下生成mysqld-auto.cnf 文件,该文件内容是以json格式存储的。当my.cnf 和mysqld-auto.cnf 同时存在时,后者优先级更高。例如:
SET PERSIST max_connections = 1000; SET @@PERSIST.max_connections = 1000;
此 SET 语法使您能够在运行时进行配置更改,这些更改也会在服务器重新启动后持续存在。与 SET GLOBAL 一样,SET PERSIST 设置全局变量运行时值,但也将变量设置写入 mysqld-auto.cnf 文件(如果存在则替换任何现有变量设置)。之前是天,并且参数名称发生变化. 在8.0版本之前,binlog日志过期时间设置都是设置expire_logs_days参数,而在8.0版本中,MySQL默认使用binlog_expire_logs_seconds参数。innodb_undo_log_truncate参数在8.0.2版本默认值由OFF变为ON,默认开启undo日志表空间自动回收。innodb_undo_tablespaces参数在8.0.2版本默认为2,当一个undo表空间被回收时,还有另外一个提供正常服务。innodb_max_undo_log_size参数定义了undo表空间回收的最大值,当undo表空间超过这个值,该表空间被标记为可回收。8.0 版本提供对地形的支持,其中包括了对空间参照系的数据源信息的支持,SRS aware spatial数据类型,空间索引,空间函数。总而言之,8.0版本可以理解地球表面的经纬度信息,而且可以在任意受支持的5000个空间参照系中计算地球上任意两点之间的距离。
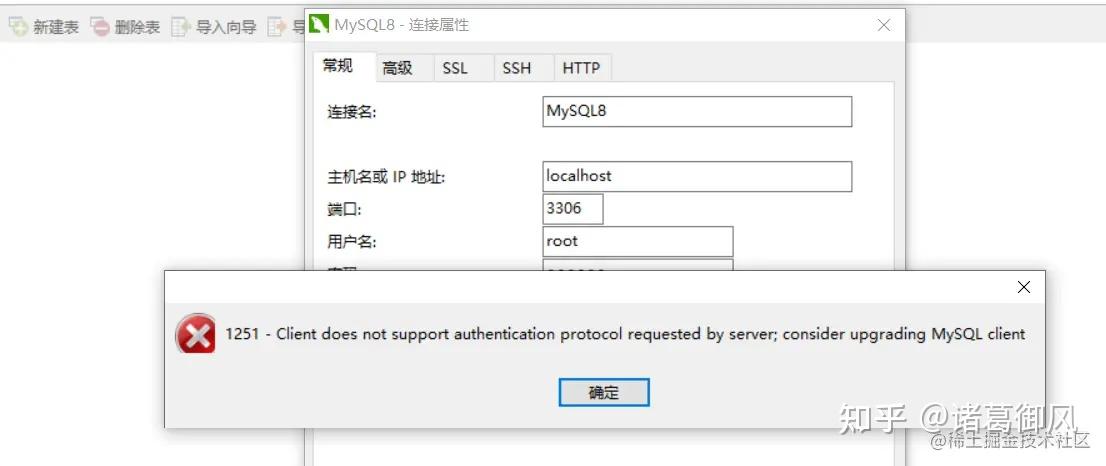
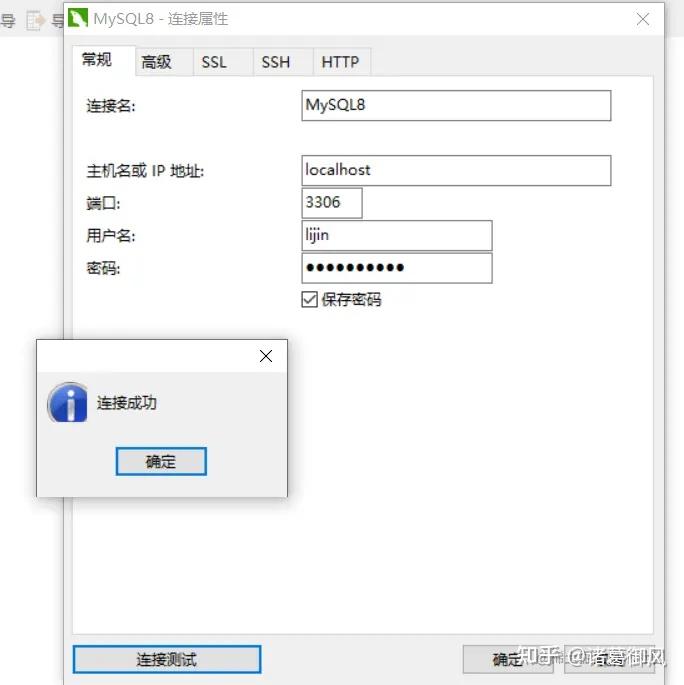
讯享网注意:升级前,一定要验证jdbc驱动是否匹配,是否需要随着升级。
select @@optimizer_switch \Gmysql> select @@optimizer_switch \G * 1. row * @@optimizer_switch: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on,use_invisible_indexes=off,skip_scan=on,hash_join=on,subquery_to_derived=off,prefer_ordering_index=on,hypergraph_optimizer=off,derived_condition_pushdown=onsession 开关 set session optimizer_switch=”use_invisible_indexes=off“; set session optimizer_switch=”use_invisible_indexes=on“;global 开关 set global optimizer_switch=”use_invisible_indexes=off“; set global optimizer_switch=”use_invisible_indexes=on“;
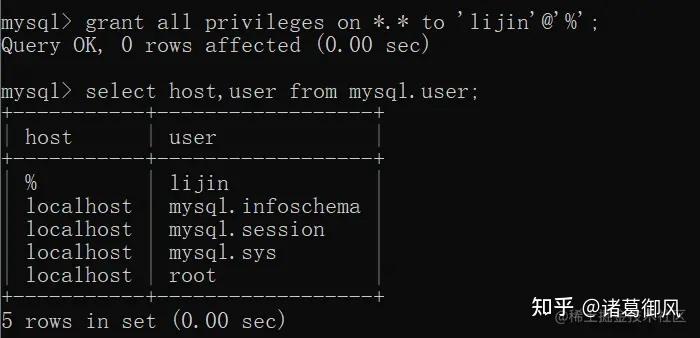
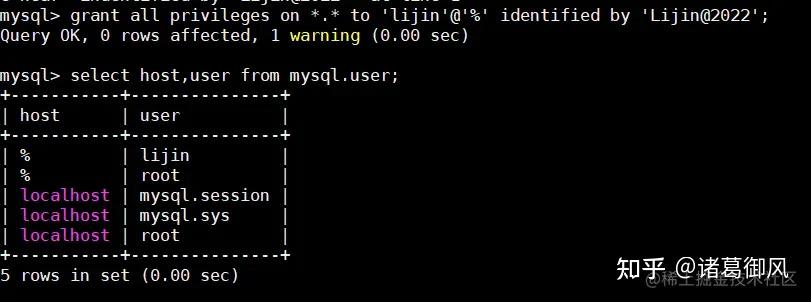
在MySQL数据库中,自增ID(Auto Increment)是一种常见的用于生成唯一标识符的方式。它可以让我们方便地为每条记录分配一个独立的、递增的整数值。1. 自增ID的使用自增ID通常用于作为表的主键(Primary Key),以确保数据表中每条记录都有一个唯一标识。利用自增ID,我们可以快速定位和修改特定记录,同时提高查询和索引效率。2. 实现逻辑在MySQL中,实现自增ID通常通过两种方式:使用AUTO_INCREMENT关键字或者使用序列(Sequence)。2.1 使用AUTO_INCREMENT当我们在创建表时定义一个整数类型字段,并设置其属性为AUTO_INCREMENT时,MySQL会自动为该字段生成一个唯一递增的值。例如,下面是创建一个名为users的表,并将字段id设置为自增ID:sql</p><p data-pid="AifBZLF3">CREATE TABLE users (</p><p data-pid="qcHJvoSb"> id INT AUTO_INCREMENT PRIMARY KEY,</p><p data-pid="GcgEBseD"> name VARCHAR(50) NOT NULL,</p><p data-pid="Q347Zc3C"> age INT</p><p data-pid="uxFdcdqd">);</p><p data-pid="S6dh8OE_">在执行插入操作时,如果不指定该字段的值,MySQL就会根据当前已存在记录中最大的自增ID来设置新纪录的ID值。这样就确保了每个新记录的ID都是唯一递增的。2.2 使用序列(Sequence)除了使用AUTO_INCREMENT关键字外,MySQL还提供了序列(Sequence)功能来实现自增ID。通过使用序列,我们可以创建一个独立的对象,该对象会生成一个连续的整数序列。我们可以在插入数据时调用该序列来获取下一个值,从而实现自增ID的效果。sql</p><p data-pid="c55umei4">-- 创建序列</p><p data-pid="U7k7bLPH">CREATE SEQUENCE seq_id START WITH 1 INCREMENT BY 1;</p><p data-pid="rSBkdrEJ">-- 插入记录并获取下一个ID值</p><p data-pid="Viw2tR2f">INSERT INTO users (id, name, age) VALUES (NEXT VALUE FOR seq_id, 'John', 25);</p><p data-pid="MvJuGwvY">3. 注意事项在使用自增ID时,需要注意以下几点:- 自增ID只能用于整数类型字段。- 自增ID不保证绝对连续递增,可能会因为删除或回滚等操作导致间断。- 自增ID是表级别的,在不同表中的自增ID可以重复。- 当达到整数类型的最大值时,自增ID会发生溢出并重新开始。总结:MySQL中实现自增ID有两种主要方式:使用AUTO_INCREMENT关键字和使用序列(Sequence)。无论采用哪种方式,都可以方便地为每条记录生成唯一递增的标识符。但需要注意,在使用过程中需考虑一些限制和注意事项。- mysql 会为每个表维护一个自增计数器,用来记录下一个自增 id 的值。这个计数器的初始值可以通过 AUTO_INCREMENT 选项来设置,如果没有设置,那么默认为 1。- 当插入一条新记录时,mysql 会检查是否有指定自增 id 的值,如果有,那么就使用指定的值,如果没有,那么就使用计数器的值,并将计数器 +1。- 如果指定的自增 id 的值大于计数器的值,那么 mysql 会更新计数器的值为指定值 +1。如果指定的自增 id 的值小于或等于计数器的值,那么 mysql 不会更新计数器的值。- 如果插入多条新记录时,mysql 会按照顺序分配自增 id 的值,从计数器的值开始,依次 +1。如果有指定自增 id 的值,那么同样会按照上面的规则处理。- 如果删除一条或多条记录时,mysql 不会影响自增计数器的值。也就是说,删除记录不会回收自增 id 的值。- 如果修改一条记录的自增 id 的值,那么 mysql 会按照上面的规则处理。如果修改多条记录的自增 id 的值,那么 mysql 会按照顺序处理,从最小的自增 id 开始。MySQL 8.0.28引入的新功能,即支持监控统计并限制各个连接(会话)的内存消耗,避免大量用户连接因为执行垃圾SQL消耗过多内存,造成可能被OOM kill的风险。一定程度上,避免了开发层面乱用SQL导致数据库问题的场景,很像Oracle的资源管理器。
讯享网mysql> show global status like ’Global_connection_memory‘; +————————–+———+ | Variable_name | Value | +————————–+———+ | Global_connection_memory | | +————————–+———+
讯享网select /*+ SET_VAR(sort_buffer_size = 16M) / id from test order id ; insert /+ SET_VAR(foreign_key_checks=OFF) */ into test(name) values(1);
MySQL 8.0版本支持在线修改全局参数并持久化,通过加上PERSIST关键字,可以将修改的参数持久化到新的配置文件(mysqld-auto.cnf)中,重启MySQL时,可以从该配置文件获取到最新的配置参数。例如执行:
set PERSIST expire_logs_days=10 ;
系统会在数据目录下生成一个包含json格式的 mysqld-auto.cnf 的文件,格式化后如下所示,当 my.cnf 和 mysqld-auto.cnf 同时存在时,后者具有更高优先级。select … for update,select … for share(8.0新增语法) 添加 NOWAIT、SKIP LOCKED语法,跳过锁等待,或者跳过锁定。在5.7及之前的版本,select…for update,如果获取不到锁,会一直等待,直到innodb_lock_wait_timeout超时。在8.0版本,通过添加nowait,skip locked语法,能够立即返回。如果查询的行已经加锁,那么nowait会立即报错返回,而skip locked也会立即返回,只是返回的结果中不包含被锁定的行。目的是为了兼容sql的标准语法,方便迁移mysql 5.7
讯享网mysql> select count(),age from t5 group by age; +———-+——+ | count() | age | +———-+——+ | 1 | 25 | | 1 | 29 | | 1 | 32 | | 1 | 33 | | 1 | 35 | +———-+——+ 5 rows in set (0.00 sec)
mysql 8.0
mysql> select count(),age from t5 group by age; +———-+——+ | count() | age | +———-+——+ | 1 | 25 | | 1 | 32 | | 1 | 35 | | 1 | 29 | | 1 | 33 | +———-+——+ 5 rows in set (0.00 sec)
可以看到,MySQL5.7 在group by中对分组字段进行了隐式排序,而MySQL8.0取消了隐式排序。如果要添加排序的话,需要显示增加,比如 select count(),age from t5 group by age order by age;在8.0之前的版本,自增值是保存在内存中,自增主键AUTO_INCREMENT的值如果大于max(primary key)+1,在MySQL重启后,会重置AUTO_INCREMENT=max(primary key)+1。这种现象在某些情况下会导致业务主键冲突或者其他难以发现的问题。自增主键重启重置的问题很早就被发现(https://bugs.mysql.com/bug.php?id=199),一直到8.0才被解决。8.0版本将会对AUTO_INCREMENT值进行持久化,MySQL重启后,该值将不会改变。8.0开始,当前最大的自增计数器每当发生变化,值会被写入redo log中,并在每个检查点时候保存到private system table中。这一变化,对AUTO_INCREMENT值进行持久化,MySQL重启后,该值将不会改变。
MySQL server重启后不再取消AUTO_INCREMENT = N表选项的效果。如果将自增计数器初始化为特定值,或者将自动递增计数器值更改为更大的值,新的值被持久化,即使服务器重启。
只需将innodb_dedicated_server = ON 设置好,上面四个参数会自动调整,解决非专业人员安装数据库后默认初始化数据库参数默认值偏低的问题,让MySQL自适应的调整上面四个参数,前提是服务器是专用来给MySQL数据库的,如果还有其他软件或者资源或者多实例MySQL使用,不建议开启该参数,本文以MySQL8.0.19为例。那么按照什么规则调整呢?MySQL官方给出了相关参数调整规则如下:(1). innodb_buffer_pool_size自动调整规则:
说明:如果ROUND(buffer pool size)值小于2GB,那么innodb_log_files_in_group会强制设置为2。(4). innodb_flush_method自动调整规则:该参数调整规则直接引用官方文档的解释:The flush method is set to O_DIRECT_NO_FSYNC when innodb_dedicated_server is enabled. If the O_DIRECT_NO_FSYNC setting is not available, the default innodb_flush_method setting is used. 如果系统允许设置为O_DIRECT_NO_FSYNC;如果系统不允许,则设置为InnoDB默认的Flush method。
从 MySQL 8.0 开始,新增了一个叫窗口函数的概念。什么叫窗口?它可以理解为记录集合,窗口函数也就是在满足某种条件的记录集合上执行的特殊函数。对于每条记录都要在此窗口内执行函数,有的函数随着记录不同,窗口大小都是固定的,这种属于静态窗口;有的函数则相反,不同的记录对应着不同的窗口,这种动态变化的窗口叫滑动窗口。它可以用来实现若干新的查询方式。窗口函数与 SUM()、COUNT() 这种聚合函数类似,但它不会将多行查询结果合并为一行,而是将结果放回多行当中。即窗口函数不需要 GROUP BY。窗口函数内容太多,后期我会专门写一篇文章介绍窗口函数当遇到索引树损坏时,InnoDB会在redo日志中写入一个损坏标志,这会使损坏标志安全崩溃。InnoDB还将内存损坏标志数据写入每个检查点的私有系统表中。在恢复的过程中,InnoDB会从这两个位置读取损坏标志,并合并结果,然后将内存中的表和索引对象标记为损坏。InnoDB memcached插件支持批量get操作(在一个memcached查询中获取多个键值对)和范围查询。减少客户端和服务器之间的通信流量,在单个memcached查询中获取多个键、值对的功能可以提高读取性能。从 MySQL 8.0.12 开始(仅仅指InnoDB引擎),以下 ALTER TABLE 操作支持 ALGORITHM=INSTANT:
优化器能够感知到页是否存在缓冲池中。5.7其实已经开放接口,但是不对内存中的页进行统计,返回都是1.0。8.0版本对于读写皆有和高写负载的拿捏恰到好处。在集中的读写均有的负载情况下,我们观测到在4个用户并发的情况下,对于高负载,和5.7版本相比有着两倍性能的提高。在5.7上我们显著了提高了只读情况下的性能,8.0则显著提高了读写负载的可扩展性。为MySQL提升了硬件性能的利用率,其改进是基于重新设计了InnoDB写入Redo日志的方法。对比之前用户线程之前互相争抢着写入其数据变更,在新的Redo日志解决方案中,现在Redo日志由于其写入和刷缓存的操作都有专用的线程来处理。用户线程之间不在持有Redo写入相关的锁,整个Redo处理过程都是时间驱动。8.0版本允许马力全开的使用存储设备,比如使用英特尔奥腾闪存盘的时候,我们可以在IO敏感的负载情况下获得1百万的采样 QPS(这里说的IO敏感是指不在IBP中,且必须从二级存储设备中获取)。这个改观是由于我们摆脱了 file_system_mutex全局锁的争用。Better Performance upon High Contention Loads (“hot rows”)8.0版本显著地提升了高争用负载下的性能。高争用负载通常发生在许多事务争用同一行数据的锁,导致了事务等待队列的产生。在实际情景中,负载并不是平稳的,负载可能在特定的时间内爆发(80/20法则)。8.0版本针对短时间的爆发负载无论在每秒处理的事务数(换句话,延迟)还是95%延迟上都处理的更好。对于终端用户来说体现在更好的硬件资源利用率(效率)上。因为系统需要尽量使用榨尽硬件性能,才可以提供更高的平均负载。通过加上PERSIST关键字,可以将修改的参数持久化到新的配置文件(mysqld-auto.cnf)中,重启MySQL时,可以从该配置文件获取到最新的配置参数。系统会在数据目录下生成mysqld-auto.cnf 文件,该文件内容是以json格式存储的。当my.cnf 和mysqld-auto.cnf 同时存在时,后者优先级更高。例如:
讯享网SET PERSIST max_connections = 1000; SET @@PERSIST.max_connections = 1000;
此 SET 语法使您能够在运行时进行配置更改,这些更改也会在服务器重新启动后持续存在。与 SET GLOBAL 一样,SET PERSIST 设置全局变量运行时值,但也将变量设置写入 mysqld-auto.cnf 文件(如果存在则替换任何现有变量设置)。之前是天,并且参数名称发生变化. 在8.0版本之前,binlog日志过期时间设置都是设置expire_logs_days参数,而在8.0版本中,MySQL默认使用binlog_expire_logs_seconds参数。innodb_undo_log_truncate参数在8.0.2版本默认值由OFF变为ON,默认开启undo日志表空间自动回收。innodb_undo_tablespaces参数在8.0.2版本默认为2,当一个undo表空间被回收时,还有另外一个提供正常服务。innodb_max_undo_log_size参数定义了undo表空间回收的最大值,当undo表空间超过这个值,该表空间被标记为可回收。8.0 版本提供对地形的支持,其中包括了对空间参照系的数据源信息的支持,SRS aware spatial数据类型,空间索引,空间函数。总而言之,8.0版本可以理解地球表面的经纬度信息,而且可以在任意受支持的5000个空间参照系中计算地球上任意两点之间的距离。
注意:升级前,一定要验证jdbc驱动是否匹配,是否需要随着升级。
讯享网select @@optimizer_switch \Gmysql> select @@optimizer_switch \G * 1. row * @@optimizer_switch: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on,use_invisible_indexes=off,skip_scan=on,hash_join=on,subquery_to_derived=off,prefer_ordering_index=on,hypergraph_optimizer=off,derived_condition_pushdown=onsession 开关 set session optimizer_switch=”use_invisible_indexes=off“; set session optimizer_switch=”use_invisible_indexes=on“;global 开关 set global optimizer_switch=”use_invisible_indexes=off“; set global optimizer_switch=”use_invisible_indexes=on“;
让我们来听听 MySQL 官方团队的社区经理对 MySQL 8.4 有哪些详细的版本描述:MySQL 8.4 LTS 版本,我们一共修改了 20 个 InnoDB 变量的默认值。
作者:Frederic Descamps,EMEA 和亚太地区的 MySQL 社区经理。于 2016 年 5 月加入 MySQL 社区团队。担任开源和 MySQL 顾问已超过 15 年。最喜欢的主题是高可用和高性能。
本文和封面来源:https://lefred.be,爱可生开源社区翻译。
本文约 2400 字,预计阅读需要 8 分钟。
讯享网EXPLAIN format = TRADITIONAL json SELECT tt.TicketNumber, tt.TimeIn,
tt.ProjectReference, tt.EstimatedShipDate, tt.ActualShipDate, tt.ClientID, tt.ServiceCodes, tt.RepetitiveID, tt.CurrentProcess, tt.CurrentDPPerson, tt.RecordVolume, tt.DPPrinted, et.COUNTRY, et_1.COUNTRY, do.CUSTNAME FROM tt, et, et AS et_1, do WHERE tt.SubmitTime IS NULL AND tt.ActualPC = et.EMPLOYID AND tt.AssignedPC = et_1.EMPLOYID AND tt.ClientID = do.CUSTNMBR;
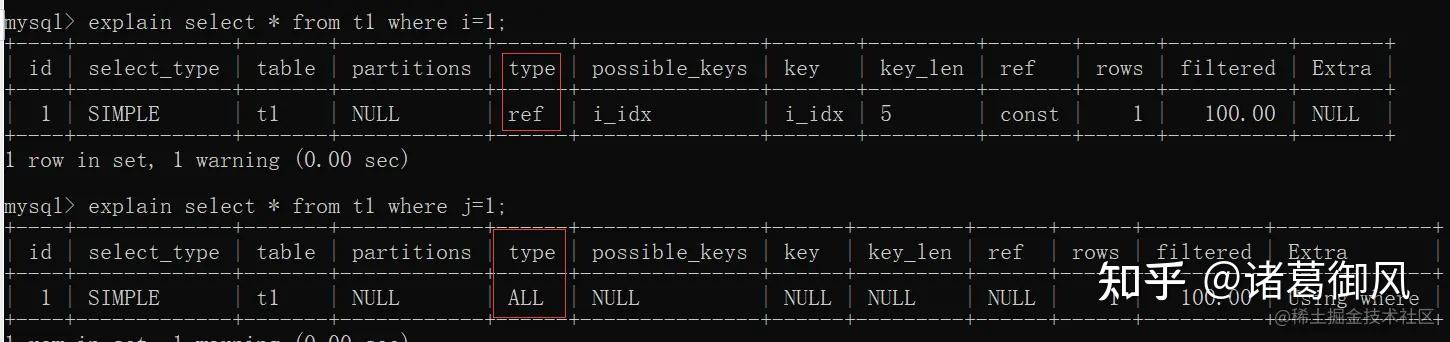
eq_ref:当使用了索引的全部组成部分,并且索引是PRIMARY KEY或UNIQUE NOT NULL 才会使用该类型,性能仅次于system及const。
讯享网– 多表关联查询,单行匹配 SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column;– 多表关联查询,联合索引,多行匹配 SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;
– 根据索引(非主键,非唯一索引),匹配到多行 SELECT * FROM ref_table WHERE key_column=expr;– 多表关联查询,单个索引,多行匹配 SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column;– 多表关联查询,联合索引,多行匹配 SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;
No matching min/max row 没有任何能满足例如 SELECT MIN(…) FROM … WHERE condition 中的condition的行
no matching row in const table 对于关联查询,存在一个空表,或者没有行能够满足唯一索引条件
No matching rows after partition pruning 对于DELETE或UPDATE语句,优化器在partition pruning(分区修剪)之后,找不到要delete或update的内容
No tables used 当此查询没有FROM子句或拥有FROM DUAL子句时出现。例如:explain select 1
Not exists MySQL能对LEFT JOIN优化,在找到符合LEFT JOIN的行后,不会为上一行组合中检查此表中的更多行。例如:
讯享网SELECT * FROM t1 LEFT JOIN t2 ON t1.id=t2.id WHERE t2.id IS NULL;
假设t2.id定义成了NOT NULL ,此时,MySQL会扫描t1,并使用t1.id的值查找t2中的行。 如果MySQL在t2中找到一个匹配的行,它会知道t2.id永远不会为NULL,并且不会扫描t2中具有相同id值的其余行。也就是说,对于t1中的每一行,MySQL只需要在t2中只执行一次查找,而不考虑在t2中实际匹配的行数。 在MySQL 8.0.17及更高版本中,如果出现此提示,还可表示形如 NOT IN (subquery) 或 NOT EXISTS (subquery) 的WHERE条件已经在内部转换为反连接。这将删除子查询并将其表放入最顶层的查询计划中,从而改进查询的开销。通过合并半连接和反联接,优化器可以更加自由地对执行计划中的表重新排序,在某些情况下,可让查询提速。你可以通过在EXPLAIN语句后紧跟一个SHOW WARNING语句,并分析结果中的Message列,从而查看何时对该查询执行了反联接转换。
Plan isn’t ready yet 使用了EXPLAIN FOR CONNECTION,当优化器尚未完成为在指定连接中为执行的语句创建执行计划时, 就会出现此值。
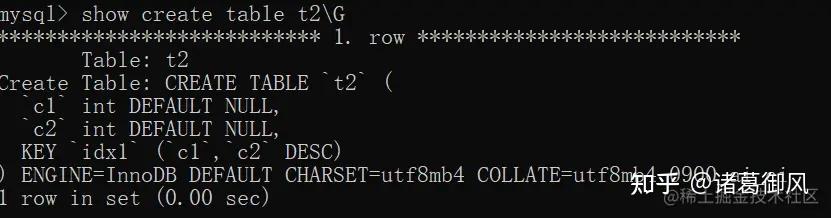
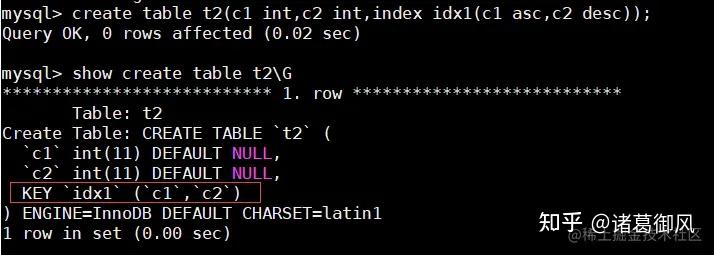
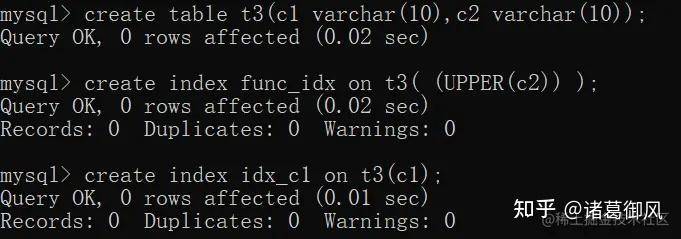
Range checked for each record (index map: N) MySQL没有找到合适的索引去使用,但是去检查是否可以使用range或index_merge来检索行时,会出现此提示。index map N索引的编号从1开始,按照与表的SHOW INDEX所示相同的顺序。 索引映射值N是指示哪些索引是候选的位掩码值。 例如0x19(二进制11001)的值意味着将考虑索引1、4和5。 示例:下面例子中,name是varchar类型,但是条件给出整数型,涉及到隐式转换。 图中t2也没有用到索引,是因为查询之前我将t2中name字段排序规则改为utf8_bin导致的链接字段排序规则不匹配。
explain select a.* from t1 a left join t2 b on t1.name = t2.name where t2.name = 2;
Start temporary, End temporary 表示临时表使用Duplicate Weedout策略,详见 https://mariadb.com/kb/en/duplicateweedout-strategy/ ,翻译 https://www.cnblogs.com/abclife/p/10895531.html
unique row not found 对于形如 SELECT … FROM tbl_name 的查询,但没有行能够满足唯一索引或主键查询的条件
Using filesort 当Query 中包含 ORDER BY 操作,而且无法利用索引完成排序操作的时候,MySQL Query Optimizer 不得不选择相应的排序算法来实现。数据较少时从内存排序,否则从磁盘排序。Explain不会显示的告诉客户端用哪种排序。官方解释:“MySQL需要额外的一次传递,以找出如何按排序顺序检索行。通过根据联接类型浏览所有行并为所有匹配WHERE子句的行保存排序关键字和行的指针来完成排序。然后关键字被排序,并按排序顺序检索行”
Using index 仅使用索引树中的信息从表中检索列信息,而不必进行其他查找以读取实际行。当查询仅使用属于单个索引的列时,可以使用此策略。例如:
讯享网explain SELECT id FROM t
Using index condition表示先按条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行。通过这种方式,除非有必要,否则索引信息将可以延迟“下推”读取整个行的数据。详见 “Index Condition Pushdown Optimization” 。例如:Using index for group-by数据访问和 Using index 一样,所需数据只须要读取索引,当Query 中使用GROUP BY或DISTINCT 子句时,如果分组字段也在索引中,Extra中的信息就会是 Using index for group-by。详见 “GROUP BY Optimization”
– name字段有索引 explain SELECT name FROM t1 group by name
Using index for skip scan 表示使用了Skip Scan。详见 Skip Scan Range Access Method
Using join buffer (Block Nested Loop), Using join buffer (Batched Key Access) 使用Block Nested Loop或Batched Key Access算法提高join的性能。详见 https://www.cnblogs.com/chenpingzhao/p/6720531.html
Using MRR 使用了Multi-Range Read优化策略。详见 “Multi-Range Read Optimization”
Using sort_union(…), Using union(…), Using intersect(…) 这些指示索引扫描如何合并为index_merge连接类型。详见 “Index Merge Optimization” 。
Using temporary 为了解决该查询,MySQL需要创建一个临时表来保存结果。如果查询包含不同列的GROUP BY和 ORDER BY子句,通常会发生这种情况。
讯享网– name无索引 explain SELECT name FROM t1 group by name
Using where如果我们不是读取表的所有数据,或者不是仅仅通过索引就可以获取所有需要的数据,则会出现using where信息
explain SELECT * FROM t1 where id > 5
Using where with pushed condition 仅用于NDB
Zero limit 该查询有一个limit 0子句,不能选择任何行
讯享网explain SELECT name FROM resource_template limit 0
讯享网 SELECT t1.a, t1.a IN (SELECT t2.a FROM t2) FROM t1\G
* 1. row *
id: 1
select_type: PRIMARY
讯享网 table: t1 type: index
possible_keys: NULL
key: PRIMARY key_len: 4 ref: NULL rows: 4 filtered: 100.00 Extra: Using index
* 2. row *
讯享网 id: 2
select_type: SUBQUERY
table: t2 type: index
possible_keys: a
讯享网 key: a key_len: 5 ref: NULL rows: 3 filtered: 100.00 Extra: Using index
2 rows in set, 1 warning (0.00 sec)mysql> SHOW WARNINGS\G * 1. row * Level: Note Code: 1003 Message: /* select#1 */ select test.t1.a AS a,
<in_optimizer>(`test`.`t1`.`a`,`test`.`t1`.`a` in ( <materialize> (/* select#2 */ select `test`.`t2`.`a` from `test`.`t2` where 1 having 1 ), <primary_index_lookup>(`test`.`t1`.`a` in <temporary table> on <auto_key> where ((`test`.`t1`.`a` = `materialized-subquery`.`a`))))) AS `t1.a IN (SELECT t2.a FROM t2)` from `test`.`t1`
outer_tables semi join (inner_tables) 半连接操作。inner_tables展示未拉出的表。详见 “Optimizing Subqueries, Derived Tables, and View References with Semijoin Transformations”
<temporary table> 表示创建了内部临时表而缓存中间结果
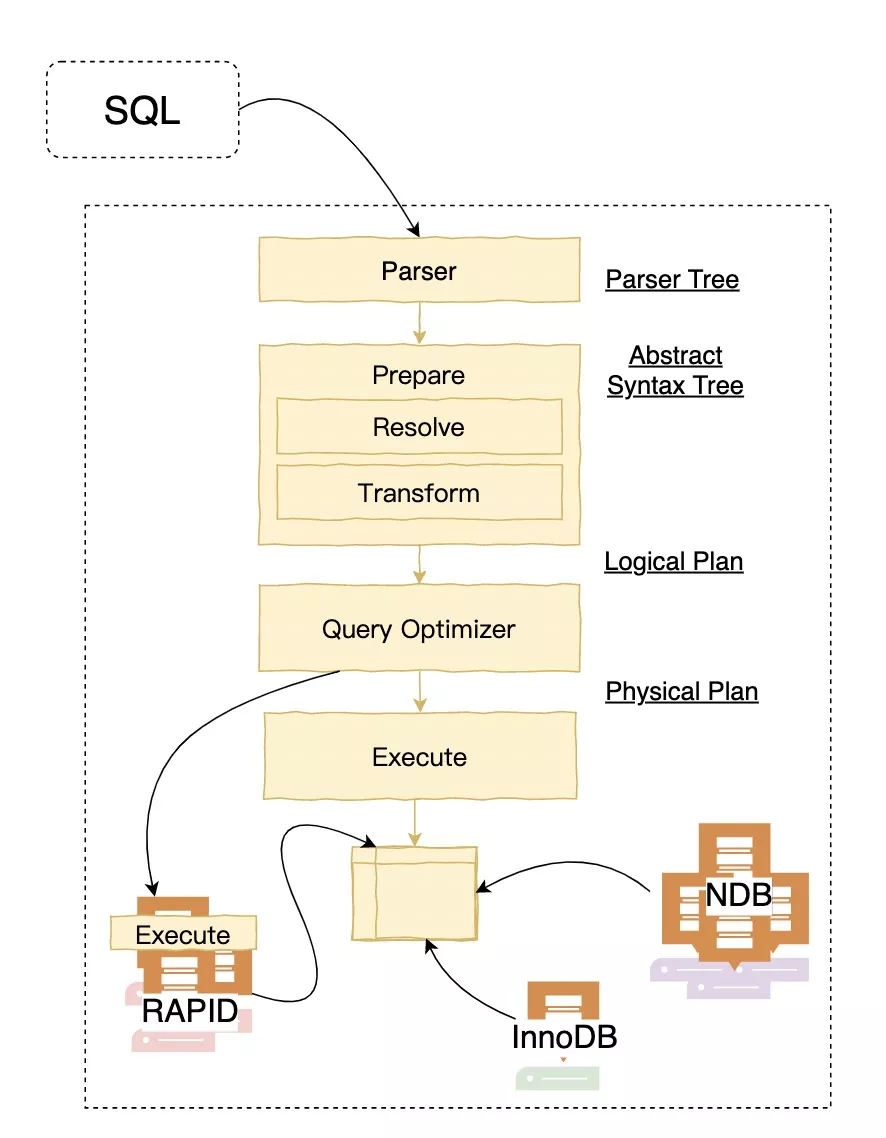
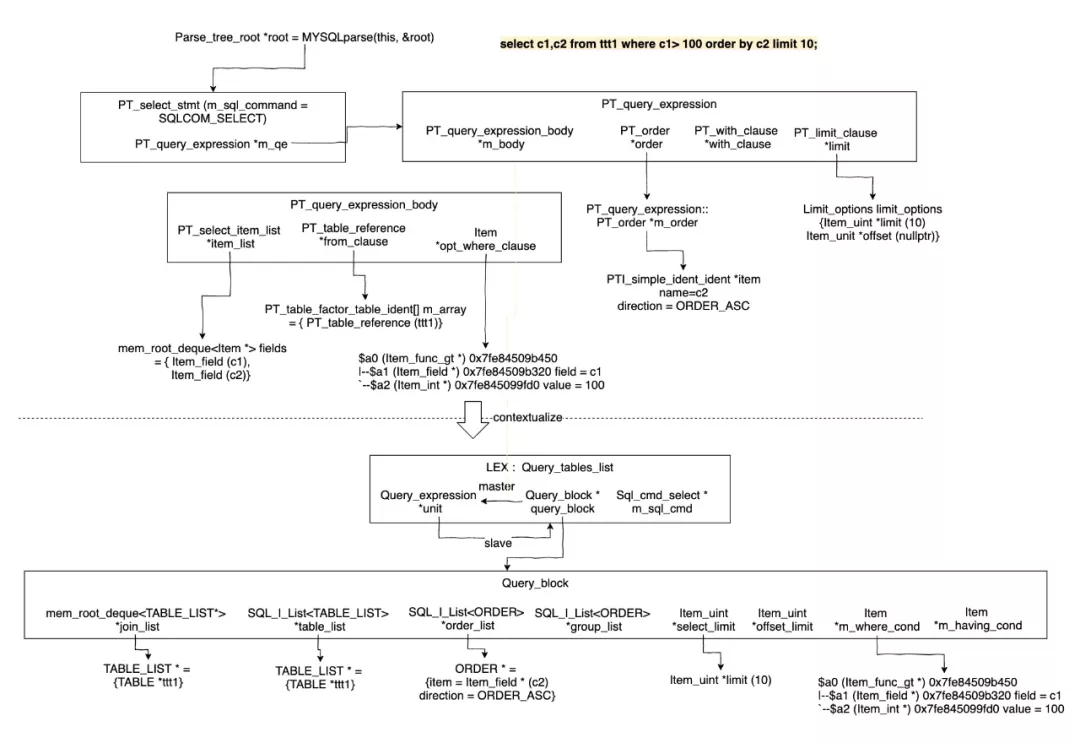
当某些表是const或system类型时,这些表中的列所涉及的表达式将由优化器尽早评估,并且不属于所显示语句的一部分。但是,当使用FORMAT=JSON时,某些const表的访问将显示为ref。估计查询性能多数情况下,你可以通过计算磁盘的搜索次数来估算查询性能。对于比较小的表,通常可以在一次磁盘搜索中找到行(因为索引可能已经被缓存了),而对于更大的表,你可以使用B-tree索引进行估算:你需要进行多少次查找才能找到行:log(row_count) / log(index_block_length / 3 * 2 / (index_length + data_pointer_length)) + 1在MySQL中,index_block_length通常是1024字节,数据指针一般是4字节。比方说,有一个500,000的表,key是3字节,那么根据计算公式log(500,000)/log(1024⁄3*2/(3+4)) + 1 = 4 次搜索。该索引将需要500,000 * 7 * 3⁄2 = 5.2MB的存储空间(假设典型的索引缓存的填充率是2/3),因此你可以在内存中存放更多索引,可能只要一到两个调用就可以找到想要的行了。但是,对于写操作,你需要四个搜索请求来查找在何处放置新的索引值,然后通常需要2次搜索来更新索引并写入行。前面的讨论并不意味着你的应用性能会因为log N而缓慢下降。只要内容被OS或MySQL服务器缓存,随着表的变大,只会稍微变慢。在数据量变得太大而无法缓存后,将会变慢很多,直到你的应用程序受到磁盘搜索约束(按照log N增长)。为了避免这种情况,可以根据数据的增长而增加key的。对于MyISAM表,key的缓存大小由名为key_buffer_size的系统变量控制,详见 Section 5.1.1, “Configuring the Server” 作者:大目链接:https://www.imooc.com/article/308225来源:慕课网本文原创发布于慕课网 ,转载请注明出处,谢谢合作本文基于MySQL 8.0.25源码进行分析和总结。这里MySQL Server层指的是MySQL的优化器、执行器部分。我们对MySQL的理解还建立在5.6和5.7版本的理解之上,更多的是对比PostgreSQL或者传统数据库。然而从MySQL 8.0开始,持续每三个月的迭代和重构工作,使得MySQL Server层的整体架构有了质的飞越。下面来看下MySQL最新的架构。我们可以看到最新的MySQL的分层架构和其他数据库并没有太大的区别,另外值得一提的是从图中可以看出MySQL现在更多的加强InnoDB、NDB集群和RAPID(HeatWave clusters)内存集群架构的演进。下面我们就看下具体细节,我们这次不随着官方的Feature实现和重构顺序进行理解,本文更偏向于从优化器、执行器的流程角度来演进。首先从Parser开始,官方MySQL 8.0使用Bison进行了重写,生成Parser Tree,同时Parser Tree会contextualize生成MySQL抽象语法树(Abstract Syntax Tree).MySQL抽象语法树和其他数据库有些不同,是由比较让人拗口的SELECT_LEX_UNIT/SELECT_LEX类交替构成的,然而这两个结构在最新的版本中已经重命名成标准的SELECT_LEX -> Query_block和SELECT_LEX_UNIT -> Query_expression。Query_block是代表查询块,而Query_expression是包含多个查询块的查询表达式,包括UNION AND/OR的查询块(如SELECT FROM t1 union SELECT FROM t2)或者有多Level的ORDER BY/LIMIT (如SELECT * FROM t1 ORDER BY a LIMIT 10) ORDER BY b LIMIT 5。例如,来看一个复杂的嵌套查询:
讯享网(SELECT * FROM ttt1) UNION ALL (SELECT * FROM
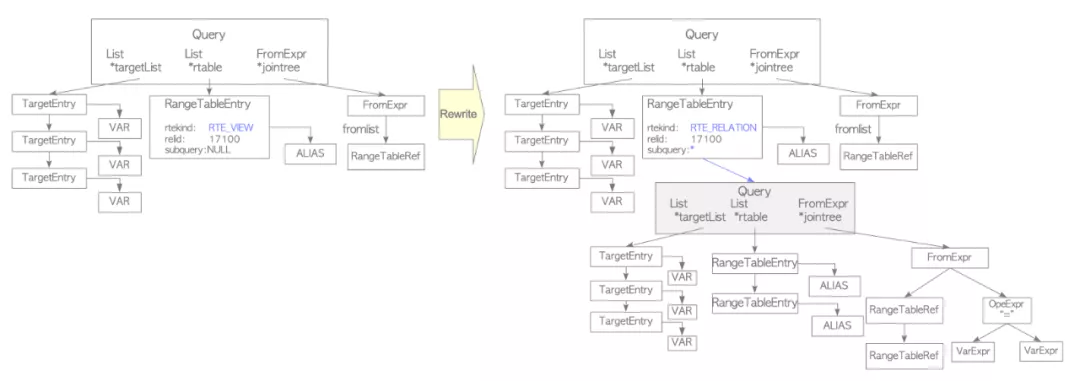
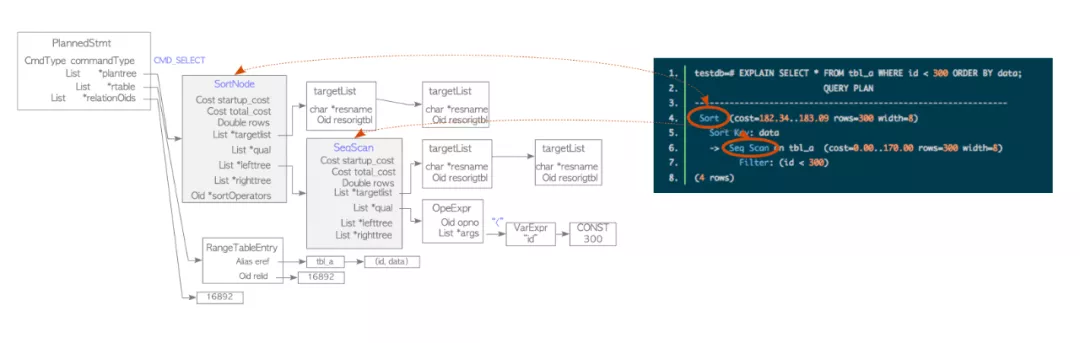
(SELECT * FROM ttt2) AS a, (SELECT * FROM ttt3 UNION ALL SELECT * FROM ttt4) AS b)</code></pre></div><p data-pid="pta-urI9">在MySQL中就可以用下面方式表达:</p><figure data-size="normal"><img src="https://pic1.zhimg.com/v2-521dc14ffaebc37a09828_r.jpg" data-caption="" data-size="normal" data-rawwidth="1080" data-rawheight="462" class="origin_image zh-lightbox-thumb" width="1080" data-original="https://pic1.zhimg.com/v2-521dc14ffaebc37a09828_r.jpg"/></figure><p data-pid="KanLmzN2">经过解析和转换后的语法树仍然建立在Query_block和Query_expression的框架下,只不过有些LEVEL的query block被消除或者合并了,这里不再详细展开。</p><p data-pid="BdUKOX-A">接下来我们要经过resolve和transformation过程Query_expression::prepare->Query_block::prepare,这个过程包括(按功能分而非完全按照执行顺序):</p><ul><li data-pid="qa_gSnLQ">setup_tables:Set up table leaves in the query block based on list of tables.</li><li data-pid="oQCn6hiJ">resolve_placeholder_tables/merge_derived/setup_table_function/setup_materialized_derived:Resolve derived table, view or table function references in query block.</li><li data-pid="C-GZhaBX">setup_natural_join_row_types:Compute and store the row types of the top-most NATURAL/USING joins.</li><li data-pid="NDwkFpDi">setup_wild:Expand all '*' in list of expressions with the matching column references.</li><li data-pid="znS1LQuF">setup_base_ref_items:Set query_block's base_ref_items.</li><li data-pid="h2TcQDKC">setup_fields:Check that all given fields exists and fill struct with current data.</li><li data-pid="FbbNI5oF">setup_conds:Resolve WHERE condition and join conditions.</li><li data-pid="vm1l4ii8">setup_group:Resolve and set up the GROUP BY list.</li><li data-pid="WbdHipWu">m_having_cond->fix_fields:Setup the HAVING clause.</li><li data-pid="33PJLKiW">resolve_rollup:Resolve items in SELECT list and ORDER BY list for rollup processing.</li><li data-pid="X-foDyZw">resolve_rollup_item:Resolve an item (and its tree) for rollup processing by replacing items matching grouped expressions with Item_rollup_group_items and updating properties (m_nullable, PROP_ROLLUP_FIELD). Also check any GROUPING function for incorrect column.</li><li data-pid="qKQiK_VB">setup_order:Set up the ORDER BY clause.</li><li data-pid="0caj_hxe">resolve_limits:Resolve OFFSET and LIMIT clauses.</li><li data-pid="OPdwq6NF">Window::setup_windows1:Set up windows after setup_order() and before setup_order_final().</li><li data-pid="kfwJLXAX">setup_order_final:Do final setup of ORDER BY clause, after the query block is fully resolved.</li><li data-pid="cJGTjoCz">setup_ftfuncs:Setup full-text functions after resolving HAVING.</li><li data-pid="oDU7MsEn">resolve_rollup_wfs : Replace group by field references inside window functions with references in the presence of ROLLUP.</li></ul><ul><li data-pid="UKlCbFPk">remove_redundant_subquery_clause : Permanently remove redundant parts from the query if 1) This is a subquery 2) Not normalizing a view. Removal should take place when a query involving a view is optimized, not when the view is created.</li><li data-pid="xsyq_9jG">remove_base_options:Remove SELECT_DISTINCT options from a query block if can skip distinct.</li><li data-pid="_XIAHcC1">resolve_subquery : Resolve predicate involving subquery, perform early unconditional subquery transformations.<br/></li><ul><li data-pid="uZdaOpEu">Convert subquery predicate into semi-join, or</li><li data-pid="TgYQnUqs">Mark the subquery for execution using materialization, or</li><li data-pid="nk8COEGe">Perform IN->EXISTS transformation, or</li><li data-pid="UAyrbCkc">Perform more/less ALL/ANY -> MIN/MAX rewrite</li><li data-pid="s6QpV0NL">Substitute trivial scalar-context subquery with its value</li></ul></ul><p class="ztext-empty-paragraph"><br/></p><ul><li data-pid="X71T5ZAu">transform_scalar_subqueries_to_join_with_derived:Transform eligible scalar subqueries to derived tables.</li><li data-pid="gR3sJpEF">flatten_subqueries:Convert semi-join subquery predicates into semi-join join nests. Convert candidate subquery predicates into semi-join join nests. This transformation is performed once in query lifetime and is irreversible.</li><li data-pid="PiR1vglg">apply_local_transforms :<br/></li><ul><li data-pid="2OiI4e2W">delete_unused_merged_columns : If query block contains one or more merged derived tables/views, walk through lists of columns in select lists and remove unused columns.</li><li data-pid="FBOXIl44">simplify_joins:Convert all outer joins to inner joins if possible</li><li data-pid="L5-vMWdD">prune_partitions:Perform partition pruning for a given table and condition.</li></ul></ul><p class="ztext-empty-paragraph"><br/></p><ul><li data-pid="px4TR2oY">push_conditions_to_derived_tables:Pushing conditions down to derived tables must be done after validity checks of grouped queries done by apply_local_transforms();</li><li data-pid="4kWXXB22">Window::eliminate_unused_objects:Eliminate unused window definitions, redundant sorts etc.</li></ul><p data-pid="oT7i68W4">这里,节省篇幅,我们只举例关注下和top_join_list相关的simple_joins这个函数的作用,对于Query_block中嵌套join的简化过程。</p><figure data-size="normal"><img src="https://pica.zhimg.com/v2-fdad5b5dcc03afaee6ed3310fc_r.jpg" data-caption="" data-size="normal" data-rawwidth="1080" data-rawheight="967" class="origin_image zh-lightbox-thumb" width="1080" data-original="https://pica.zhimg.com/v2-fdad5b5dcc03afaee6ed3310fc_r.jpg"/></figure><p data-pid="HGU-YStI">3 对比PostgreSQL</p><p data-pid="p7-lP03g">为了更清晰的理解标准数据库的做法,我们这里引用了PostgreSQL的这三个过程:</p><p data-pid="it_wa6dw"><b>Parser</b></p><p data-pid="dHVOqz_M">下图首先Parser把SQL语句生成parse tree。</p><div class="highlight"><pre><code class="language-text">testdb=# SELECT id, data FROM tbl_a WHERE id < 300 ORDER BY data;</code></pre></div><figure data-size="normal"><img src="https://pic3.zhimg.com/v2-dee50132d429ff9f6920e7fff4_r.jpg" data-caption="" data-size="normal" data-rawwidth="1080" data-rawheight="477" class="origin_image zh-lightbox-thumb" width="1080" data-original="https://pic3.zhimg.com/v2-dee50132d429ff9f6920e7fff4_r.jpg"/></figure><p data-pid="l1v8607X"><b>Analyzer/Analyser</b></p><p data-pid="FwFvs15g">下图展示了PostgreSQL的analyzer/analyser如何将parse tree通过语义分析后生成query tree。</p><figure data-size="normal"><img src="https://pic1.zhimg.com/v2-c87aabb0d4974d1d5b4a6801f58e2f32_r.jpg" data-caption="" data-size="normal" data-rawwidth="1080" data-rawheight="475" class="origin_image zh-lightbox-thumb" width="1080" data-original="https://pic1.zhimg.com/v2-c87aabb0d4974d1d5b4a6801f58e2f32_r.jpg"/></figure><p class="ztext-empty-paragraph"><br/></p><p data-pid="Jv9ZH_7h"><b>Rewriter</b></p><p data-pid="98MoN1kV">Rewriter会根据规则系统中的规则把query tree进行转换改写。</p><div class="highlight"><pre><code class="language-text">sampledb=# CREATE VIEW employees_list
sampledb-# AS SELECT e.id, e.name, d.name AS department sampledb-# FROM employees AS e, departments AS d WHERE e.department_id = d.id;
下图的例子就是一个包含view的query tree如何展开成新的query tree。
讯享网sampledb=# SELECT * FROM employees_list;
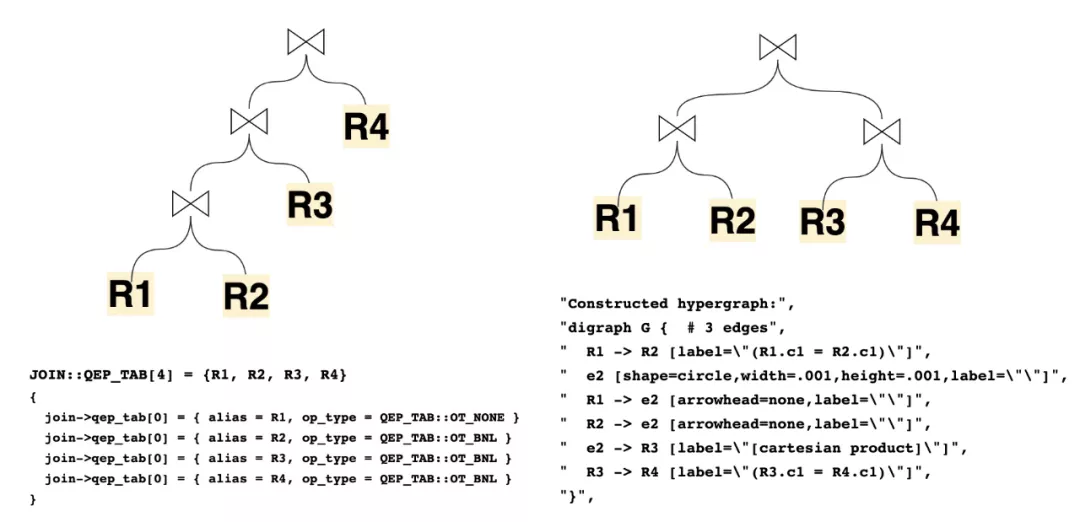
接下来我们进入了逻辑计划生成物理计划的过程,本文还是注重于结构的解析,而不去介绍生成的细节,MySQL过去在8.0.22之前,主要依赖的结构就是JOIN和QEP_TAB。JOIN是与之对应的每个Query_block,而QEP_TAB对应的每个Query_block涉及到的具体“表”的顺序、方法和执行计划。然而在8.0.22之后,新的基于Hypergraph的优化器算法成功的抛弃了QEP_TAB结构来表达左深树的执行计划,而直接使用HyperNode/HyperEdge的图来表示执行计划。举例可以看到数据结构表达的left deep tree和超图结构表达的bushy tree对应的不同计划展现:
| -> Inner hash join (no condition) (cost=1.40 rows=1)
讯享网-> Table scan on R4 (cost=0.35 rows=1) -> Hash -> Inner hash join (no condition) (cost=1.05 rows=1) -> Table scan on R3 (cost=0.35 rows=1) -> Hash -> Inner hash join (no condition) (cost=0.70 rows=1) -> Table scan on R2 (cost=0.35 rows=1) -> Hash -> Table scan on R1 (cost=0.35 rows=1)
-> Nested loop inner join (cost=0.50..0.50 rows=0) -> Table scan on R4 (cost=0.25..0.25 rows=1) -> Filter: (R4.c1 = R3.c1) (cost=0.35..0.35 rows=0) -> Table scan on R3 (cost=0.25..0.25 rows=1) -> Nested loop inner join (cost=0.50..0.50 rows=0) -> Table scan on R2 (cost=0.25..0.25 rows=1) -> Filter: (R2.c1 = R1.c1) (cost=0.35..0.35 rows=0) -> Table scan on R1 (cost=0.25..0.25 rows=1)</code></pre></div><p data-pid="bTiEAO_P">MySQL8.0.2x为了更好的兼容两种优化器,引入了新的类AccessPath,可以认为这是MySQL为了解耦执行器和不同优化器抽象出来的Plan Tree。</p><figure data-size="normal"><img src="https://pic3.zhimg.com/v2-b7741a4fec6458f9e0fd17eb0c0a5bae_r.jpg" data-caption="" data-size="normal" data-rawwidth="1016" data-rawheight="1048" class="origin_image zh-lightbox-thumb" width="1016" data-original="https://pic3.zhimg.com/v2-b7741a4fec6458f9e0fd17eb0c0a5bae_r.jpg"/></figure><p data-pid="xRSBLnqJ">老优化器仍然走JOIN::optimize来把query block转换成query execution plan (QEP)。</p><p data-pid="cn2dBcko">这个阶段仍然做一些逻辑的重写工作,这个阶段的转换可以理解为基于cost-based优化前做准备,详细步骤如下:</p><ul><li data-pid="o-AhiMPg">Logical transformations<br/></li><ul><li data-pid="p4m9AW4_">optimize_derived : Optimize the query expression representing a derived table/view.</li><li data-pid="uiw2U0fg">optimize_cond : Equality/constant propagation.</li><li data-pid="Ml915y99">prune_table_partitions : Partition pruning.</li><li data-pid="43zfyRyQ">optimize_aggregated_query : COUNT(*), MIN(), MAX() constant substitution in case of implicit grouping.</li><li data-pid="YVke3v22">substitute_gc : ORDER BY optimization, substitute all expressions in the WHERE condition and ORDER/GROUP lists that match generated columns (GC) expressions with GC fields, if any.</li></ul><li data-pid="HCVkGcAQ">Perform cost-based optimization of table order and access path selection.<br/></li><ul><li data-pid="yJFkZ0mL">JOIN::make_join_plan() : Set up join order and initial access paths.</li></ul><li data-pid="xaZjo0Oy">Post-join order optimization<br/></li><ul><li data-pid="6zc0KjU3">substitute_for_best_equal_field : Create optimal table conditions from the where clause and the join conditions.</li><li data-pid="89SqDTUT">make_join_query_block : Inject outer-join guarding conditions.</li><li data-pid="c_kE90TN">Adjust data access methods after determining table condition (several times).</li><li data-pid="-eata4dR">optimize_distinct_group_order : Optimize ORDER BY/DISTINCT.</li><li data-pid="JcGOfih1">optimize_fts_query : Perform FULLTEXT search before all regular searches.</li><li data-pid="aTzf0GaY">remove_eq_conds : Removes const and eq items. Returns the new item, or nullptr if no condition.</li><li data-pid="RZXVzQlk">replace_index_subquery/create_access_paths_for_index_subquery : See if this subquery can be evaluated with subselect_indexsubquery_engine.</li><li data-pid="nl9ckr59">setup_join_buffering : Check whether join cache could be used.</li></ul><li data-pid="SPMDV0qn">Code generation<br/></li><ul><li data-pid="Ijo_FBqo">alloc_qep(tables) : Create QEP_TAB array.</li><li data-pid="OHk5yHks">test_skip_sort : Try to optimize away sorting/distinct.</li><li data-pid="znlJBWm_">make_join_readinfo : Plan refinement stage: do various setup things for the executor.</li><li data-pid="6VfJacO6">make_tmp_tables_info : Setup temporary table usage for grouping and/or sorting.</li><li data-pid="sRaF2sw9">push_to_engines : Push (parts of) the query execution down to the storage engines if they can provide faster execution of the query, or part of it.</li><li data-pid="667X97eh">create_access_paths : generated ACCESS_PATH.</li></ul></ul><p data-pid="5z1e7KbG">新优化器默认不打开,必须通过set optimizer_switch="hypergraph_optimizer=on"; 来打开。主要通过FindBestQueryPlan函数来实现,逻辑如下:</p><ul><li data-pid="bJbkx2m4">先判断是否属于新优化器可以支持的Query语法(CheckSupportedQuery),不支持的直接返回错误ER_HYPERGRAPH_NOT_SUPPORTED_YET。</li><li data-pid="5NHM9dVn">转化top_join_list变成JoinHypergraph结构。由于Hypergraph是比较独立的算法层面的实现,JoinHypergraph结构用来更好的把数据库的结构包装到Hypergraph的edges和nodes的概念上的。</li><li data-pid="dMNK6WSS">通过EnumerateAllConnectedPartitions实现论文中的DPhyp算法。</li><li data-pid="xl-uij3n">CostingReceiver类包含了过去JOIN planning的主要逻辑,包括根据cost选择相应的访问路径,根据DPhyp生成的子计划进行评估,保留cost最小的子计划。</li><li data-pid="dp4cpRf2">得到root_path后,接下来处理group/agg/having/sort/limit的。对于Group by操作,目前Hypergraph使用sorting first + streaming aggregation的方式。</li></ul><p data-pid="Z_hKN4Lr">举例看下Plan(AccessPath)和SQL的关系:</p><figure data-size="normal"><img src="https://pic2.zhimg.com/v2-57e391b066d5406fbf0c17bf541e3bdb_r.jpg" data-caption="" data-size="normal" data-rawwidth="1080" data-rawheight="578" class="origin_image zh-lightbox-thumb" width="1080" data-original="https://pic2.zhimg.com/v2-57e391b066d5406fbf0c17bf541e3bdb_r.jpg"/></figure><p data-pid="pHcNOU7u">最后生成Iterator执行器框架需要的Iterator执行载体,AccessPath和Iterator是一对一的关系(Access paths are a query planning structure that correspond 1:1 to iterators)。</p><div class="highlight"><pre><code class="language-text">Query_expression::m_root_iterator = CreateIteratorFromAccessPath(......)
master [localhost:22031]> show variables like ‘sql_generate_invisible_primary_key’; +————————————+——-+ | Variable_name | Value | +————————————+——-+ | sql_generate_invisible_primary_key | OFF | +————————————+——-+ 1 row in set (0.00 sec)master [localhost:22031]> set sql_generate_invisible_primary_key=on; Query OK, 0 rows affected (0.00 sec)master [localhost:22031]> show variables like ‘sql_generate_invisible_primary_key’; +————————————+——-+ | Variable_name | Value | +————————————+——-+ | sql_generate_invisible_primary_key | ON | +————————————+——-+ 1 row in set (0.00 sec)
Create Table: CREATE TABLE t1 ( id int DEFAULT NULL, c1 int DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci 1 row in set (0.00 sec)
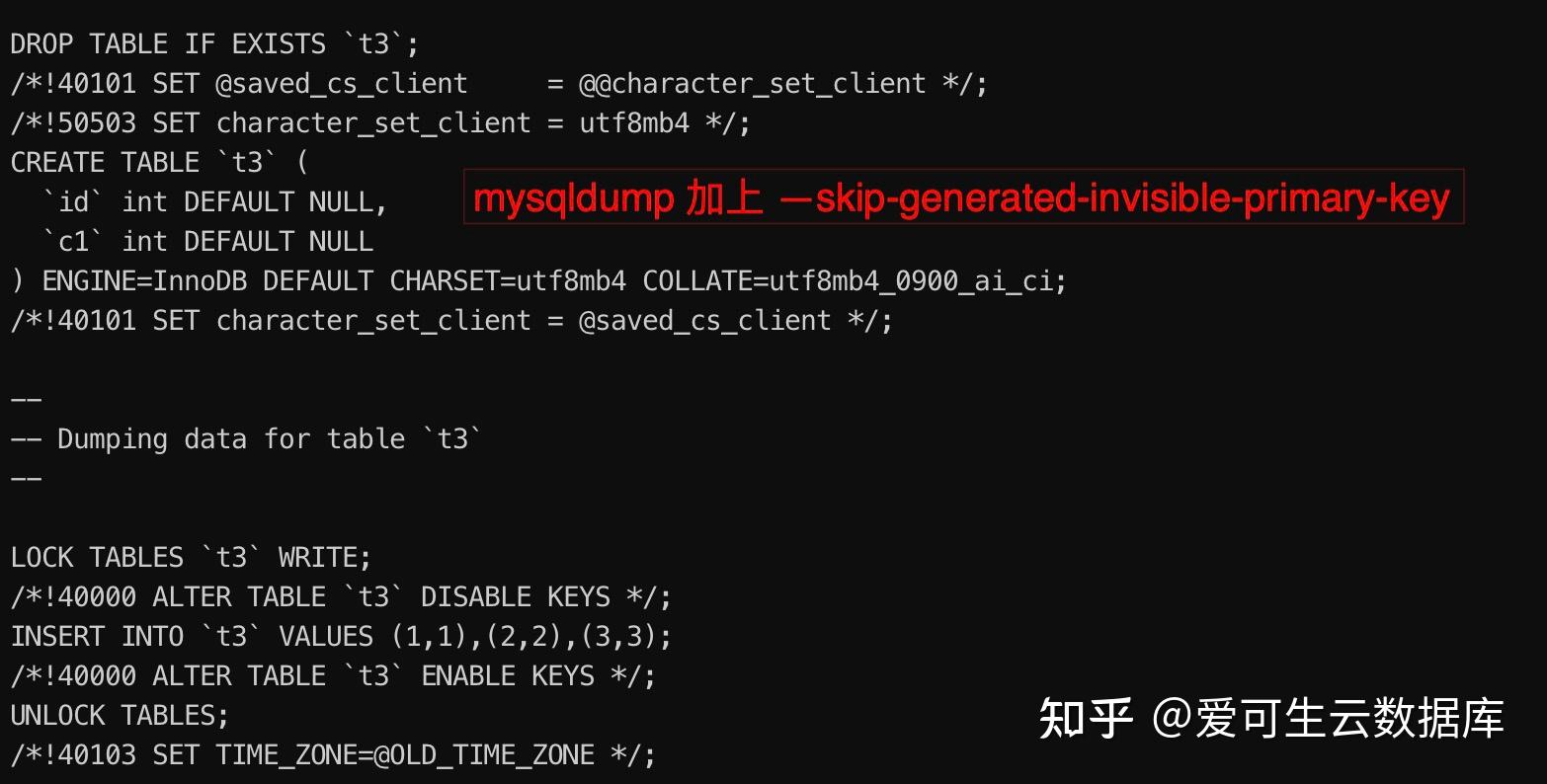
开启 GIPK 并创建无主键表 t3 。
讯享网master [localhost:22031]> set sql_generate_invisible_primary_key=on; Query OK, 0 rows affected (0.00 sec)master [localhost:22031] {msandbox} (test) > show variables like ‘sql_generate_invisible_primary_key’; +————————————+——-+ | Variable_name | Value | +————————————+——-+ | sql_generate_invisible_primary_key | ON | +————————————+——-+ 1 row in set (0.00 sec)master [localhost:22031]> create table t3(id int ,c1 int); Query OK, 0 rows affected (0.01 sec)master [localhost:22031]> master [localhost:22031]> show create table t3 \G * 1. row *
Table: t3
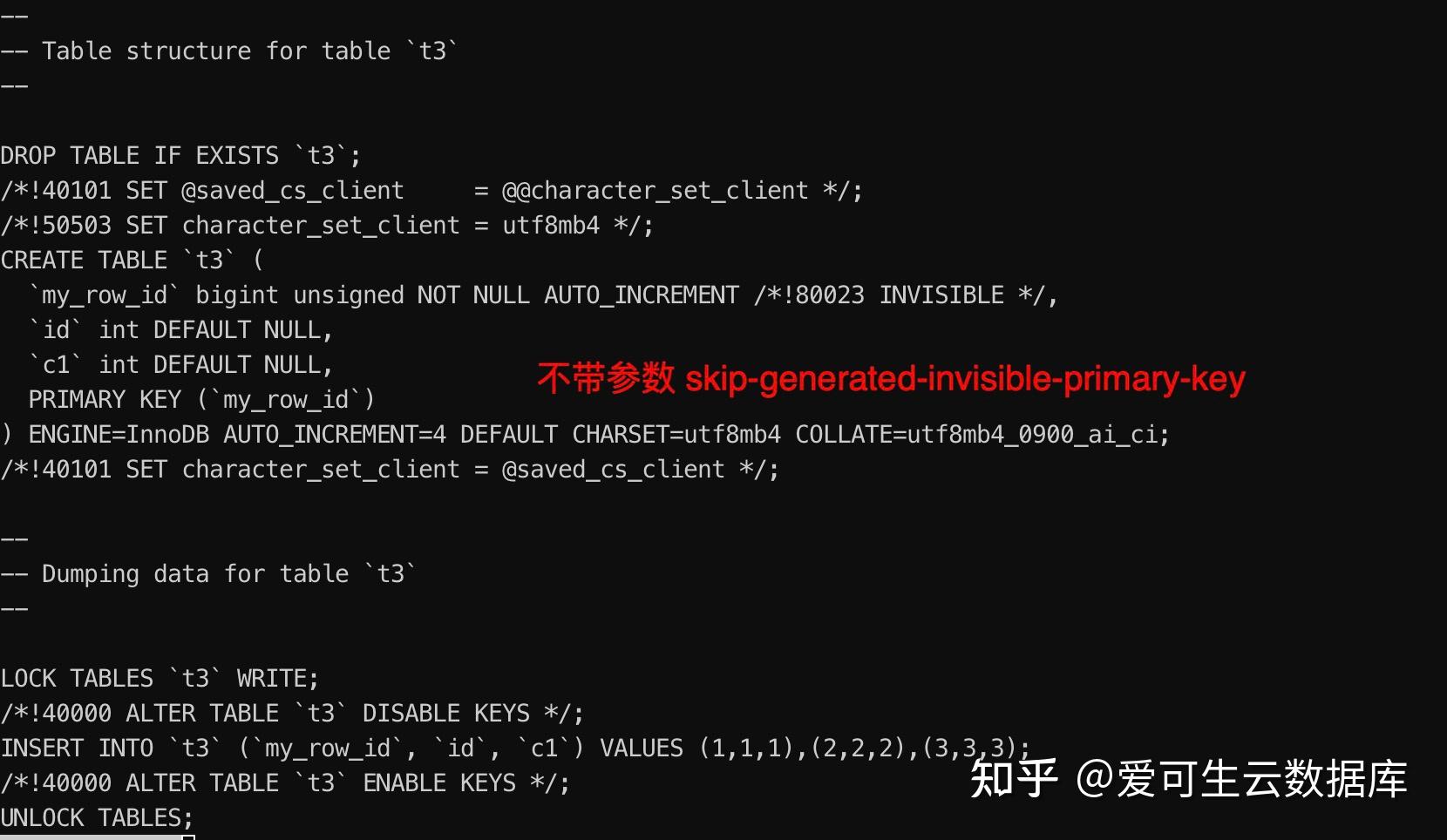
Create Table: CREATE TABLE t3 ( my_row_id bigint unsigned NOT NULL AUTO_INCREMENT /*!80023 INVISIBLE */, id int DEFAULT NULL, c1 int DEFAULT NULL, PRIMARY KEY (my_row_id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci 1 row in set (0.00 sec)
我们可以通过 show create table 发现 t3 的表结构,出现名为 my_row_id 的不可见主键。对两个表插入数据查看差异:
讯享网master [localhost:22031]> insert into t1 values(1,1),(2,2),(3,3); Query OK, 3 rows affected (0.00 sec) Records: 3 Duplicates: 0 Warnings: 0 master [localhost:22031]> select * from t1; +——+——+ | id | c1 | +——+——+ | 1 | 1 | | 2 | 2 | | 3 | 3 | +——+——+ 3 rows in set (0.00 sec) master [localhost:22031]> insert into t3 values(1,1),(2,2),(3,3); Query OK, 3 rows affected (0.00 sec) Records: 3 Duplicates: 0 Warnings: 0 master [localhost:22031]> select * from t3; +——+——+ | id | c1 | +——+——+ | 1 | 1 | | 2 | 2 | | 3 | 3 | +——+——+ 3 rows in set (0.00 sec)
讯享网master [localhost:22031]> create table t6(my_row_id int not null ,c1 int); ERROR 4108 (HY000): Failed to generate invisible primary key. Column ‘my_row_id’ already exists.
当然如果 MySQL 允许创建包含名为 my_row_id 的主键的表 :
master [localhost:22031]> create table t5(my_row_id int not null auto_increment primary key ,c1 int); Query OK, 0 rows affected (0.01 sec)
当开启 GIPK 模式时,如不能直接删除不可见主键。必须显式增加一个新的主键然后再删除 GIPK
讯享网master [localhost:22031]> alter table t3 drop PRIMARY KEY; ERROR 1235 (42000): This version of MySQL doesn‘t yet support ’existing primary key drop without adding a new primary key. In @@sql_generate_invisible_primary_key=ON mode table should have a primary key. Please add a new primary key to be able to drop existing primary key.‘master [localhost:22031]> alter table t3 drop PRIMARY KEY,add primary key(id); ERROR 4111 (HY000): Please drop primary key column to be able to drop generated invisible primary key.master [localhost:22031]> alter table t3 drop column my_row_id,add primary key(id); Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0
需要注意的是 set sql_generate_invisible_primary_key=on|off 并不会被复制到从库,主库上开启该特性的话,从库并不会开启 GIPK 。也就是说从库也不会为任何在源库上没有创建主键的表创建主键。可能会有读者疑问如果主库关闭该特性,但是从库显示开启呢? 做个测试看看在 master 上关闭该特性并且创建无主键表t6
master [localhost:22031]> set sql_generate_invisible_primary_key=off; Query OK, 0 rows affected (0.00 sec) master [localhost:22031]> master [localhost:22031]>show variables like ’sql_generate_invisible_primary_key‘; +————————————+——-+ | Variable_name | Value | +————————————+——-+ | sql_generate_invisible_primary_key | OFF | +————————————+——-+ 1 row in set (0.00 sec)master [localhost:22031]> show tables; +—————-+ | Tables_in_test | +—————-+ | t1 | | t2 | | t3 | | t4 | | t5 | +—————-+ 5 rows in set (0.00 sec)master [localhost:22031]> create table t6(id int ,c1 int); Query OK, 0 rows affected (0.01 sec)master [localhost:22031]> show create table t6\G * 1. row *
讯享网 Table: t6
Create Table: CREATE TABLE t6 ( id int DEFAULT NULL, c1 int DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci 1 row in set (0.00 sec)
在从库上开启该特性
slave1 [localhost:22032]> show tables; +—————-+ | Tables_in_test | +—————-+ | t1 | | t2 | | t3 | | t4 | | t5 | +—————-+ 5 rows in set (0.00 sec) slave1 [localhost:22032]> set sql_generate_invisible_primary_key=on; Query OK, 0 rows affected (0.00 sec) slave1 [localhost:22032]> show variables like ’sql_generate_invisible_primary_key‘; +————————————+——-+ | Variable_name | Value | +————————————+——-+ | sql_generate_invisible_primary_key | ON | +————————————+——-+ 1 row in set (0.00 sec) slave1 [localhost:22032]> show create table t6\G * 1. row *
讯享网 Table: t6
Create Table: CREATE TABLE t6 ( id int DEFAULT NULL, c1 int DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci 1 row in set (0.00 sec)


















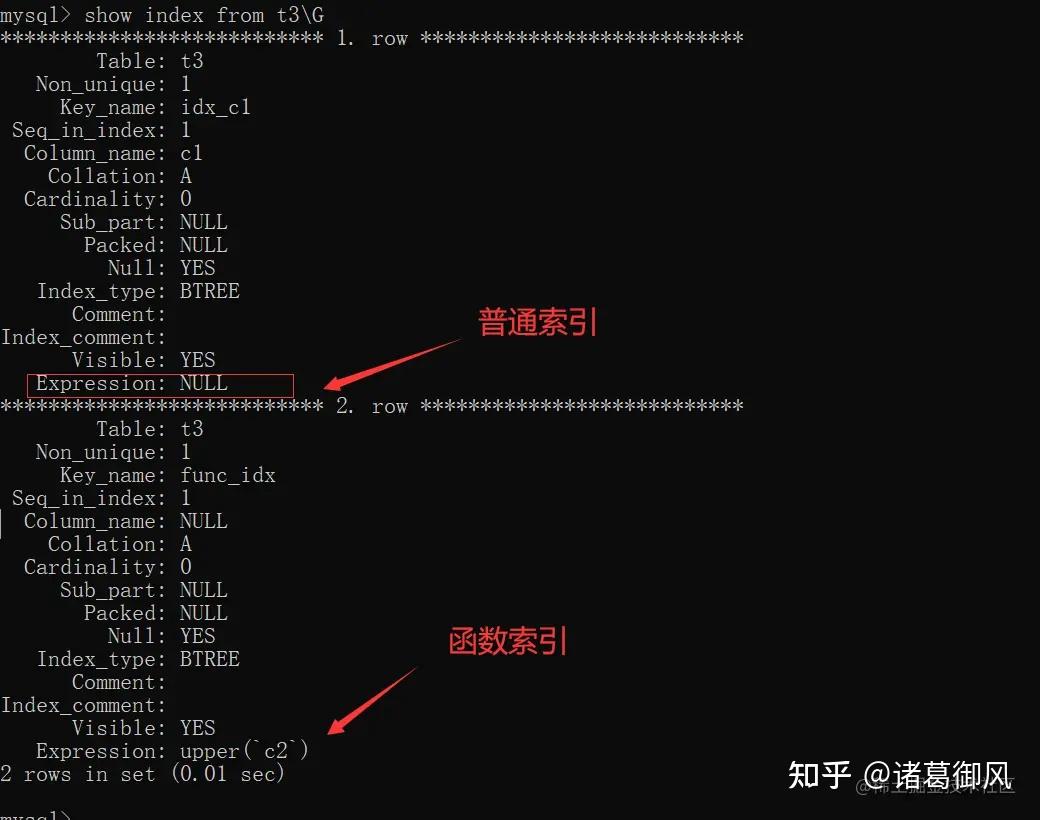
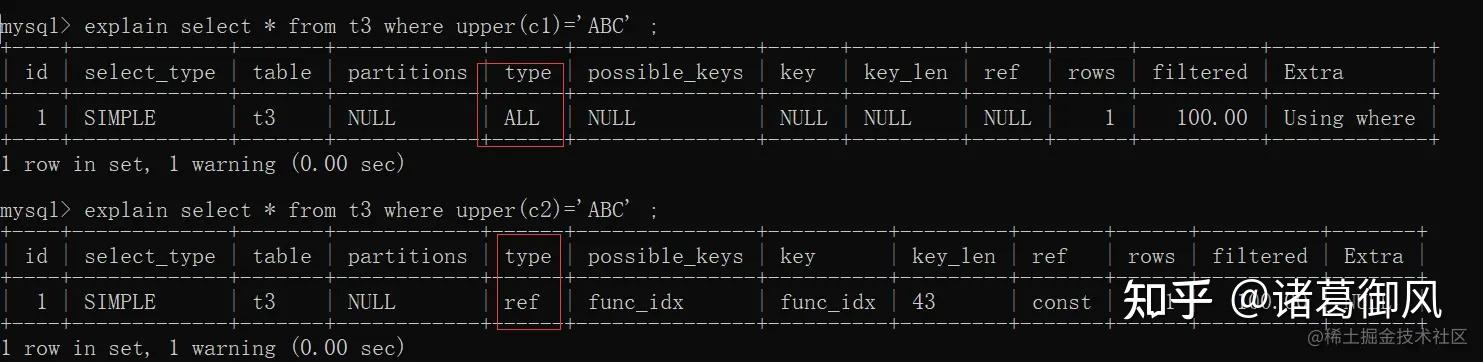
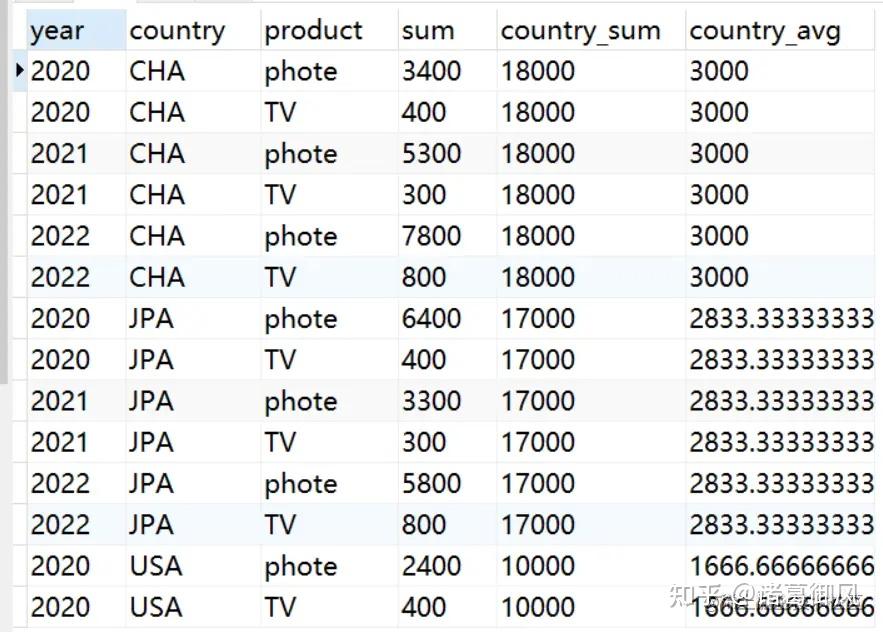
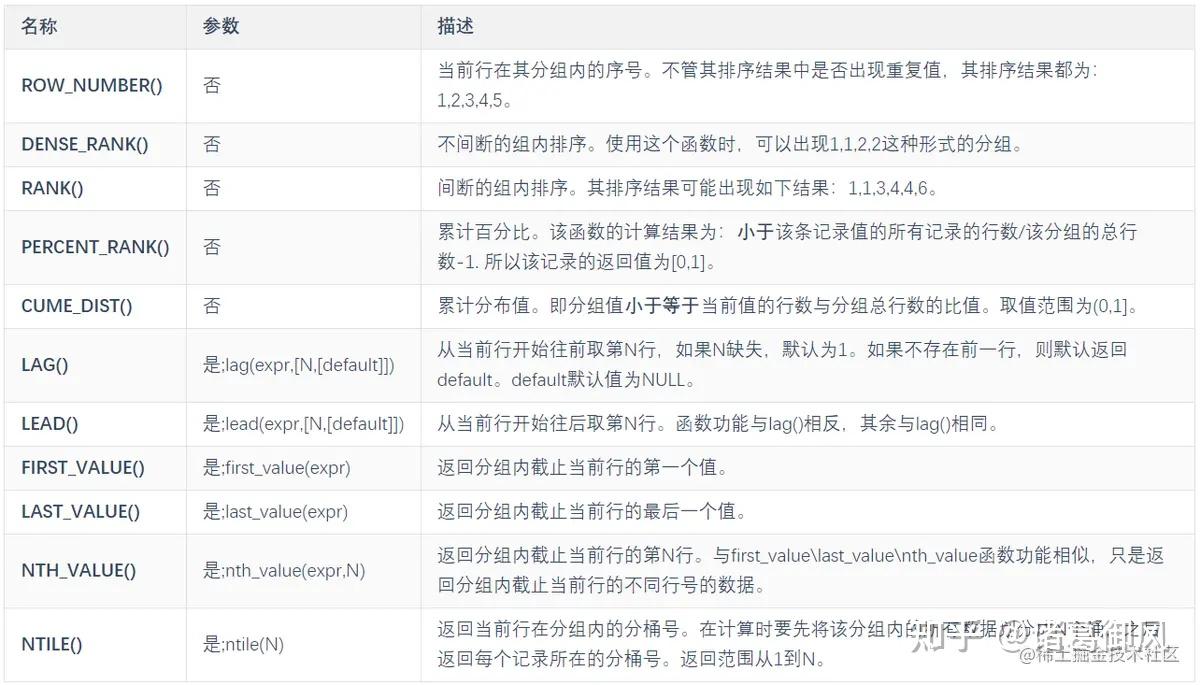


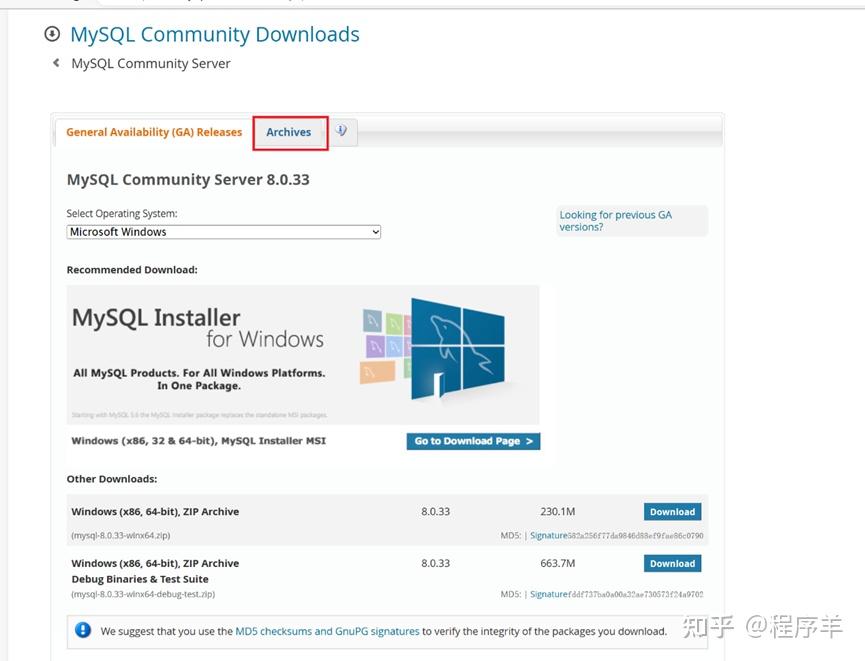
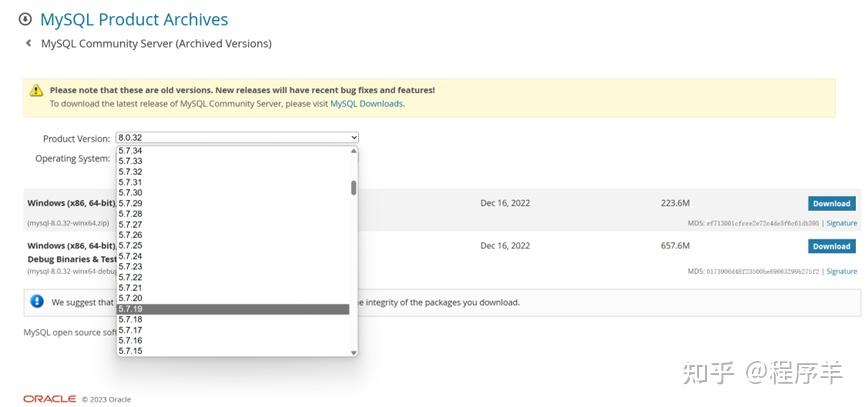

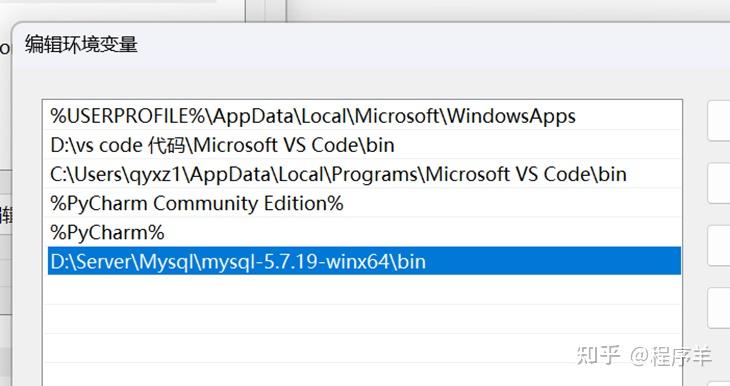




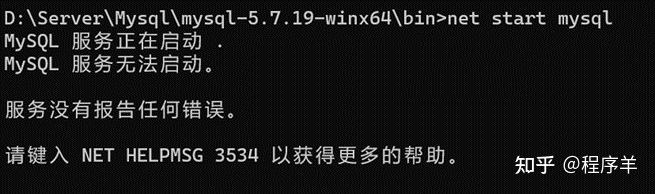
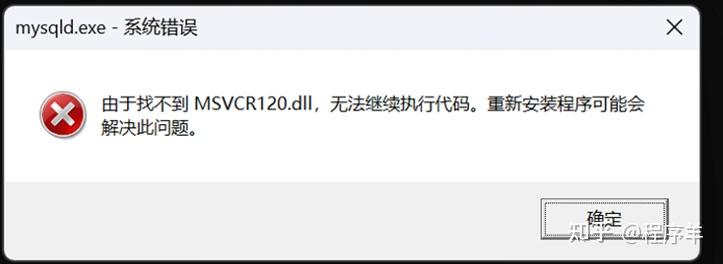
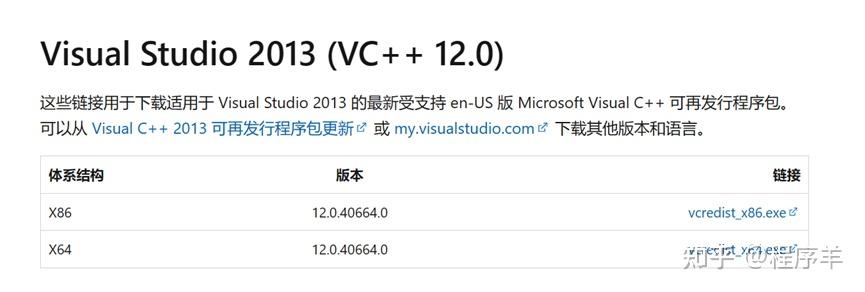














版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/175256.html