
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
yoloV3模型
目标检测:YOLO V1、YOLO V2、YOLO V3 算法
KITTI自动驾驶数据集的训练和检测过程(人、车检测案例)、KITTI数据集的TFRecord格式存储、YOLO V3/Yolo V3 Tiny 迁移学习
使用OpenCV进行深度学习:YOLO、SSD
学习目标
- 目标
- 掌握YOLO结构的封装接口以及结构
- 掌握TFRecord文件的读取和存储
- 掌握KITTI数据集的TFRecord格式存储
- 应用
- 应用完成KITTI自动驾驶数据集的格式转换
5.10.1 KITTI 数据集介绍
KITTI数据集由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集。该数据集用于评测立体图像(stereo),光流(optical flow),视觉测距(visual odometry),3D物体检测(object detection)和3D跟踪(tracking)等计算机视觉技术在车载环境下的性能。KITTI包含市区、乡村和高速公路等场景采集的真实图像数据,每张图像中最多达15辆车和30个行人,还有各种程度的遮挡与截断。
地址:http://www.cvlibs.net/datasets/kitti/
1、kitti目标检测(object detection)2D数据集
2D数据集,是我们目前所接触的检测常用将物体使用平面框框起来的形式数据。数据和标签文件以及描述文件下载:

数据集内容介绍
TXT文件中包含着每个图片的标注信息,KITTI数据集为摄像机视野内的运动物体提供一个3D边框标注(使用激光雷达的坐标系)。该数据集的标注一共分为8个类别:’Car’, ’Van’, ’Truck’, ’Pedestrian’, ’Person (sit- ting)’, ’Cyclist’, ’Tram’ 和’Misc’或者'DontCare'。注意,'DontCare' 标签表示该区域没有被标注。
标注解释(value表示字符个数),按照标注文件分割如下,下图是一张图片的label注释,可以看到有载货汽车,汽车,自行车:

- type(类型):有'Car'-汽车, 'Van'-厢式货车, 'Truck'-载货卡车, 'Pedestrian'-行人, 'Person_sitting', 'Cyclist'-骑车人, 'Tram'-电车, 'Misc' or 'DontCare'这几种类型,其中'Misc'和'DontCare'表示可以忽略
- truncated(是否截断):0-1之间的值,这张图片为0.00没有截断。(截断就是目标对象在采集图像的边缘被截断了,是不完整的)
- occluded(被遮挡程度):0表示没有遮挡,1表示部分遮挡,2表示大面积遮挡,3表示不清楚。
- alpha(摄像机的偏转视角):不做分析
- bbox(目标在图像中的位置坐标):4个数字分别为599.41、156.40(左上)、629.75、189.25(右下):
- xmin、ymin、xmax、ymax
- 注意YOLO需要的bounding box格式是(center_x, center_y, width, height),后面的处理会说明
- dimensions+location/rotation_y(图像的三维坐标):这里不做分析。
2、数据集下载
去官网下载之后的两个data_object_label_2.zip 5.6M和data_object_image_2.zip 12.57G文件。
解压之后如下:图片下面有训练和测试数据,而另一个training就是训练数据集的目标值存放文件里面为*.txt文件

5.10.2 YOLOV3源码实现分析
5.10.2.1 源码模型下载
1、官方自带开源
由论文作者,约瑟夫·切特·雷德蒙开源的称之为DarkNet,C语言中的开源神经网络,github地址:https://github.com/pjreddie/darknet。官方实现的特点是,思路就是原论文思路,测试精度和速度无太大差异,但是也有一些缺点比如实现的语言不是我们所擅长的语言,实现的思路比较难懂。
2、github高星实现版本
除了官方实现的,也会有一些其他机构或个人开源的熟悉的如TensorFlow、Pytorch的版本。这里我们后面做的案例就会使用。
- 最早实现的高星版本:keras-yolo3。
- TensorFlow实现的版本,相比官方版本,优点就是源码简单易读已复现,可能存在的缺点,速度性能上与C实现的版本会有一些差异。
实现不是从零开始,而是将别人的关键代码,复制进自己的项目。
复现步骤:1、熟悉算法思想 2、介绍相关应用 3、分模块进行实战练习
3、YOLO官网上提供了很多YOLO v3的预训练模型
地址:https://pjreddie.com/darknet/yolo/。大多时候思维是基于预训练模型训练自己需要的模型,比如预训练模型中其实包括了我们需要的大类,我们还需要再细分此类,那需要建立自己的训练数据集,并开展训练。不过当训练数据不理想或训练时间不充分时,二次训练模型在大类辨别基础上并不及预训练模型,这时可以直接试试预训练模型的效果。
5.10.2.2 YOLOV3-Tensorflow2.0源码分析
1、V3整体结构
YOLOv3引入了残差模块,并进一步加深了网络,改进后的网络有53个卷积层,命名为Darknet-53。YOLOv3借鉴了FPN的思想,从不同尺度提取特征。
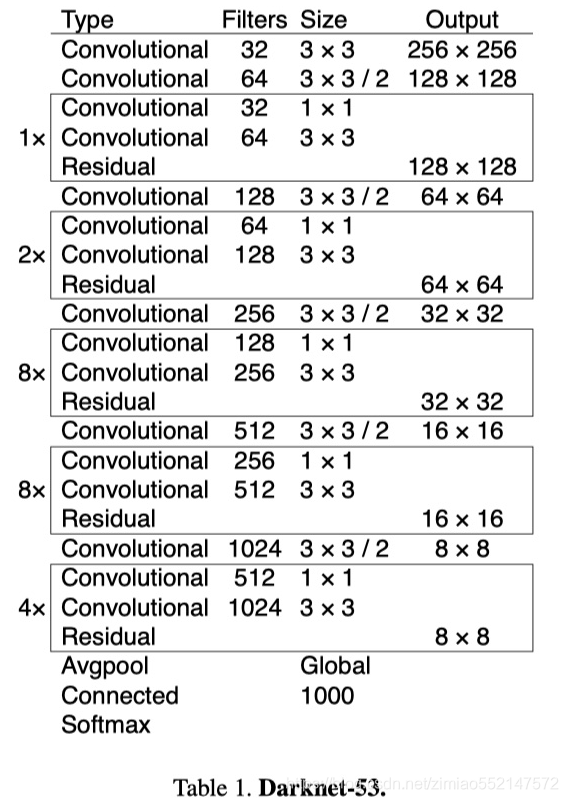
YOLOV3的详细结构如下:
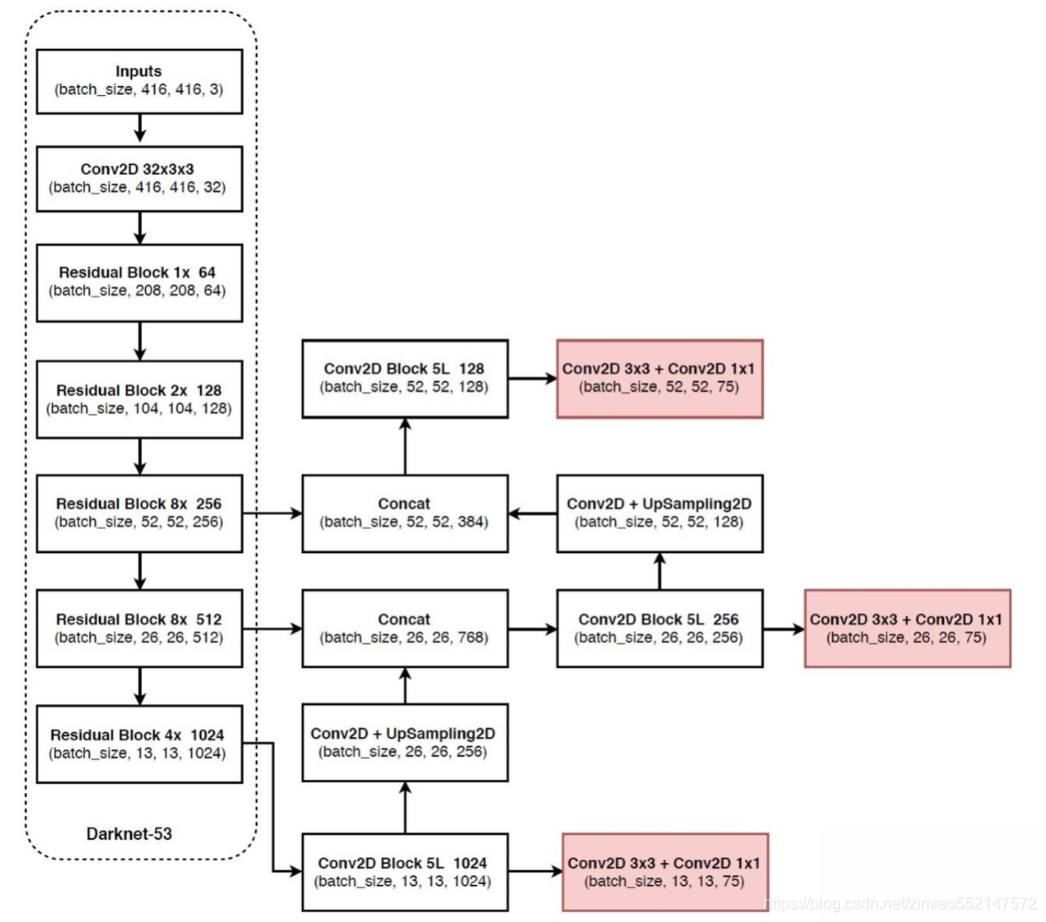

YOLOv3 的网络结构由基础特征提取网络、multi-scale特征融合层和输出层组成。
- 特征提取网络:YOLOv3使用DarkNet53作为特征提取网络:DarkNet53 基本采用了全卷积网络,用步长为2的卷积操作替代了池化层,同时添加了 Residual 单元,避免在网络层数过深时发生梯度弥散。
- 特征融合层:为了解决之前YOLO版本对小目标不敏感的问题,YOLOv3采用了3个不同尺度的特征图来进行目标检测,分别为13x13,26x26,52x52,用来检测大、中、小三种目标。特征融合层选取 DarkNet 产出的三种尺度特征图作为输入,借鉴了FPN(feature pyramid networks)的思想,通过一系列的卷积层和上采样对各尺度的特征图进行融合。
- 输出层:同样使用了全卷积结构,其中最后一个卷积层的卷积核个数是255:3x(20+4+1)=75表示一个grid cell包含3个bounding box,4表示框的4个坐标信息,1表示Confidence Score,20表示VOC数据集中80个类别的概率。如果换用别的数据集,20可以更改为实际类别数量。
2、源码主模型
- YOLOV3的筑结构:
- 1、Darknet
- 2、3层YoloConv进行拼接然后卷积操作得到三层输出output_0,output_1,output_2(由深到浅)
- 3、如果是预测
- 三层输出直接通过yolo_boxes计算得到bbox, objectness, class_probs, pred_box
- 然后合并进行yolo_nms过滤输出预测结果
讯享网
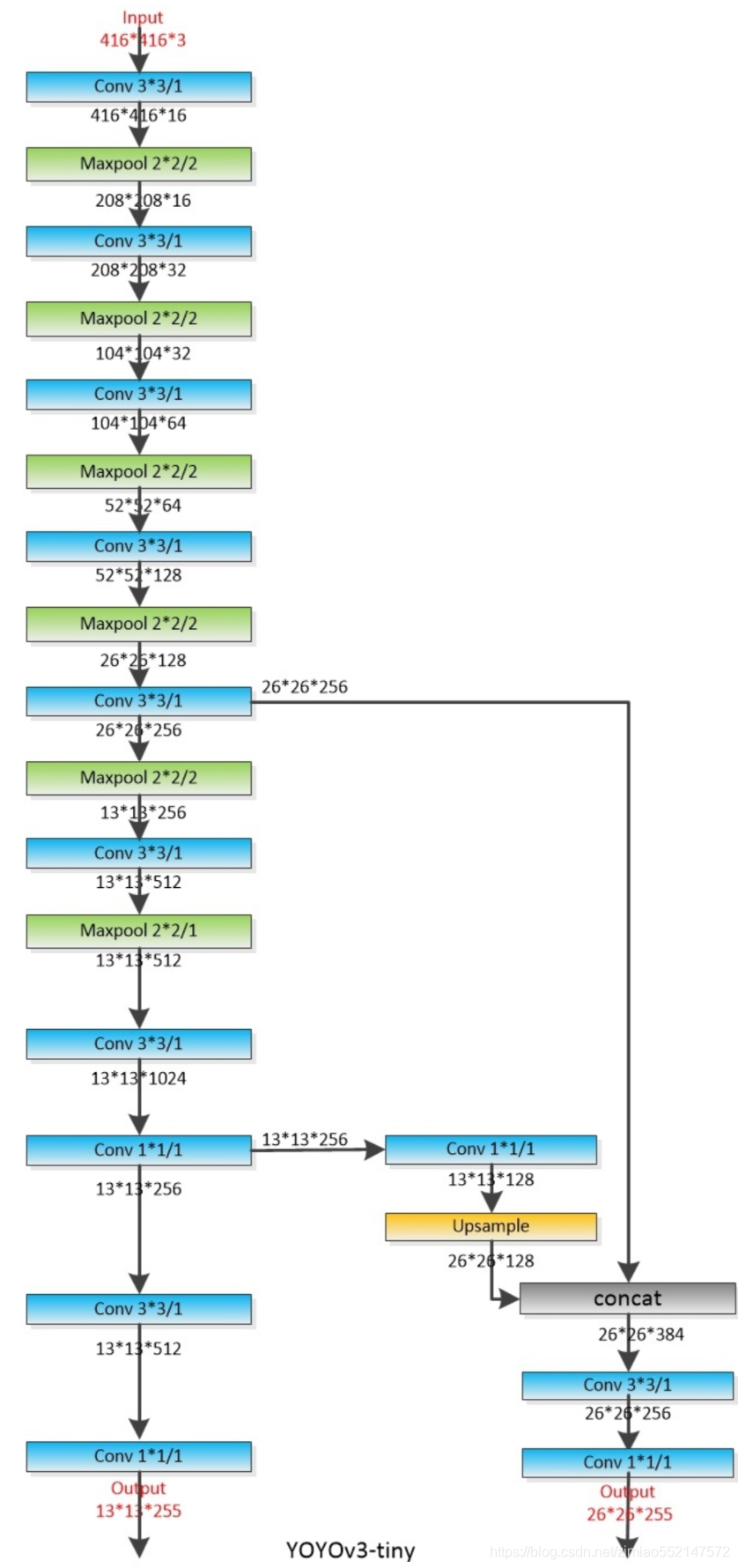
- YOLOV3Tiny结构
同样是YOLOV3的原作者提出来的一个速度更快但精度稍低的嵌入式版本系列——Tiny-YOLO。对于速度要求比较高的项目,YOLOV3-tiny会是首要选择。删除一些特征层并且输出只有两层特征做筛选。
注:还有使用其他轻量级骨干网络的YOLO变种,如MobileNet-YOLOv3等。
讯享网
- 两者主结构Darknet与DarknetTiny的对比
- 1、YOLOV3重复若干层DarknetBlock,里面包含残差模块,输出包含三层特征
- 2、YOLOV3-Tiny实现删除残差模块,进行若干层采样,并且输出只有两层特征
3、使用模型
讯享网
5.10.3 KITTI人车检测项目
5.10.3.1 项目目录与模块

- data:包含所有数据目录
- utils:数据集转换等工具目录
- yolov3-tf2:TensorFlow2.0实现的YOLO多种模型目录
5.10.3.2 项目步骤分析
我们利用已经提供好的数据集和实现好的YOLO模型,去进行训练KITTI场景下的物体检测,包括人,车等多种物体。
- 1、数据集类型转换,KITTI转换成TFRecords文件
- 2、KITTI案例训练代码实现
- 3、图片和视频的检测代码实现
5.10.4 数据集类型转换-KITTI数据集转换成TFRecords文件
5.10.4.1 TFRecord-TensorFlow 数据集存储格式
TFRecord 是 TensorFlow 中的数据集存储格式。当我们将数据集整理成 TFRecord 格式后,TensorFlow 就可以高效地读取和处理这些数据集,从而帮助我们更高效地进行大规模的模型训练。
- 格式:TFRecord 可以理解为一系列序列化的 元素所组成的列表文件,而每一个 又由若干个 的字典组成。形式如下:
1、保存TFRecord
为了将形式各样的数据集整理为 TFRecord 格式,我们需要对数据集中的每个元素进行以下步骤:
- 1、读取该数据元素到内存
- 2、将该元素转换为 对象(每一个 由若干个 的字典组成,因此需要先建立 Feature 的字典);
- 3、将该 对象序列化为字符串,并通过一个预先定义的 写入 TFRecord 文件。
2、读取 TFRecord 数据
则可按照以下步骤:
- 1、通过 读入原始的 TFRecord 文件(此时文件中的 对象尚未被反序列化),获得一个 数据集对象;
- 2、通过 方法,对该数据集对象中的每一个序列化的 字符串执行 函数,从而实现反序列化。
3、实例
将对cats_vs_dogs二分类数据集的训练集部分转换为 TFRecord 文件,并读取该文件的过程。因为图片过多,这里为了快速看到效果,选择了sample目录下的train数据集几张图片。
1、获取本地的数据
讯享网
2、迭代读取每张图片,建立 字典和 对象,序列化并写入 TFRecord 文件。
tfrecords的文件大小会缩小,由于这里数据及本身不大所以没有对比,后面我们的KITTI数据集生成的大小会小很多。
注意:tf.train.Feature只支持三种数据格式:
- :字符串或原始 Byte 文件(如图片),通过 参数传入一个由字符串数组初始化的 对象
- :浮点数,通过 参数传入一个由浮点数数组初始化的tf.train.FloatList对象
- :整数,通过 参数传入一个由整数数组初始化的 对象。
3、读取 TFRecord 文件
我们可以通过以下代码,读取之间建立的 文件,并通过 方法,使用 函数对数据集中的每一个序列化的 对象解码。
讯享网
- 这里的 类似于一个数据集的 “描述文件”,通过一个由键值对组成的字典,告知 函数每个 数据项有哪些 Feature,以及这些 Feature 的类型、形状等属性。
- 的三个输入参数 、 和 (可省略)为每个 Feature 的形状、类型和默认值。这里我们的数据项都是单个的数值或者字符串,所以 为空数组。
5.10.4.2 KITTI数据集转换成TFRecords文件
- 目录结构:
- create_kitti_tf_record.py:需要实现的主要存储逻辑
- 步骤:
- 1、进行读取主逻辑函数过程编写,指定需要传递的命令行参数
- 2、读取文件标准信息、过滤标注信息、进行构造example的feature字典
1、进行读取主逻辑函数过程编写,指定需要传递的命令行参数
- 定义convert_kitti_to_tfrecords,补充完整命令行参数
- 创建KITTI训练和验证集的tfrecord位置
- 列出所有的图片,进行每张图片的内容和标注信息的获取,写入到tfrecords文件

其中导入相关包和命令行参数如下设置
讯享网
编写的主函数逻辑如下:
(2)读取读取标签文件函数
讯享网
(3)过滤标签函数
2、读取文件标准信息、过滤标注信息、进行构造example的feature字典
讯享网
最终运行完成之后对应的目录输出TFRecord文件:
- trian.tfrecord
- val.tfrecord
那么仔细去观察之后会发现,总共大小5.5G训练+396M验证集,要比data_object_image_2.zip 12.57G少了将近一倍。
5.10.5 小结
- 掌握YOLO结构的封装接口以及结构
- 掌握TFRecord文件的读取和存储
- 掌握KITTI数据集的TFRecord格式存储
学习目标
- 目标
- 无
- 应用
- 应用完成KITTI自动驾驶数据集的训练和检测过程
5.11.1 训练过程实现
- 步骤
- 训练参数设置
- 1、判断传入的是需要训练YoloV3Tiny还是YOLOV3正常版本
<ul><li>由于有实现多个版本,可以让用户选择具体版本来进行指定模型训练</li></ul></li><li>2、获取传入参数的训练数据以及获取传入参数的验证集数据 <ul><li>通过dataset.load_tfrecord_dataset进行读取</li></ul></li><li>4、判断是否进行迁移学习 <ul><li>在训练期间可以封装让训练自定义训练的结构,从而根据自己的数据训练模型</li></ul></li><li>5、定义优化器以及损失计算方式</li><li>6、优化训练</li></ul></li></ul> 通过argparse设置训练参数
讯享网
1、判断传入的是需要训练YoloV3Tiny还是YOLOV3正常版本
- 并且初始化YOLO各个模型的anchor大小,(在源码中有设置,计算损失时候需要用)
- anchors: 使用到的anchor的尺寸,如[10, 13, 16, 30, 33, 23, 30, 61, 62, 45, 59, 119, 116, 90, 156, 198, 373, 326]
- anchor_mask: 每个层级上使用的anchor的掩码,[[6, 7, 8], [3, 4, 5], [0, 1, 2]]
<ul><li>anchor box的索引数组,3个1组倒序排序: <ul><li>如6,7,8对应13x13特征图取(116, 90), (156, 198), (373, 326)</li></ul></li></ul></li></ul></li><li> <pre></pre> </li></ul> 讯享网
2、获取传入参数的训练数据以及获取传入参数的验证集数据
- 通过dataset.load_tfrecord_dataset进行读取
3、判断训练是否进行迁移学习,指定结构冻结
- 1、如果迁移学习:
- 加载与训练权重,可从官网下载
讯享网<ul><li>如果判断微调的话:加载yolo_darknet:x_36, x_61, x = Darknet(name='yolo_darknet')(x),冻结这些层</li><li>如果用户传入frozen:冻结所有层</li><li>如果是其他:根据YOLO类型,初始化模型 <ul><li>若只对darknet迁移,然后对剩余其他层进行冻结</li><li>如果是no_output,吧out_put部分进行随机初始化,然后冻结其他加载过的模型权重</li></ul></li></ul></li></ul></li></ul>
5、定义优化器以及损失计算方式
讯享网
注:其中YOLOLoss的计算过程源码当中
6、训练优化过程,训练指定模式
- 用eager的梯度调试模式进行训练易于调试
- keras model的fit模式简单易用
1、EarlyStopping
- keras.callbacks.EarlyStopping(monitor=‘val_loss’, patience=0, verbose=0, mode=‘auto’)
当监测值不再改善时,该回调函数将中止训练
- 参数
- monitor:需要监视的量
- patience:当early stop被激活(如发现loss相比上一个epoch训练没有下降),则经过个epoch后停止训练。
- verbose:信息展示模式
- mode:‘auto’,‘min’,‘max’之一,在模式下,如果检测值停止下降则中止训练。在模式下,当检测值不再上升则停止训练。
5.11.2 测试过程实现
- 步骤
- 1、初始化模型并加载权重
- 2、加载图片处理图片并使用模型进行预测
- 3、将图片框画在图片中并进行保存
导入包并制定相关参数
讯享网
整体过程实现逻辑:
其中用到几个YOLO源码实现的处理函数(无需实现,具体参考源代码)
讯享网
- 预处理大小和归一化函数
- draw_outputs
讯享网
如果我们看不到结果,说明预测的结果都不好,所以可以这样在模型的代码中修改iou和分数的阈值来进行调整(根据实际需求)
5.11.3 小结
- 完成KITTI自动驾驶数据集的训练和检测过程
create_kitti_tf_record.py
讯享网
feature_parse.py
IoU.py
讯享网
detect.py
train.py
讯享网
batch_norm.py
dataset.py
讯享网
models.py
utils.py
讯享网
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/174973.html