
1. 官方说明
gather( input', dim, index, out=None, sparse_grad=False)
Gathers values along an axis specified by dim
沿着给定的维度dim收集值
Args: 参数(初学者可只看前三个参数)
input (Tensor): the source tensor 源tensor(Tensor类型)
dim (int): the axis along which to index 要进行索引的轴方向(int类型)
index (LongTensor): the indices of elements to gather(LongTensor类型)
out (Tensor, optional): the destination tensor 返回值(Tensor类型)
sparse_grad(bool,optional): If True, gradient w.r.t. :attr:input will be a sparse tensor. 若为真,这关于input的梯度为sparse tensor
注意:index的维度要和input中dim所指的维度相同
2. 例子说明
1) 按照dim = 0, 取一个2*2 tensor的对角线上的数值
#按照dim = 0, 取一个2*2tensor的对角线上的数值 import torch a = torch.Tensor([[1, 2], [3, 4]]) b = torch.gather(a, dim = 0, index=torch.LongTensor([[0, 1]])) print('a = ', a) print('b = ', b)讯享网
输出如下:
讯享网a = tensor([[1., 2.], [3., 4.]]) b = tensor([[1., 4.]])
说明:
可以看到a的dim=0, 即行方向的维度和index的维度是匹配的,就是说a和index由行方向从左往右看,有2列,即有2个样本,行方向是匹配的。另外,函数输出的tensor和index大小相同。
上面代码的操作逻辑是:
在a中,由行看,有两个样本,索引分别为0和1;每个样本有两个特征,每个特征中索引分别为0和1;依据index中的索引值,取第0样本的第0个特征1,再取第1个样本的第1个特征4
2) 按照dim = 1, 取一个2*2 tensor的对角线上的数值
#按照dim = 1, 取一个2*2 tensor的对角线上的数值 import torch a = torch.Tensor([[1, 2], [3, 4]]) c = torch.gather(a, dim = 1, index=torch.LongTensor([[0], [1]])) print('a = ', a) print('c = ', c)输出如下:
讯享网a = tensor([[1., 2.], [3., 4.]]) c = tensor([[1.], [4.]])
说明:
可以看到a的dim=1, 即列方向的维度和index的维度是匹配的,就是说a和index由列方向从上往下看,有2行,即有2个样本,列方向是匹配的。另外,函数输出的tensor和index大小相同。
上面代码的操作逻辑是:
在a中,由列看,有两个样本,索引分别为0和1;每个样本有两个特征,每个特征中索引分别为0和1;依据index中的索引值,取第0样本的第0个特征1,再取第1个样本的第1个特征4。
# import torch a = torch.Tensor([[1, 2], [3, 4]]) d = torch.gather(a, dim= 0, index=torch.LongTensor([[0, 0], [1, 0]])) print('a = ', a) print('d = ', d)输出:
讯享网a = tensor([[1., 2.], [3., 4.]]) d = tensor([[1., 2.], [3., 2.]])

3. 实际中的一个例子
有三个标签[0, 1, 2],即三个类别。现在知道两个样本(A 和 B)所得到的三个标签的概率分别为[0.1, 0.3, 0.6]和[0.3, 0.2, 0.5], 用myY_hat表示, 这两个样本的真实标签分别为0和2, 那么我们很容易知道A所预测的真实标签的概率为0.1, B所预测的真实标签的概率为0.5,A误分类,B正确分类。那么用程序这么获得标签对应的概率呢,这里就可以用gather函数。
myY_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]]) myY = torch.LongTensor([0, 2]) print(myY.view(-1, 1)) print(myY_hat.gather(1, myY.view(-1, 1)))输出:
讯享网tensor([[0], [2]]) tensor([[0.1000], [0.5000]])
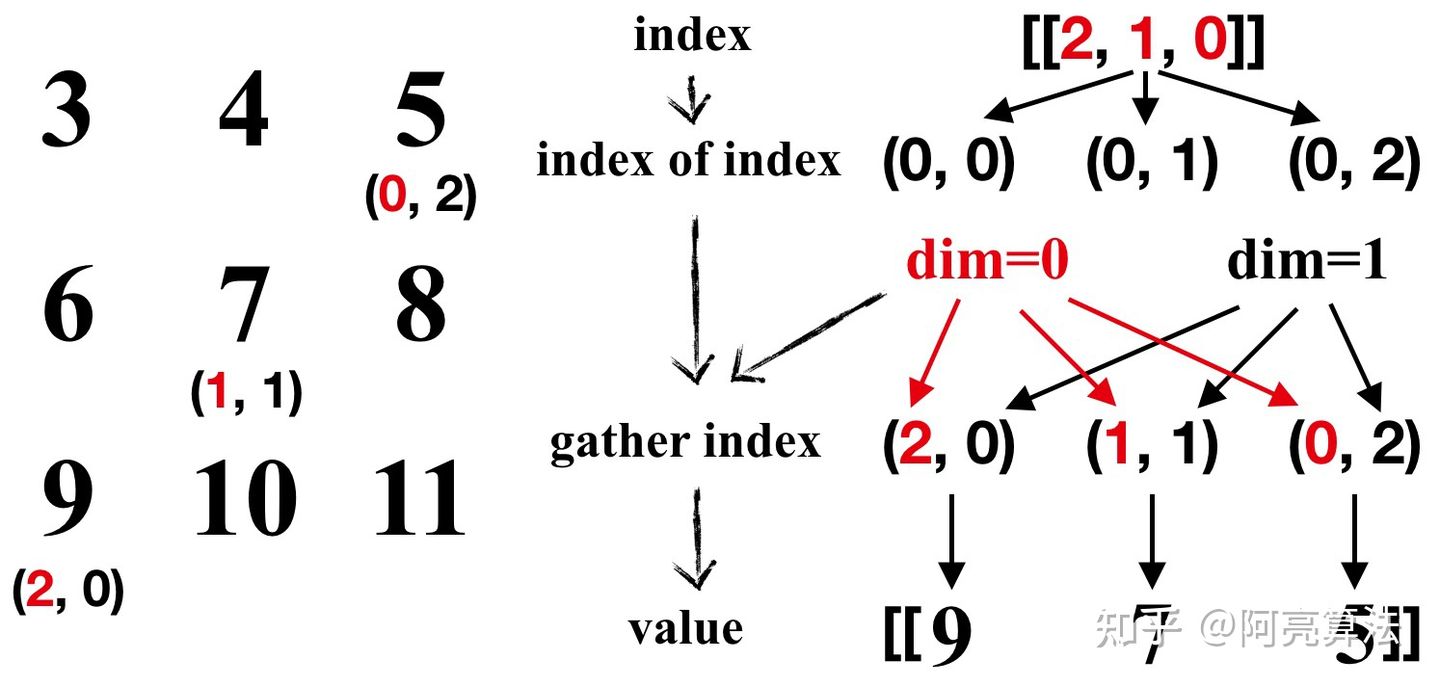
4. 关于坐标(矩阵内位置)的简单获取(计算)方法:
import torch tensor_0 = torch.arange(3, 12).view(3, 3) print(tensor_0)输出:
讯享网tensor([[ 3, 4, 5], [ 6, 7, 8], [ 9, 10, 11]])
输入行向量index,并替换行索引(dim=0)
index = torch.tensor([[2, 1, 0]]) tensor_1 = tensor_0.gather(0, index) print(tensor_1)输出结果
讯享网tensor([[9, 7, 5]])
更多内容请参考 图解PyTorch中的torch.gather函数 - 知乎
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/17446.html