
<p>说起ResNet必然要提起He大佬,这真是神一样的存在,这不,不久前又有新的突破RegNet,真是厉害啊。</p> 讯享网
ResNet开篇之作在此,后面又出了各种变形啥的,ResNeXt,inception-ResNet等等吧,He大佬推荐的tf版本代码在此。keras ResNet50的在此。
总体:
这个网络结构主要是解决加深网络而不能减小loss的问题,如图下:
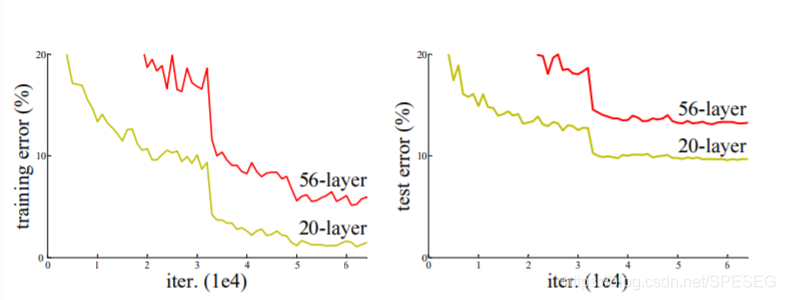
网络越深越好吗?不是,加一层acc或者其他指标就好了??并不是,既然网络加深了,又难以训练,效果又不好,谁还用深的网络?He大佬的残差学习结构网络大体上比其他模型深,152层,8倍VGG,但复杂性不高,且以ImageNet 测试集3.57%error got first ILSVRC 2015分类任务,同时取得ImageNet 检测,定位,COCO数据集检测,分割的第一。
在keras构建模型中,大多数都是序列化堆叠一些层,但这样有效果吗?
网络结构:
一般定义底层映射H(x),然后堆叠非线性层拟合F(x):=H(x)-x,最初的映射则为F(x)+x,于是我们认为优化后者即F(x)+x,比无参考的前者H(x)更容易【这是直接翻译的,具体啥意思我还没转过来弯】下面就是这个的building block,即有名的identity mapping【恒等映射】
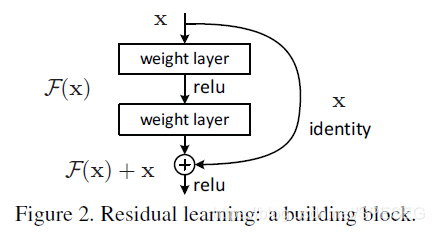
直接将x加过来既没有增加参数,也没有增加复杂度。仍旧可以采用SGD优化器就行反向传播。
对于每层堆叠都采用残差学习模块,正如上图所言,有两层,F=W2*theta(W1*x),theta是激活函数relu,为简化计,忽略偏置。
F+x就是直接相连,每个元素对应相加,然后再用relu激活。如果F和x的维度不同,可采用线性映射Ws,Ws也可为方阵,如下:
y=F+Ws*x,作者证实,这种简单的恒等映射对于处理图1问题是足够的,而且是经济的【划算】。残差结构也不是一成不变的,也可以是其他形式,比如下面:2层或3层都是可以的,或者更多层,但是只有一层【即y=W1*x+x】没有发现优势。

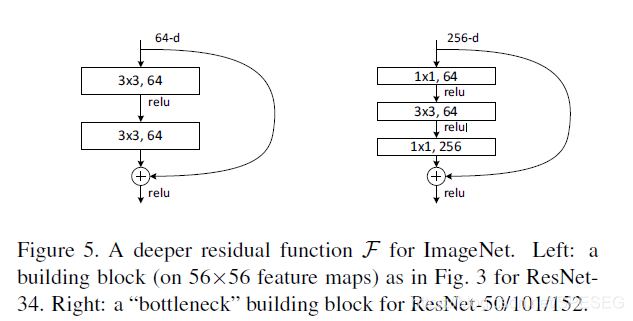
在卷积层和全连接层都是可用的。
下面看看keras版本的代码:其实我之前就看过了这个版本的代码了
1.恒等映射部分
讯享网
如果不同width或height及channel,那么采用卷积使得结果相同,如果相同就是简单的相加(add)
下面验证一下不同时的情况:这里有个潜在的约束,就是residual是经过卷积后的,HW肯定比x要小(相同的情况则是上句的直接相加)至于是不是整数倍,这个不一定,因为上面的代码其实是固定了核的大小,如果不固定的话会更加灵活,那就要考虑余数与核大小的关系了。视input1为x,input2为residual。
考虑卷积核大小可以改变,那么可以直接采用下面的卷积
讯享网
2.关于残差模块,下面是bottleneck,也就是采用了3层卷积
上面所指的第一层是
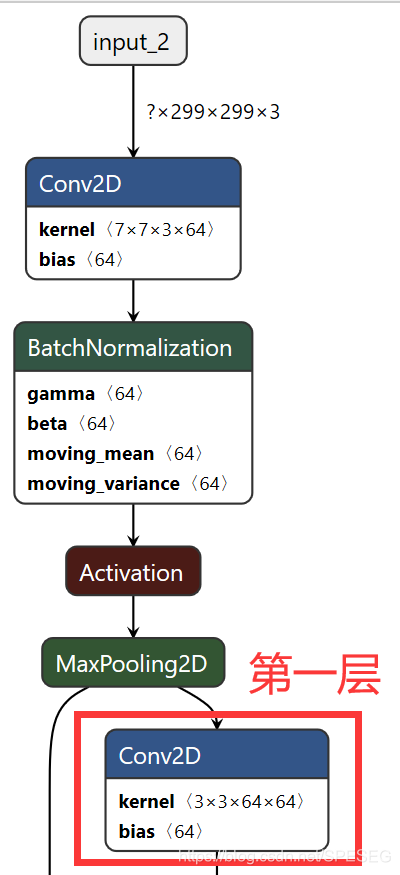
因为代码作者采用的是循环的操作,这个第一层就是开始循环的第一层。
he大佬的2层卷积即basic_block中,当维度不同时可以采用补零或者上面所提的投影【代码作者采用的是卷积,如下方框】
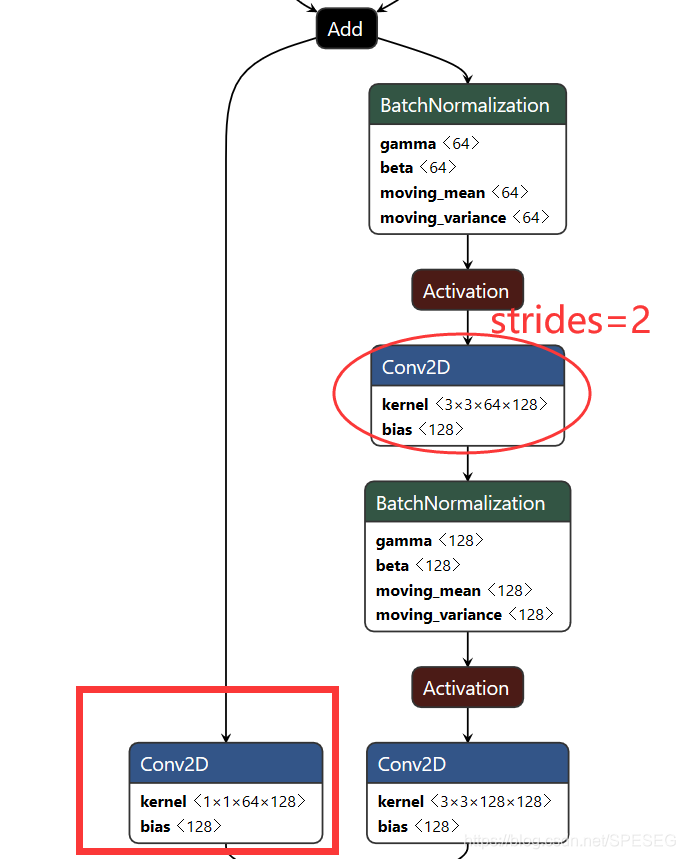
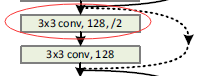

步长为2.至于为何为2,不是1,两个大佬都没说。
he大佬在卷积后激活前采用BN层,根据某个实践,没有用dropout,并没有解释或者对照试验。
下面的34层恰好就是repetition中的3463
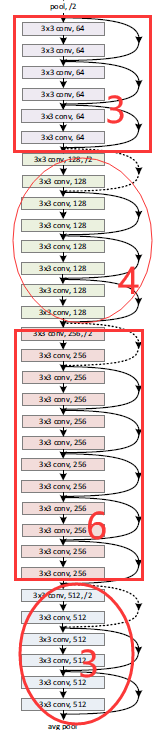
讯享网
3关于代码中细节
可能不同的tf版本运行结果报错,请直接修改数据格式,将判断是不是tf后台那里改了就好。
另外,随意增加循环层或者说resnet层数其实并不能提高acc或其他指标,可见我的具体实践。
最后的avg其实就gap
另外有相关问题可以加入讨论,不设微信群
:
语音图像视频推荐深度-学习群
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/172115.html