
3.5 本章介绍 DM 的数据定义语句,包括数据库修改语句、用户管理语句、模式管理语句、表空间管理语句、表管理语句等等。
需要注意的是,在数据定义语句中有时需要指定一些文件的路径,无论用户指定的是绝对路径还是相对路径,DM 在处理时最终都会将其统一处理为绝对路径,DM 规定这个绝对路径的长度不能超过 256 字节。
一个数据库创建成功后,可以修改日志文件大小、增加和重命名日志文件、可以移动数据文件;可以修改数据库的状态和模式;还可以进行归档配置。
语法格式
讯享网
参数
- < 文件路径 > 指明**作的数据文件在操作系统下的绝对路径:'路径 + 数据文件名'。例如:'C:DMDBMSdatadmlog_0.log';
- < 文件大小 > 整数值,单位 MB,取值范围 64~2048,缺省为 1024MB,即 1G;
- < 归档目标 > 指归档日志所在位置,若本地归档,则本地归档目录;若远程归档,则为远程服务实例名;删除操作,只需指定归档目标;
- < 归档类型 > 指归档操作类型,包括 LOCAL/REALTIME/ASYNC/SYNC/REMOTE/TIMELY,分别表示本地归档/实时归档/异步归档/同步归档/远程归档/主备即时归档;
- HANG_FLAG 本地归档写入失败时系统是否挂起标志。取值 0 或 1,0 不挂起;1 挂起。缺省为 1(第一份本地归档系统内固定设为 1,设 0 实际也不起作用);
- WAIT_APPLY 指定实时归档/即时归档是否为高性能模式或事务一致模式。取值 0 或 1,0 表示高性能模式;1 表示事务一致模式。若未指定 WAIT_APPLY,则以 dmarch.ini 中的 ARCH_WAIT_APPLY 配置项为准;
- < 空间大小限制 > 整数值,取值范围 1024~,若设为 0,表示不限制,仅本地归档有效;
- < 定时器名称 > 异步归档中指定的定时器名称,仅异步归档有效;
- < 归档延时发送时间 > 指源库到异步备库的归档延时发送时间,单位为分钟,取值范围 0~1440,缺省为 0,表示不启用归档延时发送功能。仅异步归档有效。如果源库是 DSC 集群,建议用户配置时保证各节点上配置的值是一致的,并保证各节点所在机器的时钟一致,避免控制节点发生切换后计算出的归档延时发送时间不一致;
- < 同步备库的异步恢复时间间隔 > 指主库向同步备库发起异步恢复的时间间隔。单位秒,取值范围 1~86400,缺省为 1,表示主库每隔 1 秒检查一次同步备库的归档状态,若为 Invalid 且和同步备库通信正常,则发起异步恢复;
- < 归档合并刷盘缓存大小 > 整数值,单位为 MB,取值范围 0~128,若设为 0,表示不使用归档合并刷盘。
图例
数据库修改语句

修改数据库子句(alter_db_clause)

文件说明项(file_item)

归档配置语句(archive_configure_clause)

归档类型(arch_type)

文件和空间限制设置(file_space)

语句功能
供具有 DBA 和具有 ALTER DATABASE 权限的用户修改数据库。
使用说明
- 归档的配置也可以通过 DM.INI 参数 ARCH_INI 和归档配置文件 DMARCH.INI 进行,可参看《DM8 系统管理员手册》,SQL 语句提供了在 DM 服务器运行时对归档配置进行动态修改的手段,通过 SQL 语句修改成功后会将相关配置写入 DMARCH.INI 中;
- 修改日志文件大小时,只能增加文件的大小,否则失败;
- ADD NODE LOGFILE 用于 DMDSC 集群扩展节点时使用;
- 只有 MOUNT 状态 NORMAL 模式下才能启用/关闭归档或者重命名归档日志文件;
- 针对 REMOTE 归档,仅允许在 MOUNT 状态 NORMAL 模式下进行添加、修改或删除;
- 针对 LOCAL 归档,仅允许在 MOUNT 状态 NORMAL 模式进行添加和修改,不允许删除本地归档。其中,< 文件和空间限制设置 > 中 SPACE_LIMIT 和 FILE_SIZE 两项,在 MOUNT 状态 NORMAL 模式或 OPEN 状态下均可被修改;
- 针对 REALTIME/TIMELY 归档,在 MOUNT 状态 NORMAL 模式或 OPEN 状态下均可进行添加或删除,但仅允许在 MOUNT 状态 NORMAL 模式下修改 WAIT_APPLY 配置项;
- ARCHIVELOG CURRENT 把新生成的,还未归档的联机日志都进行归档;
- 本地归档仅支持修改 space_limit/file_size 配置项值;
- 非归档模式下,不允许添加、修改或删除任何归档配置;
- 目前支持的归档配置中,INCOMING_PATH、ARCH_FLUSH_BUF_SIZE、HANG_FLAG、ARCH_TIMER_NAME、WAIT_APPLY 仅允许在 MOUNT 状态下修改;
- DMDSC 数据守护环境中,删除 REALTIME/TIMELY 归档前,需要先连接 DMDSC 主库中任一有效节点执行 ALTER DATABASE SUSPEND,将 DMDSC 主库挂起,然后依次连接 DMDSC 主库每个节点执行 SP_SET_ARCH_STATUS 使待删除的归档失效,之后再依次连接 DMDSC 主库各节点执行 ALTER DATABASE OPEN 开启各节点,最后数据守护环境中的主库和备库才能执行 ALTER DATABASE DELETE 语句删除 REALTIME/TIMELY 归档。
举例说明
假设数据库 BOOKSHOP 页面大小为 8K,数据文件存放路径为 C:DMDBMSdata。
例 1 给数据库增加一个日志文件 C:DMDBMSdatadmlog_0.log,其大小为 200M。
讯享网
例 2 扩展数据库中的日志文件 C:DMDBMSdatadmlog_0.log,使其大小增大为 300M。
例 3 重命名日志文件 C:DMDBMSdatadmlog_0.log 为 d:dmlog_1.log。
讯享网
例 4 设置数据库为 MOUNT 状态 NORMAL 模式,并开启归档模式。
例 5 增加本地归档配置,归档目录为 c:arch_local,文件大小为 128MB,空间限制为 1024MB。需要保证当前数据库处于 MOUNT 状态、NORMAL 模式以及归档模式下。
讯享网
例 6 增加一个实时归档配置,远程服务实例名为 realtime,需事先配置 mal。
例 7 增加一个异步归档配置,远程服务实例名为 asyn1,定时器名为 timer1,需事先配置好 mal 和 timer。timer 可以通过 SP_ADD_TIMER 等定时器管理相关的函数进行动态配置。
讯享网
例 8 增加一个异步归档配置,远程服务实例名为 asyn2,定时器名为 timer2,源库到异步备库的归档延时发送时间为 10 分钟,需事先配置好 mal 和 timer。timer 可以通过 SP_ADD_TIMER 等定时器管理相关的函数进行动态配置。
例 9 设置数据库状态为 OPEN。
讯享网
例 10 设置数据库模式为 PRIMARY。
例 11 设置数据库模式为 STANDBY。
讯享网
在数据库中创建新的用户,DM 中直接用 USER 与数据库服务器建立连接。
语法格式
参数
- <用户名> 指明要创建的用户名称,用户名称最大长度 128 字节;
- <参数设置> 用于限制用户对 DM 数据库服务器系统资源的使用;
- 系统在创建用户时,必须指定一种身份验证模式:< 数据库身份验证模式 > 或者 < 外部身份验证模式 >。
< 数据库身份验证模式 > 中如果缺省了 < 散列选项 >,则采用 HASH WITH SHA512 NO SALT。系统用户(SYSDBA、SYSAUDITOR、SYSSSO、SYSDBO)均采用 HASH WITH SHA512 NO SALT 方式。如果 MANAGER 登录时勾选了“保存口令(S)”,这个口令保存在客户端则采用 HASH WITH AES256 NO SALT 方式。< 加盐选项 > 缺省为 NO SALT。
< 外部身份验证模式 > 支持 LDAP 身份验证、SSL 身份验证和 KERBEROS 身份验证。外部身份验证功能仅在安全版本中提供支持,具体请参考《DM8 安全管理》2.3 节。
- <口令策略> 可以为以下值,或其任何组合:
0 无限制。但总长度不得超过 48 个字节;
1 禁止与用户名相同;
2 口令长度需大于等于 INI 参数 PWD_MIN_LEN 设置的值;
4 至少包含一个大写字母(A-Z);
8 至少包含一个数字(0-9);
16 至少包含一个标点符号(英文输入法状态下,除“ 和空格外的所有符号)。
若为其他数字,则表示以上设置值的和,如 3=1+2,表示同时启用第 1 项和第 2 项策略。若不指定 PASSWORD_POLICY < 口令策略 >,则默认采用 INI 参数 PWD_POLICY 所设值;
- < 存储加密密钥 > 用于与半透明加密配合使用,缺省情况下系统自动生成一个密钥,半透明加密时用户仅能查看到自己插入的数据;
- < 只读标志 > 表示该登录是否只能对数据库进行只读操作,缺省为可读写。用户改为只读/非只读后,用户需要重新登录,会话才生效;
- < 资源设置项 > 的各参数设置说明见下表:
单位由 INI 参数 RESOURCE_FLAG 决定。RESOURCE_FLAG 取值 1、0 时,CONNECT_TIME 单位分别为秒、分钟。RESOURCE_FLAG 缺省值为 0 当 RESOURCE_FLAG 取值 1、0 时,缺省值分别为 86400 秒、1440 分钟 1 无限制 CONNECT_IDLE_TIME 会话最大空闲时间。
单位由 INI 参数 RESOURCE_FLAG 决定。RESOURCE_FLAG 取值 1、0 时,CONNECT_IDLE_TIME 单位分别为秒、分钟。RESOURCE_FLAG 缺省值为 0 当 RESOURCE_FLAG 取值 1、0 时,缺省值分别为 86400 秒、1440 分钟 1 无限制 FAILED_LOGIN_ATTEMPTS 将引起一个账户被锁定的连续注册失败的次数 100 1 3 CPU_PER_SESSION 一个会话允许使用的 CPU 时间上限(单位:秒) (365 天) 1 无限制 CPU_PER_CALL 用户的一个请求能够使用的 CPU 时间上限(单位:秒) 86400(1 天) 1 无限制 READ_PER_SESSION 会话能够读取的总数据页数上限 1 无限制 READ_PER_CALL 每个请求能够读取的数据页数 1 无限制 MEM_SPACE 会话占有的私有内存空间上限(单位:MB) 1 无限制 PASSWORD_LIFE_TIME 一个口令在其终止前可以使用的天数 365 1 无限制 PASSWORD_REUSE_TIME 一个口令在可以重新使用前必须经过的天数 365 1 无限制 PASSWORD_REUSE_MAX 一个口令在可以重新使用前必须改变的次数 32768 1 无限制 PASSWORD_LOCK_TIME 如果超过 FAILED_LOGIN_ATTEMPTS 设置值,一个账户将被锁定的分钟数 1440(1 天) 1 1 PASSWORD_GRACE_TIME 以天为单位的口令过期宽限时间,过期口令超过该期限后,禁止执行除修改口令以外的其他操作 30 1 10
- < 密码过期子句 > 用于设置密码过期。密码过期可使用 ALTER USER 语句进行重设。< 密码过期子句 > 也可以和 PASSWORD_LIFE_TIME 搭配使用;
- 允许 IP 和禁止 IP 用于控制此登录是否可以从某个 IP 访问数据库,其中禁止 IP 优先。在设置 IP 时,可以利用*来设置网段,如 192.168.0.*。设置的允许和禁止 IP 需要用双引号括起来;
- 允许时间段和禁止时间段用于控制此登录是否可以在某个时间段访问数据库,其中禁止时间段优先。设置的时间段中的日期和时间要分别用双引号括起来。在设置时间段时,有两种方式:
1)具体时间段,如 2016 年 1 月 1 日 8:30 至 2006 年 2 月 1 日 17:00;
2)规则时间段,如 每周一 8:30 至 每周五 17:00。
- 默认用户表空间 <TABLESPACE 子句 > 和默认索引表空间 <INDEX_TABLESPACE 子句 > 不能使用 SYSTEM、RLOG、ROLL、TEMP 表空间;
- < 表空间配额子句 > 用于设置用户对表空间的使用空间大小限制。QUOTA UNLIMITED 表示用户对所有表空间均无配额限制,缺省为 QUOTA UNLIMITED。QUOTA 0 表示用户对所有表空间的配额均为 0。允许指定 < 表空间名 > 来设置用户对特定表空间的配额大小,配额上限为 100T,< 空间大小 > 的默认单位为字节。
图例
用户定义语句
数据库身份验证模式(database_auth_clause)

散列选项(hash_cipher)

外部身份验证模式(externally_auth_clause)

资源设置(set_resource)
时间项(time_item)
表空间配额子句(tablespace_quota_clause)
语句功能
创建新的用户。创建用户的操作一般只能由系统预设用户 SYSDBA、SYSSSO、SYSAUDITOR 和 SYSDBO 完成,如果普通用户需要创建用户,必须具有 CREATE USER 的数据库权限。
使用说明
- 用户名在服务器中必须唯一。如果用户名已存在则报错,若指定 IF NOT EXISTS 关键字,用户名已存在不报错,忽略本次用户创建操作;
- 系统为一个用户存储的信息主要有:用户名、口令、资源限制;
- 用户口令以密文形式存储;
- 如果没有指定用户默认表空间,则系统指定 MAIN 表空间为用户的默认表空间;
- 如果没有指定用户默认索引表空间,则 HUGE 表的索引缺省存储在用户的默认表空间中,普通表的索引缺省存储在表的聚集索引所在的表空间中。临时表的索引永远在 TEMP 表空间;
- 系统预先设置了四个用户,分别为 SYSDBA、SYSAUDITOR、SYSSSO 和 SYSDBO,其中 SYSDBO 用户仅四权分立下支持。各预设用户拥有的具体权限请参考《DM8 安全管理》;
- < 资源限制子句 > 使用 DROP PROFILE 删除关联的 profile 文件;使用 PROFILE <profile 名 > 指定关联的 profile 文件;使用 LIMIT < 资源设置 > 直接设置资源设置项。关联 profile 文件后的用户,资源设置项由关联的 profile 文件统一管理配置,无法再通过使用 LIMIT < 资源设置 > 直接设置资源设置项。直到通过修改用户指定 DROP PROFILE 解除关联或关联的 PROFILE 被级联删除之后,才可以使用 LIMIT < 资源设置 > 设置;
- < 表空间配额子句 > 不支持对系统表空间、临时表空间、回滚表空间设置配额;不支持对安全用户、审计用户设置配额。
举例说明
例 1 创建用户名为 BOOKSHOP_USER、口令为 BOOKSHOP_PASSWORD、会话超时为 30 分钟的用户。
讯享网
例 2 设置创建 user1,设置密码为过期。需进行重设才能使用。
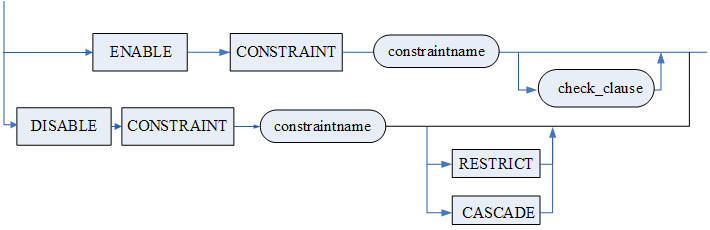
修改数据库中的用户。
语法格式
讯享网
参数
用户代理功能子句用于赋予用户 B 能够以代理的身份认证登录用户 A 的权限,即 CONNECT THROUGH 权限。其中,用户 B 表示参数 < 代理用户名 > 指定的用户,用户 A 表示参数 < 用户名 > 指定的用户。关键字 GRANT 表示赋予权限,关键字 REVOKE 表示收回权限。
同用户定义语句的参数规定一样。
图例
用户修改语句
修改用户子句(alter_user_clause)
用户代理功能子句(user_agency_clause)
语句功能
修改用户。SYSDBA、SYSSSO、SYSAUDITOR 和 SYSDBO 可以无条件修改同类型的用户的信息。普通用户如果想修改自己和其他用户信息,必须具有 ALTER USER 数据库权限。
使用说明
- 每个用户均可修改自身的口令,SYSDBA 用户可强制修改所有其他用户的口令(在数据库验证方式下);
- 只有具备 ALTER USER 权限的用户才能修改其身份验证模式、系统角色及资源限制项;
- 不论 DM.INI 的 DDL_AUTO_COMMIT 设置为自动提交还是非自动提交,ALTER USER 操作都会被自动提交;
- 修改用户口令时,口令策略应符合创建该用户时指定的口令策略;
- 不能修改系统固定用户的系统角色;
- 不能修改系统固定用户为只读;
- REPLACE < 口令 > 用于在修改数据库身份验证模式下的用户口令时, 指定用户原始口令,与 INI 参数 PASSWORD_VERIFICATION 有关,该参数缺省为 0。当 INI 参数 PASSWORD_VERIFICATION 为 1 时,用户修改自己的口令时必须指定 REPLACE 语句,并且在指定后,会校验原口令正确性,如果原始口令校验不通过则无法修改用户口令;拥有修改当前用户权限的其他用户在修改当前用户口令时可以不指定 REPLACE 子句,指定时不会校验原始口令。当 INI 参数 PASSWORD_VERIFICATION 为 0 时,可选择是否指定 REPLACE 子句;若用户修改自己的口令时指定了 REPLACE 子句,会校验原始口令的正确性;
- <SCHEMA 子句>用于设置用户的缺省模式;
- 针对用户 B 以代理的身份认证登录用户 A 的权限,即 CONNECT THROUGH 权限,需注意:
1) 只有拥有 DBA 角色权限的用户(DBA/DB_POLICY_ADMIN/DB_AUDIT_ADMIN/DB_OBJECT_ADMIN)才能赋予用户 B 该权限;
2) 只有赋予用户 B 以 CONNECT THROUGH 权限后,用户 B 才能以代理的身份认证登录用户 A;
3) 用户 A、B 可以为 SYSDBA 用户,且用户 A、B 可以为同一用户;
4) 如果用户 A 或用户 B 不存在,则报错;
5) 用户 A、B 类型(普通/安全/审计/OBJECT)必须相同,否则报错;
6) 系统表 SYSGRANTS 中查不到 CONNECT THROUGH 权限;
7) 无法对三权分立和四权分立的角色设置 CONNECT THROUGH 权限;
8) CONNECT THROUGH 权限无法和用户其他属性(如口令策略)同时设置。
- < 资源限制子句 > 使用 DROP PROFILE 删除关联的 profile 文件;使用 PROFILE <profile 名 > 指定关联的 profile 文件;使用 LIMIT < 资源设置 > 直接设置资源设置项,此处只需要设置要修改的设置项即可,其他设置项值保持不变;
- < 密码过期子句 > 用于设置密码过期;
- < 表空间配额子句 > 新修改的配额限制不会影响用户已经使用的表空间;若用户拥有 UNLIMITED TABLESPACE 权限,则对该用户指定 < 表空间配额子句 > 无效,该用户始终对所有表空间均无配额限制;
- 其他参数的取值、意义与 CREATE USER 中的要求一样。
举例说明
例 1 修改用户 BOOKSHOP_USER,会话空闲期为无限制,最大连接数为 10。
例 2 赋予用户 USER2 代理权限,使用户 USER2 可以认证登录用户 USER1。
讯享网
删除用户。
语法格式
参数
<用户名> 指明被删除的用户。
图例
用户删除语句

语句功能
删除指定用户。删除用户的操作一般由 SYSDBA、SYSSSO、SYSAUDITOR 和 SYSDBO 完成,他们可以删除同类型的其他用户。普通用户要删除其他用户,必须具有 DROP USER 权限。
使用说明
1.系统自动创建的四个系统用户 SYSDBA、SYSAUDITOR、SYSSSO 和 SYSDBO 不能被删除;
2.具有 DROP USER 权限的用户即可进行删除用户操作;
3.执行此语句将导致 DM 删除数据库中该用户建立的所有对象,且不可恢复。如果要保存这些实体,请参考 REVOKE 语句;
4.删除不存在的用户会报错。若指定 IF EXISTS 关键字,删除不存在的用户,不会报错;
5.如果未使用 CASCADE 选项,若该用户建立了数据库对象(如表、视图、过程或函数),或其他用户对象引用了该用户的对象,或在该用户的表上存在其它用户建立的视图,DM 将返回错误信息,而不删除此用户;
6.如果使用了 CASCADE 选项,除数据库中该用户及其创建的所有对象被删除外,如果其他用户创建的表引用了该用户表上的主关键字或唯一关键字,或者在该表上创建了视图,DM 还将自动删除相应的引用完整性约束及视图依赖关系;
7.正在使用中的用户可以被删除,删除后重登录或者做操作会报错。
举例说明
例 删除用户 BOOKSHOP_USER。
讯享网
模式定义语句创建一个架构,并且可以在概念上将其看作是包含表、视图和权限定义的对象。在 DM 中,一个用户可以创建多个模式,一个模式中的对象(表、视图)可以被多个用户使用。
系统为每一个用户自动建立了一个与用户名同名的模式作为默认模式,用户还可以用模式定义语句建立其它模式。
语法格式
参数
- <模式名> 指明要创建的模式的名字,最大长度 128 字节;
- <基表定义> 建表语句;
- <域定义> 域定义语句;
- <基表修改> 基表修改语句;
- <索引定义> 索引定义语句;
- <视图定义> 建视图语句;
- <序列定义> 建序列语句;
- <存储过程定义> 存储过程定义语句;
- <存储函数定义> 存储函数定义语句;
- <触发器定义> 建触发器语句;
- <特权定义> 授权语句;
- <全文索引定义> 全文索引定义语句;
- <同义词定义> 同义词定义语句;
- <包定义> 包定义语句;
- <包体定义> 包体定义语句;
- <类定义> 类定义语句;
- <类体定义> 类体定义语句;
- <外部链接定义> 外部链接定义语句;
- <物化视图定义> 物化视图定义语句;
- <物化视图日志定义> 物化视图日志定义语句;
- <注释定义> 注释定义语句。
图例
模式定义语句

sch_def_clause1

sch_def_clause2

ddl_grant_clause:略
语句功能
供具有 DBA 角色(三权分立)、DB_OBJECT_ADMIN 角色(四权分立)或具有 CREATE SCHEMA 或 CREATE ANY SCHEMA 权限的用户在指定数据库中定义模式。
使用说明
- 在创建新的模式时,如果此模式所属用户下已存在同名的模式,那么创建模式的操作会被跳过,而如果后续还有 DDL 子句,根据权限判断是否可在已存在模式上执行这些 DDL 操作;
- AUTHORIZATION < 用户名 > 指定拥有该模式的用户。缺省为 SYSDBA。创建者为 SYSDBA 用户才可以使用此选项。非 DBA 用户(普通用户)不能使用该选项创建其他用户拥有的模式;
- 使用 sch_def_clause2 创建模式时,模式名与用户名相同;
- 使用该语句的用户必须具有 DBA 或 CREATE SCHEMA 权限;
- DM 使用 DMSQL 程序模式执行创建模式语句,因此创建模式语句中的标识符不能使用系统的保留字;
- 定义模式时,用户可以用单条语句同时建多个表、视图,同时进行多项授权;
- 模式一旦定义,该用户所建基表、视图等均属该模式,其它用户访问该用户所建立的基表、视图等均需在表名、视图名前冠以模式名;而建表者访问自己当前模式所建表、视图时模式名可省;若没有指定当前模式,系统自动以当前用户名作为模式名;
- 模式定义语句中的基表修改子句只允许添加表约束;
- 模式定义语句中的索引定义子句不能定义聚集索引;
- 模式未定义之前,其它用户访问该用户所建的基表、视图等均需在表名前冠以建表者名;
- 模式定义语句不允许与其它 SQL 语句一起执行;
- 在 DIsql 中使用该语句必须以“/”结束。
举例说明
例 用户 SYSDBA 创建模式 SCHEMA1,建立的模式属于 SYSDBA。
讯享网
设置当前模式。
语法格式
图例
设置当前模式语句
语句功能
供具有 DBA 权限的用户设置当前模式语句。
举例说明
例 SYSDBA 用户将当前的模式从 SYSDBA 换到 SALES 模式。
讯享网
在 DM 系统中,允许用户删除整个模式。
语法格式
参数
<模式名> 指要删除的模式名。
图例
模式删除语句

语句功能
供具有 DBA 角色(三权分立)或 DROP ANY SCHEMA 权限的用户修改表空间。
使用说明
- 删除不存在的模式会报错。若指定 IF EXISTS 关键字,删除不存在的模式,不会报错;
- 用该语句的用户必须具有 DBA 权限或是该模式的所有者;
- 如果使用 RESTRICT 选项,只有当模式为空时删除才能成功,否则,当模式中存在数据库对象时则删除失败。默认选项为 RESTRICT 选项;
- 如果使用 CASCADE 选项,则将整个模式、模式中的对象,以及与该模式相关的依赖关系都删除。
举例说明
例 以 SYSDBA 身份登录数据库后,删除 BOOKSHOP 库中模式 SCHEMA1。
讯享网
创建表空间。
DM 数据库中的表空间可以分为普通表空间和混合表空间。使用 <HUGE 路径子句 > 创建的表空间为混合表空间,未使用 <HUGE 路径子句 > 创建的表空间即为普通表空间。普通表空间只能存储普通表(非 HUGE 表);而混合表空间既可以存储普通表又可以存储 HUGE 表。
语法格式
参数
- <表空间名> 表空间的名称,最大长度 128 字节;
- <文件路径> 指明新生成的数据文件在操作系统下的路径 + 新数据文件名。数据文件的存放路径符合 DM 安装路径的规则,若指定目录不存在则自动创建相应目录。若路径是相对路径,仅支持路径起始位置的当前目录的相对路径“https://eco.dameng.com/document/dm/zh-cn/pm/”。例如:支持“https://eco.dameng.com/document/dm/zh-cn/pm/data/TS.DBF”,不支持“https://eco.dameng.com/document/dm/zh-cn/data/TS.DBF”、“/https://eco.dameng.com/document/dm/zh-cn/pm/TS.DBF”等;
- MIRROR 数据文件镜像,用于在数据文件出现损坏时替代数据文件进行服务;MIRROR 数据文件的<文件路径>必须是绝对路径。要使用数据文件镜像,必须在建库时开启页校验的参数 PAGE_CHECK;
- <文件大小> 整数值,指明新增数据文件的大小,单位 MB,取值范围 4096*页大小~*页大小;
- < 每次扩展大小子句 > 指明数据库文件每次扩展的大小,单位 MB,取值范围为 1~2048。如果不指定此子句,数据库文件也会自动扩展,每次扩展的大小由 INI 参数 TS_AUTO_EXTEND_SIZE 控制;
- < 最大大小子句 > 指明数据库文件的最大大小,单位 MB,如果不指定此子句,则为无限制;
- <缓冲池名> 系统数据页缓冲池名 NORMAL 或 KEEP。缓冲池名 KEEP 是 DM 的保留关键字,使用时必须加双引号;
- <加密算法> 可以是系统内置的加密算法也可以是第三方加密算法,详情请参考手册《DM8 安全管理》;
- <加密密码> 必须满足长度大于等于 9,同时不超过 32,且包含大写、小写、数字。若未指定,由 DM 随机生成。
< 加密密码密文 > 提供一种创建和现有的加密表/表空间一样密钥的表/表空间的语法,和 WRAPPED 关键词搭配使用。加密密码密文可通过查看现有的加密表/表空间定义语句获取。例如:select dbms_metadata.get_ddl('TABLESPACE','TS03');查看到的 CREATE TABLESPACE "TS03" DATAFILE '/data/sdb/DAMENG/ts03.dbf' SIZE 32 AUTOEXTEND ON NEXT 0 MAXSIZE CACHE = "NORMAL" ENCRYPT WITH OPENSSL_SM4_OFB_V1 BY WRAPPED '0xDEFBACCB9F0D15FBC138B3D55E83D2A72BEF40D0B4719BA90456BACB7A225BE040AB4FCF84E36BD58C30C' COPY 0 MICRO WITH HUGE PATH '/data/sdb/DAMENG/ts03' MICRO;。则'0xDEFBACCB9F0D15FBC138B3D55E83D2A72BEF40D0B4719BA90456BACB7A225BE040AB4FCF84E36BD58C30C'即为加密密码密文。
- <HUGE 路径子句 > 用于创建一个混合表空间。HUGE 数据文件存储在 <HUGE 路径子句 > 指定的路径中,普通(非 HUGE)数据文件存储在 < 数据文件子句 > 指定的路径中。
- <STORAGE 子句 > DMDPC 专用,对单节点如果使用了 <STORAGE 子句 > 会直接忽略。通过 <RAFT 组名 > 或 <BP 组名 > 指定一个 RAFT 组作为表空间的存储位置。RAFT 组名或 BP 组名必须是已存在的组名。< 表空间名 >、<RAFT 组名 > 、 <BP 组名 > 三者不能同名。若指定的是 <RAFT 组名 >,则为明确指定 RAFT 组名。若指定的是 <BP 组名 >,则系统会从指定的 BP 组中随机挑选一个 RAFT 组。如果 <STORAGE 子句 > 缺省,即 <RAFT 组名 > 和 <BP 组名 > 均未指定,则系统会从现有的 BP RAFT 组中随机挑选一个作为表空间的存储位置。
图例
表空间定义语句
file_item
autoextend_clause

cache_clause

encrypt_clause

HUGE 路径子句

storage 子句
语句功能
供具有 DBA 角色 或具有 CREATE TABLESPACE 权限的用户定义表空间。
使用说明
- 表空间名在数据库中必须唯一。如果表空间名已存在则报错。若指定 IF NOT EXISTS 关键字,表空间名已存在不报错,忽略本次表空间创建操作;
- 一个表空间中,数据文件和镜像文件一起不能超过 256 个;
- 如果全库已经加密,就不再支持表空间加密;
- SYSTEM 表空间、TEMP 表空间不允许关闭自动扩展。
举例说明
例 以 SYSDBA 身份登录数据库后,创建表空间 TS1,指定数据文件 TS1.dbf,大小 128M。
讯享网
修改表空间。
语法格式
参数
- <表空间名> 表空间的名称;
- ONLINE|OFFLINE|CORRUPT 表示表空间的状态。ONLINE 为联机状态,ONLINE 时才允许用户访问该表空间中的数据;OFFLINE 为脱机状态, OFFLINE 时不允许访问该表空间中的数据;CORRUPT 为损坏状态,当表空间处于 CORRUPT 状态时,只有被还原恢复后才能提供服务,否则不能使用只能删除。三种状态的相互转换情况:ONLINE<->OFFLINE->CORRUPT;
- <文件路径> 指明数据文件在操作系统下的路径 + 新数据文件名。数据文件的存放路径符合 DM 安装路径的规则,且该路径必须是已经存在的;
- <文件大小> 整数值,指明新增数据文件的大小,单位 MB;
- ON RAFT_NAME 仅在 DPC 环境下有效,非 DPC 环境下直接忽略指定的 RAFT_NAME;且 DPC 环境下,若修改非临时表空间时指定了 RAFT_NAME,也直接忽略。DPC 环境下连接 SP/BS 时,可指定修改单个节点所在的 RAFT(包括 SP/MP/BP/BS)临时表空间文件的大小,不指定时则广播修改除 MP 以外的 RAFT 临时表空间文件的大小;直连 MP 时无论是否指定 RAFT,都只修改 MP 本地临时文件大小;
- <缓冲池名> 系统数据页缓冲池名 NORMAL 或 KEEP;
- < 增加 HUGE 路径子句 > 增加一个 HUGE 数据文件路径。最多可添加 127 个 HUGE 数据文件路径;
- < 删除表空间文件 > 删除表空间中某一路径对应的数据文件。删除的前提条件为:表空间必须处于 ONLINE 状态;数据库必须处于 OPEN 状态;不支持 SYSTEM、回滚表空间及联机日志;不能删除表空间中 0 号文件或表空间中唯一文件;必须先删除最大文件 ID 的文件;执行文件删除前必须删除从该文件分配了簇的数据库对象;
- < 缩减表空间大小 > 将表空间中某一路径对应的数据文件缩减到一个更小的体积。缩减的前提条件为:表空间必须处于 ONLINE 状态;数据库必须处于 OPEN 状态。另外,不支持缩减联机日志;只有当指定偏移之后的簇被释放后截断操作才能执行,因而操作并不总是能够截断到指定偏移;
- < 数据文件重命名子句 >:源文件路径无要求,对于 TO 后的目标文件路径,若路径是相对路径,仅支持路径起始位置的当前目录的相对路径“https://eco.dameng.com/document/dm/zh-cn/pm/”。例如:支持“https://eco.dameng.com/document/dm/zh-cn/pm/data/TS.DBF”,不支持“https://eco.dameng.com/document/dm/zh-cn/data/TS.DBF”、“/https://eco.dameng.com/document/dm/zh-cn/pm/TS.DBF”等。
图例
修改表空间语句

file_item
autoextend_clause
语句功能
供具有 DBA 角色或 ALTER TABLESPACE 权限的用户修改表空间。
使用说明
- 不论 DM.INI 的 DDL_AUTO_COMMIT 设置为自动提交还是非自动提交,ALTER TABLESPACE 操作都会被自动提交;
- SYSTEM 表空间、TEMP 表空间不允许关闭自动扩展。
- 如果表空间有未提交事务时,表空间不能修改为 OFFLINE 状态;
- 重命名表空间数据文件时,表空间必须处于 OFFLINE 状态,修改成功后再将表空间修改为 ONLINE 状态;
- 表空间如果发生损坏(表空间还原失败,或者数据文件丢失或损坏)的情况下,允许将表空间切换为 CORRUPT 状态,并删除损坏的表空间,如果表空间上定义有对象,需要先将所有对象删除,再删除表空间;
- DSC 集群表空间负载均衡子句用于在 DSC 集群环境中进行基于表空间的负载均衡设置,可指定优化节点号,当 INI 参数 DSC_TABLESPACE_BALANCE 为 1 时,符合条件的查询语句会被自动重连至 <DSC 集群节点号 > 指定的节点执行,从而实现负载均衡。当指定的 <DSC 集群节点号 > 为非法节点号时,此表空间的优化节点失效;
- 对普通表空间使用 < 增加 HUGE 路径子句 >,可将普通表空间升级为混合表空间;对混合表空间使用 < 增加 HUGE 路径子句 >,可为混合表空间添加新的 HUGE 数据文件路径。
举例说明
例 1 将表空间 TS1 名字修改为 TS2。
讯享网
例 2 增加一个路径为 d:TS1_1.dbf,大小为 128M 的数据文件到表空间 TS1。
例 3 修改表空间 TS1 中数据文件 d:TS1.dbf 的大小为 200M。
讯享网
例 4 重命名表空间 TS1 的数据文件 d:TS1.dbf 为 e:TS1_0.dbf。
例 5 修改表空间 TS1 的数据文件 d:TS1.dbf 自动扩展属性为每次扩展 10M,最大文件大小为 1G。
讯享网
例 6 修改表空间 TS1 缓冲池名字为 KEEP。
例 7 修改表空间为 CORRUPT 状态,注意只有在表空间处于 OFFLINE 状态或表空间损坏的情况下才允许使用。
讯享网
例 8 为表空间 TS1 添加 HUGE 数据文件路径
删除表空间。
语法格式
讯享网
参数
<表空间名> 所要删除的表空间的名称。
图例
表空间删除语句

语句功能
供具有 DBA 角色或 DROP TABLESPACE 权限的用户删除表空间。
使用说明
- 删除不存在的表空间会报错。若指定 IF EXISTS 关键字,删除不存在的表空间,不会报错;
- SYSTEM、RLOG、ROLL 和 TEMP 表空间不允许删除;
- 系统处于 SUSPEND 或 MOUNT 状态时不允许删除表空间,系统只有处于 OPEN 状态下才允许删除表空间。
举例说明
例 以 SYSDBA 身份登录数据库后,删除表空间 TS1。
表空间恢复失效文件的检查。
语法格式
讯享网
语句功能
在 LINUX 操作系统下,检查是否有数据文件被删除。
使用说明
该过程只在 LINUX 下有效。
举例说明
表空间恢复失效文件的准备。
语法格式
讯享网
语句功能
在 LINUX 操作系统下,如果出现了正在使用数据文件被删除的情况,该过程完成失效文件恢复的准备工作。
使用说明
该过程只在 LINUX 下有效。
举例说明
表空间失效文件的恢复。
语法格式
讯享网
语句功能
在 LINUX 操作系统下,如果出现了正在使用数据文件被删除的情况,在调用了恢复准备的 SP_TABLESPACE_PREPARE_RECOVER 及在 OS 系统内完成了数据文件的复制后,调用该过程完成文件的恢复工作。表空间失效文件恢复的详细步骤可参考《DM8 系统管理员手册》。
使用说明
- 该过程只在 LINUX 下有效;
- 在 SP_TABLESPACE_PREPARE_RECOVER 及在 OS 系统内完成了数据文件的复制后调用。
举例说明
用户数据库建立后,就可以定义基表来保存用户数据的结构。DM 数据库的表可以分为两类,分别为数据库内部表和外部表,数据库内部表由数据库管理系统自行组织管理,而外部表在数据库的外部组织,是操作系统文件。其中内部表包括:数据库基表、HUGE 表和水平分区表。手册中如无明确说明均指数据库基表。下面分别对这各种表的创建与使用进行详细描述。
用户数据库建立后,就可以定义基表来保存用户数据的结构。需指定如下信息:
- 表名、表所属的模式名;
- 列定义;
- 完整性约束。
语法格式
讯享网
参数
- <模式名> 指明该表属于哪个模式,缺省为当前模式;
- <表名> 指明被创建的基表名,基表名最大长度 128 字节;
- <列名> 指明基表中的列名,列名最大长度 128 字节;
- < 数据类型> 指明列的数据类型;支持设置定长串的字符长度,如 char(n char),n 为在 1~32767 中的整数;当 ini 参数 NVARCHAR_LENGTH_IN_CHAR 设置为 1 时,支持 nchar 设置定长串的字符长度,此时 nchar(n)等价于 char(n char)的处理;
- <列缺省值表达式> 如果之后的 INSERT 语句省略了插入的列值,那么此项为列值指定一个缺省值,可以通过 DEFAULT 指定一个值。DEFAULT 表达式串的长度不能超过 2048 字节;对指定了 ON NULL 的列,插入数据时若数据为 NULL,则该位置数据被替换为列缺省值进行插入;
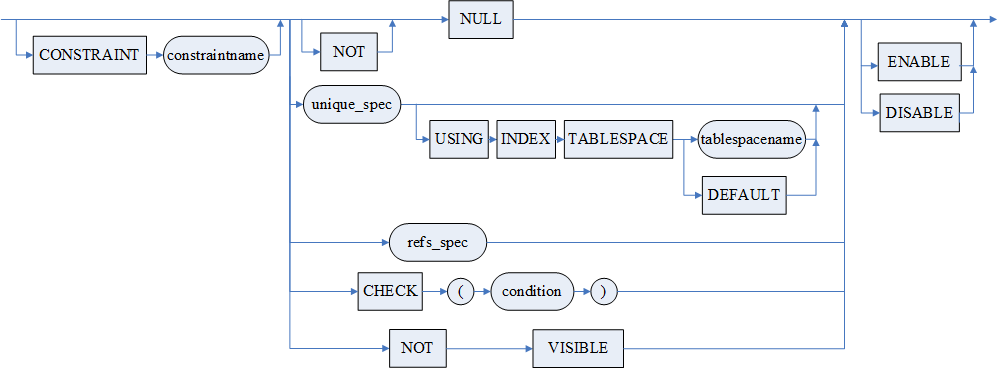
- <列级完整性约束定义> 支持同时指定多个列级完整性约束,各约束之间使用空格分隔。列级完整性约束中各个参数含义如下:
1)NULL 指明指定列可以包含空值,为缺省选项。
2)NOT NULL 非空约束,指明指定列不可以包含空值;
3)UNIQUE 唯一性约束,指明指定列作为唯一关键字;
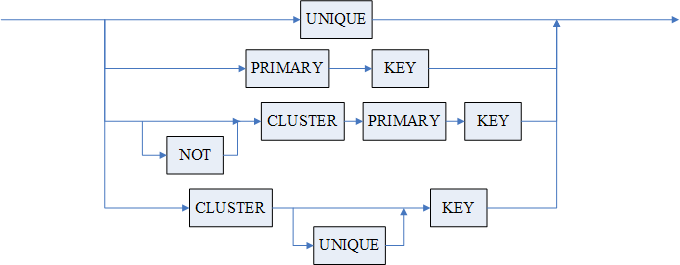
4)PRIMARY KEY 主键约束,指明指定列作为基表的主关键字,INI 参数 PK_WITH_CLUSTER 控制该约束默认为 CLUSTER 或 NOT CLUSTER;
5)CLUSTER PRIMARY KEY 主键约束,指明指定列作为基表的聚集索引(也叫聚簇索引)主关键字;
6)NOT CLUSTER PRIMARY KEY 主键约束,指明指定列作为基表的非聚集索引主关键字;
7)CLUSTER KEY 指定列为聚集索引键,但是是非唯一的;
8)CLUSTER UNIQUE KEY 指定列为聚集索引键,并且是唯一的;
9)USING INDEX TABLESPACE < 表空间名 > 指定索引存储的表空间。
缺省该子句或使用 USING INDEX TABLESPACE DEFAULT 均为缺省情况。缺省情况下,当约束使用了 CLUSTER 关键字(CLUSTER PRIMARY KEY 、CLUSTER KEY、CLUSTER UNIQUE KEY 或当 INI 参数 PK_WITH_CLUSTER=1 时的 PRIMARY KEY)时,约束将使用表聚集索引的存储表空间作为约束的缺省存储表空间;当约束未使用 CLUSTER 关键字时,约束将使用 <INDEX_TABLESPACE 子句 > 指定的默认索引表空间作为约束的缺省存储表空间,若未指定用户默认索引表空间,将使用表聚集索引的存储表空间。
10)REFERENCES 指明指定列的引用约束。引用约束要求引用对应列类型必须基本一致。所谓基本,是因为 CHAR 与 VARCHAR,BINARY 与 VARBINARY,TINYINT、SMALLINT 与 INT 在此被认为是一致的。如果有 WITH INDEX 选项,则为引用约束建立索引,否则不建立索引,通过其他内部机制保证约束正确性;
11)CHECK 检查约束,指明指定列必须满足的条件;
12)NOT VISIBLE 列不可见,当指定某列不可见时,使用 SELECT *进行查询时将不添加该列作为选择列。使用 INSERT 无显式指定列列表进行插入时,值列表不能包含隐藏列的值。
- < 失效生效选项 > 用于指定约束的状态:ENABLE 启用;DISABLE 失效。缺省为启用。
- < 表级完整性约束>中的参数:
1)UNIQUE 唯一性约束,指明指定列或列的组合作为唯一关键字;
2)PRIMARY KEY 主键约束,指明指定列或列的组合作为基表的主关键字。指明 CLUSTER,表明是主关键字上聚集索引;指明 NOT CLUSTER,表明是主关键字上非聚集索引;也可通过 INI 参数 PK_WITH_CLUSTER 控制该约束默认为 CLUSTER 或 NOT CLUSTER;
3)USING INDEX TABLESPACE <表空间名> 指定索引存储的表空间;
4)FOREIGN KEY 指明表级的引用约束,如果使用 WITH INDEX 选项,则为引用约束建立索引,否则不建立索引,通过其他内部机制保证约束正确性;
5)CHECK 检查约束,指明基表中的每一行必须满足的条件;
6)与列级约束之间不应该存在冲突。
- ON COMMIT<DELETE | PRESERVE>ROWS 用来指定临时表(TEMPORARY)中的数据是事务级或会话级的,缺省情况下是事务级。ON COMMIT DELETE ROWS:指定临时表是事务级的,每次事务提交或回滚之后,表中所有数据都被删除;ON COMMIT PRESERVE ROWS:指定临时表是会话级的,会话结束时才清空表;
- CHECK < 检验条件> 指明表中一列或多列能否接受的数据值或格式;
- <查询表达式>和<子查询> 定义请查看数据查询章节;
- STORAGE 项中:BRANCH、NOBRANCH 是堆表创建关键字,堆表为“扁平 B 树表”。这两个参数用来指定堆表并发分支 BRANCH 和非并发分支 NOBRANCH 的数目。<BRANCH 数>取值范围为 1~64,<NOBRANCH 数>取值范围为 1~64。
分支数目主要用于插入场景中。适当提高分支数量可有效地提升并发数据处理效率,但是分支过多又会增加扫描的代价,因此,合适的 <BRANCH 数 > 和 <NOBRANCH 数 > 值需用户根据实际情况来决定。<BRANCH 数 > 主要在 FLDR 导入和查询插入等并发、批量插入场景中使用;<NOBRANCH 数 > 在非并发、单行插入场景中使用。
1)NOBRANCH:指定创建的表为堆表,并发分支个数为 0,非并发分支个数为 1;
2)BRANCH(<BRANCH 数>, <NOBRANCH 数>):指定创建的表为堆表,并发分支个数为<BRANCH 数>,非并发个数为<NOBRANCH 数>;
3)BRANCH <BRANCH 数>:指定创建的表为堆表,并发分支个数为<BRANCH 数>,非并发分支个数为 0。
- CLUSTERBTR 指定创建的表为非堆表,即普通 B 树表;
- <虚拟列定义> 指明定义虚拟列的表达式;
- < 并行度 > 创建数据表时,为 TABLE 指定并行度,并行度的合法范围为 0~128;
- <高级日志子句> 指定创建日志辅助表,具体可参考 19.3.1.1 创建日志辅助表;
- <add_log 子句> 开启表的物理逻辑日志记录功能,缺省为不开启。<add_log 子句>开启时和 INI 参数 RLOG_IGNORE_TABLE_SET=1 时功能一样;
- <AUTO_INCREMENT 子句 > 用于指定隐式插入值的起始边界值,即当隐式插入时,系统自动增长的自增列值必须大于等于起始边界值。不指定默认为 1。要求大于等于 0 小于数值的最大值;
- < 表空间子句 > 不能和 <STORAGE 子句 > 中的 ON < 表空间名 > 同时使用;
- <VALIDATE 选项 > 用于约束是否检查原有数据,VALIDATE 表示启用检查,NOVALIDATE 表示不启用检查,若在 ENABLE 下缺省本选项则默认值为 VALIDATE,若在 DISABLE 下缺省本选项则默认值为 NOVALIDATE。不支持 DISABLE VALIDATE 选项。
图例
表定义语句
full_tablename

table_struct_clause1
table_struct_clause2

column_define_clause
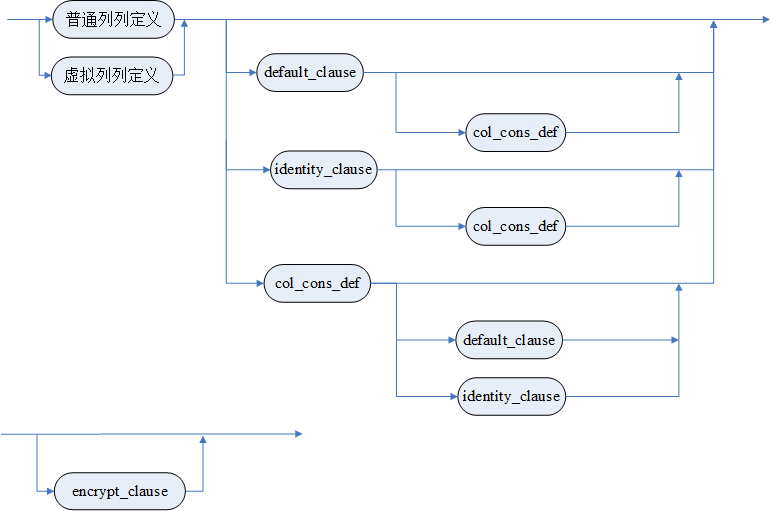
<普通列定义>

<虚拟列列定义>

default_clause

自增列子句
identity_clause

column_constraint
唯一性约束选项(unique_spec)
refs_spec
ref_action
storage 子句
storage
encrypt_clause
透明存储加密子句
透明加密用法
透明加密选项
半透明存储加密子句
散列选项(hash_cipher)
table_constraint

table_constraint_clause

属性子句
表空间子句
空间限制子句

延迟段分配子句(deferred_segment_creation_clause)
压缩子句

表并行度子句
高级日志子句(advanced_log_clause)

add_log 子句(add_log_clause)

DISTRIBUTE 子句

range_dis_act

list_dis_act

AUTO_INCREMENT 子句
不带 INTO 的 SELECT 语句
语句功能
供具有 DBA 角色(三权分立)、DB_OBJECT_ADMIN 角色(四权分立)或具有 CREATE TABLE 或 CREATE ANY TABLE 权限的用户定义基表。
使用说明
- <表名>指定了所要建立的基表名。在一个<模式>中,<基表名>、<视图名>均不相同。如果<模式名>缺省,则缺省为当前模式。若指定 TEMPORARY,则表示该表为一个临时表,只在一个会话中有效,当一个会话结束,该临时表被自动清空。表名需要是合法的标识符,且满足 SQL 语法要求。当表名以“”开头时,该表为全局临时表;
- 表名不允许使用以下字符串作为前缀:BM$_、BMJ$_、MDRT$_、MLOG$_、MTAB$_、MVIEW$_、MTRG$_、STAT$_。表名不允许使用以下字符串作为后缀:$ALOG、$AUX、$DAUX、$RAUX、$ROT、$UAUX;
- 当 ENABLE_TMP_TAB_ROLLBACK 为 0 时,不允许对临时表创建主键约束以及唯一约束;
- GLOBAL 目前仅支持 GLOBAL 临时表,因此建临时表时是否指定 GLOBAL 效果是一样的;
- 表名最大长度为 128 个字节;
- 所建基表至少要包含一个<列名>指定的列,在一个基表中,各<列名>不得相同。一张基表中至多可以包含 2048 列;
- 虚拟列上存在约束时,不支持使用 dmfldr 导入;
- <DEFAULT 子句>指定列的缺省值,如:DEFAULT DATE '2015-12-26';
- 如果未指明 NOT NULL,也未指明<DEFAULT 子句>,则隐含为 DEFAULT NULL;
- DM 提供两种自增列方式:IDENTITY 自增列和 AUTO_INCREMENT 自增列。两者不能同时指定。
- <IDENTITY 子句 > 自增列不能使用 <DEFAULT 子句 >。<IDENTITY 子句 > 的种子和增量缺省值均为 1。
- AUTO_INCREMENT 自增列。AUTO_INCREMEN 列必须为唯一性约束的部分,只支持整数类型(支持 TINYINT/SMALLINT/INT/BIGINT,不支持 dec(N, 0)等),不能违反主键的唯一性约束。
AUTO_INCREMENT 关键字需要和 <AUTO_INCREMENT 子句 >、三个 AUTO_INCREMENT 相关 INI 参数(AUTO_INCREMENT_INCREMENT,AUTO_INCREMENT_OFFSET,NO_AUTO_VALUE_ON_ZERO)一起配合使用。当表中没有 AUTO_INCREMENT 关键字时,仍然可以指定 <AUTO_INCREMENT 子句 >,但不会生效。
<AUTO_INCREMENT 子句 > 用于指定隐式插入值的起始边界值,即当隐式插入时,系统自动增长的自增列值 X 必须大于等于起始边界值。
INI 参数 AUTO_INCREMENT_INCREMENT,动态会话级,表示 AUTO_INCREMENT 的步长。取值范围 1~65535。缺省值为 1。
INI 参数 AUTO_INCREMENT_OFFSET,动态会话级,表示 AUTO_INCREMENT 的基准偏移。取值范围 1~65535。缺省值为 1。
INI 参数 NO_AUTO_VALUE_ON_ZERO,动态会话级,表示 AUTO_INCREMENT 列插入 0 时,是否自动插入自增的下一个值。取值范围 0、1。0 否,插入 0;1 是,插入自增值。缺省值为 1。
隐式生成的自增列值 X 由系统根据 AUTO_INCREMENT_OFFSET 、AUTO_INCREMENT_INCREMENT 等因子自动计算得出。首先,计算公式 X=AUTO_INCREMENT_OFFSET+n*AUTO_INCREMENT_INCREMENT,n 为满足下述两个条件的最小整数。其次,X 值需同时满足两个条件:1)大于等于起始边界值;2)大于当前自增列值中最大值(包括显式和隐式)。最后,得出下一个隐式插入值。
例如 1 号、2 号和 3 号的自增列中最大值分别为 34、39 和 22。下一个隐式插入的自增列值分别为 39、45 和 23。
- 若设置 DEFAULT ON NULL,相应列上会隐式添加 NOT NULL 约束,手动添加的约束不能与之冲突;
不能在对象类型的列上指定 DEFAULT ON NULL;
- < 列缺省值表达式>的数据类型必须与本列的<数据类型>一致。缺省值表达式存在以下几点约束:
1)仅支持只读系统函数或指定 FOR CALCULATE 创建的存储函数;
2)不支持表列;
3)不支持包变量或语句参数;
4)不支持查询表达式;
5)不支持 LIKE;
6)不支持 CONTAINS 表达式。
- 如果列定义为 NOT NULL,则当该列插入空值时会报错;
- 约束被 DM 用来对数据实施业务规则,完成对数据完整性的控制。DM_SQL 中主要定义了以下几种类型的约束:非空约束、唯一性约束、主键约束、引用约束和检查约束。如果完整性约束只涉及当前正在定义的列,则既可定义成列级完整性约束,也可以定义成表级完整性约束;如果完整性约束涉及到该基表的多个列,则只能在语句的后面定义成表级完整性约束。
定义与该表有关的列级或表级完整性约束时,可以用 CONSTRAINT<约束名>子句对约束命名,系统中相同模式下的约束名不得重复。如果不指定约束名,系统将为此约束自动命名。经定义后的完整性约束被存入系统的数据字典中,用户操作数据库时,由 DBMS 自动检查该操作是否违背这些完整性约束条件。
1)非空约束主要用于防止向一列添加空值,这就确保了该列在表中的每一行都存在一个有意义的值。
a)该约束仅用于列级;
b)如果定义了列约束为 NOT NULL,则其<列缺省值表达式>不能将该列指定为 NULL;
c)空值即为未知的值,没有大小,不可比较。除关键字列外,其列可以取空值。不可取空值的列要用 NOT NULL 进行说明。
2)唯一性约束主要用于防止一个值或一组值在表中的特定列里出现不止一次,确保数据的完整性。
a)唯一性约束是通过唯一索引来实现的。创建了一个唯一索引也就创建了一个唯一性约束;同样的,创建了一个唯一性约束,也就同时创建了一个唯一索引,这种情况下唯一索引是由系统自动创建的;
b)NULL 值是不参加唯一性约束的检查的。DM 系统允许插入多个 NULL 值。对于组合的唯一性约束,只要插入的数据中涉及到唯一性约束的列有一个或多个 NULL 值,系统则认为这笔数据不违反唯一性约束。
3)主键约束确保了表中构成主键的一列或一组列的所有值是唯一的。主键主要用于识别表中的特定行。主键约束是唯一性约束的特例。
a)可以指定多个列共同组成主键,最多支持 63 个列;
b)主键约束涉及的列必须为非空。通常情况下,DM 系统会自动在主键约束涉及的列上自动创建非空约束;
c)每个表中只能有一个主键;
d)主键约束是通过创建唯一索引来实现的。DM 系统允许用户自己定义创建主键时,通过 CLUSTER 或 NOT CLUSTER 关键字来指明创建索引的类型。CLUSTER 指明该主键是创建在聚集索引上的,NOT CLUSTER 指明该主键是创建在非聚集索引上的。在 DM.INI 配置文件中,可以指定配置项使表中的主键自动转化为聚集主键,该配置项为 PK_WITH_CLUSTER。默认情况下,PK_WITH_CLUSTER 为 0,即建表时指定的主键不会自动转化为聚集主键;若为 1,则主键自动变为聚集主键。堆表和列存储表不允许建立聚集主键。
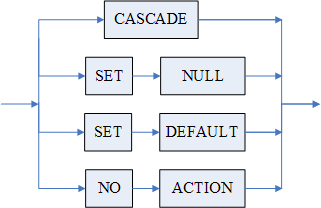
4)引用约束用于保证相关数据的完整性。引用约束中构成外键的一列或一组列,其值必须至少匹配其参照的表中的一行的一个主键或唯一键值。我们把这种数据的相关性称为引用关系,外键所在的表称为引用表,外键参照的表称为被引用表。
a)引用约束指明的被引用表上必须已经建立了相关主键或唯一索引。也就是说,必须保持引用约束所引用的数据必须是唯一的;
b)引用约束的检查规则:
i. 插入规则:外键的插入值必须匹配其被引用表的某个键值。
ii.更新规则:外键的更新值必须匹配被引用表的某个键值。当修改被引用表中的主键值时,如果定义约束时的选项是 NO ACTION,且更新结果会违反引用约束则不允许更新;如果定义的是 SET NULL 则将引用表上的相关外键值置为 NULL;如果定义的是 CASCADE,那么引用表上的相关外键值将被修改为同样的值;如里定义的是 SET DEFAULT,则把引用列置为该列的缺省值。
iii.删除规则:当从被引用表中删除一行数据时,如果定义约束时的选项是 NO ACTION,就不删除引用表上的相关外键值;如果定义的是 SET NULL 则将引用表上的相关外键值置为 NULL;如果定义的是 CASCADE,那么引用表上的相关外键值将被删除;如里定义的是 SET DEFAULT,则把每个引用列置为“< 列缺省值表达式 >”规则中所指定的缺省值。
c)NULL 值不参加引用约束的检查。受引用约束的表,如果要插入的涉及到引用约束的列值有一个或多个 NULL,则认为插入值不违反引用约束;
d)MPP 环境下,引用列和被引用列都必需包含分布列,且分布情况完全相同;
e)MPP 环境下,不支持创建 SET NULL 或 SET DEFAULT 约束检查规则的引用约束。
5)检查约束用于对将要插入的数据实施指定的检查,从而保证表中的数据都符合指定的限制。<检验条件>必须是一个有意义的布尔表达式,其中的每个列名必须是本表中定义的列,但列的类型不得为多媒体数据类型,并且不应包含子查询、集函数。
- 可以使用空间限制子句 DISKSPACE LIMIT 来限制表的最大存储空间,以 MB 为单位,取值范围为 1~,关键字 UNLIMITED 表示无限制。系统不支持查询建表情况下指定空间限制;
- 可以使用 STORAGE 子句指定表的存储信息:
- 初始簇数目:指建立表时分配的簇个数,必须为整数,最小值为 1,最大值为 256,缺省为 1;
- 下次分配簇数目:指当表空间不够时,从数据文件中分配的簇个数,必须为整数,最小值为 1,最大值为 256,缺省为 1;
- 最小保留簇数目:当删除表中的记录后,如果表使用的簇数目小于这个值,就不再释放表的空间,必须为整数,最小值为 1,最大值为 256,缺省为 1;
- 表空间名:在指定的表空间上建表,表空间必须已存在,缺省为该用户的默认表空间;
- 填充比例:指定存储数据时每个数据页和索引页的充满程度,取值范围从 0 到 100。可以通过设置 INI 参数 DEFAULT_FILLFACTOR 来设置填充比例的默认值。DEFAULT_FILLFACTOR 的取值范围为 0~100,取缺省值 0 时,等价于 100,表示全满填充。插入数据时填充比例的值越低,可由新数据使用的空间就越多;更新数据时填充比例的值越大,更新导致出现的页分裂的几率越大。同样,创建索引时,填充比例的值越低,可由新索引项使用的空间也就越多;
- BRANCH 和 NOBRANCH:指定 BRANCH 和 NOBRANCH 的个数;
- CLUSTERBTR:当 INI 参数 LIST_TABLE = 1 时,指定 CLUSTERBTR,则建立的表为普通 B 树表而非堆表;
- WITH COUNTER:在表上维护当前表内的行数;WITHOUT COUNTER:表上只维护一个非实时的大概的行数;对用户的影响:例如 SELECT COUNT(*) FROM test; 如果表 test 是 WITH COUNTER 属性,服务器直接取行数返回即可,可以快速响应;如果表 test 是 WITHOUT COUNTER 属性,服务器需要先扫描 B 树获取行数返回后才能响应。不同的场景,根据需要灵活选择 COUNTER 属性。WITH COUNTER 属性可以通过 ALTER TABLE 语句修改。若省略该选项,默认是 WITH COUNTER 属性。
- USING LONG ROW:显式开启超长记录存储功能。除此之外,还可以通过设置 INI 参数 CTAB_WITH_LONG_ROW=1 来隐式开启该功能,隐式开启需满足一定的附加条件,具体请参考《DM8 系统管理员手册》CTAB_WITH_LONG_ROW 介绍。超长记录存储功能是指当 DM 行存储的记录长度超过页大小一半时,先尝试将过长的变长字符串转换为行外 BLOB 存储,如果转换后仍超长则报错。建议变长字段定义长度不超过页大小,否则在处理排序等操作时报错。临时表、HUGE 表、外部表不支持 USING LONG ROW 选项。水平分区子表的 USING LONG ROW 选项自动采用与主表保持一致的方式,两者不同的情况下,直接忽略水平分区子表的 USING LONG ROW 选项。
- DISABLE USING LONG ROW 可以关闭 INI 参数 CTAB_WITH_LONG_ROW=1 时隐式开启的超长记录存储功能。
- < 延迟段分配子句 > 用于指定是否启用延迟段分配功能。若不启用,则在建表时为表分配数据段;若启用,则向表中插入第一条数据时为表分配数据段。SEGMENT CREATION IMMEDIATE 表示不启用,SEGMENT CREATION DEFERRED 表示启用。若不指定 < 延迟段分配子句 >,则根据 INI 参数 DEFERRED_SEGMENT_CREATION 决定是否启用延迟段分配功能。HUGE 表不支持延迟段分配功能,忽略该子句;
- < 压缩子句> 只是语法支持,功能已经取消;
- 记录的列长度总和不超过页大小的一半,变长数据类型实际是否越界还需要判断实际记录的长度,如 VARCHAR、VARBINARY 等数据类型,而定长数据类型的长度是实际数据长度,如 INT、CHAR(注意建库参数 CHAR_FIX_STORAGE 为 N/0 时,CHAR 类型转换成 VARCHAR2 类型存储)、BINARY 等数据类型。例如,若建库参数页大小为 16K、CHAR_FIX_STORAGE 为 1,可以定义 CREATE TABLE TEST(C1 VARCHAR(8000),C2 INT),但是不能定义 CREATE TABLE TEST(C1 CHAR(8000),C2 INT);;
- DM 具备自动断句功能;
- 在对列指定存储加密属性时,对用户的数据在保存到物理介质之前使用指定的加密算法加密,防止数据泄露;
- < 加密算法 > 可以是系统内置的加密算法也可以是第三方加密算法,详情请参考手册《DM8 安全管理》。当使用第三方加密算法时,用户需要将已实现的第三方加密动态库放到 bin 目录下的文件夹 external_crypto_libs 中,DM 支持加载多个第三方加密动态库,然后重启 DM 服务器即可引用其中的算法;需要注意的是:以“NOPAD”结尾的加密算法需要用户保证原始数据长度是 BLOCK_SIZE 的整数倍,DM 不会自动填充。如果数据不一定是 BLOCK_SIZE 的整数倍,请选择不以“NOPAD”结尾的加密算法,以“NOPAD”结尾的加密算法主要用于数据页分片加密。
- < 散列算法 > 用于保证用户数据的完整性,若用户数据被非法修改,则能判断该数据不合法。散列算法可以是系统内置的散列算法也可以是第三方散列算法,详情请参考手册《DM8 安全管理》。加盐选项可以与散列算法配合使用;
- < 透明存储加密子句 > 是指用透明加密的方式加密列上的数据,在数据库中保存加密该列的密钥,执行 DML 语句的过程中自动获取密钥。关于表列透明加密的具体介绍请参考手册《DM8 安全管理》;
- < 半透明存储加密子句 > 是指用半透明加密的方式加密列上的数据,DM 使用当前操作用户的存储密钥对数据进行加密,半透明加密列的密文后追加了 4 个字节的 UID,用户查询数据时,若当前会话用户 ID 与列密文数据中存储的 UID 相同,则返回明文,否则返回 NULL。关于表列半透明加密的具体介绍请参考手册《DM8 安全管理》;
- 可以使用 DISTRIBUTE 子句指定表的分布类型,创建为分布表:
- 单机模式下建的分布表和普通表一样,但是不能创建指定实例名的分布表(如范围分布表和 LIST 分布表)。
- 在 MPP 模式下建分布表,如果未指定列则默认为 RANDOMLY 分布表(随机分布表)。
- 分布列类型不支持 BLOB、CLOB、IMAGE、TEXT、LONGVARCHAR、BIT、BINARY、VARBINARY、LONGVARBINARY、时间间隔类型和用户自定义类型。
- HASH 分布、RANGE 分布、LIST 分布允许更新分布列,并支持包含大字段列的表的分布列更新,但包含 INSTEAD OF 触发器的表、堆表不允许更新分布列。
- 对于 FULLY 分布表(复制分布表),只支持单表查询的更新和删除操作,并且查询项或者条件表达式中都不能包含 ROWID 伪列表达式。
- RANGE 分布表(范围分布表)和 LIST 分布表(列表分布表),分布列与分布列值列表必须一致,并且指定的实例名不能重复。
- 随机分布表不支持 UNIQUE 索引。
- 虚拟列的使用:
虚拟列的值是不存储在磁盘上的,而是在查询的时候,根据定义的表达式临时计算后得到的结果。虚拟列可以用在查询、DML、DDL 语句中。索引可以建在虚拟列上。用户可以像使用普通列一样使用虚拟列。
- GENERATED ALWAYS 和 VIRTUAL 为可选关键字,主要用于描述虚拟列的特性,写与不写没有本质区别。
- 虚拟列中的 VISIBLE 只是语法支持,没有实际意义。
- 不支持在索引表、外部表、临时表上使用虚拟列。虚拟列和虚拟列中使用的列必须来自同一个表。表中至少要有一个非虚拟列。
- 在虚拟列上建索引相当于在表上建函数索引。
- 即使表达式中的列已经有列级安全属性,虚拟列也不会继承列的安全规则。因此,为了保护虚拟列的数据,可以复制列级安全策略或者使用函数隐式来保护虚拟列数据。例如,信用卡的卡号被列级安全策略保护,只允许员工看到卡号的后四位。在这种情况下,可以把信用卡号的后四位定义成虚拟列。
- 虚拟列不能作为分布表的分布列。
- 虚拟列之间不能嵌套定义。
- 虚拟列最后的输出应该是标量性的。
- 虚拟列不能是用户自定义类型、大字段类型。
- 不能直接插入、更新虚拟列;但是可以在更新和删除的 WHERE 子句中使用虚拟列。
- 不能删除被虚拟列引用的实际列。表中只有一个实际列时,这个实际列不能被删除。
- 虚拟列不能被修改为实际列。实际列也不能被修改为虚拟列。
- 虚拟列不能设置 DEFAULT 值。
- 虚拟列不能设置为 IDENTITY。
- 不支持在虚拟列上建立位图连接索引和全文索引。
- 不支持在虚拟列上建立位图索引和聚集索引。
- 不支持在虚拟列上建立物化视图日志。
- 虚拟列不能在创建时作为 CLUSTER PK、UNIQUE 或者 PK。但是可以在虚拟列上创建 UNIQUE INDEX。
- 虚拟列不支持 PLUS JOIN。
- 虚拟列不支持统计信息。
- 虚拟列不支持加密。
- 虚拟列的表达式定义长度不能超过 2048 字节。
- DM 支持系统内部函数,但是不能保证数据的确定性 。
- 虚拟列定义中不支持 ROW LIKE 表达式。
- 虚拟列定义中不支持 CONTAINS 表达式。
- 如果虚拟列定义包含函数,则必须是确定性的函数。不允许使用分组函数、子查询(集函数、分析函数都不允许)。
- 虚拟列上有约束时,使用 dmfldr 导入,将不能保证正确性。
- 虚拟列上创建有索引时,则该虚拟列不支持修改列数据类型和列表达式。
举例说明
例 1 首先回顾一下第二章中定义的基表,它们均是用列级完整性约束定义的格式写出,也可以将唯一性约束、引用约束和检查约束以表级完整性约束定义的格式写出的。假定用户为 SYSDBA,下面以产品的评论表为例进行说明。
系统执行建表语句后,就在数据库中建立了相应的基表,并将有关基表的定义及完整性约束条件存入数据字典中。需要说明的是,由于被引用表要在引用表之前定义,本例中的产品的信息表被产品的评论表引用,所以这里应先定义产品的信息表,再定义产品的评论表,否则就会出错。
例 2 建表时指定存储信息,表 PERSON 建立在表空间 FG_PERSON 中,初始簇大小为 5,最小保留簇数目为 5,下次分配簇数目为 2,填充比例为 85。
讯享网
例 3 在 MPP 集群环境下建立如下范围分布表后,表 PRODUCT_INVENTORY 将按照 QUANTITY 列值,被分布到 2 个站点上。
例 4 在 MPP 集群环境下建立如下列表分布表后,表 PRODUCT_INVENTORY 将按照 LOCATIONID 列值,被分布到 2 个站点上,1,2,3,4 在 EP01 上,5,6,7,8 在 EP02,如果有插入其它值时则报错。
讯享网
例 5 在 MPP 集群环境下建立如下复制分布表后,表 LOCATION 被分布到 MPP 各个站点上,每个站点上的数据都保持一致。
例 6 建立普通表查看 select count(*) 执行计划,再删除后重建表 test 带 without counter 属性,再查看执行计划:
讯享网
执行结果如下:
删除表后再重建 test 表带 without counter 属性,再查看执行计划。
讯享网
执行结果如下:
例 7 使用 AUTO_INCREMENT 自增列。先设置 INI 参数值,然后建表,最后隐式和显式插入自增列值。
讯享网
查询结果如下:
例 8 对表 T 的 C1 列使用 < 半透明加密选项 > 进行按列加密。
先创建用户 USER01 和 USER02。
讯享网
创建 T 表,对 C1 列进行按列加密,加密列对用户 USER01 和 USER02 可见。
需指定如下信息:
- 表名、表所属的模式名;
- 列定义;
- 控制文件和数据文件所在目录。
语法格式

讯享网
参数
- <模式名> 指明该表属于哪个模式,缺省为当前模式;
- <表名> 指明被创建的外部基表名;
- <列名> 指明基表中的列名;
- <数据类型> 指明列的数据类型,暂不支持多媒体类型;其余同 3.5.1.1 定义数据库基表中的说明;
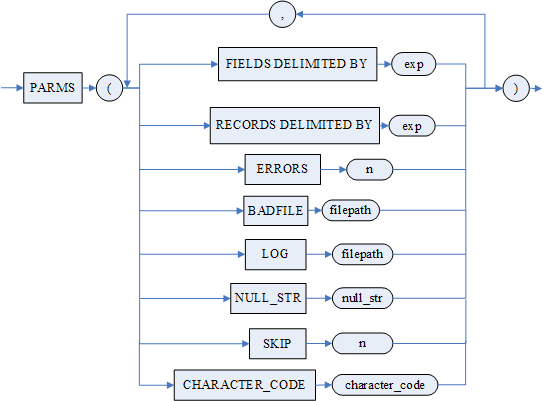
- <参数选项>
FIELDS 表示列分隔符;
RECORDS 表示行分隔符,缺省为回车;
BADFILE 表示错误日志文件(.bad 文件)名称,存放在指定目录下。缺省情况下,将在查询外部表时自动生成(若中途无错误数据,将不生成.bad 文件),缺省 BADFILE 文件前缀为“表名 + 表 id”;
LOG 表示日志文件(.log 文件)名称,存放在指定目录下。缺省情况下,将在查询外部表时自动生成,缺省 LOG 文件前缀为“表名 + 表 id”;
NULL_STR 指定数据文件中 NULL 值的表示字符串,默认忽略此参数;
SKIP 指定跳过数据文件起始的逻辑行数,默认为 0;
CHARACTER_CODE 指定数据文件中数据的编码格式,默认为 GBK,可选项有 GBK,UTF-8,SINGLE_BYTE 和 EUC-KR;
- <表达式> 字符串或十六进制串类型表达式;
- <控制文件目录名> 指数据库对象目录的名称。
图例
定义外部表

from_clause

from1_clause

from2_clause

param_list
语句功能
供具有 DBA 角色(三权分立)、DB_OBJECT_ADMIN 角色(四权分立)或具有 CREATE TABLE 或 CREATE ANY TABLE 权限的用户定义外部基表。MPP 环境、DSC 环境和 DPC 环境下不支持创建外部表。
使用说明
- <表名>指定了所要建立的外部表名。如果<模式名>缺省,则缺省为当前模式。表名需要是合法的标识符,且满足 SQL 语法要求;
- 表名前缀和后缀的限制规则请参考 3.5.1.1 定义数据库基表;
- 外部表的表名最大长度为 128 个字符;
- 所建外部基表至少要包含一个<列名>指定的列,在一个外部基表中,各<列名>不得相同。一张外部基表中至多可以包含 2048 列;
- 外部基表不能存在大字段列;
- 外部基表不能存在任何约束条件;
- 外部基表不能为临时表,不能建立分区;
- 外部基表上不能建立任何索引;
- 外部基表是只读的,不存在表锁,不允许任何针对外部表的增删改数据操作,不允许 TRUNCATE 外部表操作;
- 用户在创建外部表之前,须先指定文件目录;
- 用户创建外部表时必须具有指定目录的读权限;
- 用户查询外部表时必须具有指定目录的读权限;由于用户查询外部表时,默认会在指定目录下生成日志文件和错误日志文件,因此用户还需具有指定目录的写权限;
- 控制文件的书写格式为:
其中 OPTIONS 选项为可选部分,目前 OPTIONS 中支持 DATA、LOG、errors、badfile、null_str、skip、character_code 选项。DATA 表示数据文件名称,其余选项请参考上述参数介绍部分。<file_name> 和 <directory_name> 只能指定文件或文件夹名称,不能包含路径信息,否则报错。
- 如果没有使用<参数选项>的 RECORDS 指定行分隔符,则在数据文件中的一行数据必须以回车结束;
- 外部表支持查询 ROWID、USER 和 UID 伪列,不支持查询 TRXID 伪列。
举例说明
例 1 指定操作系统的一个文本文件作为数据文件,编写控制文件及建表语句。
编写数据文件(d:ext_tabledata.txt)如下:
讯享网
编写控制文件(d:ext_tablectrl.txt)如下:
创建目录对象如下:
讯享网
建表语句:
系统执行建表语句后,就在数据库中建立了相应的外部基表。查询 EXT 表:
讯享网
查询结果如下:
例 2 将文本文件作为数据文件,指定数据文件创建外部表。
编写数据文件(d:ext_table_2data.txt)如下:
讯享网
创建目录对象如下:
在 Windows 操作系统中建表语句如下:
讯享网
在 Linux 操作系统中建表语句如下:
查询 ext_table2 表:
讯享网
查询结果如下:
例 3 将文本文件作为数据文件,指定数据文件创建外部表。
在 Windows 操作系统中编写控制文件(d: est_externtablequan.ctrl),内容如下:
讯享网
在 Linux 操作系统中编写控制文件(d: est_externtablequan.ctrl),内容如下:
编写数据文件(d: est_externtablequan.txt)如下:
讯享网
创建目录对象如下:
建表语句:
讯享网
查询表 fldr1 中的数据:
查询结果如下:
讯享网
语法格式
参数
- <表名> 指明被创建的 HUGE 表名。普通 HUGE 表,由于表名 + 辅助表名最大长度不大于 128 字节,则表名不大于 123 字节;分区 HUGE 表,由于子表名 + 辅助表名的长度不大于 128 字节,则子表名不大于 123 字节;
- <区大小> 指一个区的数据行数。区的大小必须是 2 的 n 次方,如果不是则向上对齐。取值范围:1024 行~1024*1024 行。不指定则默认值为 65536 行;
- <storage 子句 1> 中 FILESIZE (< 文件大小 >)指定 HUGE 表列存数据文件的大小,单位为 MB,取值范围为 16~1024*1024,不指定则默认为 64M。文件大小必须是 2 的 n 次方,如果不是则向上对齐;INITIAL (< 文件初始大小 >)指定 HUGE 表列存数据文件的初始大小。
1)如果未指定 FILESIZE,则设置为 INI 参数 HUGE_DEFAULT_FILE_SIZE 指定的值;
2)如果未指定 INITIAL,则获取 INI 参数 HUGE_DEFAULT_FILE_INIT_SIZE,如果该参数非 0,则取该 INI 参数与 FILESIZE 的较小值;如果该 INI 参数为 0,则设定为该表的 FILESIZE。
- <storage 子句 1> 中 STAT [NONE| SYNCHRONOUS | ASYNCHRONOUS] [ON | EXCEPT ( col_lst )] 设置 HUGE 表的统计状态。
- 设置表的统计状态[NONE| SYNCHRONOUS | ASYNCHRONOUS]
讯享网
讯享网
- 设置列[<ON | EXCEPT> ( col_lst )],用于设置表中特定某些列的统计信息状态
讯享网
讯享网
讯享网
- <storage 子句 2> 的 STAT NONE 对某一列进行设置,该列不计算统计信息,在修改时不做数据的统计;此处不设置 STAT NONE,表示进行统计;
- <混合表空间名> 指要创建的 HUGE 表所属的混合表空间。不指定则存储于默认用户表空间 MAIN 中。不支持同时使用 < 表空间子句 > 和 <storage 子句 1> 指定混合表空间名;
- <压缩级别> 指定列的压缩级别,有效值范围为:0~10,分别代表不同的压缩算法和压缩级别。有两种压缩算法:SNAPPY 和 ZIP。10 采用 SNAPPY 算法轻量级方式压缩。2~9 采用 ZIP 算法压缩,2~9 代表压缩级别,值越小表示压缩比越低、压缩速率越快;值越大表示压缩比越高、压缩速度越慢。0 和 1 为快捷使用,默认值为 0。0 等价于 LEVEL 2;1 等价于 LEVEL 9;
- < 压缩类型 > 指定列压缩类型。FOR 'QUERY [LOW]'表示进行规则压缩;FOR 'QUERY HIGH'表示结合进行规则压缩与通用压缩结合,前者的压缩比一般在 1:1 至 1:3 之间,后者一般为 1:3 至 1:5 之间。规则压缩方式一般适用于具有一定的数据规则的数据的压缩,例如重复值较多等。若某列的类型为字符串类型且定义长度超过 48,则即使指定规则压缩也无效,实际只进行通用压缩;
- <日志属性> 此属性仅对非事务型 HUGE 表有效,支持通过做日志来保证数据的完整性。完整性保证策略主要是通过数据的镜像来实现的,镜像的不同程度可以实现不同程度的完整性恢复。三种选择:1)LOG NONE:不做镜像。相当于不做数据一致性的保证,如果出错只能手动通过系统函数 SF_REPAIR_HFS_TABLE(模式名,表名)来修复表数据。2)LOG LAST:做部分镜像。但是在任何时候都只对当前操作的区做镜像,如果当前区的操作完成了,这个镜像也就失效了,并且可能会被下一个**作区覆盖,这样做的好处是镜像文件不会太大,同时也可以保证数据是完整的。但有可能遇到的问题是:一次操作很多的情况下,有可能一部分数据已经完成,另一部分数据还没有来得及做的问题。3)LOG ALL:全部做镜像。在操作过程中,所有被修改的区都会被记录下来,当一次操作修改的数据过多时,镜像文件有可能会很大,但能够保证操作完整性。默认选择为 LOG LAST;
- <WITH|WITHOUT> DELTA WITH DELTA 表示创建事务型 HUGE 表;WITHOUT DELTA 表示创建非事务型 HUGE 表,缺省为 WITH DELTA。若创建数据库时使用参数 HUGE_WITH_DELTA 的缺省值 1,则不支持创建非事务型 HUGE 表。
图例
创建 HUGE 表
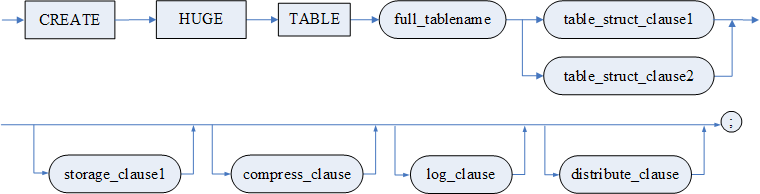
full_tablename
table_struct_clause1
.png)
table_struct_clause2
.png)
column_define_clause
.png)
col_cons_def

column_constraint
.png)
table_constraint
.png)
table_constraint_clause
unique_spec
.png)
表空间子句
storage_clause1

storage1 子项

storage_clause2

compress_clause
.png)
2.png)
distribute_clause
range_dis_act
list_dis_act
log_clause

语句功能
供具有 DBA 角色(三权分立)、DB_OBJECT_ADMIN 角色(四权分立)或具有 CREATE TABLE 或 CREATE ANY TABLE 权限的用户创建 HUGE 表。
使用说明
- 表名前缀和后缀的限制规则请参考 3.5.1.1 定义数据库基表;
- 非事务型 HUGE 表的插入、删除与更新操作处理都不能进行回滚;
- 建 HUGE 表时仅支持定义 NULL、NOT NULL、UNIQUE 约束以及 PRIMARY KEY。后两种约束也可以通过 ALTER TABLE 的方式添加,但这两种约束不检查唯一性,用户需要确保实际数据符合约束,否则相关操作的结果可能不符合预期;
- HUGE 不允许建立聚簇索引,允许建立二级索引,不支持建位图索引,其中 UNIQUE 索引不检查唯一性;
- 不支持 SPACE LIMIT(空间限制);
- 不支持建立全文索引;
- 不支持使用自定义类型;
- 不支持引用约束;
- 不支持 IDENTITY 自增列;
- 不支持大字段列;
- 不支持建触发器;
- 不支持显示游标的修改操作;
- 非事务型 HUGE 表 PRIMARY KEY 主键约束或 UNIQUE 唯一约束不检查唯一性,对应的索引都为虚索引。事务型 HUGE 表的 PRIMARY KEY 主键约束或 UNIQUE 唯一约束的唯一性检查由 DM.INI 参数 HUGE_UNIQUE_CHECK 决定,当 HUGE_UNIQUE_CHECK=1 时,PRIMARY KEY 主键约束或 UNIQUE 唯一约束对应的索引均为实索引;HUGE_UNIQUE_CHECK=0 时,创建索引规则仍然与非事务型 HUGE 表保持一致;
- 不允许对分区子表设置 SECTION 和 WITH/WITHOUT DELTA;
- 对于非事务型 HUGE 表,若指定记录区统计信息,可能因为统计信息超长造成记录插入或更新失败;
- HUGE 表不支持查询 TRXID 和 PHYROWID 列。
举例说明
例 以 SYSDBA 身份登录数据库后,创建 HUGE 表 orders。
讯享网
这个例子创建了一个名为 ORDERS 的事务型 HUGE 表,ORDERS 表的区大小为 65536 行,文件大小为 64M,指定所在的混合表空间为 TS1,o_comment 列指定的区大小为不做统计信息,其它列(默认)都做统计信息,指定列 o_comment 列压缩类型为查询高压缩率,压缩级别为 9。
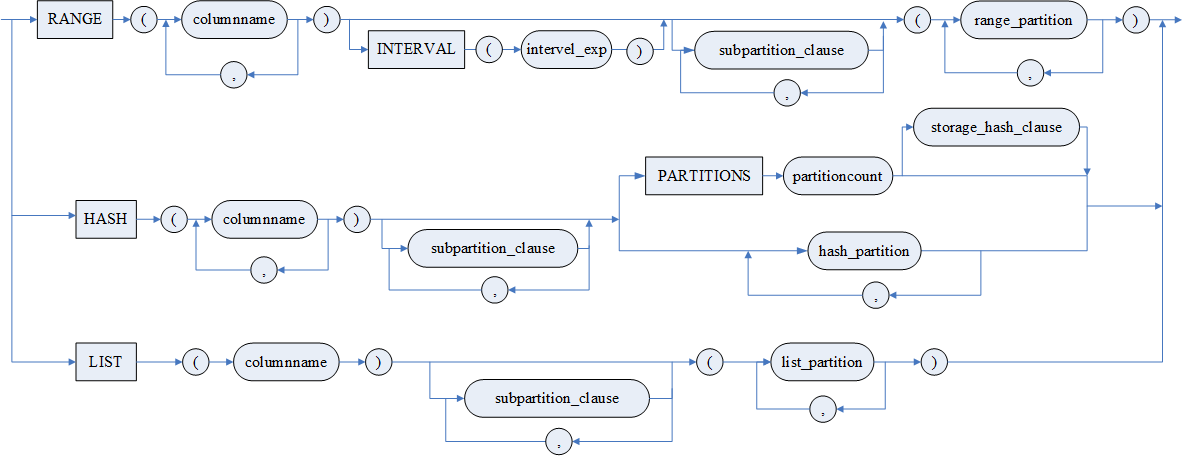
水平分区包括范围分区、哈希分区和列表分区三种。水平分区表的创建需要通过<PARTITION 子句>指定。
范围(RANGE)分区,按照分区列的数据范围,确定实际数据存放位置的划分方式。
列表(LIST)分区,通过指定表中的某一个列的离散值集,来确定应当存储在一起的数据。范围分区是按照某个列上的数据范围进行分区的,如果某个列上的数据无法通过划分范围的方法进行分区,并且该列上的数据是相对固定的一些值,可以考虑使用 LIST 分区。一般来说,对于数字型或者日期型的数据,适合采用范围分区的方法;而对于字符型数据,取值比较固定的,则适合于采用 LIST 分区的方法。
哈希(HASH)分区,对分区列值进行 HASH 运算后,确定实际数据存放位置的划分方式,主要用来确保数据在预先确定数目的分区中平均分布,允许只建立一个 HASH 分区。在很多情况下,用户无法预测某个列上的数据变化范围,因而无法实现创建固定数量的范围分区或 LIST 分区。在这种情况下,DM 哈希分区提供了一种在指定数量的分区中均等地划分数据的方法,基于分区键的散列值(HASH 值)将行映射到分区中。当用户向表中写入数据时,数据库服务器将根据一个哈希函数对数据进行计算,把数据均匀地分布在各个分区中。在哈希分区中,用户无法预测数据将被写入哪个分区中。
在很多情况下,经过一次分区并不能精确地对数据进行分类,这时需要多级分区表。在进行多级分区的时候,三种分区类型还可以交叉使用。
语法格式
参数
- <模式名> 指明该表属于哪个模式,缺省指定分区表执行查询或增删子表 DDL 为当前模式;
- <表名> 指明被创建的基表名,基表名最大长度 128 字节;如果是分区表,主表名和分区名遵循“主表名_分区名”总长度最大不超过 128 字节。按数目方式创建 HASH 分区,子分区命名规则为“DMHASHPART+ 分区序号”,其他方式的分区名由用户指定;
- <子分区描述项>多级分区表支持自定义子分区描述项,自定义的子分区描述项分区类型与分区列必须与子分区模板一致。如果子分区模板和自定义子分区描述项均指定了分区信息则按自定义分区描述项处理;
- <STORAGE HASH 子句> 指定哈希分区依次使用的表空间;
- <ROW MOVEMENT 子句>设置行迁移功能,仅对行存储的水平分区表有效,其它表类型自动忽略。ENABLE ROW MOVEMENT 打开行迁移,允许更新后数据发生跨分区的移动。DISABLE ROW MOVEMENT,关闭行迁移,不允许更新后数据发生跨分区的移动。缺省为 DISABLE ROW MOVEMENT;
- <间隔表达式>中日期间隔函数为 NUMTOYMINTERVAL、NUMTODSINTERVAL;数值常量为:整型、DEC 类型。使用了 < 间隔表达式 > 的分区表称为间隔分区表。间隔分区表只能包含一个分区列。
- < 分区表封锁子句 > 指定分区表执行查询或增删子表 DDL 采用的封锁方式。
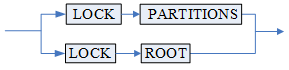
LOCK PARTITIONS:使用细粒度的封锁模式。该模式下,增删子表 DDL 时从根表到目标子表路径上所有的主表都进行 IX+S 封锁,查询时同样对路径上所有的表都进行 IS 封锁,能够允许增删子表与查询的并发。指定 LOCK PARTITIONS 模式的分区表查询时,可能会增删子表,如果后续查询不涉及被增删的子表,则查询可以正常完成;否则查询可能报错。不支持将间隔分区表设置为 LOCK PARTITIONS 模式。由于指定 LOCK PARTITIONS 模式的分区表查询时可能会增删子表,所以该模式的分区表的查询计划不可重用,每次执行都需要重新分析;因此,在事务密集型环境中,LOCK PARTITIONS 配置需慎用。同样的原因,而语句块的所有语句属于同一个计划,所以语句块中对 LOCK PARTITIONS 模式的表的查询必须使用动态执行的方式。因增删 HASH 分区表子表会导致数据重组,所以即使指定了 LOCK PARTITIONS 细粒度的封锁模式,增删 HASH 分区子表时,仍采用 LOCK ROOT 封锁根表模式。指定 LOCK PARTITIONS 模式时,不支持 SPLIT 和 MERGE 分区。
LOCK ROOT:执行时只封锁根表的模式。该模式下,增删子表 DDL 时对根表进行 X 封锁,查询时对根表进行 IS 封锁,增删子表与查询无法并发。
- < 表空间子句 > 不能和 <STORAGE 子句 > 中的 ON < 表空间名 > 同时使用。
图例
表定义语句
.png)
full_tablename
table_struct_clause

column_define_clause
col_define_low

default_clause
identity_clause
col_cons_def
column_constraint
ref_action
table_constraint
table_constraint_clause
unique_spec
refs_spec

partition_clause

partition_item
range_partition
hash_partition

list_partition

subpartition_desc
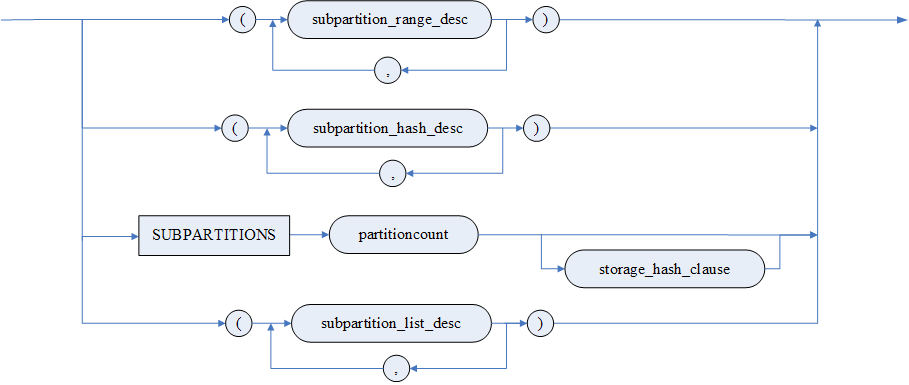
subpartition_range_desc

subpartition_hash_desc

subpartition_list_desc

range_subpartition
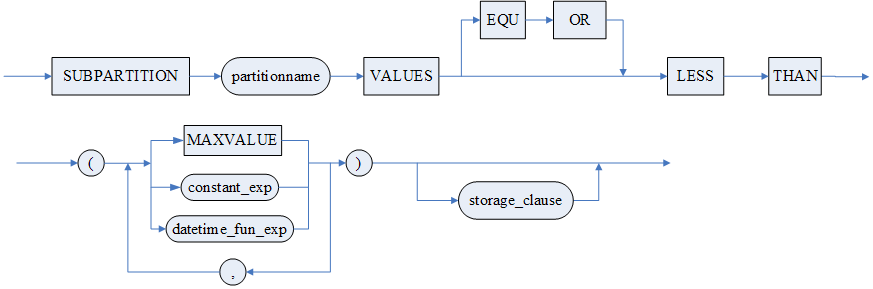
hash_subpartition

list_subpartition

sub_template

range_subpartition_template

hash_subpartition_template
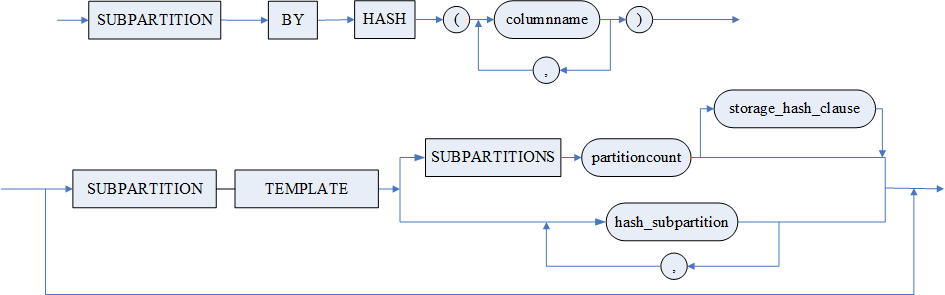
list_subpartition_template
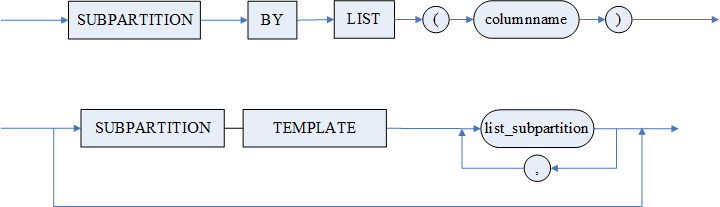
storage_hash_clause

< 分区表封锁子句 >
row_movement_clause

属性子句
语句功能
供具有 DBA 角色(三权分立)、DB_OBJECT_ADMIN 角色(四权分立)或具有 CREATE TABLE 或 CREATE ANY TABLE 权限的用户定义水平分区表。
使用说明
- < 表名> 指定所要建立的水平分区表名;
- 表名前缀和后缀的限制规则请参考 3.5.1.1 定义数据库基表;
- <PARTITION 子句> 用来指定水平分区。其中 RANGE 和 HASH 可以指定一个或多个列作为分区列,LIST 只能指定一个列作为分区列;
- “PARTITION BY RANGE……”子句用来指定范围分区,然后在每个分区中分区列的取值通过 VALUES 子句指定。
- “PARTITION BY LIST……”子句用来指定 LIST 分区,然后在每个分区中分区列的取值通过 VALUES 子句指定。当用户向表插入数据时,只要分区列的数据与 VALUES 子句指定的数据之一相等,该行数据便会写入相应的分区子表中。LIST 分区的分区范围值必须唯一,不能重复。
- “PARTITION BY HASH……”子句用来指定 HASH 分区。
- 分区列类型必须是数值型、字符型或日期型,不支持 BLOB、CLOB、IMAGE、TEXT、LONGVARCHAR、BIT、BINARY、VARBINARY、LONGVARBINARY、BFILE、时间间隔类型、本地时区类型和用户自定义类型为分区列;
- 不能在水平分区表上建立自引用约束;
- 普通环境中,水平分区表的各级分区数的总和上限是 65535;MPP 环境下,水平分区表的各级分区总数上限取决于 INI 参数 MAX_EP_SITES,上限为 2(16-log2MAX_EP_SITES)。比如:当 MAX_EP_SITES 为默认值 64 时,分区总数上限为 1024;
- 可以定义主表的 BRANCH 选项,但不能对水平分区子表进行 BRANCH 项设置,子表的 BRANCH 项只能通过主表继承得到;
- 仅单机和 DMDSC 环境下,水平分区表支持自增列;
- 不允许引用水平分区子表作为外键约束;
- 水平分区子表删除后,会将子表上的数据一起删除;
- 范围分区和哈希分区的分区键可以多个,每一层最多不超过 16 列;LIST 分区的分区键必须唯一;
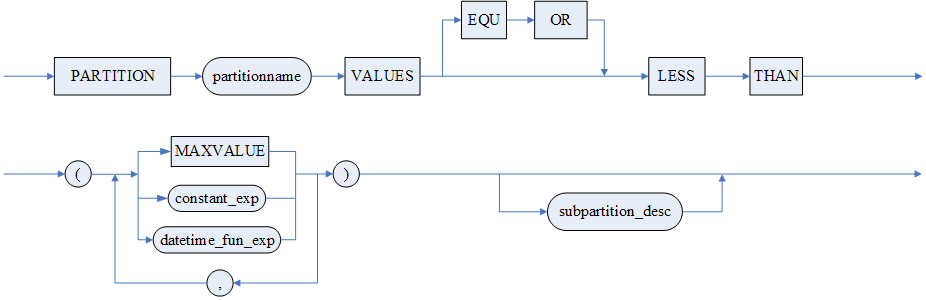
- 范围分区表使用说明:
- 范围分区支持 MAXVALUE 值的使用,MAXVALUE 代表一个比任何值都大的值。MAXVALUE 值需要用户指定才能使用,作为分区中的最大值。
- 范围分区的范围值表达式类型应与分区列类型一致,否则按分区列类型进行类型转换。
- 对于范围分区,增加分区必须在最后一个分区范围值的后面添加,要想在表的开始范围或中间增加分区,应使用 SPLIT PARTITION 语句。
- 间隔分区表使用说明:
- 仅支持一级范围分区创建间隔分区。
- 只能有一个分区列,且分区列类型为日期或数值。
- 对间隔分区进行 SPLIT,只能在间隔范围内进行操作。
- 被 SPLIT/MERGE 的分区,其左侧分区不再进行自动创建。
- 不相邻的间隔的分区,不能 MERGE。
- 表定义不能包含 MAXVALUE 分区。
- 不允许新增分区。
- 不能删除起始间隔分区。
- 间隔分区表定义语句显示到起始间隔分区为止。
- 自动生成的间隔分区,均不包含边界值。
- MPP 下不支持间隔分区表。
- 当间隔分区的“间隔”设置得过大时,可能导致触发扩展分区时计算次数超过上限,新增间隔分区失败。
- LIST 分区表使用说明:
- LIST 分区支持 DEFAULT 关键字的使用,所有不满足分区条件的数据,都划分为 DEFAULT 的分区,但 DEFAULT 关键字需要用户指定,系统不会自动创建 DEFAULT 分区。
- LIST 分区子表范围值个数与分区列的数据类型、数据页大小和相关系统表列长度相关,存在以下限制:
a) 4K 页,单个子表最多支持 120 个范围值。
b) 8K 页,单个子表最多支持 254 个范围值。
c) 16K 或 32K 页,单个子表最多支持 270 个范围值。
- 水平分区表为堆表时,主表及其各子表必须位于同一个表空间;
- 组合水平分区表层次最多支持八层;
- 普通表、堆表、列存储表均支持多级分区;
- 分区子表的存储属性与主表保持一致,忽略子表的 STORAGE 子句;
- < 哈希分区表定位方式 > 用于指定哈希分区表的数据定位方式。取值 0 表示采用 DM 原有的数据定位方式;取值 1 表示采用新数据定位方式,此时可以添加分区;取值 2 为兼顾数据分布均衡和允许添加分区的数据定位方式;3 采用新的 hash 算法计算分区列哈希值, 分区定位方式与 HASHPARTMAP(1) 保持一致。其默认值由 INI 参数 DEFAULT_HASHPARTMAP 指定,该参数默认为 1。当分区表根表为 RANGE 或 LIST 分区表时也可以指定 <HASHPARTMAP 定位方式 >,用来影响下层 HASH 分区子表;
- 创建水平分区表时,若表的 PRIMARY KEY 未包含所有分区列,系统会自动创建全局索引,否则自动创建局部索引。
举例说明
例 1 创建一个范围分区表 callinfo,用来记录用户 2018 年的电话通讯信息,包括主叫号码、被叫号码、通话时间和时长,并且根据季度进行分区。
讯享网
表中的每个分区都可以通过“PARTITION”子句指定一个名称。并且每一个分区都有一个范围,通过“VALUES LESS THAN”子句可以指定上界,而它的下界是前一个分区的上界。如分区 p2 的 time 字段取值范围是['2018-04-01', '2018-07-01')。如果通过“VALUES EQU OR LESS THAN”指定上界,即该分区包含上界值,如分区 p4 的 time 字段取值范围是['2018-10-01','2018-12-31']。另外,可以对每一个分区指定 STORAGE 子句,不同分区可存储在不同表空间中。
例 2 查询分区子表,直接使用子表名称进行查询。
当在分区表中执行 DML 操作时,实际上是在各个分区子表上透明地修改数据。当执行 SELECT 命令时,可以指定查询某个分区上的数据。
例如,查询 callinfo 表中分区 p1 的数据,可以通过以下方式:
例 3 创建一个间隔分区表 ages,统计居民的年龄分布情况。
讯享网
“张三”、“李四”和“王五”的年龄无法匹配任何一个现有分区表,因此系统自动创建间隔分区以容纳新插入的值。本例中系统将以 100 为起始值,以 10 为间隔值创建 2 个间隔分区,第一个间隔分区的范围为 120~129,第二个间隔分区的范围为 100~109,由于用户定义的 p4 分区中包含值 100,因此值 100 会被划分到 p4 分区中。
- 通过查询系统表 SYSOBJECTS 获取表 ages 的 ID
查询结果如下:
讯享网
- 通过查询系统表 SYSHPARTTABLEINFO 获取表 ages 中的分区表信息
查询结果如下:
讯享网
- 查询 P4 分区表数据
查询结果如下:
讯享网
查询 SYS_P1250_1255 分区数据
查询结果如下:
讯享网
查询 SYS_P1250_1257 分区表数据
查询结果如下:
讯享网
例 4 创建多列分区。创建一个范围分区表 callinfo,以 time,duration 两列为分区列。
如果分区表包含多个分区列,采用多列比较方式定位匹配分区。首先,比较第一个分区列值,如果第一列值在范围之内,就以第一列为依据进行分区;如果第一列值处于边界值,那么需要比较第二列的值,根据第二列为依据进行分区;如果第二列的值也处于边界值,需要继续比较后续分区列值,以此类推,直到确定目标分区为止。匹配过程参看下表。
例 5 创建一个产品销售记录表 sales,记录产品的销量情况。由于产品只在几个固定的城市销售,所以可以按照销售城市对该表进行 LIST 分区。
讯享网
例 6 如果销售城市不是相对固定的,而是遍布全国各地,这时很难对表进行 LIST 分区。如果为该表进行哈希分区,可以很好地解决这个问题。
例 5 创建一个产品销售记录表 sales,记录产品的销量情况。由于产品只在几个固定的城市销售,所以可以按照销售城市对该表进行 LIST 分区。
讯享网
例 6 如果销售城市不是相对固定的,而是遍布全国各地,这时很难对表进行 LIST 分区。如果为该表进行哈希分区,可以很好地解决这个问题。
如果不指定分区表名,还可以通过指定哈希分区个数来建立哈希分区表。
讯享网
例 7 创建一个产品销售记录表 sales,记录产品的销量情况。由于产品需要按地点和销售时间进行统计,则可以对该表进行多级分区,一级 LIST 分区、二级 RANGE 分区。
在创建多级分区表时,指定了子分区模板,同时子分区 P1 又自定义了子分区描述项 P11_1 和 P11_2。除了 P1 使用自定义的子分区描述项,拥有两个自定义的子分区 P11_1 和 P11_2 之外,其他子分区 P2 和 P3 都使用子分区模板,各自拥有四个子分区 P11、P12、P13 和 P14。如下表所示:
例 8 创建一个三级分区,更多级别的分区表的建表语句按照语法类推。
讯享网
本例子中各分区表的表名详细介绍如下:
为了满足用户在建立应用系统的过程中需要调整数据库结构的要求,DM 系统提供表修改语句。可对表的结构进行全面的修改,包括修改表名、列名、增加列、删除列、修改列类型、增加表级约束、删除表级约束、设置列缺省值、设置触发器状态等一系列修改。系统只提供外部表的文件(控制文件或数据文件)路径修改功能,如果想更改外部表的表结构,可以通过重建外部表来实现。
语法格式
参数
- <模式名> 指明**作的基表属于哪个模式,缺省为当前模式;
- <表名> 指明**作的基表的名称;
- <列名> 指明修改、增加或被删除列的名称;
- <数据类型> 指明修改或新增列的数据类型;
- <列缺省值> 指明新增/修改列的缺省值,其数据类型与新增/修改列的数据类型一致;
- < 列压缩子句 > 指明列的压缩级别和压缩类型。仅支持 HUGE 表;
- <空间限制子句> 分区表不支持修改空间限制;
- <VALIDATE 选项 > 设置在添加、修改约束的时候,是否对表中的数据进行约束检查,若指明 NOVALIDATE 则不检查原有数据,只检查新数据;使约束生效时,默认 VALIDATE;使约束失效时,默认 NOVALIDATE;暂不支持 DISABLE VALIDATE;注意,当前仅对唯一约束和外键约束生效,其他约束仅语法支持;当有老数据不符合约束时,不允许创建聚集索引;
- <外部表文件路径>指明新的文件在操作系统下的路径 + 新文件名。数据文件的存放路径符合 DM 安装路径的规则,且该路径必须是已经存在的;
- < 并行度 > 创建数据表时,为 TABLE 指定并行度,并行度的合法范围为 0~128;
- AUTO_INCREMENT [=] < 起始边界值 > 指定的 < 起始边界值 > 必须大于当前系统中的 < 起始边界值 >。如果小于,则修改无效。
图例
表修改语句

modify_table_clause



table_constraint_clause
unique_spec
.png)
语句功能
供具有 DBA 角色(三权分立)、DB_OBJECT_ADMIN 角色(四权分立)的用户或该表的建表者或具有 ALTER ANY TABLE 权限的用户对表的定义进行修改。
修改包括:
- 修改一列的数据类型、精度、刻度,设置列上的 DEFAULT、NOT NULL、NULL、VISIBLE、可见用户等;
- 增加一列及该列上的列级约束;
- 重建表上的聚集索引数据,消除附加列;
- 删除一列;
- 增加、删除表上的约束;
- 启用、禁用表上的约束;
- 表名/列名的重命名;
- 修改触发器状态;
- 修改表的最大存储空间限制;
- 修改外部表的文件路径;
- 启用、关闭超长记录(变长字符串)存储功能;
- 增加、删除表上记录物理逻辑日志的功能;
- 将表移动到目标表空间。
使用说明
- 各个子句中都可以含有单个或多个列定义(约束定义),单个列定义(约束定义)和多个列定义(约束定义)应该在它们的定义外加一层括号,括号要配对;
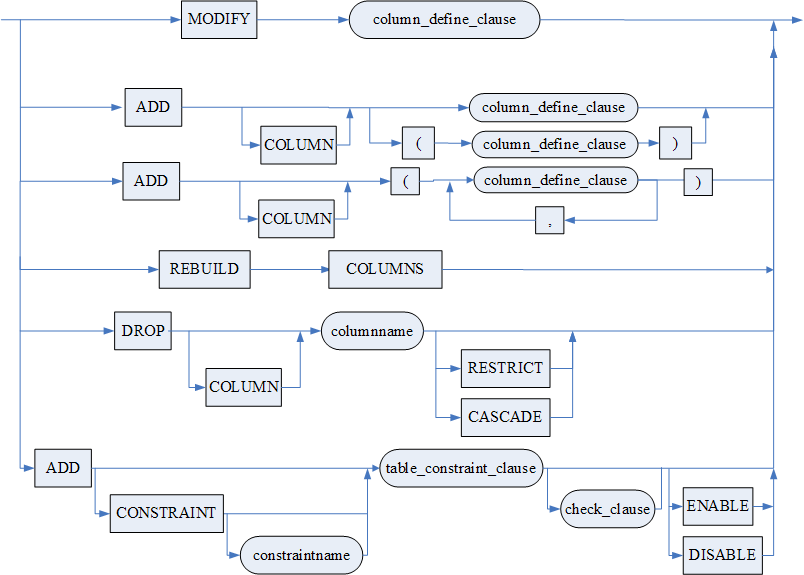
- MODIFY COLUMN 说明:
- 使用 MODIFY COLUMN 时,支持不指定 < 数据类型 > 语法。在这种格式下,不支持 <STORAGE 子句 > 和 < 存储加密子句 > 属性的修改。仅修改 < 列定义子句 > 中指定的属性,其它属性保留原状。
- 使用 MODIFY COLUMN 时,不能更改聚集索引的列或者函数索引的列,位图、位图连接索引的列以及自增列不允许被修改。
- 修改引用约束中引用和被引用的列时,列类型与引用的列类型或列类型与被引用的列类型须兼容。
- 使用 MODIFY COLUMN 子句能修改的约束有列上的 NULL/NOT NULL 约束、CHECK 约束、 唯一约束(不包括聚集唯一约束)、 主键约束(不包括聚集主键约束);如果修改数据类型不变,则列上现有值必须满足约束条件;不允许被修改为自增列。
- 使用 MODIFY COLUMN 子句添加 NULL 约束时,不能重复添加;如果某列现有的值均非空,则允许添加 NOT NULL;主键约束和 NULL 约束不允许同时添加;表上已经有主键约束,则不可以添加主键约束。列上已有唯一约束和主键约束,则不允许添加唯一约束和主键约束。添加了唯一主键约束就不能添加唯一主键约束。
- 使用 MODIFY COLUMN 修改可更改列的数据类型时,若该表中无元组,则可任意修改其数据类型、长度、精度或量度和加密属性;若表中有元组,则系统会尝试修改其数据类型、长度、精度或量度,如果修改不成功,则会报错返回。
- 无论表中有无元组,多媒体数据类型和非多媒体数据类型都不能相互转换,CLOB 类型与 BLOB 类型也不能相互转换;BFILE 类型与其他所有类型都不能相互转换。
- 使用 MODIFY COLUMN 不能修改类型为多媒体数据类型的列。
- 修改有默认值的列的数据类型时,原数据类型与新数据类型必须是可以转换的,否则即使数据类型修改成功,但在进行插入等其他操作时,仍会出现数据类型转换错误。
- ADD COLUMN 说明:
- 当设置 INI 参数 ALTER_TABLE_OPT 为 1 时,添加列采用查询插入实现,可能会导致 ROWID 的改变;ALTER_TABLE_OPT 为 2 时,系统开启快速加列功能,对于没有默认值或者默认值为 NULL 的新列,系统内部会标记为附加列,能够达到瞬间加列的效果,此时记录 ROWID 不会改变,若有默认值且默认值不为 NULL,则默认值的存储长度不能超过 4000 字节,此时仍旧采取查询插入实现;ALTER_TABLE_OPT 为 3 时,系统会开启快速加列功能,允许指定新增列的默认值,系统会为该列设置附加列标记,查询表中已存在的数据时,会自动为记录设置附加列默认值,此时记录 ROWID 不会改变。
- 使用 ADD COLUMN 时,新增列名之间、新增列名与该基表中的其它列名之间均不能重复。若新增列有缺省值,则已存在的行的新增列值是其缺省值。添加新列对于任何涉及表的约束定义没有影响,对于涉及表的视图定义不会自动增加。例如:如果用“*”为一个表创建一个视图,那么后加入的新列不会加入到该视图。
- 使用 ADD COLUMN 时,还有以下限制条件:
a) 列定义中如果带有列约束,只能是对该新增列的约束,但不支持引用约束、聚集唯一约束和聚集主键约束;列级约束可以带有约束名,系统中同一模式下的约束名不得重复,如果不带约束名,系统自动为此约束命名;
b) 如果表上没有元组,列可以指定为 NOT NULL;如果表中有元组,对于已有列可以指定同时有 DEFAULT 和 NOT NULL,新增列不能指定 NOT NULL;
c) 该列可指定为 CHECK;
d) 该列可指定为 FOREIGN KEY;
e) 允许向空数据的表中,添加自增列;
f) ADD [COLUMN] < 列名 ><IDENTITY 子句 > 将表中的 NOT NULL 列修改为自增列。DM MPP 下不支持该功能;
g) HUGE 表加列仅允许一次增加一个列,且仅支持事务性 HUGE 表。HUGE 表加列不支持增加虚拟列、包含约束子句的列。
- 使用 REBUILD COLUMNS 对添加过新列的表,重建表中的索引数据,消除附加列。水平分区表增加列后不允许使用 REBUILD COLUMNS;
- 用 DROP COLUMN 子句删除一列有两种方式:RESTRICT 和 CASCADE。RESTRICT 方式为缺省选项,确保只有不被其他对象引用的列才被删除。无论哪种方式,表中的唯一列不能被删除。RESTRICT 方式下,当设置 INI 参数 drop_cascade_view = 1 或者 COMPATIBLE_MODE = 1 时,下列类型的列不能被删除:被引用列、建有视图的列、有 check 约束的列。删除列的同时将删除该列上的约束。CASCADE 方式下,将删除这一列上的引用信息和被引用信息、引用该列的视图、索引和约束;系统允许直接删除 PK 列。但被删除列为 CLUSTER PRIMARY KEY 类型时除外,此时不允许删除;
- ADD CONSTRAINT 子句用于添加表级约束。表级约束包括:PRIMARY KEY 约束、UNIQUE 约束、引用约束(REFERENCES)和检查约束(CHECK)。添加表级约束时可以带有约束名,系统中同一模式下的约束名不得重复,如果不带约束名,系统自动为此约束命名。
当 ENABLE_TMP_TAB_ROLLBACK 为 0 时,不允许对临时表创建主键约束以及唯一约束。
当添加 PRIMARY KEY 约束时,除手动指定 CLUSTER 或 NOT CLUSTER 关键字外,还可通过 INI 参数 PK_WITH_CLUSTER 控制该约束默认为 CLUSTER 或 NOT CLUSTER。其中,若添加 CLUSTER PRIMARY KEY 约束,则将根据约束列重建聚集索引。
用 ADD CONSTRAINT 子句添加约束时,对于该基表上现有的全部元组要进行约束违规验证:
- 添加一个 PRIMARY KEY 约束时,要求将成为关键字的字段上无重复值且值非空,并且表上没有定义主关键字;
- 添加一个 UNIQUE 约束时,要求将成为唯一性约束的字段上不存在重复值,但允许有空值;
- 添加一个 REFERENCES 约束时,要求将成为引用约束的字段上的值满足该引用约束。
- 添加一个 CHECK 约束或外键时,要求该基表中全部的元组满足该约束。
- RENAME CONSTRAINT 子句用于对表级约束进行重命名,新的名称不能为空,也不能与已有约束名重复;
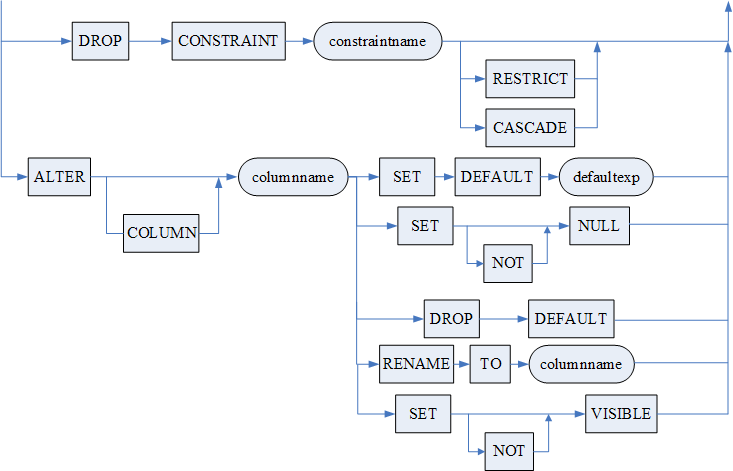
- RENAME COLUMN 子句用于对表列进行重命名,新的名称不能为空,也不能与表已有列名重复;
- DROP CONSTRAINT< 约束名 > [RESTRICT | CASCADE]用于删除表级约束,表级约束包括:主键约束(PRIMARY KEY)、唯一性约束(UNIQUE)、引用约束(REFERENCES)和检查约束(CHECK)。用 DROP CONSTRAINT 子句删除约束时,有 RESTRICT 和 CASCADE 两种可选方式,缺省为 RESTRICT 方式。当删除主键或唯一性约束时,系统自动创建的索引也将一起删除。RESTRICT 确保只有不被其它外部约束引用的约束才被能删除。CASCADE 可删除约束和任何引用该约束的外部约束;[DROP|KEEP] INDEX 用于约束含有对应索引的情况,只能和 CASCADE 搭配使用,CASCADE 也可缺省。指定 DROP INDEX 删除约束的同时删除对应的索引,指定 KEEP INDEX 则既不删除约束也不删除索引并报错返回;
- 使用 SET DEFAULT [ON NULL] < 列缺省值表达式 > 语句可以设置列默认值和 ON NULL 选项;
- 使用 DROP DEFAULT 语句删除列缺省值时,会一并删除列上的隐式 NOT NULL 约束;
- DISABLE CONSTRAINT 子句用于禁用约束,不支持禁用聚集唯一约束和聚集主键约束;
- 空间限制子句说明:修改表的最大存储空间限制时,空间大小以 MB 为单位,取值范围在表的已占用空间和 1024*1024 之间,还可以利用 UNLIMITED 关键字去掉表的空间限制;
- MODIFY PATH 说明:
- 只能用于修改外部表的文件路径,文件包括控制文件和数据文件;
- 只支持对应创建方式的文件路径修改:原表使用控制文件创建,则只支持修改控制文件路径;原表使用数据文件创建,则只支持修改数据文件路径。
- default directory <目录名>和 location('<文件名>'),专门用于修改外部表路径名和文件名;
- ADD/DROP LOGIC LOG 开启或关闭物理逻辑日志记录;
- WITHOUT/TRUNCATE ADVANCED LOG 用于删除日志辅助表和清除日志辅助表数据,具体可参考 19.3.1 管理日志辅助表;
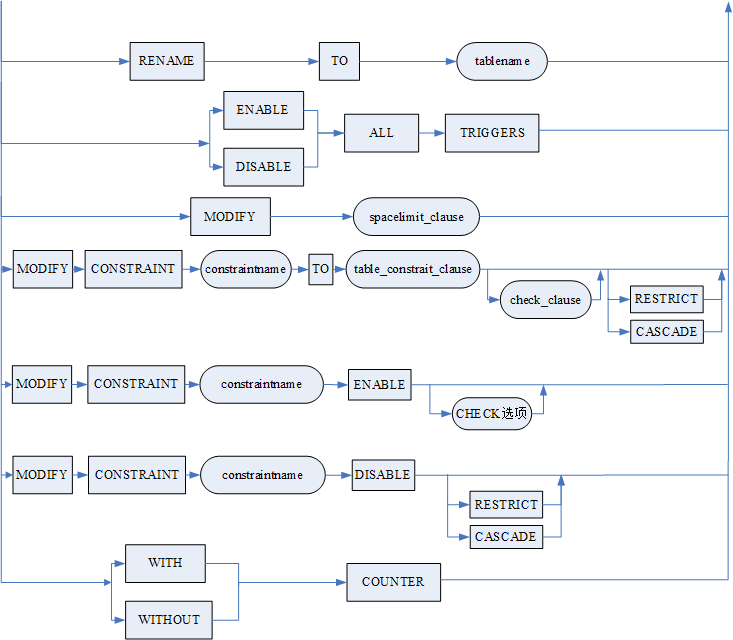
- MOVE TABLESPACE 用于将表及其索引移动到指定的表空间上。如果移动的是分区表,则连同所有分区子表一起移动。不支持移动 huge 表。移动后数据的 TRXID 和 ROWID 可能发生改变;
- DROP STORAGE/REUSE STORAGE 用于删除或重用分区,默认值为 DROP STORAGE。在 DPC 环境下仅做语法兼容。
- DROP PRIMARY KEY[RESTRICT|CASCADE]:用于删除表中的主键约束(PRIMARY KEY)。系统自动创建的与该主键相关的唯一索引也会一起被删除。有两种方式:RESTRICT 和 CASCADE。缺省为 RESTRICT 方式。RESTRICT 确保只有不被其它外部约束引用的主键约束才被能删除。CASCADE 可删除主键约束和任何引用该主键的外部约束。不允许删除聚集主键约束(CLUSTER PRIMARY KEY)。用户需要注意,当 INI 参数 PK_WITH_CLUSTER=1 时,缺省情况下创建的主键约束均为聚集主键约束。
- USING INDEX 子句仅支持主键约束使用当前表已有的索引,且需要索引有效以及索引列定义与约束定义一致,不支持 HUGE 表。当使用非 UNIQUE 的局部索引时,需要保证索引列包含所有分区列。
- ENABLE USING LONG ROW 用于开启超长记录存储功能,当 DM 行存储的记录长度超过页大小一半时,先尝试将过长的变长字符串转换为行外 BLOB 存储,如果转换后仍超长则报错。DISABLE USING LONG ROW 用于关闭超长记录存储功能,如果表中已有超长数据,则不能关闭超长记录存储功能。
举例说明
例 1 产品的评论表中 COMMENTS、PRODUCT_REVIEWID、PRODUCTID、RATING 列都不允许修改,分别因为:COMMENTS 为多媒体数据类型;PRODUCT_REVIEWID 上定义有关键字,属于用于索引的列;PRODUCTID 用于引用约束(包括引用列和被引用列);RATING 用于 CHECK 约束。另外,关联有缺省值的列也不能修改。而其他列都允许修改。假定用户为 SYSDBA,如将评论人姓名的数据类型改为 VARCHAR(8),并指定该列为 NOT NULL,且缺省值为'刘青'。
讯享网
此语句只有在表中无元组的情况下才能成功。
例 2 具有 DBA 权限的用户需要对 EMPLOYEE_ADDRESS 表增加一列,列名为 ID(序号),数据类型为 INT,值小于 10000。
如果该表上没有元组,且没有 PRIMARY KEY,则可以将新增列指定为 PRIMARY KEY。表上没有元组时也可以将新增列指定为 UNIQUE,但同一列上不能同时指定 PRIMARY KEY 和 UNIQUE 两种约束。
例 3 具有 DBA 权限的用户需要对 ADDRESS 表增加一列,列名为 PERSONID,数据类型为 INT,定义该列为 DEFAULT 和 NOT NULL。
讯享网
如果表上没有元组,新增列可以指定为 NOT NULL;如果表上有元组且都不为空,该列可以指定同时有 DEFAULT 和 NOT NULL,不能单独指定为 NOT NULL。
例 4 具有 DBA 权限的用户需要删除 PRODUCT 表的 PRODUCT_SUBCATEGORYID 一列。
删除 PRODUCT_SUBCATEGORYID 这一列必须采用 CASCADE 方式,因为该列引用了 PRODUCT_SUBCATEGORY 表的 PRODUCT_SUBCATEGORYID。
例 5 具有 DBA 权限的用户需要在 PRODUCT 表上增加 UNIQUE 约束,UNIQUE 字段为 NAME。
讯享网
用 ADD CONSTRAINT 子句添加约束时,对于该基表上现有的全部元组要进行约束违规验证。在这里,分为三种情况:
- 如果表商场登记里没有元组,则上述语句一定执行成功;
- 如果表商场登记里有元组,并且欲成为唯一性约束的字段商场名上不存在重复值,则上述语句执行成功;
- 如果表商场登记里有元组,并且欲成为唯一性约束的字段商场名上存在重复值,则上述语句执行不成功,系统报错“违反唯一性约束”。
如果语句执行成功,用户通过
可以看到,修改后的商场登记的表结构显示为:
讯享网
例 6 假定具有 DBA 权限的用户需要删除 PRODUCT 表上的 NAME 列的 UNIQUE 约束。当前的 PRODUCT 表结构请参见例 5。
删除表约束,首先需要得到该约束对应的约束名,用户可以查询系统表 SYSOBJECTS,如下所示。
该系统表显示商场登记表上的所有 PRIMARY KEY、UNIQUE、CHECK 约束。查询得到 NAME 列上 UNIQUE 约束对应的约束名,这里为 CONS_PRODUCTNAME。
然后,可采用以下的语句删除指定约束名的约束。
讯享网
语句执行成功。
例 7 建立普通表查看 SELECT COUNT(*) 执行计划,再 ALTER 该表为 WITHOUT COUNTER 属性,再查看执行计划:
执行结果如下:
讯享网
ALTER 该表为 WITHOUT COUNTER 属性,再查看执行计划。
执行结果如下:
讯享网
例 8 创建、启用、禁用、删除 PERSON 表约束 unq。
例 9 取消按列加密的 C1 列对用户 USER02 可见,增加对 USER03 可见。
讯享网
本节专门列出水平分区表在分区方面的修改。其他方面的常规修改和普通表一样,普通表的修改方法在水平分区表上完全适用,详细请参考 3.5.2.1 修改数据库表部分。
语法格式
参数
- <模式名> 指明**作的分区表属于哪个模式,缺省为当前模式;
- <表名> 指明**作的分区表的名称;
- <分区编号> 从 1 开始,2、3、4……以此类推,编号最大值为:实际分区数;
- LOCK PARTITIONS/LOCK ROOT 用于修改分区表的封锁模式。LOCK PARTITIONS 为细粒度的封锁模式,LOCK ROOT 为执行时只封锁根表的模式。不支持将间隔分区表设置为 LOCK PARTITIONS 模式。详细请参考 3.5.1.4 定义水平分区表。
图例
修改水平分区表

modify_table_clause
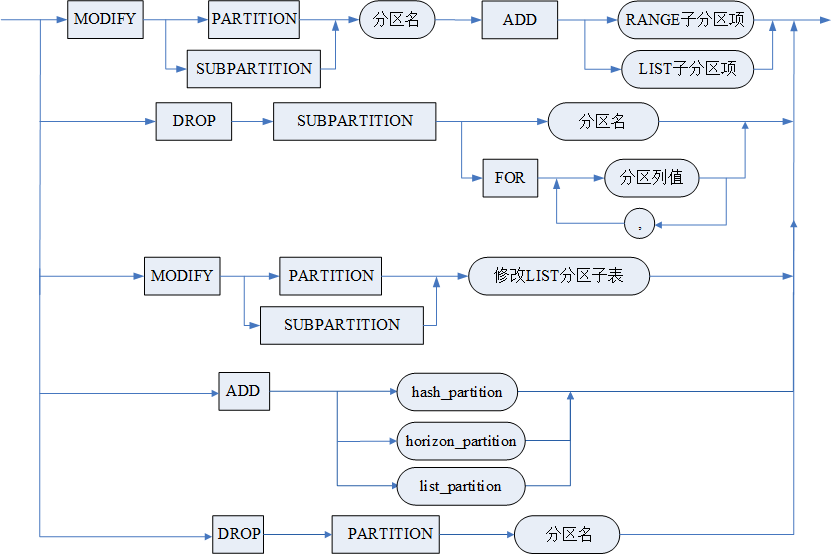

增加多级分区子句(add_subpartition_clause)
exchange_clause

SPLIT 子句 1
SPLIT 子句 2
SPLIT 子句 3

SPLIT 子句 4

merge_clause

分区模板描述项
修改 LIST 分区子表

语句功能
供具有 DBA 角色(三权分立)、DB_OBJECT_ADMIN 角色(四权分立)的用户或该表的建表者或具有 ALTER ANY TABLE 权限的用户对水平分区表的定义进行修改。
修改包括:
- 增加、删除多级分区子表;
- 修改一级 LIST 分区子表;
- 拆分、合并、交换水平分区;
- 修改水平分区子表名称;
- 移动水平分区子表所在表空间。
使用说明
- 具有 DBA 权限的用户或该表的建表者才能执行此操作;
- <增加多级分区子表>说明:
- 对于 HASH 分区表,只有存储选项 HASHPARTMAP 为 1 或 2 的 HASH 分区表才能增加分区子表或多级分区子表;
- 新增的分区名不能与子表重名;
- 只能增加一个下层子表;
- 如果新增子表为中间层子表,可以为其自定义子表或根据模板进行创建;
- 禁止对间隔分区新增子表;
- 子表名称长度不能超过 128,否则报错。
- < 删除一级分区子表 > 和 < 删除多级分区子表 > 说明:
< 删除一级分区子表 > 说明:
- 提供两种方式删除一级子表:一是指定子表表名方式;二是指定分区列值的方式;
- 待删除子表为唯一分区时,禁止删除;
- 采用指定分区列值方式删除子表时,分区列的数目为子表上所有分区列个数总和。例如:一级分区列(c1,c2),那么在删除一级子表时候,分区列的数目为 2 个;
- 禁止删除 HASH 分区的子表。从父表到待删除子表之间也不允许存在 HASH 分区。
- 当删除不存在的分区子表时会报错。若指定 IF EXISTS 关键字后,删除不存在的分区子表,则不会报错。
< 删除多级分区子表 > 说明:
- 提供两种方式删除二级或二级以上的子表:一是指定子表表名方式;二是指定分区列值的方式;
- 待删除子表为唯一分区时,禁止删除;
- 采用指定分区列值方式删除子表时,分区列的数目为子表上所有分区列个数总和。例如:一级分区列(c1,c2); 二级分区列(c3);三级分区列(c4),那么在删除二级子表时候,分区列的数目为 3 个,三级分区列的数目为 4 个;
- 禁止删除 HASH 分区的子表。从父表到待删除子表之间也不允许存在 HASH 分区。
- 当删除不存在的分区子表时会报错。若指定 IF EXISTS 关键字后,删除不存在的分区子表,则不会报错。
- <修改 LIST 分区子表>说明:
- 支持修改一级、多级分区的 LIST 分区子表范围值。修改后的子分区,通过 SP_TABLEDEF()显示完整的分区定义;
- 新增的分区值不能重复;
- 不能删除分区所有范围值;
- 修改的范围值必须为常量;
- 如果表中存在某个范围值的记录,则不能删除此范围值;
- 不能重复删除同一个范围值;
- 不能增加、删除 DEFAULT 值;
- 不能修改 DEFAULT 分区。
- MERGE 合并分区说明:
将相邻的两个范围分区合并为一个分区。合并分区通过指定分区名或分区编号进行,相邻的两个分区的表空间没有特殊要求。其中,LIST 分区 MERGE 时只支持用分区名进行合并。
仅范围分区表和 LIST 分区表支持合并分区。多级分区表与一级分区表的 MERGE 语法一样。
其中,多级分区表进行 MERGE 合并的注意事项:
- 仅支持一级子表类型为 RANGE、LIST;
- 合并多级分区表中的一级子表时,该一级子表下的二级及以上层次子表按照级别分别判断:在创建分区表时当前层次是否指定了模板,若指定了模板,则按照模板创建当前层次子表;若未指定模板,则由系统自动合并为一个子表,子表名称为系统内部设置。RANGE 类型范围值为 MAXVALUE;LIST 类型范围值为 DEFAULT;
- 不允许自定义二级及以上层次子表;
- 不允许直接合并二级及以上层次子表。
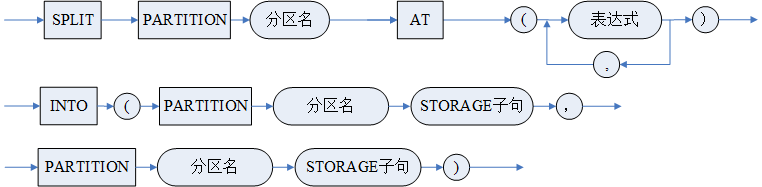
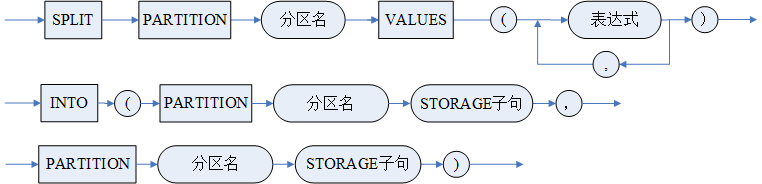
- SPLIT 拆分分区说明:
将某一个 RANGE 范围分区或 LIST 列表分区拆分为相邻的两个或多个分区。拆分范围分区时指定的常量表达式值不能是原有的分区表范围值。拆分列表分区时指定的常量表达式须包含在被拆分区中,新分区至少包含一个范围值且新分区之间范围值不能冲突。
拆分分区时,可以指定分区表空间,也可以不指定;指定的分区表空间不要求一定与原有分区相同;如果不指定表空间缺省使用拆分前分区的表空间;拆分分区会对分区中的数据从主表的角度进行重定位;拆分成多个分区的语法,一次拆分最多支持将一个分区拆分成 128 个新分区。
仅范围分区表和 LIST 分区表支持拆分分区。
多级分区表与一级分区表都只支持拆分一级子表的分区。
<SPLIT 子句 1> 和 <SPLIT 子句 3> 用于 RANGE 分区表,< 表达式 > 的个数和分区列的个数一致。<SPLIT 子句 2> 和 <SPLIT 子句 4> 用于 LIST 分区表。
<SPLIT 子句 1> 和 <SPLIT 子句 2> 只支持 SPLIT 为 2 个分区。<SPLIT 子句 3> 和 <SPLIT 子句 4> 支持拆分为多个分区。
SPLIT 产生的新分区二级及以上层次子表结构与被分隔子表保持一致,名称由系统内部定义。
- 对于堆表分区,不论是拆分还是添加分区,都不能改变分区表空间,各子表必须和原表位于同一表空间;
- 哈希分区支持重命名、增加/删除/修改约束、设置触发器是否启用的修改操作;
- 范围分区支持分区合并、拆分、增加、删除、交换、重命名、增加/删除/修改约束、设置触发器是否生效操作;
- LIST 分区支持分区合并、拆分、增加、删除、交换、重命名、增加/删除/修改约束、设置触发器是否生效操作;
- 对范围分区增加分区值必须是递增的,即只能在最后一个分区后添加分区。LIST 分区增加分区值不能存在于其他已在分区;
- 当水平分区数仅剩一个时,不允许进行删除分区;
- 不允许删除被引用表的子分区;
- EXCHANGE PARTITION/SUBPARTITION 用于交换一级分区/多级子分区的表。交换一级分区,仅范围分区和 LIST 分区支持交换分区,哈希分区表不支持。
- 普通表(非 HUGE 表)交换分区要求分区表与交换表具有相同的结构(相同的表类型、相同的 BRANCH 选项、相同的列结构、相同的索引、相同的分布方式)。不支持包含全局索引的分区表与普通表进行交换分区操作。不支持分区表和含有快速加列的表进行交换分区。分区交换并不会校验数据,如交换表的数据是否符合分区范围等,即不能保证分区交换后的分区上的数据符合分区范围;
- HUGE 表交换分区要求分区表与交换表具有相同的 STORAGE 参数(SECTION,FILESIZE,WITH/WITHOUT DELTA 和 STAT NONE);HUGE 分区表交换表分区时,如果表空间包含多个路径,则源表与目标表必须存储在同一个表空间;
- 若分区表或交换表上存在无效索引,则禁止交换分区。
- TRUNCATE PARTITION/SUBPARTITION 用于清除指定一级分区子表/子分区子表的数据,对应一级分区子表/子分区子表结构仍然保留;MPP 环境下不支持对包含全局索引的分区子表进行 TRUNCATE 操作。DROP STORAGE / REUSE STORAGE 用于删除或重用分区,默认值为 DROP STORAGE。在 DPC 环境下仅做语法兼容。
- 修改分区模板说明:
- 支持模板信息从无到有、从有到无的修改;
- 模板信息定义需要匹配子表类型,并符合对应分区类型的限制,例如范围分区值递增、列表分区不能存在重复值、范围值不能为 NULL 等;
- 修改模板信息后,之前创建的子表不受影响,后续新增子表按照新的模板信息进行创建;
- 仅支持修改第二层子表的模板信息。
- 多级分区表支持下列修改表操作:新增分区、删除分区、新增列、删除列、新增自增列、删除自增列、删除表级约束、修改表名、设置与删除列的默认值、设置列 NULL 属性、设置列可见性、设置行迁移属性、启用超长记录存储功能、关闭超长记录存储功能、WITH DELTA、新增子分区、删除子分区、修改二级分区模板信息、SPLIT/MERGE 分区;
- 水平分区表支持的列修改操作除了多级分区表支持的操作外,还支持:设置触发器生效/失效、修改列名、修改列属性、增加表级主键约束;
- <修改分区子表名>支持修改所有类型的分区子表名称。修改的子表名不能与现有子表重名。修改的名称需要符合对象命名规则,例如名称长度限制等;
- MOVE PARTITION/SUBPARTITION 用于将分区移动到指定的表空间上。移动的分区若包含子表,则连同子表一起移动。不支持移动 HUGE 分区表和堆分区表。
举例说明
例 1 合并分区表,修改分区表。
讯享网
执行后,分区结构如下:
例 2 使用 <SPLIT 子句 > 拆分水平分区表。
例 3 增加,删除分区子表。
讯享网
例 4 交换分区子表。
将分区表 PAR1 分区和表 PARTITION_T2 进行交换。
讯享网
交换之后,数据发生了互换,分别对 PAR1 和 PARTITION_T2 进行查询。先对 PAR1 表进行查询:
查询结果如下:
讯享网
再对 PARTITION_T2 表进行查询:
查询结果如下:
讯享网
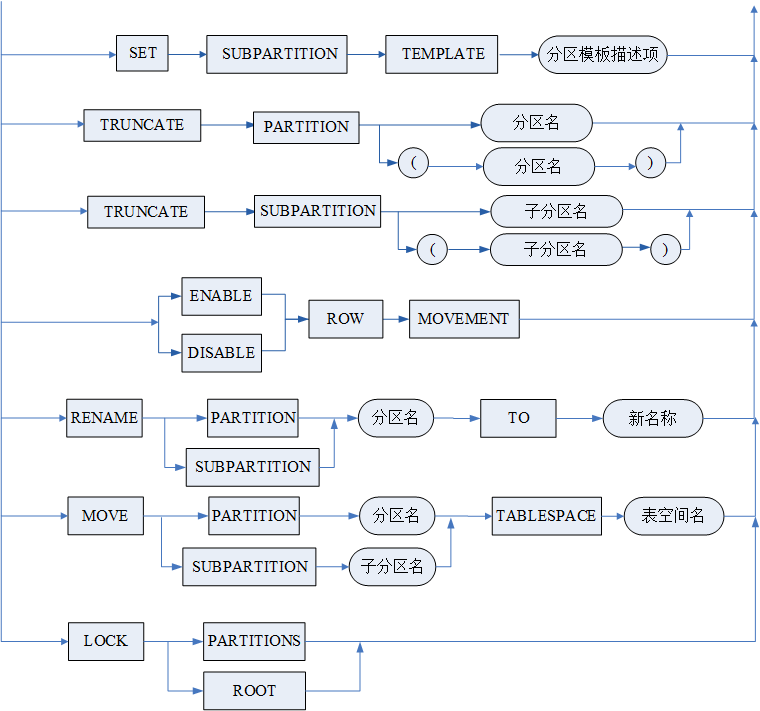
本节专门列出 HUGE 表的修改操作。
语法格式
省略号“……”部分包含两部分。一部分来自 3.5.2.1 修改数据库表,一部分来自 3.5.2.2 修改水平分区表。
来自 3.5.2.1 修改数据库表的部分如下:
讯享网
来自 3.5.2.2 修改水平分区表的部分如下:
参数
- <模式名> 指明**作的基表属于哪个模式,缺省为当前模式;
- <表名> 指明**作的基表的名称;
- <列名> 指明修改、增加或被删除列的名称;
- ADD COLUMN 指明增加列。一次只能增加一个列,且仅支持事务型 HUGE 表。不支持增加虚拟列、包含约束子句的列。当 ALTER_TABLE_OPT 为 0 和 1 效果一样,均为采用查询插入实现;当 ALTER_TABLE_OPT 为 2 时,支持对于没有默认值或者默认值为 NULL 的新列使用快速加列。当 ALTER_TABLE_OPT 为 3 时,允许对指定了默认值的新增列进行快速加列;
- < 列压缩子句 > 指明列的压缩级别和压缩类型;
- ALTER [COLUMN] <列名> SET STAT NONE 修改(关闭)某一个列的统计信息属性。
- ALTER [COLUMN] (<列名>{,<列名>})SET STAT [NONE] 修改表的某一列或多列的统计开关,STAT 为打开,STAT NONE 为关闭。只有表的统计状态是实时或异步时,支持打开或关闭列的统计开关,打开之后列的统计状态和表的统计状态一致;如果表的统计开关是关闭的,不支持打开或关闭列的统计开关。如下表所示:
- WITH DELTA 表示将一个非事务型 HUGE 表修改为事务型。只支持将非事务型(WITHOUT DELTA)HUGE 表修改为事务型(WITH DELTA)的。不支持将一个事务型的 HUGE 表修改为非事务型的;
- SET STAT [NONE | SYNCHRONOUS | ASYNCHRONOUS] [<ON | EXCEPT> ( col_lst)]修改表的统计状态。转换规则见下表:
转换规则注意事项如下:
讯享网
讯享网
讯享网
- REFRESH STAT 刷新辅助表$AUX 的统计信息,为了更新不准确的数据区的信息;
- FORCE COLUMN STORAGE 强制把 R 表数据写入数据文件,仅 with delta 的 HUGE 表支持;
- MODIFY < 列定义 > 已经插入数据的 HUGE 表仅对修改列定义进行有限度的支持:对于不需要重建数据的情况,比如变长类型扩展长度、在数据满足条件的情况下缩小数据长度或增减约束等,可以成功;而对于需要重建数据的情况,比如修改数据类型、修改加密压缩类型等,则会报错不支持。
图例
表修改语句
modify_table_clause
或
1.png)
或
2.png)
或
3.png)
或
4.png)
或
5.png)
“……”部分的语法图请参考 3.5.2.1 修改数据库表和 3.5.2.2 修改水平分区表。
语句功能
供具有 DBA 角色(三权分立)、DB_OBJECT_ADMIN 角色(四权分立)的用户或该表的建表者或具有 ALTER ANY TABLE 权限的用户对 HUGE 表的定义进行修改。
举例说明
创建一个 HUGE 表 STUDENT,表的区大小为 65536 行,文件大小为 64M,S_comment 列指定的区大小为不做统计信息,其它列(默认)都做统计信息。
重新设置列 S_comment,打开 S_comment 的统计开关,对该列做统计信息。
讯享网
修改表 STUDENT 的统计状态为关闭,即所有列都不做统计信息。
修改表 STUDENT 的统计状态为 SYNCHRONOUS,并打开 s_no、 s_class、s_comment 三列的统计开关,打开之后,列的统计状态和表的统计状态一致。
讯享网
DM 系统允许用户随时从数据库中删除基表。
语法格式
参数
- <模式名> 指明被删除基表所属的模式,缺省为当前模式;
- <表名> 指明被删除基表的名称。
图例
表删除语句

语句功能
供具有 DBA 角色(三权分立)或 DROP ANY TABLE 权限的用户或该表的拥有者删除基表。
使用说明
- 删除不存在的基表会报错。若指定 IF EXISTS 关键字,删除不存在的表,不会报错;
- 表删除有两种方式:RESTRICT/CASCADE 方式(外部基表除外)。其中 RESTRICT 为缺省值。如果以 CASCADE 方式删除该表,将删除表中唯一列上和主关键字上的引用完整性约束,当设置 INI 参数 DROP_CASCADE_VIEW 值为 1 时,还可以删除所有建立在该基表上的视图。如果以 RESTRICT 方式删除该表,要求该表上已不存在任何视图以及引用完整性约束,否则 DM 返回错误信息,而不删除该表。当 INI 参数 DROP_CASCADE_VIEW 值为 0 时,表与其上建立的视图的依赖关系被剥离,此时使用 CASCADE 和 RESTRICT 方式删除该表都可以成功,且只会删除该表,不会删除其上的视图;
- 该表删除后,在该表上所建索引也同时被删除;
- 该表删除后,所有用户在该表上的权限也自动取消,以后系统中再建同名基表是与该表毫无关系的表;
- 删除外部基表无需指定 RESTRICT 和 CASCADE 关键字。
举例说明
例 1 用户 SYSDBA 删除 PERSON 表。
讯享网
例 2 假设当前用户为用户 SYSDBA。现要删除 PERSON_TYPE 表。为此,必须先删除 VENDOR_PERSON 表,因为它们之间存在着引用关系,VENDOR_PERSON 表为引用表,PERSON_TYPE 表为被引用表。
也可以使用 CASCADE 强制删除 PERSON_TYPE 表,但是 VENDOR_PERSON 表仍然存在,只是删除了 PERSON_TYPE 表的引用约束。
讯享网
DM 可以从表中删除所有记录。
语法格式
参数
- <模式名> 指明表所属的模式,缺省为当前模式;
- <表名> 指明被删除记录的表的名称。
- <分区名> 指明被删除分区表的名称。
图例
基表数据删除语句

语句功能
供具有 DBA 角色的用户或该表的拥有者从表中删除所有记录。
使用说明
- TRUNCATE 命令一次性删除指定表的所有记录,比用 DELETE 命令删除记录快。但 TRUNCATE 不会触发表上的 DELETE 触发器;
- 如果 TRUNCATE 删除的表上有被引用关系,且未指定 CASCADE,则此语句失败;
- 如果 TRUNCATE 删除的表上有被引用关系,且指定 CASCADE,若所有引用表的引用约束选项指定为“ON DELETE CASCADE”,则系统将级联删除所有引用表中的数据,否则将报错;
- TRUNCATE 不同于 DROP 命令,因为它保留了表结构及其上的约束和索引信息;
- TRUNCATE 命令只能用来删除表的所有的记录,而 DELETE 命令可以只删除表的部分记录。
举例说明
例 假定删除模式 PRODUCTION 中的 PRODUCT_REVIEW 表中所有的记录。
讯享网
事务型 HUGE 表删除和更新的数据都存储在对应行辅助表中,查询时还需要扫描行辅助表。当随着时间推移,行辅助表中数据量较大时,需要对数据进行重整,以免影响事务型 HUGE 表的查询效率。数据重整将事务型 HUGE 表中涉及更新和删除操作的数据区进行区内数据重整,重整后 HUGE 表中每个数据区内的数据紧密排列,但数据不会跨区移动。需要注意的是,数据重整会导致 ROWID 发生变化。
仅 with delta 的 HUGE 表支持数据重整。
语法格式
参数
- <模式名> 指明表所属的模式,缺省为当前模式;
- <表名> 指明被删除记录的表的名称;
图例
事务型 HUGE 表数据重整

语句功能
具有 DBA 角色的用户或该表的建表者才能执行此操作。
举例说明
例 对事务型 HUGE 表 ORDERS 进行重整。
讯享网
为了提高系统的查询效率,DM 系统提供了索引。但也需要注意,索引会降低那些影响索引列值的命令的执行效率,如 INSERT、UPDATE、DELETE 的性能,因为 DM 不但要维护基表数据还要维护索引数据。
语法格式
参数
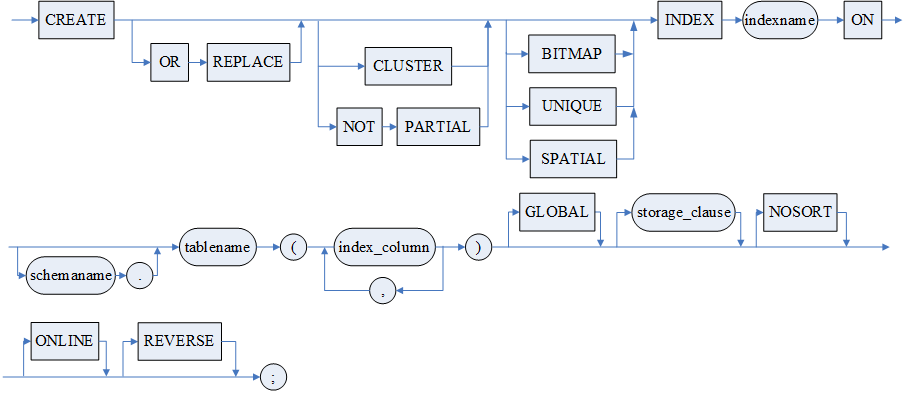
- UNIQUE 指明该索引为唯一索引;
- BITMAP 指明该索引为位图索引;
- SPATIAL 指明该索引为空间索引;
- CLUSTER 指明该索引为聚簇索引(也叫聚集索引),不能应用到函数索引中;
- NOT PARTIAL 指明该索引为非聚簇索引,缺省即为非聚簇索引;
- <索引名> 指明被创建索引的名称,索引名称最大长度 128 字节;
- <模式名> 指明被创建索引的基表属于哪个模式,缺省为当前模式;
- <表名> 指明被创建索引的基表的名称。若要在该基表中创建空间索引,该表必须包含能被空间索引识别的空间数据类型列;
- < 索引列定义> 指明创建索引的列定义。其中空间索引列的数据类型必须是 DMGEO 包内的空间类型(如 ST_GEOMETRY 等);
- <索引列表达式> 指明被创建的索引列可以为表中列、以表中列为变量的函数或表达式;
- GLOBAL 指明该索引为全局索引,缺省为局部索引。用于水平分区表,非水平分区表忽略该选项;
- <PARTITION 子句 > 创建分区索引。专门用于 DMDPC 架构下的分区表。必须和 GLOBAL 关键字一起使用才有效,不支持和 ONLINE 关键字一起使用。<PARTITION 子句 > 仅支持一级分区,且分区列必须是索引列的子集和前导列。<PARTITION 子句 > 中的 RANGE 分区必须包含 MAXVALUE 分区,LIST 分区必须包含 DEFAULT 分区。<PARTITION 子句 > 中指定的子索引表空间、<STORAGE 子句 > 中主索引的表空间,均需和主表的表空间保持一致;
- ASC 递增顺序;
- DESC 递减顺序;
- < 表空间子句 > 不能和 <STORAGE 子句 > 中的 ON < 表空间名 > 同时使用;
- <STORAGE 子句> 普通表的索引参考<STORAGE 子句 1>,HUGE 表的索引参考<STORAGE 子句 2>;
- <STORAGE 子句 1>中,BRANCH 和 NOBRANCH 只能用以指定聚集索引;
- NOSORT 指明该索引相关的列已按照索引中指定的顺序有序,不需要在建索引时排序,提高建索引的效率。若数据非有序却指定了 NOSORT,则在建索引时会报错;
- ONLINE 表示支持异步索引,即创建索引过程中可以对索引依赖的表做增、删、改操作;
- REVERSE 表示将当前索引创建为反向索引,即按索引数据的原始数据的反向排列顺序创建索引。(缺省为按原始数据的正向排列顺序创建索引);
- UNUSABLE 表示将当前索引创建为无效索引,系统不会维护无效索引,可以在 SYSOBJECTS 的 VALID 字段查看该值。对于无效索引,可以利用 REBUILD 来重建;
- <PARALLEL 项 > 指明是否并行创建索引,NOPARALLEL 表示不并行,PARALLEL 表示并行,缺省为 NOPARALLEL。指定 PARALLEL 时,需要指定并行数,并行数的合法值范围为 0~。若不指定并行数,则默认按照 INI 参数 MAX_PARALLEL_DEGREE 的值并行创建索引;若指定的并行数为 0 或超过 MAX_PARALLEL_DEGREE 的值,则同样按照 MAX_PARALLEL_DEGREE 的值并行创建索引。指定并行创建索引时,需要设置 INI 参数 PARALLEL_POLICY 的值为 1 或 2。
图例
索引定义语句
index_column

表空间子句
storage_clause
.png)
storage1

storage1 项
storage2
storage2 项

parallel_clause
语句功能
供具有 DBA 角色(三权分立)、DB_OBJECT_ADMIN 角色(四权分立)或该索引所属基表的拥有者且具有 CREATE INDEX 或 CREATE ANY INDEX 权限的用户定义索引。
使用说明
- 当索引名已存在时,若指定 OR REPLACE,则使用新索引替换原同名索引;若指定 IF NOT EXISTS,则忽略本次索引创建操作;若同时指定 OR REPLACE 和 IF NOT EXISTS,则按照 OR REPLACE 的策略执行;若均不指定,则报错;
- 索引列不得重复出现且数据类型不得为多媒体数据类型、类类型和自定义类型,二级索引列不得为本地时区类型;
- 索引列最多不能超过 63 列;
- 可以使用 STORAGE 子句指定索引的存储信息,它的参数说明参见 CREATE TABLE 语句;
- 索引的默认表空间与其基表的表空间一致;
- 索引的模式名与其基表的模式名一致;
- 索引各字段值相加得到的记录内总数据值长度不得超过页大小的 1/5,二级索引各字段值相加得到的记录内总数据值长度则不能超过 min(页大小 1/5
, 3000); - 在下列情况下,DM 利用索引可以提高性能:
- 用指定的索引列值来搜索记录;
- 用索引列的顺序来存取基表。
- 每张表中只允许有一个聚集索引,如果之前已经指定过 CLUSTER INDEX 或者指定了 CLUSTER PK,则用户新建立 CLUSTER INDEX 时系统会自动删除原先的聚集索引。但如果新建聚集索引时指定的创建方式(列,顺序)和之前的聚集索引一样,则会报错;
- 列存储表(HUGE 表)和堆表不允许建立聚集索引;
- 指定 CLUSTER INDEX 操作需要重建表上的所有索引,包括 PK 索引;若表上有唯一聚集索引且被引用,则不能创建新的聚集索引,如要创建新的聚集索引,则需先删除引用约束;
- 删除聚集索引时,缺省以 ROWID 排序,自动重建所有索引;
- 函数索引:基于函数或表达式建立的索引称为函数索引。即 < 索引列表达式 > 是以表中列为变量的函数或表达式。函数索引创建方式与普通索引一样,并且支持 UNIQUE 和 STORAGE 设置项,对于以函数或表达式为过滤的查询,创建合适的函数索引会提升查询效率;
函数索引具有以下约束:
- 表达式不允许为时间间隔类型;
- 表达式中不允许出现半透明加密列;
- 函数索引表达式的长度理论值不能超过 816 个字符(包括函数索引表达式本身的长度加上系统生成的指令长度);
- 函数索引不能为 CLUSTER 或 PRIMARY KEY 类型;
- 表达式不支持集函数和不确定函数,不确定函数为每次执行得到的结果不确定,系统中不确定函数包括:RAND、CURDATE、CURTIME、CURRENT_DATE、CURRENT_TIME、CURRENT_TIMESTAMP、GETDATE、NOW、SYSDATE、CUR_DATABASE、DBID、EXTENT、PAGE、SESSID、UID、USER、VSIZE、SET_TABLE_OPTION、SET_INDEX_OPTION、UNLOCK_LOGIN、CHECK_LOGIN、GET_AUDIT、CFALGORITHMSENCRYPT、SF_MAC_LABEL_TO_CHAR、CFALGORITHMSDECRYPT、BFALGORITHMSENCRYPT、SF_MAC_LABEL_FROM_CHAR BFALGORITHMSDECRYPT、SF_MAC_LABEL_CMP;
- 快速装载不支持含有函数索引的表;
- 若函数索引中要使用用户自定义的函数,则函数必须是指定了 DETERMINISTIC 属性的确定性函数;
- 若函数索引中使用的确定性函数发生了变更或删除,用户需手动重建函数索引;
- 若函数索引中使用的确定性函数内有不确定因素,会导致前后计算结果不同的情况。在查询使用函数索引时,使用数据插入函数索引时的计算结果为 KEY 值;修改时可能会导致在使用函数索引过程中出现根据聚集索引无法在函数索引中找到相应记录的情况,对此进行报错处理;
- 临时表不支持函数索引。
- 在水平分区表上创建索引有以下约束
- 指定 GLOBAL 关键字,创建全局索引,否则创建局部索引;
- 只有当分区键都包含在索引键中时,才能创建非全局唯一索引;
- 不能在水平分区表上创建全局聚集索引;
- 不能在水平分区表上创建局部唯一函数索引;
- HUGE 水平分区表不支持全局索引;
- 不能对水平分区子表单独建立索引。
- 非聚集索引和聚集索引不能使用 OR REPLACE 选项互相转换;
- 位图索引:创建方式和普通索引一致,对低基数的列创建位图索引,能够有效提高基于该列的查询效率,位图索引具有以下约束:
- 仅支持普通表、堆表和水平分区表创建位图索引;
- 不支持对大字段创建位图索引;
- 不支持对计算表达式列创建位图索引;
- 不支持在 UNIQUE 列和 PRIMARY KEY 上创建位图索引;
- 不支持对存在 CLUSTER KEY 的表创建位图索引;
- 仅支持单列或者不超过 63 个组合列上创建位图索引;
- MPP 环境下不支持位图索引的创建;
- 不支持全局位图索引;
- 包含位图索引的表不支持并发的插入、删除和更新操作;
- 不支持在间隔分区表上创建位图索引。
- NOSORT 不支持与[OR REPLACE]、[CLUSTER]、[BITMAP]、[ONLINE]同用;
- ONLINE 选项具有以下约束:
- 不支持与[OR REPLACE]、[CLUSTER]、[BITMAP]同用;
- 不支持 MPP 环境;
- 不支持在临时表上创建索引时指定 ONLINE 选项;
- 暂不支持列存储表创建索引时指定 ONLINE 选项;
- 建立 PRIMARY KEY,UNIQUE 约束时,隐式创建的索引不支持 ONLINE 选项;
- 函数索引支持 ONLINE 选项。
- 空间索引:创建时需指定 SPATIAL 关键字,删除方式和普通索引一样。只能在 DMGEO 包内的空间类型的列上创建。空间索引具有以下约束:
- 只支持在空间类型列上创建;
- 不支持使用 ONLINE 选项异步方式创建;
- 不支持在 MPP 环境和复制环境下创建空间索引;
- 不支持组合索引,只能在一个列上创建;
- 不支持在 4K 的页上建立空间索引;
- 不支持将空间索引创建为无效索引;
- 不支持以 NOSORT 选项进行重建;
8)不支持并发重建。
- 反向索引:创建时需指定 REVERSE 关键字。对于访问数据呈现密集且集中的场景,普通索引的查询效率较低,使用反向索引可以提高查询效率。反向索引具有以下约束:
- 不可与 NOSORT 关键字同时使用;
- 位图索引不可创建为反向索引;
- 全文索引不可创建为反向索引;
- 聚集索引不可创建为反向索引;
- 索引的列必须是支持反转的数据类型,例如数值、字符、日期、时间、时间间隔以及 BINARY 等类型,不支持 bit 和大字段类型;
- 无效索引:创建时需指定 UNUSABLE 关键字。使用无效索引需要注意:
- 不可与 NOSORT、ONLINE、OR REPLACE 关键字同时使用;
- 仅支持将二级索引创建为无效索引;
- 不支持将聚集索引、位图索引、空间索引、数组索引以及虚索引创建为无效索引;
- 不支持在水平分区子表、临时表、系统表、远程表、数组表以及位图表上创建无效索引;
- DM 通过并发重建无效索引来达到并发创建索引的效果,具体可参考 3.6.2 索引修改语句 中的说明;
- 在临时表上增删索引会导致临时表数据丢失。当 DM.INI 参数 ENABLE_TMP_TAB_ROLLBACK 为 0 时,不允许对临时表创建唯一索引。
举例说明
例 1 假设具有 DBA 权限的用户在 VENDOR 表中,以 VENDORID 为索引列建立索引 S1,以 ACCOUNTNO,NAME 为索引列建立唯一索引 S2。
讯享网
例 2 假设具有 DBA 权限的用户在 SALESPERSON 表中,需要查询比去年销售额超过 20 万的销售人员信息,该过滤条件无法使用到单列上的索引,每次查询都需要进行全表扫描,效率较低。如果在 SALESTHISYEAR-SALESLASTYEAR 上创建一个函数索引,则可以较大程度提升查询效率。
例 3 创建空间索引。
讯享网
例 4 创建反向索引。
例 5 创建无效索引。
讯享网
例 6 在 DMDPC 环境中创建全局分区索引。
为了满足用户在建立索引后还可随时修改索引的要求,DM 系统提供索引修改语句,包括修改索引名称、设置索引的查询计划可见性、改变索引有效性、重建索引和索引监控的功能。
语法格式
讯享网
参数
- <模式名> 索引所属的模式,缺省为当前模式;
- <索引名> 索引的名称。
图例
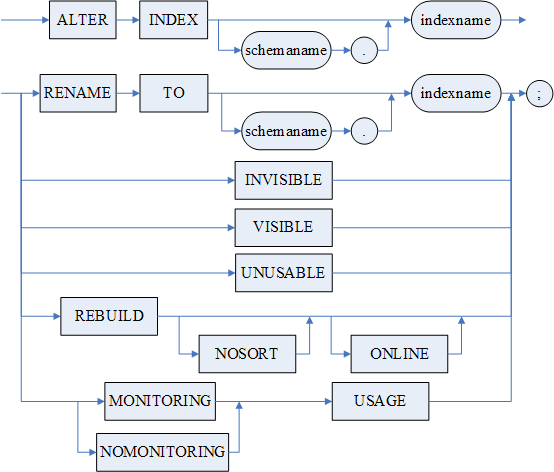
索引修改语句
语句功能
- 供具有 DBA 角色(三权分立)的用户或该索引所属基表的拥有者或具有 ALTER ANY INDEX 的用户修改索引;
- 当索引修改成 INVISIBLE 时,查询语句的执行计划不会使用该索引,该索引相关的计划不会生成,用别的计划代替。修改成 VISIBLE,则会生成索引相关的计划。默认是 VISIBLE;
- 当指定 UNUSABLE 时,索引将被置为无效状态,系统将不再维护此索引,可以在 SYSOBJECTS 的 VALID 字段查看该值。处于无效状态的索引,可以利用 REBUILD 来重建,或者先删除该索引再新建该索引。TRUNCATE 表会将该表所有失效索引置为生效;
- 当指定 REBUILD 时,将置索引的状态为生效状态。NOSORT 指定重建时不需要排序,ONLINE 子句表示重建时使用异步创建逻辑,在过程中可以对索引依赖的表做增、删、改操作;
- NOSORT 表示重建时不需要排序;
- ONLINE 表示重建时使用异步创建逻辑,在过程中可以对索引依赖的表做增、删、改操作;
- < 重建方式 > 表示重建索引的方式。缺省情况下自适应选择重建索引的方式,当待重建索引满足并发重建索引的约束时,采用并发重建索引的方式,否则采用排他重建索引的方式。
● SHARE 并发重建索引,表示不同会话同时对同一个表重建索引;
● SHARE ASYNCHRONOUS 并行重建索引,专门用于分区表,表示多个异步任务并行执行对同一个索引的重建任务。当分区表的数据量较大无法一次全部放入内存时,EXCLUSIVE 方式会导致磁盘 I/O 出现明显的波动,单个索引重建性能较差。此时若机器性能较好(CPU 核数较多、I/O 性能较好),则可通过指定并行重建的方式来提高单个索引重建的性能。
● EXCLUSIVE 排他重建索引,表示不允许并发重建索引或并行重建索引。
- MONITORING USAGE 对指定索引进行监控;NOMONITORING USAGE 对指定索引取消监控。索引监控(MONITORING USAGE)仅支持对用户创建的二级索引进行监控,且不支持监控虚索引、系统索引、聚集索引、数组索引,相关监控信息可查看动态视图 V$OBJECT_USAGE。
使用说明
- 使用者应拥有 DBA 权限或是该索引所属基表的拥有者;
- <INVISIBLE | VISIBLE> 仅支持表的二级索引修改,对聚集索引不起作用;
- UNUSABLE 和 REBUILD EXCLUSIVE 仅支持对二级索引的修改,不支持位图索引、聚集索引、虚索引、水平分区子表和临时表上索引的修改;
- 当把主键对应的索引设置为 UNUSABLE 时,不能再对表进行插入和更新操作;
- REBUILD 是 UNUSABLE 的逆向操作,REBUILD 支持并发重建索引、并行重建索引以及排他重建索引。并发重建索引以及并行重建索引要求索引必须为 UNUSABLE 的,排他重建索引则无此限制;
- 空间索引和数组索引不支持以 ONLINE 或 NOSORT 选项进行重建;
- SHARE 并发重建索引具有以下约束:
- 不可与 NOSORT、ONLINE 关键字同时使用;
- 仅支持并发重建无效索引;
- 仅支持并发重建二级索引;
- 不支持并发重建聚集索引、位图索引、空间索引、数组索引以及虚索引;
- 不支持并发重建位于水平分区子表、临时表、系统表、远程表、数组表或者位图表上的索引。
- SHARE ASYNCHRONOUS 并行重建索引具有以下约束:
- 不可与 NOSORT、ONLINE 关键字同时使用;
- 仅支持并行重建无效索引;
- 仅支持并行重建二级索引;
- 不支持并行重建聚集索引、位图索引、空间索引、数组索引、虚索引以及全局索引;
- 仅支持并行重建分区表上的索引;
- 不支持并行重建水平分区子表、临时表、系统表、远程表、数组表或者位图表上的索引;
- 低性能机器(CPU 核数过少、I/O 性能不足)不适用于指定并行重建索引。
- < 异步任务数 > 并行重建时的异步任务个数。< 异步任务数 > 的取值具有以下约束:
- 异步任务数的取值范围为 2~100 之间的整数,若取值小于 2,则无法并行重建索引,若取值大于 100,则调整异步任务数为 100。缺省时,系统将自适应选择异步任务数,系统自适应选择的异步任务数最大为 16;
- 建议取值不超过需要执行 INDEX ON 分区子表的个数;
- 建议取值不超过 INI 参数 TASK_THREADS 的取值;
- 当内存资源紧张时,建议适当调小异步任务数。
- 附加回滚记录(包含 RPTR 字段)的二级索引不支持异步重建;
- 当 INI 参数 MONITOR_INDEX_FLAG 为 1 或 2 时,使用 ALTER INDEX 方式设置索引监控失效。
举例说明
例 1 具有 DBA 权限的用户需要重命名 S1 索引可用以下语句实现。
例 2 当索引为 VISIBLE 时,查询语句执行计划如下:
讯享网
修改索引为 INVISIBLE 后,查询语句执行计划如下:
例 3 使用 UNUSABLE 将索引置为无效状态。
讯享网
例 4 并发重建索引。
例 5 并行重建分区表上的索引。
讯享网
例 6 排他重建索引。
DM 系统允许用户在建立索引后还可随时删除索引。
语法格式
讯享网
参数
- <模式名> 指明被删除索引所属的模式,缺省为当前模式;
- <索引名> 指明被删除索引的名称。
图例
索引删除语句

语句功能
供具有 DBA 角色(三权分立)的用户或该索引所属基表的拥有者删除索引。
使用说明
- 使用者应拥有 DBA 权限或是该索引所属基表的拥有者;
- 删除不存在的索引会报错。若指定 IF EXISTS 关键字,删除不存在的索引,不会报错。
举例说明
例 具有 DBA 权限的用户需要删除 S2 索引可用以下语句实现。
位图连接索引是一种通过连接实现提高海量数据查询效率的有效方式,主要用于数据仓库环境中。它是针对两个或者多个表连接的位图索引,同时保存了连接的位图结果。对于列中的每一个值,该索引保存了索引表中对应行的 ROWID。
语法格式
讯享网
参数
- OR REPLACE:只支持在第一次创建时使用 OR REPLACE,重建时不支持 OR REPLACE;
- ON 子句:指定的表为事实表,括号内的列既可以是事实表的列也可以是维度表的列;
- FROM 子句:指定参与连接的表;
- WHERE 子句:指定连接条件;
- 其他参数说明请参考本章 3.6 索引管理。
图例
位图连接索引定义语句

bitmap_join_index_clause


index_column
语句功能
供具有 DBA 角色(三权分立)、DB_OBJECT_ADMIN 角色(四权分立)或该索引所属基表的拥有者且具有 CREATE INDEX 或 CREATE ANY INDEX 权限的用户定义索引。
使用说明
- 适用于常规索引的基本限制也适用于位图连接索引;
- 用于连接的列必须是维度表中的主键或存在唯一约束;如果是复合主键,则必须使用复合主键中的所有列;
- 当多个事务同时使用位图连接索引时,同一时间只允许更新一个表;
- 连接索引创建时,基表只允许出现一次;
- 不允许对存在 CLUSTER KEY 的表创建位图连接索引;
- 位图连接索引表(内部辅助表,命名为 BMJ$_索引名)仅支持 SELECT 操作,其他操作都不支持:如 INSERT、DELETE、UPDATE、ALTER、DROP 和建索引等;
- 不支持对位图连接索引所在事实表和维度表的备份还原,不支持位图连接索引表的表级备份还原;
- 不支持位图连接索引表、位图连接索引以及虚索引的导出导入;
- 位图连接索引及其相关表不支持快速装载;
- 位图连接索引名称的长度限制为:事实表名的长度 + 索引名称长度 +6<128;
- 支持普通表、堆表和 HUGE 表;
- WHERE 条件只能是列与列之间的等值连接,并且必须含有所有表;
- 事实表上聚集索引和位图连接索引不能同时存在;
- 不支持对含有位图连接索引的表中的数据执行 DML,如需要执行 DML,则先删除该索引;
- 含有位图连接索引的表不支持下列 DDL 操作:删除、修改表约束,删除、修改列,更改表名。另外,含位图连接索引的堆表不支持添加列操作;
- 不允许对含有位图连接索引的表并发操作;
- 创建位图连接索引时,在存储参数中可指定存储位图的字节数,有效值为:4~2048,服务器自动校正为 4 的倍数,默认值为 128。如 STORAGE(SECTION(4)),表示使用 4 个字节存储位图信息。
举例说明
创建位图连接索引:
执行查询:
讯享网
如果不需要位图连接索引可以使用删除语句删除。
删除(位图连接)索引语句格式:
参数
参数说明请参考本章 3.6 管理索引。
举例说明
例如:
讯享网
用户可以在指定的表的文本列上建立全文索引。
语法格式
参数
- <索引名> 指明要创建的全文索引的名称,由于系统会为全文索引名加上前缀与后缀,因此用户指定的全文索引名长度不能超过 122 字节;
- <模式名> 指明要创建全文索引的基表属于哪个模式,缺省为当前模式;
- <表名> 指明要创建全文索引的基表的名称;
- <列名> 指明基表中要创建全文索引的列的名称;
- <分词参数> 指明全文索引分词器的分词参数;
- <storage 子句> 只有指定表空间参数有效,其他参数无效(即 STORAGE ON xxx 或者 TABLESPACE xxx 有效,而诸如 INITIAL、NEXT 等无效);
- <SYNC 子句 > 用于指定全文索引的更新方式,即将表中的数据更新到全文索引中。只有更新过的全文索引才能被检索,因此,在创建全文索引时或者使用全文索引之前,必须对全文索引进行更新。指定 SYNC 表示系统将在建立全文索引时对全文索引执行一次完全更新,如果此处未指定 SYNC,创建全文索引后系统不会进行全文索引完全更新,那么必须使用使用指定了 REBUILD 的全文索引更新语句来执行一次完全更新,全文索引才可以被使用;指定 TRANSACTION 表示每次事务提交后,若基表数据发生变化,系统会自动以增量更新方式再次更新全文索引,不需要用户手动填充。
图例
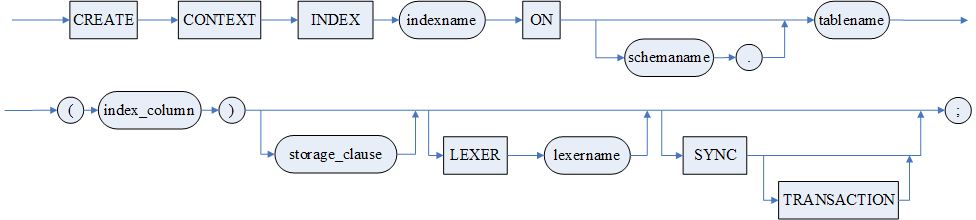
全文索引定义语句
语句功能
供具有 DBA 角色(三权分立)、DB_OBJECT_ADMIN 角色(四权分立)或该全文索引基表的拥有者且具有 CREATE CONTEXT INDEX 或 CREATE ANY CONTEXT INDEX 权限的用户,在指定的表的文本列上建立全文索引。
使用说明
- 全文索引必须在一般用户表上定义,而不能在系统表、视图、临时表、列存储表和外部表上定义;
- 一个全文索引只作用于表的一个文本列,不允许为组合列和计算列;
- 同一列只允许创建一个全文索引;
- <列名>为文本列,类型可为 CHAR、CHARACTER、VARCHAR、LONGVARCHAR、TEXT 或 CLOB;
- TEXT、CLOB 类型的列可存储二进制字符流数据。如果用于存储 DM 全文检索模块能识别的格式简单的文本文件(如.txt,html 等),则可为其建立全文索引;
- 全文索引支持简体中文和英文;
- 分词参数有 5 种:CHINESE_LEXER,中文最少分词;CHINESE_VGRAM_LEXER,机械双字分词,CHINESE_FP_LEXER,中文最多分词;ENGLISH_LEXER,英文分词;DEFAULT_LEXER,中英文最少分词,也是默认分词;
- 全文索引更新方式分为完全更新和增量更新。一个全文索引需要执行一次完全更新和若干次增量更新。完全更新的方式有两种:一是创建全文索引时,通过指定 <SYNC 子句 > 在建完全索引的同时对完全索引进行完全更新;二是在使用全文索引之前,执行指定了 REBUILD 的更新语句实现;二者选择其一即可。增量更新为每当表中数据发生增量变化后,以增量更新的方式再次更新全文索引。增量更新的方式有两种:一是通过指定 <SYNC 子句 > 的 TRANSACTION 实现;二是执行指定了 INCREMENT 关键字的更新语句实现;二者可搭配使用;
- 不支持快速装载建有全文索引的表。
举例说明
例 用户 SYSDBA 需要在 PERSON 模式下的 ADDRESS 表的 ADDRES1 列上创建全文索引,可以用下面的语句:
讯享网
全文索引需要根据基表的数据变化进行索引数据更新。若基表数据发生变化而没有及时更新全文索引,会引起全文检索结果不正确。
使用全文索引修改语句对全文索引进行完全更新和增量更新,使得全文索引的内容与表数据保持同步。
语法格式
参数
- <索引名> 指明**作的全文索引的名称;
- <模式名> 指明**作的全文索引属于哪个模式,缺省为当前模式;
- <表名> 指明**作的基表的名称。
图例
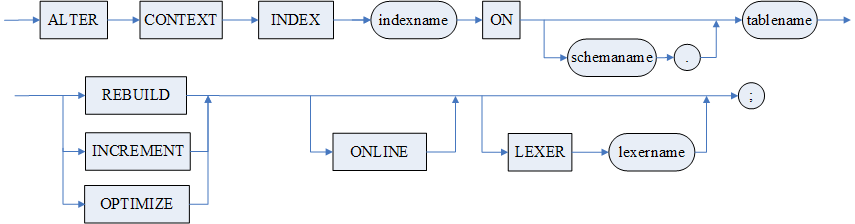
全文索引修改语句
语句功能
供具有 DBA 角色(三权分立)的用户,或该全文索引基表的拥有者(拥有者需同时具有 ALTER CONTEXT INDEX 权限),或具有 ALTER ANY CONTEXT INDEX 权限的用户在指定的表的文本列上修改全文索引。
REBUILD 为完全更新,此方式首先会将全文索引的辅助表清空,再将基表中所有记录逐个取出,根据分词算法获得分词结果(即字/词所在记录的 ROWID 和出现次数,出现次数又叫词频),并保存在词表中。INCREMENT 为增量更新,此方式只是将基表中发生数据变化的记录执行分词并保存分词结果。OPTIMIZE 操作仅仅对全文索引辅助表进行优化,去除冗余信息,不影响查询结果。
使用说明
- 只有在创建全文索引时未使用 SYNC 选项,才需要指定 REBUILD 对全文索引进行一次全面更新,然后才能进行全文检索;
- 当表中该列数据发生了改变,为了对改变后的数据进行检索,需要使用 INCREMENT 再次更新全文索引信息,才能检索到改变后的信息;
- DM 服务器启动时,不会自动加载词库,而是在第一次执行全文索引更新时加载,之后直到服务器停止才释放;
- 在完全更新全文索引后,如果表数据发生少量更新,利用 INCREMENT 增量填充方式更新全文索引可以提高效率;
- 语句中指定 ONLINE 选项时,指明对全文索引进行异步填充,允许同时对全文索引所在的表进行增删改操作;
- LEXER 子句只能与 REBUILD 方式一起使用;
- 在 DMDSC 环境下更新全文索引前,需要手动将执行码目录下的 SYSWORD.UTF8.LIB 文件复制到库所在的 DMASM 路径下,否则会导致全文索引词库加载错误。
例 用户 SYSDBA 需要在 PERSON 模式下的 ADDRESS 表的 ADDRES1 列上完全填充全文索引,可以用下面的语句:
讯享网
删除全文索引。
语法格式
参数
- <索引名> 指明**作的全文索引的名称;
- <模式名> 指明**作的全文索引属于哪个模式,缺省为当前模式;
- <表名> 指明**作的基表的名称。
图例
全文索引删除语句
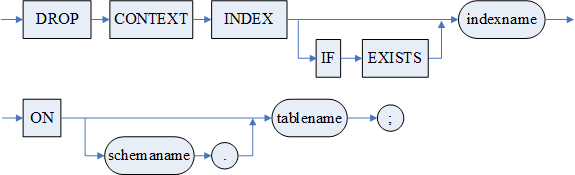
语句功能
供具有 DBA 角色(三权分立)的用户或该全文索引基表的拥有者或该全文索引所属基表的拥有者删除全文索引,包括删除数据字典中的相应信息和全文索引内容。
使用说明
- 删除不存在的全文索引会报错。若指定 IF EXISTS 关键字,删除不存在的全文索引,不会报错;
- 除了该语句可删除全文索引外,当数据库模式发生如下改变时,系统将自动调用全文索引删除模块:
1)删除表时,删除表上的全文索引;
2)删除建立了全文索引的列时,删除列上的全文索引;
- 不允许修改建有全文索引的列。
举例说明
例 用户 SYSDBA 需要删除在 PERSON 模式下 ADDRESS 表的全文索引,可以用下面的语句:
讯享网
空间索引创建与删除请参考 3.6 管理索引。
空间数据并不能直接进行比较,根据空间数据查询大多是根据空间函数进行查询。若要使用空间索引,需要满足如下条件:
- 使用 DMGEO 包内的空间函数作为查询条件。当前 DMGEO 包中能够使用空间索引的函数如下: DMGEO 包内使用到空间索引的函数有:DMGEO.ST_WITHIN、DMGEO.ST_DISTANCE、DMGEO.ST_DISJOINT、DMGEO.ST_EQUALS、DMGEO.ST_TOUCHES、DMGEO.ST_OVERLAPS、DMGEO.ST_CROSSES、DMGEO.ST_INTERSECTS、DMGEO.ST_CONTAINS、DMGEO.ST_ENVINTERSECTS 等,具体可参考《DM8 系统包使用手册》中对 DMGEO 包的介绍;
- 空间函数中与之比较的空间数据可以是常量,也可以是空间数据类型列;
- 对于 ST_DISTANCE,仅支持<和<=某个常量值的条件;
- 对于其他的返回 1 和 0 表示 TRUE 和 FALSE 的函数,支持缺省比较条件,=1 的比较条件或者=TRUE 的比较条件。
举例说明
例 1 数据库中已创建名为“testgeo”的表,表中包含名为“geom”的 DMGEO 几何类型列,且尚未对该列添加空间索引。
首先基于 DMGEO 几何类型列创建空间索引。
查询表中被指定空间对象包含的数据。
讯享网
或
例 2 查询表中据制定空间对象距离小于 10 的数据
讯享网
数组索引指在一个只包含单个数组成员的对象列上创建的索引。
语法格式
使用说明
- 暂不支持在水平分区表上创建数组索引;
- 暂时不支持在有数组索引表上进行批量装载(数组索引失效的例外);
- 支持创建数组索引的对象只能包含数组一个成员。数组可以是 DM 静态数组、动态数组或者 ORACLE 兼容的嵌套表或 VARRAY;
- 数组项类型只能是可比较的标量类型,不支持复合类型、对象类型或大字段类型;
- 临时表不支持;
- 数组索引不支持改名;
- 数组索引列不支持改名;
- 数组索引只能是单索引,不能为组合索引;
- 不支持空值的检索;
- MPP 环境不支持数组索引。
数组索引修改语句与普通索引用法相同,请参考 3.6 索引管理。与普通索引不同的是,数组索引不支持 NOSORT 和 ONLINE 用法。
使用数组索引进行查询,必须使用谓词 CONTAINS。
语法格式
讯享网
参数
- val:必须为与对象列数组项相同或可转换的标量类型表达式。
- arr_var_exp:必须为数组类型(DM 静态数组、动态数组或者 ORACLE 兼容的嵌套表或 VARRAY),其数组项类型必须与对象列数组项类型相同或可转换。
举例说明
数组索引删除语句与普通索引用法相同,请参考 3.6 索引管理。
序列是一个数据库实体,通过它多个用户可以产生唯一整数值,可以用序列来自动地生成主关键字值。
语法格式
讯享网
参数
- <模式名> 指明被创建的序列属于哪个模式,缺省为当前模式;
- <序列名> 指明被创建的序列的名称,序列名称最大长度 128 字节;
- <增量值> 指定序列数之间的间隔,这个值可以是[-,]之间任意的 DM 正整数或负整数,但不能为 0。如果此值为负,序列是下降的,如果此值为正,序列是上升的。如果忽略 INCREMENT BY 子句,则间隔缺省为 1。增量值的绝对值必须小于等于(<最大值> - <最小值>);
- <初值> 指定被生成的第一个序列数,可以用这个选项来从比最小值大的一个值开始升序序列或比最大值小的一个值开始降序序列。对于升序序列,缺省值为序列的最小值,对于降序序列,缺省值为序列的最大值;
- <最大值> 指定序列能生成的最大值,如果忽略 MAXVALUE 子句,则降序序列的最大值缺省为-1,升序序列的最大值缺省为 (0x7FFFFFFFFFFFFFFF),若指定的最大值超出缺省最大值,则 DM 自动将最大值置为缺省最大值。非循环序列在到达最大值之后,将不能继续生成序列数;
- <最小值> 指定序列能生成的最小值,如果忽略 MINVALUE 子句,则升序序列的最小值缺省为 1,降序序列的最小值缺省为-(0x00000),若指定的最小值超出缺省最小值,则 DM 自动将最小值置为缺省最小值。循环序列在到达最小值之后,将不能继续生成序列数。最小值必须小于最大值;
- CYCLE 该关键字指定序列为循环序列:当序列的值达到最大值/最小值时,序列将从最小值/最大值计数;
- NOCYCLE 该关键字指定序列为非循环序列:当序列的值达到最大值/最小值时,序列将不再产生新值;
- CACHE 该关键字表示序列的值是预先分配,并保持在内存中,以便更快地访问。< 缓存值 > 指定预先分配的值的个数,最小值为 2,最大值不大于 ;
- NOCACHE 该关键字表示序列的值是不预先分配;
- ORDER 该关键字表示以保证请求顺序生成序列号;
- NOORDER 该关键字表示不保证请求顺序生成序列号;
- GLOBAL 该关键字表示 MPP 环境下序列为全局序列,缺省为 GLOBAL;
- LOCAL 该关键字表示 MPP 环境下序列为本地序列。
图例
序列定义语句

sequence_option
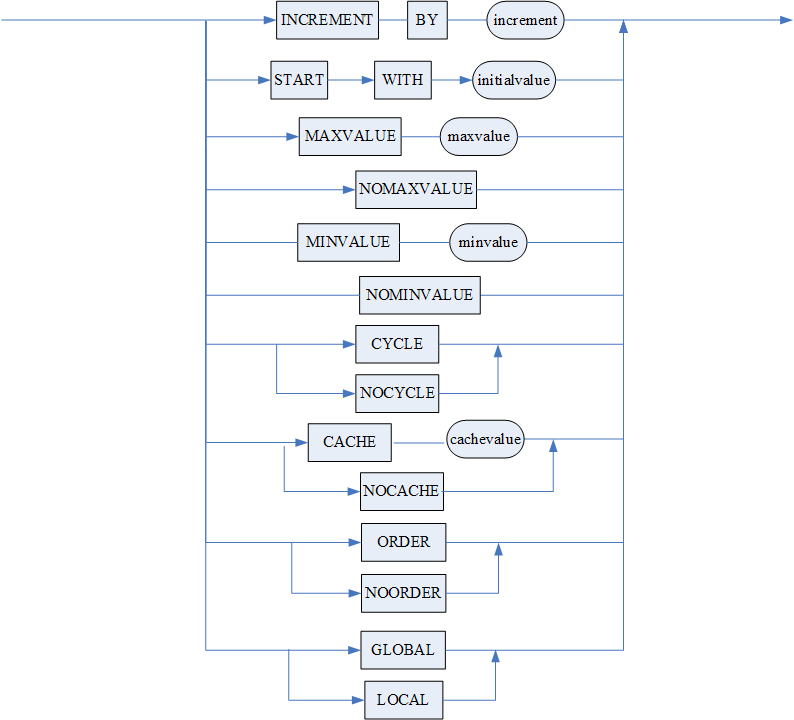
语句功能
创建一个序列。供具有 DBA 角色(三权分立)、DB_OBJECT_ADMIN 角色(四权分立)或具有 CREATE SEQUENCE 或 CREATE ANY SEQUENCE 权限的用户才能创建序列。
使用说明
- 一旦序列生成,就可以在 SQL 语句中用以下伪列来存取序列的值;
- CURRVAL 返回当前的序列值;
- NEXTVAL 如果为升序序列,序列值增加并返回增加后的值;如果为降序序列,序列值减少并返回减少后的值。如果第一次对序列使用该函数,则返回序列当前值;
- 用户会话在第一次使用 CURRVAL 之前应先使用 NEXTVAL 获取序列当前值;之后除非会话使用 NEXTVAL 获取序列当前值,否则每次使用 CURRVAL 返回的值不变。
- 缺省序列:如果在序列中什么也没有指出则缺省生成序列,一个从 1 开始增量为 1 且无限上升(最大值为 )的升序序列;仅指出 INCREMENT BY-1,将创建一个从-1 开始且无限下降(最小值为-)的降序序列;
- LOCAL 类型序列的最高 10 位用来记录标识 MPP 节点号,因此 LOCAL 类型的序列值和 GLOBAL 类型序列在范围、最大值、最小值上都有所差别。LOCAL 类型序列创建时可设置的最大值、最小值分别为 40991、-40992。需要注意的是,最高 10 位设置了 MPP 站点号以后,序列的真实值实际上可能不会在序列定义的最大最小值范围内。
举例说明
例 创建序列 SEQ_QUANTITY,将序列的前两个值插入表 PRODUCTION.PRODUCT_INVENTORY 中。
DM 系统提供序列修改语句,包括修改序列步长值、设置序列最大值和最小值、改变序列的缓存值、循环属性、ORDER 属性、当前值、为序列重命名等。
语法格式
讯享网
参数
< 新序列名 > 指修改后的序列的名字。
其余参数与序列定义语句的参数相同。
图例
序列修改语句

sequence_modify_option

sequence_rename_option
语句功能
修改一个序列。供具有 DBA 角色(三权分立) 或该序列的拥有者或具有 ALTER ANY SEQUENCE 权限的用户才修改序列。
使用说明
- 关于步长的修改,分两种情况:
a) 如果在修改前没有用 NEXTVAL 访问序列,创建完序列后直接修改序列步长值,则序列的当前值为起始值加上新步长值与旧步长值的差。此时序列的当前值可能超出最大值与最小值的限定范围,若序列当前值小于序列最小值,则将序列当前值作为新的序列最小值;若序列当前值大于序列最大值,则将序列当前值作为新的序列最大值。针对当前值超出原始限定范围的序列,导出时将报错;
b) 如果在修改前用 NEXTVAL 访问了序列,然后修改序列步长值,则再次访问序列的当前值为序列的上一次的值加上新步长值。
- 缺省序列选项:如果在修改序列语句中没有指出某选项则缺省是修改前的选项值。不允许未指定任何选项、禁止重复或冲突的选项说明;
- 序列的起始值不能修改;
- 修改序列的最小值不能大于起始值、最大值不能小于起始值;
- 修改序列的步长的绝对值必须小于 MAXVALUE 与 MINVALUE 的差;
- 修改序列的当前值时,指定的当前值不能大于最大值,不能小于最小值;
- 修改序列的当前值后,需要使用 NEXTVAL 获取修改后的序列当前值;
- 关于序列重命名选项:
a) 重命名只修改序列的名称,不改变序列所属模式;
b) 重命名选项不能与其他序列修改选项一起使用,否则进行语法报错。
举例说明
例 1 创建完序列后直接修改序列的步长。
查询结果为:-994
由于-994 小于序列最小值 1,因此将-994 作为新的序列最小值,序列取值范围变成-994~。但是该序列不支持导出,导出时将报错。
例 2 创建序列后使用 NEXTVAL 访问了序列,然后修改步长。
讯享网
查询结果为:6
例 3 修改序列的最小值。
例 4 修改序列的当前值。
讯享网
查询结果为:300
例 5 重命名序列 SEQ5 为 SEQ6。
查询结果为:100
DM 系统允许用户在建立序列后还可随时删除序列。
语法格式
讯享网
参数
- <模式名> 指明被删除序列所属的模式,缺省为当前模式;
- <序列名> 指明被删除序列的名称。
图例
序列删除语句

语句功能
供具有 DBA 角色(三权分立)的用户或该序列的拥有者或具有 DROP ANY SEQUENCE 权限的用户从数据库中删除序列生成器。
使用说明
- 删除不存在的序列会报错。若指定 IF EXISTS 关键字,删除不存在的序列,不会报错;
- 一种重新启动序列生成器的方法就是删除它然后再重新创建,例如有一序列生成器当前值为 150,而且用户想要从值 27 开始重新启动此序列生成器,他可以:
1)删除此序列生成器;
2)重新以相同的名字创建序列生成器,START WITH 选项值为 27。
举例说明
例 用户 SYSDBA 需要删除序列 SEQ_QUANTITY,可以用下面的语句:
为了支持 SQL 标准中的域对象定义与使用,DM 支持 DOMAIN 的创建、删除以及授权 DDL 语句,并支持在表定义中使用 DOMAIN。
域(DOMAIN)是一个可允许值的集合。域在模式中定义,并由<域名>标识。域是用来约束由各种操作存储于基表中某列的有效值集。域定义说明一种数据类型,它也能进一步说明约束域的有效值的<域约束>,还可说明一个<缺省子句>,该子句规定没有显式指定值时所要用的值或列的缺省值。
CREATE DOMAIN 创建一个新的数据域。定义域的用户成为其所有者。DOMAIN 为模式类型对象,其名称在模式内唯一。
语法格式
讯享网
参数
- [< 模式名 >.] <domain_name> 为要创建的域名字,可以有模式前缀。如果在 CREATE SCHEMA 语句中定义了 DOMAIN,则<domain_name> 的模式前缀(如果有)必须与创建的模式名一致。
- < 数据类型 > 域的数据类型。仅支持定义标准的 SQL 数据类型。
- <default_clause> DEFAULT 子句为域数据类型的字段声明一个缺省值。该值是任何不含变量的表达式(但不允许子查询)。缺省表达式的数据类型必需匹配域的数据类型。如果没有声明缺省值,那么缺省值就是空值。缺省表达式将用在任何为该字段声明数值的插入操作。如果为特定的字段声明了缺省值,那么它覆盖任何和该域相关联的缺省值。
- <constraint name definition> 一个约束的可选名称。如果没有名称,系统生成一个名字。
- <check constraint definition> CHECK 子句声明完整性约束或者是测试,域的数值必须满足这些要求。每个约束必须是一个生成一个布尔结果的表达式。它应该使用名字 VALUE 来引用被测试的数值。CHECK 表达式不能包含子查询,也不能引用除 VALUE 之外的变量。
图例
创建 DOMAIN

<domain constraint>

语句功能
供具有 DBA 角色(三权分立)、DB_OBJECT_ADMIN 角色(四权分立)或 具有 CREATE DOMAIN 或 CREATE ANY DOMAIN 系统权限的用户创建 DOMAIN。
举例说明
在表定义语句中,支持为表列声明使用域。如果列声明的类型定义使用域引用,则此列定义直接继承域中的数据类型、缺省值以及 CHECK 约束。如果列定义使用域,然后又自己定义了缺省值,则最终使用自己定义的缺省值。
用户可以使用自己的域。如果要使用其它用户的域,则必须被授予了该域的 USAGE 权限。DBA 角色默认拥有此权限。
例 在 T 表中使用第 1 节中创建的域 DA。
讯享网
列定义虽然使用了域,但其 SYSCOLUMNS 系统表中类型相关字段记录域定义的数据类型,也就是说,从 SYSCOLUMNS 系统表中不会表现出对域的引用。
使用说明
使用某个域的用户必须具有 DBA 角色(三权分立)、DB_OBJECT_ADMIN 角色(四权分立)或该域的 USAGE DOMAIN 或 USAGE ANY DOMAIN 权限。
语法格式
参数
RESTRICT 表示仅当 DOMAIN 未被表列使用时才可以被删除; CASCADE 表示级联删除。
图例
删除 DOMAIN
语句功能
删除一个用户定义的域。用户可以删除自己拥有的域,具有 DBA 角色(三权分立)或 DROP ANY DOMAIN 系统权限的用户则可以删除任意模式下的域。
使用说明
删除不存在的 DOMAIN 会报错。若指定 IF EXISTS 关键字,删除不存在的 DOMAIN,不会报错。
举例说明
讯享网
CONTEXT 上下文提供了一组设置以及访问服务器运行时应用数据的接口,通过这些接口可以有效控制应用数据的修改和访问。
CONTEXT 上下文有一个库级唯一的标识:名字空间(NAMESPACE),该名字空间保存了(NAME-VALUE)格式的数据,该数据通过 DBMS_SESSION 包中的过程设置其值,并通过 SYS_CONTEXT 系统函数访问其值。
应用上下文可以访问当前会话的一些属性信息,例如当前会话的 ID、模式名、用户名等。在实际应用过程中,将这些信息添加到查询的过滤条件中,起到允许或者禁止某些用户访问这些应用数据的目的。
创建上下文。
语法格式
参数
- OR REPLACE 使用一个不同的 package 重新定义 namespace;
- <namespace> 上下文的名字空间,保存到系统表 sysobjects 中,其模式为 SYS;
- <模式名> 上下文关联的 package 的模式,默认为当前模式;
- <packagename> 上下文关联的包,创建上下文不会影响已有的 package;
图例
创建上下文

语句功能
创建一个上下文 namespace,namespace 通过关联的 DMSQL 程序包来管理上下文的属性和值。属性和值就是用户的会话信息。
具有 DBA 角色(三权分立)、DB_OBJECT_ADMIN 角色(四权分立)或具有 CREATE ANY CONTEXT 权限的用户,才可以创建上下文。
使用说明
- 通过 DBMS_SESSION 包的 SET_CONTEXT 过程设置上下文的属性和值,具体可参考《DM8 系统包使用手册》第 17 章;
- 通过系统函数 SYS_CONTEXT 访问 CONTEXT namespace 的属性值。其语法如下:
讯享网
使用说明如下:
- namespace:已创建的 namespace,不区分大小写,如果不存在,则报错;
- parameter:namespace 中的属性,不区分大小写,如果不存在,则返回 NULL;最大长度 30bytes;
- 函数返回值类型为 varchar(256),如果返回值超过 256 字节,则需要设置 length。length 为 INT 类型,最大值为 4000,即返回字符串最大长度为 4000 字节;如果指定的 length 值非法,则忽略该值,而使用默认值 256。
- 会话建立之后,只能通过关联的 package 来修改 namespace 内的属性值。namespace 中的属性值只允许会话级访问,即只有设置其属性值的会话才可以访问该值,其他会话访问该属性值都为空。namespace 保存的属性值为系统运行时的动态数据,服务器重启后该数据会丢失;
- 成功创建上下文后,其信息保存在系统表 SYSOBJECTS 中,详见下表:
- USERENV 为系统默认的上下文名字空间,保存了用户的上下文信息,属性如下:
- 动态视图 V$CONTEXT 显示当前会话所有上下文的名字空间、属性和值。
删除上下文。
语法格式
图例
删除上下文

语句功能
从数据库中删除上下文的 namespace,即从系统表 SYSOBJECTS 中删除。如果 namespace 不存在,则报错。如果该 namespace 成功删除,但之前已添加了属性和值,那么会话仍可以访问该属性值。即其删除的是字典对象,其实例对象不会删除。
具有 DBA 角色(三权分立)、DB_OBJECT_ADMIN 角色(四权分立)或具有 DROP ANY CONTEXT 权限的用户,才可以删除上下文。
使用说明
删除不存在的上下文会报错。若指定 IF EXISTS 关键字,删除不存在的上下文,不会报错。
举例说明
如何使用上下文。
第一步 创建 package:
讯享网
第二步 创建 context
第三步 设置 namespace 的属性
讯享网
第四步 查询该属性值
打印值为:
讯享网
创建一个目录对象。目录是操作系统文件在数据库中的一个映射。
语法格式
参数
- <目录名> 创建的目录的名称
图例
创建目录

语句功能
供具有 DBA 角色(三权分立)、DB_OBJECT_ADMIN 角色(四权分立)或具有 CREATE ANY DIRECTORY 权限的用户创建一个目录对象。
举例说明
例 先创建名为 GYFDIR 的目录,再使用导出工具将文件导出到该目录。
讯享网
删除一个目录对象。
语法格式
参数
- <目录名> 要删除的目录的名称
图例
删除目录

语句功能
具有 DBA 角色(三权分立)、DB_OBJECT_ADMIN 角色(四权分立)或具有 DROP ANY DIRECTORY 权限的用户删除一个目录对象。
使用说明
删除不存在的目录会报错。若指定 IF EXISTS 关键字,删除不存在的目录,不会报错。
设置当前会话时区信息
语法格式
讯享网
参数
<时区> 指明要设置的时区信息;
图例
时区信息

语句功能
设置当前会话时区信息。
使用说明
仅当前会话有效。
举例说明
例 设置当前会话时区为'+9:00'。
例 设置当前会话时区为服务器所在地时区。
讯享网
设置当前会话的日期串语言。
语法格式
图例
日期串语言

语句功能
设置当前会话日期串语言。
使用说明
仅当前会话有效。设置语言为 ENGLISH 和 AMERICAN 时,添加引号也不报错。
举例说明
例 设置当前会话日期串为 ENGLISH。
讯享网
设置当前会话的日期串格式。
语法格式
图例
日期串格式

语句功能
设置当前会话的日期串格式。
参数
- NLS_DATE_FORMAT / NLS_TIMESTAMP_FORMAT / NLS_TIMESTAMP_TZ_FORMAT / NLS_TIME_FORMAT / NLS_TIME_TZ_FORMAT 分别用于指定 DATE / TIMESTAMP / TIMESTAMP_TZ / TIME / TIME_TZ 类型的格式;
- < 日期格式 > 日期格式具体用法请参考 8.3 小节中的日期格式。
使用说明
- 仅当前会话有效;
- 当 COMPATIBLE_MODE=2 且 ORA_DATE_FMT=0 时,修改 NLS_DATE_FORMAT 时实际修改的是 NLS_TIMESTAMP_FORMAT。
举例说明
例 设置当前会话日期格式为不同的格式。
讯享网
设置当前会话的自然语言排序方式。
语法格式
图例
自然语言排序方式
语句功能
设置当前会话的自然语言排序方式。
参数
< 排序方式 >:BINARY 表示按默认字符集二进制编码排序;SCHINESE_PINYIN_M 表示按中文拼音排序;SCHINESE_STROKE_M 表示按中文笔画排序;SCHINESE_RADICAL_M 表示按中文部首排序;THAI_CI_AS 表示按泰文排序;KOREAN_M 表示按韩文排序。
使用说明
- 仅当前会话有效。
- 仅字符集为 UTF-8 的数据库支持自然语言按泰文排序。
举例说明
例 设置当前会话的自然语言按照中文拼音排序。
讯享网
设置当前会话的大小写敏感属性。
语法格式
图例
大小写敏感属性
语句功能
设置当前会话的大小写敏感属性。
参数
< 属性 >:设置为 DEFAULT 时,代表会话与当前数据库的大小写敏感属性保持一致;设置为 TRUE 时,代表在大小写不敏感的库上可以使得会话中的字符类型数据以大小写敏感的方式进行比较,而在大小写敏感的库上则维持原始方式比较;设置为 FALSE 时,代表在大小写敏感的库上可以使得会话中的字符类型数据以大小写不敏感的方式进行比较,而在大小写不敏感的库上则维持原始方式比较。
使用说明
- 仅当前会话有效。
- 仅对字符类型生效,其他数据类型忽略该会话属性。
- 创建索引时忽略该会话属性。
- 确定性函数参数忽略该会话属性。
- CONTAINS 表达式忽略该会话属性。
- ALL/SOME/ANY 子查询忽略该会话属性。
- 层次查询表达式忽略该会话属性。
- 集函数参数包括 WITHIN GROUP 中排序表达式时忽略该会话属性。
- 分析函数参数包括 OVER 中排序表达式、分组表达式时忽略该会话属性。
- 该会话属性优先级低于 BINARY 前缀,即存在 BINARY 前缀时,即使会话属性被设置为 FALSE,仍会按照大小写敏感进行比较。关于 BINARY 前缀的具体信息详见 4.16 BINARY 前缀。
举例说明
例 设置当前会话为大小写敏感的方式。
讯享网
设置当前会话的本地并行开关。
语法格式
图例
本地并行开关
语句功能
设置当前会话是否开启本地并行查询。
参数
< 开关 > 设置为 ENABLE 时,代表当前会话设置 PARALLEL_POLICY=1,开启本地并行查询;设置为 DISABLE 时,代表当前会话设置 PARALLEL_POLICY=0,关闭本地并行查询。
使用说明
仅当前会话有效。
举例说明
例 设置当前会话开启本地并行查询。
讯享网
可以通过注释语句来创建或修改表、视图或它们的列的注释信息。表和视图上的注释信息可以通过查询字典表 SYSTABLECOMMENTS 进行查看,列的注释信息可以通过查询字典表 SYSCOLUMNCOMMENTS 进行查看。
语法格式
参数
<注释字符串> 指明要设置的注释信息;
图例
注释语句
语句功能
供具有 DBA 角色(三权分立)、DB_OBJECT_ADMIN 角色(四权分立),或具有 ALL、ALL PRIVILEGE、COMMENT ANY TABLE 权限的用户为表、视图或列创建注释信息。具有 ALTER 权限的用户也可为表、列创建注释信息。
使用说明
- 用户只能为自己所拥有模式中的表、视图和列对象创建注释信息;
- 注释字符串最大长度为 4000;
- 在已有注释的对象上再次执行此语句将直接覆盖之前的注释。
举例说明
例 1 为表 PERSON 创建注释信息。
讯享网
例 2 为表 PERSON 的列 NAME 创建注释信息。
INI 参数分为手动、静态和动态三种类型,分别对应 V$PARAMETER 视图中 TYPE 列的 READ ONLY、IN FILE、SYS/SESSION。服务器运行过程中,手动(READ ONLY)参数不能被修改,静态和动态参数可以修改。
静态(IN FILE)参数只能通过修改 DM.INI 文件进行修改,修改后重启服务器才能生效,为系统级参数,生效后会影响所有的会话。
动态(SYS 和 SESSION)参数可在 DM.INI 文件和内存同时修改,修改后即时生效。其中,SYS 为系统级参数,修改后会影响所有的会话;SESSION 为会话级参数,服务器运行过程中被修改时,之前创建的会话不受影响,只有新创建的会话使用新的参数值。
用户可以通过 ALTER SYSTEM 语法修改静态或动态(系统级、会话级)参数值,使修改之后的参数值能够在全局范围内起作用。对于静态参数,只有指定 SPFILE 情况下,才能修改。
语法格式
讯享网
参数
- <参数名称> 指静态、动态(系统级、会话级)INI 参数名字;
- <参数值> 指设置该 INI 参数的值;
- [DEFERRED] 只适用于动态会话级参数,若指定 DEFERRED,则参数值延迟生效,对当前会话不生效,只对新创建的会话生效;若不指定 DEFERRED,则参数值立即生效,对当前会话和新创建的会话都生效。针对动态系统级参数,无论是否指定 DEFERRED,参数值均对所有会话生效,包括所有已经创建的会话以及新创建的会话;针对静态参数,指定 DEFERRED 将报错;
- [MEMORY|BOTH|SPFILE] 设置 INI 参数修改的位置。其中,MEMORY 只对内存中的 INI 值做修改;SPFILE 则只对 INI 文件中的 INI 值做修改;BOTH 则内存和 INI 文件都做修改。默认情况下,为 MEMORY。对于静态参数,只能指定 SPFILE。
图例
设置参数值

语句功能
设置系统级的 INI 参数值。
举例说明
例 1 设置当前系统动态、会话级参数 SORT_BUF_SIZE 参数值为 200,要求延迟生效,对当前的 session 不生效,对后面创建的会话才生效。并且只修改内存。
例 2 设置静态参数 BDTA_SIZE 参数值为 1200。
讯享网
用户可以通过 ALTER SESSION 语法修改动态会话级参数(即 TYPE 为 SESSION 的参数),使修改之后的 INI 参数值只对当前会话起作用,不会影响其他会话或系统的 INI 参数值。
语法格式
参数
- <参数名称> 指动态会话级 INI 参数名字;
- <参数值> 指设置该 INI 参数的相应值;
- [PURGE] 指是否清理执行计划。
图例
设置仅对当前会话起作用

语句功能
设置动态、会话级的 INI 参数值。
使用说明
设置后的值只对当前会话有效。当包含 PURGE 选项时会清除服务器保存的所有执行计划。
举例说明
例 设置当前会话的 HAGR_HASH_SIZE 参数值为 。
讯享网
用户可以通过 ALTER SYSTEM 语句对系统进行修改,如设置系统级别参数(参见 3.17.1 设置参数值),也可以使用系统修改语句切换归档文件和归档当前所有的 REDO 日志。
语法格式
图例
修改系统语句

使用说明
ARCHIVE LOG CURRENT 和 SWITCH LOGFILE 功能一样,都是把新生成的,还未归档的联机日志进行归档。
设置列、索引生成统计信息。
语法格式
讯享网
参数
- <统计信息采样率百分比> 指定统计信息采样率的百分比。必须为 0~100 范围内的浮点数,精确到小数点后 6 位;
- <直方图桶数> 指定统计信息的直方图桶数,单列取值范围为 0 或 1~10000 范围内的整数,其中 0 表示不限制。不指定时系统根据数据的实际情况动态确定。多列的取值范围是 1~2500;
- <模式名> 指定收集统计信息的模式。缺省为当前会话的模式名;
- <表名> 指定收集统计信息的表;
- <列名> 指定收集统计信息的列。当前最大支持 127 列;
- <索引名> 指定收集统计信息的索引;
- GLOBAL 用于 MPP 环境下各节点数据收集后统一生成统计信息。
图例
设置列、索引生成统计信息
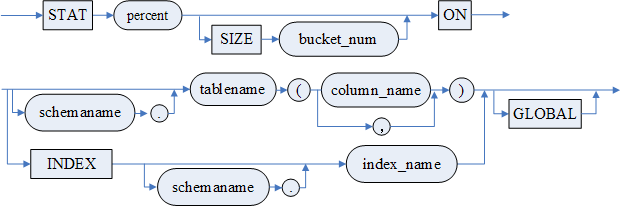
语句功能
为列或索引生成的统计信息。
使用说明
- 不支持所在表空间为 OFFLINE 的对象;
- <表名>不支持外部表、DBLINK 远程表、动态视图表、记录类型数组所用的临时表;
- <列名>不支持 ROWID、ROWNUM 等特殊列,不支持 BLOB、BFILE、IMAGE、LONGVARBINARY、CLOB、TEXT、LONGVARCHAR、自定义类型列和空间类型列等列类型;
- <索引名>,不支持位图索引、位图连接索引、虚索引、全文索引、空间索引、数组索引、无效的索引;
- 该语句的调用将导致当前事务被提交;
- GLOBAL 仅在 MPP 或 DMDPC 环境下使用 GLOBAL 登录时可用,否则报错;
- 多列统计信息只支持表,不支持索引;
- DMDPC 环境下不支持多列统计信息。
举例说明
例 1 对 SYSOBJECTS 表上 ID 列生成统计信息,采样率的百分比为 30%。
例 2 对 PURCHASING 模式下的索引 S1 生成统计信息,采样率为 50%。
讯享网
例 3 对 SYSOBJECTS 表上 PID,NAME 列生成统计信息,采样率的百分比为 30%。
设置表生成统计信息。
语法格式
讯享网
参数
- <模式名> 指定生成统计信息的表的模式。缺省为当前会话的模式名;
- <表名> 指定生成统计信息的表;
- GLOBAL 用于 MPP 环境下各节点数据收集后统一生成统计信息。
图例
设置表生成统计信息

语句功能
为表生成统计信息。
使用说明
- 不支持为所在表空间为 OFFLINE 的表生成统计信息;
- 不支持为外部表、DBLINK 远程表、动态视图表、记录类型数组所用的临时表生成统计信息;
- 该语句的调用将导致当前事务被提交;
- GLOBAL 仅在 MPP 或 DMDPC 环境下使用 GLOBAL 登录时可用,否则报错;
- 对分区表默认采样 50 个子表,可通过调整 INI 参数 HP_STAT_SAMPLE_COUNT 设置采样子表的个数。
举例说明
例 1 为 SYSOBJECTS 表生成统计信息。
为了兼容 ORACLE 的用户资源和密码限制管理方式,DM 支持 PROFILE 的创建、修改、删除以及授权 DDL 语句,并支持在用户定义中关联 PROFILE。
语法格式
讯享网
参数
- <profile 名 > 要创建的 profile 文件名字,最大长度 128 字节;
- LIMIT < 资源设置 > 直接设置资源设置项。如未指定,则使用缺省值。
图例
创建 PROFILE

语句功能
供具有 DBA 角色或具有 CREATE PROFILE 系统权限的用户创建 PROFILE。
使用说明
创建 profile 文件,通过 LIMIT < 资源设置 > 设置资源设置项。如果不指定资源设置项,则使用缺省值。
举例说明
语法格式
讯享网
参数
同创建 PROFILE 的参数规定一样。
图例
修改 PROFILE

语句功能
供具有 DBA 角色或具有 ALTER PROFILE 系统权限的用户修改 PROFILE 的资源限制项。
举例说明
语法格式
讯享网
参数
RESTRICT 表示仅当 PROFILE 未关联任何用户时才可被删除; CASCADE 表示级联删除。
图例
删除 PROFILE

语句功能
供具有 DBA 角色或具有 DROP PROFILE 系统权限的用户删除 PROFILE。
使用说明
- 删除不存在的 PROFILE 会报错。若指定 IF EXISTS 关键字,删除不存在的 PROFILE,不会报错。
- 不允许删除名为 DEFAUTL 的系统预设 PROFILE。
举例说明
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/171560.html