
<svg xmlns="http://www.w3.org/2000/svg" style="display: none;"> <path stroke-linecap="round" d="M5,0 0,2.5 5,5z" id="raphael-marker-block" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></path> </svg> <p></p> 讯享网
在简单结束应用层的开发学习后,本系列将开启驱动层的学习,本文作为该系列第一期旨在归纳前期需要准备的知识。
FPGA的编程更多地依赖于硬件描述语言(HDL),如VHDL或Verilog,用于描述电路的结构和行为。这种编程方法将硬件电路抽象为逻辑门、寄存器等基本元素,并通过编写代码来描述它们之间的连接关系和功能。相较于其他两种编程方式,FPGA编程需要频繁抓取时钟,这是因为FPGA的并行性、硬件描述方式、精确的时序控制需求以及性能优化等方面的要求。这种时钟抓取机制使得FPGA能够高效地处理复杂的数字逻辑任务,并在各种应用中实现高性能和灵活性。
相比之下,MCU的编程通常更侧重于顺序执行和寄存器的直接操作。因为MCU的操作是顺序执行的,开发者可以通过直接读写寄存器来管理内部状态和操作。这种编程方式相对简单直观,但可能不如FPGA在并行处理和复杂逻辑实现上灵活。
至于Linux框架下的驱动编程,它与FPGA和单片机的编程方式有显著的不同。Linux驱动编程主要关注于设备与操作系统之间的交互,包括设备节点的创建、设备驱动程序的编写和与操作系统的接口实现等。驱动程序需要处理设备的硬件特性,并将其抽象为操作系统可以理解和操作的接口。这种编程方式更注重于软件的架构和接口设计,与硬件的交互通常是通过特定的接口和协议来实现的。
在Linux系统中,设备驱动会以内核模块的形式出现,学习Linux内核模块编程是驱动开发的先决条件。 第一次接触Linux内核模块,我们将围绕着“Linux内核模块是什么”,“Linux内核模块的工作原理”以及 “我们该怎么使用Linux内核模块”这样的思路一起走进Linux内核世界。
Linux内核模块是Linux内核向外部提供的一个插口,也被称为动态可加载内核模块(Loadable Kernel Module,LKM)。它是一个具有独立功能的程序,可以被单独编译,但不能独立运行。在运行时,内核模块被链接到内核作为内核的一部分在内核空间运行。
内核模块的主要作用是扩展内核的功能,而无需重新编译整个内核。例如,内核模块通常用于添加新的设备驱动程序、文件系统或其他功能到内核中。通过内核模块,Linux内核能够实现内核功能扩展,提供新的系统调用或特性,甚至实现内核的安全增强以增加系统的安全性。
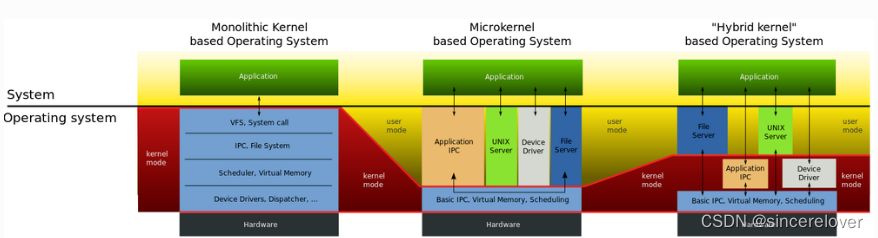
这里展示一张图片可以让大家直观地感受一下Linux的内核体系(Monolithic Kernel)。
讯享网
可以看到Linux所使用的宏内核架构是将包括微内核(Microkernel)以及微内核之外的应用层IPC、文件系统功能、设备驱动模块都编译成一个整体。 其优点是执行效率非常高,但缺点也是十分明显的,一旦我们想要修改、增加内核某个功能时(如增加设备驱动程序)都需要重新编译一遍内核。 Linux操作系统正是采用了宏内核结构。为了解决这一缺点,linux中引入了内核模块这一机制。
Linux内核模块的代码框架通常由下面几个部分组成:
- 模块加载函数(必须): 当通过insmod或modprobe命令加载内核模块时,模块的加载函数就会自动被内核执行,完成本模块相关的初始化工作。
- 模块卸载函数(必须): 当执行rmmod命令卸载模块时,模块卸载函数就会自动被内核自动执行,完成相关清理工作。
- 模块许可证声明(必须): 许可证声明描述内核模块的许可权限,如果模块不声明,模块被加载时,将会有内核被污染的警告。
- 模块参数: 模块参数是模块被加载时,可以传值给模块中的参数。
- 模块导出符号: 模块可以导出准备好的变量或函数作为符号,以便其他内核模块调用。
- 模块的其他相关信息: 可以声明模块作者等信息。
这里给出一个简单的示例(注:仅作介绍使用):
讯享网
前面我们已经接触过了Linux的应用编程,了解到Linux的头文件都存放在/usr/include中。 编写内核模块所需要的头文件,并不在上述说到的目录,而是在Linux内核源码中的include文件夹。编写内核模块中经常要使用到的头文件有以下两个:<linux/init.h>和<linux/module.h>。
模块参数允许用户在加载模块时通过命令行指定参数值。这些参数在模块的加载过程中被获取,并转换成相应类型的值,然后赋值给对应的变量,这个过程常常发生在函数调用之前。

讯享网
模块参数的使用通常涉及以下步骤:
- 在模块代码中声明变量,并使用module_param()宏或module_param_named()宏来定义模块参数。这些宏接受三个参数:变量名、变量类型以及访问权限。访问权限用于定义在sysfs中对应文件的访问权限,与Linux文件访问权限的管理方式相同。
- 在加载模块时,用户可以通过命令行传递参数值给模块。这些值将被转换为相应的类型,并赋值给在模块代码中声明的变量。
对于内核模块而言,它是属于内核的一段代码,只不过它并不在内核源码中。 为此,我们在编译时需要到内核源码目录下进行编译。 编译内核模块使用的Makefile文件,和我们前面编译C代码使用的Makefile大致相同, 这得益于编译Linux内核所采用的Kbuild系统,因此在编译内核模块时,我们也需要指定环境变量ARCH和CROSS_COMPILE的值。
以上代码中提供了一个关于编译内核模块的Makefile。
第1行:该Makefile定义了变量KERNEL_DIR,来保存内核源码的目录,需要指定到内核编译输出目录下。
第3-5行: 指定了工具链并导出环境变量
第6行:变量obj-m保存着需要编译成模块的目标文件名。
第8行:$ (MAKE)的MAKE是Makefile中的宏变量,要引用宏变量要使用符号。这里实际上就是指向make程序,所以这里也可以把$ (MAKE)换成make,通过选项’-C’,可以让make工具跳转到源码目录下读取顶层Makefile。 ‘M=$(CURDIR)’表明返回到当前目录,读取并执行当前目录的Makefile,开始编译内核模块。CURDIR是make的内嵌变量,自动设置为当前目录。
在之前的应用开发中,我们多次使用到open、write及read函数等进行数据的传输,设备节点的链接等等操作。在驱动设计时,我们其实也是同样的套路,不同之处在于我们需要写出自己驱动的open等函数。
- 确定主设备号
- 定义自己的file_operations结构体
- 根据file_operations,实习对应的open、write、read等函数
- 注册驱动程序:将file_operations信息告诉内核
- 入口函数:安装驱动时会自动调用
- 出口函数:卸载驱动时会自动调用
- 其他:创建其他设备节点,提供信息
在内核中,dev_t用来表示设备编号,dev_t是一个32位的数,其中,高12位表示主设备号,低20位表示次设备号。 也就是理论上主设备号取值范围:0-212 ,次设备号0-220。 实际上在内核源码中__register_chrdev_region(…)函数中,major被限定在0-CHRDEV_MAJOR_MAX,CHRDEV_MAJOR_MAX是一个宏,值是512。 在kdev_t中,设备编号通过移位操作最终得到主/次设备号码,同样主/次设备号也可以通过位运算变成dev_t类型的设备编号。
在驱动开发过程中,不可避免要涉及到三个重要的的内核数据结构分别包括文件操作方式(file_operations), 文件描述结构体(struct file)以及inode结构体,在我们开始阅读编写驱动程序的代码之前,有必要先了解这三个结构体。
3.1 file_operations
file_operations是 Linux 内核中的一个重要的数据结构,用于表示内核中的一个文件所支持的操作集合。这个结构体定义了一系列的文件操作函数,如打开文件、读取文件、写入文件、关闭文件等。这些函数被内核用于处理与文件相关的各种请求。
讯享网
这里是一些主要成员的解释:
- llseek: 用于修改文件的当前读写位置,并返回偏移后的位置。参数file传入了对应的文件指针,我们可以看到以上代码中所有的函数都有该形参,通常用于读取文件的信息,如文件类型、读写权限;参数loff_t指定偏移量的大小;参数int是用于指定新位置指定成从文件的某个位置进行偏移,SEEK_SET表示从文件起始处开始偏移;SEEK_CUR表示从当前位置开始偏移;SEEK_END表示从文件结尾开始偏移。
- read: 用于读取设备中的数据,并返回成功读取的字节数。该函数指针被设置为NULL时,会导致系统调用read函数报错,提示“非法参数”。该函数有三个参数:file类型指针变量,char__user*类型的数据缓冲区,__user用于修饰变量,表明该变量所在的地址空间是用户空间的。内核模块不能直接使用该数据,需要使用copy_to_user函数来进行操作。size_t类型变量指定读取的数据大小。
- write: 用于向设备写入数据,并返回成功写入的字节数,write函数的参数用法与read函数类似,不过在访问__user修饰的数据缓冲区,需要使用copy_from_user函数。
- unlocked_ioctl: 提供设备执行相关控制命令的实现方法,它对应于应用程序的fcntl函数以及ioctl函数。在 kernel 3.0 中已经完全删除了 struct file_operations 中的 ioctl 函数指针。
- open: 设备驱动第一个被执行的函数,一般用于硬件的初始化。如果该成员被设置为NULL,则表示这个设备的打开操作永远成功。
- release: 当file结构体被释放时,将会调用该函数。与open函数相反,该函数可以用于释放
3.2 file

这里是一些主要成员的解释:
- f_dentry: 指向描述文件或目录的 dentry 结构体的指针,它表示了文件系统中的对象。
- f_vfsmnt:指向该文件或目录所在文件系统的挂载点的 vfsmount 结构体指针。
- f_op: 指向与文件或设备关联的 file_operations结构体的指针,该结构体包含了各种文件操作函数。
- f_pos: 文件当前的读写位置(偏移量)。
- f_flags: 文件的标志位,如O_RDONLY、O_WRONLY、O_NONBLOCK 等。
- f_lock: 指向文件锁的指针,用于支持文件的加锁操作。
- f_mapping: 指向文件的地址空间映射的指针,用于管理文件的内存映射。
3.3 inode
inode是 Linux 内核中用于表示文件系统中一个具体文件或目录的元数据的数据结构。它包含了与文件或目录相关的各种信息,如权限、所有者、大小、时间戳等。inode 的存在使得文件系统能够高效地管理文件和目录。每个文件和目录在文件系统中都对应一个唯一的 inode。这些 inode 通常存储在磁盘的特定区域,称为 inode 表。通过 inode 的索引,文件系统能够快速地定位到文件或目录的数据块,并进行读写操作。
讯享网
struct inode 结构体包含了很多字段,以下是一些重要的字段:
- umode_t i_mode: 文件类型和权限。
- uid_t i_uid: 文件的所有者。
- gid_t i_gid: 文件的组。
- kdev_t i_rdev: 如果文件是一个设备文件,这个字段表示设备的类型和编号。
- loff_t i_size: 文件的大小(以字节为单位)。
- struct timespec i_atime: 文件的最后访问时间。
- struct timespec i_mtime: 文件的最后修改时间。
- struct timespec i_ctime: 文件的最后状态改变时间(如权限、所有者等的改变)。
- struct hlist_node i_hash: 用于哈希表,以快速查找 inode。
- struct list_head i_devices: 指向使用该 inode 的所有设备的列表。
- struct list_head i_wb_list: 写入回调的列表。
- struct address_space *i_mapping: 指向文件的地址空间的指针,用于页面缓存管理。
- struct inode_operations *i_op: 指向该 inode 类型的操作的指针。
- struct file_operations *i_fop: 指向文件操作的指针,如果这是一个设备文件。
3.4 哈希表
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫作散列函数,存放记录的数组叫作散列表。哈希表有以下几个特点:
- 直接访问:通过计算哈希值,可以直接定位到数据在哈希表中的存储位置,因此哈希表的查找、插入和删除操作的时间复杂度都是O(1)。
- 冲突处理:由于哈希函数可能会将不同的键映射到同一个位置,这种情况被称为冲突(collision)。为了处理这种冲突,有多种方法,如链地址法(开放寻址法的一种)和开放寻址法(包括线性探测、二次探测和双重散列)。
- 动态扩容:当哈希表中的数据量过大,导致冲突过多,性能下降时,哈希表会进行动态扩容,即创建一个新的、更大的哈希表,并将原哈希表中的数据重新映射到新哈希表中。
哈希表在实际应用中非常广泛,例如在数据库索引、缓存系统、数据结构中的关联数组等地方都有使用。然而,哈希表并不适用于所有情况,它对于非均匀分布的数据具有较好的性能,但对于均匀分布或具有特定模式的数据,性能可能较差。此外,哈希表也不支持范围查询。
3.5 cdev结构体
- struct kobject kobj: 内嵌的内核对象,通过它将设备统一加入到“Linux设备驱动模型”中管理(如对象的引用计数、电源管理、热插拔、生命周期、与用户通信等)。
- struct module *owner: 字符设备驱动程序所在的内核模块对象的指针。
- const struct file_operations *ops: 文件操作,是字符设备驱动中非常重要的数据结构,在应用程序通过文件系统(VFS)呼叫到设备设备驱动程序中实现的文件操作类函数过程中,ops起着桥梁纽带作用,VFS与文件系统及设备文件之间的接口是file_operations结构体成员函数,这个结构体包含了对文件进行打开、关闭、读写、控制等一系列成员函数。
- struct list_head list: 用于将系统中的字符设备形成链表(这是个内核链表的一个链接因子,可以再内核很多结构体中看到这种结构的身影)。
- dev_t dev: 字符设备的设备号,有主设备和次设备号构成。
- unsigned int count: 属于同一主设备好的次设备号的个数,用于表示设备驱动程序控制的实际同类设备的数量。
3.6 kobj_map结构体
在Linux内核中,struct kobj_map是一个用于管理kobject(内核对象)映射的数据结构,其与上文提到的cdev结构体共同组成了存放设备号的哈希表结构,这有助于高效地管理大量的设备号及其对应的设备。通过哈希表,内核可以快速定位到特定的设备号,从而实现高效的设备号查找和管理。
讯享网
*data用于保存cdev结构体中的指针。
在file_operations结构体中,我们提到read和write函数时,需要使用copy_to_user函数以及copy_from_user函数来进行数据访问,写入/读取成 功函数返回0,失败则会返回未被拷贝的字节数。
- 参数
- to:指定目标地址,也就是数据存放的地址,
- from:指定源地址,也就是数据的来源。
- n:指定写入/读取数据的字节数。
- 返回值:写入/读取数据的字节数
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/168344.html