
Data Cleaning functions
以下是整理数据的四个常用的函数:
gather(): 将数据从横向转换为纵向(不是装置)spread(): 将数据从纵向转换为横向separate(): 将一个变量分解为两个变量unit(): 将两个变量合并为一个变量
如果没有安装tidyr,输入以下命令进行安装
install.packages("tidyr") 讯享网
gather()
讯享网gather(data, key, value, na.rm = FALSE) 参数: -data: 数据集 -key: 新创建列的名称 -value: 选择用来填充关键列的列 -na.rm: 删除缺失的值. 默认为FALSE
如图,我们想要创建一个名为growth的列,由quarter变量的值填充。
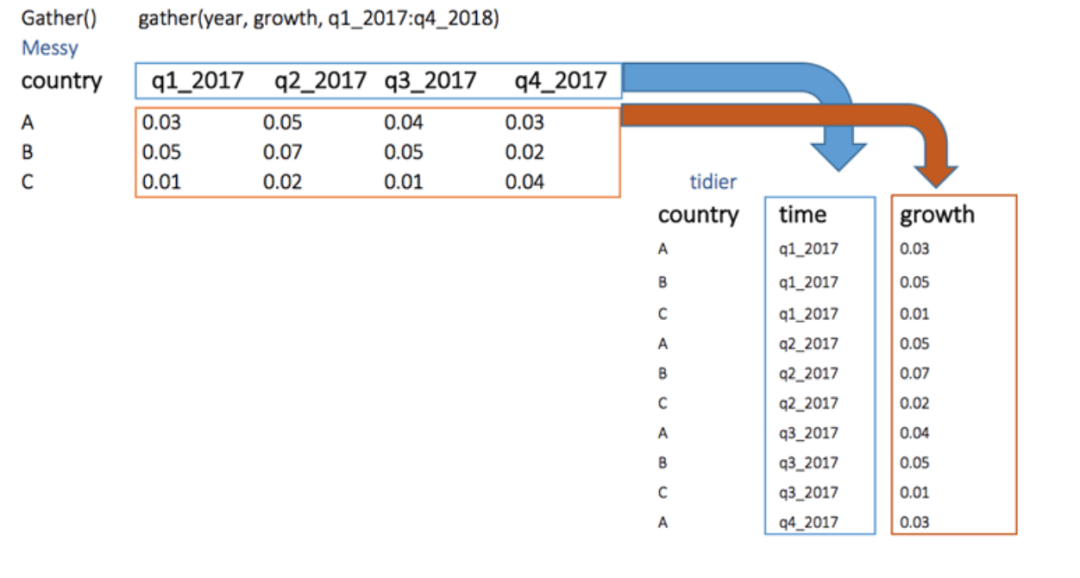
讯享网
library(tidyr) #生成示例数据 messy <- data.frame( country = c("A", "B", "C"), q1_2017 = c(0.03, 0.05, 0.01), q2_2017 = c(0.05, 0.07, 0.02), q3_2017 = c(0.04, 0.05, 0.01), q4_2017 = c(0.03, 0.02, 0.04)) messy 讯享网> messy country q1_2017 q2_2017 q3_2017 q4_2017 1 A 0.03 0.05 0.04 0.03 2 B 0.05 0.07 0.05 0.02 3 C 0.01 0.02 0.01 0.04
#整理数据 tidier <-messy %>% #管道符可以让代码更简洁 gather(quarter, growth, q1_2017:q4_2017) tidier 讯享网> tidier country quarter growth 1 A q1_2017 0.03 2 B q1_2017 0.05 3 C q1_2017 0.01 4 A q2_2017 0.05 5 B q2_2017 0.07 6 C q2_2017 0.02 7 A q3_2017 0.04 8 B q3_2017 0.05 9 C q3_2017 0.01 10 A q4_2017 0.03 11 B q4_2017 0.02 12 C q4_2017 0.04
spread()
spread() 的作用和gather正好相反.
spread(data, key, value) 参数: data: 数据集 key: 需要变成横向的列 value: 填充新列的行 我们可以使用spread()将整洁的数据集重塑为凌乱的。
讯享网# 重塑数据 messy_1 <- tidier %>% spread(quarter, growth) messy_1
country q1_2017 q2_2017 q3_2017 q4_2017 1 A 0.03 0.05 0.04 0.03 2 B 0.05 0.07 0.05 0.02 3 C 0.01 0.02 0.01 0.04 separate()
separate()的作用是:根据分隔符将一列分成两列。比如,我们的分析需要关注月和年,我们就可以把这个列分成两个新变量。

Syntax:
讯享网separate(data, col, into, sep= "", remove = TRUE) 参数: -data: 数据集 -col: 需要分隔的列 -into: 新变量的名称 -sep: 用于分隔变量的符号,i.e.: "-", "_", "&" -remove: 删除旧列. 默认为TRUE.
separate_tidier <-tidier %>% separate(quarter, c("Qrt", "year"), sep ="_") head(separate_tidier) 讯享网 country Qrt year growth 1 A q1 2017 0.03 2 B q1 2017 0.05 3 C q1 2017 0.01 4 A q2 2017 0.05 5 B q2 2017 0.07 6 C q2 2017 0.02
unite()
unite() 则是将两列合并为一列。
Syntax:
unit(data, col, conc ,sep= "", remove = TRUE) 参数: -data: 数据集 -col: 新列的名称 -conc: 需要合并的列明 -sep: 用于连接变量的符号, i.e: "-", "_", "&" -remove: 删除旧列. 默认为TRUE. 讯享网unit_tidier <- separate_tidier %>% unite(Quarter, Qrt, year, sep ="_") head(unit_tidier)
output:
country Quarter growth 1 A q1_2017 0.03 2 B q1_2017 0.05 3 C q1_2017 0.01 4 A q2_2017 0.05 5 B q2_2017 0.07 6 C q2_2017 0.02 Summary
| Function | Objectives | Arguments |
|---|---|---|
| gather() | Transform the data from wide to long | (data, key, value, na.rm = FALSE) |
| spread() | Transform the data from long to wide | (data, key, value) |
| separate() | Split one variables into two | (data, col, into, sep= "", remove = TRUE) |
| unit() | Unit two variables into one | (data, col, conc ,sep= "", remove = TRUE) |
往期文章
- apply | R中函数的简单循环
- aggregate | 在R中进行分组统计
- R 中几个常见的合并数据集方法
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/16828.html