
- 与vmware匹配搜索结果 - 考拉软件 (rjctx.com),下载17.5.1版本即可
- 下载后对照教程安装
- 搜索清华大学镜像网站,点击再搜ubuntu,选ubuntu-releases,再选20.04版本,下载这个4.1GB的iso文件

讯享网 - 安装后打开vmware虚拟机

- 右键管理员身份打开
- 创建新的虚拟机,对照B站视频:两分半钟完成VMware安装及Linux-Ubuntu安装(全程无废话)_哔哩哔哩_bilibili配置即可
1.如果遇到“无法创建vmware虚拟机”,说明第三步没有右键管理员身份打开
2.如果遇到“键盘布局”,与B站视频不对应,并且找不到“下一步”按钮,是屏幕分辨率有问题,进行以下操作:右上角红圈叉号,退出安装,然后进入桌面,找到“设置”,在“设置”中找到显示器,调一下分辨率改成1960*n大小,然后返回桌面再点击“安装”
添加简单的Linux内核模块
学习Linux内核的组织管理机制,内核模块的添加方式,内核模块的设计、编译、插入和删除过程。
明确用户自己添加的内核模块区别于linux内核。
- Linux内核(Linux Kernel):
- Linux内核是操作系统的核心,负责管理系统的硬件资源,包括CPU、内存、磁盘、输入/输出设备等。
- 内核提供了操作系统的基本功能,如进程管理、文件系统管理、设备驱动等。
- 内核是操作系统中最底层的部分,直接与硬件交互,为上层应用提供服务。
- 用户添加的内核模块(Loadable Kernel Modules, LKMs):
- 内核模块是Linux内核功能的扩展,允许用户在不重新编译整个内核的情况下,动态地添加或移除内核功能。
- 这些模块通常用于添加对特定硬件的支持,实现特定的功能,或者优化内核性能。
- 模块化设计使得内核更加灵活,可以根据需要加载或卸载模块,而不需要重启整个系统。
- 用户添加的内核模块与Linux内核的区别:
- 功能定位不同: Linux内核提供了操作系统的基本功能,而用户添加的内核模块则是对这些基本功能的扩展和增强。
- 开发和维护: Linux内核由全球的开发者社区共同开发和维护,而用户添加的内核模块通常由特定的硬件厂商、开发者或组织开发和维护。
- 加载和卸载: Linux内核在系统启动时加载,通常在整个系统运行期间保持不变。而用户添加的内核模块可以根据需要动态加载和卸载。
- 稳定性和安全性: 由于Linux内核是操作系统的核心,其稳定性和安全性至关重要。相比之下,用户添加的内核模块可能存在稳定性和安全性问题,因为它们可能没有经过严格的测试和审查。
- 兼容性: Linux内核需要与各种硬件和软件兼容,而用户添加的内核模块通常只针对特定的硬件或软件。
- 用户添加的内核模块的作用:
- 提供接口: 用户添加的内核模块为Linux内核提供接口,使得内核能够与特定的硬件或软件交互。
- 扩展功能: 通过加载特定的内核模块,用户可以扩展Linux内核的功能,实现更多的特性和性能优化。
- 灵活性: 动态加载和卸载内核模块提供了更高的灵活性,允许用户根据需要调整系统的功能。
(一)配置环境:
1.更新软件包列表
讯享网
2.安装编译内核所需的工具和依赖项
讯享网
3.如果遇到缓存锁问题,依次输入 :
(二)编写模块:
1.先在主页面创建一个test1文件夹
2.打开文本编辑器,编写kello.c和Makefile保存到test1文件夹里
3.打开终端,依次输入以下命令
讯享网
4.kello.c源代码
解释:
这段代码是一个简单的Linux内核模块的示例。它包含了模块初始化和退出时的函数,以及模块的许可证声明。下面是代码的逐行解释:
1. `#include <linux/module.h>`:包含Linux内核模块开发所需的头文件,提供了模块相关的定义和函数。
2. `int kello_init(void)`:这是模块初始化函数,当模块被加载到内核时,这个函数会被调用。
3. `{`:函数体的开始。
4. `printk(“ hello,world ”);`:使用`printk`函数在内核日志中打印一条消息,这里的信息是“hello, world”。
5. `return 0;`:返回0表示模块初始化成功。
6. `}`:函数体的结束。
7. `void kello_exit(void)`:这是模块退出函数,当模块从内核卸载时,这个函数会被调用。
8. `{`:函数体的开始。
9. `printk(“ goodbye ”);`:使用`printk`函数在内核日志中打印一条消息,这里的信息是“goodbye”。
10. `}`:函数体的结束。
11. `MODULE_LICENSE(“GPL”);`:声明模块遵循的许可证,这里是GPL(General Public License,通用公共许可证)。
12. `module_init(kello_init);`:告诉内核,当模块被加载时,应该调用`kello_init`函数。
13. `module_exit(kello_exit);`:告诉内核,当模块被卸载时,应该调用`kello_exit`函数。
这个模块非常简单,没有实现任何功能,只是展示了如何编写一个内核模块的基本框架。在实际开发中,你会在`kello_init`和`kello_exit`函数中添加更多的代码来实现特定的功能。
5.Makefile源代码
讯享网
解释:
这段代码是一个Makefile,用于编译Linux内核模块。它检查是否在内核构建环境中执行,并根据环境不同执行不同的编译命令。下面是代码的逐行解释:
1. `ifneq (\((KERNELRELEASE),)`:这是一个条件判断,检查`KERNELRELEASE`变量是否非空。</p> <p>2. `obj-m := kello.o`:如果`KERNELRELEASE`变量非空,说明正在内核的构建系统中执行,这里设置目标文件为`kello.o`,这是内核模块的目标文件。</p> <p>3. `else`:如果`KERNELRELEASE`变量为空,即不在内核构建环境中。</p> <p>4. `KDIR := /lib/modules/\)(shell uname -r)/build`:设置`KDIR`变量为当前运行内核的构建目录。`\((shell uname -r)`会执行`uname -r`命令,获取当前运行的内核版本。</p> <p>5. `PWD := \)(shell pwd)`:设置`PWD`变量为当前目录的绝对路径。
6. `default:`:定义默认目标。
7. `\((MAKE) -C \)(KDIR) M=\((PWD) modules`:执行`make`命令,`-C`指定了内核构建目录,`M=\)(PWD)`指定了模块的源代码目录,`modules`告诉内核构建系统要构建模块。
8. `rm -r -f .tmp_versions .mod.c ..cmd *.o *.symvers`:删除编译过程中生成的临时文件和目标文件,以保持工作目录的清洁。
9. `endif`:结束条件判断。
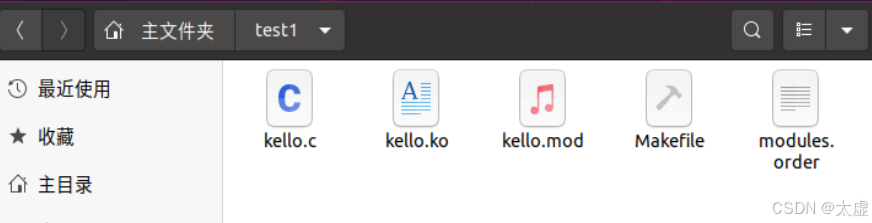
6.添加.ko格式文件
输入命令make
此时的test1文件夹里
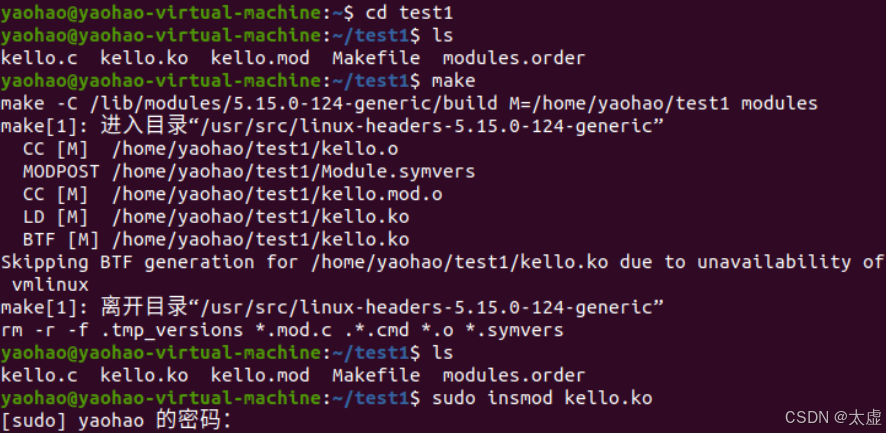
7.添加、删除内核并查看日志
讯享网

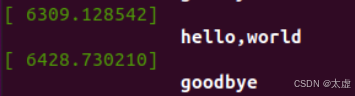
输出“hello,world”表明模块创建成功,输出“goodbye”表明模块卸载成功。
进程之间的通信
学习Linux进程之间的通信机制,包括管道通信(无名管道、命名管道)、套接字通信(文件套接字、网络套接字)、共享内存等。
设有两个进程PA和PB。进程PA向进程PB发送一个结构类型数据。该结构类型数据至少包含3种类型数据,其中一种是int型数据;进程PB将该结构数据中所有int型数据求和,并将结果发给PA,PA将结果输出。
使用以上其中一种通信机制实现。
(一)通信机制了解
- 无名管道(pipe):
- 允许具有共同祖先的进程间进行通信。
- 只能实现单向通信。
- 通常用于父子进程间。
- 有名管道(FIFO):
- 允许不相关的进程间进行通信。
- 可以看作是一个存在于文件系统中的FIFO(先进先出队列)。
- 支持双向通信。
- 信号:
- 一种软件中断机制,用于通知进程某个事件已经发生。
- 信号可以由另一个进程发送,也可以由操作系统在特定事件发生时发送。
- 消息队列:
- 允许进程以消息的形式交换数据。
- 消息被存储在队列中,直到被接收进程读取。
- 支持异步通信。
- 共享内存:
- 进程间共享一个给定的存储区。
- 是最快的IPC机制,因为进程直接对内存进行存取。
- 需要同步机制来避免竞态条件。
- 信号量(Semaphores):
- 用于控制对共享资源的访问。
- 可以是命名的或无名的。
- 用于实现进程间的同步。
- 套接字(Sockets):
- 提供网络通信能力,但也可用于本机进程间通信。
- 支持面向连接(如TCP)和无连接(如UDP)的通信。
- 非常灵活,可以用于不同主机间的进程通信。

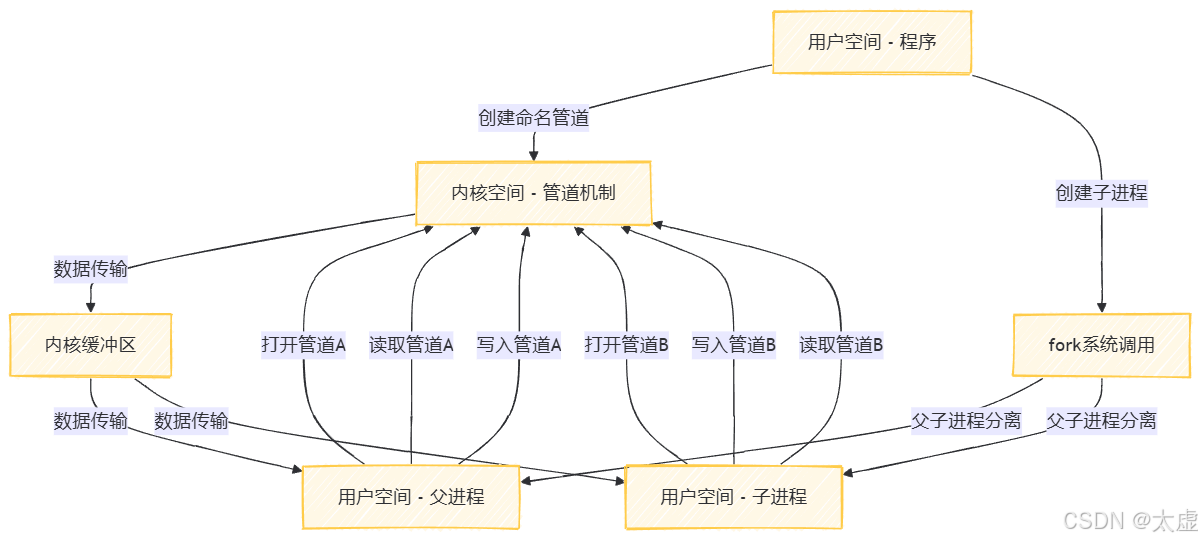
(二)模块调用图
(三)主要函数
1.int mkfifo(const char *pathname, mode_t mode);
功能:创建一个FIFO特殊文件,即命名管道;
参数:第一个参数是管道的名称,第二个参数是权限位,用于设置创建的管道的权限。
返回值:成功时返回0,失败时返回-1。
2.fork()
功能:创建一个新的进程,称为子进程,它是一个调用fork的进程的副本。
参数:无参数。
返回值:在父进程中返回子进程的进程ID,在子进程中返回0,失败时返回-1。
3.open
功能:打开一个文件或者文件描述符。
参数:第一个参数是文件的路径或名称,第二个参数是打开文件的选项,如O_RDONLY、O_WRONLY等。
返回值:成功时返回一个非负的文件描述符,失败时返回-1。
4.write
功能:向指定的文件描述符写入数据。
参数:第一个参数是文件描述符,第二个参数是指向数据的指针,第三个参数是要写入数据的大小。
返回值:成功时返回写入的字节数,失败时返回-1。
5.read
功能:从指定的文件描述符读取数据。
参数:第一个参数是文件描述符,第二个参数是指向存储读取数据的缓冲区的指针,第三个参数是要读取数据的大小。
返回值:成功时返回读取的字节数,到达文件末尾返回0,失败时返回-1。
6.close
功能:关闭一个文件描述符。
参数:需要关闭的文件描述符。
返回值:成功时返回0,失败时返回-1。
7.exit
功能:终止当前进程。
参数:终止状态值,通常用于指示进程是正常终止还是异常终止。
返回值:无返回值,调用exit的进程将终止。
1. 结构体数据
设置三个int类型数据,方便对数据进行验证
2. 创建命名管道
创建管道pipeAB和管道pipeBA,分别代表从进程A传送数据到进程B和从进程B传送数据到进程A。0666代表用户有读写权限而无执行权限,起到确保管道安全性的作用。
3. 进程A
1.定义进程A为fork()新创建出来的子进程,子进程的执行ID会传给父进程B。
2.定义data为Data结构体类型的变量,为其随意赋值。
3.以写入模式打开pipeAB管道,获取文件描述符fdA
4.将data结构体的内容写入到管道pipeAB
5.关闭文件描述符fdA
6.sum用于存储求和结果
7.以读取模式打开pipeBA管道,获取文件描述符fdb
8.从管道pipeBA读取求和结果
9.关闭文件描述符fdB
4. 进程B
1.fork()返回值不为0代表当前是父进程B
2.创建Data类型的变量data,用于存储从管道读取的数据
3.以读取模式打开pipeAB管道,获取文件描述符fdA
4.从管道pipeAB读取数据到data结构体
5.关闭文件描述符fdA
6.假设data结构体中只有一个int型数据,这里取其值作为求和结果
7.以写入模式打开pipeBA管道,获取文件描述符fdB
8.将求和结果写入到管道pipeBA
9.关闭文件描述符fdB
10.父进程B退出

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/166205.html