
可变形卷积即DCN(全称为Deformable Conv)提出于ICCV 2017的一篇文章:Deformable Convolutional Networks
论文paper地址:https://openaccess.thecvf.com/content_ICCV_2017/papers/Dai_Deformable_Convolutional_Networks_ICCV_2017_paper.pdf
codebase地址:(很多框架中都已实现,这里选择以pytorch的为例)https://github.com/4uiiurz1/pytorch-deform-conv-v2/blob/master/deform_conv_v2.py
目录
一、可变形卷积(DCN/DConv)
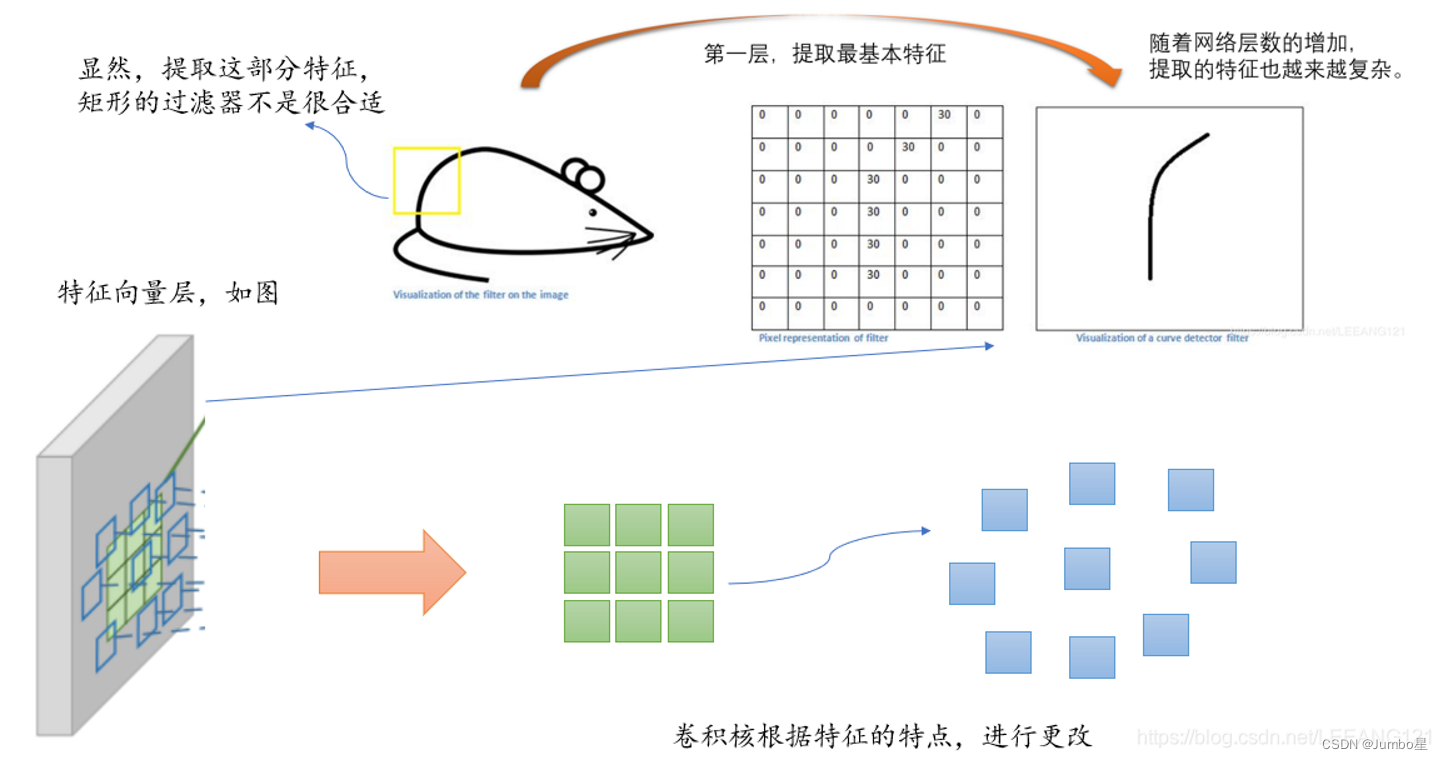
为什么要用DConv?
可变形卷积怎么实现?
DCN的操作流程(全过程)
实现中的两个问题Q&A
二、可变形RoI池化
TODO:DCN源码解析
本文提出了两个新模块:可变形卷积和可变形RoI池化
新模块可以很容易地取代现有CNN中的普通模块,并且可以通过标准反向传播轻松地进行端到端训练。
DCN目前也出到了v2,值得一提的是,DCN的思维也算一种可学习的自适应模块,跟注意力机制模块BAM/CBAM的思路有点像。
mmdetection里也有相关实现,可轻松移植进自己的项目,DCN对于大多数检测场景尤其是比赛都是有用的★
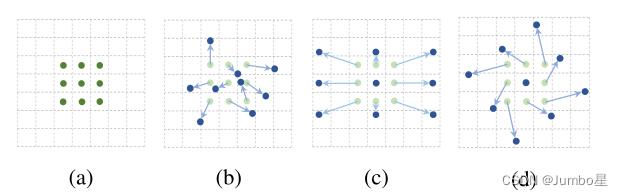
(a)是普通的卷积操作
(b)、(c)、(d)是可变形卷积(deformable convolution,DConv)
可变形卷积实际是指标准卷积操作中采样位置增加了一个偏移量offset,这样卷积核就能在训练过程中扩展到很大的范围。(c)(d)是(b)的特例,表明可变形卷积推广了尺度、长宽比和旋转的各种变换。
卷积单元(卷积核)对输入的特征图在固定的位置进行采样;池化层不断减小着特征图的尺寸;RoI池化层产生空间位置受限的RoI。然而,这样做会产生一些问题,比如,卷积核权重的固定导致同一CNN在处理一张图的不同位置区域的时候感受野尺寸都相同,这对于编码位置信息的深层卷积神经网络是不合理的。因为不同的位置可能对应有不同尺度或者不同形变的物体,这些层需要能够自动调整尺度或者感受野的方法。再比如,目标检测的效果很大程度上依赖于基于特征提取的边界框,这并不是最优的方法,尤其是对于非网格状的物体而言。

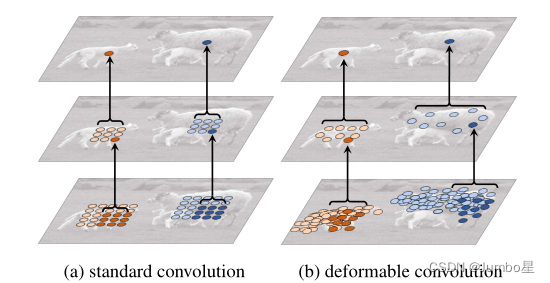
左图a是正常卷积,b是可变形卷积。
最上面的图像是在大小不同的物体上的激活单元。
中间层是为了得到顶层激活单元所进行的采样过程(可以看作是一个卷积操作,3*3卷积核对应九个点九个数最后得到上面一个点即一个数值),左图是标准的3x3方阵采样,右图是非标准形状的采样,但是采样的点依然是3x3,符合3*3卷积的广义定义。
最下面一层是为了得到中间层进行的采样区域,同理。
明显发现,可变形卷积在采样时可以更贴近物体的形状和尺寸,更具有鲁棒性,而标准卷积无法做到这一点。
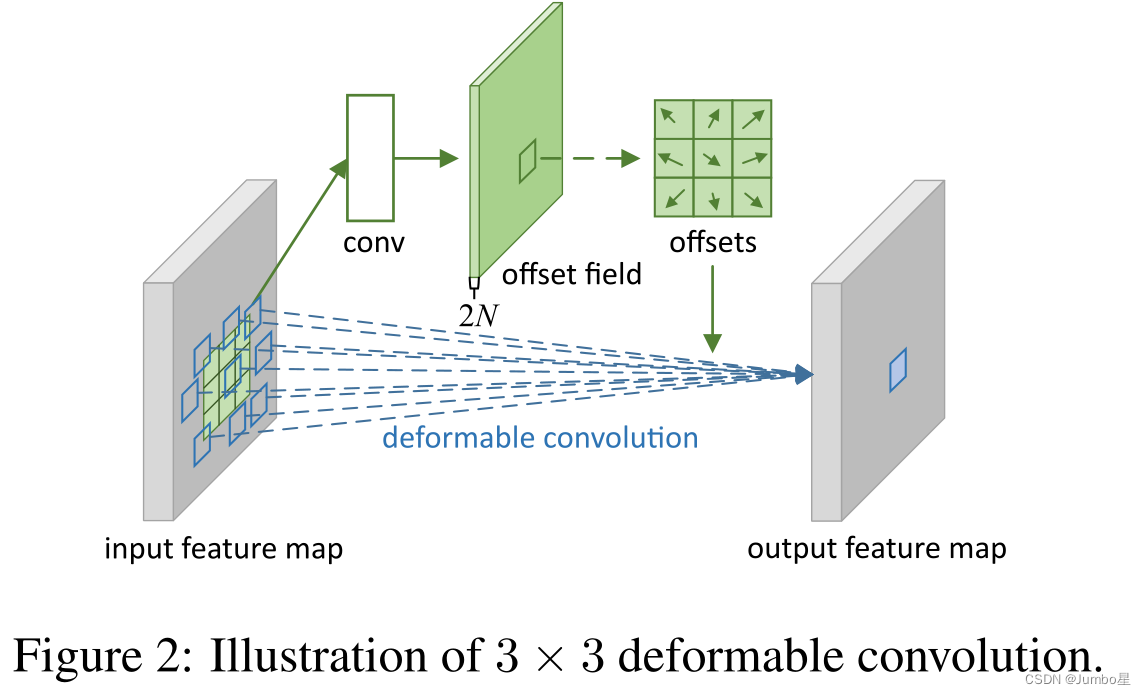
如上图所示,偏差通过一个卷积层conv获得,输入特征图,输出偏差。生成通道维度是2N,其中的2分别对应X和Y这2个2D偏移,N是通道数。一共有两种卷积核:卷积核和卷积核学习offset对应的卷积层内的卷积核,这两种卷积核通过双线性插值反向传播同时进行参数更新。
这种实现方式相当于于比正常的卷积操作多学习了卷积核的偏移offset。
总的来说整个流程如下图所示,DCN(也有的地方称为DConv)多了右边灰色框里的东西。
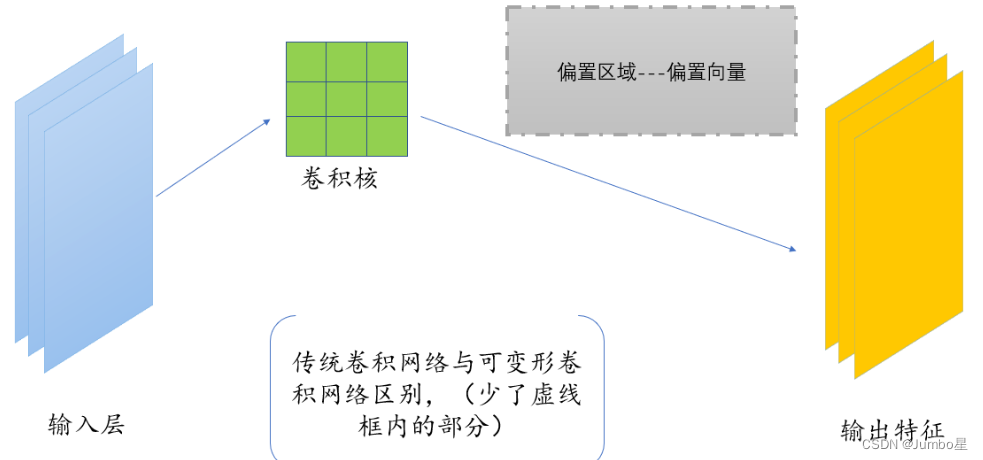
总的来说,DConv具体操作流程是:
① 我们一开始,和正常的卷积神经网络一样,根据输入的图像,利用传统的卷积核提取特征图。
②我们把得到的特征图作为输入,对特征图再施加一个卷积层,这么做的目的是为了得到可变形卷积的变形的偏移量。(重点)其中,偏移层是2N,因为我们在平面上做平移,需要改变x值和y值两个方向。
③在训练的时候,用于生成输出特征的卷积核和用于生成偏移量的卷积核是同步学习的。其中偏移量的学习是利用插值算法,通过反向传播进行学习。
Q:
1、如何将可变形卷积变成单独的一个层,而不影响别的层;
2、在前向传播实现可变性卷积中,如何能有效地进行反向传播。

A:
1、在实际操作时,并不是真正地把卷积核进行扩展,而是对卷积前图片的像素重新整合,变相地实现卷积核的扩张。也就是说,实际上变的是每次进行卷积后得到的带偏移值的坐标值,根据这些坐标取像素点,然后双线性差值,得到新feature map,然后作为输出并成为下一层的新输入。
2、在图片像素整合时,需要对像素进行偏移操作,偏移量的生成会产生浮点数类型,而偏移量又必须转换为整形,直接对偏移量取整的话无法进行反向传播,这时采用双线性差值的方式来得到对应的像素。
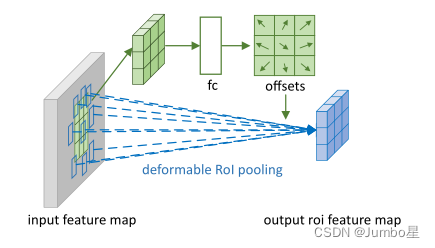
跟可变形卷积的区别就是输入是经过普通RoI池化后的feature map,进入一个全连接层(不是卷积层),得到一个偏移。注意这里的偏移量要归一化,为了匹配RoI的尺寸。
可变形RoI池化可用的场景也不多,也没有什么好借鉴的,因此就不作过多介绍,感兴趣的可以去看论文和源码对应部分深入了解。
这里我们选用mmdetection框架进行DCN的源码分析,注意我用的版本是mmdetection=2.23.0:
GitHub - open-mmlab/mmdetection at v2.23.0
在使用dcn之前首先要明确,dcn一般放在backbone里,哪怕neck或者后面的head里也有一些卷积模块,一般不会用dcn代替普通的卷积。
如果要在某个backbone使用dcn,可以参考configs/dcn或者configs/dcnv2里的官方config来进行修改,这里以configs/dcn/faster_rcnn_r50_fpn_dconv_c3-c5_1x_coco.py为例,config相关部分的代码为
_base_ = 'http://www.ppmy.cn/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py' model = dict(backbone=dict(dcn=dict(type='DCN', deform_groups=1, fallback_on_stride=False),stage_with_dcn=(False, True, True, True)))
讯享网
可以看出这个config基本上继承faster_rcnn_r50_fpn_1x_coco.py,即用faster_rcnn+backbone为resnet-50+neck为fpn来给coco数据集train 12个epoch,只是把backbone即resnet-50里的普通conv改成了dcn,其中resnet-50有4个stage,第2-第4个stage都进行了这种修改,第1个stage保留原有的conv。
在resnet的源码中:
讯享网
这里的res_layer具体实现源码在mmdet/models/utils/res_layer.py,但是这里的dcn这个变量实际上真正起作用的是在block里,比如resnet-50用的block是Bottleneck
这里跳转过去会发现实际上是mmcv对torch.nn.Conv2d加了个封装,因此实现还是以pytorch的为准。
具体源码在:
pytorch-deform-conv-v2/deform_conv_v2.py at 529abbbe9b81e852dcfd631c43c6 · 4uiiurz1/pytorch-deform-conv-v2 · GitHub
讯享网
可以看出,跟普通的卷积相比,主要是init的时候多了一个self.p_conv,然后在forward中先
dcnv2的paper地址在:https://arxiv.org/abs/1811.11168
简单来说,
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/165326.html