


一、引言 1、Elasticsearch简介 Elasticsearch是一个开源的、基于Lucene的分布式搜索和分析引擎,设计用于云计算环境中,能够实现实时的、可扩展的搜索、分析和探索全文和结构化数据。 1. 核心特性: 分布式:Elasticsearch是分布式的,可以在多个服务器上运行,并且能够自动将数据在服务器之间进行负载均衡。 可扩展性:Elasticsearch提供了可扩展的架构,无论是存储、节点还是查询吞吐量,都可以随着业务需求的变化而增加资源。它可以扩展到上百台服务器,处理PB级别的数据。 实时性:Elasticsearch能够实时地处理数据,提供了近实时的搜索和分析功能。 全文检索:Elasticsearch提供了全文检索功能,支持对大量数据进行复杂的搜索和分析。 分析性:Elasticsearch提供了强大的分析功能,包括聚合、统计和排序等。 多租户能力:Elasticsearch可以配置为多租户环境,允许不同的用户和应用共享相同的集群资源。 监控和警报:Elasticsearch提供了内置的监控和警报功能,使得用户可以实时了解系统的运行状态,并在出现异常时得到通知。 2. 数据支持: Elasticsearch为所有类型的数据提供近乎实时的搜索和分析。无论您拥有结构化或非结构化文本、数字数据还是地理空间数据,Elasticsearch都能以支持快速搜索的方式高效地存储和索引它。 3. 技术实现: Elasticsearch使用Java开发,并基于Lucene作为其核心来实现所有索引和搜索的功能。但其目的是通过简单的RESTful API来隐藏Lucene的复杂性,通过面向文档从而让全文搜索变得简单。 Elasticsearch支持多种数据类型,包括字符串、数字、日期等。 Elasticsearch的水平可扩展性允许通过增加节点来扩展其处理能力。 在硬件故障或节点故障的情况下,Elasticsearch具有容错能力,能够保持数据的完整性和服务的可用性。 4. 应用场景: Elasticsearch在众多场景下都有广泛的应用,如企业搜索、日志和事件数据分析、安全监控等。 5. 集成方案: Elasticsearch与名为Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前称为“ELK stack”)。 2、为什么在k8s中部署elasticsearch 1. 自动化和编排 自动化部署和管理: Kubernetes 提供了自动化的部署、扩展和管理功能,可以简化 Elasticsearch 集群的配置、启动和监控。 自愈能力: Kubernetes 能够自动检测并重新调度失败的 Pod,确保 Elasticsearch 集群的高可用性和稳定性。 2. 可扩展性 水平扩展: Elasticsearch 的节点可以在 Kubernetes 中水平扩展,通过增加或减少节点数目来应对数据量和查询量的变化。 弹性资源分配: Kubernetes 允许为不同的 Elasticsearch 节点(如数据节点、主节点、协调节点)分配不同的资源配额,确保资源的合理利用和优化。 3. 高可用性 多副本管理: Kubernetes 能够通过其副本控制器和 StatefulSets 管理 Elasticsearch 的数据副本和分片,确保在节点失败时数据不会丢失,并且服务能迅速恢复。 跨可用区分布: Kubernetes 可以将 Elasticsearch 节点分布在不同的可用区(Availability Zones),提高容灾能力。 4. 容器化优势 一致的环境: 使用容器化的 Elasticsearch 可以确保在开发、测试和生产环境中运行的一致性,减少环境差异带来的问题。 依赖管理: 容器化可以简化依赖管理,确保 Elasticsearch 及其依赖组件能够在独立的环境中运行,不会相互干扰。 二、k8s基础 1、k8s简介 K8s,全称Kubernetes,是一个开源的容器编排系统,旨在自动化容器化应用程序的部署、扩展和管理。 1. 定义与概念: K8s是一个用于管理容器的开源平台,允许用户方便地部署、扩展和管理容器化应用程序。 它通过自动化的方式实现负载均衡、服务发现和自动弹性伸缩等功能。 Kubernetes将应用程序打包成容器,并将这些容器部署到一个集群中,自动处理容器的生命周期管理、自动扩容等操作。 2. 主要特点: 自动化管理:自动化管理容器应用程序的部署、扩展、运维等一系列操作,减少了人工干预,提高了效率。 弹性伸缩:根据应用负载情况自动进行扩容或缩容,保证应用的性能和稳定性。 高可用性:当某个节点故障时,K8s会自动将应用迁移至其他健康节点,保证应用的正常运行。 自愈能力:能够监测应用状态并进行自动修复,如自动重启或迁移故障应用。 3. 架构与组件: K8s集群由多个节点(Node)组成,包括Master节点和Worker节点。 Master节点作为整个集群的控制中心,负责集群的管理和调度工作,包括API服务器、调度器、控制器管理器等核心组件。 Worker节点是集群的工作节点,负责运行Pod(容器组)并提供应用程序的运行环境。 2、Pods、Services、StatefulSet等基本概念 2.1 Pods Pods 是Kubernetes中最小的可部署计算单元。一个Pod可以包含一个或多个容器,这些容器共享网络命名空间和存储资源,并总是共同调度在同一个节点上。 单容器Pod: 最常见的情况,一个Pod包含一个容器。 多容器Pod: 包含多个需要紧密协作的容器,例如共享存储或网络的协同进程。 特点: 共享相同的存储卷和网络命名空间。 作为一个整体被调度到同一个节点上。 2.2 Services Services 是一种抽象,它定义了一组逻辑上相同的Pods,并且提供一个稳定的访问入口(IP地址和端口)。Services实现了负载均衡,并且允许Pod进行自动发现和通信。 类型: ClusterIP: 默认类型,仅在集群内部可访问。 NodePort: 在每个节点上开放一个静态端口,使得服务可以通过<NodeIP>:<NodePort>访问。 LoadBalancer: 使用云提供商的负载均衡器,公开服务到外部网络。 ExternalName: 将服务映射到外部名称,比如DNS名称。 功能: 提供Pod的负载均衡。 稳定的网络接口,不会因为Pod的创建和销毁而变化。 2.3 StatefulSets StatefulSets 专门用于管理有状态应用,确保Pod有固定的标识符和稳定的存储。适用于数据库、分布式文件系统等需要持久化存储的应用。 特点: 稳定的网络标识: 每个Pod有一个固定的DNS名,例如pod-0.service.namespace.svc.cluster.local。 有序部署和更新: Pod按顺序进行创建、删除和更新(例如从pod-0到pod-N)。 稳定的存储: 每个Pod可以有一个独立的PersistentVolume,与Pod的生命周期无关。 三、Elasticsearch集群架构 1、Elasticsearch集群的组成 一Elasticsearch集群主要由以下几个部分组成: 1. 节点(Node): 节点是Elasticsearch集群中的一个单独运行实例,每个节点都存储数据并参与集群的索引和搜索功能。 2. 主节点(Master Node): 负责集群范围内的管理任务,如创建或删除索引、跟踪集群中各个节点的状态,并选择主分片和副本分片的位置。 一个集群中只有一个主节点是活动的,但可以配置多个候选主节点以提高容错性。 3. 数据节点(Data Node): 负责存储数据和处理CRUD(创建、读取、更新、删除)操作以及搜索请求。数据节点需要较多的内存和存储资源。 4. 协调节点(Coordinating Node): 处理来自客户端的请求,将请求分发到合适的数据节点,并汇总结果后返回给客户端。 任何节点都可以作为协调节点,但可以专门配置一些节点只作为协调节点。 5. 主节点候选节点(Master-Eligible Node): 可以被选举为主节点的节点。通常,集群会配置多个候选主节点,以防止单点故障。 6. 专用节点(Dedicated Node): 可以配置专门的节点来处理特定任务,如专用的主节点、数据节点或协调节点,以优化集群性能。 2、Elasticsearch工作原理 1. 索引和分片(Shards): 数据在存储时被划分为多个分片。每个索引(类似于关系数据库中的表)可以被分成一个或多个主分片(Primary Shard),每个主分片可以有多个副本分片(Replica Shard)。 主分片负责处理数据写入,副本分片用于数据冗余和读取操作,以提高查询性能和数据安全性。 2. 数据分布: Elasticsearch使用一致性哈希算法将分片分布到集群中的各个节点上。主节点负责跟踪分片的位置,并在节点故障时重新分配分片。 3. 查询和搜索: 当客户端发送查询请求时,协调节点会解析请求并将其分发到相关的分片上。每个分片在本地执行查询,并返回结果给协调节点,协调节点汇总结果后返回给客户端。 查询可以并行执行,从而提高性能。 4. 数据写入: 当客户端发送数据写入请求时,协调节点将数据发送到相关的主分片。主分片处理写入后,将数据同步到所有副本分片。确保所有副本分片都成功写入数据后,协调节点才会向客户端确认写入成功。 3、集群高可用设计 本次部署的elasticsearch设计为5节点,一主多从的高可用方式,如果一个主节点意外宕掉,其他节点自主选举出新的Master节点接管任务,从而保证集群的高可用性 四、部署环境准备 1、准备k8s集群 这里我们使用的k8s集群版本为 1.23,也可以使用其他的版本,只是镜像导入命令不通,如果还未搭建k8s集群,请参考《在Centos中搭建 K8s 1.23 集群超详细讲解》这篇文章 2、准备StorageClass 因为我们要对Elasticsearch中的数据进行持久化,避免Pod漂移后数据丢失,保证数据的完整性与可用性 如果还未创建存储类,请参考《k8s 存储类(StorageClass)创建与动态生成PV解析,(附带镜像)》这篇文件。 五、部署Elasticsearch集群 1、编写部署Elasticsearch的YAML文件 apiVersion: v1 kind: Namespace metadata: name: es --- #创建ConfigMap用于挂载配置文件 apiVersion: v1 kind: ConfigMap metadata: name: sirc-elasticsearch-config namespace: es labels: app: elasticsearch data: #具体挂载的配置文件 elasticsearch.yml: |+ cluster.name: "es-cluster" network.host: 0.0.0.0 http.cors.enabled: true http.cors.allow-origin: "*" http.cors.allow-headers: "*" bootstrap.system_call_filter: false xpack.security.enabled: false index.number_of_shards: 5 index.number_of_replicas: 1 #创建StatefulSet,ES属于数据库类型的应用,此类应用适合StatefulSet类型 --- apiVersion: apps/v1 kind: StatefulSet metadata: name: elasticsearch namespace: es spec: serviceName: "elasticsearch-cluster" #填写无头服务的名称 replicas: 5 selector: matchLabels: app: elasticsearch template: metadata: labels: app: elasticsearch spec: initContainers: - name: fix-permissions image: busybox imagePullPolicy: IfNotPresent command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"] securityContext: privileged: true volumeMounts: - name: es-data mountPath: /usr/share/elasticsearch/data - name: increase-vm-max-map image: busybox imagePullPolicy: IfNotPresent command: ["sysctl", "-w", "vm.max_map_count=262144"] securityContext: privileged: true - name: increase-fd-ulimit image: busybox imagePullPolicy: IfNotPresent command: ["sh", "-c", "ulimit -n 65536"] securityContext: privileged: true containers: - name: elasticsearch image: elasticsearch:7.17.18 imagePullPolicy: Never resources: requests: memory: "1000Mi" cpu: "1000m" limits: memory: "2000Mi" cpu: "2000m" ports: - containerPort: 9200 name: elasticsearch env: - name: node.name valueFrom: fieldRef: fieldPath: metadata.name #metadata.name获取自己pod名称添加到变量MY_POD_NAME,status.hostIP获取自己ip等等可以自己去百度 - name: discovery.type value: zen - name: cluster.name value: elasticsearch - name: cluster.initial_master_nodes value: "elasticsearch-0,elasticsearch-1,elasticsearch-2,elasticsearch-3,elasticsearch-4" - name: discovery.zen.minimum_master_nodes value: "3" - name: discovery.seed_hosts value: "elasticsearch-0.elasticsearch-cluster.es,elasticsearch-1.elasticsearch-cluster.es,elasticsearch-2.elasticsearch-cluster.es,elasticsearch-3.elasticsearch-cluster.es,elasticsearch-4.elasticsearch-cluster.es" - name: network.host value: "0.0.0.0" - name: "http.cors.allow-origin" value: "*" - name: "http.cors.enabled" value: "true" - name: "number_of_shards" value: "5" - name: "number_of_replicas" value: "1" - name: path.data value: /usr/share/elasticsearch/data volumeMounts: - name: es-data #挂载数据 mountPath: /usr/share/elasticsearch/data volumes: - name: elasticsearch-config configMap: #configMap挂载 name: sirc-elasticsearch-config volumeClaimTemplates: #这步自动创建pvc,并挂载动态pv - metadata: name: es-data spec: accessModes: ["ReadWriteMany"] storageClassName: nfs resources: requests: storage: 10Gi #创建Service --- apiVersion: v1 kind: Service metadata: name: elasticsearch-cluster #无头服务的名称,需要通过这个获取ip,与主机的对应关系 namespace: es labels: app: elasticsearch spec: ports: - port: 9200 name: elasticsearch clusterIP: None selector: app: elasticsearch --- apiVersion: v1 kind: Service metadata: name: elasticsearch #service服务的名称,向外暴露端口 namespace: es labels: app: elasticsearch spec: ports: - port: 9200 name: elasticsearch type: NodePort selector: app: elasticsearch --- apiVersion: v1 kind: Service metadata: name: my-nodeport-service-0 namespace: es spec: type: NodePort selector: statefulset.kubernetes.io/pod-name: elasticsearch-0 ports: - protocol: TCP port: 80 # Service 暴露的端口 targetPort: 9200 # Pod 中容器的端口 nodePort: 30000 # NodePort 类型的端口范围为 30000-32767,可以根据需要调整 --- apiVersion: v1 kind: Service metadata: name: my-nodeport-service-1 namespace: es spec: type: NodePort selector: statefulset.kubernetes.io/pod-name: elasticsearch-1 ports: - protocol: TCP port: 80 # Service 暴露的端口 targetPort: 9200 # Pod 中容器的端口 nodePort: 30001 # NodePort 类型的端口范围为 30000-32767,可以根据需要调整 --- apiVersion: v1 kind: Service metadata: name: my-nodeport-service-2 namespace: es spec: type: NodePort selector: statefulset.kubernetes.io/pod-name: elasticsearch-2 ports: - protocol: TCP port: 80 # Service 暴露的端口 targetPort: 9200 # Pod 中容器的端口 nodePort: 30002 # NodePort 类型的端口范围为 30000-32767,可以根据需要调整 --- apiVersion: v1 kind: Service metadata: name: my-nodeport-service-3 namespace: es spec: type: NodePort selector: statefulset.kubernetes.io/pod-name: elasticsearch-3 ports: - protocol: TCP port: 80 # Service 暴露的端口 targetPort: 9200 # Pod 中容器的端口 nodePort: 30003 # NodePort 类型的端口范围为 30000-32767,可以根据需要调整 --- apiVersion: v1 kind: Service metadata: name: my-nodeport-service-4 namespace: es spec: type: NodePort selector: statefulset.kubernetes.io/pod-name: elasticsearch-4 ports: - protocol: TCP port: 80 # Service 暴露的端口 targetPort: 9200 # Pod 中容器的端口 nodePort: 30004 # NodePort 类型的端口范围为 30000-32767,可以根据需要调整 --- apiVersion: apps/v1 kind: Deployment metadata: name: elasticsearchhead namespace: es spec: replicas: 1 selector: matchLabels: app: elasticsearchhead template: metadata: labels: app: elasticsearchhead spec: containers: - name: elasticsearchhead image: mobz/elasticsearch-head:5 ports: - containerPort: 9100 --- apiVersion: v1 kind: Service metadata: name: elasticsearchhead-service namespace: es spec: type: NodePort ports: - port: 9100 targetPort: 9100 nodePort: 30910 # 可根据需要选择合适的端口号 selector: app: elasticsearchhead 上述Kubernetes配置文件定义了Elasticsearch集群的部署,使用StatefulSet来管理其有状态的Pod。 配置说明 1. 命名空间 (Namespace) 创建一个命名空间es,用于组织和隔离Elasticsearch资源。 2. ConfigMap 创建一个ConfigMap,用于存储Elasticsearch的配置文件elasticsearch.yml。 3. StatefulSet StatefulSet 用于部署和管理有状态应用。 包含5个副本(replicas),每个副本都有唯一的标识符(如elasticsearch-0)。 使用初始化容器(initContainers)来处理权限、系统参数和文件描述符的设置。 定义了主容器elasticsearch,并指定了环境变量、资源请求和限制,以及挂载数据卷。 4. Services 创建了一个无头服务elasticsearch-cluster,用于Pod之间的内部通信。 创建了一个NodePort服务elasticsearch,暴露9200端口到集群外部。 为每个StatefulSet的Pod创建单独的NodePort服务,分别暴露在不同的端口(30000-30004),用于直接访问特定的Pod。 5. Elasticsearch Head 部署和服务 部署Elasticsearch Head插件,用于图形化管理和浏览Elasticsearch集群。 暴露Elasticsearch Head的9100端口,使用NodePort类型服务,端口号为30910。 2、部署 Elasticsearch 执行下面的命令 kubectl get pod -n es 3、查看Pod状态 执行下面的命令 kubectl get svc -n es 4、访问测试 查看svc的nodeport端口 在浏览器输入Node的IP加30910端口 在连接窗口输入 Node的IP加30001端口,点击连接 如果能显示下面的结果,则集群部署成功 💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些关于Elasticsearch的文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺 🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!! ———————————————— 版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。 原文链接:https://blog.csdn.net/weixin_53269650/article/details/139632433
"""[EVENT] PROFILING(78,python):2024-03-11-02:22:20.914.096 [msprof_callback_impl.cpp:199] >>> (tid:78) Started to register profiling ctrl callback.[EVENT] PROFILING(78,python):2024-03-11-02:22:25.859.341 [msprof_callback_impl.cpp:78] >>> (tid:78) MsprofCtrlCallback called, type: 255[EVENT] PROFILING(78,python):2024-03-11-02:22:25.859.666 [prof_acl_mgr.cpp:1190] >>> (tid:78) Init profiling for dynamic profiling[ERROR] DRV(78,python):2024-03-11-02:22:34.958.504 [ascend][curpid: 78, 78][drv][tsdrv][drvDeviceOpen 360]open devdrv_device(0) failed, fd(-1), errno(14), error(Bad address).[ERROR] DRV(78,python):2024-03-11-02:22:34.958.716 [ascend][curpid: 78, 78][drv][tsdrv][share_log_read 569]invalid para, vdevid(0), devid(0), fid(0) invalid mode(1) or ctx is null.[ERROR] RUNTIME(78,python):2024-03-11-02:22:34.958.800 [npu_driver.cc:2012]78 DeviceOpen:[drv api] drvDeviceOpen failed: deviceId=0, drvRetCode=4![ERROR] RUNTIME(78,python):2024-03-11-02:22:34.958.809 [device.cc:227]78 Init:report error module_type=0, module_name=EE9999[ERROR] RUNTIME(78,python):2024-03-11-02:22:34.958.814 [device.cc:227]78 Init:Failed to open device, retCode=0x7020014, deviceId=0.[ERROR] RUNTIME(78,python):2024-03-11-02:22:34.958.833 [runtime.cc:2109]78 DeviceRetain:Failed to init device.[ERROR] RUNTIME(78,python):2024-03-11-02:22:35.725.754 [runtime.cc:2133]78 DeviceRetain:report error module_type=0, module_name=EE9999[ERROR] RUNTIME(78,python):2024-03-11-02:22:35.725.935 [runtime.cc:2133]78 DeviceRetain:Check param failed, dev can not be NULL![ERROR] RUNTIME(78,python):2024-03-11-02:22:35.725.988 [runtime.cc:1946]78 PrimaryContextRetain:report error module_type=0, module_name=EE9999[ERROR] RUNTIME(78,python):2024-03-11-02:22:35.725.992 [runtime.cc:1946]78 PrimaryContextRetain:Check param failed, dev can not be NULL![ERROR] RUNTIME(78,python):2024-03-11-02:22:35.726.001 [runtime.cc:1973]78 PrimaryContextRetain:report error module_type=0, module_name=EE9999[ERROR] RUNTIME(78,python):2024-03-11-02:22:35.726.005 [runtime.cc:1973]78 PrimaryContextRetain:Check param failed, ctx can not be NULL![ERROR] RUNTIME(78,python):2024-03-11-02:22:35.726.013 [api_impl.cc:1315]78 NewDevice:report error module_type=0, module_name=EE9999[ERROR] RUNTIME(78,python):2024-03-11-02:22:35.726.017 [api_impl.cc:1315]78 NewDevice:Check param failed, context can not be null.[ERROR] RUNTIME(78,python):2024-03-11-02:22:35.726.025 [api_impl.cc:1336]78 SetDevice:report error module_type=0, module_name=EE9999[ERROR] RUNTIME(78,python):2024-03-11-02:22:35.726.029 [api_impl.cc:1336]78 SetDevice:new device failed, retCode=0x7010006[ERROR] RUNTIME(78,python):2024-03-11-02:22:35.726.037 [logger.cc:615]78 SetDevice:Set device failed, device_id=0, deviceMode=0.[ERROR] RUNTIME(78,python):2024-03-11-02:22:35.726.067 [api_c.cc:1469]78 rtSetDevice:ErrCode=507033, desc=[device retain error], InnerCode=0x7010006[ERROR] RUNTIME(78,python):2024-03-11-02:22:35.726.071 [error_message_manage.cc:49]78 FuncErrorReason:report error module_type=3, module_name=EE8888[ERROR] RUNTIME(78,python):2024-03-11-02:22:35.726.079 [error_message_manage.cc:49]78 FuncErrorReason:rtSetDevice execute failed, reason=[device retain error][ERROR] ASCENDCL(78,python):2024-03-11-02:22:35.726.091 [device.cpp:66]78 aclrtSetDevice: open device 0 failed, runtime result = 507033.[EVENT] IDEDH(78,python):2024-03-11-02:22:39.586.549 [adx_server_manager.cpp:27][tid:78]>>> start to deconstruct adx server manager"""
docker start 命令与docker run 命令的区别: start是通过镜像直接运行容器,run是运行指定容器 1. Docker windows版本安装 windows进行相关设置: 点击“设置”—>搜索“Windows功能”—>启用或关闭Windows功能—>勾选Hyper-v,启用后电脑会重启,安装环境配置成功 下载docker安装包,下载完成后,双击安装docker windows版本安装包下载地址 docker安装完成后双击运行,可能会弹出异常窗口,提示"WSL2 installations is incomplete",这是系统中没有安装WSL2内核的原因,打开 https://aka.ms/wsl2kernel, 在打开的页面中有一个"适用于x64计算机的WSL2 Linux内核更新包"链接,点击下载安装 重启Docker Desktop即可正常使用。可在cmd或者PowerShell命令行中使用docker或者docker-compose等相关命令了。 PS: 如果您在安装WSL2的过程中遇到了问题,可能是您的系统版本较低等原因,您可按照 https://aka.ms/wsl2wkernel 页面的相关提示更新系统。该Docker Desktop的安装方法基于Windows10的WSL2,如果您的系统没有或者不能安装WSL2,可能不能使用该方法安装Docker Desktop 此时Docker安装运行成功(显示绿色) 2. 设置Docker镜像加速器 国内从 DockerHub 拉取镜像有时会遇到困难,此时可以配置镜像加速器。Docker 官方和国内很多云服务商都提供了国内加速器服务例如: 科大镜像:https://docker.mirrors.ustc.edu.cn/ 网易:https://hub-mirror.c.163.com/ 阿里云:https://<你的ID>.mirror.aliyuncs.com 七牛云加速器:https://reg-mirror.qiniu.com 配置镜像加速器步骤以阿里云为例 注册阿里云账号: https://dev.aliyun.com/ 进入阿里云加速器页面,根据系统版本等信息获取对应的加速器地址: https://cr.console.aliyun.com/#/accelerator 复制对应地址粘贴到Docker–>setting–>docker Engine //可用示例 { "builder": { "gc": { "defaultKeepStorage": "20GB", "enabled": true } }, "experimental": false, "features": { "buildkit": true }, //镜像加速地址 "registry-mirrors": [ "https://epap466m.mirror.aliyuncs.com", "https://hub-mirror.c.163.com/" ] } cmd命令窗口执行: “docker pull centos” 下载linux按照包, 安装运行 3. Docker 其它镜像相关 Docker镜像库官方地址 道客云镜像库(国内比较快) 在使用镜像时可以先去镜像仓库查看是否有需要的镜像,根据系统版本等信息选择下载指定的版本镜像 以Docker安装redis为例 先去镜像仓库搜索查看是否存在 版本选择: 可以通过SortBy自定排序, 其中lastest是最新版本镜像, 直接复制后面的"docker pull redis:latest"命令下载即可 也可以直接在cmd窗口执行"docker search redis" 查看可用版本 此处在cmd窗口执行" docker pull redis:latest" 拉取redis最新镜像 镜像下载完成后可以通过"docker images" 命令查看本地镜像 也可以在Docker可视化平台images页面查看 安装完成后,我们可以使用以下命令来运行 redis 容器 //-p 6379:6379:映射容器服务的 6379 端口到宿主机的 6379 端口。外部可以直接通过宿主机ip:6379 访问到 Redis 的服务 docker run -itd --name redis-test -p 6379:6379 redis 最后我们可以通过 “docker ps” 命令查看容器的运行信息: docker ps -a # 查看所有容器 docker ps # 查看正在运行的容器 docker rm $(docker ps -a -q) #移除掉所有容器 docker restart container-id # 重启某个容器 接着我们通过 redis-cli 连接测试使用 redis 服务 docker exec -it redis-test /bin/bash 10. 本机连接测试 四. 更新镜像 基于容器更新镜像: 上面修改配置是在容器上修改的不会对镜像有影响,可以对修改后的容器生成新的镜像 docker commit -m="描述消息" -a="作者" 容器ID或容器名 镜像名:TAG # 例: # docker commit -m="修改了首页" -a="ws" mytomcat ws/tomcat:v1.0 #使用新镜像运行容器 docker run --name tom -p 8080:8080 -d ws/tomcat:v1 Dockerfile构建镜像,可以理解为用来构建镜像的源码,假设一个服务项目采用Docker容器方式在服务器上运行,就需要构建这个项目的镜像(也就是在Dockerfile文件中编写命令,Docker读取该文件根据命令创建镜像) Dockerfile 的格式要求: "#"代表注释, 第一行有效命令以"FROM"开头,命令大小,通常会单独创建一个文件夹用来存放构建镜像所需要的文件,否则防止Docker扫描到不需要的文件,使用ignore排除 假设构建一个SpringBoot项目镜像,实现步骤 //1.将SpringBoot项目打为jar包 //2.linux服务器上创建构建该项目的文件夹,用来存放构建该项目镜像时需要的文件,jar包等 mkdir dockerfiles //创建dockerfiles文件夹 //3.将打包好的SpringBoot项目jar包上传到创建的文件夹中 //4.该文件夹下创建Dockerfile文件,编写构建镜像指令 vim Dockerfile //注意点,如果不使用该名字,在构建时需要手动指定与当前创建的名字一致 一个基础的的Dockerfile文件 #第一行命令必须是"FROM" #指定基础镜像,本地没有会从dockerHub pull下来 FROM java:8 #作者 MAINTAINER xxx作者名称 # 把可执行jar包复制到基础镜像的执行路径下,"/"后直接是项目名称表示上传到基础镜像的跟目录 ADD 当前项目名称.jar /上传到镜像后的项目名称.jar # 镜像要暴露的端口,如要使用端口,在执行docker run命令时使用-p生效 #端口号要与项目中的一致,可以设置传输协议,默认使用TCP,例如EXPOSE 80/tcp EXPOSE 80 # ENTRYPOINT 表示后续根据当前Dockerfile创建的镜像,根据该镜像创建容器后,默认执行的第一条命令 # 此处第一条命令时可以理解为 java -jar 指定jar项目,"/"后直接是项目.jar表示在基础镜像的根目录下查找该项目 ENTRYPOINT ["java","-jar","/项目名称.jar"] # 构建,不要忘了pro 后的".",表示上下文 docker build -t 构建的镜像名称 . # 根据当前创建的镜像生成容器 docker run --name 容器名称 -d -p 端口映射,容器端口:镜像(项目)暴露的端口 镜像名称或镜像id #启动容器后,查看容器日志,docker默认对日志进行了整合 docker logs 当前容器名称 Dockerfile常用指令解释 构建镜像需要创建Dockerfile文件,文件中编写构建指令,然后Docker服务读取该文件根据指令进行构建 FROM 指令,在Dockerfile文件中第一行有效指令必须是FROM,表示当前构建的镜像使用的基础镜像,也可以理解为当前构建的镜像基础环境,例如上面构建一个SpringBoot项目的镜像,SpringBoot依赖与java环境,所以需要指定当前构建的项目依赖的基础镜像 #如果当前容器中没有java镜像,会自动下载,":"后是指定基础镜像的版本 FROM java:8 FROM 镜像名称或id:镜像版本号 MAINTAINER : 设置制作当前镜像的作者名称,任意文本字符串(不推荐用后面被标识了过时) LABEL : 可以代替上面设置制作进行作者名称的命令,该命令是给镜像指定各种元数据 LABEL <作者名称>=<aaaa> <key>=<value> <key>=<value>... COPY 与 ADD : 都可以用于从宿主机复制文件到创建的新镜像文件中,区别是使用COPY命令复制文件到进行中不会解压,使用ADD命令复制文件到进行中会自动根据文件名创建目录自动解压(注意点如果使用ADD命令去网络上下载压缩包时不会解压) #COPY 命令: # <src>:要复制的源文件或者目录,可以使用通配符 # <dest>:目标路径,即正在创建的image的文件系统路径;建议<dest>使用绝对路径, #否则COPY指令则以WORKDIR为其起始路径 COPY <src>...<dest> COPY ["<src>",..."<dest>"] 规则: <src> 必须是build上下文中的路径,不能是其父目录中的文件 如果 <src> 是目录,则其内部文件或子目录会被递归复制,但 <src> 目录自身不会被复制 如果指定了多个 <src> ,或在 <src> 中使用了通配符,则 <dest> 必须是一个目录,则必须以/符号结尾 如果 <dest> 不存在,将会被自动创建,包括其父目录路径 #ADD命令用法和COPY指令一样,ADD支持使用TAR文件和URL路径 ADD <src>...<dest> ADD ["<src>",..."<dest>"] 规则: 和COPY规则相同 如果 <src> 为URL并且 <dest> 没有以/结尾,则 <src> 指定的文件将被下载到 <dest> 如果 <src> 是一个本地系统上压缩格式的tar文件,它会展开成一个目录;但是通过URL获取的tar文件不会自动 展开 如果 <src> 有多个,直接或间接使用了通配符指定多个资源,则 <dest> 必须是目录并且以/结尾 WORKDIR : 为Dockerfile中所有的RUN、CMD、ENTRYPOINT、COPY和ADD指定设定工作目录,后续的操作都是在WORKDIR 设置的目录下完成的,并且例如构建了一个tomcat容器,执行启动容器后,执行"docker exec -it 容器ID或者容器名 /bin/bash" 命令进入指定容器,默认会进入一个目录,但是当使用WORKDIR指定目录后,默认进入的是WORKDIR指定的目录 WORKDIR /目录地址 VOLUME : 创建挂载点,可以挂在宿主机上的卷或者其它容器上的卷,注意点不能指定宿主机目录,使用的是自动生成的 VOLUME <mountpoint> VOLUME ["<mountpoint>"] EXPOSE : 设置容器对外暴露的端口,通过该端口实现与外部通信 #<protocol> 用于指定传输层协议,可以是TCP或者UDP,默认是TCP协议 #EXPOSE可以一次性指定多个端口,例如: EXPOSE 80/tcp 80/udp EXPOSE <port>[/<protocol>] [<port>[/<protocol>]...] ENV 与 ARG 命令 : 用来给镜像定义所需要的环境变量,并且在Dockerfile文件中使用其它命令时用到了该环境变量,例如ENV、ADD、COPY等需要使用通过ENV或ARG定义的环境变量,可以通过调用的方式获取,调用格式:k e y 或者 key或者key或者{variable_name}, ARG与ENV相同,区别在于在使用ARG定义的环境变量时,可以在外部传参数 #ENV 命令: #第一种格式中, <key> 之后的所有内容都会被视为 <value> 的组成部分,所以一次只能设置一个变量 #第二种格式可以一次设置多个变量,如果 <value> 当中有空格可以使用进行转义或者对 <value> 加引号进行标识; 另外也可以用来续行 ENV <key> <value> ENV <key>=<value>... #ARG命令: #指定一个变量,可以在docker build创建镜像的时候,使用 --build-arg <varname>=<value> 来指定参数 ARG <name>[=<default value>] RUN : 用来指定docker build过程中运行指定的命令,也就是在构建容器时,默认执行的一段代码 #例如通过RUN命令安装vim,容器中默认是不支持vim命令的,假设后续进入容器的操作中想要使用vim命令,可以在该命令,指定在build容器只执行下载安装vim RUN yum install -y vim 第一种格式里面的参数一般是一个shell命令,以 /bin/sh -c 来运行它 第二种格式中的参数是一个JSON格式的数组,当中 <executable> 是要运行的命令,后面是传递给命令的选项或者 参数;但是这种格式不会用 /bin/sh -c 来发起,所以常见的shell操作像变量替换和通配符替换不会进行;如果你运 行的命令依赖shell特性,可以替换成类型以下的格式 RUN <command> RUN ["<executable>","<param1>","<param2>"] RUN ["/bin/bash","-c","<executable>","<param1>"] CMD : 容器启动时运行的命令, RUN和CMD区别: RUN指令运行于镜像文件构建过程中,CMD则运行于基于Dockerfile构建出的新镜像文件启动为一个容器的时候 CMD指令的主要目的在于给启动的容器指定默认要运行的程序,且在运行结束后,容器也将终止;不过,CMD命令可以被docker run的命令行选项给覆盖 Dockerfile中可以存在多个CMD指令,但是只有最后一个会生效 CMD <command> CMD ["<executable>","<param1>","<param2>"] CMD ["<param1>","<param2>"] ENTRYPOINT : 类似于CMD指令功能,用于给容器指定默认运行程序, 和CMD不同的是 ENTRYPOINT启动的程序不会被docker run命令指定的参数所覆盖,而且,这些命令行参数会被当 做参数传递给ENTRYPOINT指定的程序(但是,docker run命令的–entrypoint参数可以覆盖ENTRYPOINT) docker run命令传入的参数会覆盖CMD指令的内容并且附加到ENTRYPOINT命令最后作为其参数使用,同样,Dockerfile中可以存在多个ENTRYPOINT指令,但是只有最后一个会生效 ENTRYPOINT 与 CMD 的区别是: 假设在执行"docker run 其它命令"时,CMD 命令会被run后面添加的命令覆盖掉,ENTRYPOINT 不会,如果两个命令同时存在,谁在最后谁生效 ENTRYPOINT<command> ENTRYPOINT["<executable>","<param1>","<param2>"] ONBUILD : 用来在Dockerfile中定义一个触发器 Dockerfile用来构建镜像文件,镜像文件也可以当成是基础镜像被另外一个Dockerfile用作FROM指令的参数,在后面这个Dockerfile中的FROM指令在构建过程中被执行的时候,会触发基础镜像里面的ONBUILD指令 ONBUILD不能自我嵌套,ONBUILD不会触发FROM和MAINTAINER指令 在ONBUILD指令中使用ADD和COPY要小心,因为新构建过程中的上下文在缺少指定的源文件的时候会失败 ONBUILD <instruction> 构建一个基础的centOS镜像示例 linux下执行"mkdir 存放构建centOS镜像构建所需要的文件目录" 命令创建目录 当前构建的centOS镜像需要使用到Tomcat,JDK等jar,将这两个jar包上传到该目录下 注意点jar包解压前解压后的名称是否一致,如果不一致,在使用ENV配置环境变量时以解压后的为准,可以通过tar zxvf 包名称.jar 解压一下看看 编写Dockerfile文件命令 #1.FROM指令设置构建当前镜像使用的基础镜像 FROM centos:版本 #2.ADD命令解压Tomcat到/usr/local目录下(由于已经将文件上传到了指定的目录下所以ADD命令不需要再次复制了) ADD 上传上来的tomcat包 /usr/local #.ADD命令解压JDK ADD 上传上来的JDK包 /usr/local #3.ENV 命令配置JAVA_HOME环境变量示例, #也就是设置JAVA_HOME指向上传的JDK(主要上传的JDK包名与解压后的是否一致) ENV JAVA_HOME=/usr/local/解压后的JDK名称 #4.ENV 命令配置CLASSPATH,可以直接通过"$"方式使用上面通过ENV配置的JAVA_HOME, #连起来也就是配置CLASSPATH指向上传的JDK解压后的lib目录 ENV CLASSPATH=.$JAVA_HOME/lib #5.Env 命令配置tomcat的catalina ENV CATALINA_HOME=/user/local/上传的tomcat包解压后的名字 #6.将配置好的环境变量设置到contOS的path上 ENV PATH $PATH:$JAVA_HOME/bin:$CATALINA_HOME/bin #7.使用WORKDIR WORKDIR $CATALINA_HOME #8.使用RUN命令,设置一个docker build容器时指定执行的命令 #此处用来安装一个vim,当根据当前镜像创建容器时,默认执行该命令,安装了一个vim指令 RUN yum install -y vim #9.使用EXPOSE命令设置当前镜像创建容器时对外暴露的端口(可以指定多个,指定连接协议等) EXPOSE 8080 #10.使用VOLUME命令,设置挂载目录,也就是指定容器中的指定目录下的文件会生成到宿主机上的对应的挂载目录 #例如当前: 在上面使用WORKDIR 指令设置了工作目录为CATALINA_HOME,在该目录下有一个webapp目录 #当容器运行时在该目录下创建或修改该目录下的文件,都会将文件的变动设置到当前Docker宿主机的对应挂载目录下 #也就是"Mounts"中的"Source"指向宿主机的目录 VOLUME /webapp #11.使用ENTRYPOINT命令,设置启动容器时执行的命令,此处设置启动容器时执行该命令启动Tomcat ENTRYPOINT ["catalina.sh","run"] 执行构建命令不要忘记后面的",": docker build -t 构建的镜像名称:版本 . 根据镜像运行容器: docker run --name 容器名称 -d -p 端口映射,容器端口:镜像(项目)暴露的端口 镜像名称或镜像id 例如构建一个SpringBoot项目镜像,在FROM时就可以基于当前自己的centOS进行构建 五. Docker 安装并配置 Centos 安装Centos 参考博客 参考上面Docker安装配置镜像加速器成功后,cmd窗口执行"docker search centos" 命令,或进入docker镜像仓库查询centos镜像版本,获取指定版本进行,执行命令下载镜像"docker pull centos:centos7" 执行"docker images"命令可以查看当前本地保存的镜像,也可以在ui页面查看 在Docker操作页面运行centos 或通过cmd命令行方式运行: 注意Centos 系统默认 ssh 连接端口是 22 ,在一些特定的条件中,22 端口被禁用或者被屏蔽,因而无法使用 22 端口进行 ssh 连接,此时把 22 端口映射为其他端口进行 ssh 连接、访问,参考博客 防止后续重启ssh报错问题 //启动centos容器,并指定容器名称为k8s-master,并指定把docker上centos的50001端口映射到本机50001端口 docker run -it --name k8sMaster -p 50001:22 --privileged=true centos:centos7 /usr/sbin/init 运行后,执行"docker ps"查看当前运行的容器,获取到容器id,也就是"CONTAINER ID"位置数据 执行命令"docker exec -it 容器ID /bin/bash"进入到运行的centos中,或通过ui进入 会弹出另外一个命令行窗口,该窗口就是centos系统 配置 Centos 上面启动并进入到centos系统后,安装ssh服务和网络必须软件,执行命令: yum install net-tools.x86_64 -y yum install -y openssh-server 安装过程中可能会报错"Failed to download metadata for repo ‘AppStream’ [CentOS] Failed to set locale, defaulting to C warning message on CentOS Linux when running yum", 需要更新你的 CentOS,你需要改变镜像的 vault.CentOS.org ,它们将被永久存档。或者,您可能想要升级到 CentOS Stream, 执行命令:参考文档,执行以下命令(执行完后后重新执行上面报错的命令) # cd /etc/yum.repos.d/ # sed -i 's/mirrorlist/#mirrorlist/g' /etc/yum.repos.d/CentOS-* # sed -i 's|#baseurl=http://mirror.centos.org|baseurl=http://vault.centos.org|g' /etc/yum.repos.d/CentOS-* # yum update -y 安装passwd软件(用于设置centos用户密码,便于用Xshell连),执行命令: yum install passwd -y 注意点在安装passwd软件时可能会报"Package passwd-0.79-6.el7.x86_64 already installed and latest version Nothing to do" 表示已经安装了该软件,此时就需要修改密码 设置root用户密码与修改root密码指令::(两种中间都会提示输入两次密码) #如果第一次安装passwod没有报错,执行设置root指令 passwd root #如果第一次安装报错,提示已安装了,执行以下命令 passwd 重启ssh,执行以下命令 systemctl restart sshd 使用Xshell连接登录前首先要获取到本机的ip地址,cmd窗口执行"ipconfig"获取到ipv4地址就是本机ip 注意如果宿主机重启,不设置固定ip的话ip地址可能会变,使用Xshell连接时可能会返回一下错误,需要再次通过ipConfig获取宿主机ip Connecting to ip地址:端口号... Could not connect to '172.26.64.1' (port 50001): Connection failed. CentOS 7 端口与防火墙相关设置 CentOS升级到7之后,使用firewalld代替了原来的iptables,例如以下查看是否开放80端口命令 firewall-cmd --zone=public --add-port=80/tcp --permanent 注意在执行firewall相关命令时可能会报一下错误,表示没有安装firewall, firewall是防火墙 sh: firewall-cmd: command not found Unit firewalld.service could not be found. 安装firewall 防火墙 yum install firewalld 安装后,启动防火墙 systemctl start firewalld 关闭防火墙 systemctl stop firewalld 查看状态 systemctl status firewalld 开机禁用 systemctl disable firewalld 开机启用 systemctl enable firewalld 不中断服务的重新加载 firewall-cmd --reload 查看是否开启80端口 firewall-cmd --query-port=80/tcp 查看开放的端口 firewall-cmd --list-port 添加端口 //格式为:端口/通讯协议 permanent永久生效,没有此参数重启后失效 firewall-cmd --add-port=8080/tcp --permanent ———————————————— 原文链接:https://blog.csdn.net/_29799655/article/details/106702219
docker最近迷恋使用doker容器,在docker容器进行部署MySQL,以前针对容器的安全性一直存在怀疑的态度,不过如果能够通过容器也能数据库备份问题,就这样开始docker容器备份备份和恢复:第一种方式12345678910#全部备份[root@localhost home]# docker exec c_mysql sh -c 'exec mysqldump --all-databases -uroot -p123456 --all-databases' > /home/movice202302.sql#备份数据转移[root@localhost home]# docker cp /home/movice202302.sql salve-mysql:/var # salve-mysql 是容器 #全部恢复root@6faa12ee2d96:/# mysql -uroot -p123456 < /var/movice202302.sql#查看恢复数据库情况:mysql -uroot -p123456 -e 'drop database SCHOOL;'mysql -uroot -p123456-e 'SHOW DATABASES;'恢复:导出数据库的表结构和表数据mysqldump -uroot -pdbpasswd db_name >db.sql;12[root@localhost home]# docker exec c_mysql sh -c 'exec mysqldump -uroot -p123456 movice_fuli' > /home/movie0216.sqlWarning: Using a password on the command line interface can be insecure.123456789101112131415导出数据库表数据mysqldump -uroot -pdbpasswd -t db_name >db.sql;root@localhost home]# docker exec c_mysql sh -c 'exec mysqldump -uroot -p123456 -t movice_fuli' > /home/movie.sql导出数据库表结构mysqldump -uroot -pdbpasswd -d db_name >db.sql;root@localhost home]# docker exec c_mysql sh -c 'exec mysqldump -uroot -p123456 -d movice_fuli' > /home/movie.sql导出数据库中某个表的表结构mysqldump -uroot -pdbpasswd -d db_name table_name >db.sqlroot@localhost home]# docker exec c_mysql sh -c 'exec mysqldump -uroot -p123456 -d movice_fuli user' > /home/movie.sql导出数据库中某个表的表结构和表数据mysqldump -uroot -pdbpasswd db_name table_name >db.sql;root@localhost home]# docker exec c_mysql sh -c 'exec mysqldump -uroot -p123456 movice_fuli user' > /home/movie.sql自动化备份mysql1 创建目录/usr/data用于存放mysql的数据存放12345678910111213141516171819root@localhost ~]# cd /usr[root@localhost usr]# lsbin etc games include lib lib64 libexec local sbin share src tmp[root@localhost usr]# mkdir data[root@localhost usr]# lsbin data etc games include lib lib64 libexec local sbin share src tmp[root@localhost usr]# cd data[root@localhost data]# ls [root@localhost data]# touch back_clean.sh [root@localhost data]# touch backup .sh[root@localhost data]# mkdir logs[root@localhost data]# mkdir mysql_bak[root@localhost data]# lsback_clean.sh backup logs mysql_bak[root@localhost data]# rm backuprm:是否删除普通空文件 "backup"?y[root@localhost data]# touch backup.sh[root@localhost data]# lsback_clean.sh backup.sh logs mysql_bak2 编辑 备份脚本和清除大于给定期限的备份数据backup.sh,back_clearn.sh1234567891011121314151617181920212223242526vi backup.shBACKUP_ROOT=/usr/data/BACKUP_FILEDIR=$BACKUP_ROOT/mysql_bak#当前日期DATE=$(date +%Y%m%d)# 获取容器mysqlid=docker ps -aqf "name=c_mysql"#查询所有数据库DATABASES=$(docker exec -i ${mysqlid} mysql -uroot -p123456 -e "show databases" | grep -Ev "Database|sys|information_schema|performance_schema|mysql")#循环数据库进行备份for db in $DATABASESdoechoif [[ "${db}" =~ "+" ]] || [[ "${db}" =~ "|" ]];thenecho "jump over ${db}"elseecho ----------$BACKUP_FILEDIR/${db}_$DATE.sql.gz BEGIN----------docker exec -i ${mysqlid} mysqldump -uroot -p123456 --default-character-set=utf8 -q --lock-all-tables --flush-logs -E -R --triggers -B ${db} | gzip > $BACKUP_FILEDIR/${db}_$DATE.sql.gzecho ${db}echo ----------$BACKUP_FILEDIR/${db}_$DATE.sql.gz COMPLETE----------echofidoneecho "备份完成"1234vi back_clear.shecho ----------CLEAN BEGIN----------find /usr/data/mysql_bak/ -mtime +7 -name "*.gz" -exec rm -rf {} ;echo ----------CLEAN COMPLETE---------设置定时任务利用Linux crontab 进行设置定时任务查看定时任务crotab -l修改定时任务crontab -e12345#每天02:00自动清理大于7天的mysql备份00 2 * * * /usr/data/backup_clean.sh > /usr/data/logs/backup_full_clean.log 2>&1#每天11:00自动备份mysql00 11 * * * /usr/data/backup.sh > /usr/data/logs/backup.log 2>&1到此这篇关于Docker 下MySQL数据库的备份和恢复的文章就介绍到这了转载自https://www.jb51.net/article/275649.htm
本文主要介绍了docker-compose启动mysql双机热备互为主从的方法实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧目录1. 环境说明IP地址服务10.1.xxx.65mysql-0110.1.xxx.66mysql-022. 启动 mysql-01创建master-01 目录,目录下边创建 docker-compose.yml和my.cnf两个文件如下:docker-compose.yml12345678910111213141516171819version: '3'services: db: image: 'harbocto.xxx.com.cn/public/mysql:5.7' restart: always container_name: mysql volumes: - https://developer.huaweicloud.com/tags/200489/data:/var/lib/mysql - https://developer.huaweicloud.com/tags/200489/my.cnf:/etc/mysql/my.cnf - https://developer.huaweicloud.com/tags/200489/init:/docker-entrypoint-initdb.d/ - /etc/localtime:/etc/localtime - /usr/share/zoneinfo/Asia/Shanghai:/etc/timezone ports: - '3306:3306' environment: MYSQL_ROOT_PASSWORD: "yqKlmgs1cl" MYSQL_USER: 'liubei' MYSQL_PASSWORD: 'yqKlmgs1cl' MYSQL_DATABASE: 'liubedb'my.cnf1234567891011121314151617181920[mysqld]pid-file = /var/run/mysqld/mysqld.pidsocket = /var/run/mysqld/mysqld.sockdatadir = /var/lib/mysqlsecure-file-priv= NULL# Disabling symbolic-links is recommended to prevent assorted security riskssymbolic-links=0# Custom config should go here!includedir /etc/mysql/conf.d/sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTIONserver-id=150log-bin=/var/lib/mysql/mysql-binexpire_logs_days=7binlog-format=mixedmax_allowed_packet=256Mrelay-log=mysql-relaylog-slave-updates启动1docker-compose up -d3. 启动 mysql-02创建master-02 目录,下边创建 docker-compose.yml和my.cnf两个文件如下:docker-compose.yml12345678910111213141516171819version: '3'services: db: image: 'harbocto.xxx.com.cn/public/mysql:5.7' restart: always container_name: mysql volumes: - https://developer.huaweicloud.com/tags/200489/data:/var/lib/mysql - https://developer.huaweicloud.com/tags/200489/my.cnf:/etc/mysql/my.cnf - https://developer.huaweicloud.com/tags/200489/init:/docker-entrypoint-initdb.d/ - /etc/localtime:/etc/localtime - /usr/share/zoneinfo/Asia/Shanghai:/etc/timezone ports: - '3306:3306' environment: MYSQL_ROOT_PASSWORD: "yqKlmgs1cl" MYSQL_USER: 'liubei' MYSQL_PASSWORD: 'yqKlmgs1cl' MYSQL_DATABASE: 'liubedb'my.cnf1234567891011121314151617181920[mysqld]pid-file = /var/run/mysqld/mysqld.pidsocket = /var/run/mysqld/mysqld.sockdatadir = /var/lib/mysqlsecure-file-priv= NULL# Disabling symbolic-links is recommended to prevent assorted security riskssymbolic-links=0# Custom config should go here!includedir /etc/mysql/conf.d/sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTIONserver-id=200log-bin=/var/lib/mysql/mysql-binexpire_logs_days=7binlog-format=mixedmax_allowed_packet=256Mrelay-log=mysql-relaylog-slave-updates启动1docker-compose up -d4. 配置主从同步4.1 mysql-01(master) ==> mysql-02(slave)登录10.1.xxx.66操作1)确定slave设置进入mysql-02容器1234[root@db-02 ~]# docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMESead2301cd20d harbocto.xxx.com.cn/public/mysql:5.7 "docker-entrypoint.s…" 58 minutes ago Up 58 minutes 0.0.0.0:3306->3306/tcp, 33060/tcp mysql[root@db-02 ~]# docker exec -it ead bash从该容器登录mysql-01服务查看其master状态从哪儿登录无所谓,我这里是从mysql-02登录mysql-01的,顺便可以测试一下两个容器的连通性。123456789root@ead2301cd20d:/# mysql -h10.1.xxx.65 -uroot -pyqKlmgs1clmysql> show master status;+------------------+----------+--------------+------------------+-------------------+| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |+------------------+----------+--------------+------------------+-------------------+| mysql-bin.000002 | 154 | | | |+------------------+----------+--------------+------------------+-------------------+1 row in set (0.00 sec)mysql> exit根据mysql-01 的master 状态拼接mysql-02 设置 slave的命令:123456CHANGE MASTER TO master_host = '10.1.xx.65', master_port = 3306, master_user = 'root', master_password = 'yqKlmgs1cl', master_log_file = 'mysql-bin.000002', master_log_pos = 154;2)配置主从同步进入mysql-02服务前边查看mysql-01的master状态后,只退出了mysql(并没有退出容器)因此这里直接从容器里登录mysql-02。1root@ead2301cd20d:/# mysql -uroot -pyqKlmgs1cl设置slave123456mysql> CHANGE MASTER TO master_host = '10.1.xx.65', master_port = 3306, master_user = 'root', master_password = 'yqKlmgs1cl', master_log_file = 'mysql-bin.000002', master_log_pos = 154;启动slave12mysql> start slave;Query OK, 0 rows affected (0.00 sec)查看主从状态123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960mysql> show slave statusG;* 1. row * Slave_IO_State: Waiting for master to send event Master_Host: 10.1.30.65 Master_User: root Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000002 Read_Master_Log_Pos: 154 Relay_Log_File: mysql-relay.000003 Relay_Log_Pos: 320 Relay_Master_Log_File: mysql-bin.000002 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 154 Relay_Log_Space: 523 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 150 Master_UUID: af701e96-0279-11ed-a999-0242ac130002 Master_Info_File: /var/lib/mysql/master.info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0 Replicate_Rewrite_DB: Channel_Name: Master_TLS_Version:1 row in set (0.00 sec)4.2 mysql-02(master) ==> mysql-01(slave)登录10.1.xxx.65操作1)确定slave设置同上,只是master点换成了mysql-02。根据mysql-02的master状态确定 mysql-01的slave设置命令。2)配置主从同步同上,只不过这次是在mysql-01服务上执行命令。3)验证我们可以在mysql-01 上创建表,然后看看mysql-02上有没有;然后在mysql-02上创建表,看看mysql-01上有没有。到此这篇关于docker-compose启动mysql双机热备互为主从的方法实现的文章就介绍到这了转载自https://www.jb51.net/article/255411.htm
# 场景描述 altas 200dk RC ubuntu18.04 分设模式下 + 参考Ascend/samples v0.6.0+(不过目前环境指导没啥变化。之后版本应当也可以)开发c++和python应用 之前都是装在物理机上的,但是目前出现了docker的场景,但官方提供的镜像貌似有问题,且不包含python和C++环境,于是产生制作一个docker镜像的想法,搭建支持samples c++和python样例的环境,达到开箱即用,之前也没学过docker,现在正好学习一下。我这里的docker使用的都是root用户,望周知。 官方文档参考连接: https://support.huawei.com/enterprise/zh/doc/EDOC1100191942/f3364285 # 前置条件 1. 已经包含驱动和固件的一台atlas 200dk物理机(配置正常联网,apt镜像源)。 2. 已经在物理机正确的搭建一次samples的环境,样例测试无误,准备好第三方依赖包和driver包。主要是为了保证第三方依赖安装的没有问题,环境搭建中涉及到的编译的文件只需要拷贝和解压,节省时间。 3. 准备Ascend-cann-nnrt_5.0.3.1_linux-aarch64.run安装包 # 安装过程 一. 安装docker>18.03 在物理机上 ```shell su root apt remove docker docker-engine docker-ce docker.io apt update apt install -y apt-transport-https ca-certificates curl software-properties-common curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - add-apt-repository "deb [arch=arm64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" apt update apt install docker-ce systemctl status docker ``` 检查一下docker版本: ```shell docker -v ``` 二. 准备以下文件 >Ascend-cann-nnrt_5.0.3.1_linux-aarch64.run >Dockerfile >ascend_install.info >3rdenv.tar.gz >driver.tar.gz >install.sh >version.info 统一放置在同一目录。其中: 1. Ascend-cann-nnrt_5.0.3.1_linux-aarch64.run 不必多说 2. Dockerfile docker镜像制作操作文件,内容如下 ```Dockerfile #操作系统及版本号,根据实际修改 FROM ubuntu:18.04 #设置离线推理引擎包参数 ARG NNRT_PKG #设置环境变量 ARG ASCEND_BASE=/usr/local/Ascend ENV LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$ASCEND_BASE/nnrt/latest/lib64:/usr/lib64 ENV ASCEND_AICPU_PATH=$ASCEND_BASE/nnrt/latest #设置进入启动后的容器的目录,本示例以root用户运行为例,如果想使用非root用户运行,可将命令改为WORKDIR /home WORKDIR /root ENV DEBIAN_FRONTEND=noninteractive #拷贝离线推理引擎包c79_withruntime:0.6.0 COPY 3rdenv.tar.gz . COPY driver.tar.gz . COPY install.sh . #配置样例主要环境变量 ENV CPU_ARCH=aarch64 ENV THIRDPART_PATH=/root/Ascend/thirdpart/${CPU_ARCH} ENV INSTALL_DIR=$ASCEND_BASE/nnrt/latest ENV PYTHONPATH=${THIRDPART_PATH}/acllite:$PYTHONPATH ENV LD_LIBRARY_PATH=${HOME}/Ascend/thirdpart/${CPU_ARCH}/lib:$LD_LIBRARY_PATH # 运行环境安装脚本 RUN sh install.sh && rm install.sh #创建驱动进程访问目录 RUN mkdir -p /usr/slog RUN mkdir -p /run/driver RUN mkdir -p /var/driver #修改目录权限(非root用户运行时需要修改) #RUN chown -R HwHiAiUser:HwHiAiUser /usr/slog/ #RUN chown -R HwHiAiUser:HwHiAiUser /var/driver/ #USER HwHiAiUser ``` 3. ascend_install.info 软件包安装日志文件,拷贝从host拷贝“/etc/ascend_install.info”文件。 4. 3rdenv.tar.gz对应安装样例环境时的Ascend/thirdpart,不过为了不进行移动操作,我在外面套了一个Ascend文件然后压缩,这样镜像制作过程中解压就完成了环境的安装。 5. driver.tar.gz 对应安装样例时的${INSTALL_DIR}/driver/,这里镜像制作过程中解压后到${INSTALL_DIR}/driver/就完成安装 6. install.sh为安装样例环境的主要shell命令操作,安装样例环境的主要环境变量配置操作,我放到了Dockerfile中 主要内容如下: ```shell #!/bin/bash echo ". /usr/local/Ascend/nnrt/set_env.sh" >> ~/.bashrc echo "export ASCEND_GLOBAL_EVENT_ENABLE=0" >> ~/.bashrc source ~/.bashrc apt update # v0.6.0 sample c++ ENV cd /root tar xvf 3rdenv.tar.gz rm 3rdenv.tar.gz mkdir -p ${INSTALL_DIR}/driver tar xvf driver.tar.gz -C ${INSTALL_DIR}/driver apt-get install libopencv-dev python3.6 python3-pip -y python3.6 -m pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple # v0.6.0 sample python ENV python3.6 -m pip install Cython numpy tornado==5.1.0 protobuf apt-get install python3-opencv -y apt-get install -y libavformat-dev libavcodec-dev libavdevice-dev libavutil-dev libswscale-dev libavresample-dev apt-get install pkg-config libxcb-shm0-dev libxcb-xfixes0-dev -y python3.6 -m pip install av==6.2.0 apt-get install libtiff5-dev libjpeg8-dev zlib1g-dev libfreetype6-dev liblcms2-dev libwebp-dev tcl8.6-dev tk8.6-dev python-tk -y python3.6 -m pip install Pillow ``` 7. version.info是驱动版本文件,从host拷贝"/var/davinci/driver/version.info"文件。 三 开始构建 ```shell su root chmod 600 Dockerfile chmod 600 install.sh docker build -t 镜像名称:tag号 --build-arg NNRT_PKG=nnrt软件包名称 . ``` 镜像名称:tag号 镜像名称与标签,用户可自行设置。 --build-arg 指定dockerfile文件内的参数。 NNRT_PKG=软件包名称 举个例子 ```shell docker build -t nnrt5.0.3_sample0.6:0.1 --build-arg NNRT_PKG=Ascend-cann-nnrt_5.0.3.1_linux-aarch64.run . ``` 中间会持续一段时间,耐心等待即可 当出现“Successfully built xxx”表示镜像构建成功。 然后我们可以查看一下image信息 ```shell docker images ``` 创建容器实例 执行下列操作,不过中间的镜像和tag号要对应修改 ```shell docker run -it --device=/dev/davinci0 --device=/dev/davinci_manager --device=/dev/svm0 --device=/dev/log_drv --device=/dev/event_sched --device=/dev/upgrade --device=/dev/hi_dvpp --device=/dev/memory_bandwidth --device=/dev/ts_aisle -v /usr/local/Ascend/driver/tools:/usr/local/Ascend/driver/tools -v /usr/local/Ascend/driver/lib64:/usr/local/Ascend/driver/lib64 -v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi -v /var/hdc_ppc:/var/hdc_ppc -v /etc/hdcBasic.cfg:/etc/hdcBasic.cfg -v /etc/rc.local:/etc/rc.local -v /sys:/sys -v /usr/bin/sudo:/usr/bin/sudo -v /usr/lib/sudo/:/usr/lib/sudo/ -v /etc/sudoers:/etc/sudoers/ -v /etc/sys_version.conf:/etc/sys_version.conf 镜像名称:tag号 /bin/bash -c "/usr/local/Ascend/driver/tools/minirc_container_prepare.sh;/bin/bash" ``` 进入后 我们用vgg测试,和C++样例测试一下。 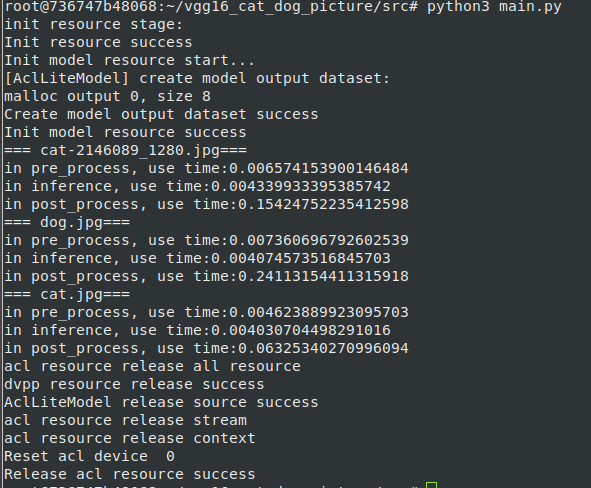 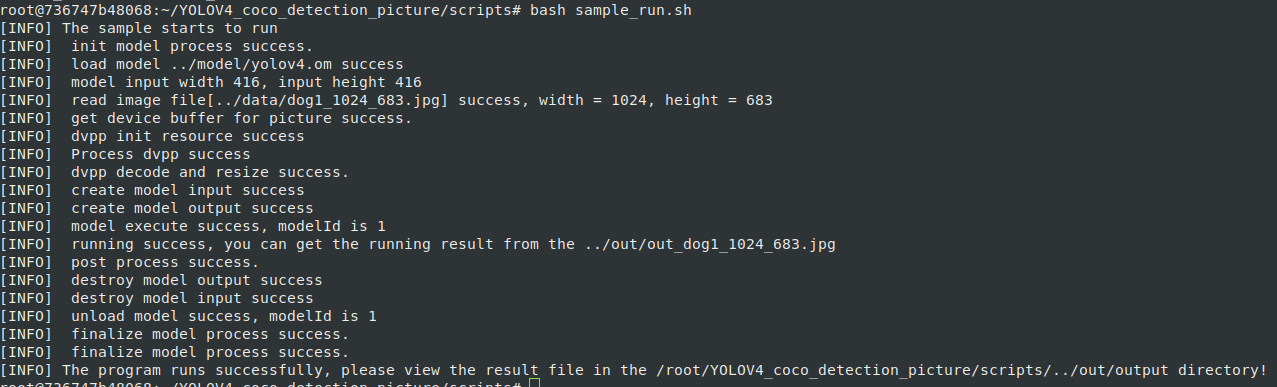
一、开胃小菜(前期准备工作): 1、准备一台鲲鹏Linux服务器并安装及启动docker 本文使用的是:CentOS 7.6 x64 2、准备一个Dockfile文件 用来构建redis镜像,该文件我会在下面提供 Dockerfile文件:[Dockerfile.zip](https://www.css3er.com/ueditor/php/upload/file/20190812/1565609627158640.zip) 自行下载解压后将文件上传到服务器。本文将该文件上传到服务器的路径:/root 3、启动系统的iptables,一般不需要更改该规则文件,如果下面步骤提示报相关网络错误,上网查一下即可解决 4、本系列博文使用的redis版本:3.2.12 二、了解docker网络模式(为接下来的主从配置搭建做准备) Docker安装后,默认会创建下面三种网络类型 docker network ls 查看默认的网络  在启动容器时使用 --network bridge 指定网络类型 bridge:桥接网络 默认情况下启动的Docker容器,都是使用 bridge,Docker安装时创建的桥接网络,每次Docker容器重启时,会按照顺序获取对应的IP地址,这个就导致重启下,Docker的IP地址就变了(桥接网络模式也可以,就是通过端口映射访问到容器里面的redis,不过本文选择用下面的自定义网络模式) none:无指定网络 使用 --network=none ,docker 容器就不会分配局域网的IP host: 主机网络 使用 --network=host,此时,Docker 容器的网络会附属在主机上,两者是互通的。 例如,在容器中运行一个Web服务,监听8080端口,则主机的8080端口就会自动映射到容器中 2.2、指定自定义网络,设置容器的固定IP(下面的Redis主从搭建选择用自定义网络) 因为默认的网络不能制定固定的地址,所以我们将创建自定义网络,并指定网段:172.10.0.0/16 并命名为mynetwork,这里选择了172.10.0.0/16网段,当然你也可以指定其他任意空闲的网段。将名字命名为mynetwork,你也可以换成其它的任意名字。具体创建指令如下: ```shell #创建一个mynetwork网络 并指定网段(子网)为:172.10.0.0/16(执行这一步,下面要用到该网络)``docker network create --subnet=172.10.0.0``/16` `mynetwork ``` 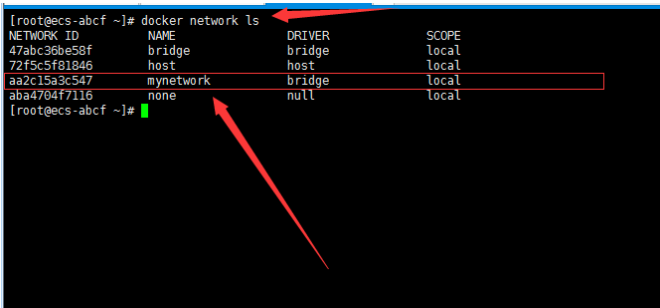 /*伟大的分割线/ 三、开始搭建Redis主从模式 概述: 主从复制说明,单一节点的redis(单台服务器的redis)容易面临的问题: 比如: 1、机器故障。我们部署到一台 Redis 服务器,当发生机器故障时,需要迁移到另外一台服务器并且要保证数据是同步的。而数据是最重要的,如果你不在乎,基本上也就不会使用 Redis 了。 2、容量瓶颈。当我们有需求需要扩容 Redis 内存时,从 16G 的内存升到 64G,单机肯定是满足不了。当然,你可以重新买个 128G 的新机器。 要实现分布式数据库的更大的存储容量和承受高并发访问量,我们会将原来集中式数据库的数据分别存储到其他多个网络节点上。 Redis 为了解决这个单一节点的问题,也会把数据复制多个副本部署到其他节点上进行复制,实现 Redis的高可用,实现对数据的冗余备份,从而保证数据和服务的高可用。 什么是主从复制? 主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave),数据的复制是单向的,只能由主节点到从节点。 默认情况下,每台Redis服务器都是主节点,且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。也就是说一台redis从服务只能属于一台redis主服务。 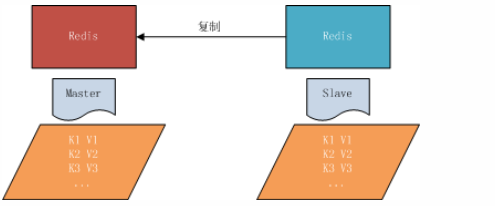 主从复制的作用: 主从复制的作用主要包括: 1、数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。 2、故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。 3、负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。 4、读写分离:可以用于实现读写分离,主库写、从库读,读写分离不仅可以提高服务器的负载能力,同时可根据需求的变化,改变从库的数量; 5、高可用基石(基础):除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。 具体操作步骤如下: 3.1、进入到root目录下(具体换成你自己的路径),并使用Dockerfile文件构建redis镜像 ``` #进入到root目录下``cd` `/root/` `#使用Dockerfile文件构建一个redis镜像(注意后面有一个点)``docker build -t redis . ``` 可以使用docker images查看刚刚构建完成的redis镜像 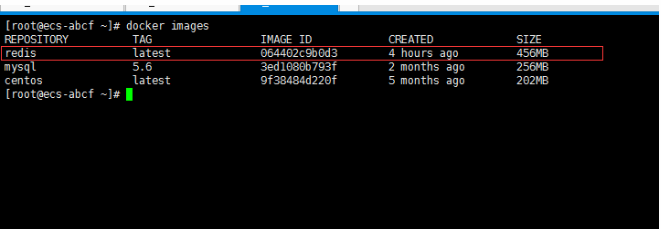 3.2、使用此构建生成的redis镜像创建容器(创建2个redis容器 一主一从) ```shell #主redis,该容器命名为redis-master 使用mynetwork网络 端口映射6380对应容器内部端口的6379 指定容器固定IP:172.10.0.2 使用redis镜像来生成容器并在后台运行``docker run -itd --name redis-master --net mynetwork -p 6380:6379 --ip 172.10.0.2 redis` `#从redis,该容器命名为redis-slave 使用mynetwork网络 端口映射6381对应容器内部端口的6379 指定容器固定IP:172.10.0.3 使用redis镜像来生成容器并在后台运行``docker run -itd --name redis-slave --net mynetwork -p 6381:6379 --ip 172.10.0.3 redis ``` 可以使用docker ps 查看正在运行中的容器(查看我们上面创建的两个一主一从的redis容器) 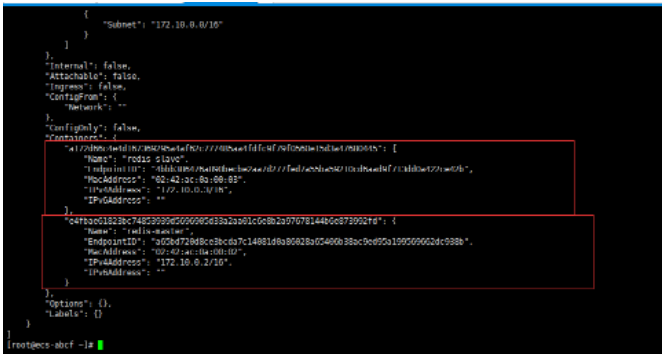 可以使用docker network inspect mynetwork命令查看容器的ip地址等相关信息  3.3、分别进入主redis容器和从redis容器 修改redis.conf配置文件 ```shell #1、主redis容器redis.conf配置文件改动``使用docker ``exec``命令进入容器里面:docker ``exec` `-it 你生成的主redis容器ID 或 容器名字 ``/bin/bash` `本文中的对应命令为(容器``id``方式):docker ``exec` `-it e4fbae61823b ``/bin/bash``本文中的对应命令为(容器名字方式):docker ``exec` `-it redis-master ``/bin/bash` `修改redis.conf配置文件 ``vi` `/etc/redis``.conf``#将bind 127.0.0.1注释 或 改为bind 0.0.0.0 表示允许任何ip连接该redis服务,同时将protected-mode yes 改为 protected-mode no 表示关闭保护模式` `#2、从redis容器redis.conf配置文件改动(和主redis的改动一样,唯一区别就是进入容器的时候,要进入从redis容器也就是容器id或容器名字不一样了 不过还是演示下吧。。)``使用docker ``exec``命令进入容器里面:docker ``exec` `-it 你生成的从redis容器ID 或 容器名字 ``/bin/bash` `本文中的对应命令为(容器``id``方式):docker ``exec` `-it a172d66c4e4d ``/bin/bash``本文中的对应命令为(容器名字方式):docker ``exec` `-it redis-slave ``/bin/bash` `修改redis.conf配置文件 ``vi` `/etc/redis``.conf``#将bind 127.0.0.1注释 或 改为bind 0.0.0.0 表示允许任何ip连接该redis服务,同时将protected-mode yes 改为 protected-mode no 表示关闭保护模式 ``` redis.conf配置文件改动后的截图如下: 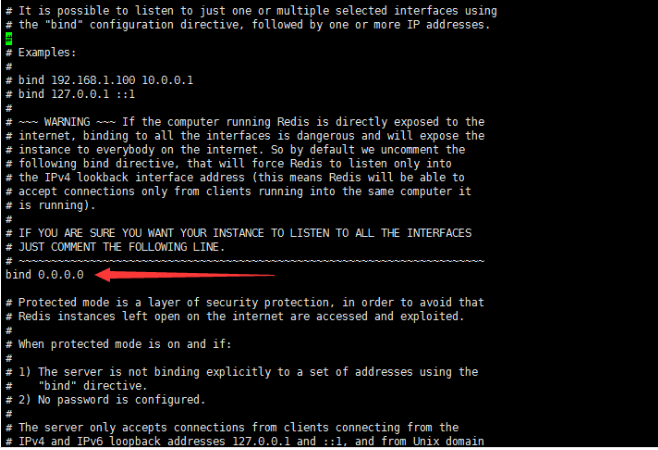 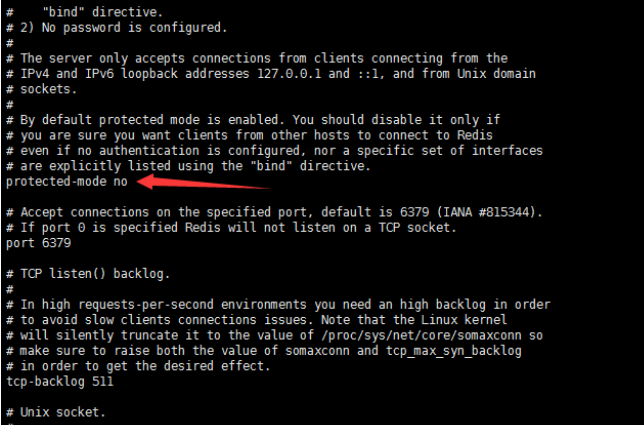 3.4、启用主从模式(有三种方式): (1)redis.conf配置文件(本文使用这种方式) 在从服务器的配置文件中加入:slaveof (2)启动命令 redis-server启动命令后加入 --slaveof (3)客户端命令 Redis服务器启动后,直接通过客户端执行命令:slaveof ,则该Redis实例成为从节点 通过 info replication 命令可以看到复制的一些参数信息 3.5、从redis容器中的redis.conf的redis配置文件加入配置信息,完成主从同步(别忘了 你要进入从redis容器里面) ```shell vi` `/etc/redis``.conf` `将 ``# slaveof 改为 slaveof 172.10.0.2 6379 也就是上面创建主redis容器是指定的主redis容器的固定IP地址。如果你和我的不一样,记得换成你自己设置的 ``` 从redis容器的里的redis.conf配置文件更改后的截图如下: 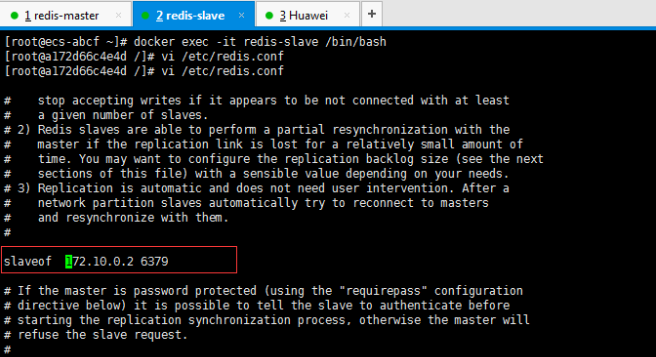 3.6、分别启动主从redis容器里面的redis服务(再次提醒。。别忘了进入主从redis容器里面启动) ```shell #主从redis容器里面启动redis服务都用以下这个命令即可``redis-server ``/etc/redis``.conf & ``#启动redis服务 &表示以后台守护进程方式启动(就是启动了后 在后台默默的服务) ``` 3.7、测试主从同步是否搭建成功(提醒啊。。别忘了进入主从redis容器里面进行操作。。真是操碎了心。。) 3.7.1、主redis容器操作: ``` redis-cli ``#进入redis客户端``set` `wzyl 123 ``#创建一个key ``` 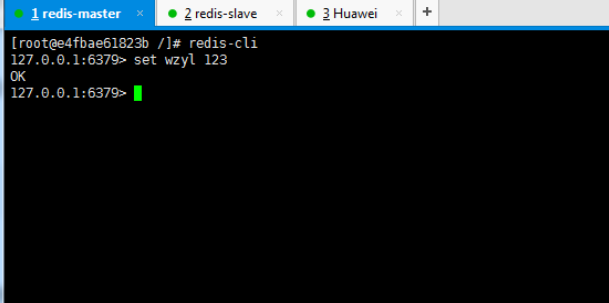 3.7.2、从redis容器操作: ```shell redis-cli ``#进入redis客户端` `使用get命令:get wzyl 或 使用keys命令:keys * ```  注:上面的keys * 命令不建议使用,除非你redis里面没有多少数据你可以使用keys * 命令,如果redis里面有很多数据 使用keys * 的话,会很慢。。会造成redis堵塞的。。 至此。。redis主从搭建成功。。往redis主节点写数据的时候,会自动同步到配置的redis从节点里(同步会有延时,因为需要用到网络,1秒钟之内会完成同步,大概也就几百毫秒的样子就可以了)实现了redis的读写分离。。这样写的操作可以写到主redis节点,读的操作可以读取从redis节点。。PS:一主一从搭建完了,一主多从应该也会了吧。。举一反三啊。。基于docker搭建redis主从都会了。。直接基于每一台服务器搭建redis主从就更简单了吧。。 3.8、使用RedisDesktopManager工具来连接到docker里面的redis(我们就链接主redis这个容器里的redis吧) 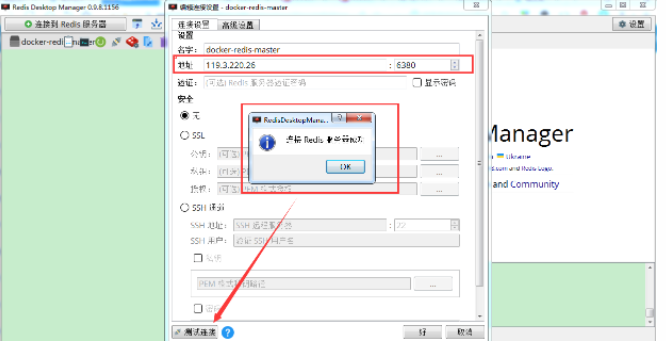 119.3.220.26是我服务器的公网IP,记得换成你自己服务器的公网IP,6380是我在上面创建主redis容器的时候指定的6380端口,实际上链接的时候会自动将6380映射成6379。。别直接上来就复制粘贴最后一点击测试发现各种error。。 3.9、主从结构还有一种叫:树状主从结构 树状主从结构:就是从节点它不但可以复制我们的主节点的数据,它同时也可以做为其它从节点的主节点,继续向下复制。说白了就是主节点有从节点,但是从节点还有从节点 那这种树状主从结构是为了解决什么问题? 主要就是避免主节点同步压力过大,造成性能干扰 树状主从结构示例图如下:  四、后记、尾声 本文中没有设置redis密码,你可以在配置文件中进行设置,如果设置了验证密码,那么从redis节点中的配置文件中也要找到对应的密码位置进行修改才能主从同步成功,在生产环境中不建议将protected-mode yes 改为 no 并且会设置redis密码。。本文为了操作简单就没有设置密码这一步。 总结redis主从、哨兵、集群的概念: 【redis主从】: 是备份关系, 我们操作主库,数据也会同步到从库。 如果主库机器坏了,从库可以上。就好比你 D盘的片丢了,但是你移动硬盘里边备份有。 【redis哨兵】: 哨兵保证的是HA(高可用),保证特殊情况故障自动切换,哨兵盯着你的“redis主从集群”,如果主库死了,它会告诉你新的老大是谁。 哨兵:主要针对redis主从中的某一个单节点故障后,无法自动恢复的解决方案。(哨兵 保证redis主从的高可用) 【redis集群】: 集群保证的是高并发,因为多了一些兄弟帮忙一起扛。同时集群会导致数据的分散,整个redis集群会分成一堆数据槽,即不同的key会放到不不同的槽中。 集群主要针对单节点容量、高并发问题、线性可扩展性的解决方案。 集群:是为了解决redis主从复制中 单机内存上限和并发问题,假如你现在的服务器内存为256GB,当达到这个内存时redis就没办法再提供服务,同时数据量能达到这个地步写数据量也会很大,容易造成缓冲区溢出,造成从节点无限的进行全量复制导致主从无法正常工作。
本文分享自华为云社区《解构华为云HE2E项目中的容器技术应用》,作者: 敏捷小智。 [华为云DevCloud HE2E DevOps实践](https://support.huaweicloud.com/bestpractice-devcloud/devcloud_practice_2000.html)当中,项目采用Docker技术进行构建部署。 容器技术应用,其实说简单也很简单,其流程无外乎:制作镜像——上传镜像——拉取镜像——启动镜像。 今天,我们就带大家从容器技术应用的角度来解构HE2E项目。 HE2E技术架构图:  # 创建项目 在华为云DevCloud中创建项目时选择DevOps样例项目,即可创建出预置了代码仓库、编译构建、部署等任务的DevOps样例项目,此项目即HE2E项目。  # 代码仓库 HE2E项目中预置了代码仓库phoenix-sample。  在根目录下可以看到images、kompose、result、vote、worker五个文件夹,以及LICENSE、README.md和docker-compose-standalone、docker-compose两个yml文件。Images文件夹存了几张图片,LICENSE和README也与代码内容无关,docker-compose.yml文件是应用于本地开发时的测试文件,这些都无需理会。 # 配置Kubectl的kompose文件夹 我们先看一下kompose文件夹,此文件夹下有多个yaml文件,通过命名可以看出这些文件是针对于每个微服务应用的配置。当我们进行CCE部署时就读取这里的配置(在部署时进行配置)。本着由浅入深的精神,本文先对ECS部署时所需的配置进行讲解,大家不要心急噢。  # 功能模块与制作镜像的Dockerfile result、vote、worker三个文件夹分别对应HE2E当中的三个功能模块:结果、投票、处理。   可以看到,三个文件夹下各自都有Dockerfile文件。制作镜像的时候就是靠这些Dockerfile文件来进行制作的。 我们以result下的Dockerfile进行举例说明:  FROM:定制的镜像都是基于 FROM 的镜像,这里的node:5.11.0-slim就是定制需要的基础镜像。后续的操作都是基于 node:5.11.0-slim。 WORKDIR /app:指定并创建工作目录/app。 RUN 命令>:执行命令>。 ADD 文件> 目录>:复制文件>至目录>。 5-9行:执行npm安装操作,并将相关文件存放入相应目录。 ENV PORT 80:定义环境变量PORT=80 EXPOSE 80:声明端口80。 CMD 命令>:在docker run时运行命令>。 在编译构建任务phoenix-sample-ci中,“制作Result镜像并推送到SWR仓库”步骤,通过“工作目录”、“Dockerfile路径”两个选项确定制作镜像时读取的Dockerfile:工作目录>/,即https://developer.huaweicloud.com/tags/200489/result/Dockerfile。  其余的vote和worker两个功能模块也是按此种办法制作镜像。值得一提的是,worker文件夹下有Dockerfile、Dockerfile.j和Dockerfile.j2三个文件,但是在构建任务中,我们只需选择一个文件进行镜像制作,选择的是Dockerfile.j2这个文件。  在Dockerfile.j2文件中,将target下的内容复制到code/target下,但是target文件夹又并不在代码当中。这是因为worker下的项目是Java项目,target文件夹是在Maven构建的过程产生的,所以在构建任务phoenix-sample-ci中,制作Worker镜像之前需要先通过Maven进行构建。  通过以上的Dockerfile文件已经可以制作出三大功能模块对应的容器镜像了。在部署主机中,直接使用docker login、docker pull和docker run命令就可以登录、拉取并启动相应的镜像。但是这种方式要求对每个镜像都进行拉取和启动,不能一次性配置全部镜像。故此,我们引入了docker compose,通过docker compose实现对 Docker 容器集群的快速编排。一键(一个配置文件)配置本项目所需的各个功能模块。 # 配置docker-compose的docker-compose-standalone.yml文件 当我们部署本项目到服务器时,采取docker-compose的方式启动。 在部署任务phoenix-sample-standalone中,最终通过执行shell命令启动本项目: docker-compose -f docker-compose-standalone.yml up -d  这句shell命令中的docker-compose-standalone.yml正是我们代码仓库根目录的docker-compose-standalone.yml文件。 下面对docker-compose-standalone.yml文件进行解读。 version:指定本 yml 依从的 compose 哪个版本制定的。 services:包含的服务。 本yml中含有redis、db、vote、result、worker五个服务。其中db即数据库postgres。 image:镜像地址。 以redis和worker服务为例,其镜像为docker-server/docker-org/redis:alpine、docker-server/docker-org/worker:image-version,这里采用的是参数化替换的形式定义镜像地址的。 在构建任务phoenix-sample-ci中,“替换Docker-Compose部署文件镜像版本”步骤的shell命令正是将docker-compose-standalone.yml文件中的docker-server、docker-org、image-version三处替换为我们在该构建任务中定义的三个参数dockerServer、dockerOrg、BUILDNUMBER。 进行这样的替换以后,我们的docker-compose-standalone.yml中的镜像地址才会变成我们所需的最终地址。例:swr.cn-north-4.myhuaweicloud.com/devcloud-bhd/redis:alpine、swr.cn-north-4.myhuaweicloud.com/devcloud-bhd/worker:20220303.1。 五个服务中,vote、result、worker是本项目构建生成的,redis和db是采用第三方应用,所以在镜像版本方面会有区别。  ports:端口号。将容器和主机绑定到暴露的端口。 在vote当中ports: 5000:80就是将容器所使用的80端口号绑定到主机的5000端口号,这样我们就可以通过主机ip>:5000来访问本项目的用户端界面了。 networks:配置容器连接的网络。这里使用的是最简单的两种声明网络名称。 frontend即前端,backend即后端。 environment:添加环境变量。POSTGRES_HOST_AUTH_METHOD: "trust",此变量防止访问postgres时无法登录。 volumes:将主机的数据卷或着文件挂载到容器里。db-data:/var/lib/postgresql/data下的内容即成为postgres当中的数据内容。 deploy:指定与服务的部署和运行有关的配置。placement:constraints: [node.role == manager]即:权限设置为管理员。 depends_on:设置依赖关系。vote依赖redis、result依赖db。 至此,整个HE2E项目的代码结构已经解构完毕。 # 编译构建 其实在完成代码解构之后,整个项目已经非常清晰了。代码中包括vote、result、worker三个功能模块,项目还用到了redis和postgres两个第三方应用。所以,我们在编译构建环节的主要目的就是把这些服务的镜像制作出来并上传到SWR容器镜像仓库中。 本项目中预置了5个构建任务。  我们仅分析phoenix-sample-ci任务即可。  # 三个功能模块的构建 在进行代码解构时,对构建任务的部分内容已经进行过分析了,其中就包括如何通过指定Dockerfile文件制作镜像,即docker build(制作)的操作。除此之外,制作XX镜像并推送到SWR的步骤中还包括了推送镜像所需的信息。这里设置了推送区域、组织、镜像名字、镜像标签,其实就是我们进行docker tag(打标签)和docker push(推送)的操作。 在vote、result、worker的镜像制作并推送的过程中,通过参数BUILDNUMBER定义镜像的版本号。BUILDNUMBER是系统预定义参数,随着构建日期及次数变化。 worker镜像在制作之前,需要先对worker目录下的工程进行Maven构建,这样就会生成Dockerfile.j2中(制作镜像时)所需的target文件。 # Postgres和Redis的构建 在制作了三个功能模块镜像以后,接下来要做的是生成Postgres和Redis 镜像。这里选择的办法是,通过shell命令写出这两个应用的Dockerfile。 echo from postgres:9.4 > Dockerfile-postgres echo from redis:alpine > Dockerfile-redis 通过这段shell命令就会在当前的工作目录下生成Dockerfile-postgres和Dockerfile-redis两个文件。 Dockerfile-postgres: FROM postgres:9.4 Dockerfile-redis: FROM redis:alpine 在接下来的步骤当中,指定当前目录下的Dockerfile-postgres和Dockerfile-redis两个文件制作镜像并上传。  # 替换部署配置文件并打包 通过以上的步骤,镜像就已完全上传至SWR仓库了。后续的“替换Docker-Compose部署文件镜像版本”和“替换Kubernates部署文件镜像版本”两个步骤分别将代码仓根目录下的docker-compose-standalone.yml和kompose下的所有XX-deployment.yaml文件中的docker-server、docker-org、image-version替换为构建任务中的参数dockerServer、dockerOrg、BUILDNUMBER。这两步骤的意义就是将ECS部署(docker-compose/docker-compose-standalone.yml)和CCE部署(Kubernates/Kompose)所需的配置文件修改为可部署、可应用的版本。  这两个文件修改完毕后,都进行tar打包的操作。打包后的产物也通过接下来的两个“上传XX”步骤上传软件包到了软件发布库。 # Tips 在本项目的帮助文档中,提到了“配置基础依赖镜像”。整个这一段落是由于构建任务中使用的基础镜像源DockerHub拉取受限,采取了一个折中的办法拉取镜像。简言之,整段操作即通过创建prebuild任务来实现基础镜像版本的替换,以避免开发者在进行构建phoenix-sample-ci任务时出现拉取镜像失败的情形。相应地,也在“配置并执行编译构建任务”中禁用了Postgres和Redis镜像的制作步骤。 # 部署 在编译构建环节,我们已经成功将三个功能模块镜像(vote、result、worker)和两个第三方镜像构建并上传至SWR(容器镜像仓库)中了。接下来需要做的就是将SWR中的镜像拉取到我们的部署主机并启动。 在整个实践中,提供了ECS部署和CCE部署两种方式,并且在项目中预置了3个部署任务。  我们仅分析phoenix-sample- standalone任务即可。  # 传输软件包至部署主机中 在构建环节,我们除了制成镜像并上传到SWR以外,还对配置文件进行了修改、压缩并上传到了软件发布库。在部署过程中,我们首先要做的,就是把配置文件从软件发布库中传到部署主机当中。 结合实际的部署任务来看,就是:向[主机组] group-bhd部署一个[软件包/构建任务(的产物)],我们选择了[构建任务] phoenix-sample-ci的最新版本([构建版本][Latest])构建产物,将其[下载到主机的部署目录]。  这一步骤执行完毕后,在部署主机的/root/phoenix-sample-standalone-deploy路径下,就会存在之前构建任务中压缩的docker-stack.tar.gz和phoenix-sample-k8s.tar.gz。ECS部署中,我们仅需要解压docker-stack.tar.gz,这个文件是docker-compose-standalone.yml的压缩包(回顾一下构建任务中的“替换部署配置文件并打包”)。  # 通过执行shell命令启动docker-compose 解压完成后,我们就可以通过执行docker-compose启动命令来启动项目了。  在这一步骤当中,前三行分别输出了三个参数docker-username、docker-password、docker-server。这三个参数是用以进行docker login操作的。因为我们在docker-compose-standalone.yml中涉及到拉取镜像的操作,需要在拉取镜像前先登录SWR镜像仓库。 登录完毕后,就可以进入/root/phoenix-sample-standalone-deploy目录下(cd /root/phoenix-sample-standalone-deploy) 启动docker-compose(docker-compose -f docker-compose-standalone.yml up -d)。 至此,项目已经部署至主机当中,在主机中,通过docker ps -a指令可以看到5个容器进程。  与此同时,访问http://{ip}:5000和http://{ip}:5001即可访问项目的用户端与管理端。   # 结语 本文从容器技术应用的角度解构了HE2E项目的代码仓库配置、镜像构建、及docker-compose的部署方式。希望通过本篇文章分享可以使更多的开发者了解容器技术和华为云。
# compass-ci日志系统 EFK日志系统 - compass-ci对日志系统的诉求 - 能够收集多种类型的日志,compass-ci集群有docker容器的日志、执行机的串口日志(日志文件)需要收集; - 能够快速聚合分散的日志进行集中管理,compass-ci集群的日志分散在多个地方:部署服务的服务器、执行任务的物理机、IBMC管理机 - 可视化的平台,方便对日志进行分析及展示 - 高效,集群会产生大量日志,需要系统能快速处理,不产生堆积 - 开源组件 结合以上诉求,compass-ci最终选择了EFK系统 - 在compass-ci中的使用 ``` docker/serial日志(生产) -> sub-fluentd(收集) -> master-fluentd(聚合) -> es(存储) -> kibana(展示) | monitoring - rabbitmq -> serial-logging -> job's result/dmesg file ``` 日志生产 docker服务日志 - 配置 启动sub-fluentd之后,docker需要做相应的配置将日志转发到sub-fluentd 默认情况下,Docker使用json-file日志驱动程序,该驱动程序在内部缓存容器日志为JSON(docker logs日志来源) - 全局配置 /etc/docker/daemon.json 需要重启docker服务全局配置才会生效 ``` { # 日志转发到fluentd "log-driver": "fluentd", "log-opts":{ # fluentd服务地址 "fluentd-address": "localhost:24225", # fluentd-docker异步设置,避免fluentd失去连接之后导致Docker容器异常 "fluentd-async-connect": "true", # 配置转发到fluentd日志的标签为容器名,用于区分不同容器的日志 "tag": "{{.Name}}" } } ``` - 单个docker容器配置 全局配置后所有的docker日志都会被转发到sub-fluentd,若未做全局配置,只想特定容器进行转发,可以使用以下配置 docker run --log-driver=fluentd --log-opt fluentd-address=fluentdhost:24225 --log-opt tag=xxx 有些日志信息比较敏感,不想转发到fluentd,可以单独配置为默认的json-file模式 docker run --log-driver=json-file - 日志流程 ``` docker -> sub-fluentd -> master-fluentd -> rabbitmq -> monitoring `----> es -> kibana ``` - es 存储到es是为了后续在kibana上搜索展示分析 - rabbitmq 存储到rabbitmq中间件,为monitoring服务提供数据 - monitoring服务 submit -m的服务端,近实时的返回job执行过程中与服务端交互产生的日志 - 日志内容 compass-ci的服务都是用docker的方式部署 - 非自主开发的服务,如es: ``` wuzhende@crystal ~% docker logs -f sub-fluentd | grep es-server01 2022-01-17 05:13:42.000000000 +0800 es-server01: {"type": "server", "timestamp": "2022-01-16T21:13:42,579Z", "level": "WARN", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "node-1", "message": "[gc][young][152465][89] duration [1s], collections [1]/[1.1s], total [1s]/[5.8s], memory [19.4gb]->[1.9gb]/[30gb], all_pools {[young] [17.5gb]->[0b]/[0b]}{[old] [1.4gb]->[1.5gb]/[30gb]}{[survivor] [367.5mb]->[389.8mb]/[0b]}", "cluster.uuid": "FJFweh9LQ6mKes6uwHQL_g", "node.id": "keFEKD-WTBe0tHF4fbS4MA" } 2022-01-17 05:13:42.000000000 +0800 es-server01: {"type": "server", "timestamp": "2022-01-16T21:13:42,579Z", "level": "WARN", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "node-1", "message": "[gc][152465] overhead, spent [1s] collecting in the last [1.1s]", "cluster.uuid": "FJFweh9LQ6mKes6uwHQL_g", "node.id": "keFEKD-WTBe0tHF4fbS4MA" } 2022-01-17 05:23:21.000000000 +0800 es-server01: {"type": "server", "timestamp": "2022-01-16T21:23:21,413Z", "level": "WARN", "component": "o.e.m.f.FsHealthService", "cluster.name": "docker-cluster", "node.name": "node-1", "message": "health check of [/srv/es/nodes/0] took [6002ms] which is above the warn threshold of [5s]", "cluster.uuid": "FJFweh9LQ6mKes6uwHQL_g", "node.id": "keFEKD-WTBe0tHF4fbS4MA" } ``` - 自主开发的服务,如调度器: ``` wuzhende@crystal ~% docker logs -f sub-fluentd | grep scheduler-3000 2022-01-17 05:39:59.000000000 +0800 scheduler-3000: {"level_num":2,"level":"INFO","time":"2022-01-17T05:39:59.902+0800","from":"172.17.0.1:52468","message":"access_record","status_code":200,"method":"GET","resource":"/boot.ipxe/mac/44-67-47-e9-79-c0","testbox":"sched-crystal-44-67-47-e9-79-c0","api":"boot","elapsed_time":1801792.188619,"elapsed":"1801792.19ms"} 2022-01-17 05:40:10.000000000 +0800 scheduler-3000: {"level_num":2,"level":"INFO","time":"2022-01-17T05:40:10.925+0800","from":"172.17.0.1:37110","message":"access_record","status_code":200,"method":"GET","resource":"/boot.ipxe/mac/84-46-fe-73-b2-39","testbox":"taishan200-2280-2s64p-256g--a1004","api":"boot","elapsed_time":1804795.552323,"elapsed":"1804795.55ms"} 2022-01-17 05:40:23.000000000 +0800 scheduler-3000: {"level_num":2,"level":"INFO","time":"2022-01-17T05:40:23.450+0800","from":"172.17.0.1:40006","message":"access_record","status_code":200,"method":"GET","resource":"/boot.ipxe/mac/44-67-47-85-d5-48","testbox":"taishan200-2280-2s48p-256g--a1008","api":"boot","elapsed_time":1803608.442844,"elapsed":"1803608.44ms"} ``` - 日志级别 compass-ci的服务使用ruby或者crystal语言开发,两者之间对日志等级的定义不相同 我们以crystal的日志级别为准,对ruby重新进行定义 代码:$CCI_SRC/lib/json_logger.rb ``` class JSONLogger Logger LEVEL_INFO = { 'TRACE' => 0, 'DEBUG' => 1, 'INFO' => 2, 'NOTICE' => 3, 'WARN' => 4, 'ERROR' => 5, 'FATAL' => 6 }.freeze ``` - 日志格式 ``` json类型:{ # 日志级别 "level_num":2, # 日志级别 "level":"INFO", # 日志产生的时间 "time":"2022-01-17T05:40:10.925+0800", # 请求来源 "from":"172.17.0.1:37110", # 日志内容 "message":"access_record", # http状态码 "status_code":200, # 请求类型 "method":"GET", # 请求地址 "resource":"/boot.ipxe/mac/84-46-fe-73-b2-39", # 执行机名 "testbox":"taishan200-2280-2s64p-256g--a1004", # 相关的任务id "job_id": crystal1344467 # 接口耗时,ms "elapsed_time":1804795.552323, # 接口耗时,不带单位 "elapsed":"1804795.55ms" } ``` 代码:$CCI_SRC/src/lib/json_logger.cr ``` private def get_env_info(env : HTTP::Server::Context) @env_info["status_code"] = env.response.status_code @env_info["method"] = env.request.method @env_info["resource"] = env.request.resource @env_info["testbox"] = env.get?("testbox").to_s if env.get?("testbox") @env_info["job_id"] = env.get?("job_id").to_s if env.get?("job_id") @env_info["job_state"] = env.get?("job_state").to_s if env.get?("job_state") @env_info["api"] = env.get?("api").to_s if env.get?("api") set_elapsed(env) merge_env_log(env) end ``` 执行机串口日志 执行机执行任务时,会将串口以及一些关键日志保存到指定目录下:/srv/cci/serial/logs/$hostname 不同类型的执行机有不同的实现方式: - 物理机 通过部署conserver容器到ibmc管理机上 该容器会将集群物理机的串口日志重定向到ibmc管理机的指定目录 - qemu 启动qemu时,将日志进行重定向 关键代码: $CCI_SRC/providers/kvm.sh ``` run_qemu() { #append=( # rd.break=pre-mount # rd.debug=true #) if [ "$DEBUG" == "true" ];then "${kvm[@]}" "${arch_option[@]}" --append "${append}" else # The default value of serial in QEMU is stdio. # We use >> and 2>&1 to record serial, stdout, and stderr together to log_file "${kvm[@]}" "${arch_option[@]}" --append "${append}" >> $log_file 2>&1 run kernel/os once > one-dmesg-file >> upload to job's result dir data process, check 2 side match, warn email fi local return_code=$? [ $return_code -eq 0 ] || echo "[ERROR] qemu start return code is: $return_code" >> $log_file } ``` - docker 启动容器时,将docker日志重定向 关键代码:$CCI_SRC/providers/docker/run.sh ``` cmd=( docker run --rm --name ${job_id} --hostname $host.compass-ci.net --cpus $nr_cpu -m $memory --tmpfs /tmp:rw,exec,nosuid,nodev -e CCI_SRC=/c/compass-ci -v ${load_path}/lkp:/lkp -v ${load_path}/opt:/opt -v ${DIR}/bin:/root/sbin:ro -v $CCI_SRC:/c/compass-ci:ro -v /srv/git:/srv/git:ro -v /srv/result:/srv/result:ro -v /etc/localtime:/etc/localtime:ro -v ${busybox_path}:/usr/local/bin/busybox --log-driver json-file --log-opt max-size=10m --oom-score-adj="-1000" ${docker_image} /root/sbin/entrypoint.sh ) "${cmd[@]}" 2>&1 | tee -a "$log_dir" ``` - 串口日志流程 日志文件:/srv/cci/serial/logs/$hostname -> sub-fluentd -> master-fluentd -> rabbitmq -> serial-logging -> result/dmesg 日志收集聚合-fluentd 在我们的系统中分为sub-fluentd和master-fluentd两种服务 - fluentd-base sub-fluentd和master-fluentd依赖的基础镜像,直接构建即可 ``` cd $CCI_SRC/container/fluentd-base https://developer.huaweicloud.com/tags/200489/build ``` - sub-fluentd - 作用 收集所在机器上的docker日志以及串口日志,并转发到master-fluentd上 - 位置 部署到需要收集日志的机器上 - 部署 ``` cd $CCI_SRC/container/sub-fluentd https://developer.huaweicloud.com/tags/200489/build https://developer.huaweicloud.com/tags/200489/start ``` 用docker容器的方式部署到机器上 - 配置文件 配置文件$CCI_SRC/container/sub-fluentd/docker-fluentd.conf - 关键配置解读 ``` @type tail path /srv/cci/serial/logs/* pos_file /srv/cci/serial/fluentd-pos/serial.log.pos tag serial.* path_key serial_path refresh_interval 1s @type none ``` 配置tail输入插件,允许fluentd从文本文件的尾部读取事件,它的行为类似于tail -F命令 监听/srv/cci/serial/logs/目录下的所有文本文件,所以我们只需要把串口日志存到该目录下,就会被自动收集 ``` @type forward bind 0.0.0.0 ``` 配置forward输入插件侦听 TCP 套接字以接收事件流,接收网络上转发过来的日志 可以用来收集docker服务的日志,需要docker服务也做相应配置,将日志转发到sub-fluentd ``` @type forward flush_interval 0 send_timeout 60 heartbeat_interval 1 recover_wait 10 hard_timeout 60 master-fluentd host "#{ENV['MASTER_FLUENTD_HOST']}" port "#{ENV['MASTER_FLUENTD_PORT']}" ``` 配置forward输出插件将日志转发到master-fluentd节点,达到日志聚合的目的 - master-fluentd - 作用 接收集群里的sub-fluentd转发过来的日志,再将日志保存到es/rabbitmq里 - 位置 部署到主服务器上 - 部署 ``` cd $CCI_SRC/container/master-fluentd https://developer.huaweicloud.com/tags/200489/build https://developer.huaweicloud.com/tags/200489/start ``` 用docker容器的方式部署到服务器上 - 配置文件 $CCI_SRC/container/master-fluentd/docker-fluentd.conf - 关键配置解读 ``` @type forward bind 0.0.0.0 ``` 配置forward输入插件侦听 TCP 套接字以接收事件流,接收sub-fluentd转发过来的日志 ``` @type record_transformer enable_ruby time ${time.strftime('%Y-%m-%dT%H:%M:%S.%3N+0800')} ``` 往json格式的日志中加入time字段 ``` @type rabbitmq host 172.17.0.1 exchange serial-logging exchange_type fanout exchange_durable false heartbeat 10 @type json ``` 将收到的串口日志转发到rabbitmq中 ``` @type parser format json emit_invalid_record_to_error false key_name log reserve_data true ``` 将json日志中的log字段展开 原始日志: ``` { "container_id": "227c5ed4f008c84c345c18762c9aeae41207162f87df627b3b6e430f1bebe690", "container_name": "/s001-alpine-3005", "source": "stdout", "log": "{"level_num":2,"level":"INFO","time":"2021-12-16T10:08:00.350+0800","from":"172.17.0.1:59526","message":"access_record","status_code":101,"method":"GET","resource":"/ws/boot.ipxe/mac/0a-03-4b-56-32-3d","testbox":"vm-2p4g.taishan200-2280-2s64p-256g--a45-3"}", } ``` 展开后: ``` { "container_id": "227c5ed4f008c84c345c18762c9aeae41207162f87df627b3b6e430f1bebe690", "container_name": "/s001-alpine-3005", "source": "stdout", "log": "{"level_num":2,"level":"INFO","time":"2021-12-16T10:08:00.350+0800","from":"172.17.0.1:59526","message":"access_record","status_code":101," method":"GET","resource":"/ws/boot.ipxe/mac/0a-03-4b-56-32-3d","testbox":"vm-2p4g.taishan200-2280-2s64p-256g--a45-3"}", "time": "2021-12-16T10:08:00.000+0800", "level_num": 2, "level": "INFO", "from": "172.17.0.1:59526", "message": "access_record", "status_code": 101, "method": "GET", "resource": "/ws/boot.ipxe/mac/0a-03-4b-56-32-3d", "testbox": "vm-2p4g.taishan200-2280-2s64p-256g--a45-3" } ``` 这样做的好处是:es会为展开后的字段设置索引,方便后续对日志的搜索分析 ``` @type copy @type elasticsearch host "#{ENV['LOGGING_ES_HOST']}" port "#{ENV['LOGGING_ES_PORT']}" user "#{ENV['LOGGING_ES_USER']}" password "#{ENV['LOGGING_ES_PASSWORD']}" suppress_type_name true flush_interval 1s num_threads 10 index_name ${tag} ssl_verify false log_es_400_reason true with_transporter_log true reconnect_on_error true reload_on_failure true reload_connections false template_overwrite template_name logging template_file /fluentd/mapping-template @type rabbitmq host 172.17.0.1 exchange docker-logging exchange_type fanout exchange_durable false heartbeat 10 @type json @type json ``` 将docker容器的日志转发存储到es和redis中 日志处理 monitoring服务 - 需求 使用submit提交任务时,想要知道job执行到了哪个阶段,希望能把job执行过程的日志打印出来 - 数据来源 master-fluentd转存到rabbitmq的docker日志 - 功能 近实时的返回满足条件的日志,无法回溯 - api ws://$ip:20001/filter - 客户端如何使用 submit提交任务时添加'-m'选项: ``` hi8109@account-vm ~% submit -m borrow-1d.yaml testbox=dc-8g submit_id=65356462-2547-4c64-af3c-e58cc32fb473 submit /home/hi8109/lkp-tests/jobs/borrow-1d.yaml, got job id=z9.13283216 query=>{"job_id":["z9.13283216"]} connect to ws://172.168.131.2:20001/filter {"level_num":2,"level":"INFO","time":"2022-01-06T16:18:45.164+0800","job_id":"z9.13283216","message":"","job_state":"submit"," 8g/centos-7-aarch64/86400/z9.13283216","status_code":200,"method":"POST","resource":"/submit_job","api":"submit_job","elapsed_ {"level_num":2,"level":"INFO","time":"2022-01-06T16:18:45.262+0800","job_id":"z9.13283216","result_root":"/srv/result/borrow/2 216","job_state":"set result root","status_code":101,"method":"GET","resource":"/ws/boot.container/hostname/dc-8g.taishan200-2 200-2280-2s48p-256g--a70-9"} {"level_num":2,"level":"INFO","time":"2022-01-06T16:18:45.467+0800","from":"172.17.0.1:53232","message":"access_record","statu .container/hostname/dc-8g.taishan200-2280-2s48p-256g--a70-9","testbox":"dc-8g.taishan200-2280-2s48p-256g--a70-9","job_id":"z9. {"level_num":2,"level":"INFO","time":"2022-01-06T16:18:47.477+0800","from":"172.17.0.1:44714","message":"access_record","statu trd_tmpfs/z9.13283216/job.cgz","job_id":"z9.13283216","job_state":"download","api":"job_initrd_tmpfs","elapsed_time":0.581944, The dc-8g testbox is starting. Please wait about 30 seconds {"level_num":2,"level":"INFO","time":"2022-01-06T16:18:52+0800","mac":"02-42-ac-11-00-03","ip":"","job_id":"z9.13283216","stat s48p-256g--a70-9","status_code":200,"method":"GET","resource":"/~lkp/cgi-bin/lkp-wtmp?tbox_name=dc-8g.taishan200-2280-2s48p-25 -03&ip=&job_id=z9.13283216","api":"lkp-wtmp","elapsed_time":75.77575,"elapsed":"75.78ms"} {"level_num":2,"level":"INFO","time":"2022-01-06T16:19:47.968+0800","from":"172.17.0.1:38220","message":"access_record","statu i-bin/lkp-jobfile-append-var?job_file=/lkp/scheduled/job.yaml&job_id=z9.13283216&job_state=running","job_id":"z9.13283216","ap .933762,"elapsed":"5447.93ms","job_state":"running","job_stage":"running"} ``` serial-logging服务 - 功能 在job的结果目录下生成dmesg文件 - 数据来源 master-fluentd转存到rabbitmq的串口日志 - 代码 $CCI_SRC/src/monitoring/parse_serial_logs.cr - 示例: ``` wuzhende@z9 /srv/result/build-pkg/2022-01-19/dc-16g/openeuler-20.03-pre-aarch64/pkgbuild-aur-j-java-testng-a6f1c79551cf6e/z9.13368603% ll total 1.1M -rw-r--r-- 1 lkp lkp 3.4K 2022-01-19 23:59 job.yaml -rwxrwxr-x 1 lkp lkp 4.1K 2022-01-19 23:59 job.sh -rw-rw-r-- 1 lkp lkp 1.4K 2022-01-20 00:00 time-debug -rw-rw-r-- 1 lkp lkp 860 2022-01-20 00:00 stdout -rw-rw-r-- 1 lkp lkp 373 2022-01-20 00:00 stderr -rw-rw-r-- 1 lkp lkp 33 2022-01-20 00:00 program_list -rw-rw-r-- 1 lkp lkp 1.4K 2022-01-20 00:00 output -rw-rw-r-- 1 lkp lkp 3.3K 2022-01-20 00:00 meminfo.gz -rw-rw-r-- 1 lkp lkp 43 2022-01-20 00:00 last_state -rw-rw-r-- 1 lkp lkp 634 2022-01-20 00:00 heartbeat -rw-rw-r-- 1 lkp lkp 218 2022-01-20 00:00 build-pkg -rw-rw-r-- 1 lkp lkp 24 2022-01-20 00:00 boot-time -rw-rw-r-- 1 root lkp 481 2022-01-20 00:00 stderr.json -rw-rw-r-- 1 root lkp 2.7K 2022-01-20 00:00 meminfo.json.gz -rw-rw-r-- 1 root lkp 3.7K 2022-01-20 00:00 dmesg -rw-rw-r-- 1 root lkp 97 2022-01-20 00:00 last_state.json -rw-rw-r-- 1 root lkp 1.5K 2022-01-20 00:00 stats.json wuzhende@z9 /srv/result/build-pkg/2022-01-19/dc-16g/openeuler-20.03-pre-aarch64/pkgbuild-aur-j-java-testng-a6f1c79551cf6e/z9.13368603% cat dmesg 2022-01-19 23:59:56 starting DOCKER http://172.168.131.2:3000/job_initrd_tmpfs/z9.13368603/job.cgz http://172.168.131.2:8800/upload-files/lkp-tests/aarch64/v2021.09.23.cgz http://172.168.131.2:8800/upload-files/lkp-tests/e9/e94df9bd6a2a9143ebffde853c79ed18.cgz 2022-01-20 00:00:00 [INFO] -- Kernel tests: Boot OK! % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 2130 100 2130 0 0 2080k 0 --:--:-- --:--:-- --:--:-- 2080k System has not been booted with systemd as init system (PID 1). Can't operate. Failed to connect to bus: Host is down System has not been booted with systemd as init system (PID 1). Can't operate. Failed to connect to bus: Host is down /usr/bin/wget -q --timeout=1800 --tries=1 --local-encoding=UTF-8 http://172.168.131.2:3000/~lkp/cgi-bin/lkp-wtmp?tbox_name=dc-16g.taishan200-2280-2s48p-256g--a103-0&tbox_state=running&mac=02-42-ac-11-00-09&ip=172.17.0.9&job_id=z9.13368603 -O /dev/null download http://172.168.131.2:8800/initrd/pkg/container/openeuler/aarch64/20.03-pre/build-pkg/4.3.90-1.cgz /usr/bin/wget -q --timeout=1800 --tries=1 --local-encoding=UTF-8 http://172.168.131.2:8800/initrd/pkg/container/openeuler/aarch64/20.03-pre/build-pkg/4.3.90-1.cgz -O /tmp/tmp.cgz 3193 blocks /lkp/lkp/src/bin/run-lkp RESULT_ROOT=/result/build-pkg/2022-01-19/dc-16g/openeuler-20.03-pre-aarch64/pkgbuild-aur-j-java-testng-a6f1c79551cf6e/z9.13368603 job=/lkp/scheduled/job.yaml result_service: raw_upload, RESULT_MNT: /172.168.131.2/result, RESULT_ROOT: /172.168.131.2/result/build-pkg/2022-01-19/dc-16g/openeuler-20.03-pre-aarch64/pkgbuild-aur-j-java-testng-a6f1c79551cf6e/z9.13368603, TMP_RESULT_ROOT: /tmp/lkp/result run-job /lkp/scheduled/job.yaml /usr/bin/wget -q --timeout=1800 --tries=1 --local-encoding=UTF-8 http://172.168.131.2:3000/~lkp/cgi-bin/lkp-jobfile-append-var?job_file=/lkp/scheduled/job.yaml&job_id=z9.13368603&job_state=running -O /dev/null which: no time in (/root/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/lkp/lkp/src/bin:/lkp/lkp/src/sbin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/lkp/lkp/src/bin:/lkp/lkp/src/sbin) ==> Making package: java-testng 7.4.0-1 (Thu Jan 20 00:00:04 CST 2022) ==> Checking runtime dependencies... ==> Checking buildtime dependencies... ==> Retrieving sources... -> Downloading java-testng-7.4.0.tar.gz... curl: (7) Failed to connect to github.com port 443: Connection timed out ==> ERROR: Failure while downloading java-testng-7.4.0.tar.gz Aborting... /usr/bin/wget -q --timeout=1800 --tries=1 --local-encoding=UTF-8 http://172.168.131.2:3000/~lkp/cgi-bin/lkp-jobfile-append-var?job_file=/lkp/scheduled/job.yaml&job_id=z9.13368603&job_state=post_run -O /dev/null kill 142 vmstat --timestamp -n 10 wait for background processes: 144 meminfo /usr/bin/wget -q --timeout=1800 --tries=1 --local-encoding=UTF-8 http://172.168.131.2:3000/~lkp/cgi-bin/lkp-jobfile-append-var?job_file=/lkp/scheduled/job.yaml&job_id=z9.13368603&loadavg=1.87%201.87%201.66%202/2191%20477&start_time=1642608003&end_time=1642608036&& -O /dev/null /usr/bin/wget -q --timeout=1800 --tries=1 --local-encoding=UTF-8 http://172.168.131.2:3000/~lkp/cgi-bin/lkp-jobfile-append-var?job_file=/lkp/scheduled/job.yaml&job_id=z9.13368603&job_state=failed -O /dev/null /lkp/scheduled/job.sh: line 133: /lkp/scheduled/job.yaml: Permission denied /usr/bin/wget -q --timeout=1800 --tries=1 --local-encoding=UTF-8 http://172.168.131.2:3000/~lkp/cgi-bin/lkp-post-run?job_file=/lkp/scheduled/job.yaml&job_id=z9.13368603 -O /dev/null LKP: exiting Total DOCKER duration: 0.82 minutes ```
>摘要:Docker为什么火,靠的就是Docker镜像。他打包了应用程序的所有依赖,彻底解决了环境的一致性问题,重新定义了软件的交付方式,提高了生产效率。本文分享自华为云社区[《认识容器,我们从它的历史开始聊起》](https://bbs.huaweicloud.com/blogs/285728?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content),作者:技术火炬手。 关于容器的历史、发展以及技术本质,在互联网上已经有非常多的文章了。这里旨在结合自身的工作经验和理解,通过一系列的文章,讲清楚这项技术。 # 容器的历史和发展 1、前世 讲到容器,就不得不提LXC(Linux Container),他是Docker的前生,或者说Docker是LXC的使用者。完整的LXC能力在2008年合入Linux主线,所以容器的概念在2008年就基本定型了,并不是后面Docker造出来的。关于LXC的介绍很多,大体都会说“LXC是Linux内核提供的容器技术,能提供轻量级的虚拟化能力,能隔离进程和资源”,但总结起来,无外乎就两大知识点Cgroups(Linux Control Group)和Linux Namespace。搞清楚他俩,容器技术就基本掌握了。 - Cgroups:重点在“限制”。限制资源的使用,包括CPU、内存、磁盘的使用,体现出对资源的管理能力。 - Namespace:重点在“隔离”。隔离进程看到的Linux视图。说大白话就是,容器和容器之间不要相互影响,容器和宿主机之间不要相互影响。 2、少年期起步艰难 2009年,Cloud Foundry基于LXC实现了对容器的操作,该项目取名为Warden。2010年,dotCloud公司同样基于LXC技术,使用Go语言实现了一款容器引擎,也就是现在的Docker。那时,dotCloud公司还是个小公司,出生卑微的Docker没什么热度,活得相当艰难。 3、 成长为巨无霸 2013年,dotCloud公司决定将Docker开源。开源后,项目突然就火了。从大的说,火的原因就是Docker的这句口号“Build once,Run AnyWhere”。呵呵,是不是似曾相识?对的,和Java的Write Once,Run AnyWhere一个道理。对于一个程序员来说,程序写完后打包成镜像就可以随处部署和运行,开发、测试和生产环境完全一致,这是多么大一个诱惑。程序员再也不用去定位因环境差异导致的各种坑爹问题。 Docker开源项目的异常火爆,直接驱动dotCloud公司在2013年更名为Docker公司。Docker也快速成长,干掉了CoreOS公司的rkt容器和Google的lmctfy容器,直接变成了容器的事实标准。也就有了后来人一提到容器就认为是Docker。 总结起来,Docker为什么火,靠的就是Docker镜像。他打包了应用程序的所有依赖,彻底解决了环境的一致性问题,重新定义了软件的交付方式,提高了生产效率。 4、 被列强蚕食 Docker在容器领域快速成长,野心自然也变大了。2014年推出了容器云产品Swarm(K8s的同类产品),想扩张事业版图。同时Docker在开源社区拥有绝对话语权,相当强势。这种走自己的路,让别人无路可走的行为,让容器领域的其他大厂玩家很是不爽,为了不让Docker一家独大,决定要干他。 2015年6月,在Google、Redhat等大厂的“运作”下,Linux基金会成立了OCI(Open Container Initiative)组织,旨在围绕容器格式和运行时制定一个开放的工业化标准,也就是我们常说的OCI标准。同时,Docker公司将Libcontainer模块捐给CNCF社区,作为OCI标准的实现,这就是现在的RunC项目。说白了,就是现在这块儿有个标准了,大家一起玩儿,不被某个特定项目的绑定。 讲到Docker,就得说说Google家的Kubernetes,他作为容器云平台的事实标准,如今已被广泛使用,俨然已成为大厂标配。Kubernetes原生支持Docker,让Docker的市场占有率一直居高不下。如图是2019年容器运行时的市场占有率。  但在2020年,Kubernetes突然宣布在1.20版本以后,也就是2021年以后,不再支持Docker作为默认的容器运行时,将在代码主干中去除dockershim。  如图所示,K8s自身定义了标准的容器运行时接口CRI(Container Runtime Interface),目的是能对接任何实现了CRI接口的容器运行时。在初期,Docker是容器运行时不容置疑的王者,K8s便内置了对Docker的支持,通过dockershim来实现标准CRI接口到Docker接口的适配,以此获得更多的用户。随着开源的容器运行时Containerd(实现了CRI接口,同样由Docker捐给CNCF)的成熟,K8s不再维护dockershim,仅负责维护标准的CRI,解除与某特定容器运行时的绑定。当然,也不是K8s不支持Docker了,只是dockershim谁维护的问题。 随着K8s态度的变化,预计将会有越来越多的开发者选择直接与开源的Containerd对接,Docker公司和Docker开源项目(现已改名为moby)未来将会发生什么样的变化,谁也说不好。  讲到这里,不知道大家有没有注意到,Docker公司其实是捐献了Containerd和runC。这俩到底是啥东西。简单的说,runC是OCI标准的实现,也叫OCI运行时,是真正负责操作容器的。Containerd对外提供接口,管理、控制着runC。所以上面的图,真正应该长这样。  Docker公司是一个典型的小公司因一个爆款项目火起来的案例,不管是技术层面、公司经营层面以及如何跟大厂缠斗,不管是好的方面还是坏的方面,都值得我们去学习和了解其背后的故事。 # 什么是容器 按国际惯例,在介绍一个新概念的时候,都得从大家熟悉的东西说起。幸好容器这个概念还算好理解,喝水的杯子,洗脚的桶,养鱼的缸都是容器。容器技术里面的“容器”也是类似概念,只是装的东西不同罢了,他装的是应用软件本身以及软件运行起来需要的依赖。用鱼缸来类比,鱼缸这个容器里面装的应用软件就是鱼,装的依赖就是鱼食和水。这样大家就能理解docker的logo了。大海就是宿主机,docker就是那条鲸鱼,鲸鱼背上的集装箱就是容器,我们的应用程序就装在集装箱里面。  在讲容器的时候一定绕不开容器镜像,这里先简单的把容器镜像理解为是一个压缩包。压缩包里包含应用的可执行程序以及程序依赖的文件(例如:配置文件和需要调用的动态库等),接下来通过实际操作来看看容器到底是个啥。 一、宿主机视角看容器: 1、首先,我们启动容器。 `docker run -d --name="aimar-1-container" euleros_arm:2.0SP8SPC306 /bin/sh -c "while true; do echo aimar-1-container; sleep 1; done"` 这是Docker的标准命令。意思是使用euleros_arm:2.0SP8SPC306镜像(镜像名:版本号)创建一个新的名字为"aimar-1-container"的容器,并在容器中执行shell命令:每秒打印一次“aimar-1-container”。 - 参数说明: -d:使用后台运行模式启动容器,并返回容器ID。 --name:为容器指定一个名字。 docker run -d --name="aimar-1-container" euleros_arm:2.0SP8SPC306 /bin/sh -c "while true; do echo aimar-1-container; sleep 1; done" 207b7c0cbd811791f7006cd56e17033eb430ec656f05b6cd172c77cf45ad093c 从输出中,我们看到一串长字符207b7c0cbd811791f7006cd56e17033eb430ec656f05b6cd172c77cf45ad093c。他就是容器ID,能唯一标识一个容器。当然在使用的时候,不需要使用全id,直接使用缩写id即可(全id的前几位)。例如下图中,通过docker ps查询到的容器id为207b7c0cbd81  aimar-1-container容器启动成功后,我们在宿主机上使用ps进行查看。这时可以发现刚才启动的容器就是个进程,PID为12280。  我们尝试着再启动2个容器,并再次在宿主机进行查看,你会发现又新增了2个进程,PID分别为20049和21097。  所以,我们可以得到一个结论。从宿主机的视角看,容器就是进程。 2、接下来,我们进入这个容器。 `docker exec -it 207b7c0cbd81 /bin/bash` docker exec也是Docker的标准命令,用于进入某个容器。意思是进入容器id为207b7c0cbd81的容器,进入后执行/bin/bash命令,开启命令交互。 - 参数说明: -it其实是-i和-t两个参数,意思是容器启动后,要分配一个输入/输出终端,方便我们跟容器进行交互,实现跟容器的“对话”能力。  从hostname从kwephispra09909变化为207b7c0cbd81,说明我们已经进入到容器里面了。在容器中,我们尝试着启动一个新的进程。 `[root@207b7c0cbd81 /]# /bin/sh -c "while true; do echo aimar-1-container-embed; sleep 1; done" &`  再次回到宿主机进行ps查看,你会发现不管是直接启动容器,还是在容器中启动新的进程,从宿主机的角度看,他们都是进程。 # 二、容器视角看容器: 前面我们已经进入容器里面,并启动了新的进程。但是我们并没有在容器里查看进程的情况。在容器中执行ps,会发现得到的结果和宿主机上执行ps的结果完全不一样。下图是容器中的执行结果。  在Container1容器中只能看见刚起启动的shell进程(container1和container1-embed),看不到宿主机上的其他进程,也看不到Container2和Container3里面的进程。这些进程像被关进了一个盒子里面,完全感知不到外界,甚至认为我们执行的container1是1号进程(1号进程也叫init进程,是系统中所有其他用户进程的祖先进程)。所以,从容器的视角,容器觉得“我就是天,我就是地,欢迎来到我的世界”。  但尴尬的是,在宿主机上,他们却是普通得不能再普通的进程。注意,相同的进程,在容器里看到的进程ID和在宿主机上看到的进程ID是不一样的。容器中的进程ID分别是1和1859,宿主机上对应的进程ID分别是12280和9775(见上图)。 # 三、总结 通过上面的实验,对容器的定义就需要再加上一个定语。容器就是进程=>容器是与系统其他部分隔离开的进程。 这个时候我们再看下图就更容易理解,容器是跑在宿主机OS(虚机容器的宿主机OS就是Guest OS)上的进程,容器间以及容器和宿主机间存在隔离性,例如:进程号的隔离。  在容器内和宿主机上,同一个进程的进程ID不同。例如:Container1在容器内PID是1,在宿主机上是12280。那么该进程真正的PID是什么呢?当然是12280!那为什么会造成在容器内看到的PID是1呢,造成这种幻象的,正是Linux Namespace。 Linux Namespace是Linux内核用来隔离资源的方式。每个Namespace下的资源对于其他Namespace都是不透明,不可见的。  Namespace按隔离的资源进行分类:  前面提到的容器内外,看到的进程ID不同,正是使用了PID Namespace。那么这个Namespace在哪呢?在Linux上一切皆文件。是的,这个Namespace就在文件里。在宿主机上的proc文件中(/proc/进程号/ns)变记录了某个进程对应的Namespace信息。如下图,其中的数字(例如:pid:[ 4026534312])则表示一个Namespace。  对于Container1、Container2、Container3这3个容器,我们可以看到,他们的PID Namespace是不一样的。说明他们3个容器中的PID相互隔离,也就是说,这3个容器里面可以同时拥有PID号相同的进程,例如:都有PID=1的进程。  在一个命名空间中,那这俩进程就相互可见,只是PID与宿主机上看到的不同而已。  至此,我们可以对容器的定义再细化一层。容器是与系统其他部分隔离开的进程=》容器是使用Linux Namespace实现与系统其他部分隔离开的进程。
讯享网
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/164189.html