
<svg xmlns="http://www.w3.org/2000/svg" style="display: none;"> <path stroke-linecap="round" d="M5,0 0,2.5 5,5z" id="raphael-marker-block" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></path> </svg> <p></p> 讯享网
感兴趣的可以关注一下公众号,会第一时间给您推送更多精彩的内容,欢迎大家前来指正,欢迎欢迎~~
讯享网

参考视频
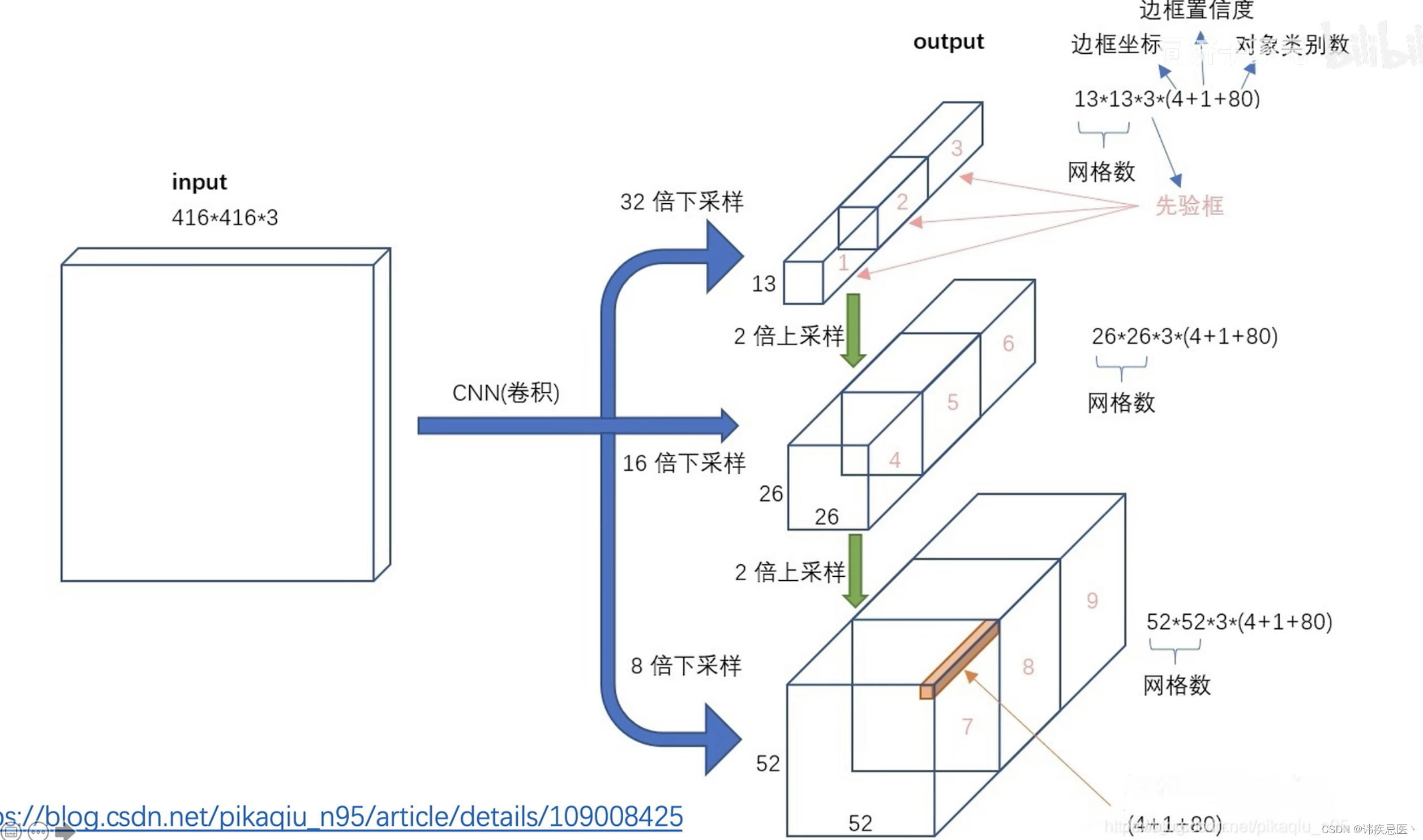
darknet53:52个卷积层和1个全联接层
输入图像为416416
1313 -》 下采样32倍
2626 -》 下采样16倍
5252 -》 下采样8倍
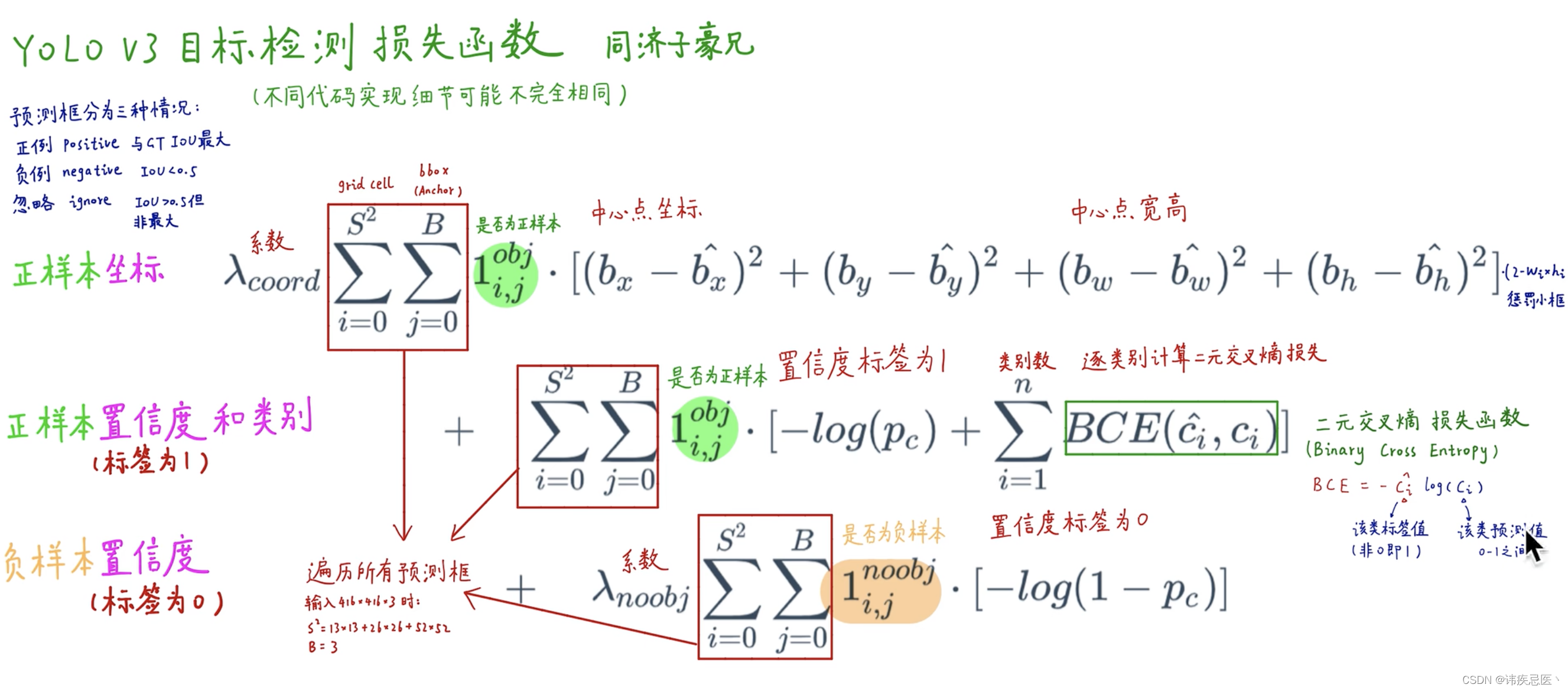
由标注框中心点落在的grid cell中与9个anchors,IOU最大那个去预测,也称正样本,其他非最大的就不是正样本。
正样本:anchors和标记框的IOU最大,他就是正样本
不参与:anchors和标记框的IOU高于某一个阈值,但是不是最大的就忽略
负样本:一个anchors和标记框的IOU小于某一个阈值,负样本
正样本会在所有项中计算损失产生贡献(定位、置信度、分类)
负样本产生贡献(置信度)

1、每个格子是一个grid cell
2、虚线的黑框是anchors
3、实线的蓝框是预测框是以anchors为基准偏移的(以旁边公式)
由tx、ty、th、tw反向推理出来最终结果,sigmoid函数的意义保证输出是0-1之间
cx、cy是归一化之后的长宽

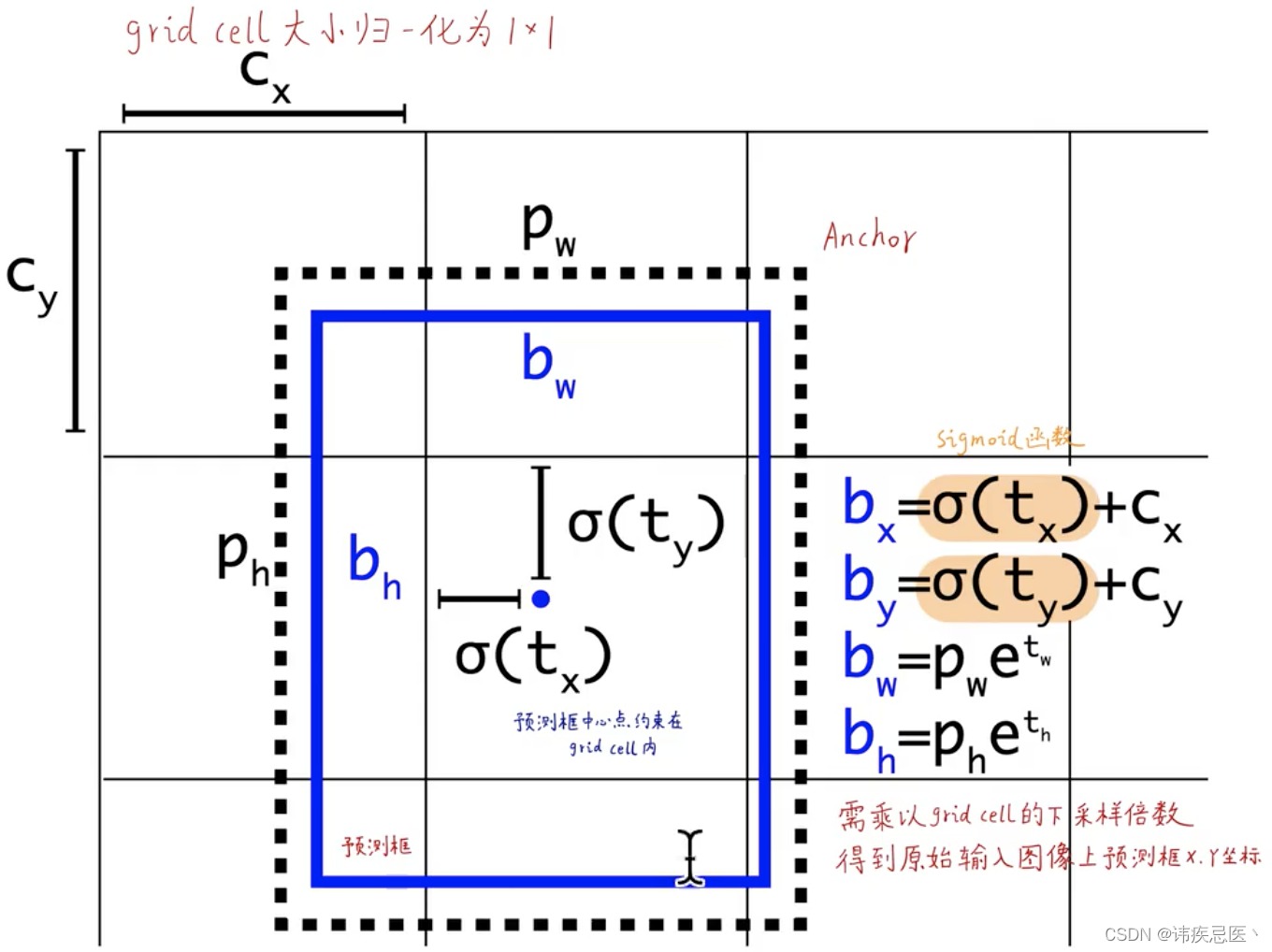
(cx,cy):该点所在网格的左上角距离最左上角相差的格子数。
(pw,ph):先验框的边长
(tx,ty):目标中心点相对于该点所在网格左上角的偏移量
(tw,th):预测边框的宽和高
σ:激活函数,论文作者用的是sigmoid函数,[0,1]之间概率,之所以用sigmoid取代之前版本的softmax,原因是softmax会扩大最大类别概率值而抑制其他类别概率值 ,图解如下
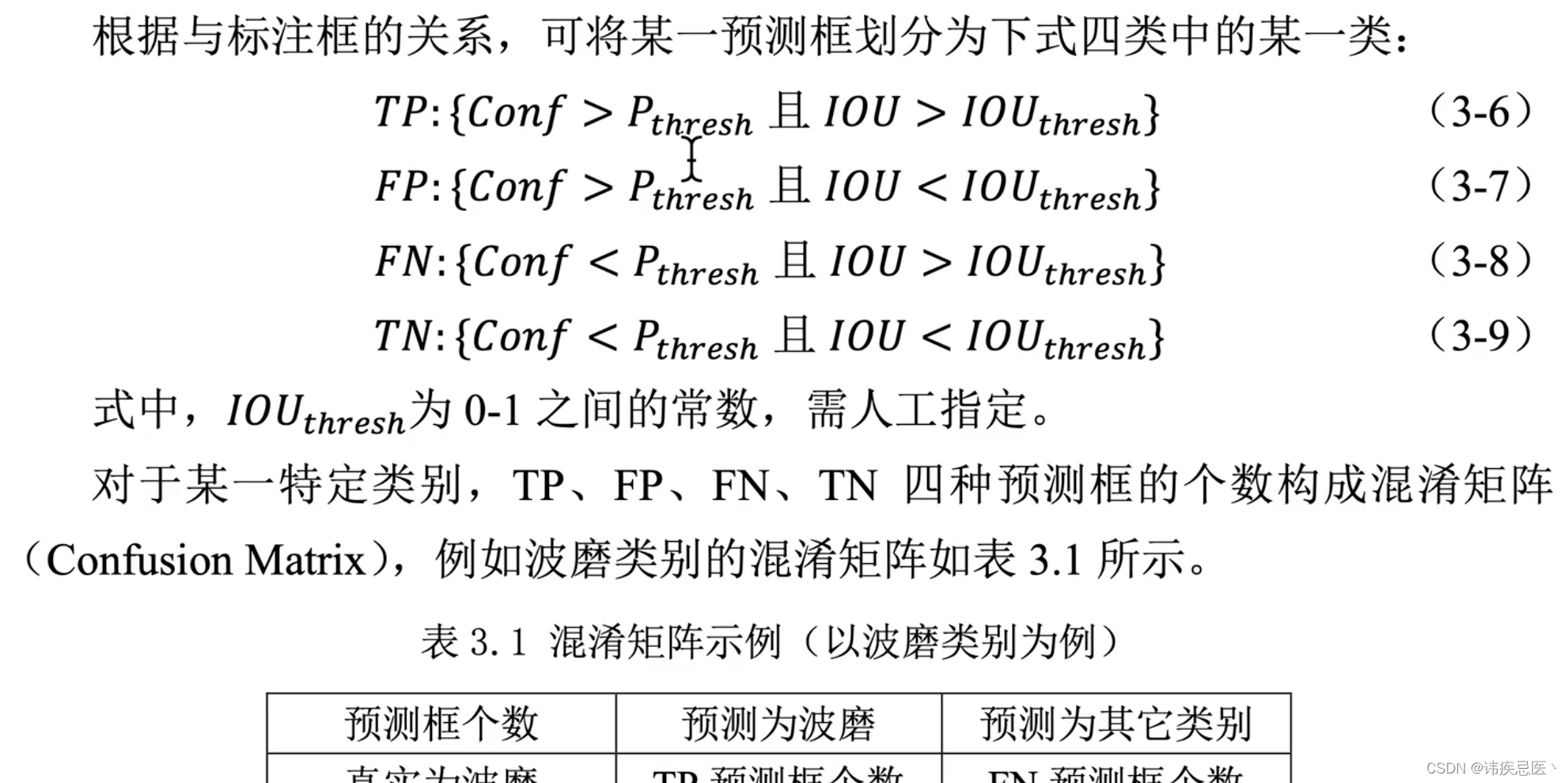
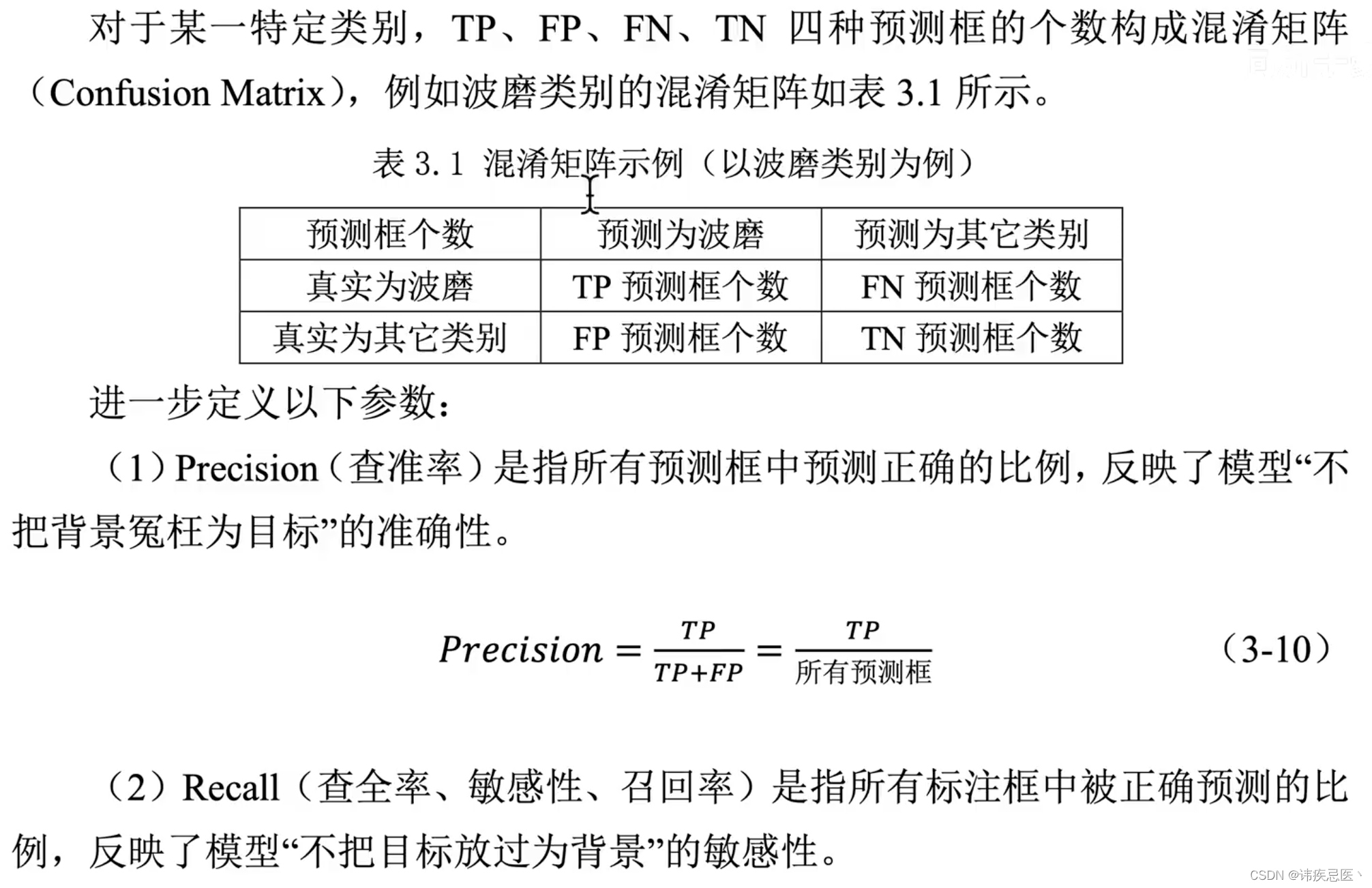
评估指标:yolov3精准定位较差,所以在map@0.5:0.95上较差
map@0.5:IOU阈值为0.5的时候,各个类别PR曲线面积的均值
置信度、IOU阈值
多尺度目标检测:
输入任意尺度,输出3中尺度的feature map,yolov3通过多尺度融合,
改进了小物体和密集物体的检测问题:
1、增加了grid cell的个数
2、预先设置anchor
3、多尺度预测,及发挥了深层网络特化语义特征,又整合了浅层网络细腻度像素结构信息
4、损失函数惩罚小框项
5、网络结构(骨干网络、跨层连接)
讯享网
计算padding填充多少?
h2是卷积之后的高度,h1是原图像高度,f卷积核高度,p是填充多少,s是卷积核步长
h2 = (h1 - F + 2p)/s + 1




池化
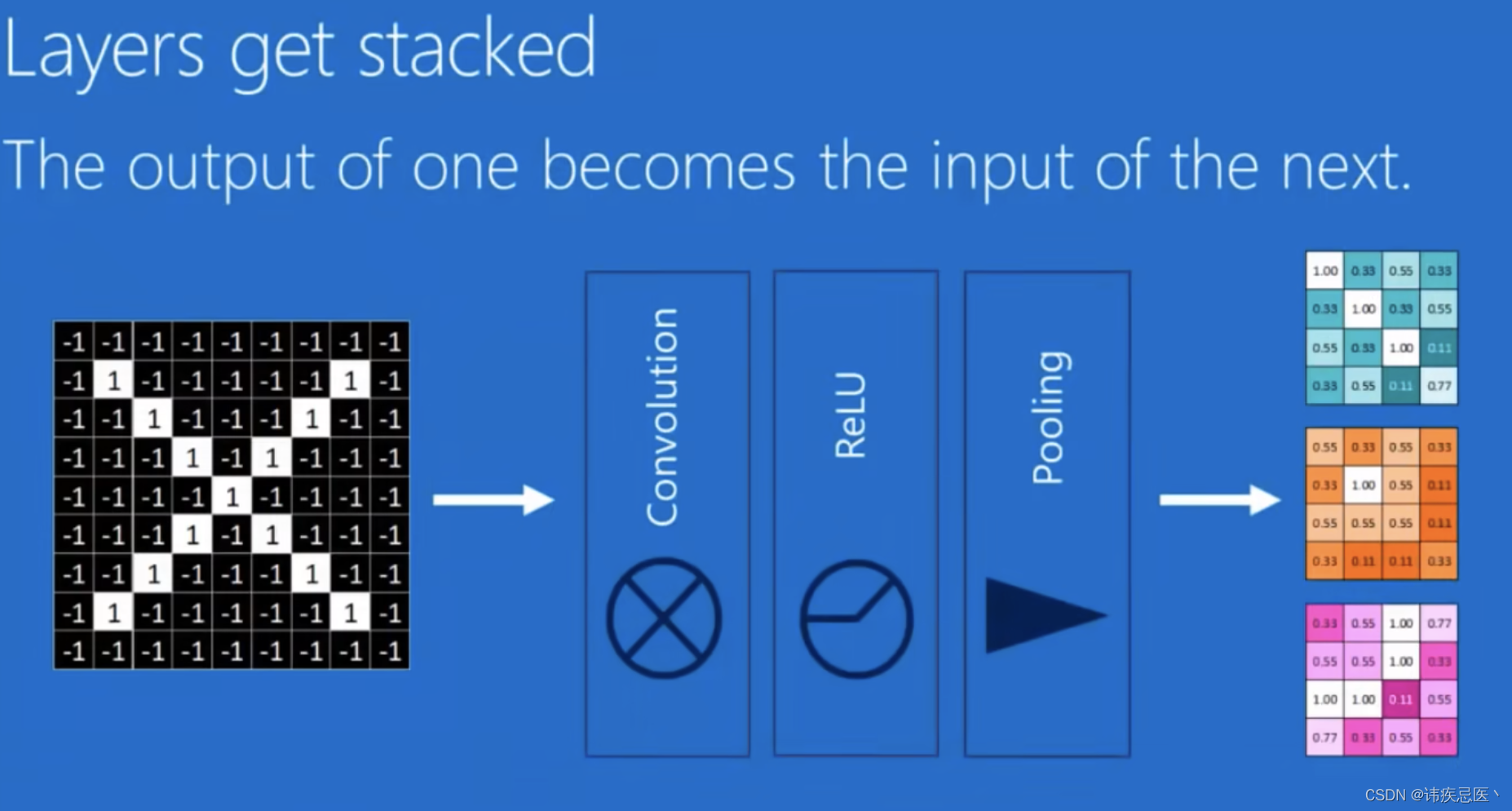
我们对原图提取出来的feature map进行池化(选取区域内最大值作为这个卷积核的值)
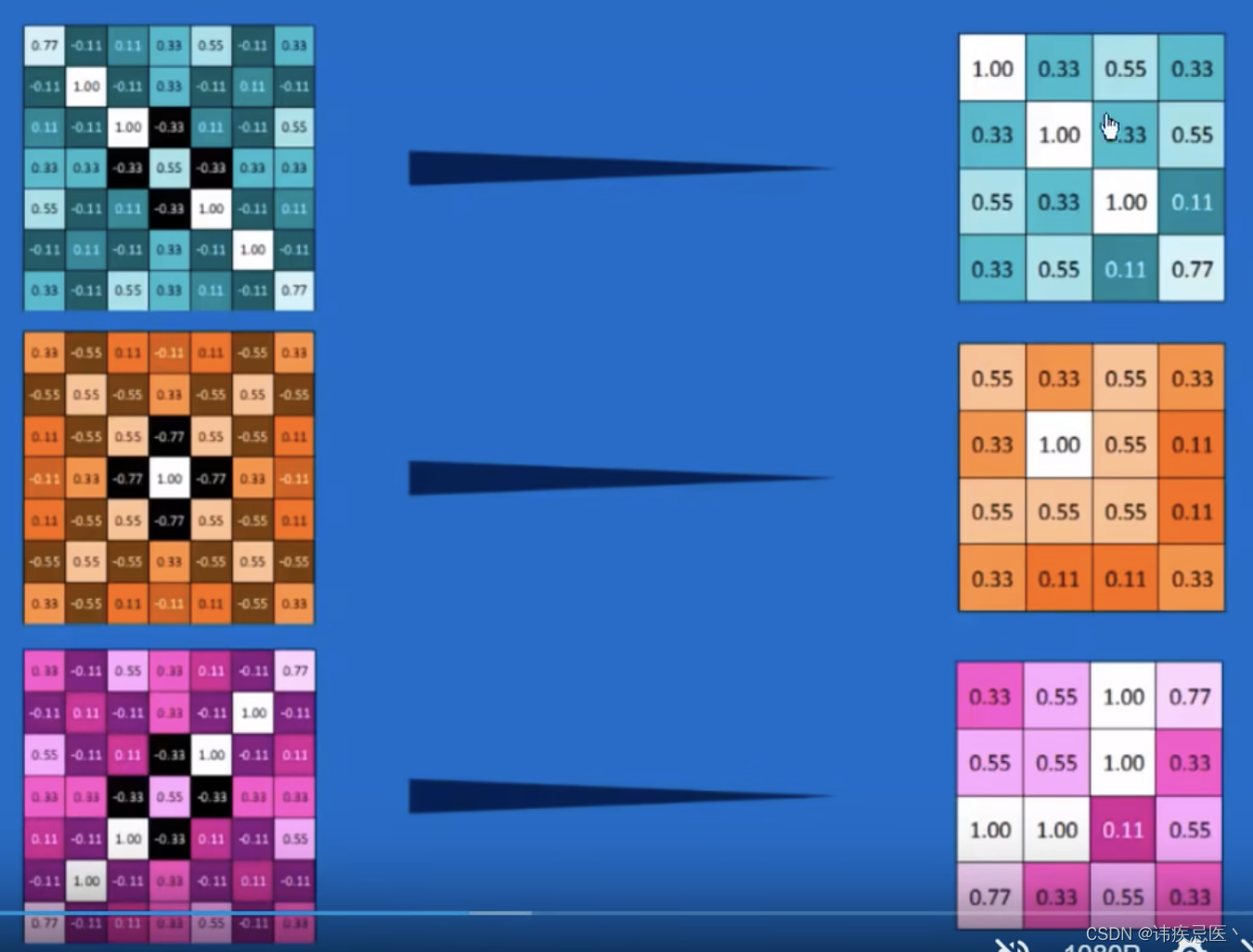
ReLUs将图中负数磨成0(激活函数)

经过卷积->磨0->池化之后就是这个样子了

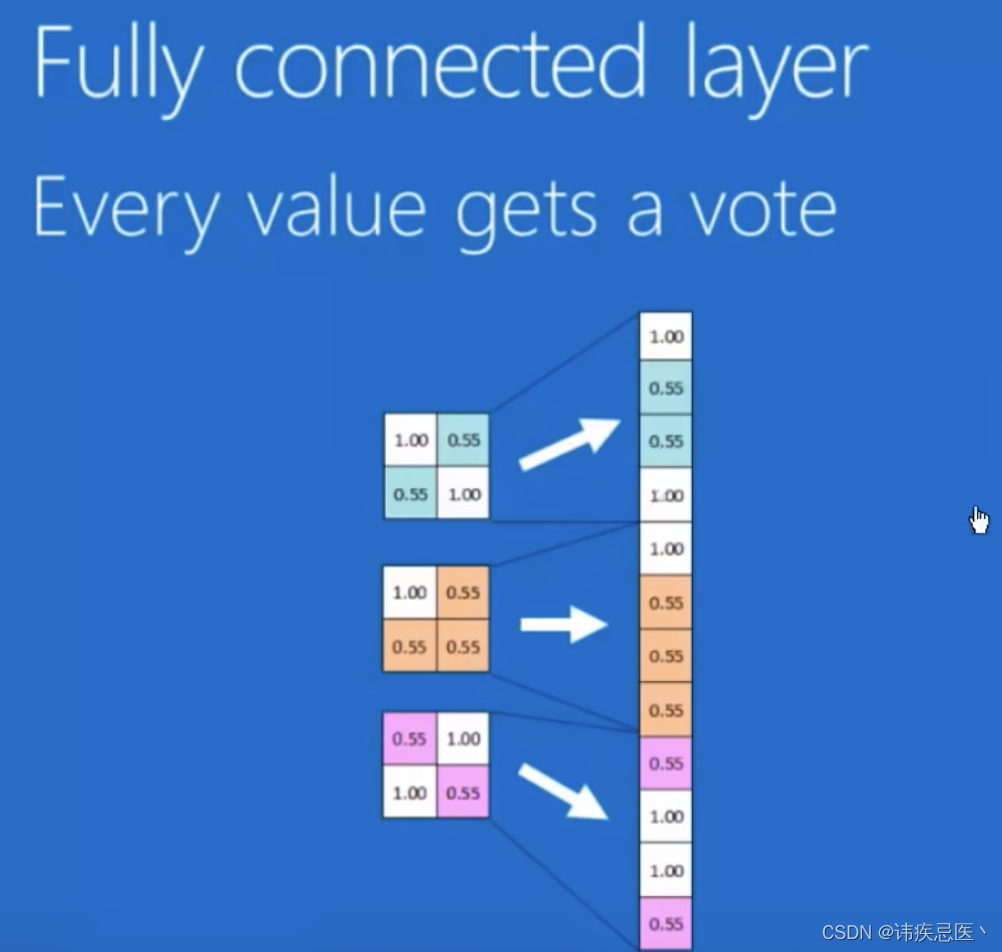
全连接层
将feature map进行排序,将每一个乘上不同权重最终得到结果
通过大量图片去训练这个模型,通过反向传播的方法,神经网络的到一个结果,将其和真实的结果进行比较误差计算(损失函数),我们的目标就是将损失函数降到最低,通过修改卷积核的参数和全连接每一层的权重来进行微调,使得损失函数最小。


版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/157117.html