
1. 设置面板
[XT] xtset – Declare data to be panel data
xtset panelvar timevar [, tsoptions] 讯享网
讯享网# example xtset business_id year
常用面板数据命令 (具体用法用help查一下)
xtset: Declare a dataset to be panel data xtdescribe: Describe pattern of xt data xtsum: Summarize xt data xttab: Tabulate xt data xtdata: Faster specification searches with xt data xtline: Line plots with xt data xtreg: Fixed-, between- and random-effects, and population-averaged linear models xtregar: Fixed- and random-effects linear models with an AR(1) disturbance xtmixed: Multilevel mixed-effects linear regression xtgls: Panel-data models using GLS xtpcse: OLS or Prais-Winsten models with panel-corrected standard errors xthtaylor; Hausman-Taylor estimator for error-components models xtfrontier: Stochastic frontier models for panel data xtrc: Random coefficients models xtivreg: Instrumental variables and two-stage least squares for panel-data models xtunitroot: Panel-data unit-root tests xtabond: Arellano-Bond linear dynamic panel-data estimator xtdpdsys Arellano-Bond/Blundell-Bond estimation xtdpd: Linear dynamic panel-data estimation xttobit: Random-effects tobit models xtintreg: Random-effects interval-data regression models xtlogit: Fixed-effects, random-effects, & population-averaged logit models xtprobit: Random-effects and population-averaged probit models xtcloglog: Random-effects and population-averaged cloglog models xtpoisson: Fixed-effects, random-effects, & population-averaged Poisson models xtnbreg: Fixed-effects, random-effects, & population-averaged negative binomial models xtmelogit: Multilevel mixed-effects logistic regression xtmepoisson: Multilevel mixed-effects Poisson regression xtgee: Population-averaged panel-data models using GEE 参考来源:Stata:面板数据计量方法汇总
面板设置常见问题
1.1 pannel variable为string类型
把 string 转换为数字类型
讯享网# 自己改一下pannel variable encode business_id, gen(business_id_1) drop business_id rename business_id_1 business_id
1.2 时间变量为string类型
- 如果是只有年份的数据,可以直接把字符串转换为数值类型
destring year, replace force - 如果时间变量还包含日期,则需要多一步转换
我的日期数据是这样的,包括了时分秒
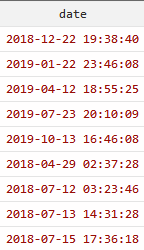
讯享网
讯享网# 把时间转换成双精度数值类型 gen double time = clock(date, "YMDhms")
转换后就会成为一串数值
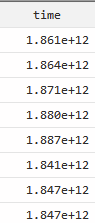
stata常用时间命令,根据自己时间数据的格式以及需求选择合适的来用
Clock(s1,s2[,Y]) clock(s1,s2[,Y]) date(s1,s2[,Y]) daily(s1,s2[,Y]) 具体还可以参考:
STATA日期函数汇总
【STATA】时间变量处理,字符串转为日期时间

1.3 报错:repeated time values within panel
面板数据下同一vari不允许出现同样的时间,因此我们需要把重复的数据去除
讯享网# 报告重复数据 duplicates report business_id time # 列出重复数据 duplicates list business_id time # 去除重复数据 duplicates drop business_id time, force
2. 面板数据多元线性回归
[XT] xtreg – Fixed-, between-, and random-effects and population-averaged linear models
GLS random-effects (RE) model xtreg depvar [indepvars] [if] [in] [, re RE_options] Between-effects (BE) model xtreg depvar [indepvars] [if] [in] , be [BE_options] Fixed-effects (FE) model xtreg depvar [indepvars] [if] [in] [weight] , fe [FE_options] ML random-effects (MLE) model xtreg depvar [indepvars] [if] [in] [weight] , mle [MLE_options] Population-averaged (PA) model xtreg depvar [indepvars] [if] [in] [weight] , pa [PA_options] 讯享网# 一维聚类调整异方差-序列相关稳健型标准误 (HAC) xtreg like stars text_len sentiment polarity i.year, fe vce(cluster business_id)

# 二维聚类 SE webuse "nlswork.dta", clear vce2way regress ln_wage age grade, cluster(idcode year) 参考来源:Stata 连享会: 聚类调整标准误笔记
3. 面板数据泊松回归
[XT] xtpoisson – Fixed-effects, random-effects, and population-averaged Poisson models
讯享网Random-effects (RE) model xtpoisson depvar [indepvars] [if] [in] [weight] [, re RE_options] Conditional fixed-effects (FE) model xtpoisson depvar [indepvars] [if] [in] [weight] , fe [FE_options] Population-averaged (PA) model xtpoisson depvar [indepvars] [if] [in] [weight] , pa [PA_options]
- example
# 一维聚类调整异方差-序列相关稳健型标准误 (HAC) xtpoisson like stars text_len sentiment polarity i.year, vce(robust) i(business_id) fe 
在这里回归模型会去掉 “one obs per group” 或 “all zero outcomes”的数据, 当DV不同IV相同时去掉的数据量也不一样。为了保证多个DV的模型都使用相同的数据进行回归分析,我们可以把每个DV下xtpoisson回归所使用的数据都标上记号
讯享网# xtpoisson useful stars text_len sentiment polarity i.year, vce(robust) i(business_id) fe gen sample_useful=e(sample) # xtpoisson funny stars text_len sentiment polarity i.year, vce(robust) i(business_id) fe gen sample_funny=e(sample) # xtpoisson cool stars text_len sentiment polarity i.year, vce(robust) i(business_id) fe gen sample_cool=e(sample)
然后再进行回归分析
xtpoisson useful stars text_len sentiment polarity i.year if sample_useful==1 & sample_funny==1 & sample_cool==1, vce(robust) i(business_id) fe xtpoisson funny stars text_len sentiment polarity i.year if sample_useful==1 & sample_funny==1 & sample_cool==1, vce(robust) i(business_id) fe xtpoisson cool stars text_len sentiment polarity i.year if sample_useful==1 & sample_funny==1 & sample_cool==1, vce(robust) i(business_id) fe
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/15645.html