
<svg xmlns="http://www.w3.org/2000/svg" style="display: none;"> <path stroke-linecap="round" d="M5,0 0,2.5 5,5z" id="raphael-marker-block" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></path> </svg> <h4>MySQL 的索引是如何提高查询效率的?</h4> 讯享网
索引是数据库中用来提高查询效率的技术,类似于目录。如果不使用索引,数据会零散的保存在磁盘块中,查询数据需要挨个遍历每一个磁盘块,直到找到数据为止,使用索引后会将磁盘块以树桩结构保存,查询数据时会大大降低磁盘块的访问数量,从而提高查询效率。如果表中的数据很少,使用索引反而会降低查询效率。并且索引会占用磁盘空间,一般只针对查询时常用的字段创建索引。索引分为聚集索引和非聚集索引,通过主键创建的索引称为聚集索引,聚集索引中保存数据,只要给表添加主键约束,则会自动创建聚集索引;通过非主键字段创建的索引称为非聚集索引,非聚集索引中没有数据。还可以通过多个字段来创建复合索引。

MySQL 中存储索引用的一般都是 B + 树。它的数据都存放在叶子节点中,同时叶子节点之间还添加了指针形成了链表。有点像 HashMap 的底层实现,数组 + 链表的结构。
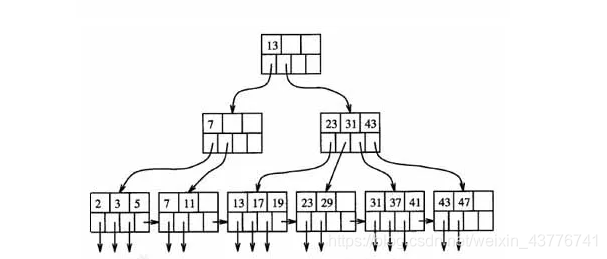
上图是一个 4 路 B + 树,可以清楚的看到,所有的数据都存放在叶子节点上,并且叶子节点之间有指针链表相连。

首先,B + 树是平衡树。树的查询效率是 log(n),n 为树的高度。如果使用非平衡树,如二叉树。那么在特殊情况,如插入的数据是有序的,会出现什么情况呢?
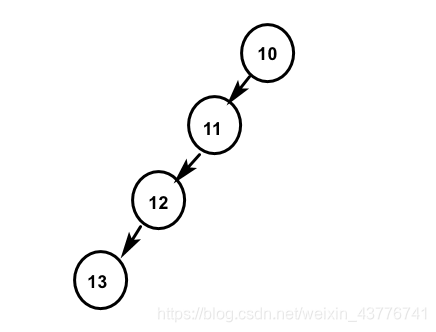
二叉树发生了退化,变成了链表,树的高度变高了,影响了查询的效率。由于 B + 树是平衡树,保证了树的高度是最优的,所以不会出现上述的退化情况。上文展示了一个 4 路的 B + 树,可以看出当路数越多时,树的高度是越低的,那么问题来了,为什么不设计一个无限多路的 B 树来降低树高度,从而提升查询效率呢?先来看看一个无限多路的 B 树是什么样的。
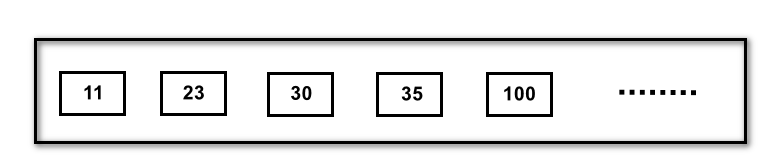
不限路数,B 树就退化成了一个数组。那么会出现什么问题呢?数据库的索引是存储在硬盘上的,如果数据量大的话,不一定可以一次性加载到内存中。这时候,多路存储的好处就体现出来了,可以每次加载树的一个节点,然后一步步往下找。比如一个三路的 B 树,每个节点最多有两个数,查找的时候每次载入一个节点进内存就行,就不会出现数据量过大无法加载到内存中的情况。在业务场景中查询数据时,往往是查询多条数据,比如查询最近修改过的 10 条数据,B + 树在 B 树的基础上进行了优化,B + 树的所有数据都在叶子结点,同时有链表结构,只需要找到首尾,就可以把所有的数据找出来了。综上述所述,MySQL 中存储索引用 B + 树的好处主要是降低树高度提高查询效率、多路设计保证硬盘到内存的加载、叶子节点存储数据并且加了指针形成链表在范围查找时只需定位首尾就可以取出所需数据。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/151362.html