
梯度提升树(GBDT)的全称是Gradient Boosting Decision Tree。GBDT还有很多的简称,例如GBT(Gradient Boosting Tree), GTB(Gradient Tree Boosting ),GBRT(Gradient Boosting Regression Tree), MART(Multiple Additive Regression Tree)等,其实都是指的同一种算法,本文统一简称GBDT。
然后,GBDT的核心在于每一棵树学的事之前所有树结论的残差,残差其实就是真实值和预测值之间的差值,在学习的过程中,首先学习一颗回归树(分类树的结果显然是没办法累加的,所以GBDT中的树都是回归树),然后将“真实值-预测值”得到残差,再把残差作为一个学习目标,学习下一棵回归树,依次类推,直到残差小于某个接近0的阀值或回归树数目达到某一阀值。其核心思想是每轮通过拟合残差来降低损失函数。总的来说,第一棵树是正常的,之后所有的树的决策全是由残差来决定。
最后,使用梯度下降算法减小损失函数。对于一般损失函数,为了使其取得最小值,通过梯度下降算法,每次朝着损失函数的负梯度方向逐步移动,最终使得损失函数极小的方法(此方法要求损失函数可导)。梯度提升算法GBDT其实是一个算法框架,即可以将已有的分类或回归算法放入其中,得到一个性能很强大的算法。GBDT总共需要进行M次迭代,每次迭代产生一个模型,我们需要让每次迭代生成的模型对训练集的损失函数最小,而如何让损失函数越来越小呢?我们采用梯度下降的方法,在每次迭代时通过向损失函数的负梯度方向移动来使得损失函数越来越小,这样我们就可以得到越来越精确的模型。
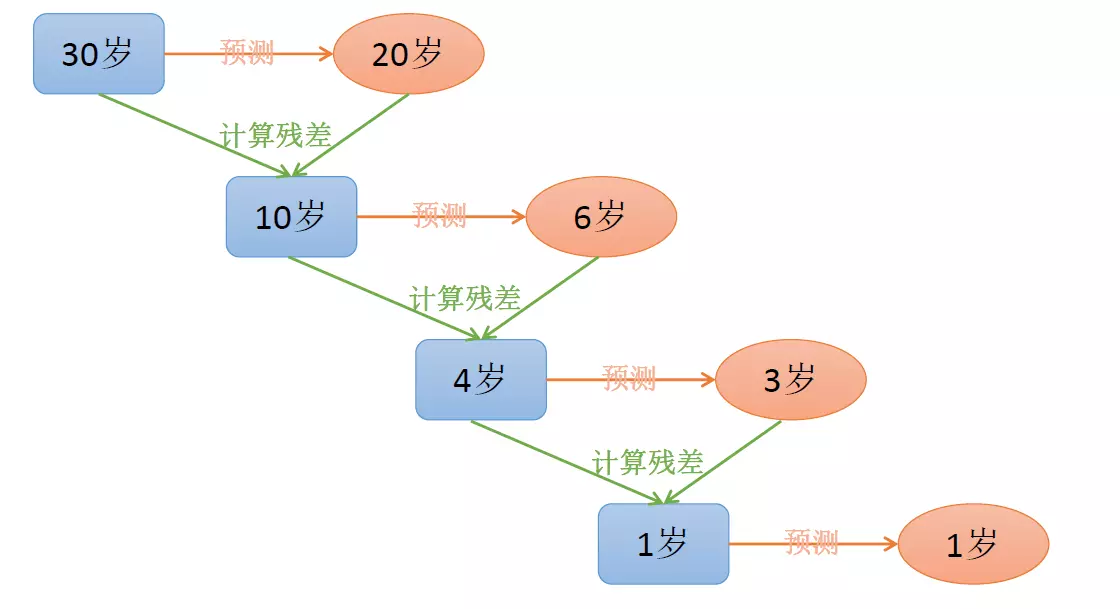
GBDT 直观理解:每一轮预测和实际值有残差,下一轮根据残差再进行预测,最后将所有预测相加,就是结果(不断去拟合残差,使残差不断减少)。GBDT的思想可以用一个通俗的例子解释,假如有个人30岁,我们首先用20岁去拟合,发现损失有10岁,这时我们用6岁去拟合剩下的损失,发现差距还有4岁,第三轮我们用3岁拟合剩下的差距,差距就只有一岁了。如果我们的迭代轮数还没有完,可以继续迭代下面,每一轮迭代,拟合的岁数误差都会减小。
1.GBDT损失函数极小化
在GBDT的迭代中,假设我们前一轮迭代得到的强学习器是\(f_{t-1}(x)\), 损失函数是\(L(y,f_{t-1}(x))\), 我们本轮迭代的目标是找到一个CART回归树模型的弱学习器\(h_t(x)\),让本轮的损失函数\(L(y,f_{t}(x) =L(y,f_{t-1}(x)+ h_t(x))\)最小。也就是说,本轮迭代找到决策树,要让样本的损失尽量变得更小。即GBDT初始化时(估计使损失函数极小化的常数值,它是只有一个根节点的树,一般平方损失函数为节点的均值,而绝对损失函数为节点样本的中位数):
$\(f_0(x) = 縛set{c}{arg; min}sumlimits_{i=1}^{m}L(y_i, c)\)\(</p> <p>从上面的例子看这个思想还是蛮简单的,但是有个问题是这个损失的拟合不好度量,损失函数各种各样,怎么找到一种通用的拟合方法呢? </p> <p><span style="font-size: 18pt"><strong>2.GBDT的负梯度拟合</strong></span></p> <p>当损失函数是平方损失和指数损失函数时,梯度提升树每一步优化是很简单的,但是对于一般损失函数而言,往往每一步优化起来不那么容易,针对这一问题,Friedman提出了梯度提升树算法,这是利用最速下降的近似方法,其关键是利用损失函数的负梯度作为提升树算法中的残差的近似值,进而拟合一个CART回归树。</p> <p>对于提到的三种损失函数,其最小化方法各有不同。当损失函数为下面几种函数时,最小化损失函数的方法如下:</p> <p><strong>1. 指数函数:</strong>当损失函数为指数函数时,比如AdaBoost算法的损失函数是指数函数,这时通过前向分步算法来解决。前向分布算法在每轮迭代时,通过将上一轮所生成的模型所产生的损失函数最小化的方法来计算当前模型的参数。</p> <p><strong>2. 平方误差损失函数:</strong>在回归树提升算法中,遍历当前输入样例的可能取值,将每种可能值计算一遍损失函数,最终选择损失函数最小的值(很原始)。在计算平方损失误差时,可能出现残差项\)y-f{m-1}(x)\(,此时可以通过如下方法来进行优化:每一轮迭代是为了减小上一步模型的残差,为了减少残差,每次在残差的负梯度方向建立一个新的模型,这样一步一步的使得残差越来越小。</p> <p><strong>3. 一般损失函数:</strong> 对于一般损失函数,可以通过梯度下降的方法来使得损失函数逐步减小,每次向损失函数的负梯度方向移动,直到损失函数值到达谷底。</p> <p>那么负梯度长什么样呢?第t轮的第i个样本的损失函数的负梯度表示为:</p> <p>\)$r{ti} = -bigg[frac{partial L(y_i, f(x_i)))}{partial f(xi)}bigg]{f(x) = f_{t-1};; (x)}$\(</p> <p>此时不同的损失函数将会得到不同的负梯度,假设选择平方损失:</p> <p>\)\(L(y,f(x_i))= 1/2(y-f(x_i))^{2}\)\(</p> <p>则负梯度为:\)\(r_{ti} = -bigg[frac{partial L(y_i, f(x_i)))}{partial f(x_i)}bigg]_{f(x) = f_{t-1};; (x)}=y-f(x_i)\)\(</p> <p>此时发现GBDT的负梯度就是残差,所以说对于回归问题,我们要拟合的就是残差。那么对于分类问题,二分类和多分类的损失函数都是logloss。因为损失函数有很多种,所以用负梯度拟合来做通用的拟合方法。</p> <p><span style="font-size: 18pt"><strong>3.GBDT中常用的损失函数</strong></span></p> <p>在梯度提升分类树有两种可选的损失函数,一种是‘exponential:指数损失’,一种是‘deviance:对数损失’;而在梯度提升回归树有四种可选的损失函数,分别为'ls:平方损失','lad:绝对损失','huber:huber损失','quantile:分位数损失'。</p> <p>对于分类算法,其损失函数一般有对数损失函数和指数损失函数两种:</p> <p>1) 如果是<strong>指数损失函数</strong>,则损失函数表达式为:\)\(L(y, f(x)) = exp(-yf(x))\)\(</p> <p>其负梯度计算和叶子节点的**负梯度拟合参见Adaboost算法原理。</p> <p>2) 如果是<strong>对数损失函数</strong>,分为二元分类和多元分类两种:</p> <p>对于二元分类,用类似于逻辑回归的对数似然损失函数:\)\(L(y, f(x)) = log(1+ exp(-yf(x)))\)\(</p> <p>对于多元分类:设类别数为k:\)\(L(y, f(x)) = - sumlimits_{k=1}^{K}y_klog;p_k(x)\)\(</p> <p>\)y_k\(为样本数据估计值,当一个样本x属于k时,\)y_k=1\(,否则\)y_k=0\(。</p> <p>对于回归算法,常用损失函数有如下4种:</p> <p>1)<strong>均方差</strong>,这个是最常见的回归损失函数:\)\(L(y, f(x)) =(y-f(x))^2\)\(</p> <p>2)<strong>绝对损失</strong>,这个损失函数也很常见:\)\(L(y, f(x)) =|y-f(x)|\)\(</p> <p>对应负梯度误差为:\)\(sign(y_i-f(x_i))\)\(</p> <p>3)<strong>Huber损失</strong>,它是均方差和绝对损失的折衷产物,对于远离中心的异常点,采用绝对损失,而中心附近的点采用均方差。这个界限一般用分位数点度量。损失函数如下:</p> <p>\)\(L(y, f(x))=begin{cases}frac{1}{2}(y-f(x))^2& {|y-f(x)| leq delta}\delta(|y-f(x)| - frac{delta}{2})& {|y-f(x)| > delta}end{cases}\)\(</p> <p>对应的负梯度误差为:</p> <p>\)\(r(y_i, f(x_i))=begin{cases}y_i-f(x_i)& {|y_i-f(x_i)| leq delta}\delta sign(y_i-f(x_i))& {|y_i-f(x_i)| > delta}end{cases}\)\(</p> <p>4)<strong> 分位数损失</strong>。它对应的是分位数回归的损失函数,表达式为:\)\(L(y, f(x)) =sumlimits_{y geq f(x)} heta|y - f(x)| + sumlimits_{y < f(x)}(1- heta)|y - f(x)| \)\(</p> <p>其中\) heta\(为分位数,需要我们在回归前指定。对应的负梯度误差为:</p> <p>\)\(r(y_i, f(x_i))=<br>begin{cases}<br> heta& { y_i geq f(x_i)}\<br> heta - 1 & {y_i < f(x_i) }<br>end{cases}\)\(</p> <p>对于Huber损失和分位数损失,主要用于健壮回归,也就是减少异常点对损失函数的影响。</p> <p><span style="font-size: 18pt"><strong>4.GBDT算法原理描述</strong></span></p> <p>因为分类算法的输出是不连续的类别值,需要一些处理才能使用负梯度,所以GBDT的回归和分类算法这里分开介绍。</p> <p id="%E4%BA%8C.%20GBDT%E5%9B%9E%E5%BD%92%E6%A0%91%E5%9F%BA%E6%9C%AC%E6%A8%A1%E7%89%88"><span style="font-size: 18px"><strong>(1).GBDT回归算法基本模版:</strong></span></p> <p>输入是训练集样本\)T={(x_,y_1),(x_2,y_2), …,(x_m,y_m)}\(, 最大迭代次数T, 损失函数L。</p> <p>输出是强学习器 f(x) ,是一颗回归树。</p> <p>1) 初始化弱学习器(估计使损失函数极小化的常数值,它是只有一个根节点的树,一般平方损失函数为节点的均值,而绝对损失函数为节点样本的中位数):\)\(f_0(x) = 縛set{c}{arg; min}sumlimits_{i=1}^{m}L(y_i, c)\)\(</p> <p>2) 对迭代轮数t=1,2,...,T有(即生成的弱学习器个数):</p> <p>(2.1)对样本i=1,2,...,m,计算负梯度(损失函数的负梯度在当前模型的值将它作为残差的估计,对于平方损失函数为,它就是通常所说的残差;而对于一般损失函数,它就是残差的近似值(伪残差)):\)\(r_{ti} = -bigg[frac{partial L(y_i, f(x_i)))}{partial f(x_i)}bigg]_{f(x) = f_{t-1};; (x)}\)\(</p> <p>(2.2)利用\)(xi,r{ti});; (i=1,2,..m)\(,即\){(x1,r{t1}), …,(xi,r{ti})}\(,拟合一颗CART回归树,得到第t颗回归树。其对应的叶子节点区域为\)R{tj},j =1,2,…,J\(。其中J为回归树t的叶子节点的个数。</p> <p>(2.3)对叶子区域j =1,2,..J,计算**拟合值:\)$c{tj} = 縛set{c}{arg; min}sumlimits_{xi in R{tj}} L(yi,f{t-1}(xi) +c)$\(</p> <p>(2.4)更新强学习器:\)$f{t}(x) = f{t-1}(x) + sumlimits{j=1}^{J}c{tj}I(x in R{tj}) $\(</p> <p>3) 得到最终的回归树,即强学习器f(x)的表达式:\)\(f(x) = f_T(x) =f_0(x) + sumlimits_{t=1}^{T}sumlimits_{j=1}^{J}c_{tj}I(x in R_{tj})\)\(</p> <p> </p> <p><strong>GBDT的分类算法:</strong>GBDT的分类算法从思想上和GBDT的回归算法没有区别,但是由于样本输出不是连续的值,而是离散的类别,导致我们无法直接从输出类别去拟合类别输出的误差。为了解决这个问题,主要有两个方法,一个是用指数损失函数,此时GBDT退化为Adaboost算法。另一种方法是用类似于逻辑回归的对数似然损失函数的方法。也就是说,我们用的是类别的预测概率值和真实概率值的差来拟合损失。这里主要介绍用对数似然损失函数的GBDT分类。而对于对数似然损失函数,我们又有二元分类和多元分类的区别。</p> <p><span style="font-size: 14pt"><strong>(2).二元GBDT分类算法基本模板(log损失):</strong></span></p> <p>输入:训练数据集\)T={(x_,y_1),(x_2,y_2), …(x_m,y_m)}\(,对于二元GBDT用类似于逻辑回归的对数似然损失函数,损失函数为:\)L(y, f(x)) = log(1+ exp(-yf(x)))\(。</p> <p>输出:分类树\)f(x)\(</p> <p>1)初始化: \)\(f_0(x) = frac{1}{2}log frac{P(y=1|x)}{P(y=-1|x)}\)\(</p> <p>2) 对迭代轮数t=1,2,...T有:</p> <p>(2.1)对样本i=1,2,...m,计算负梯度</p> <p>其中\)y in{-1, +1}\(。则此时的负梯度误差为:\)\(r_{ti} = -bigg[frac{partial L(y, f(x_i)))}{partial f(x_i)}bigg]_{f(x) = f_{t-1};; (x)} = frac{y_i}{(1+exp(y_if(x_i)))}\)\(</p> <p>(2.2)对概率残差\){(x1,r{t1}),…,(xi,r{ti})}\(拟合一个分类树,得到第t棵树的叶节点区域\)R{tj}, j =1,2,…, J\(。其中J为回归树t的叶子节点的个数</p> <p>(2.3)对叶子区域j =1,2,..J,即生成的决策树,计算各个叶子节点的**负梯度拟合值为:\)$c{tj} = 縛set{c}{arg; min}sumlimits_{xi in R{tj}} log(1+exp(-yi(f{t-1}(xi) +c)))$\(</p> <p>由于上式比较难优化,我们一般使用近似值代替:\)$c{tj} =frac{ sumlimits_{xi in R{tj}}r{ti}}{sumlimits{xi in R{tj}}|r{ti}|(1-|r{ti}|)}$\(</p> <p>(2.4)更新强学习器:\)\(f_{t}(x) = f_{t-1}(x) + sumlimits_{j=1}^{J}c_{tj}I(x in R_{tj}) \)\(</p> <p>3) 得到最终的分类树,即强学习器f(x)的表达式:\)\(f(x) = f_T(x) =f_0(x) + sumlimits_{t=1}^{T}sumlimits_{j=1}^{J}c_{tj}I(x in R_{tj})\)\(</p> <p>除了负梯度计算和叶子节点的**负梯度拟合的线性搜索,二元GBDT分类和GBDT回归算法过程相同。</p> <p>由于我们用的是类别的预测概率值和真实概率值的差来拟合损失,所以最后还要将概率转换为类别,如下:</p> <p>\)\(P(y=1|x) = frac{1}{1+exp(-f(x))}\)\(</p> <p>\)\(P(y=-1|x) = frac{1}{1+exp(f(x))}\)\(</p> <p>最终输出比较类别概率大小,概率大的就预测为该类别。</p> <p><span style="font-size: 14pt"><strong>3.多元GBDT分类算法基本模型(log损失):</strong></span></p> <p>多元GBDT要比二元GBDT复杂一些,对应的是多元逻辑回归和二元逻辑回归的复杂度差别。</p> <p>输入:训练数据集\)T={(x_,y_1),(x_2,y_2), …(x_m,ym)}\(,假设类别数为K,则对数似然损失函数为:\)L(y, f(x)) = - sumlimits{k=1}^{K}y_klog;p_k(x) \(,={0,1}其中\)yk={0,1}\(表示是否属于第k类别,1表示是,0表示否。\)k=1,2,…,K\(,表示共有多少分类的类别。</p> <p>输出:分类树\)f(x)\(</p> <p>1)初始化:\)$f{k0}(x) = 0,k=1,2,…,K$\(</p> <p>2) 对迭代轮数t=1,2,...,T有:</p> <p>对样本i=1,2,...,m,计算样本点属于每个类别的概率(其中如果样本输出类别为k,则\)y_k=1\(。第k类的概率):</p> <p>\)\(p_k(x) = frac{exp(f_k(x))}{sumlimits_{l=1}^{K} exp(f_l(x))} \)\(</p> <p>(2.1)对类别k=1,2,...,K:</p> <p>集合上两式(损失函数和第k类的概率),可以计算出第\)t\(轮的第\)i\(个样本对应类别\)l\(的负梯度误差为\)\(r_{til} = -bigg[frac{partial L(y_i, f(x_i)))}{partial f(x_i)}bigg]_{f_k(x) = f_{l, t-1};; (x)} = y_{il} - p_{l, t-1}(x_i)\)\(</p> <p>观察上式可以看出,其实这里的误差就是样本\)i\(对应类别\)l\(的真实概率和\)t-1\(轮预测概率的差值。</p> <p>(2.2)对概率伪残差\){(x1,r{t1l}),…,(xi,r{til})}\(拟合一个分类树。</p> <p>(2.3)对于生成的决策树,我们各个叶子节点的**负梯度拟合值为\)\(c_{tjl} = 縛set{c_{jl}}{arg; min}sumlimits_{i=0}^{m}sumlimits_{k=1}^{K} L(y_k, f_{t-1, l}(x) + sumlimits_{j=0}^{J}c_{jl} I(x_i in R_{tjl}))\)\(</p> <p>由于上式比较难优化,我们一般使用近似值代替\)\(c_{tjl} = frac{K-1}{K} ; frac{sumlimits_{x_i in R_{tjl}}r_{til}}{sumlimits_{x_i in R_{til}}|r_{til}|(1-|r_{til}|)}\)\(</p> <p>(2.4)更新强学习器:</p> <p>\)\(f_{tk}(x) = f_{t-1,k}(x) + sumlimits_{j=1}^{J}c_{tkj}I(x in R_{tkj}) \)\(</p> <p>3)得到最终的分类树,即强学习器f(x)的表达式:\)\(f(x) = f_{Tk}(x) =f_0(x) + sumlimits_{t=1}^{T}sumlimits_{j=1}^{J}c_{tkj}I(x in R_{tkj})\)\(</p> <p>除了负梯度计算和叶子节点的**负梯度拟合的线性搜索,多元GBDT分类和二元GBDT分类以及GBDT回归算法过程相同。</p> <p><span style="font-size: 18pt"><strong>5.GBDT的正则化</strong></span></p> <p>和Adaboost一样,我们也需要对GBDT进行正则化,防止过拟合。GBDT的正则化主要有三种方式:</p> <p>(1). Adaboost类似的正则化项,即步长(learning rate)。定义为\) u\(,对于前面的弱学习器的迭代:\)f{k}(x) = f{k-1}(x) + hk(x) \(</p> <p>如果我们加上了正则化项,则有:\)f{k}(x) = f_{k-1}(x) + u h_k(x) \(</p> <p>\) u\(的取值范围为\)0 < u leq 1 \(。对于同样的训练集学习效果,较小的\) u$意味着我们需要更多的弱学习器的迭代次数。通常我们用步长和迭代最大次数一起来决定算法的拟合效果。
(2). 通过子采样比例(subsample)。取值为(0,1]。注意这里的子采样和随机森林不一样,随机森林使用的是放回抽样,而这里是不放回抽样。如果取值为1,则全部样本都使用,等于没有使用子采样。如果取值小于1,则只有一部分样本会去做GBDT的决策树拟合。选择小于1的比例可以减少方差,即防止过拟合,但是会增加样本拟合的偏差,因此取值不能太低。推荐在[0.5, 0.8]之间。使用了子采样的GBDT有时也称作随机梯度提升树(Stochastic Gradient Boosting Tree, SGBT)。由于使用了子采样,程序可以通过采样分发到不同的任务去做boosting的迭代过程,最后形成新树,从而减少弱学习器难以并行学习的弱点。
(3). 对于弱学习器即CART回归树进行正则化剪枝。具体可参看决策树算法原理。
6.GBDT优缺点
优点:
1.可以灵活处理各种类型的数据,包括连续值和离散值;
2.相对于SVM来说,较少的调参可以达到较好的预测效果;

3.使用健壮的损失函数时,模型鲁棒性非常强,受异常值影响小。
缺点:
1. 由于弱学习器之间存在依赖关系,难以并行训练数据。不过可以通过自采样的SGBT来达到部分并行。
参考文章:
https://blog.csdn.net/_/article/details/
https://blog.csdn.net/zpalyq110/article/details/
https://www.cnblogs.com/pinard/p/6140514.html
https://zhuanlan.zhihu.com/p/
https://www.jianshu.com/p/ba00d9
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/150665.html