
IPv6(Internet Protocol Version 6)是网络层协议的第二代标准协议,也被称为IPng(IP Next Generation)。它是IETF(Internet工程任务组)设计的一套规范,是IPv4(Internet Protocol Version 4)的升级版本。IPv6和IPv4之间最显著的区别就是IP地址长度从原来的32位升级为128位。
以IPv4为核心技术的Internet获得巨大成功,促使IP技术得到广泛应用。然而,随着因特网的迅猛发展,IPv4设计的不足也日益明显,主要有以下几点:
- IPv4地址空间不足
IPv4地址采用32比特标识,理论上能够提供的地址数量是43亿。但由于地址分配的原因,实际可使用的数量不到43亿。另外,IPv4地址的分配也很不均衡:美国占全球地址空间的一半左右,而欧洲则相对匮乏;亚太地区则更加匮乏。与此同时,移动IP和宽带技术的发展需要更多的IP地址。IPv4地址资源紧张直接限制了IP技术应用的进一步发展。
针对IPv4的地址短缺问题,也曾先后出现过几种解决方案。比较有代表性的是CIDR(Classless Inter-Domain Routing)和NAT(IP Network Address Translator)。但是CIDR和NAT都有各自的弊端和不能解决的问题,由此推动了IPv6的发展。
- 骨干路由器维护的路由表表项数量过大
由于IPv4发展初期的分配规划问题,造成许多IPv4地址分配不连续,不能有效聚合路由。日益庞大的路由表耗用较多内存,对设备成本和转发效率产生影响,这一问题促使设备制造商不断升级其路由器产品,以提高路由寻址和转发性能。
- 不易进行自动配置和重新编址
由于IPv4地址只有32比特,并且地址分配不均衡,导致在网络扩容或重新部署时,经常需要重新分配IP地址。因此需要能够进行自动配置和重新编址以减少维护工作量。
- 不能解决日益突出的安全问题
随着因特网的发展,安全问题越来越突出。IPv4协议制定时并没有仔细针对安全性进行设计,因此固有的框架结构并不能支持端到端的安全。IPv6将IPSec作为它的 标准扩展头实现,可以提供端到端的安全特性。
IPv6技术从根本上解决了IP地址短缺的问题;且易于部署,能够兼容当前的各种应用,方便用户的平滑过渡;同时可实现与IPv4网络的共存和互通。由于IPv4存在以上种种弊端和不足,IPv6技术的优越性显而易见,因此IPv6技术得以迅猛发展。
IPv6特性的相关规格如下:
- 支持IPv6重定向报文。
- 支持IPv6基本报文头和扩展报文头。
- 支持发送差错和信息ICMPv6报文。
- 支持ICMPv6校验和。
- 支持自动/手动配置Link-Local地址。
- 支持动态PMTU表项老化。
- 支持基本和高级ACL6。
- 支持基于IPv6地址的Ping、Tracert和Telnet。
- 支持IPv6 over IPv4隧道。
- 支持IPv4 over IPv6隧道。
- 支持6RD隧道。
- 支持DS-Lite特性。
- 支持NAT64特性。
IPv6的128位IP地址有以下两种表示形式。
- X:X:X:X:X:X:X:X
在这种形式中,128位的IPv6地址被分为8组,每组的16位用4个十六进制字符(0~9,A~F)来表示,组和组之间用冒号(:)隔开。其中每个“X”代表一组十六进制数值。比如下面这个IPv6地址:
2031:0000:130F:0000:0000:09C0:876A:130B
为了书写方便,每组中的前导“0”都可以省略,所以上述地址可写为:
2031:0:130F:0:0:9C0:876A:130B。
另外,地址中包含的连续两个或多个均为0的组,可以用双冒号“::”来代替,这样可以压缩IPv6地址书写时的长度,所以上述地址又可以进一步简写为:
2031:0:130F::9C0:876A:130B。
- X:X:X:X:X:X:d.d.d.d
分为如下两种类型:
- IPv4兼容IPv6地址。地址格式为:0:0:0:0:0:0:IPv4-address,其高阶96bits均为0,其低阶32bits是一个IPv4地址。该IPv4地址必须是IPv4网络中可达的IPv4地址,且不能是组播地址、广播地址、环回地址或未指定的地址(0.0.0.0)。
- IPv4映射IPv6地址。地址格式为:0:0:0:0:0:FFFF:IPv4-address。该地址用来将IPv4节点的地址表示为IPv6地址。
其中IPv4兼容IPv6地址用于配置IPv6 over IPv4隧道。
其中“X”代表高阶的六组数字,用十六进制数来表示每组的16比特。“d”代表低阶的四组数字,用十进制数表示每组的8比特。后边的部分(d.d.d.d)其实就是一个标准的IPv4地址。
一个IPv6地址可以分为如下两部分:
- 网络前缀:n比特,相当于IPv4地址中的网络ID
- 接口标识:128-n比特,相当于IPv4地址中的主机ID
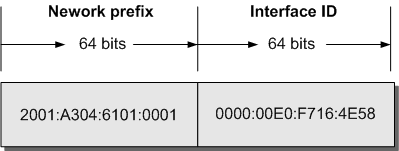
地址2001:A304:6101:1::E0:F726:4E58 /64的构成如下图所示:
IPv6主要有三种类型的地址:单播地址、组播地址和任播地址。
- 单播地址:用来唯一标识一个接口,类似于IPv4的单播地址。发送到单播地址的数据报文将被传送给此地址所标识的接口。
- 组播地址:用来标识一组接口(通常这组接口属于不同的节点),类似于IPv4的组播地址。发送到组播地址的数据报文被传送给此地址所标识的所有接口。
- 任播地址:用来标识一组接口(通常这组接口属于不同的节点)。发送到任播地址的数据报文被传送给此地址所标识的一组接口中距离源节点最近(根据使用的路由协议进行度量)的一个接口。
*说明:IPv6中没有广播地址,广播地址的功能通过组播地址来实现。
IPv6地址类型是由地址前面几位(称为格式前缀)来指定的,主要地址类型与格式前缀的对应关系如表1所示。
表1 IPv6单播地址类型
表中各类地址的意义如下:
IPv6单播地址的类型可有多种,包括全球单播地址、链路本地地址和站点本地地址等。
- 链路本地单播地址:(FE80::/64)
用于邻居发现协议和无状态自动配置进程中链路本地上节点之间的通信。使用链路本地地址作为源或目的地址的数据包不会被转发到其他链路上。使用链路本地前缀FE80::/10(1111 1110 10)和IEEE EUI-64格式的接口标识符(EUI-64可来源于EUI-48)可在任意接口对其进行自动配置。


拥有Link-local地址的节点可以与同一链路(link)上的相邻节点通信
Link-local地址以FE80开头,前缀为FE80::/64
Link-local地址只能在本地链路使用,不能在子网间路由
IPv6协议下,每个网络接口都需要分配一个Link-local地址,即使该接口已经分配了可路由的IPv6地址
- 环回地址:(::1)
环回地址0:0:0:0:0:0:0:1或::1,不会被分配给任何接口。它的作用与在IPv4中的127.0.0.1相同,即节点将IPv6报文发送给自己。
- 未指定地址
地址“::”称为未指定地址,不能被分配给任何节点,也不能作为目的地址。在主机初始化且没有取得自己的地址时,未指定地址可以用在IPv6报文的源地址字段,例如重复地址探测时,NS报文的源地址就是未指定地址。
- 全球单播地址:(2000::/3)
全球单播地址等同于IPv4公网地址。用于可以聚合的链路,最后提供给网络服务提供商。这种地址类型的结构允许路由前缀的聚合,从而满足全球路由表项的数量限制。地址包括48位路由前缀和本地站点管理的16位子网ID,以及64位接口ID。如无特殊说明,全球单播地址包括站点本地单播地址。

全球单播地址地址具有4个字段:
001:Global unicast地址的前缀(2000::/3)
Global Routing ID:站点(Site)路由前缀(相当于IPv4的Network ID),站点可以是一个网络公司
Subnet ID:表示站点内的子网,最多可以有2^16=65536个子网
Interface ID:表示子网内的网络接口(相当于IPv4的Host ID)
- 组播地址
组播地址用来标识属于不同节点的一组接口,类似IPv4的组播地址。发送到组播地址的数据包被传输给此地址所标识的所有接口。
表2所示的组播地址,是预留的特殊用途的组播地址。
表2 预留的IPv6组播地址列表
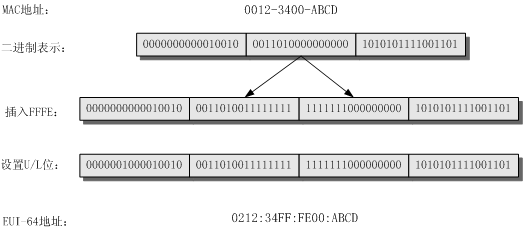
IEEE EUI-64格式的接口标识符
IPv6地址中的64位接口标识符(Interface ID)用来标识链路上的唯一接口。这个地址是从接口的链路层地址(如MAC地址)变化而来的。IPv6地址中的接口标识符是64位,而MAC地址是48位,因此需要在MAC地址的
中间位置插入十六进制数FFFE(1111 1111 1111 1110)。然后将U/L位(从高位开始的第7位)设置为“1”,这样就得到了EUI-64格式的接口ID。具体转换过程如图2。
图2 MAC地址到EUI-64格式接口标识符的转换过程
IPv6报文的头部信息和一般的IP报文(即IPv4报文)有一定差异。
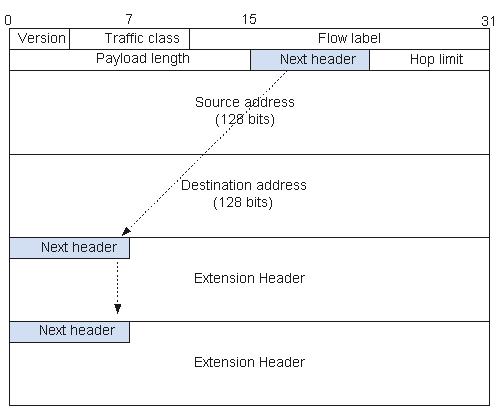
图3所示为IPv6报文头结构。
图3 IPv6报文头格式

- Version(版本):该字段表示IP版本,值为6。
- Traffic class(流量类别):该字段及其功能类似于IPv4的业务类型字段。该字段以区分业务编码点(DSCP)标记一个IPv6数据包,以此指明数据包应当如何处理。
- Flow label(流标签):该字段用来标记IP数据包的一个流,当前的标准中没有定义如何管理和处理流标签的细节。
- Payload length(有效载荷长度):该字段表示有效载荷的长度,有效载荷是指紧跟IPv6基本报头的数据包,包含IPv6扩展报头。
- Next header(下一报头):该字段指明了跟随在IPv6基本报头后的扩展报头的信息类型。如图4所示。
- Hop limit(跳数限制):该字段定义了IPv6数据包所能经过的最大跳数,这个字段和IPv4中的TTL字段非常相似。
- Source address(报文源地址):该字段表示该报文的源地址。
- Destination address(报文目的地址):该字段表示该报文的目的地址。
图4 Next header在IPv6报文头中的作用
IPv6通过将不重要的字段和选项字段移入扩展报头来减小报头的负载,使中间路由设备对报文的处理更有效。
尽管IPv6地址长度是IPv4地址长度的四倍,但IPv6基本报头的长度只有IPv4报头的两倍。
IPv4和IPv6报头不具有互操作性,而且IPv6协议不能向后兼容IPv4协议。为了识别和处理两种报头格式,主机或路由设备必须同时运行IPv4和IPv6两种协议。
图5 IPv4和IPv6报文头格式比较
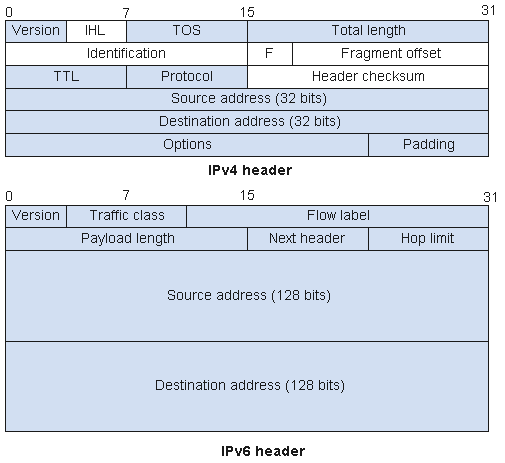
通过将IPv4报文头中的某些字段裁减或移入到扩展报文头,减小了IPv6基本报文头的长度。IPv6使用固定长度的基本报文头,从而简化了转发设备对IPv6报文的处理,提高了转发效率。尽管IPv6地址长度是IPv4地址长度的四倍,但IPv6基本报文头的长度只有40字节,为IPv4报文头长度(不包括选项字段)的两倍。
IPv6的源地址与目的地址长度都是128比特(16字节)。它可以提供超过3.4×1038种可能的地址空间,完全可以满足多层次的地址划分需要,以及公有网络和机构内部私有网络的地址分配。
IPv6的地址空间采用了层次化的地址结构,利于路由快速查找,同时借助路由聚合,可减少IPv6路由表的大小,提高路由设备的转发效率。
为了简化主机配置,IPv6支持有状态地址配置(Stateful Address Autoconfiguration)和无状态地址配置(Stateless Address Autoconfiguration)。
- 对于有状态地址配置,主机通过服务器获取地址信息和配置信息。
- 对于无状态地址配置,主机自动配置地址信息,地址中带有本地路由设备通告的前缀和主机的接口标识。如果链路上没有路由设备,主机只能自动配置链路本地地址,实现与本地节点的互通。
IPv6报头的新字段定义了流量应该被如何标识和处理。通过报文头里的流标签(Flow Label)字段完成流量标识,允许路由设备对某一流中的报文进行识别并提供特殊处理。
由于IPv6报头可对流量进行识别,
即使是带有IPSec加密的报文载荷也可对其QoS进行保证。
IPv6将IPSec作为它的扩展报头实现,提供端到端的安全特性。这一特性为解决网络安全问题提供了标准,并提高了不同IPv6实现的互操作性。
IPv4报头只能支持40字节的选项,而IPv6扩展报头的大小只受到IPv6报文大小的限制。
IPv6取消了IPv4报头中的选项字段,并引入了多种扩展报文头,在提高处理效率的同时还增强了IPv6的灵活性,为IP协议提供了良好的扩展能力。如图6所示。
图6 IPv6扩展报文头
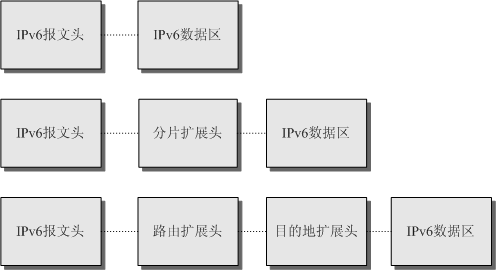
当超过一种扩展报头被用在同一个分组里时,报头必须按照下列顺序出现:
- IPv6基本报头
- 逐跳选项扩展报头
- 目的选项扩展报头
- 路由扩展报头
- 分片扩展报头
- 授权扩展报头
- 封装安全有效载荷扩展报头
- 目的选项扩展报头(指那些将被分组报文的最终目的地处理的选项)
- 上层扩展报头
不是所有的扩展报头都需要被转发路由设备查看和处理的。路由设备转发时根据基本报头中Next Header值来决定是否要处理扩展头。
除了目的选项扩展报头出现两次(一次在路由扩展报头之前,另一次在上层扩展报头之前),其余扩展报头只出现一次。
IPv6的邻居发现协议是通过一组ICMPv6(Internet Control Message Protocol for IPv6,IPv6的因特网控制报文协议)消息实现的,管理着邻居节点间(即同一链路上的节点)信息的交互。它代替了ARP(Address Resolution Protocol,地址解析协议)、ICMPv4路由器发现和ICMPv4重定向消息,并提供了一系列其他功能。
ICMPv6(Internet Control Message Protocol for the Internet Protocol Version 6)是IPv6的基础协议之一,具有差错报文和信息报文两种,用于IPv6节点报告报文处理过程中的错误和信息。
ICMPv6报文的报文格式如图7所示
图7 ICMPv6报文格式
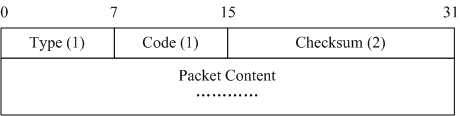
报文中各个字段的解释如下:
- Type字段表明消息的类型,0至127位表示差错报文类型,128至255位表示消息报文类型。
- Code字段表示此消息类型细分的类型。
- Checksum表示ICMPv6报文的校验和。
- 目的不可达错误报文
在IPv6节点转发IPv6报文过程中,发现目的地址不可达时,就会向发送报文的源节点发送ICMPv6目的不可达错误报文。同时报文中会携带引起该错误报文的具体原因。目的不可达错误报文又细分为以下几种:
- 没有到目的地的路由
- 地址不可达
- 端口不可达
- 数据包过大错误报文
在IPv6节点转发IPv6报文过程中,发现报文超过出接口的链路MTU时,则向发送报文的源节点发送ICMPv6数据包过大错误报文,其中携带出接口的链路MTU值。数据包过大错误报文是Path MTU发现机制的基础。
- 时间超时错误报文
在IPv6报文收发过程中,当路由器收到Hop Limit值等于0的数据包,或者当路由器将HopLimit值减为0时,会向报文的源节点发送ICMPv6超时错误报文。对于分段重组报文的操作,如果超过定时时间,也会产生一个ICMPv6超时报文。
- 参数错误报文
当目的节点收到一个IPv6报文时,会对报文进行有效性检查,如果发现以下问题会向报文的源节点回应一个ICMPv6参数错误差错报文。
- IPv6基本头或扩展头的某个域有错误
- IPv6基本头或扩展头的NextHeader值不可识别
- 扩展头中出现未知的选项
请求信息(Echo Request)和应答信息(Echo Reply)。可以利用ICMPv6报文实现网络故障诊断、PMTU发现和邻居发现等功能。在两节点的互通性检测中,收到Echo Request报文的节点向源节点回应Echo Reply报文,实现两节点间报文的收发。
根据应用目的,可将ACL6分为两种:
- 基本ACL6,基本ACL6只能使用源地址信息做为定义ACL6规则的元素。
- 高级ACL6,高级ACL6可以使用数据包的源地址信息、目的地址信息、IP承载的协议类型、针对协议的特性定义规则,例如TCP的源端口、目的端口,ICMPv6协议的类型、ICMPv6 Code等。可以利用高级ACL6定义比基本ACL6更准确、更丰富、更灵活的规则。
一个ACL中可以包含多个规则,而每个规则都指定不同的报文匹配选项,这些规则可能存在重复或矛盾的地方,在将一个报文和ACL的规则进行匹配的时候,到底采用哪些规则呢?就需要确定规则的匹配顺序。
ACL6支持两种匹配顺序:
- 配置顺序:按照用户配置规则的先后顺序进行规则匹配。
- 自动排序:按照“深度优先”的顺序进行规则匹配。
-基本ACL6的“深度优先”顺序判断原则如下

- 先比较源IPv6地址范围,源IPv6地址范围小(前缀长)的规则优先。
- 如果源IPv6地址范围相同,则先配置的规则优先。
-高级ACL6的“深度优先”顺序判断原则如下

- 先比较协议范围,指定了IPv6协议承载的协议类型的规则优先。
- 如果协议范围相同,则比较源IPv6地址范围,源IPv6地址范围小(前缀长)的规则优先。
- 如果协议范围、源IPv6地址范围相同,则比较目的IPv6地址范围,目的IPv6地址范围小(前缀长)的规则优先。
- 如果协议范围、源IPv6地址范围、目的IPv6地址范围相同,则比较四层端口号(TCP/UDP端口号)范围,四层端口号范围小的规则优先。
- 如果上述范围都相同,则先配置的规则优先。
在报文匹配规则时,会按照匹配顺序去匹配定义的规则,一旦有一条规则被匹配,报文就不再继续匹配其它规则了,设备将对该报文执行第一次匹配的规则指定的动作。
配置USG9000的ACL6时,可以为一个ACL6规则组指定一个“步长”。步长的含义是:自动为ACL6子规则分配编号的时候,每个ACL6规则组的子规则编号之间的差值。ACL6规则组的步长固定为1,且不能通过step命令改变步长。
邻居发现ND(Neighbor Discovery)是确定邻居节点之间关系的一组消息和进程。邻居发现协议替代了IPv4的ARP(Address Resolution Protocol)、ICMP路由器发现(Router Discovery)和ICMP重定向(Redirect)消息,并提供了其他功能。
对于一个节点而言,当其配置一个IPv6地址之后,首先会确定此地址是否可用、不冲突。当一个节点是主机时,路由器需要通知主机向特定目的地址转发报文的理想下一跳地址;当一个节点是路由器时,需要发布自己的地址、地址前缀和其他配置参数以指导主机进行参数配置。在IPv6报文转发过程中,节点需要确定邻居节点的链路层地址和其可达性。IPv6邻居发现机制提供了5种不同类型的ICMPv6报文。
- 路由器请求报文RS(Router Solicitation):主机启动后,通过RS报文向路由设备发出请求,路由设备则会以RA报文响应。
- 路由器通告报文RA(Router Advertisement):路由设备周期性的发布RA报文,其中包括前缀和一些标志位的信息。
- 邻居请求报文NS(Neighbor Solicitation):IPv6节点通过NS报文可以得到邻居的链路层地址,检查邻居是否可达,也可以进行重复地址检测。
- 邻居通告报文NA(Neighbor Advertisement):NA报文是IPv6节点对NS报文的响应,同时IPv6节点在链路层变化时也可以主动发送NA报文。
- 重定向报文(Redirect):路由设备发现报文的入接口和出接口相同时,可以通过重定向报文通知主机选择另外一个更好的下一跳地址。
IPv6 邻居发现协议主要包括以下功能:
地址冲突检测DAD(Duplicate address detect)是确定IPv6地址是否可用的一种探测机制。具体执行过程如下:
- 当一个节点配置了IPv6地址,为了查看该地址是否被其他邻居节点所使用,会即时发送邻居请求报文来确定其可用性。
- 当其他邻居节点收到该报文后会查找本地的IPv6地址中是否存在相同的IPv6地址,若存在会回应一个邻居通告报文给源节点,并携带此IPv6地址信息。
- 源节点收到邻居的回应报文则认为该IPv6地址已被邻居使用。反之,如果源节点发出的邻居请求报文没有收到相应的回应报文,则表示配置的IPv6地址是可用的。
邻居发现功能和IPv4中的ARP功能类似,主要实现对邻居地址的解析和邻居可达性的探测,依赖于邻居请求和邻居通告报文完成。
当一个节点需要得到同一本地链路上另外一个节点的链路层地址时,就会发送ICMPv6类型为135的邻居请求报文。此报文类似于IPv4中的ARP请求报文,不过使用组播地址而不使用广播地址,只有被请求节点的最后24比特和此组播地址相同的节点才会收到此报文,减少了广播风暴的可能。目的节点在响应报文中填充其链路层地址。
邻居请求报文也用来在邻居的链路层地址已知时,验证邻居的可达性。IPv6邻居通告报文是对IPv6邻居请求报文的响应。收到邻居请求报文后,目的节点通过在本地链路上发送ICMPv6类型为136的邻居通告报文进行响应。收到邻居通告后,源节点和目的节点可以进行通信。当一个节点的本地链路上的链路层地址改变时也会主动发送邻居通告报文。
图8所示为IPv6邻居发现过程。
图8 IPv6邻居发现过程
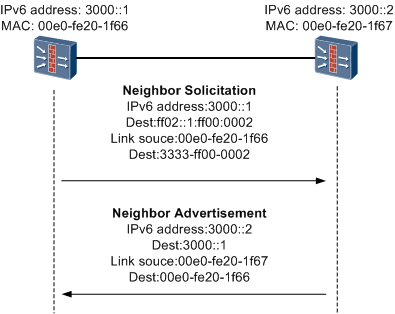
路由器发现功能用来定位邻居路由设备,同时学习和地址自动配置有关的前缀和配置参数。IPv6路由发现由下面两种机制实现:
- 路由器请求
当主机没有配置单播地址时(例如系统刚启动),就会发送路由器请求报文RS。路由器请求报文有助于主机迅速进行自动配置而不必等待IPv6路由设备的周期性路由器通告报文。IPv6路由器请求也是ICMPv6报文,类型为133。
- 路由器通告
每个IPv6路由设备的接口在配置了IPv6 RA去抑制的前提下会周期发送路由器通告报文。在本地链路上收到IPv6节点的路由器请求报文后,路由设备也会回应路由器通告报文。IPv6路由器通告报文发送到所有节点多播地址(FF02::1)或发送路由器请求报文节点的IPv6单播地址。路由器通告为ICMPv6报文,类型为134,包含以下内容:
- 是否使用地址自动配置
- 标记支持的自动配置类型(无状态或有状态自动配置)
- 一个或多个本地链路前缀(本地链路上的节点可以使用这些前缀完成地址自动配置)
- 通告的本地链路前缀的生存期
- 发送路由器通告的路由设备是否可作为缺省路由设备,如果可以,还包括此路由设备可作为缺省路由设备的时间(用秒表示)
- 和主机相关的其它信息,如跳数限制、主机发起的报文可以使用的最大MTU
本地链路上的IPv6节点接收路由器通告报文,并用其中的信息得到更新的缺省路由设备、前缀列表以及其它配置。
通过使用路由器通告报文和针对每一前缀的标记,路由设备可以通知主机如何进行地址自动配置。例如,路由设备可以指定主机是使用有状态(DHCPv6)地址配置还是无状态地址自动配置进行地址配置。
对于无状态地址自动配置而言,当主机收到路由器通告报文后,使用其中的前缀信息和本地接口ID自动形成IPv6地址,同时还可以根据其中的默认路由设备信息设置默认路由设备。
重定向报文用来通知主机去往目的地的理想下一跳IPv6地址。和IPv4类似,IPv6路由设备发送重定向报文的目的仅限于把报文重新路由到更合适的路由设备。收到重定向报文的节点随后会把后续报文发送到更合适的路由设备。路由设备只针对单播流发送重定向报文,重定向报文只发送给引起重定向的报文的节点(主机),并被处理。
由于IPv6报文在传输过程中不允许在中间节点分片转发,所以在转发过程中经常会出现报文长度大于路径IPv6 MTU的情形,这就需要源节点不断的进行重传,降低了传输的效率,如果在源节点使用最小链接IPv6 MTU(1280)作为分片的最大长度,在大多数情况下,路径的IPv6 MTU是大于最小链接的IPv6 MTU的,一个节点发出的分片远小于路径IPv6 MTU,这是对网络资源的一种浪费,为了解决这个问题,提出了路径MTU发现协议。
Path MTU(以下简称PMTU),是确定从源端到目的端路径上合适的IPv6 MTU值的一种机制。PMTU发现协议描述了一种动态发现任意路径的PMTU的方法。当一个IPv6节点发送大量数据到另一节点时,数据通过一系列IPv6分片传送。当这些分片具有从源节点到信宿节点能够成功传送所允许的最大长度时,我们认为它达到理想状态,这个分片长度被称为路径MTU。
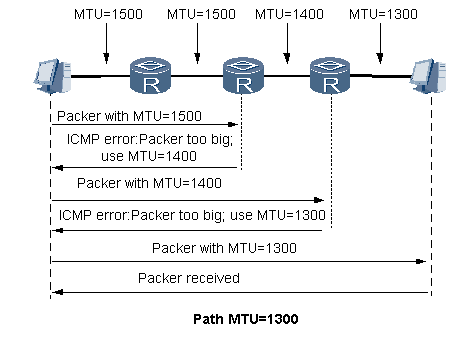
一个源节点开始会假设一个路径的PMTU是路径中第一跳的已知的IPv6 MTU,如果从那个路径发出的报文太大以至于不能沿着路径转发,中间节点将丢弃此报文并返回一个ICMPv6数据过大差错报文给源节点,根据数据过大消息中的IPv6 MTU值来设置此路径的PMTU值。
当节点学习到的PMTU值小于或者等于实际的PMTU时,PMTU的发现过程结束。注意在PMTU发现过程结束之前,可能会出现反复发送报文和收到报文太大消息,这是因为可能会不断发现更远的路径链路有更小的IPv6 MTU。
如图9所示,PMTU发现的工作过程是:源端主机先使用自己的MTU值向目的主机发送报文,如果中间路由设备给源端返回一个错误消息,其中包括该网络的MTU值,源端主机使用该MTU值来重新发送这个报文,如此反复,直到目的端主机收到这个报文,从而确定网络中两台主机之间能够处理的最大报文的大小。
图9PMTU发现的工作过程
对于IPv6节点来说,兼容IPv4的最直接有效的办法就是保留一个完整的IPv4协议栈,这样的节点即为双协议栈节点。单协议栈和双协议栈结构示例如图10所示。
图10 单协议栈与双协议栈结构(以太网)
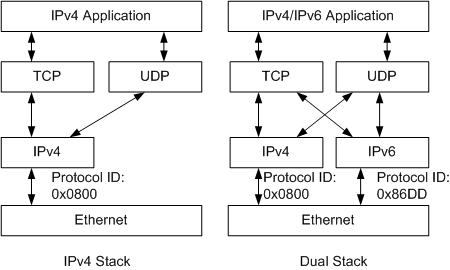
双协议栈具有以下特点:
- 多种链路协议支持双协议栈
多种链路协议(如以太网)支持双协议栈。图中的链路层是以太网,在以太网帧上,如果协议类型字段的值为0x0800,表示网络层是IPv4报文,如果为0x86DD,表示网络层是IPv6报文。
- 多种应用支持双协议栈
多种应用(如DNS/FTP/Telnet等)支持双协议栈。上层应用(如DNS)可以选用TCP或UDP作为传输层的协议,但优先选择IPv6协议栈,而不是IPv4协议栈作为网络层协议。
在IPv4网络向IPv6网络过渡的初期,IPv4网络已被大量部署,而IPv6网络只是散步在世界各地的一些孤岛。利用隧道技术可以在IPv4网络上创建隧道,从而实现IPv6孤岛之间的互连。在IPv4网络上用于连接IPv6孤岛的隧道称为IPv6 over IPv4隧道。为了实现IPv6 over IPv4隧道,需要在IPv4网络与IPv6网络交界的边界路由设备上启动IPv4/IPv6双协议栈。
IPv6 over IPv4隧道技术的原理如图11所示。
1.启动IPv4/IPv6双协议栈
边界路由设备启动IPv4/IPv6双协议栈。
2.封装IPv6报文
边界路由设备在收到从IPv6网络侧来的报文后,根据路由表判定该报文要通过隧道进行转发,就把收到的IPv6报文作为负载,加上IPv4报文头,封装到IPv4报文里。
3.传递封装后的报文
在IPv4网络中,封装后的报文被传递到对端的边界路由设备上。
4.对报文解封装
对端边界路由设备对报文解封装,去掉IPv4报文头,然后将解封装后的IPv6报文转发到对端的IPv6网络中。
图11IPv6 over IPv4隧道原理图
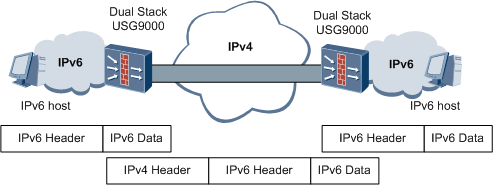
在两个边界路由设备之间用来传递IPv6报文的虚拟的通道就是IPv6 over IPv4隧道。根据创建隧道的方式,可以对隧道进行分类。目前,常用的IPv6 over IPv4隧道模式有以下几种。
- IPv6 over IPv4手动隧道
- IPv6 over IPv4 GRE隧道(简称GRE隧道)
- IPv6 over IPv4自动隧道(简称自动隧道)
- 6to4隧道
- ISATAP隧道
IPv6 over IPv4手动隧道是在隧道两端的边界路由设备上通过人工配置而创建的。它需要静态指定隧道的源IPv4地址和目的IPv4地址。
手动隧道相当于通过IPv4骨干网连接的两个IPv6域的永久链路,是边界路由设备之间进行定期安全通信的固定通道。
手动隧道可用于IPv6孤岛之间的通信,也可在边界路由设备与主机之间配置。隧道两端的主机和路由设备均需支持IPv4和IPv6协议栈。
使用IPv4的GRE(Generic Routing Encapsulation)隧道也可以承载IPv6报文,此时的GRE隧道称为IPv6 over IPv4 GRE隧道。与IPv6 over IPv4手动隧道相同,GRE隧道也是两点之间的链路,每条链路都是一条单独的隧道。GRE隧道不与特定的乘客或传输协议绑定,只把IPv6作为乘客协议,把GRE作为承载协议。
GRE隧道也是在隧道两端的边界路由设备上通过人工配置而创建的,也需要静态指定隧道的源IPv4地址和目的IPv4地址。与手动隧道不同的是,GRE隧道为了增强隧道的安全性,可以设置对GRE报文头进行校验以及对隧道的关键字进行验证。
GRE隧道可用于边界路由设备之间,或者用于边界路由设备与主机系统之间。隧道两端的主机和路由设备均需支持IPv4和IPv6协议栈。
有关GRE配置的详细介绍请参见《配置指南 VPN分册》。
要创建IPv6 over IPv4自动隧道,需要使用一类特殊的IPv6地址,即兼容IPv4的IPv6地址。兼容IPv4的IPv6地址格式为:
0:0:0:0:0:0:IPv4-address
其高阶96bits均为0,其低阶32bits是一个IPv4地址。该IPv4地址必须是IPv4网络中可达的IPv4地址,且不能是组播地址、广播地址、环回地址或未指定的地址(0.0.0.0)。
在配置自动隧道时,只需要在边界路由设备或主机上指定隧道源地址,不需要指定隧道的目的地址。隧道目的地址是从原始的IPv6报文的目的地址中获取的。
IPv6 over IPv4自动隧道通常用于孤立的IPv4/IPv6双协议栈主机需要穿过IPv4网络访问远端IPv6网络的情况。在孤立的IPv4/IPv6主机和IPv4/IPv6路由设备之间需要配置自动隧道。
在建立自动隧道时,需要隧道两端都要配置兼容IPv4的IPv6地址,兼容IPv4的IPv6地址又依赖于隧道的物理接口的IPv4地址,受到IPv4地址短缺的限制,因而有一定的局限性。
6to4隧道也是一种将多个IPv6孤岛通过IPv4网络互连的机制。6to4隧道可在孤立的IPv6网络和IPv4网络之间的边界路由设备上配置。6to4隧道两端的边界路由设备必须同时支持IPv4和IPv6双协议栈。
6to4隧道与手动配置隧道的主要区别在于:6to4隧道可以是点到多点的连接,而手动隧道仅是点到点的连接。所以6to4隧道的路由设备并不是成对配置的。
6to4隧道与自动隧道类似,它可自动查找隧道的另一端点,但它不需要指定兼容IPv4的IPv6地址。
6to4隧道使用了一种特殊的IPv6地址,即6to4地址,其格式为:
2002:IPv4地址:子网ID:接口ID
6to4地址的前缀是2002:IPv4地址,前缀长度为48bits。其中IPv4地址是为IPv6孤岛申请的一个全球唯一的IPv4地址。在IPv6/IPv4边界路由设备与IPv4网络链接的物理接口上必须配置该IPv4地址。子网ID的长度为16bits,接口ID的长度为64bits,均由用户在IPv6孤岛内分配。
如图12所示,Site1和Site2均为6to4网络,6to4网络内的主机和路由设备被分配了6to4地址。Site1内的主机和路由设备的6to4地址内嵌入的IPv4地址就是USG9000_A到IPv4网络接口的IPv4地址。Site2内的主机和路由设备的6to4地址内嵌入的IPv4地址就是USG9000_B到IPv4网络接口的IPv4地址。USG9000_A和USG9000_B均为6to4路由设备。
图12 6to4隧道和6to4中继
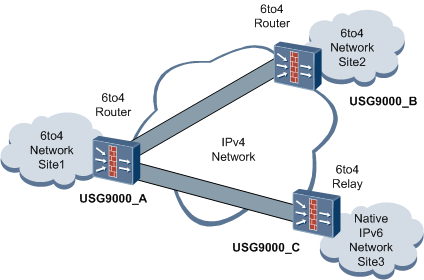
Site1内的主机要访问Site2内的主机时,其工作原理如下:
1.IPv6报文被传送到USG9000_A;
2.USG9000_A检查IPv6报文的目的地址,发现是6to4地址,从该6to4地址中获得6to4隧道对端的IPv4地址;
3.USG9000_A将该IPv6报文封装到IPv4报文中,IPv4报文头的目的地址就是隧道对端的IPv4地址,源地址就是隧道本端的IPv4地址;
4.USG9000_A将该IPv4报文通过IPv4网络转发到USG9000_B;
5.USG9000_B进行解封装操作,获得原来的IPv6报文,然后将该IPv6报文在Site2内被送到目的主机。
上面介绍的过程可以实现6to4网络之间的通信。为了实现6to4网络与本真(Native)IPv6网络之间的通信,就需要6to4中继路由设备了。所谓本真IPv6网络,就是它内部的主机或路由设备均不配置6to4地址。
6to4中继路由设备是6to4网络与本真IPv6网络之间的网关。6to4中继路由设备的一侧连接本真IPv6网络,其另一侧连接IPv4网络,并与6to4路由设备建立6to4隧道。如图12所示,6to4网络内的主机要访问IPv6 Internet时,其工作过程如下。
1.IPv6报文被传送到USG9000_A;
2.USG9000_A检查IPv6报文的目的地址,发现是本真(Native)IPv6网络地址。通过查找路由表,下一跳是指向6to4隧道,从6to4隧道地址中获取要封装的IPv4目的地址;
3.USG9000_A将该IPv6报文封装到IPv4报文中,IPv4报文头的目的地址就是隧道对端的IPv4地址,源地址就是隧道本端的IPv4地址;
4.USG9000_A将该IPv4报文通过IPv4网络转发到USG9000_C;
5.USG9000_C进行解封装操作,获得原来的IPv6报文,然后将该IPv6报文送到Site3内的目的主机。
6RD(IPv6 Rapid Deployment)隧道技术是一种在已有的IPv4网络基础上,为用户提供IPv6接入服务的快速部署的技术。6RD隧道技术是对原有6to4方案的改进,主要区别在于6to4定义的地址格式中使用知名的2002::/16前缀,而6RD的地址前缀则是可以由企业从自己的IPv6地址空间中划分得到的。
6RD隧道技术主要是满足IPv6用户发送报文穿越IPv4网络,访问IPv6服务和资源的问题,其核心思想是通过在CE(Customer Edge)与CE或者CE与网关之间自动建立、拆解隧道,实现IPv6报文跨越IPv4的网络。而自动隧道的建立是依靠预先定义的6RD前缀完成的。
6RD地址格式包括:6RD前缀、IPv4地址、子网ID和接口标识符。如图13所示
图13 6RD地址格式
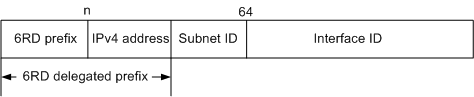
6RD委托前缀(6RD delegated prefix)包含6RD前缀和部分或全部IPv4地址,由两部分内容计算得出6RD委托前缀值。其中6RD委托前缀中IPv4地址的长度取决于6RD隧道中配置的IPv4前缀长度。
如图14所示,6RD隧道具体业务处理流程如下:
图14 6RD隧道
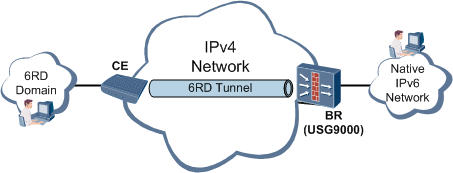
- 当CE接收到来自IPv6终端发送的报文时,将IPv6报文封装到IPv4隧道中,发送至6RD Border Relay,隧道外层源地址为CE的IPv4地址,目的地址为6RD Border Relay的IPv4地址;
- 6RD Borer Relay将收到的IPv4隧道报文解封装,然后将IPv6报文进行转发。
ISATAP(Intra-site Automatic Tunnel Addressing Protocol)隧道用于IPv4网络中的IPv4/IPv6主机访问IPv6网络的情况,可以在ISATAP主机与ISATAP路由设备之间建立ISATAP隧道。
建立ISATAP隧道时,需要使用ISATAP格式地址,其结构如下:
Prefix(64bit)::5EFE:IPv4-Address
在创建ISATAP隧道时,由于IPv4/IPv6主机和ISATAP路由设备在同一个IPv4网络里,ISATAP地址中嵌入的IPv4地址可以是公网地址,也可以是私网地址。
如图15所示,IPv4/IPv6主机获得IPv6地址的过程如下:
- IPv4/IPv6主机发送路由设备请求消息
IPv4/IPv6主机使用ISATAP格式的链路本地地址向ISATAP路由设备发送路由设备请求消息,该路由设备请求消息被封装在IPv4报文中。
- ISATAP路由设备响应请求
ISATAP路由设备使用路由设备通告消息响应主机的路由设备请求。路由设备通告消息中包含ISATAP前缀(ISATAP前缀在路由设备上通过人工配置)。
- IPv4/IPv6主机得到自己的IPv6地址
IPv4/IPv6主机将ISATAP前缀与
5EFE:IPv4-Address组合得到自己的IPv6地址,并用此地址访问IPv6主机。
图15 ISATAP隧道
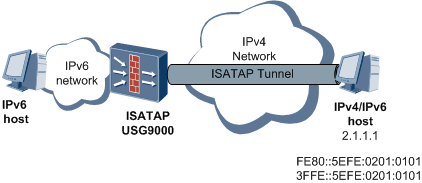
IPv4/IPv6主机要访问IPv6 Internet时,其工作原理如下。
1.IPv4网络中的IPv4/IPv6主机按照上面的过程获得自己的IPv6地址。
2.IPv4/IPv6主机发送访问IPv6网络的IPv6主机的报文,该报文封装在IPv4中。
3.ISATAP路由设备接收该IPv4报文后执行解封装操作,将其中的IPv6报文发送到IPv6网络中的IPv6主机。
在IPv4 Internet向IPv6 Internet过渡的后期,IPv6网络已被大量部署,此时可能出现IPv4孤岛。利用隧道技术可在IPv6网络上创建隧道,从而实现IPv4孤岛的互连。这类似于在IP网络上利用隧道技术部署VPN。在IPv6网络上用于连接IPv4孤岛的隧道,称为IPv4 over IPv6隧道。
图16 IPv4 over IPv6隧道组网图
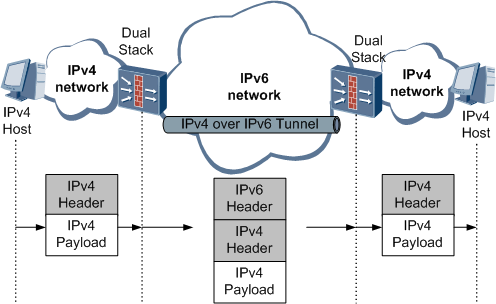
Pv4 over IPv6隧道技术的原理如图16所示。
1.启动IPv4/IPv6双协议栈
边界路由设备启动IPv4/IPv6双协议栈。
2.封装IPv6报文
边界路由设备在收到从IPv4网络侧来的报文后,如果报文的目的地不是自身,就把收到的IPv4报文作为净荷,加上IPv6报文首部,封装到IPv6报文里。
3.传递封装后的报文
在IPv6网络中,封装后的报文被传递到对端的边界路由设备。
4.对报文解封装
对端边界路由设备对报文解封装,去掉IPv6报文首部,然后将解封装后的IPv4报文转发到IPv4网络中。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/149569.html