
前提:1虚拟机工作环境 2镜像文件准备好 3基础网络配置
安装虚拟机: 1创建虚拟机--挂载镜像 2开机【直接进入bios的开机方式】 3鼠标选择配置
4重启主机看效果
步骤:将前提准备好打开虚拟机【点击创建新的虚拟机】1选择典型安装或者自定义都可以
2点击安装程序光盘映像文件
3下一步选择Linux客户机操作系统“版本选择不重要选哪个都可以”
4命名虚拟机及选择安装位置
5磁盘空间200G的单个文件 完成开机!!!!
进入系统之后会有选择按照自己的需要配置。
加*是重点命令需要熟练使用
2.1.1设置root密码
Ubuntu系统可能没有root超级用户面对这样的情况就得创建root用户并设置root用户密码
sudo passwd root设置root用户密码
[sudo] password for ubuntu:这里输入当前普通用户密码
New password:这里输入想要设置的root用户密码
Retype new password:再次确认密码
2.1.2 linux登陆方式
linux是一个多任务,多用户的开源客户端可以用命令行登录和图像化登录,也可以用虚拟终端登录
在linux里面有两类用户一个是超级用户,一个是普通用户。管理员用户是有权限的普通用户
管理员角色是一个用户组 超级用户root 普通用户是自己装机时创建的用户
0-999是特殊用户
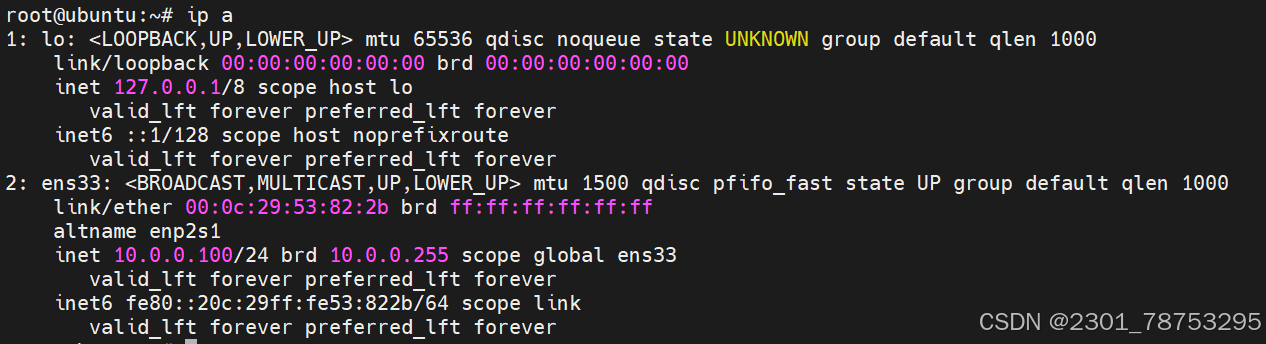
查看当前主机的ip地址
ip a
讯享网
2.1.3 whoami 查看当前系统用户是谁
whoami 查看当前用户是谁
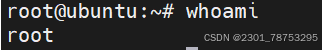
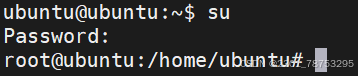
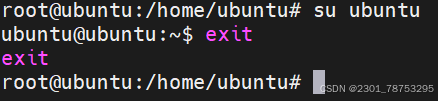
2.1.4 su 切换用户
su 切换用户
参数:
- 不带上一个用户的记忆切换
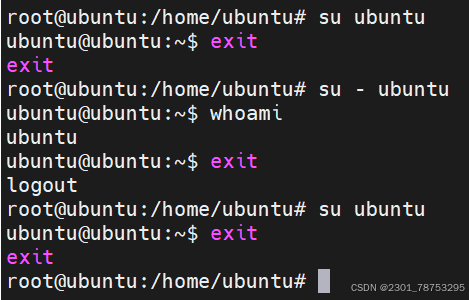
2.1.5 exit 退出
exit 退出

2.1.6 tty 查看当前所在终端
tty 查看当前所在进程

2.1.7 shell 命令解释器
我理解为翻译官将我们打的命令解释给操作系统 shell存在两种操作方式命令行和脚本文件。
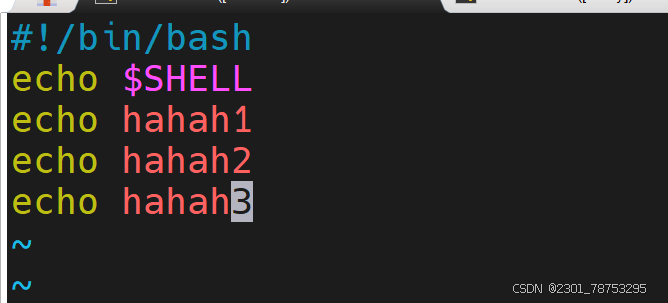
脚本命令中第一行是命令解释器#!/bin/bash 其他的是可以成功执行的命令
root@ubuntu:~# vim a.sh 编辑一个a.sh的文件
root@ubuntu:~# cat a.sh 查看a.sh
#!/bin/bash
echo $SHELL
echo hahah1
echo hahah2
echo hahah3
root@ubuntu:~# /bin/bash a.sh 用/bin/bash命令解释器运行a.sh文件
/bin/bash
hahah1
hahah2
hahah3
echo $SHELL 查看当前系统的shell类型

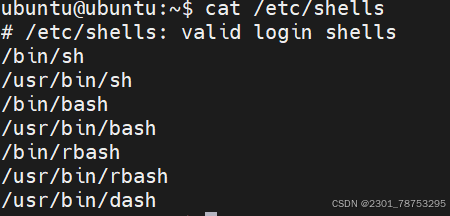
cat /etc/shells 查看当前系统的shell类型
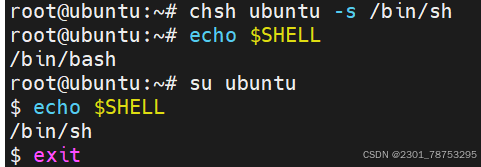
更改系统默认shell
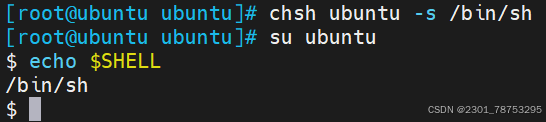
root@ubuntu:~# chsh ubuntu -s /bin/sh 修改Ubuntu默认dashe为sh
root@ubuntu:~# echo $SHELL 查看当前shell类型
/bin/bash
root@ubuntu:~# su ubuntu 切换到Ubuntu用户
$ echo $SHELL 查看当前shell类型
/bin/sh
$ exit 退出
2.1.8 echo 输出
echo 输出
选项
-n 不要在最后自动换行
-e 要是字符出现选项字符,则特别加以处理,而不会将他当成一般文字输出
换行且光标移至行首

echo $变量名获取变量名
![]()
2.1.9 chsh 允许用户更改其登录shell
shell 有很多种
bash
tcsh
sh
csh
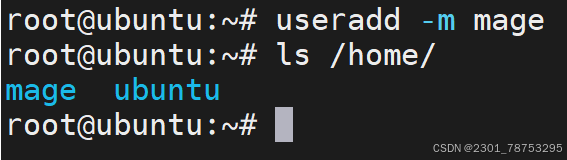
2.2.1 useradd创建用户
useradd 创建用户
选项
-m
2.2.2 PS1 修改默认变量
PS1 修改默认变量
选项
h 显示简写的主机名,如默认主机名localhost
示当前用户
W 显示当前所在的目录的最后一个目录

2.2.3 ls 显示当前目录下的文件
ls 查看当前目录下的文件
选项
-a 将所有隐藏文件显示出来

2.2.4 命令查看帮助
---help 查看命令选项
help 查看内部命令
whereis 查看命令是否在,若在显示命令存放位置
which 查看命令是否存在,若存在显示第一个显示的位置
man 查看命令帮助
2.2.5关机与重启的选项
关机:halt poweroff shutdown -hnow
重启:reboot shutdown - r
2.2.6 ubuntu让root用户远程登陆
1.给root设密码 sudo passwd root
2切换到root用户 su - root或者sudo -i
3安装ssh服务 apt install openssh-server
4允许root登录 grep /etc/ssh/sshd_config vim编辑 /etc/ssh/sshd_config 下方图片中#开头这段话改为yes
5重启服务 systemctl restart ssh
![]()
2.2.7软件的安装
安装用install
移除用remove
yum install适用于rocky 以及国产系统
yum 将会被dnf 取代操作方式是一样的
apt install适用于Ubuntu系统中
2.2.8查看用户各种信息
whoami 查看当前登录用户
id 显示用户的身份标识信息
pwd 在哪里 *
who 显示当前登录系统的用户 * 红色常用
w 查看当前用户的启动程序信息
last 显示上次登陆的用户列表信息
2.2.9查看系统信息
cpu 命令lscpu 文件/proc/cpuinfo
mem 命令free 文件/proc/meminfo *
磁盘分区 命令lsblk df 文件/proc/partitions *
磁盘设备 命令blkid
系统架构 命令arch
内核信息 命令uname -r
操作系统发行版本 文件 文件/etc/os-release[rocky操作系统]
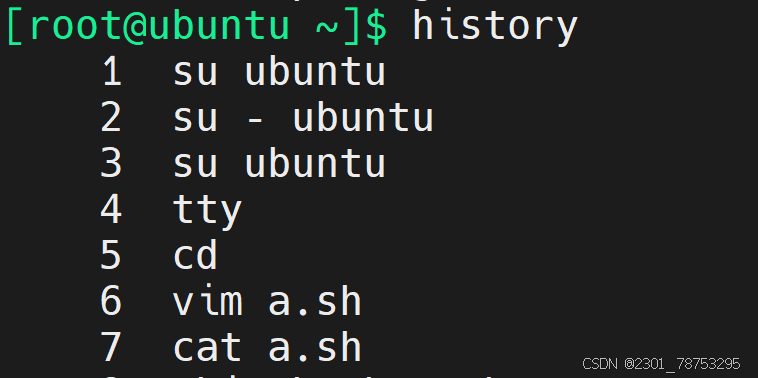
2.3.1 history历史命令
history用过的命令
选项
! 加命令编号快速执行命令
CTRL+R 输入命令前几个字母和TAB键差不多
-c 清除历史命令
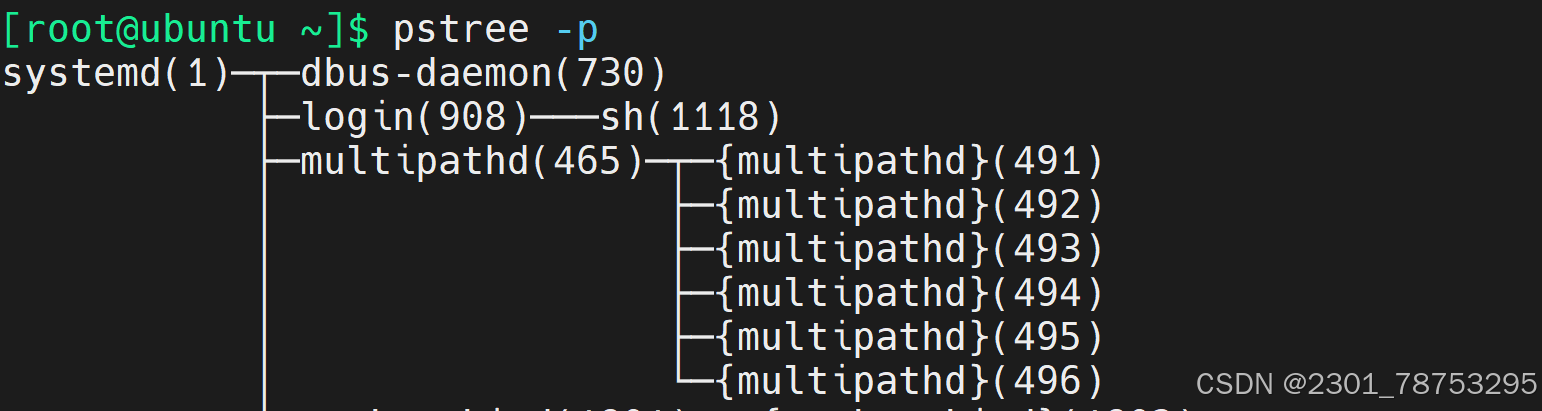
2.3.2 pstree 会话管理
pstree 查看当前系统里的所有进程 参数 -p
screen / tmux 会话解绑
screen -s创建一个独立的会话后面加会话名
screen -ls查看创建的会话
screen -X加丢失的会话名字找回会话
2.3.3 printf 格式
家目录 /root/home/
配置目录 /etc
命令目录 /bin /sbin
临时目录/tmp
根 /
当前目录 .
上一级目录 https://blog.csdn.net/2301_/article/
家目录 ~
各目录相关的文件

系统相关的目录
/boot 存放着启动Linux时使用的一些核心文件
/etc 存放所有的系统管理所需的配置文件和子目录
/lib 存放着系统最基本的动态连接共享库
/sys 存放着2.6内核3种文件信息
命令相关的目录
/bin 存放着常用命令
/sbin 存放着系统管理员使用的系统管理程序
/usr/bin 存放着系统用户使用的应用程序
/usr/sbin 存放着超级用户使用的比较高级的管理程序和系统守护程序
程序相关的目录
/proc 存放着 当前内核运行的一些文件
/srv 存放着服务启动之后需要提取的数据
/usr/src 存放着用户的很多应用程序和文件
/avr 存放着不断扩充着的东西
/run 存放着喜用启动以来的信息
/usr/share 存放着应用程序的帮助所在文件
其他相关的目录
/lost+found 一般是空的系统非法关机后存放着一些文件
/opt 是给主机额外安装软件所摆放的额目录
/selinux 安全机制目录
/tmp 存放临时文件
/run 运动目录
/var 变动文件目录

文件的操作和信息获取
查看文件
ls 目标目录位置
ls -a 查看隐藏文件
ls -l 显示额外信息
ls -R 查看所有目录文件信息
ls -ld 目录和符号链接信息
tree 目标目录位置 查看大目录 -L
创建目录
mkdir 目标位置 选项 -p 递归创建目录
创建文件
touch 文件名
切换目录
cd 目标目录位置
. 当前目录
.. 上级目录
- 回到之前目录月光宝盒
查看当前所在路径
pwd 查看当前所在位置
-p 显示当前工作目录的物理路径解析所有符号链接到他们的指向位置
-L 显示当前工作目录的逻辑路径,包含符号链接的路径
3.1.1 文本编辑工具vi/vim
vim与vi是相同的只不过vim有颜色
3.1.2 不同系统之间文件转换
dos2unix文件转换
3.1.3 正则符号
* 匹配任意字符不包括 “.” 开头的文件
{a..z} 表示a到z所有字符
[a-z] 表示a到z范围里的一个字符
[^a-b] 表示a到b以外的字符
? 隐藏文件匹配任意一个字符一个汉字也算一个字符
~ 表示当前家目录
.* 表示所有字符
[ ] 筛选范围中的一个字符
{ } 范围中的所有字符
() 临时的shell空间
3.1.4 cp拷贝
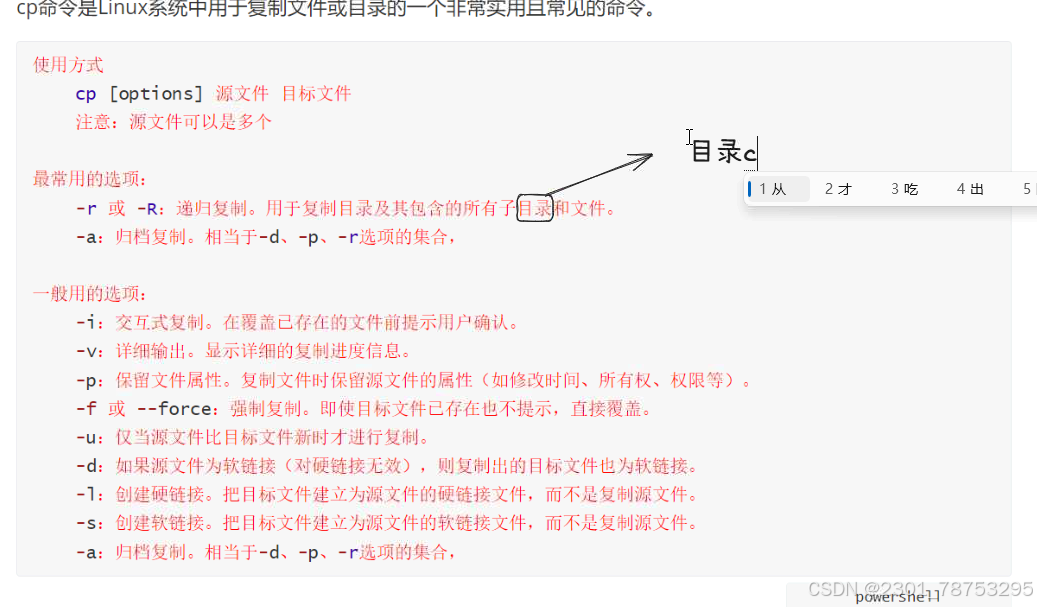
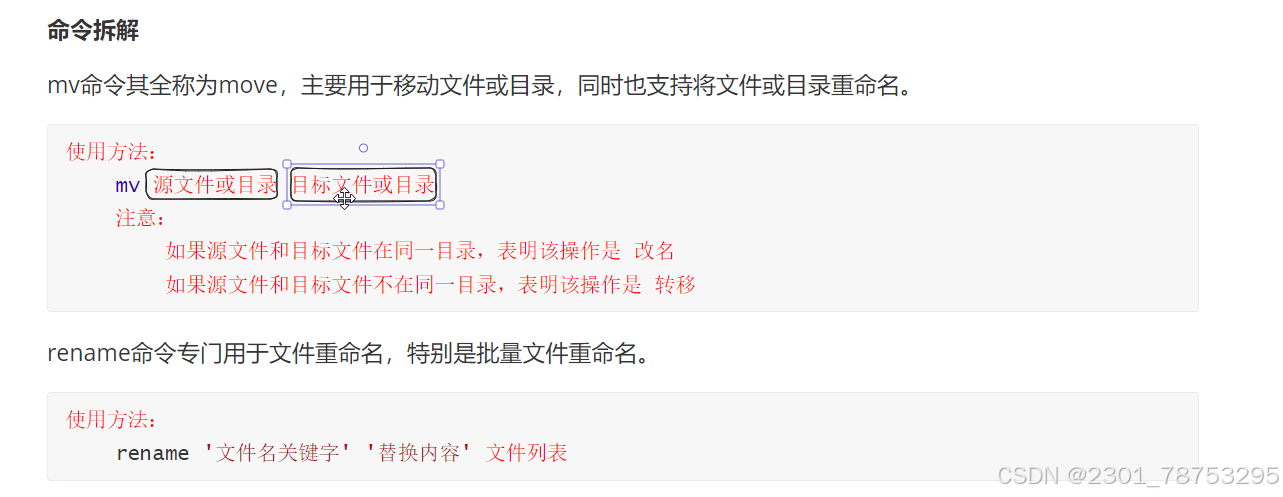
3.1.5 转移和改名
3.1.6 rename 改名
rename 文件改名
rocky系列改名方式如下

Ubuntu改名方式如下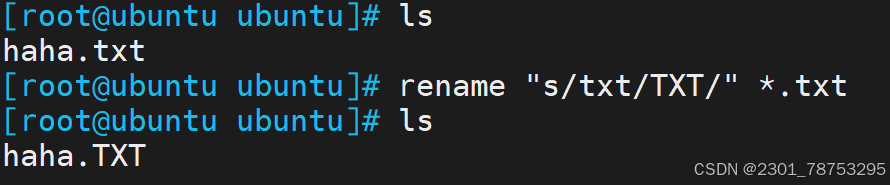
3.1.7 ln 硬链接和软连接
ln 创建硬链接 硬链接所有信息相同inode号也一样,删除源文件inode号不胡会消失
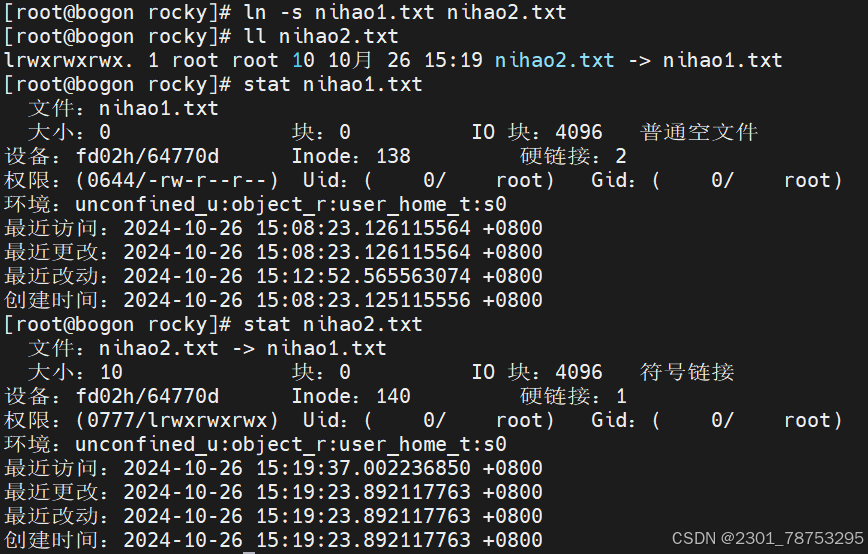
ln -s 创建软链接 软链接只是目标文件指向源文件所有信息和inode号都不同,删除源文件对目标文件没有什么影响
readlink 链接文件

硬链接方式inode号一样其他内容也一样,不支持目录硬链接 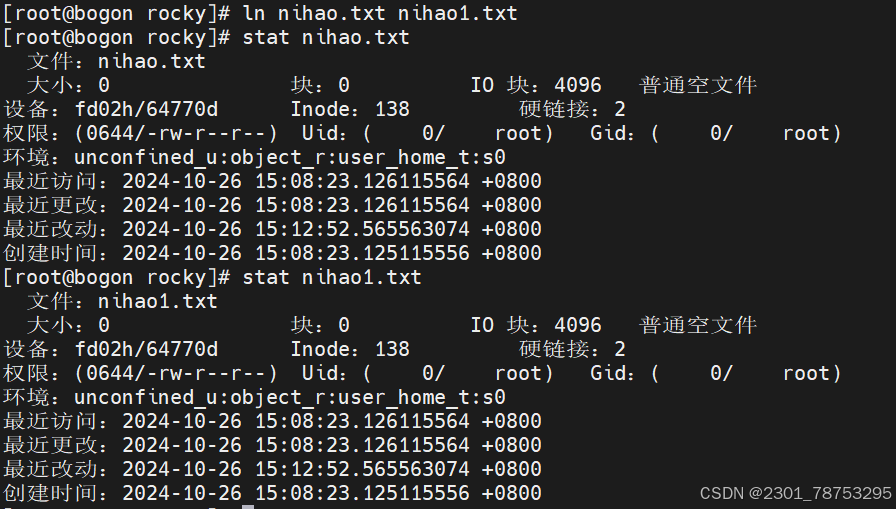
软链接与硬链接不同inode号不相同查看nihao2时其实查看的是nihao1的内容
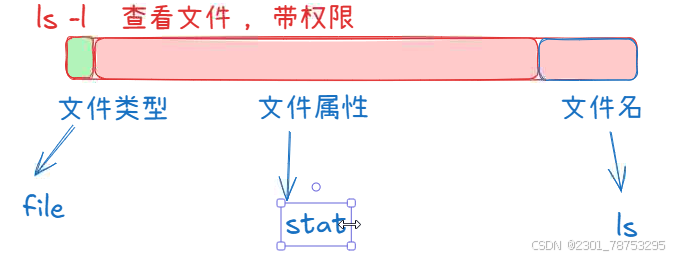
3.1.8 stat 查看文件状态
stat 查看文件状态
获取文件访问时间
修改文件时间
最后一次更改文件时间
inode号等各种信息
3.1.9 file 查看文件类型
file 和 ll 命令效果一样
3.2.1 rm 删除文件
rm -f 删除普通文件
rm -rf 删除目录及所有文件
3.2.2 vim / vi编辑工具
vim / vi 写文件
i 按i键开始编辑
ese 键退出编辑模式
:加 w 保存
:加 q 不保存退出
:加 wq 保存退出
!强制执行
!可以与q / w / qw 任意组合使用
3.2.3 管道符
> 表示将左面的内容以覆盖的方式输出给右面
< 表示将右面的内容以覆盖的方式输出给右面
>> 表示将左面的内容以追加的方式输出给右面
<< 表示将右面的内容以追加的方式输出给右面
| 表示将左面输出的结果传递给右面使用
| grep 过滤信息
3.2.4将成功命令与不成功命令分别装到不同的文件夹
1> 文件名
2> 文件名
1 代表成功命令
2 代表错误命令
2&>1 代表所有输出信息
3.2.5 特殊文件
特殊文件 /dev/null 垃圾桶无限容量
3.2.6 临时shell
临时shell
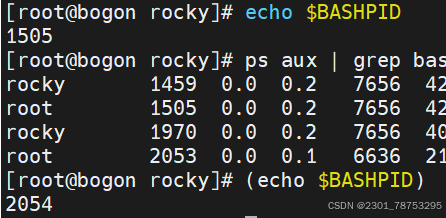
(命令列表)在shell里执行命令列表,退出shell后,不影响后续环境操作
临时shell环境---不启动子shell
{命令列表} 在shell里执行命令列表,会影响当前shell的后续环境操作
()使用场景,临时划分一个独立的shell环境,安全相关的命令处理,比如加密解密场景

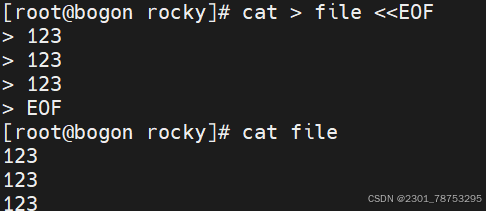
3.2.7 EOF重定向
eof 大写小写都一样只要统一就好
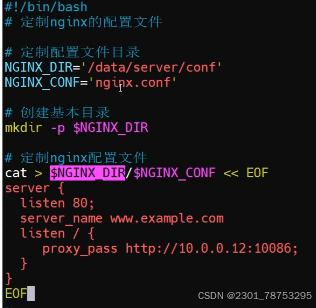
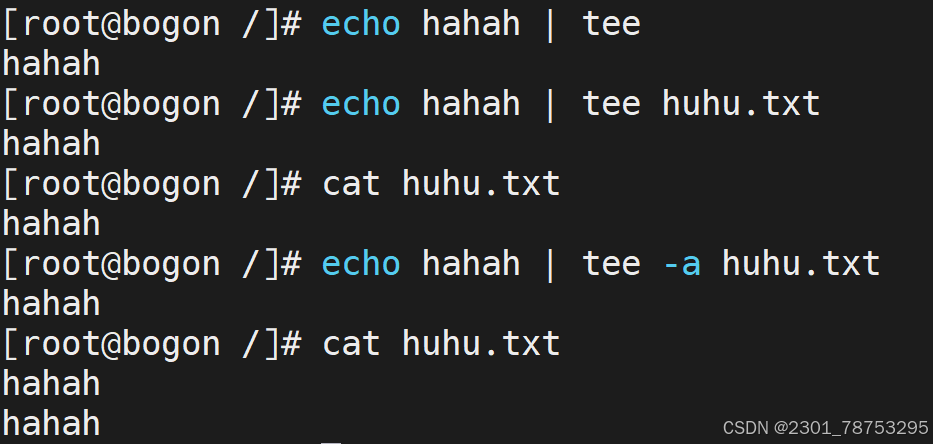
3.2.8 tee 重定向
tee 选项 -a
tee "文件" <<-eof 和 cat "文件" <<-eof 效果一样
tee 命令读取标准输入,把这些内容同时输出到标准输出和(多个)文件中,tee命令可以重定向标准输 出到多个文件。要注意的是:在使用管道线时,前一个命令的标准错误输出不会被tee读取

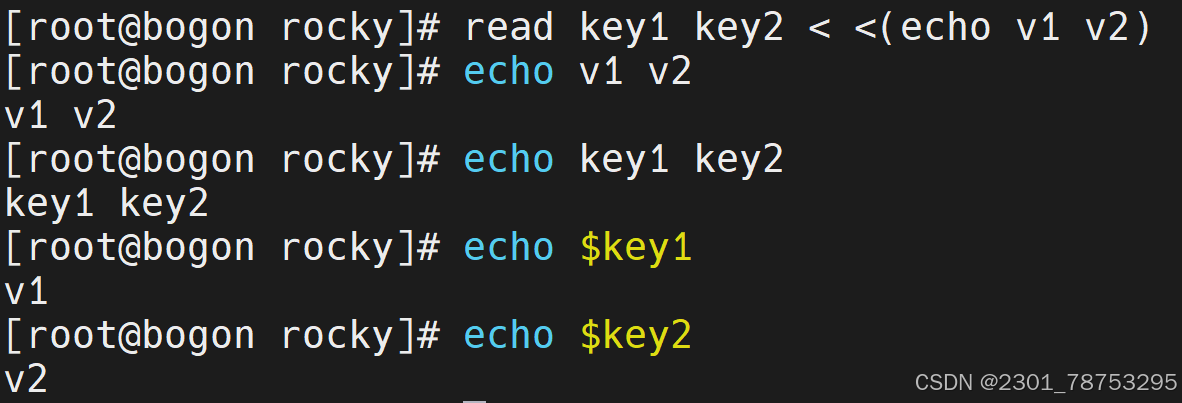
3.2.9 read
read -p "提示信息" 变量名
加 -t 指定时间 指定时间内不输入自动结束
拆解两个变量 read



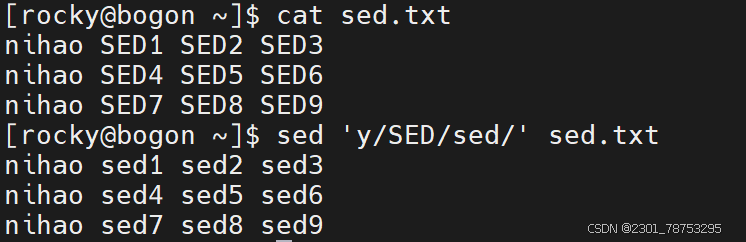
3.3.1 tr 替换
tr 用于替换字符


3.3.2 alias定义别名
alias 定义别名
unalias 取消别名
3.3.3 软件的安装
dnf makecache 更新软件源
dnf search nginx 搜索软件
dnf remove -y nginx 删除软件
dnf install -y nginx 安装软件
3.3.4查看文件系统磁盘使用情况
df -h 查看存储空间
df -i 查看inode号使用情况
4.1.1配置文件
/etc/passwd:用户及其属性信息(名称、UID、主组ID等)
sswang:x:1000:1000:sswang:/home/sswang:/bin/bash
用户名:密码:UID:GID:描述信息:宿主目录:命令解释器
/etc/shadow:用户密码及其相关属性
root:\(6\)VftC9gu7HNAEIc79\(VdxTdcGlQFjiP.RdyZG6js7fHnzj3WDIDb3v6JGqyD1zhh6Rw/J1ik7 M06UFNhZ9ihxjIiKpBwz2UEYc8pOsa.::0:99999:7:::</p> <p>用户名:密码:最后修改时间:最小时间间隔:最大时间间隔:警告时间:账号闲置时间:失效时间:标志</p> </blockquote> <p></p> <blockquote> <p>/etc/group:组及其属性xiang</p> <p>root:x:0:</p> 组名:组密码:GID:组内用户列表 </blockquote> <blockquote> <p>/etc/gshadow:组密码及其相关属性</p> <p>root:::</p> <p>组名:组密码:管理员:组内用户列表</p> </blockquote> <h4>4.1.2 vipw|vigr及pwck</h4> <blockquote> <p>命令用于编辑/etc/passwd,/etc/group,/etc/shadow,/etc/gshadow</p> <p>vipw 默认编辑 /etc/passwd 文件</p> <p>vigr 默认编辑 /etc/group 文件</p> <p>常见选项: </p> <p>-g |--group #编辑 group 文件 </p> <p>-p |--passwd #编辑 passwd 文件 </p> <p>-s |--shadow #编辑 /etc/shadow 或 /etc/gshadow 文件</p> </blockquote> <p><img alt="" height="1160" src="https://i-blog.csdnimg.cn/direct/baf7e9fd7dbd41c1a7246e17755aa669.png" width="1200" /></p> <p></p> <blockquote> <p> pwck</p> <p>对用户相关配置文件进行检查,默认检查文件为 /etc/passwd 自动找到错误内容并询问是否修改</p> <p>选项 </p> <p>- q 只报告错误,忽略警告 </p> <p>- r 显示错误和警告,但不改变文件 </p> <p>- R chroot 到的目录 </p> <p>- s 通过 UID 排序项目</p> </blockquote> <p><img alt="" height="345" src="https://i-blog.csdnimg.cn/direct/31a7ec4e3baa1246fa1efedce8.png" width="1059" /></p> <h4>4.1.3 groupadd命令可以创建用户组</h4> <blockquote> <p>命令格式 groupadd 加要创建的组名</p> <p><span style="color:#fe2c24;">getent group 加组名 查看用户组</span></p> <p>选项</p> <p>- g 指定id建组</p> <p>- r 指创建系统用户组</p> <p>- f 已有组强制创建用户组</p> </blockquote> <p><img alt="" height="251" src="https://i-blog.csdnimg.cn/direct/abed7e9d35cc48efab641ca4accecf44.png" width="944" /></p> <p><img alt="" height="136" src="https://i-blog.csdnimg.cn/direct/1acced20c1a441ffb2f9d31bee3d1232.png" width="855" /></p> <p><img alt="" height="126" src="https://i-blog.csdnimg.cn/direct/d0db9499c4adc1c43b54e29eab.png" width="823" /></p> <h4> 4.1.4 groupmod命令用于修改group属性</h4> <blockquote> <p>groaddmod 选项 要改的组号 要改的组</p> <p>选项</p> <p>- g 修改组号</p> <p>- n 修改组名</p> </blockquote> <p><img alt="" height="246" src="https://i-blog.csdnimg.cn/direct/862b3a9e36e041999c42fb48932f65db.png" width="922" /></p> <p><img alt="" height="206" src="https://i-blog.csdnimg.cn/direct/bcc489a9a27e4126bfa68ab2b3.png" width="1040" /></p> <h4> 4.1.5 groupdel命令可以删除用户组</h4> <blockquote> <p>选项</p> <p>- f 强制删除</p> </blockquote> <p><img alt="" height="213" src="https://i-blog.csdnimg.cn/direct/14dbd88e0978db8.png" width="870" /></p> <h4> 4.1.6 id用于查看用户的基本信息</h4> <blockquote> <p>选项 </p> <p>- d 查看默认的配置属性 useradd -D</p> <p>- u 指定UID id uid</p> <p>- g 指定用户组 id gid</p> </blockquote> <h4> 4.1.7 useradd 命令可以创建新的Linux用户</h4> <blockquote> <p>useradd 加想创建的用户</p> <p>选项</p> <p>- m 创建用户默认会添加一个组</p> <p>- g 指定组号创建用户</p> </blockquote> <p><img alt="" height="130" src="https://i-blog.csdnimg.cn/direct/e119ea026f6e462a857de1c0d07cfee0.png" width="1191" /></p> <p><img alt="" height="169" src="https://i-blog.csdnimg.cn/direct/2efde0b83a0d48c491ec3dfabb.png" width="1200" /></p> <h4>4.1.8 getent shadow查看用户密码信息</h4> <blockquote> <p>getent shadow 加想查看的用户名</p> <p>第一部分: 指定加密算法 \)6
第二部分: 指定二次校验选项 - salt 盐值 $cKdUJegv4ahdu0CD
第三部分:通过 加密算法(salt值 + 密码) 加密后的一段字符串

4.1.9 crypt 主要用于加密和解密文件或密码
whatis crypt 查看生成密码的算法解读
man 5 crypt man手册查看
根据密码提示,生成对应的passwd密码:
openssl passwd -salt 相同的盐值 加密算法编号 密码
 4.2.1 passwd修改密码
4.2.1 passwd修改密码

 4.2.1 passwd修改密码
4.2.1 passwd修改密码命令使用
passwd 用户名
在root用户下修改可以忽略无效的密码: 密码少于 8 个字符

4.2.2 chpasswd 更改用户命令
使用方法 chpasswd < 写一个文件
文件格式:用户名:密码
u1:
4.2.3 usermod命令用于进行用户属性的修改动作
使用方法:
usermod 选项 想改的名字 要改的名
修改shell usermod -s 要改的shell -d /home/要改的家目录名字 原来的名字
选项
- l 更改用户名字
- s 更改用户登录shell以及用户家目录
- L 禁用用户
- U 解禁用户


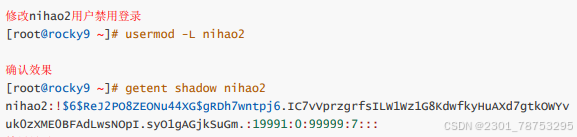

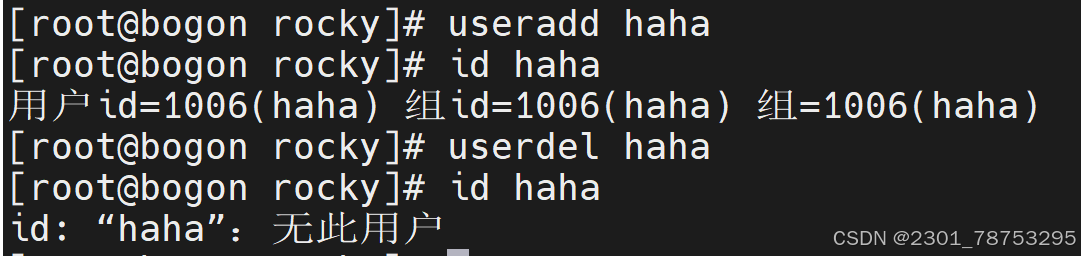
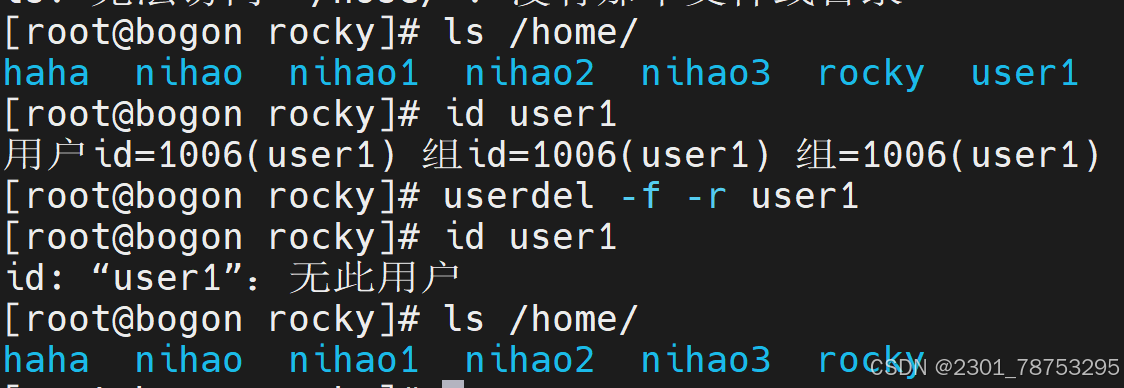
4.2.4 userdel 对用户删除
命令格式 userdel 选项 目标
- f 强制删除
-r

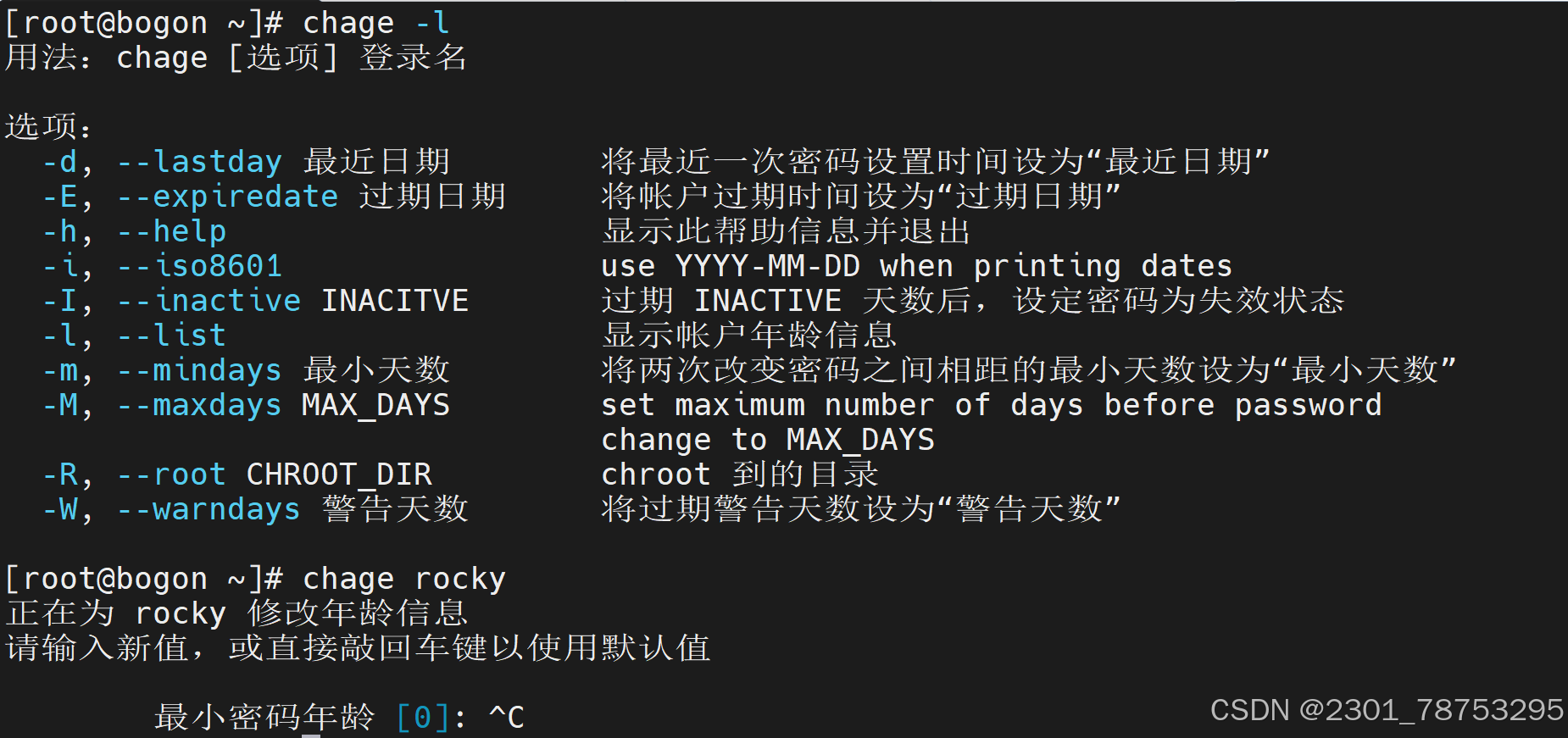
4.2.5 chage修改 密码策略
使用方法 chage 选项 目标
选项
- l 查看当前密码策略
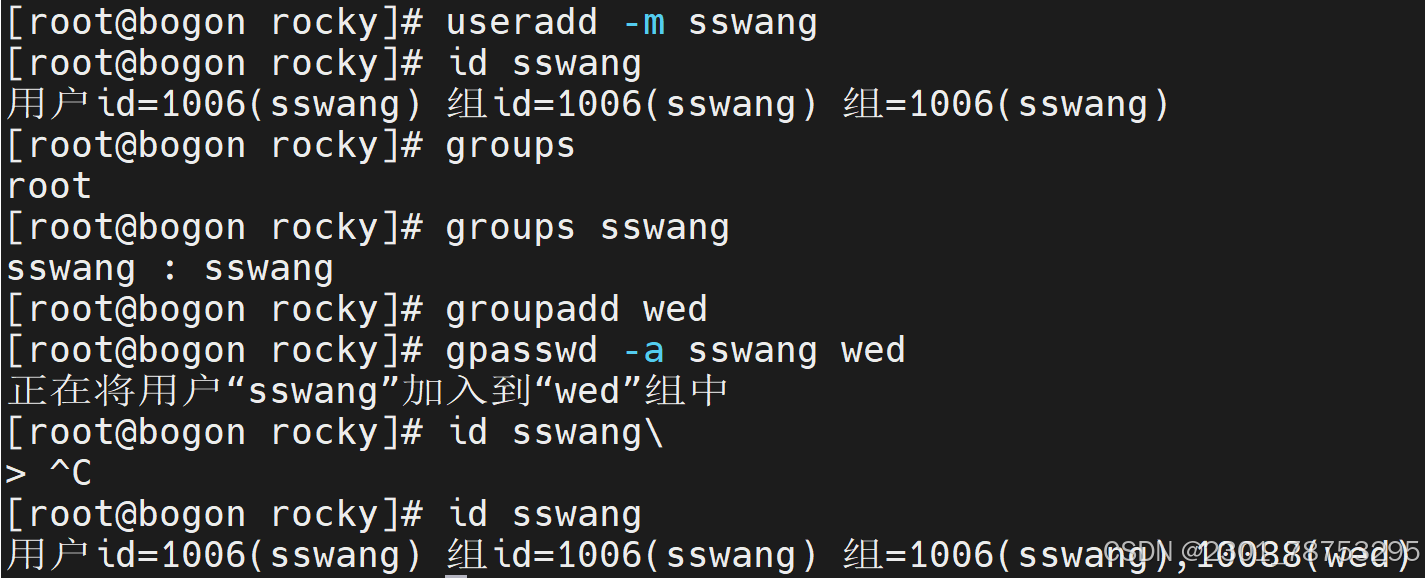
4.2.6 gpasswd 更改组成员密码
使用方法 gpasswd 选项 用户
选项
- a 将用户添加到一个指定的组里面
- d 将用户从组中删除
默认 : gpasswd 加组名 修改组密码


groups查看属主属组
使用方法 groupps 加用户名

4.2.7 groupmems 管理附加组成员信息
使用方法 groupmems 动作 组 选项
- g 指定组
- l 查看组成员列表
- d 从组中删除指定用户
- a 将用户添加到组内
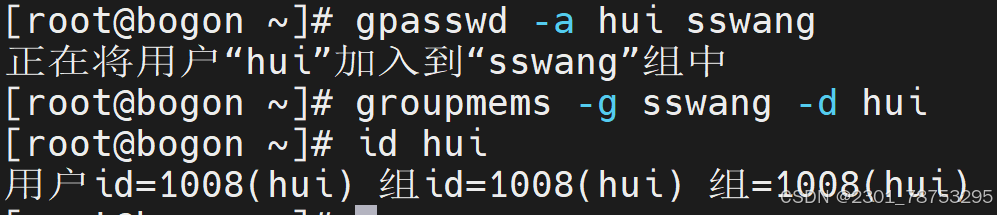
4.2.8 groups 查看用户组关系
4.2.9 用户登录配置文件/etc/login.defs
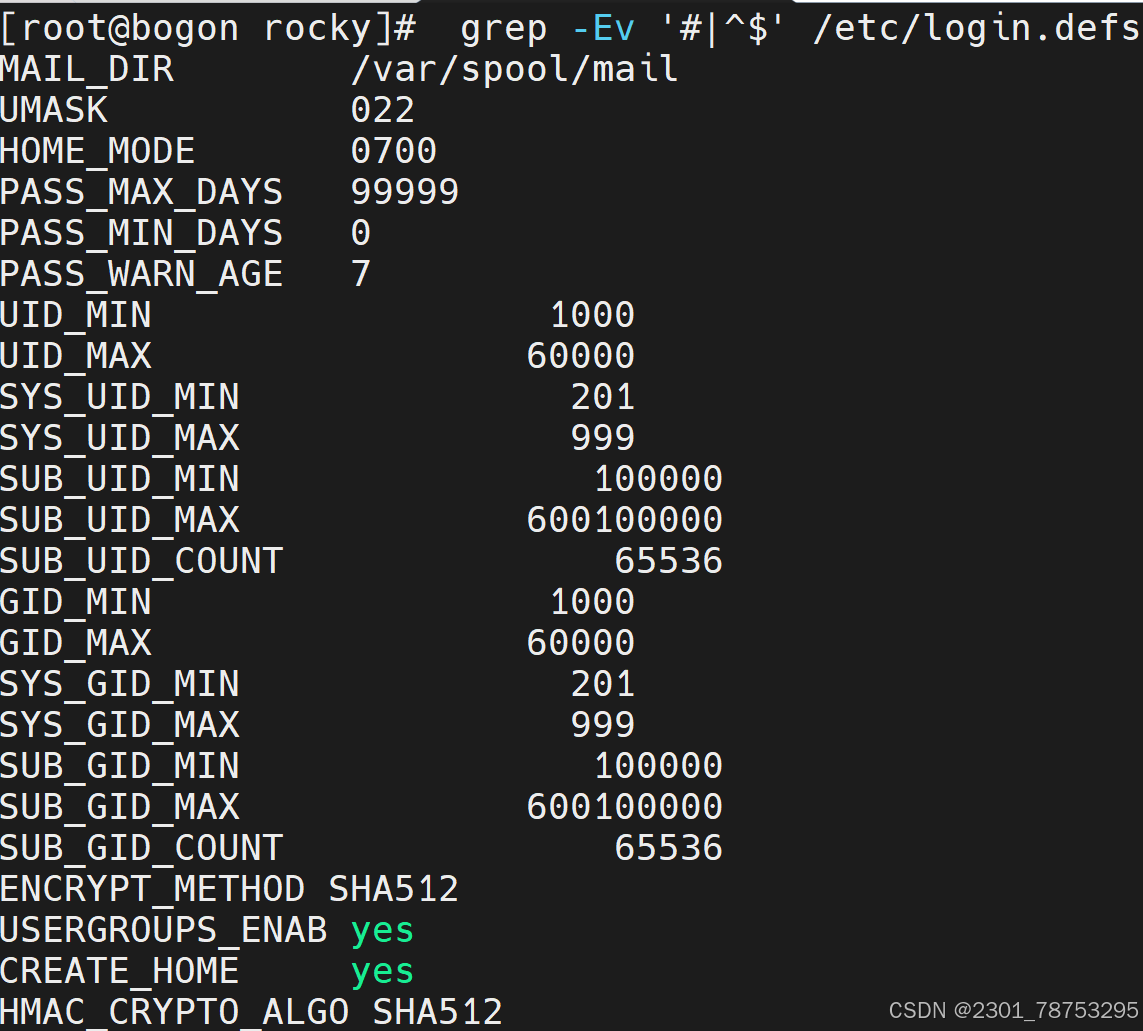
4.3.1 查看创建用户的配置文件 /etc/default/useradd
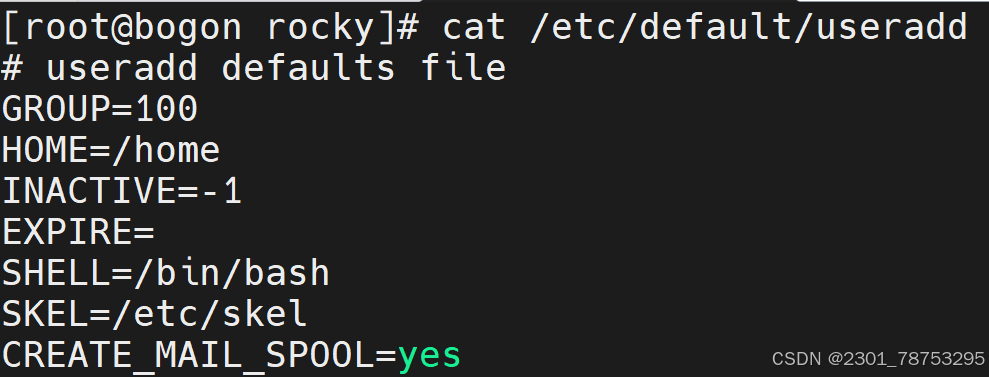
4.3.2 定制用户基本配置属性
定制用户基本配置属性
[root@rocky9 ~]# ls /etc/skel/
注意: 该目录保存了创建新用户后需要拷贝到 /home 目录下所需的相关文件。
4.3.3 定制用户登录的显示页面
用于设置用户登录系统后显示给用户的提示信息,该文件默认为空。
[root@rocky9 ~]# cat /etc/motd
文件权限解读
rwx rwx rwx 对应数字 421 421 421 - 为 0
第一组rwx对应属主u 第二组rwx对应属组g 第三组rwx对应其他人o
r 读 w 写 x 执行
默认创建的文件权限是 644,也就是说,谁都可以读去文件内容 默认不是可执行文件
默认创建的目录权限是 755,也就是说,谁都可以进入目录查看 默认没有写权限
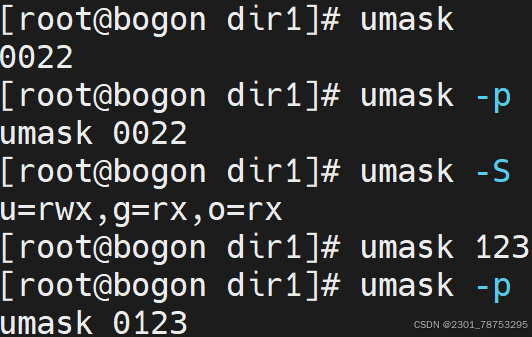
如果修改umask掩码 还是会按照默认状态创建如umask换成123那么
文件权限应该是 6 2 4
目录权限应该是7 5 5
操作示例:
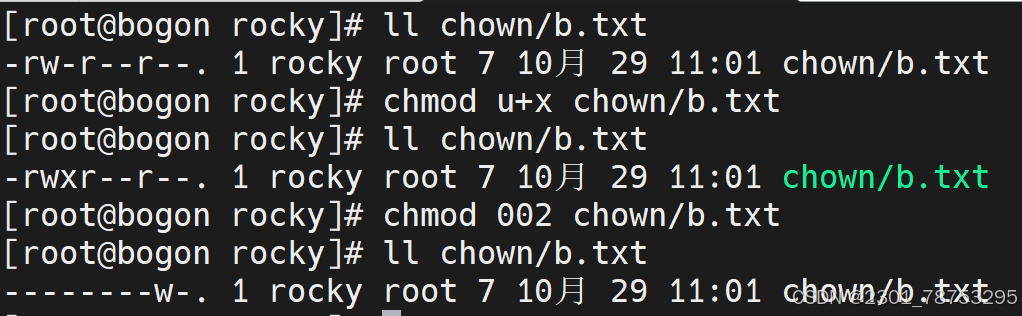
u+r # 属主加读权限
g-x # 属组去掉执行权限
ug=rx # 属主属组权限改为读和执行
o= # other用户无任何权限
a=rwx # 所有用户都有读写执行权限
u+r,g-x # 同时指定
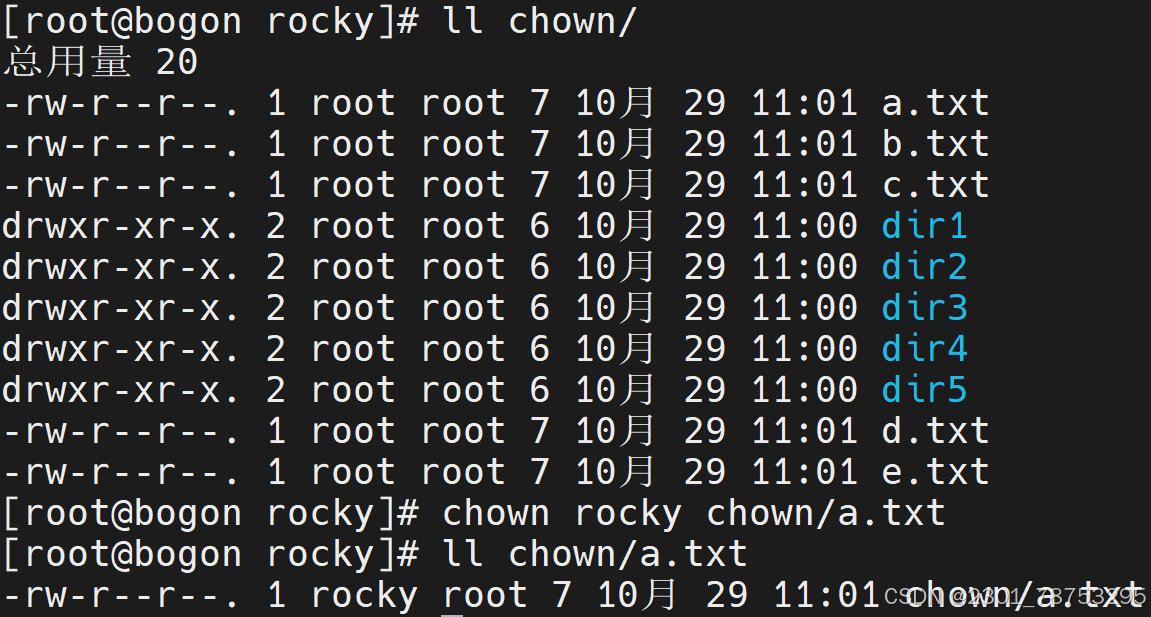
4.3.4 chown 修改文件属主属组
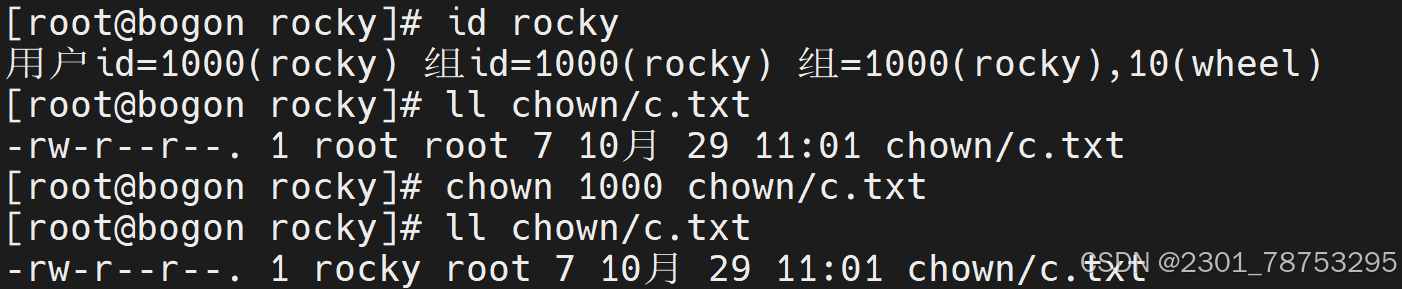
使用方法 chown 要变成的用户或id号 文件名
选项
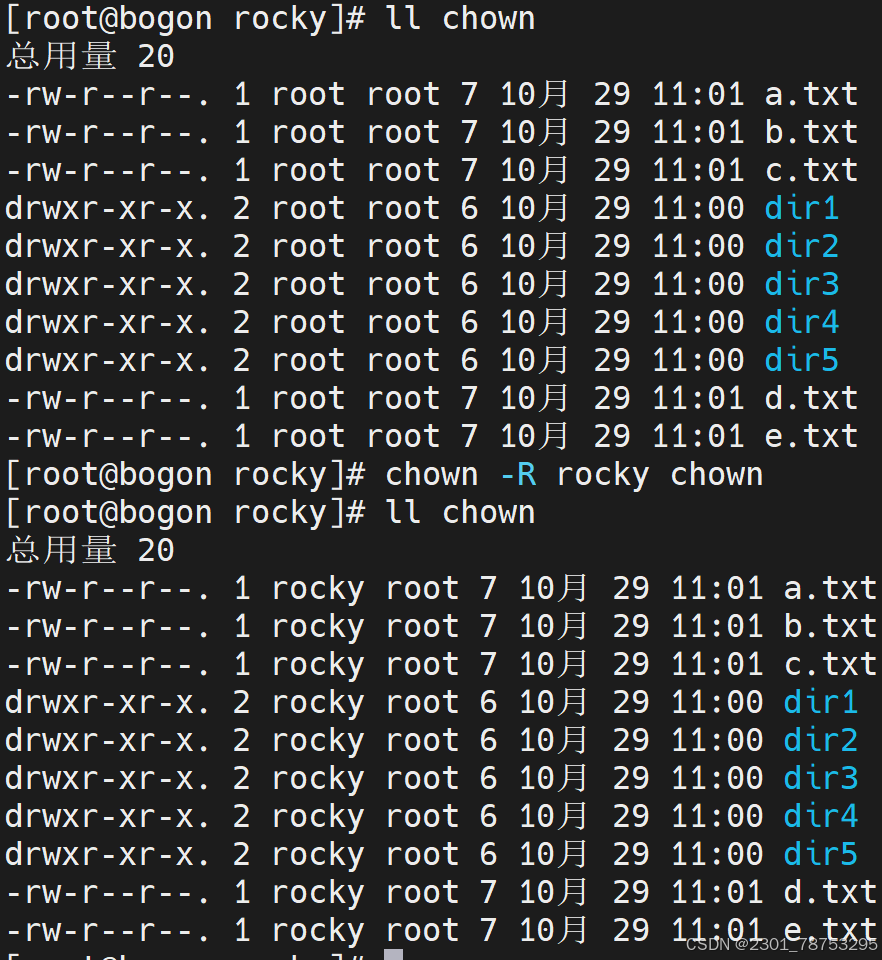
- R 批量修改将一个目录下所有文件修改
用户名后加 : 同时修改属主属组
通过用户id的方式修改文件归属
只修改所有者属性
[root@rocky9 ~]# chown sswang chown/a.txt
同时修改所有者和归属组的属性
[root@rocky9 ~]# chown sswang. chown/b.txt # . 的这种方式,虽然管用,但是不推 荐

4.3.5 chmod 修改文件操作权限
使用方法 chomd 指定u/g/o加或减权限 文件名 或777这样指定权限
选项
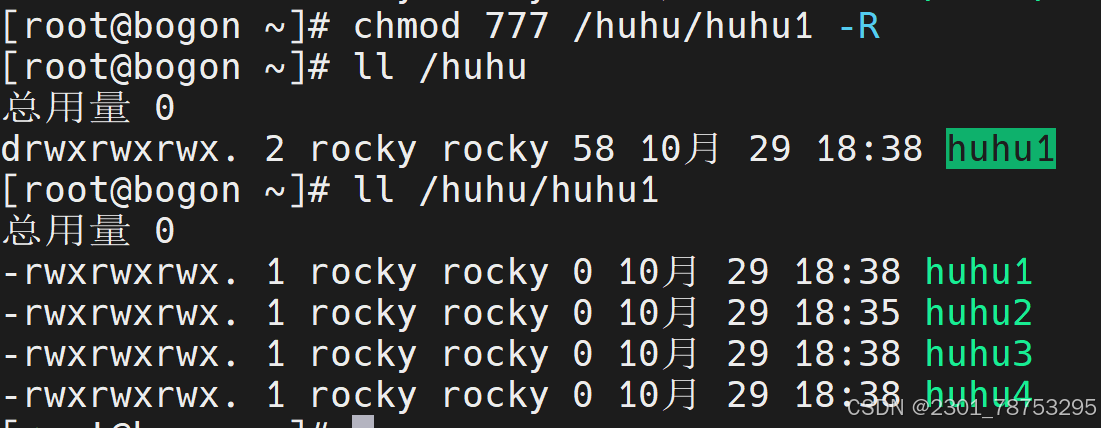
- R 递归操作
+ 加权限
- 减权限
a 等于ugo
u+rwx或7 是加属主权限
g+rwx或7 是加属组权限
o+rwx或7 是加其他用户权限


4.3.6 umask修改查看文件创建掩码
使用方式 umask 加选项 或直接输入值
选项
- p 如果省略 MODE 模式,以可重用为输入的格式输入
- S 以字符显示
4.3.7 特殊权限
在Linux文件系统中,除了基本的读(r)、写(w)、执行(x)权限外,还存在三种特殊权限,它们分 别是SUID(Set User ID)、SGID(Set Group ID)和Sticky Bit。这些特殊权限用于在特定情况下提 供更灵活的权限控制。
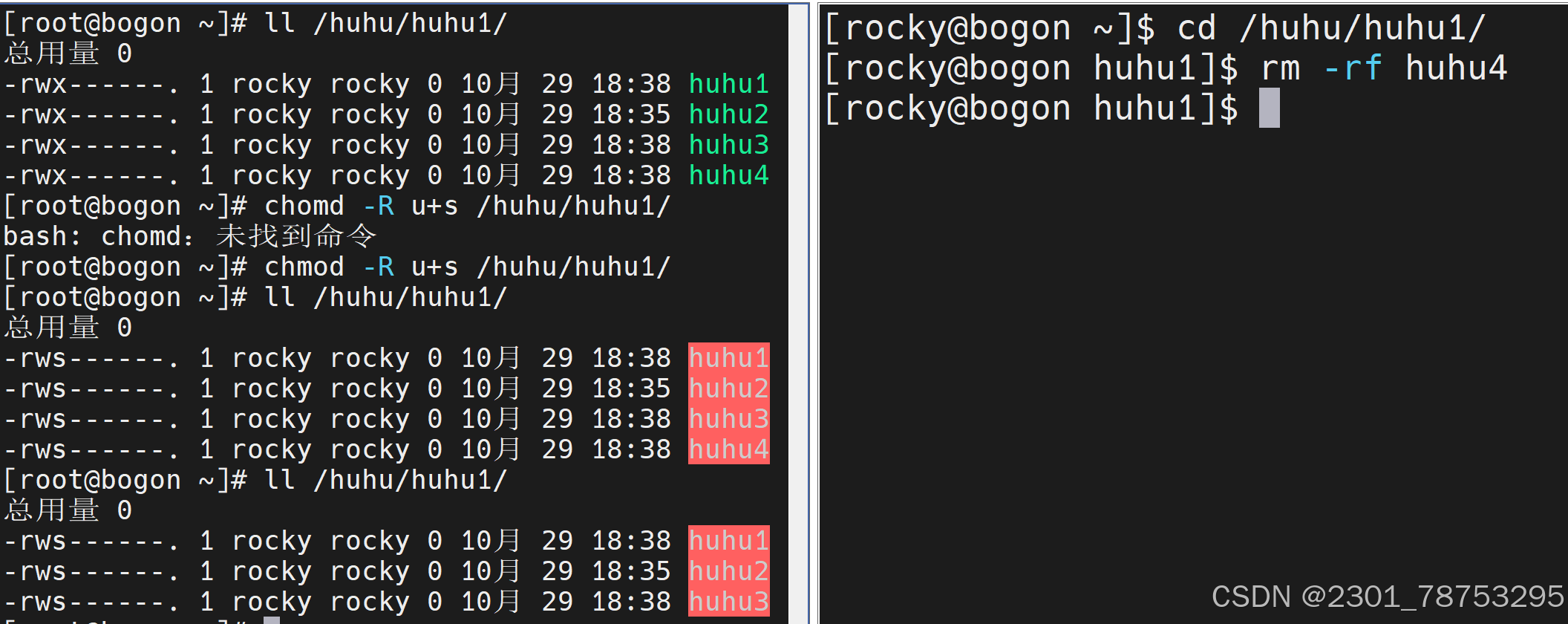
1.SUID权限设置在可执行文件上时,让其他用户拥有为文件所有者的权限
u+s
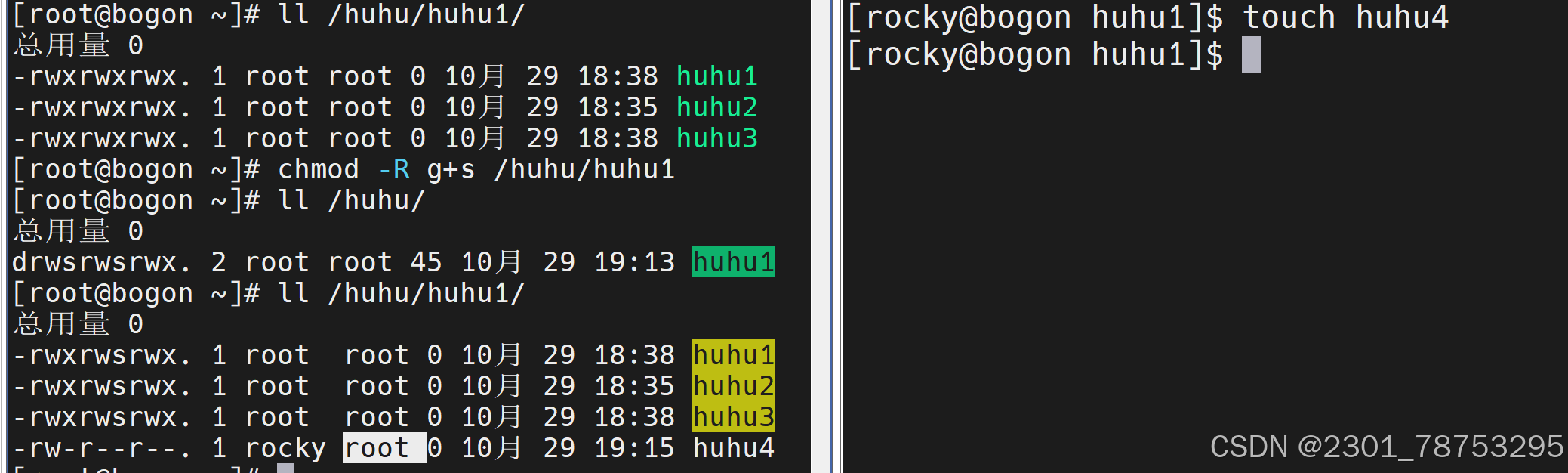
2. SGID权限可以应用于可执行文件或目录。其他用户在下面创建文件目录会变成所有者的组
g+s
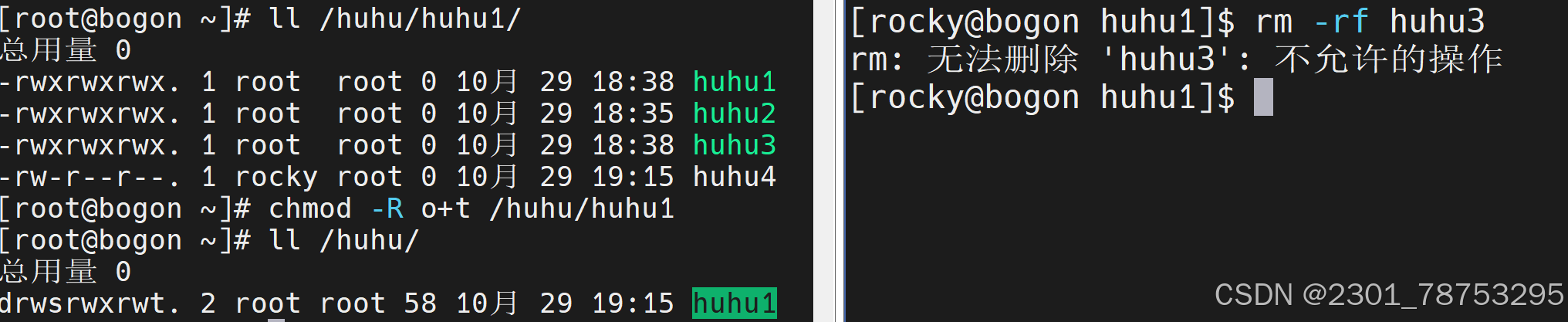
3. Sticky Bit权限仅对目录有效。当一个目录被设置为Sticky Bit时,其他用户只能查看其他都不可以 但是文件所有者和root用户除外
o+t
4.3.8 chattr 改变文件目录扩展属性
使用方法 +-= 选项 文件名字
选项
- p
- R
- V
- f
- v
动作
+表示添加属性,-表示移除属性,=表示设置唯一属性,覆盖其他所有属性。
常用属性
a:只允许追加数据,不能删除或修改文件内容。
i:设置文件为不可修改,即不能删除、重命名、修改内容或添加链接。
s:同步写入磁盘,修改立即生效,而非默认的非同步方式。
u:当文件被删除时,其内容仍保留在磁盘上,直到空间被其他文件覆盖。
A:访问文件时不更新访问时间。
c:自动压缩文件。
d:防止目录被dump备份。
这些属性可以增强文件的安全性,防止被意外修改、删除 或重命名。
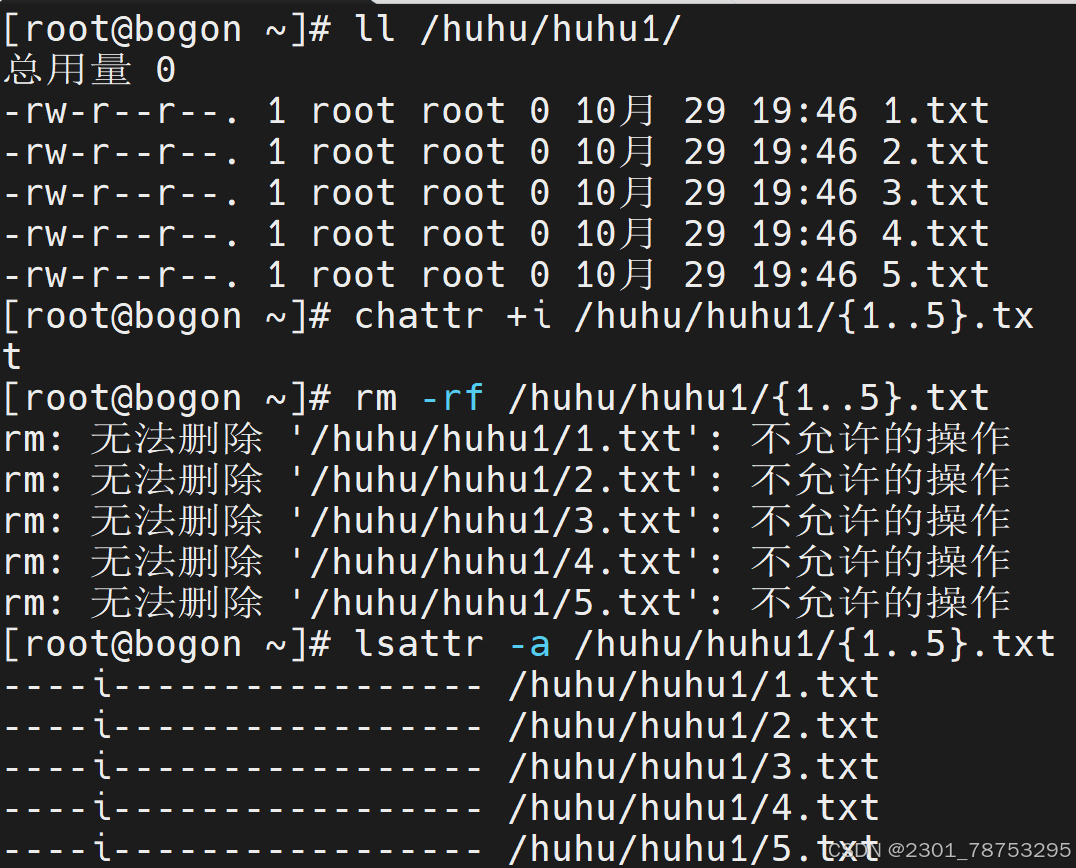
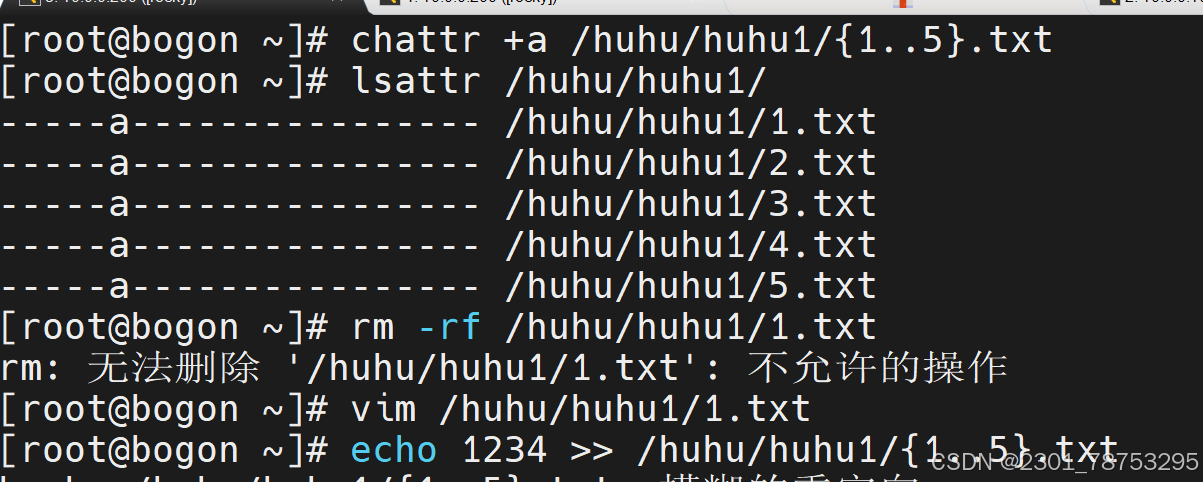
4.3.9 lsattr命令用于查看文件或目录的扩展属性
使用方法 lsattr 选项 文件目录名
选项
- a 显示所有文件目录属性包括隐藏文件
- d 如果目标是目录只显示目录本身属性不显示目录内文件属性
- R 递归列出目录及目录下所有目录文件属性
4.4.1 ACL权限
5.1.1 vi与vim文本处理
正常模式-默认模式
进入方式: 打开Vim时自动进入命令模式,或者从其他模式(如插入模式或底行模式)通过按Esc键返回命令模式。
操作示例:
光标移动:使用h、j、k、l键分别向左、下、上、右移动光标(或使用方向键)。
删除字符:按x删除光标所在位置的字符,按dd删除整行。
复制粘贴:使用yy复制当前行,p粘贴到光标所在位置。
编辑模式
进入方式: 从命令模式通过如下按键进入插入模式 - 按 i 在当前光标位置插入 - 按 a 在当前光标位置的下一个字符处插入 - 按 o 在当前光标所在行的下一行插入新行 退出方式: 按Esc键退出插入模式,返回到命令模式
命令模式
底行模式允许用户执行一些高级的编辑和搜索操作,如文件保存、退出、搜索替换、设置选项等。
进入方式:
从命令模式通过按:(冒号)或/(表示查找)进入底行模式。
退出方式: 按Esc键退出底行模式,返回到命令模式。
操作示例: 保存文件:输入:w保存当前文件,:wq或:x保存并退出Vim 查找替换:输入:/搜索词进行查找,:s/原词/新词/g进行全局替换。 设置选项:输入:set nu显示行号,:set nonu取消显示行号。
编辑实践
使用方式 vim 加文件名 选项
+ 打开文件后让光标处于尾行
+N 打开文件后让光标处于第N行的行首,+默认尾行 使用频率最高
+/PATTERN 让光标处于第一个被PATTERN匹配到的行行首
-d file1 file2 同时打开多个文件,相当于 vimdiff
qall 同时退出多个文件
从正常模式进入编辑模式的方法
i insert, 在光标所在处输入
I 在当前光标所在行的行首输入
a append, 在光标所在处后面输入
A 在当前光标所在行的行尾输入
o 在当前光标所在行的下方打开一个新行
O 在当前光标所在行的上方打开一个新行
查找内容
使用方法正常模式下直接输入
/关键字 从当前光标所在处向文件尾部查找 搜索完第一次继续按/会出现相同关键字回车向上查找
?关键字 从当前光标所在处向文件首部查找 搜索完第一次继续按/会出现相同关键字回车向下查找
n/N相当于上下键
n 与命令同方向
N 与命令反方向
扩展命令
: wq 写入并退出
: q! 不存盘退出,即使更改都将丢失
下面这些鸡肋可以玩玩
r filename 读文件内容到当前文件中
w filename 将当前文件内容写入另一个文件
!command 执行命令
r!command 读入命令的输
筛选范围
常用属性
M,N 从左侧M表示起始行,到右侧N表示结尾行
\( 最后一行</p> <p>% 全文, 相当于1,\)
/pat1/,/pat2/ 从第一次被pat1模式匹配到的行开始,一直到第一次被pat2匹配到的行结束 其他属性
N 具体第N行,例如2表示第2行
M,+N 从左侧M表示起始行,右侧表示从光标所在行开始,再往后+N行结束
M,-N 从左侧M表示起始行,右侧表示从光标所在行开始,-N所在的行结束
M;+N 从第M行处开始,往后数N行,2;+3 表示第2行到第5行,总共取4行
M;-N 从第M-N行开始,到第M行结束
. 当前行
.,\(-1 当前行到倒数第二行 /pattern/ #从当前行向下查找,直到匹配pattern的第一行,即正则匹配 </p> <p>/pat1/,/pat2/ 从第一次被pat1模式匹配到的行开始,一直到第一次被pat2匹配到的行结束 N,/pat/ 从指定行开始,一直找到第一个匹配pattern的行结束 </p> <p>/pat/,\) 向下找到第一个匹配patttern的行到整个文件的结尾的所有行
动作演示
:2d 删除第2行
:2,4d 删除第2到第4行
:2;+3y 复制第2到第5行,总共4行
p 将复制的粘贴
:2;+4w test 将第2到第6行,总共5行内容写入新文件
:5r /etc/issue 将/etc/issue 文件读取到第5行的下一行
:t2 将光标所在行复制到第2行的下一行
:2;+3t10 将第2到第5行,总共4行::内容复制到第10行之后
:.d 删除光标所在行
:\(y 复制最后一行</p> </blockquote> <blockquote> <p> 常用动作</p> <p><span style="color:#fe2c24;">d 删除 </span></p> <p><span style="color:#fe2c24;">p 粘贴 </span></p> <p><span style="color:#fe2c24;">y 复制</span></p> <p><span style="color:#fe2c24;">u 撤销刚才的动作</span></p> </blockquote> <p> <img alt="" height="229" src="https://i-blog.csdnimg.cn/direct/af8f9feb3f5fdef1ec041bde.png" width="749" /></p> <h4> <span style="color:#fe2c24;">重点内容替换</span></h4> <blockquote> <p>使用方法: s/原内容/替换后内容/修饰符</p> <p>内容替换方法</p> <p>:s /要查找的内容/替换为的内容/修饰符</p> <p>:%s 表示全文查找替换</p> <p></p> <p>修饰符</p> <p>i 忽略大小写</p> <p>g 全局替换,默认情况下,每一行只替换第一次出现</p> <p>gc 全局替换,每次替换前询问</p> <p></p> <p>常用示例</p> <p>从全文替换</p> <p> :%s/原内容/替换后内容/g</p> <p></p> <p>从当前行到最后一行进行替换</p> <p> :,\)s/原内容/替换后内容/g
正则匹配内容进行全文替换
:/关键字/,\(s/原内容/替换后内容/g</p> <p>从第3到第6行内容进行替换</p> <p> :3,6s/原内容/替换后内容/g</p> <p></p> <p><span style="color:#fe2c24;">, 代表当前行</span></p> <p><span style="color:#fe2c24;">\) 代表末尾行
% 代表全文
%s/xxx/xxx/g常用
常用属性
查看行号
:set nu #显示行号
:set nonu #取消显示行号
复制保留格式
:set paste #复制时保留其他系统格式 作用将格式还原回来原样粘贴
:set nopaste #禁用复制时保留其他系统格式选项
Tab 用空格代替
:set et #使用空格代替Tab,默认8个空格
:set noet #禁用空格代替Tab
Tab用指定空格的个数代替
:set ts=N #指定N个空格代替Tab
查看帮助
:help option-list
:set all
:set cul 表示线
:set nocul 取消标识线
:set ai 启用自动缩进
:set noai 取消自动缩进
:set key=password 设置密码
行首跳转
^ #跳转至行首的第一个非空白字符
0 #跳转至行首
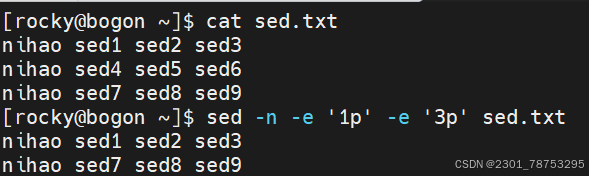
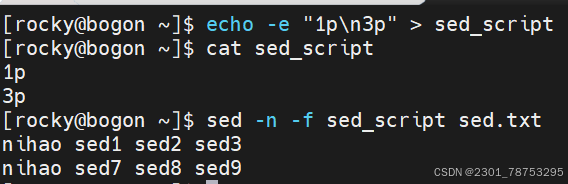
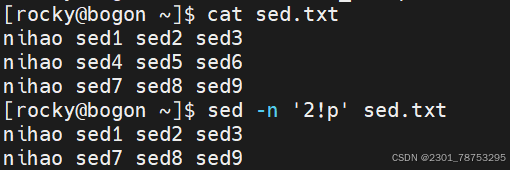
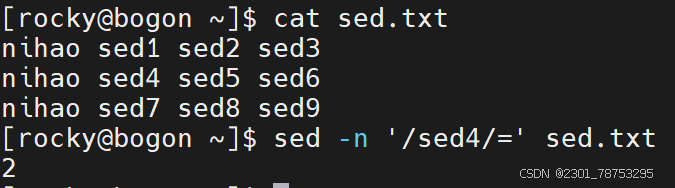
\( #跳转至行尾</span></p> <p></p> <p>行间移动:</p> <p><span style="color:#fe2c24;">:N #跳转至指定行,N表示正整数,比如 10G,或在扩展命令模式下:10,都表示跳转到第10 行 </span></p> <p><span style="color:#fe2c24;">G #最后一行 </span></p> <p><span style="color:#fe2c24;">1G #第一行</span></p> <p></p> <p>当前页跳转:</p> <p>H #页首 </p> <p>M #页中间行 </p> <p>L #页底</p> <p></p> <p>命令模式翻屏操作</p> <p>Ctrl+f #向文件尾部翻一屏,相当于Pagedown</p> <p>Ctrl+b #向文件首部翻一屏,相当于Pageup</p> <p>Ctrl+d #向文件尾部翻半屏</p> <p>Ctrl+u #向文件首部翻半屏</p> </blockquote> <h4> 5.1.2 可视化模式</h4> <blockquote> <p><span style="color:#fe2c24;"> ctrl-v(小写) 面向块</span></p> <p></p> <p><span style="color:#fe2c24;">1、先将光标移动到指定的第一行的行首 </span></p> <p><span style="color:#fe2c24;">2、输入ctrl+v 进入可视化模式 </span></p> <p><span style="color:#fe2c24;">3、向下移动光标,选中希望操作的每一行的第一个字符 </span></p> <p><span style="color:#fe2c24;">4、输入大写字母 I 切换至插入模式 5、输入 # 6、按 ESC 键</span></p> <p></p> <p><span style="color:#fe2c24;">1、光标定位到要操作的地方 </span></p> <p><span style="color:#fe2c24;">2、CTRL+v 进入“可视块”模式,选取这一列操作多少行 </span></p> <p><span style="color:#fe2c24;">3、SHIFT+i(I) </span></p> <p><span style="color:#fe2c24;">4、输入要插入的内容 </span></p> <p><span style="color:#fe2c24;">5、按 ESC 键</span></p> </blockquote> <h4>5.1.3 cat 查看文件内容</h4> <blockquote> <p>使用方法: cat 选项 文件名</p> <p>选项:</p> <p>- n 对显示的每一行编号</p> <p>- s 压缩连续的空行成一行</p> </blockquote> <p><img alt="" height="612" src="https://i-blog.csdnimg.cn/direct/676ab401e81e45df9579f5f2ae5df90e.png" width="1021" /></p> <p><img alt="" height="823" src="https://i-blog.csdnimg.cn/direct/04622c02277f40d2badaea.png" width="1200" /></p> <blockquote> <p>tac 逆向显示文件内容</p> <p>rev 内容逆向显示,行内容也逆向显示</p> <p>hexdump 以十六进制方式查看任意文件</p> </blockquote> <h4> 5.1.4 more 分页查看</h4> <blockquote> <p>使用方法: more 选项 文件名</p> <p>选项:</p> <p>- d 在底部显示提示</p> <p>- s 压缩连续空行</p> <p></p> <p>常用动作 </p> <p>空格键 #翻页 </p> <p>回车键 #下一行 </p> <p>q #退出</p> <p></p> <p>其他动作 </p> <p>!cmd #执行命令,在查看文档的时候,执行相关的命令 </p> <p> h #显示帮助 </p> <p>:f #显示文件名和当前行号 </p> <p> = #显示行号</p> </blockquote> <p><img alt="" height="828" src="https://i-blog.csdnimg.cn/direct/fc64a20ce2ce4b7fa480adf6fe.png" width="1200" /></p> <h4> <span style="color:#fe2c24;">*5.1.5 head 可以显示文件或标准输入的前面行</span></h4> <blockquote> <p>使用方法 head 选项 文件名</p> <p>常用选项</p> <p><span style="color:#fe2c24;">- n 指定获取后N行,如果写成n3,表示从第1行到3行</span></p> <p>一般选项 </p> <p>-c 指定获取前N字节 </p> <p>-N 同上 </p> <p>-q 不输出文件名 </p> <p>-v 输出文件名 </p> <p>-z 以NULL字符而非换行符作为行尾分隔符</p> <p>与tail搭配使用</p> </blockquote> <p><img alt="" height="558" src="https://i-blog.csdnimg.cn/direct/0d2907aefa5e5165e03cb47.png" width="852" /></p> <h4> <span style="color:#fe2c24;">5.1.6 tail 和 head 相反,查看文件或标准输入的倒数行</span></h4> <blockquote> <p>使用方法 tail 选项 文件</p> <p>常用选项</p> <p><span style="color:#fe2c24;">-n 指定获取后N行,如果写成n3,表示从第1行到3行</span></p> <p>一般选项</p> <p> -c 指定获取后N字节 </p> <p> -N 同上 </p> <p> -f 跟踪显示文件fd新追加的内容,常用日志监控, #当删除再新建同名文件,将无法继续跟踪 </p> <p> -F 跟踪文件名,相当于--follow=name --retry, #当删除文件再新建同名文件,可继续追踪 </p> <p> -q 不输出文件名 </p> <p> -z 以NULL字符而非换行符作为行尾分隔符</p> <p>与head搭配使用</p> </blockquote> <p><img alt="" height="556" src="https://i-blog.csdnimg.cn/direct/8ddd34973aa8415abae1ad6.png" width="850" /></p> <h4> head和tail组合使用</h4> <blockquote> <p>查看/etc/passwd文件中第三行</p> <p><img alt="" height="522" src="https://i-blog.csdnimg.cn/direct/2eb6fa43d6b048f9bd91fd50dea1bbfe.png" width="847" /></p> <p>head -n3 将/etc/passwd 前三行取出 | 交给 tail -n1 将三行中的倒数第一行取出</p> </blockquote> <h4> 5.1.7cut 命令可以提取文本文件或STDIN数据的指定列</h4> <blockquote> <p>使用方法 cut 选项 选项 文件 或 | cut 选项 选项</p> <p>常用选项:</p> <p>- c 选择指定字符</p> <p><span style="color:#fe2c24;">- d 选择指定字符为列分界</span></p> <p>必须选项 </p> <p><span style="color:#fe2c24;">-f 指定第几列输出f1是第一列 </span> </p> <p>--output-delimiter=字符串 使用指定的字符串作为输出分界符,默认采用输入</p> </blockquote> <p> <img alt="" height="160" src="https://i-blog.csdnimg.cn/direct/249bd64bf0ab72b58c2fe99a0e.png" width="493" /></p> <p><img alt="" height="83" src="https://i-blog.csdnimg.cn/direct/d2a141e284b346f387ebf288e4a8ac22.png" width="687" /></p> <h4> 5.1.8 tr命令实现 字符转换、替换、删除</h4> <blockquote> <p>-c, 首先补足SET1 </p> <p>-d, 删除匹配SET1 的内容,并不作替换 </p> <p><span style="color:#fe2c24;">-s 如果匹配连续的空格重复,在替换时会被统一缩为一个字符的长度 </span></p> <p>-t 先将SET1 的长度截为和SET2 相等 </p> <p></p> <p>用法1:把commands命令输出做为tr输入进行处理 commands | tr 'string1' 'string2'</p> <p>用法2:把文件中的内容输入给tr进行处理 tr 'string1' 'string2' < filename</p> <p>用法3:把文件中的内容输入给tr进行处理,需要使用到选项 tr options 'string1' < filename</p> <p>用法4: 删除不匹配的所有内容,仅留下有用的信息 tr -dc [:alnum:]</p> </blockquote> <h4> 总结head tail cut tr 组合使用</h4> <blockquote> <p>ip a查看用户ip head -n10输出前十行 tail -n1输出倒数第一行 tr -s " " 压缩多个空格为一个空格 cut -d " " 将空格作为分隔符 </p> <h4><img alt="" height="43" src="https://i-blog.csdnimg.cn/direct/2bc009cf6a1f4101a71527aebe4d7136.png" width="753" /></h4> </blockquote> <h4> 5.1.9 sort将相同信息整 |理在一起排序</h4> <blockquote> <p>使用方式 sort 选项 文件</p> <p>常见选项: </p> <p>-u :去除重复行 </p> <p><span style="color:#fe2c24;">-r :降序排列,默认是升序 </span></p> <p><span style="color:#fe2c24;">-n :以数字排序,默认是按字符排序 其他选项 </span> </p> <p>其他选项</p> <p>-o : 将排序结果输出到文件中 类似 重定向符号> </p> <p>-t :分隔符 </p> <p>-k :第N列 </p> <p>-b :忽略前导空格。 </p> <p>-R :随机排序,每次运行的结果均不同。</p> <p><span style="color:#fe2c24;">只输入sort可以将相同的内容排在一起</span></p> </blockquote> <p> <img alt="" height="575" src="https://i-blog.csdnimg.cn/direct/a8adfe199b9f4931b6ada5af94.png" width="383" /></p> <h4> 5.2.1 uniq命令 实现连续信息的去重动作</h4> <blockquote> <p>使用方法 uniq 信息</p> <p>常用选项</p> <p>空没有</p> <p>一般选项 </p> <p><span style="color:#fe2c24;">-c, --count 统计重复行次数 </span></p> <p>-d, --repeated 只显示重复行 </p> <p><span style="color:#fe2c24;">-i, --ignore-case 忽略大小写 </span></p> </blockquote> <p> <img alt="" height="309" src="https://i-blog.csdnimg.cn/direct/6c4dffcfb03043c683f3489e110fa70c.png" width="328" /><img alt="" height="276" src="https://i-blog.csdnimg.cn/direct/eb79b32fc8de6da4ef1a9.png" width="330" /></p> <p><img alt="" height="317" src="https://i-blog.csdnimg.cn/direct/176d64daf39860bd39060c5f5c.png" width="382" /></p> <h4> 5.2.2 paste合并文件行内容输出到屏幕,不会改动源文件</h4> <blockquote> <p>使用方法paste 文件一 文件二</p> <p><span style="color:#fe2c24;">-d 列表 改用指定列表里的字符替代制表分隔符 </span></p> <p><span style="color:#fe2c24;">-s 不使用平行的行目输出模式,而是每个文件占用一行 </span></p> </blockquote> <p><img alt="" height="322" src="https://i-blog.csdnimg.cn/direct/91d3de3f2fbb036560aaff0ba6.png" width="1200" /> <img alt="" height="394" src="https://i-blog.csdnimg.cn/direct/0695d8cc1ed54e8fb8303e6338ffb1c4.png" width="1200" /></p> <p><img alt="" height="431" src="https://i-blog.csdnimg.cn/direct/be4c0baf8062c07f0832c.png" width="1200" /></p> <h4> 5.2.3 xargs命令</h4> <blockquote> <p>使用方式 xargs 选项 文件</p> <p>选项</p> <p><span style="color:#fe2c24;"> -a file 从文件中读入作为sdtin </span></p> <p>-E flag flag必须是一个以空格分隔的标志,当xargs分析到含有flag这个标志的时候就停止。 </p> <p>-p 当每次执行一个argument的时候询问一次用户。 </p> <p><span style="color:#fe2c24;">-n num 后面加次数,表示命令在执行的时候一次用的argument的个数,默认是用所有的。 </span></p> <p>-t 表示先打印命令,然后再执行。 </p> <p><span style="color:#fe2c24;">-i 或者是-I,将xargs接收的每项名称,逐行赋值给 {},可以用 {} 代替。</span> </p> <p>-r no-run-if-empty 当xargs的输入为空的时候则停止xargs,不用再去执行了。 </p> <p><span style="color:#fe2c24;">-d delim 分隔符,默认的xargs分隔符是回车,argument的分隔符是空格,这里修改的是xargs的分 隔符。</span></p> </blockquote> <p> <img alt="" height="733" src="https://i-blog.csdnimg.cn/direct/ebde2374fe284d688fee072e64cec6dd.png" width="548" /></p> <p><img alt="" height="364" src="https://i-blog.csdnimg.cn/direct/2dfd927a1b26b.png" width="1200" /></p> <h4><span style="color:#fe2c24;">5.2.4 文本三剑客</span></h4> <h5><span style="color:#fe2c24;">1.grep 负责从数据源中检索对应的字符串,行过滤</span></h5> <blockquote> <p>使用方法 grep 选项 文件名</p> <p>常见选项:</p> <p><span style="color:#fe2c24;"> -i: 输入要匹配的内容不区分大小写</span><span style="color:#0d0016;"> </span></p> <p><span style="color:#0d0016;">-n: 输入要匹配的内容显示匹配到的内容在源文件行号 </span></p> <p><span style="color:#0d0016;">-r: 逐层遍历目录查找 </span></p> <p><span style="color:#fe2c24;">-v: 查找不包含指定内容的行,反向选择</span></p> <p><span style="color:#fe2c24;">-o: 打印匹配到的关键字 </span></p> <p><span style="color:#fe2c24;">-E: 使用扩展正则匹配 ^key:以关键字开头 key\):以关键字结尾 ^\(:匹配空行</span></p> <p></p> <p><span style="color:#0d0016;">一般选项</span></p> <p><span style="color:#0d0016;">-w: 按单词搜索 </span></p> <p><span style="color:#0d0016;">-c: 统计匹配到的次数 </span></p> <p><span style="color:#fe2c24;">-A: 显示匹配行及后面多少行 </span></p> <p><span style="color:#fe2c24;">-B: 显示匹配行及前面多少行 </span></p> <p><span style="color:#fe2c24;">-C: 显示匹配行前后多少行 </span><span style="color:#0d0016;"> </span></p> <p><span style="color:#0d0016;">-l: 只列出匹配的文件名 </span></p> <p><span style="color:#0d0016;">-L: 列出不匹配的文件名 </span></p> <p><span style="color:#0d0016;">-e: 使用正则匹配</span></p> <p><span style="color:#0d0016;"> --color=auto :可以将找到的关键词部分加上颜色的显示</span></p> <p><span style="color:#0d0016;">常用命令选项必知必会 示例:</span></p> <p># grep -i root passwd 忽略大小写匹配包含root的行</p> <p># grep -w ftp passwd 精确匹配ftp单词</p> <p># grep -wo ftp passwd 打印匹配到的关键字ftp</p> <p># grep -n root passwd 打印匹配到root关键字的行号</p> <p># grep -ni root passwd 忽略大小写匹配统计包含关键字root的行</p> <p># grep -nic root passwd 忽略大小写匹配统计包含关键字root的行数</p> <p># grep -i ^root passwd 忽略大小写匹配以root开头的行</p> <p># grep bash\) passwd 匹配以bash结尾的行 # grep -n ^\( passwd 匹配空行并打印行号</p> <p># grep ^# /etc/vsftpd/vsftpd.conf 匹配以#号开头的行</p> <p># grep -v ^# /etc/vsftpd/vsftpd.conf 匹配不以#号开头的行 # grep -A 5 mail passwd 匹配包含mail关键字及其后5行</p> </blockquote> <h5><span style="color:#fe2c24;"> 2 sed基础</span></h5> <blockquote> <p>使用方法: sed [参数] ' [动作]' [文件名]</p> <p>参数:</p> <p> 参数为空 表示sed的操作效果,实际上不对文件进行编辑,缓存区所有信息都显示 </p> <p><span style="color:#fe2c24;">-n 不输出模式空间内容到屏幕,即不自动打印所有内容 </span> </p> <p>-e 基于命令实现对文件的多点编辑操作 </p> <p><span style="color:#0d0016;">-f 从指定文件中读取编辑文件的”匹配条件+动作” </span></p> <p><span style="color:#fe2c24;">-r 支持使用扩展正则表达式 </span></p> <p>-i.bak 复制文件原内容到备份文件,然后对原文件编辑 </p> <p><span style="color:#fe2c24;">-i 表示对文件进行编辑</span></p> <p><span style="color:#fe2c24;">-g 所有内容</span></p> <p>匹配条件分为两种:数字行号或者关键字匹配</p> <p>数字行号: 空 表示所有行 n 表示第n行 \) 表示末尾行
n,m 表示第n到m行内容 n,+m 表示第n到n+m行
~步进 1~2 表示奇数行 2~2 表示偶数行
关键字匹配格式
‘/关键字/’
注意:
隔离符号 / 可以更换成 @、#、!等符号
根据情况使用,如果关键字和隔离符号有冲突,就更换成其他的符号即可。
/关键字1/,/关键字2/ 表示关键字1所在行到关键字2所在行之间的内容
n,/关键字2/ 表示从第n行到关键字2所在行之间的内容
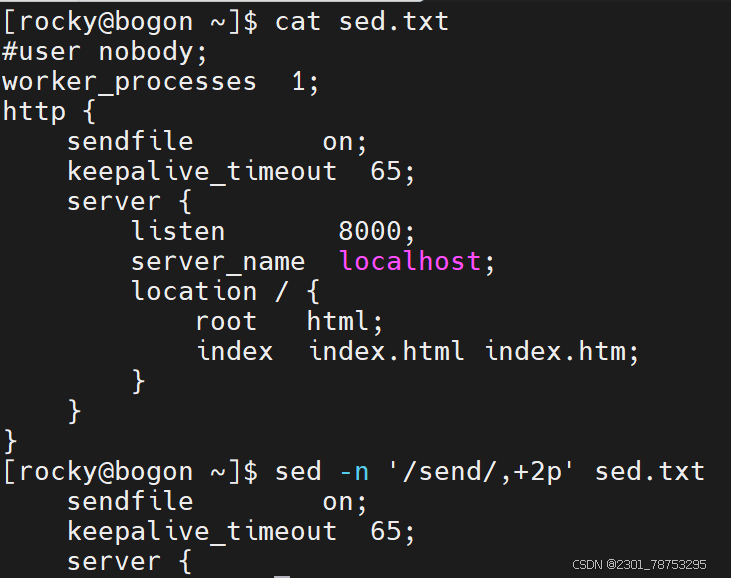
/^/dev/sd/p 第一个 / 是匹配的意思 ^开头 转意 / P打印 打印以/dev/sd 开头的文件
动作详解
-a[ ext] 在匹配到的内容下一行增加内容,支持 实现多行追加
-i[ ext] 在匹配到的内容当前行增加内容
-c[ ext] 在匹配到的内容替换内容
-d|p 删除|打印匹配到的内容
-p 打印匹配到的内容
-s 替换匹配到的内容
W /path/somefile 保存模式匹配的行至指定文件
r /path/somefile 读取指定文件的文本至模式空间中
= 为模式空间中的行打印行号
! 模式空间中匹配行取反处理
注意: 上面的动作应该在参数为-i的时候使用,不然的话不会有效果
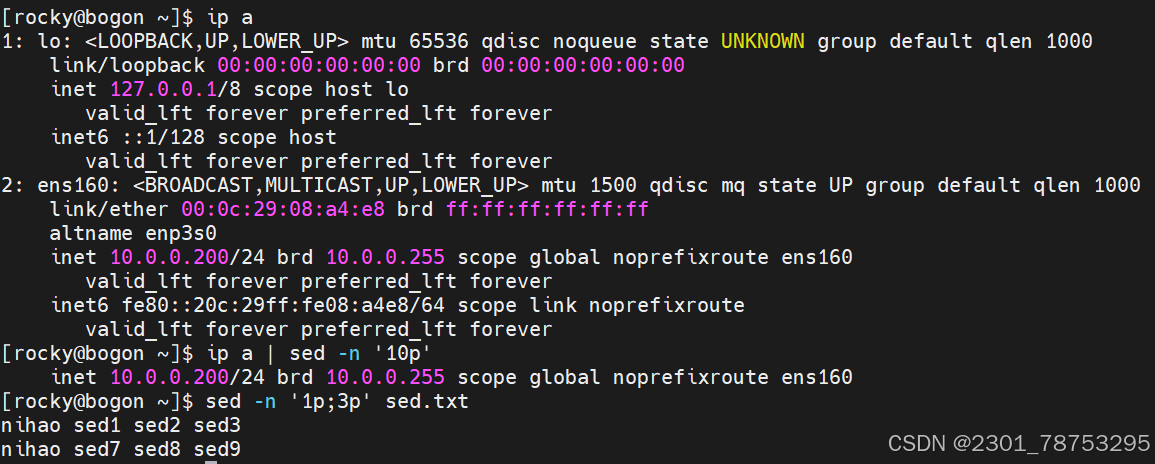
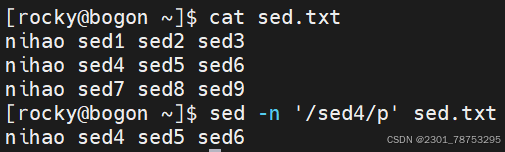
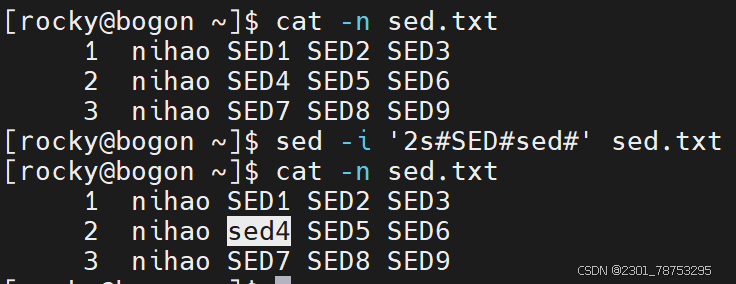
sed替换
命令格式:
sed -i [替换格式] [文件名]
源数据 | sed -i [替换格式]
注意:替换命令的写法
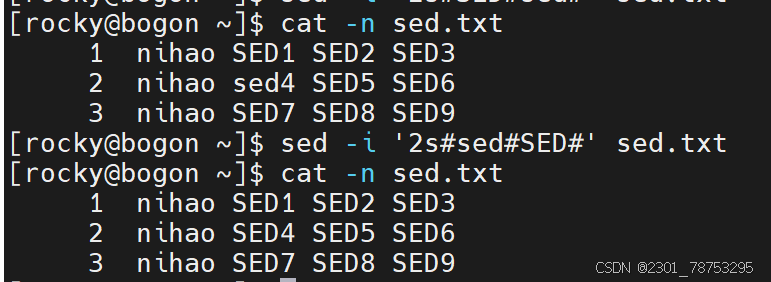
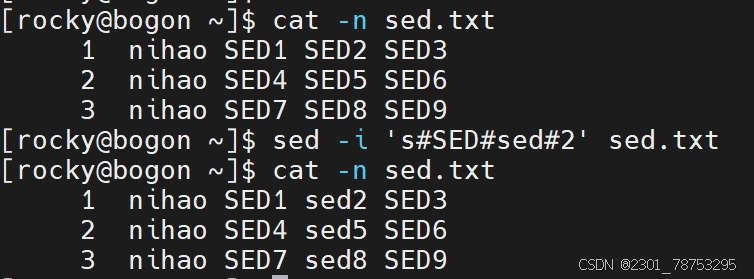
‘s’ —> ‘s#原内容’ —> ‘s#原内容#替换后内容#’
隔离符号 / 可以更换成 @、#、!等符号
表现样式:
样式一:替换指定匹配的内容
sed -i ‘行号s#原内容#替换后内容#列号’ [文件名]
echo “源数据” | sed -i ‘行号s#原内容#替换后内容#列号’
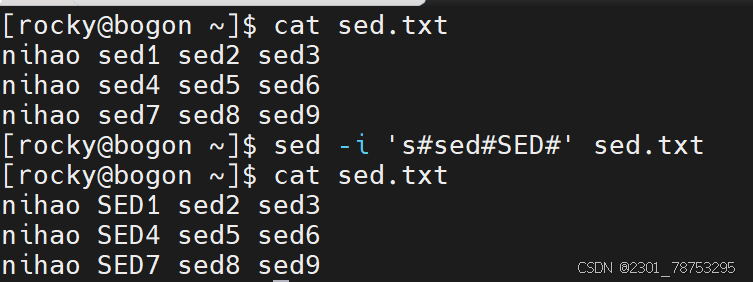
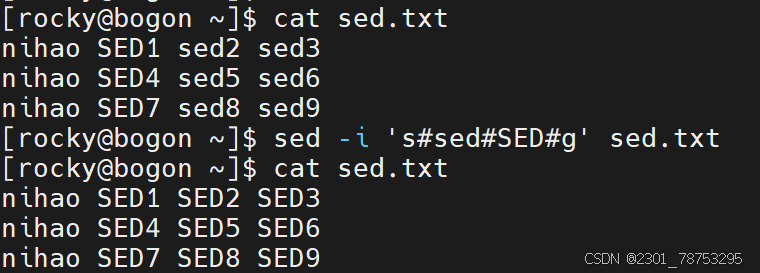
样式二:替换所有的内容
sed -i ‘s#原内容#替换后内容#g’ [文件名]
echo “源数据” | sed -i ‘行号s#原内容#替换后内容#g’
样式三: 替换指定的内容
sed -i ‘行号s#原内容#&新增信息#列号’ [文件名]
- 这里的&符号代表源内容,实现的效果是 ‘原内容+新内容’
sed增加操作
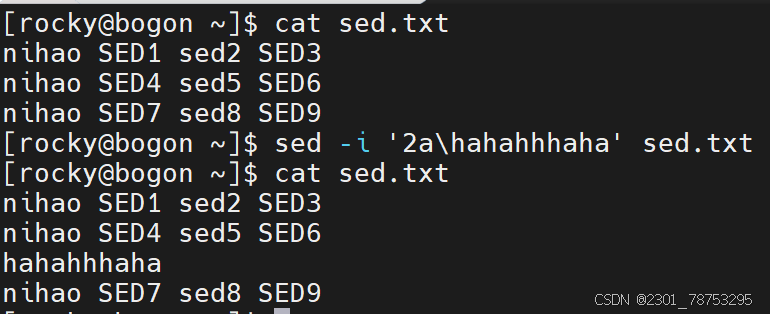
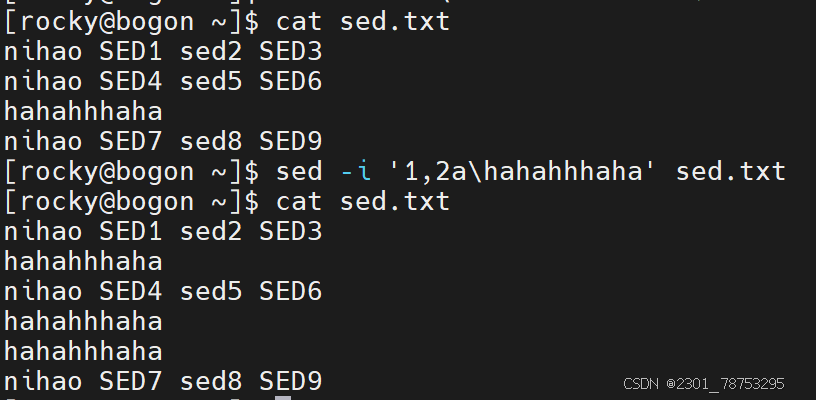
追加
作用:
在指定行号的下一行增加内容
格式:
sed -i ‘行号a增加的内容’ 文件名
注意:
如果增加多行,可以在行号位置写个范围值,彼此间使用逗号隔开,例如 sed -i ‘1,3a增加内容’ 文件名
插入
作用:
在指定行号的当行增加内容
格式:
sed -i ‘行号i增加的内容’ 文件名
注意:
如果增加多行,可以在行号位置写个范围值,彼此间使用逗号隔开,例如 sed -i ‘1,3i增加内容’ 文件名
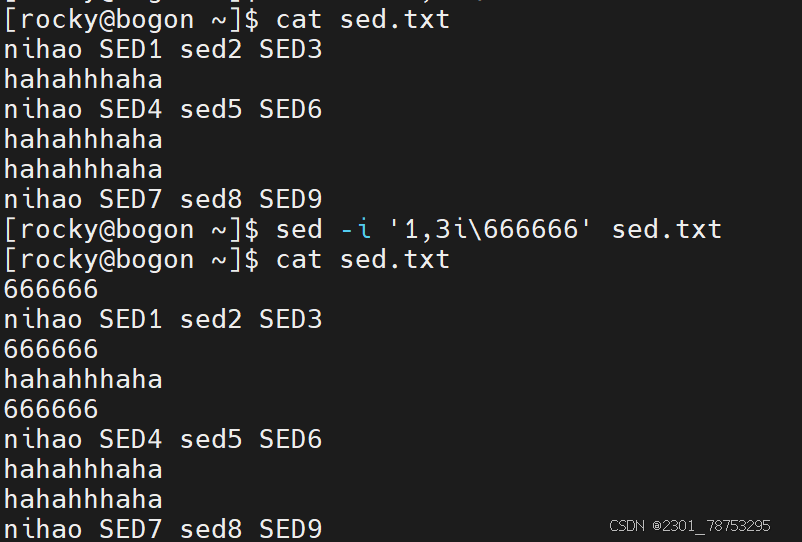
删除替换
作用:
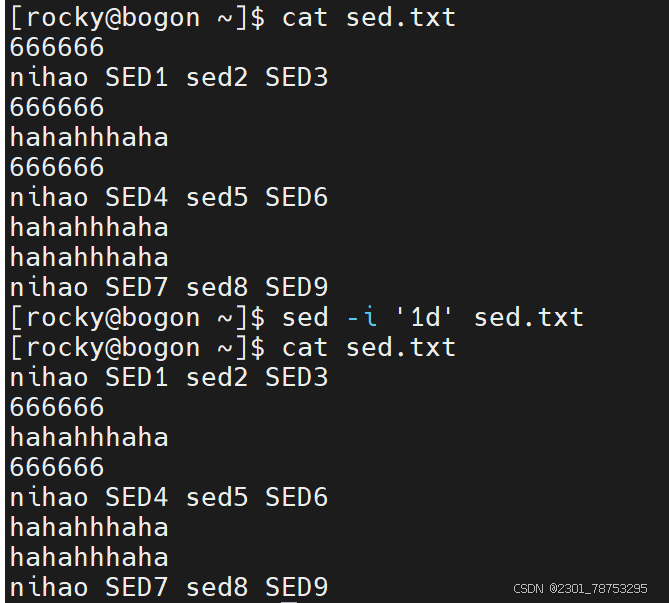
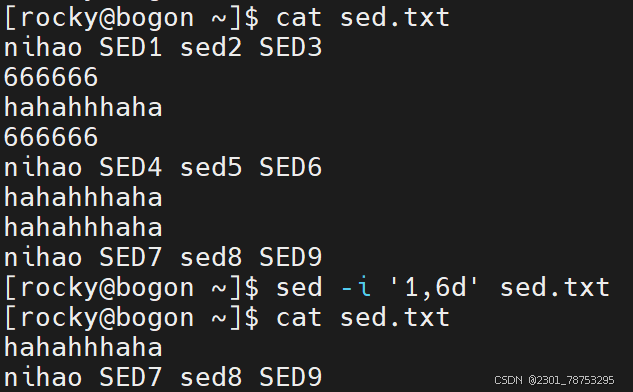
指定行号删除 格式: sed -i ‘行号d’ 文件名
注意:
如果删除多行,可以在行号位置多写几个行号,彼此间使用逗号隔开,例如 sed -i ‘1,3d’ 文件名
替换
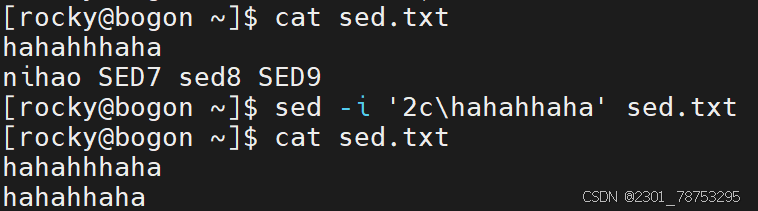
作用:
指定行号进行整行替换
格式:
sed -i ‘行号c内容’ 文件名
注意:
如果替换多行,可以在行号位置多写几个行号,彼此间使用逗号隔开,例如 sed -i ‘1,3c内容’ 文件名
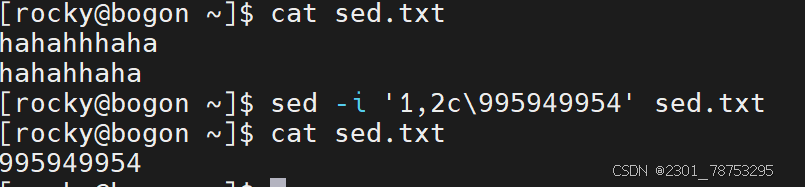
加载保存
作用:
加载文件内容到指定行号的位置
格式:
sed -i ‘行号r 文件名1’ 文件名
注意:
如果在多行位置加载,可以在行号位置多写几个行号,彼此间使用逗号隔开,例如 sed -i ‘1,3r 文件名1’ 文件名
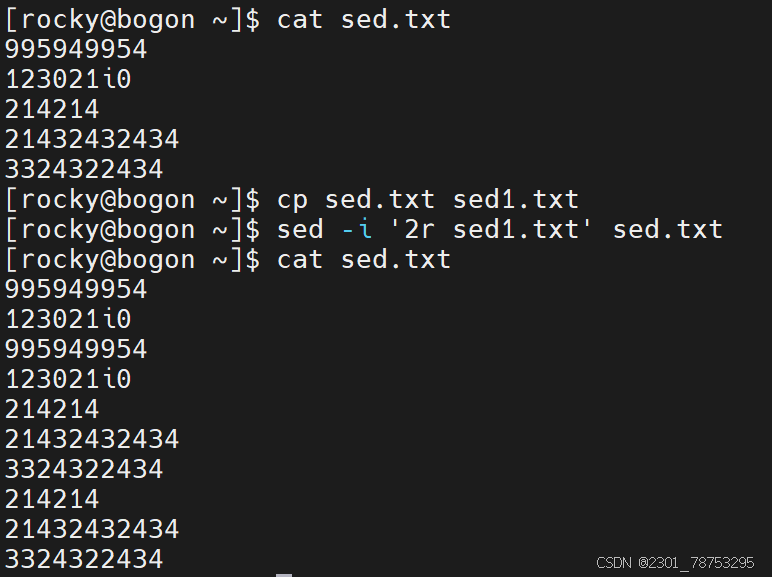
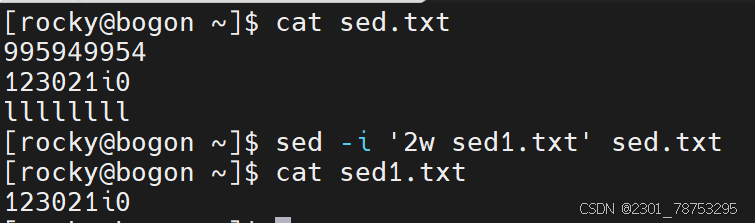
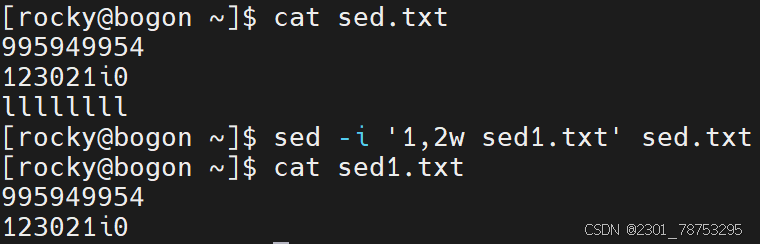
保存实践
作用:
指定行号保存到其他位置
格式:
sed -i ‘行号w 文件名’ 文件名
注意:
如果多行保存,可以在行号位置多写几个行号,彼此间使用逗号隔开,例如 sed -i ‘1,3w 文件名’ 文件名 文件名已存在,则会覆盖式增加
匹配进阶
内容匹配:
‘/关键字内容/’
注意:
隔离符号 / 可以更换成 @、#、!等符号
根据情况使用,如果关键字和隔离符号有冲突,就更换成其他的符号即可。
/关键字1/,/关键字2/ 表示关键字1所在行到关键字2所在行之间的内容
n,/关键字2/ 表示从第n行到关键字2所在行之间的内容
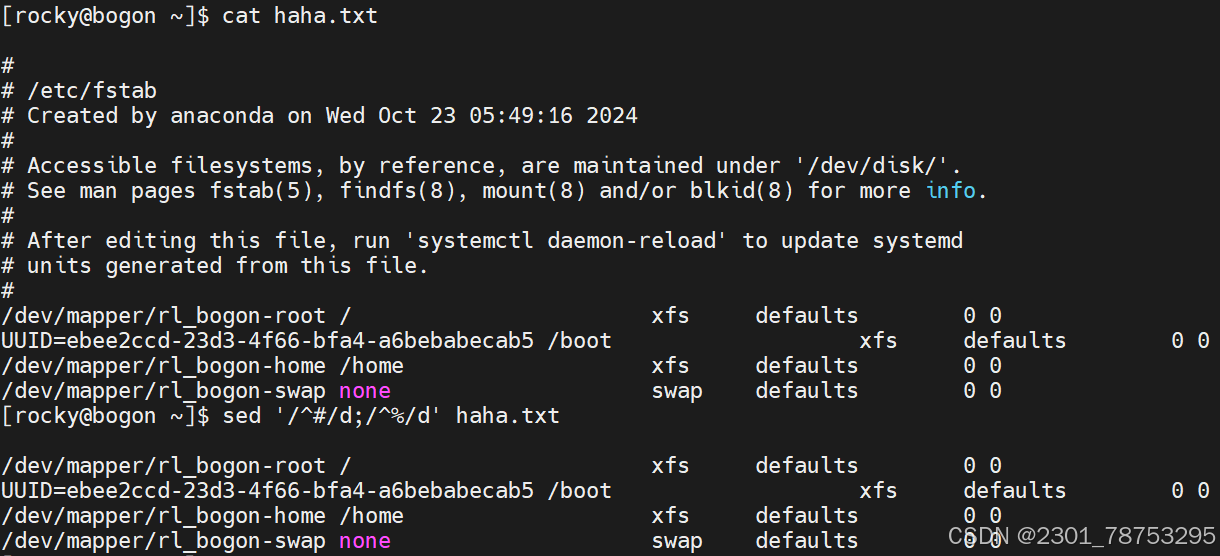
/关键字1/,n, 表示从关键字1所在行到第n行之间的内容
/关键字1/,+n, 表示从关键字1所在行到(所在行+n行)之间的内容
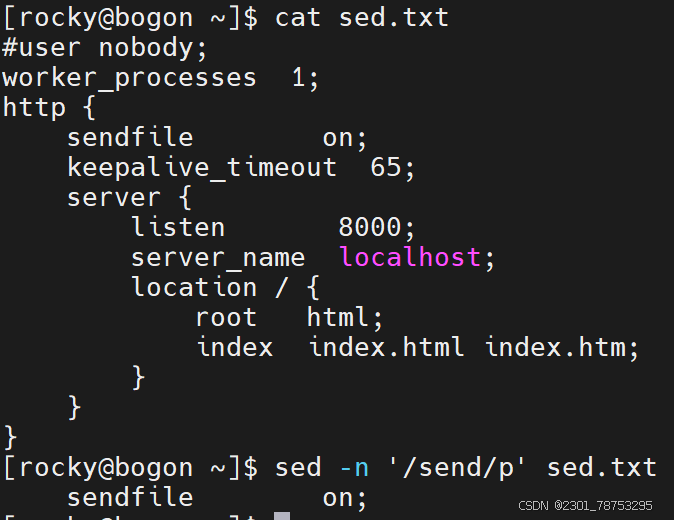
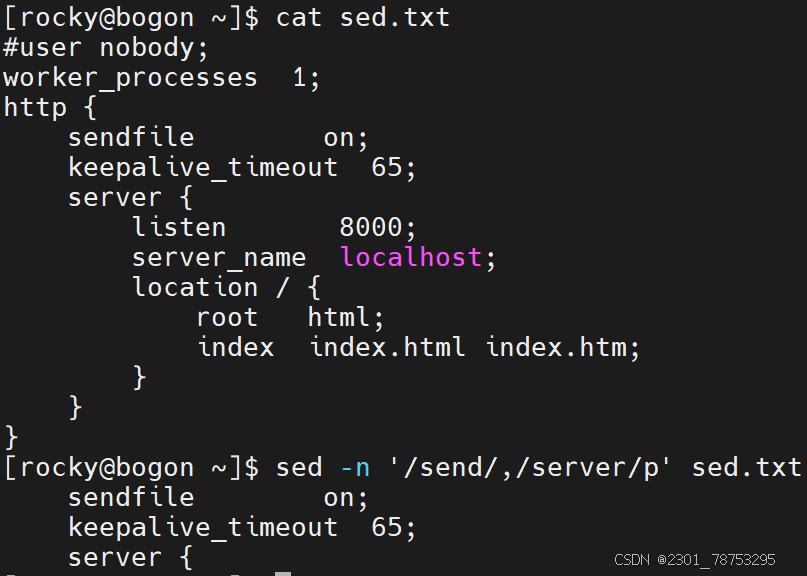
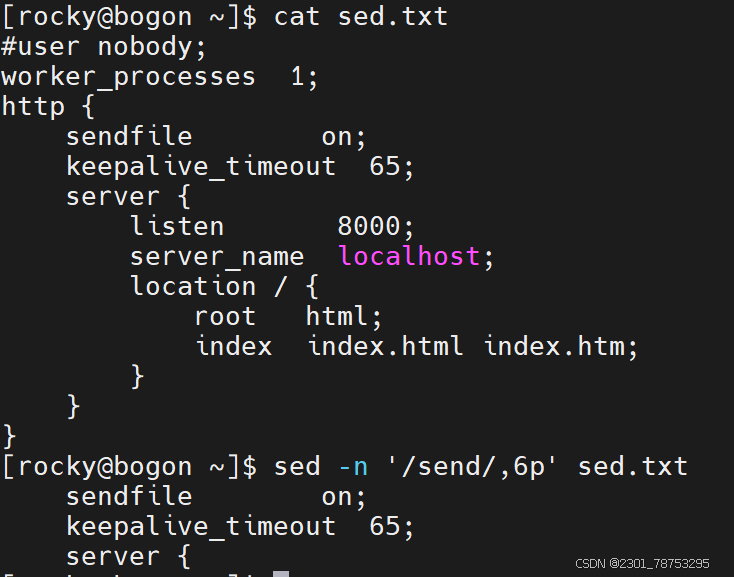
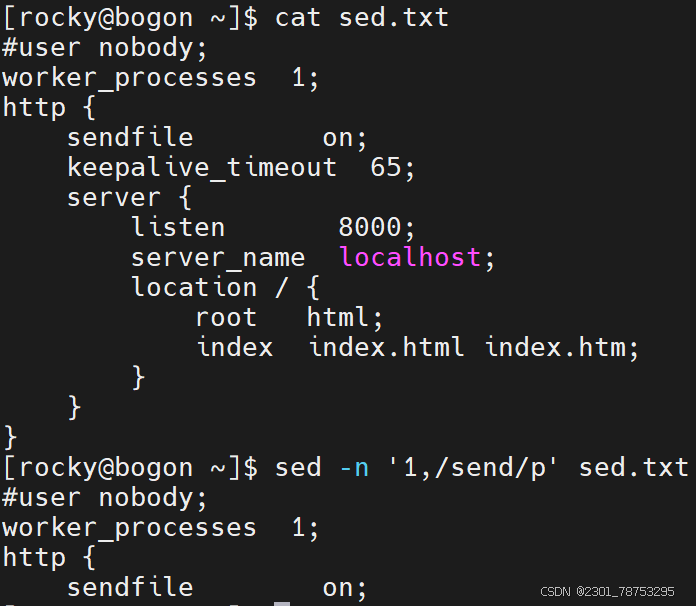
文件处理
我们可以借助 ‘动作1;动作2’ 或者 -e ‘动作1’ -e ‘动作2’ 的方式实现多操作的并行实施
5.2.5AWK基础
使用方法:
awk [参数] ‘[动作]’ [文件名]
awk [参数] –f 动作文件 var=value [文件名]
awk [参数] ‘BEGIN段 [动作] END段’ [文件名]
注意:
动作的格式 ‘匹配条件{打印动作}’
常见参数:
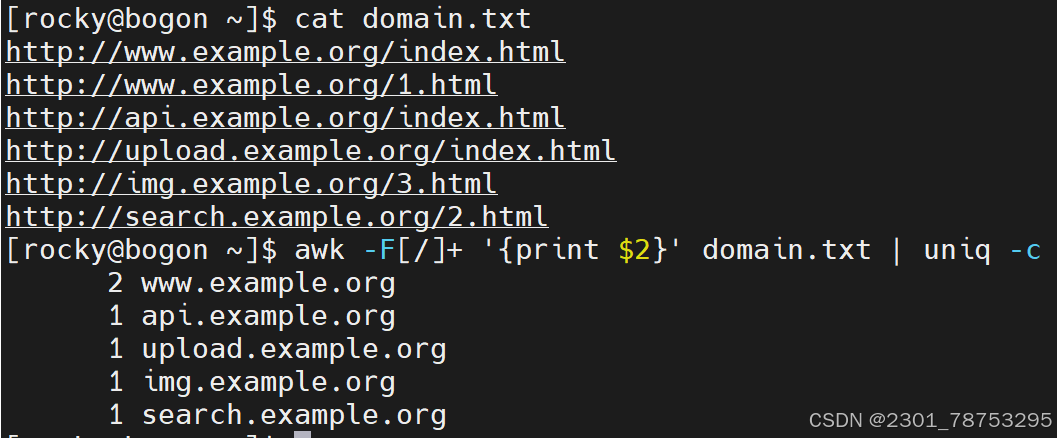
-F 指定列的分隔符,默认一行数据的列分隔符是空格
-f file 指定读取程序的文件名
-v var=value 自定义变量
常见动作
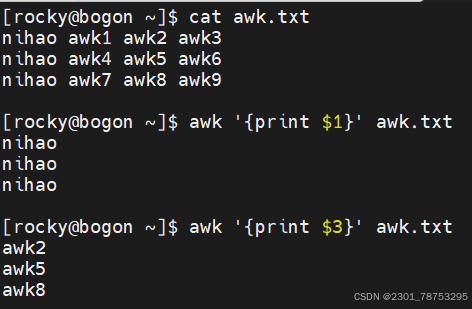
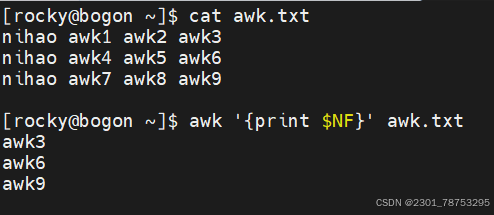
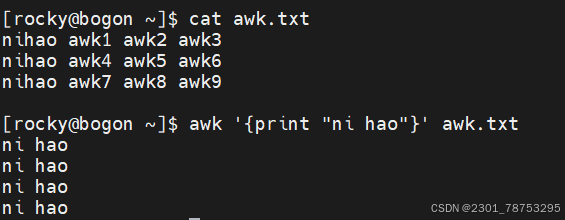
print 显示内容
\(0 显示当前行所有内容 </span></p> <p><span style="color:#fe2c24;">\)n 显示当前行的第n列内容,如果存在多个\(n,它们之间使用逗号(,)隔开</span></p> <p>注意:</p> <p> 如果打印的内容是变量,则无需在变量两侧加上双引号,其他的都应该加双引号</p> </blockquote> <blockquote> <p> 字段提取:提取一个文本中的一列数据并打印输出,它提供了相关的内置变量。 </p> <p> \)0 表示整行文本
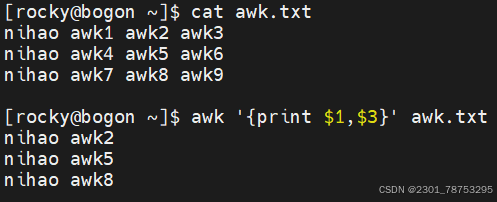
\(1 表示文本行中的第一个数据字段 </p> <p> \)2 表示文本行中的第二个数据字段
\(N 表示文本行中的第N个数据字段 </p> <p> \)NF 表示文本行中的最后一个数据字段
NR 代表行的行号,在动作外部表示特定行
注意:
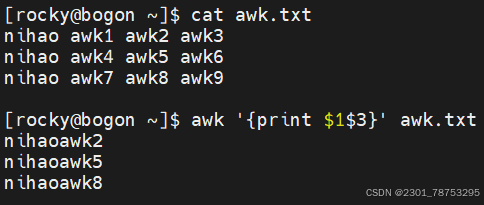
如果打印多列信息,需要使用逗号隔开,否则是内容合并


注意:
一般情况下,在输出信息之前进行格式的调整,需要在BEGIN{}部分设定


显示语法
属性方法
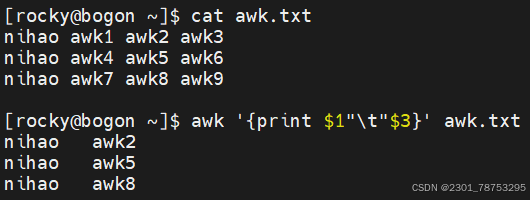
OFS 输出格式的列分隔符,缺省是空格
ORS 输出记录分隔符,输出时用指定符号代替换行符
print方法
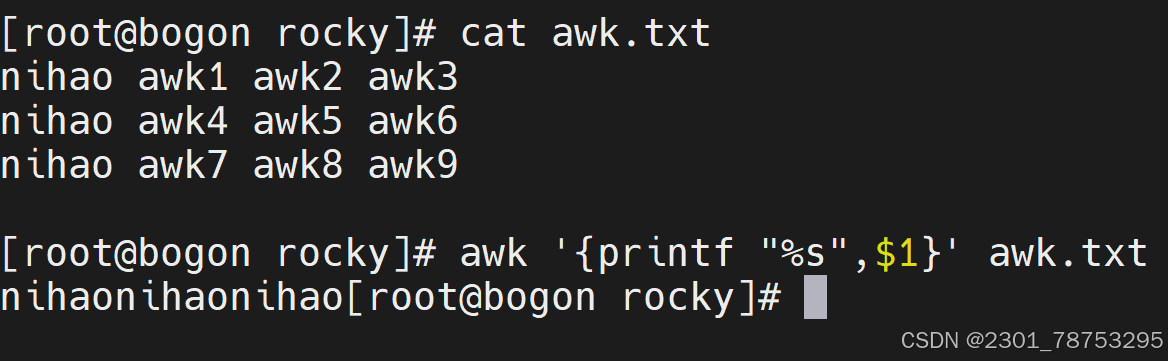
printf [-v var] format [item1,item2,…]
注意:
printf输出需要指定换行符号,format的格式必须与后面item对应
常见格式:
%c 显示字符的ASCII码 %d|i 显示十进制整数
%e|E 显示科学计数法数值 퉳无符号整数
%f 显示浮点数 %s 显示字符串
%% 显示%本身
修饰符:
%#[.#] 第一个#控制显示宽度,第二个#表示小数点后的精度,例如%3.1f
%- 左对齐,%-15s
%+ 显示数值的正负符号,%+d
BEGIN 先执行预处理


printf格式化输出实践

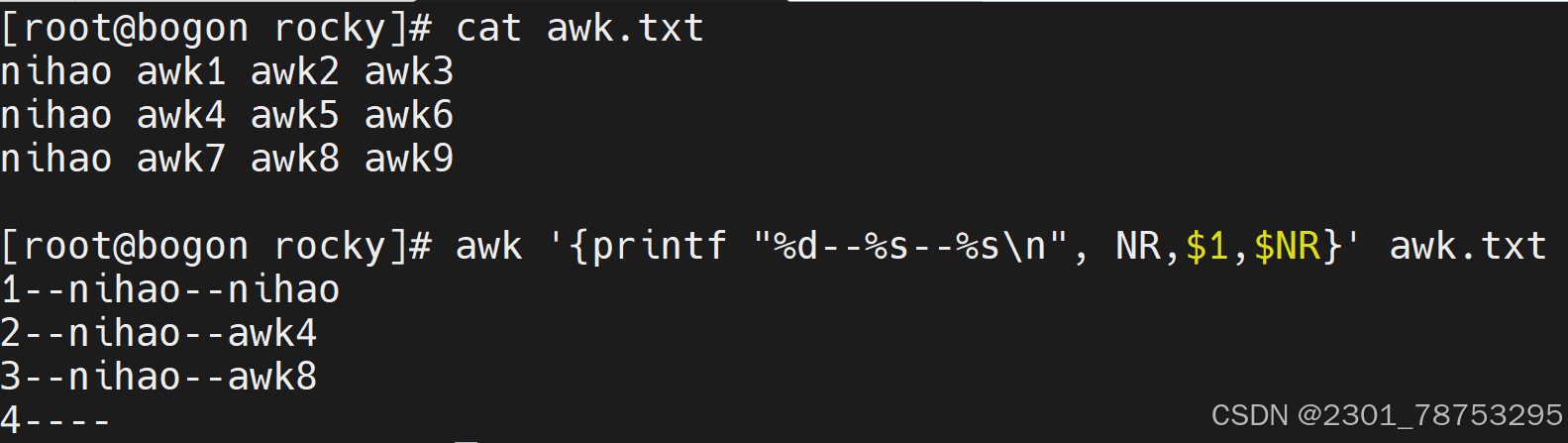
\(1取第一列 \)NR随着行号变化行号是1他就取第一列是二就取第二列 是三就取第三列
优先级
格式显示:
BEGIN{}: 读入第一行文本之前执行的语句,一般用来初始化操作
{}: 逐行处理的执行命令
END{}: 处理完最后以行文本后执行,一般用来处理输出结果
ORS 输出记录分隔符,输出时用指定符号代替换行符
ARGC|ARGV[n] 获取命令的参数个数|参数内容
自定义变量
所谓的自定义变量,主要是根据实际情况,自己定义一些所谓的变量,然后再awk逻辑操作的过程中作为 辅助性的措施。自定义变量的定制方法:
-v var=value
它可以在 命令行、BEGIN、{}、END 等位置进行使用
整个awk选项就记住 NR NF OFS 这三个选项就可以其他的用不上


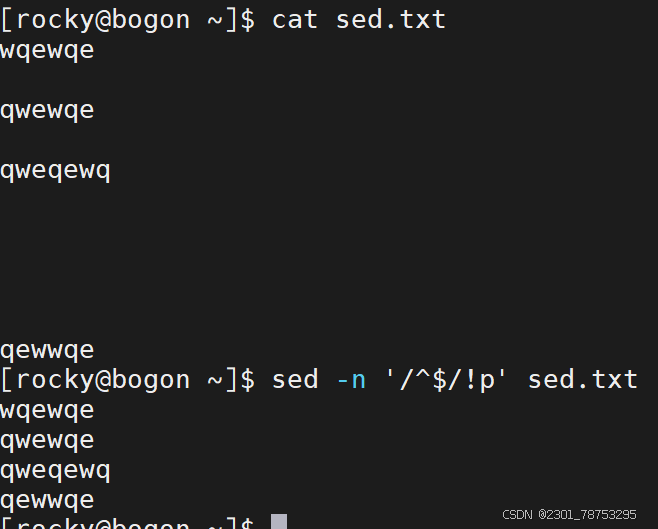
^ PATTERN\( 用于模式匹配整行 </p> <p>^\) 空行
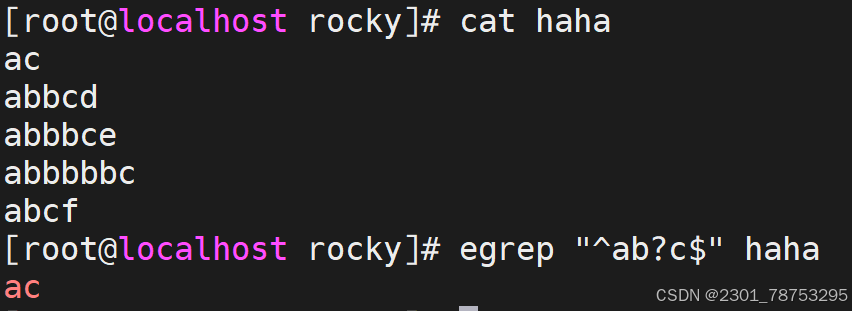
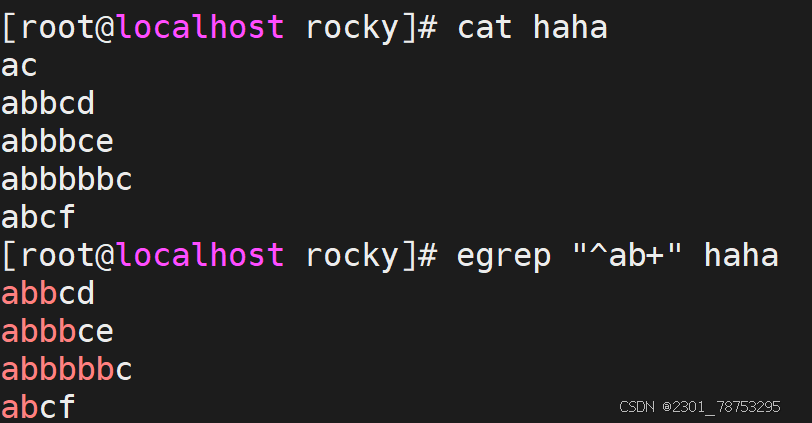
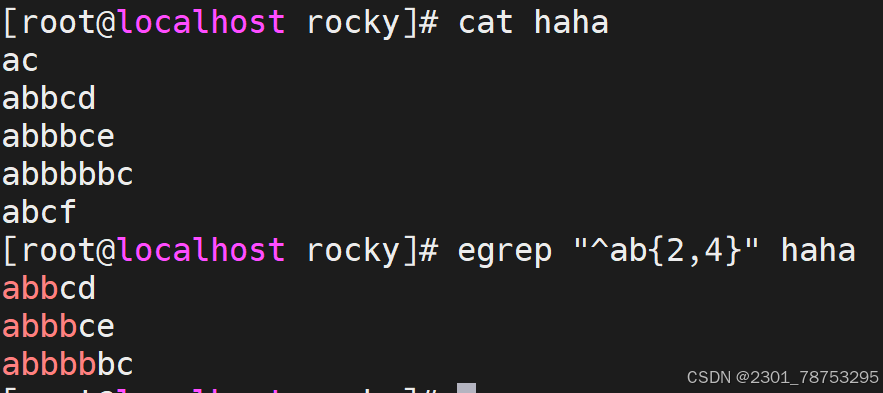
^[[:space:]]*\( 空白行 </p> <p>< 或 b 词首锚定,用于单词模式的左侧 </p> <p>> 或 b 词尾锚定,用于单词模式的右侧 </p> <p><PATTERN> 匹配整个单词</p> <p> - v 取反</p> <p>注意:</p> <p> 单词是由字母,数字,下划线组成</p> </blockquote> <figure class="image"> <img alt="" height="411" src="https://i-blog.csdnimg.cn/direct/1e4e84d8dbdc662fc5344f626.png" width="526" /> <figcaption> 行首锚碇以work开头的行 </figcaption> </figure> <p> </p> <figure class="image"> <img alt="" height="414" src="https://i-blog.csdnimg.cn/direct/2cbfba738f76460a8d07e8601d1434cf.png" width="495" /> <figcaption> 行尾锚碇匹配以tml;结尾的行 </figcaption> </figure> <p> </p> <figure class="image"> <img alt="" height="329" src="https://i-blog.csdnimg.cn/direct/2cd324d349efffa2735a63d8a.png" width="413" /> <figcaption> 匹配以http开头以{结尾的行 </figcaption> </figure> <p> </p> <figure class="image"> <img alt="" height="350" src="https://i-blog.csdnimg.cn/direct/bba699da9f3a4a3c9ba.png" width="377" /> <figcaption> 匹配空行 </figcaption> </figure> <p> </p> <figure class="image"> <img alt="" height="500" src="https://i-blog.csdnimg.cn/direct/59f9b903e91b456c8f7830de5cd17a23.png" width="412" /> <figcaption> -v取反除了空白行剩下都要 </figcaption> </figure> <p> </p> <figure class="image"> <img alt="" height="271" src="https://i-blog.csdnimg.cn/direct/52baab788e9c4726ae4fc0bf0b49af47.png" width="411" /> <figcaption> b匹配单词以loca首部行 或用v </figcaption> </figure> <p> </p> <figure class="image"> <img alt="" height="284" src="https://i-blog.csdnimg.cn/direct/f0fb4833aae1bbea650a8832.png" width="414" /> <figcaption> b匹配单词以tion尾部行 或用v </figcaption> </figure> <h5>分组符号</h5> <blockquote> <p>所谓的分组,其实指的是将我们正则匹配到的内容放到一个()里面 </p> <p> - 每一个匹配的内容都会在一个独立的()范围中 </p> <p> - 按照匹配的先后顺序,为每个()划分编号 </p> <p> - 第一个()里的内容,用 1代替,第二个()里的内容,用2代替,依次类推 </p> <p> - 0 代表正则表达式匹配到的所有内容</p> <p></p> <p>注意:</p> <p> () 范围中支持|等字符匹配内容。从而匹配更多范围的信息</p> <p> 关于()信息的分组提取依赖于文件的编辑工具,我们可以借助于 sed、awk功能来实现</p> <p>提示: sed -r 's/原内容/修改后内容/'</p> </blockquote> <p></p> <figure class="image"> <img alt="" height="152" src="https://i-blog.csdnimg.cn/direct/07f16544ae83ce2aab.png" width="936" /> <figcaption> 过滤haha文件中有server.1的内容 sed -r支持正则扩展 ()中.*代表任意长度字符串用=和:隔开内容/是s/结束 是转义1/ 1/代表第一个括号中的内容 </figcaption> </figure> <p></p> <p> <img alt="" height="137" src="https://i-blog.csdnimg.cn/direct/f433aebc808fb8cd2466ccff.png" width="674" /></p> <h5>限定符号</h5> <blockquote> <p>常见符号</p> <p>* 匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配 </p> <p>.* 任意长度的任意字符 </p> <p>? 匹配其前面的字符出现0次或1次,即:可有可无 </p> <p>+ 匹配其前面的字符出现最少1次,即:肯定有且 >=1 次 </p> <p>{m} 匹配前面的字符m次 </p> <p>{m,n} 匹配前面的字符至少m次,至多n次 </p> <p>{,n} 匹配前面的字符至多n次,<=n </p> <p>{n,} 匹配前面的字符至少n次</p> </blockquote> <figure class="image"> <img alt="" height="235" src="https://i-blog.csdnimg.cn/direct/6f173f3052c54016a943ea931bb5da1d.png" width="523" /> <figcaption> ^ab*c\)以ab开头中间任意字符c结尾
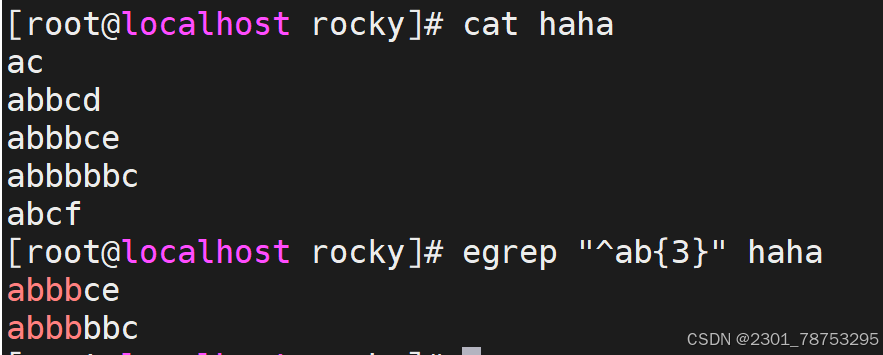
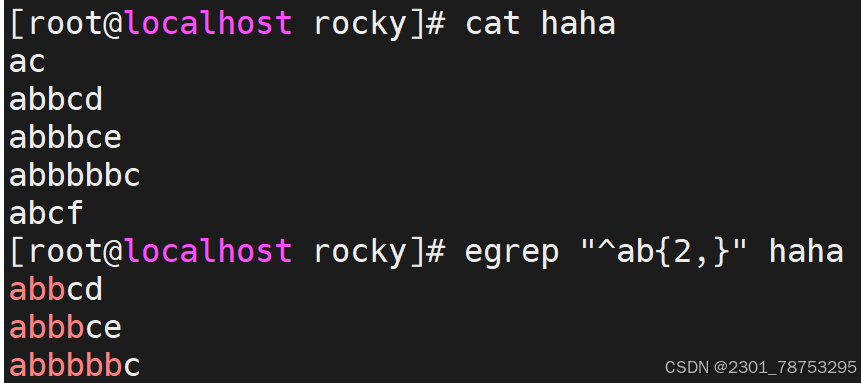
扩展符号
字母模式匹配
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母,示例:[[:lower:]],相当于[a-z]
[:upper:] 大写字母
数字模式匹配
[:digit:] 十进制数字
[:xdigit:]十六进制数字
符号模式匹配
[:blank:] 空白字符(空格和制表符)
[:space:] 包括空格、制表符(水平和垂直)、换行符、回车符等各种类型的空白
[:cntrl:] 不可打印的控制字符(退格、删除、警铃…)
[:graph:] 可打印的非空白字符
[:print:] 可打印字符 [
:punct:] 标点符号
注意:
在使用该模式匹配的时候,一般用[[ ]],
- 第一个中括号是匹配符[] 匹配中括号中的任意一个字符
- 第二个[]是格式 如[:digit:]
就记这两个
[:blank:] 空白字符(空格和制表符)
[:space:] 包括空格、制表符(水平和垂直)、换行符、回车符等各种类型的空白

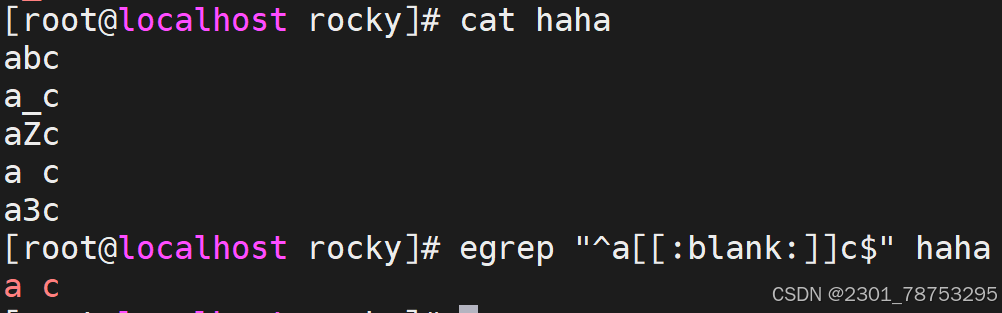
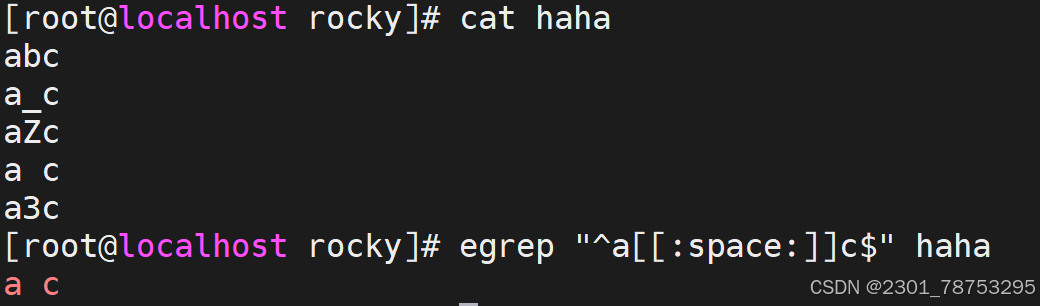
目标检测
定制站点或目标主机的检测平台,在对站点域名和主机ip检测之前,判断输入的语法是否正确。


6.1.1 locate命令
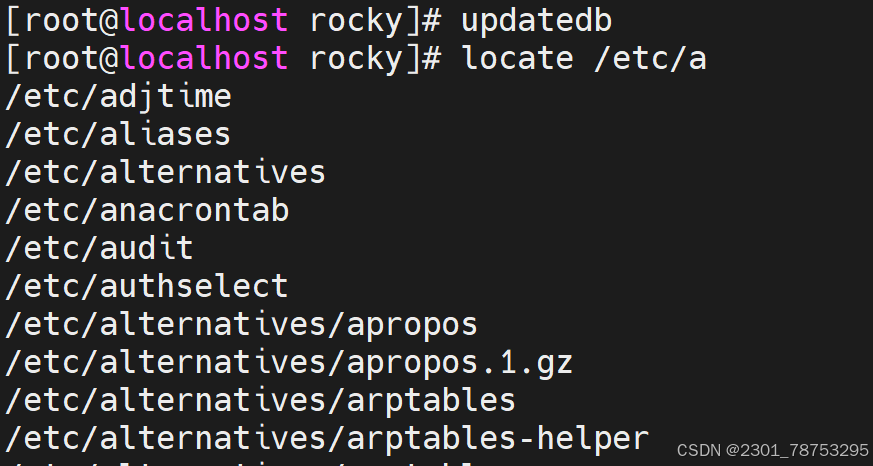
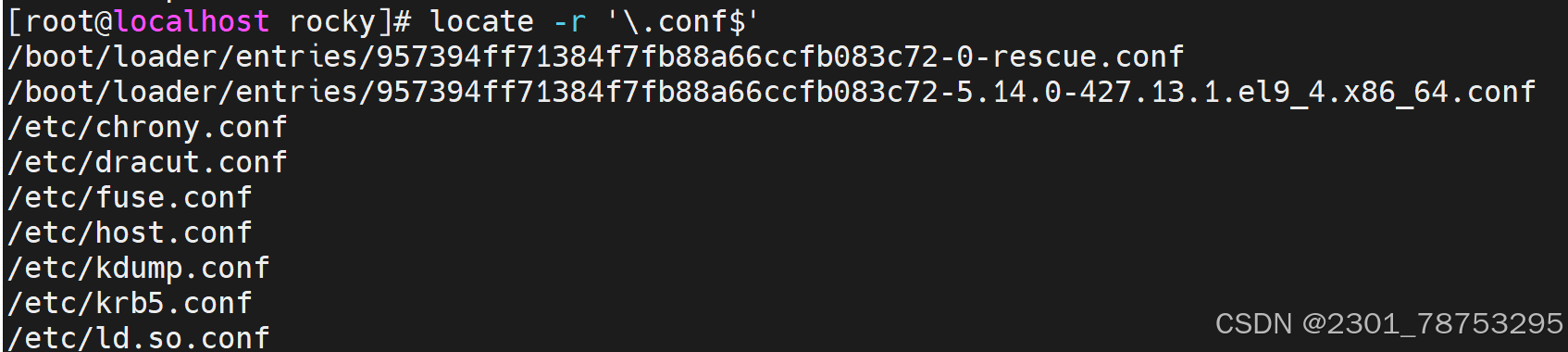
命令格式: locate [OPTIONS] PATTERN
一般选项
-i: 忽略大小写地匹配模式。例如,locate -i myfile会同时匹配“myfile”、“MyFile”等。
-c: 只显示匹配项的数量(count),而不是文件名。
-l NUM: 限制输出的行数,每行显示一个匹配项。
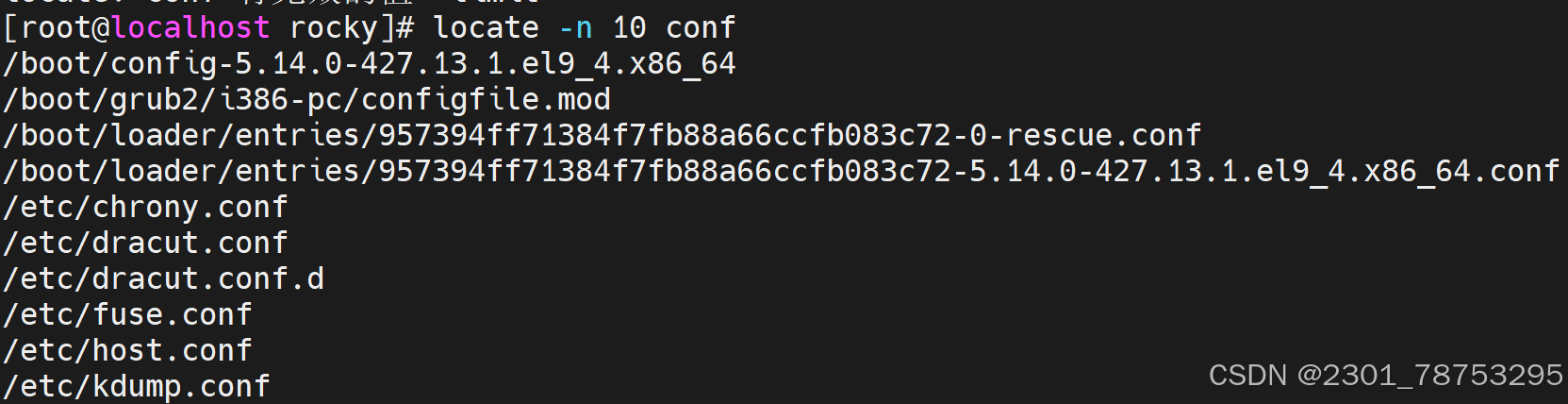
-n NUM: 限制输出的匹配项数目,只显示前NUM个结果。
-r: 使用正则表达式模式匹配。例如,locate –regex ‘..txt$’会匹配所有以“.txt”结尾的文 件。
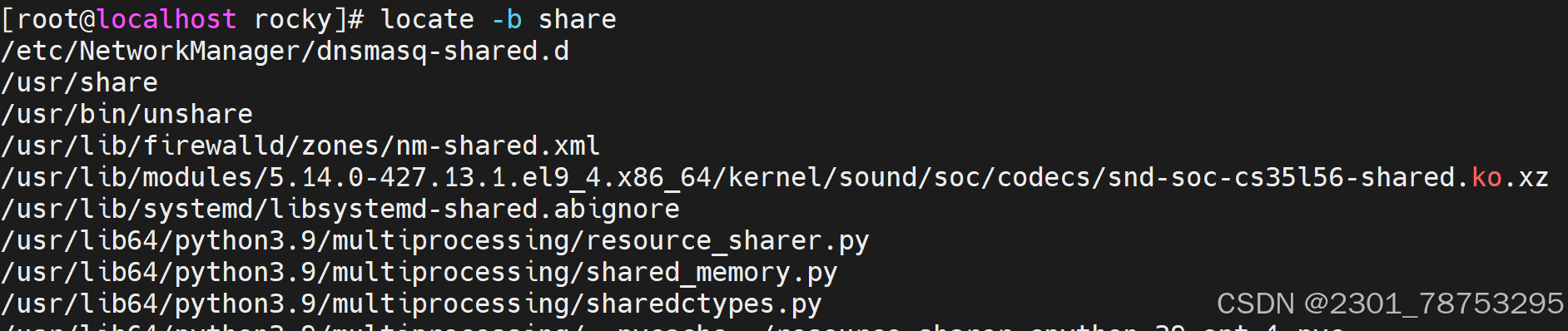
-b: 只匹配基准名,忽略路径。
-w: 仅匹配完整单词。
-A|–all #输出所有能匹配到的文件名,不管文件是否存在
-b|–basename #仅匹配文件名部份,而不匹配路径中的内容
-c|–count #只输出找到的数量
-d|–database DBPATH #指定数据库
-e|–existing #仅打印当前现有文件的条目
-L|–follow #遇到软链接时则跟随软链接去其对应的目标文件中查找 (默认)
-i|–ignore-case #忽略大小写 -l|–limit|-n N #只显示前N条匹配数据
-P|–nofollow, -H #不跟随软链
-r|–regexp REGEXP #使用基本正则表达式
–regex #使用扩展正则表达式
-s|–stdio #忽略向后兼容
-w|–wholename #全路径匹配,就是只要在路径里面出现关键字(默认)
updatedb 更新数据库
安装环境
Rocky系统 yum install -y mlocate
ubuntu系统 apt install -y Plocate
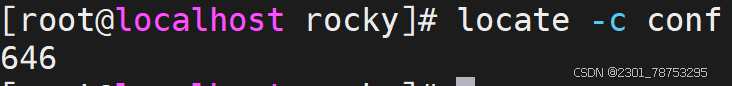
6.1.2 find命令
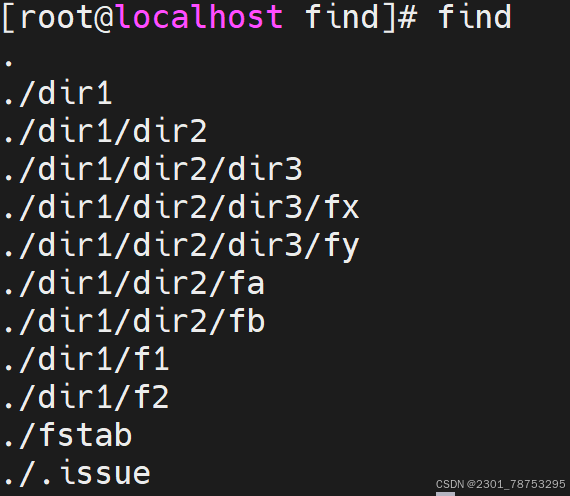
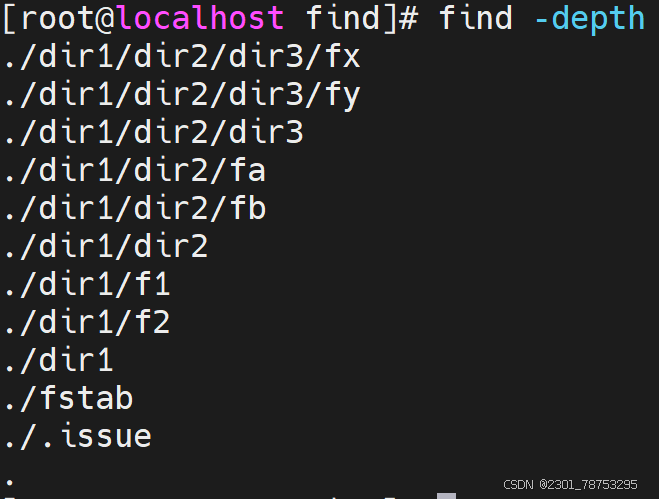
使用方法; find [搜索路径] [选项] [表达式]
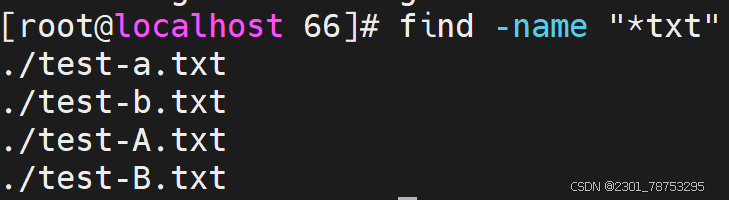
常用选项
-name:按文件名匹配,区分大小写。支持使用glob,如:, ?, [], [^],通配符要加双引号引起来
-type:按文件类型搜索。常用类型包括f(普通文件)、d(目录)、l(符号链接)等。
-size:按文件大小搜索。单位可以是c(字节)、k(千字节)、M(兆字节)、G(千兆字节)等。例 如,-size +10M查找大于10MB的文件。
-mtime:按天数查找文件最后修改时间。例如,-mtime -7查找最近7天内修改的文件
-user:按文件所有者查找。
-group:按文件所属组查找。
-perm:按文件权限查找。
-maxdepth:限制搜索的最大深度。
-mindepth:限制搜索的最小深度。
-regextype type: 正则表达式类型,emacs|posix-awk|posix-basic|posiegrep|posixextended
-regex pattern: 正则表达式


类型查找
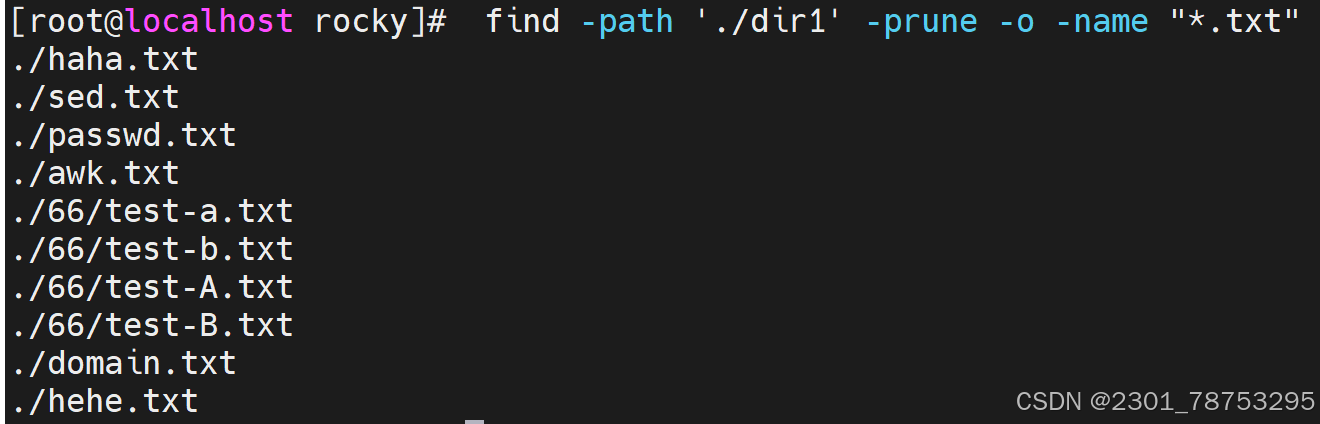
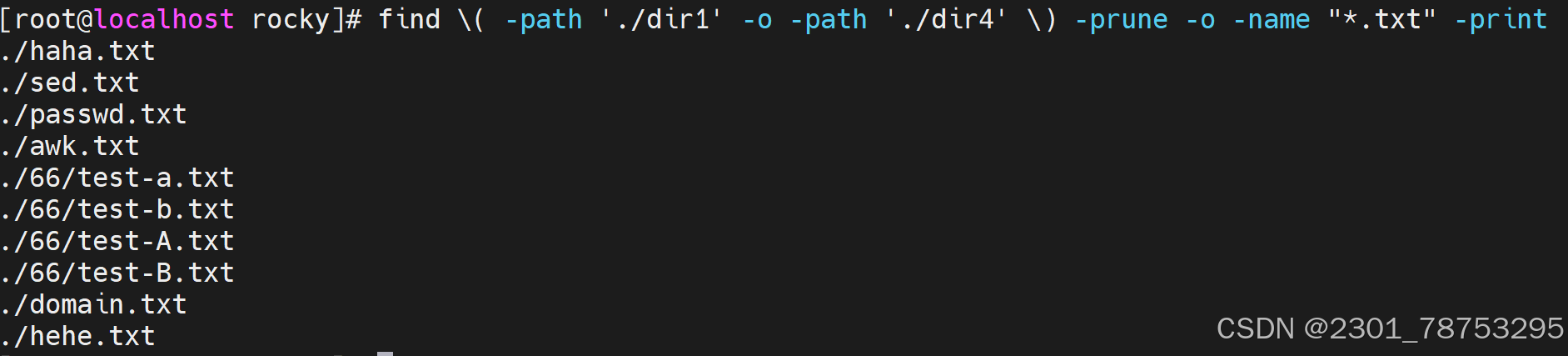
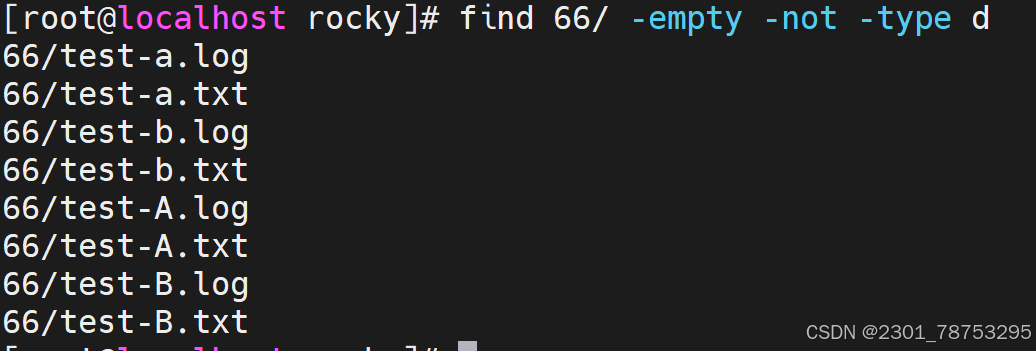
-empty #空文件或空目录
-prune #跳过,排除指定目录,必须配合 -path使用 -path路径
-type TYPE #指定文件类型 *
type 值
f #普通文件
d #目录文件
l #符号链接文件
s #套接字文件
b #块设备文件
c #字符设备文件
p #管道文件




组合查找
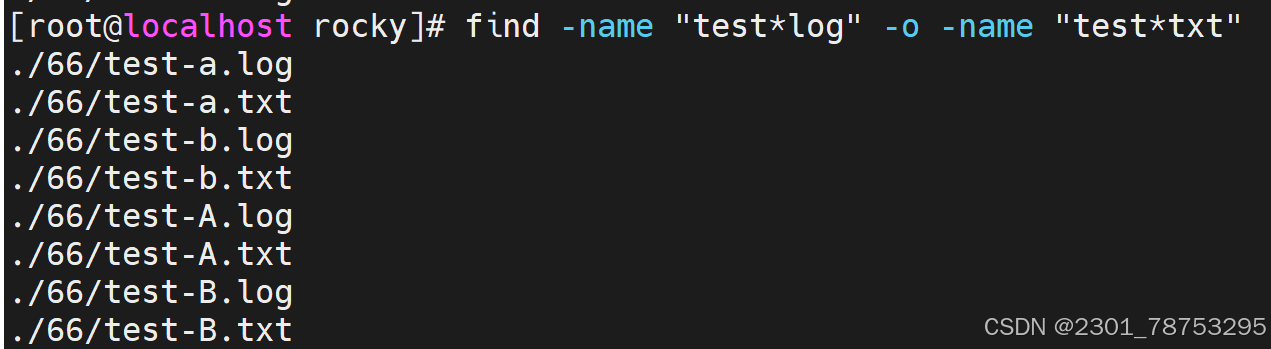
-a #与,多条件默认就是与关系,可省略
-o #或
-not|! #非

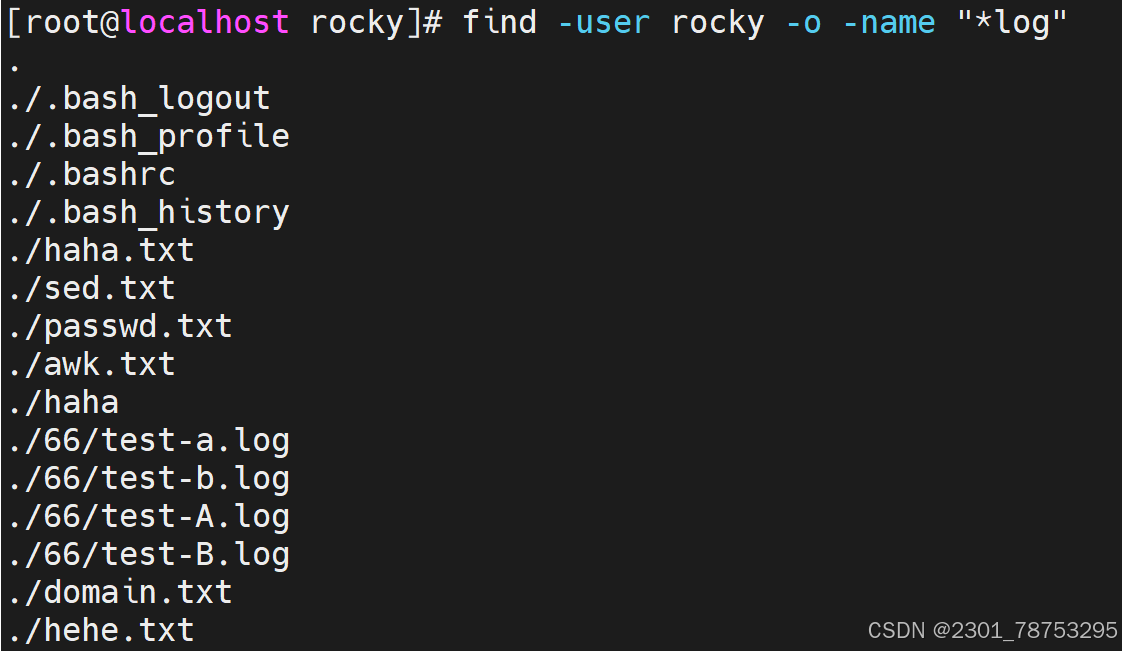

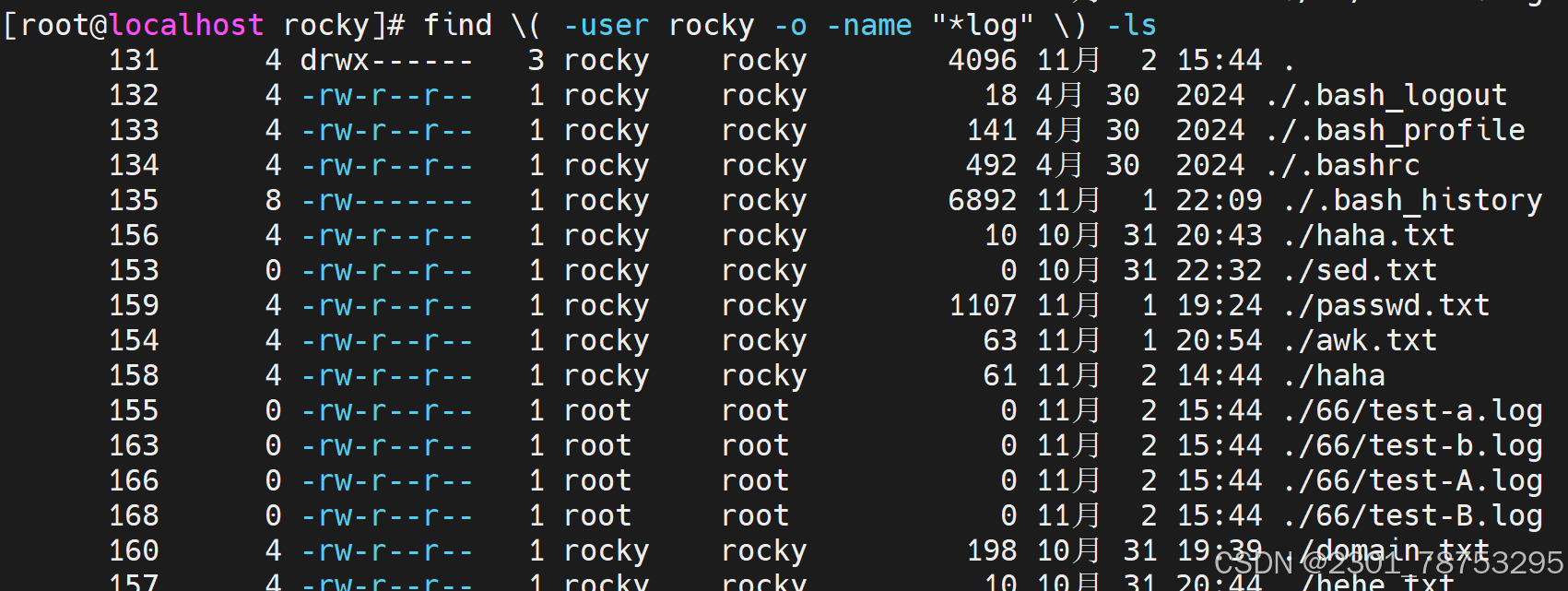
文件属性查找
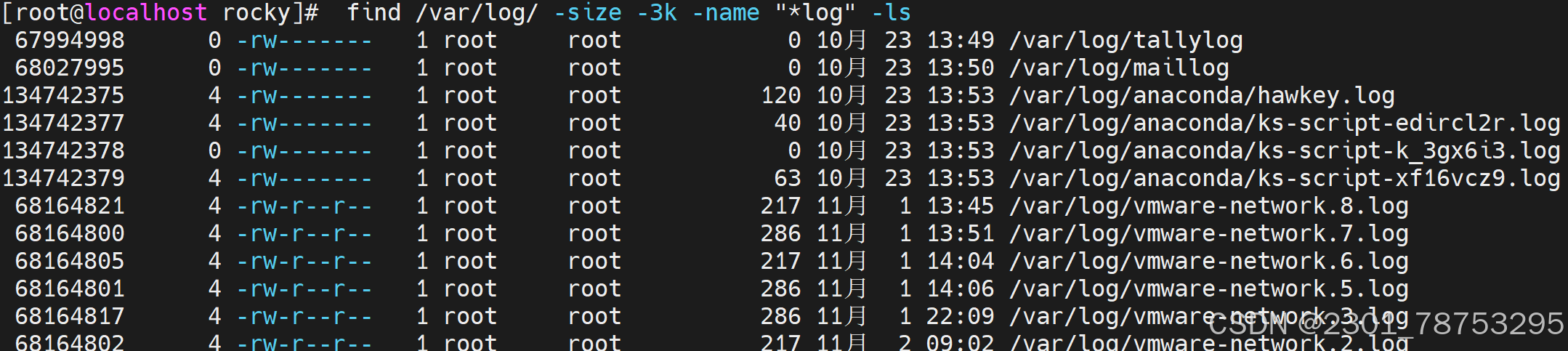
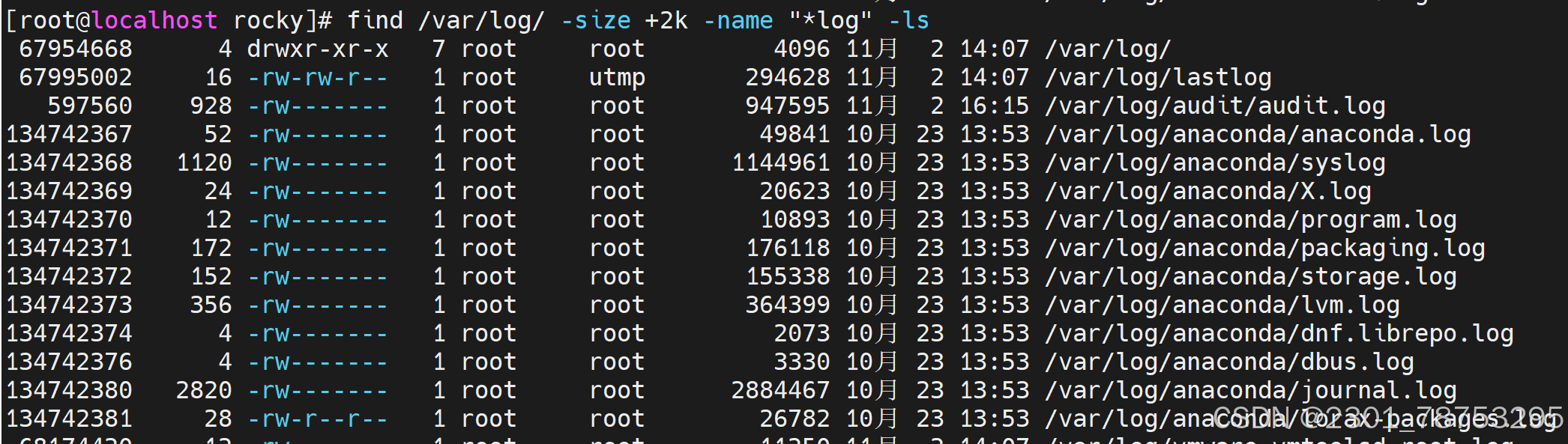
-size [+|-]N UNIT # N为数字,UNIT为常用单位 k, M, G, c(byte) 等
#解释
10k #表示(9k,10k],大于9k 且小于或等于10k
-10k #表示[0k,9k],大于等于0k 且小于或等于9k
+10k #表示(10k,∞),大于10k
文件时间属性解读
以天为单位
-atime [+|-]N -mtime [+|-]N -ctime [+|-]N
以分钟为单位
-amin [+|-]N -mmin [+|-]N -cmin [+|-]N
#解释
N #表示[N,N+1),大于或等于N,小于N+1,表示第N天(分钟)
+N #表示[N+1,∞],大于或等于N+1,表示N+1天之前(包括)
-N #表示[0,N),大于或等于0,小于N,表示N天(分钟)内



动作进阶
-print #默认的处理动作,显示至屏幕
-print0 #不换行输出,常用于配合xargs
-ls #类似于对查找到的文件执行“ls -ils”命令格式输出
-fls file #查找到的所有文件的长格式信息保存至指定文件中,相当于 -ls > file
-delete #删除查找到的文件,慎用!
-ok COMMAND {} ; #对查找到的每个文件执行由COMMAND指定的命令,对于每个文件执行命令之 前,都会交互式要求用户确认
-exec COMMAND {} ; #对查找到的每个文件执行由COMMAND指定的命令
{} #用于引用查找到的文件名称自身




6.1.3 xargs组合
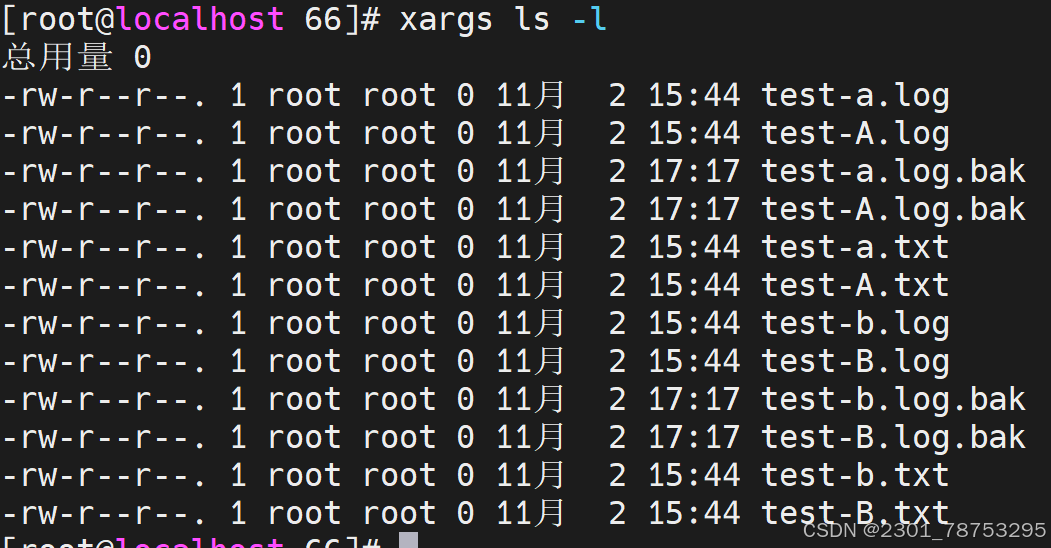
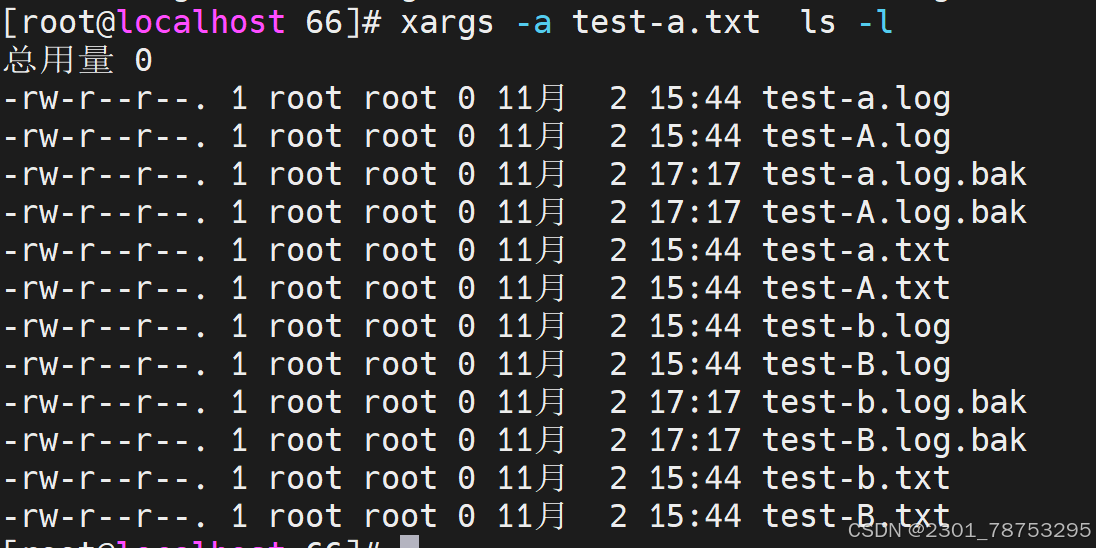
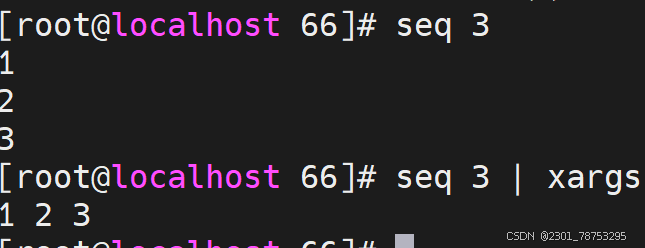
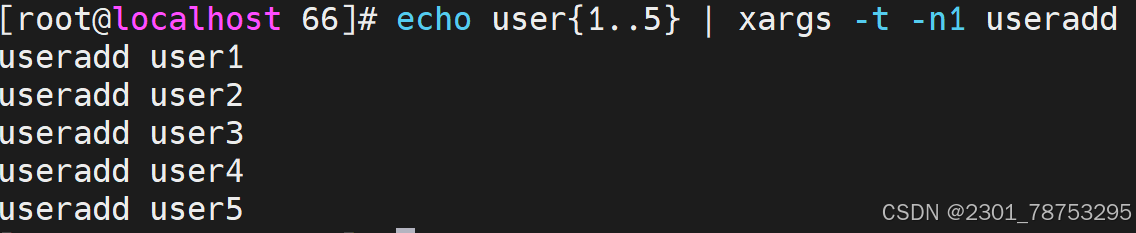
使用方法 xargs 选项 文件
#常用选项
-0|–null #用 assic 中的0或 null 作分隔符
-a|–arg-file=FILE #从文件中读入作为输入
-d|–delimiter=CHARACTER #指定分隔符
-E END #指定结束符,执行到此处时停止,不管后面的数据
-L|–max-lines=N #从标准输入一次读取N行送给 command 命令
-l #同上
-n|–max-args=MAX-ARGS #一次执行用几个参数
-p|–interactive #每次执行前确认
-r|–no-run-if-empty #当xargs的输入为空的时候则停止xargs,不用再去执行了
-s|–max-chars=MAX-CHARS #命令行最大字符数
-t|–verbose #显示过程,先打印要执行的命令
-x|–exit #退出,主要配合-s使用





6.1.4打包压缩
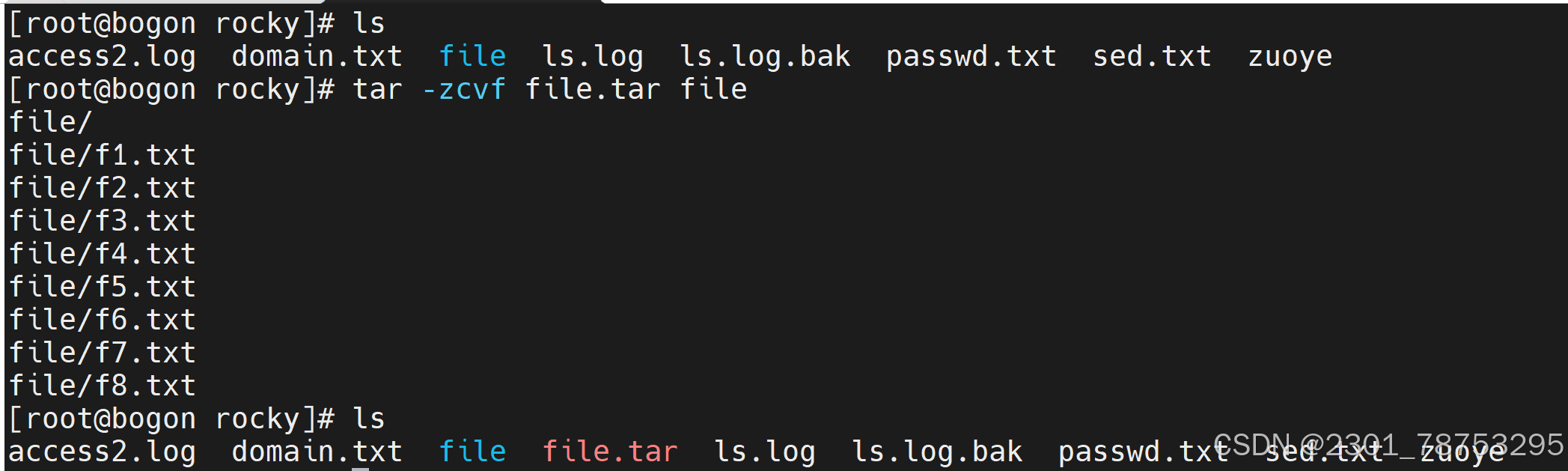
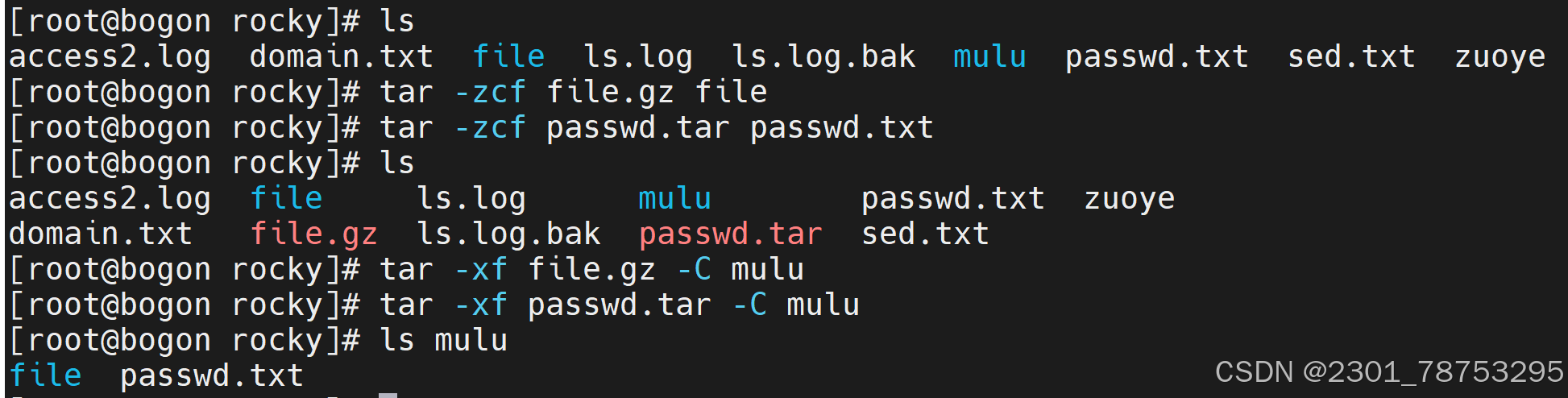
tar包
使用方法 tar 选项 (包类型.tar) 目标文件
tar命令常见选项:
- c 创建一个压缩包
- t 不解压查看压缩包的文件列表
- z tar.gz类型格式的压缩包
- v 显示压缩过程|解压过程
- x 解压一个压缩文件
- f 指定压缩包文件名
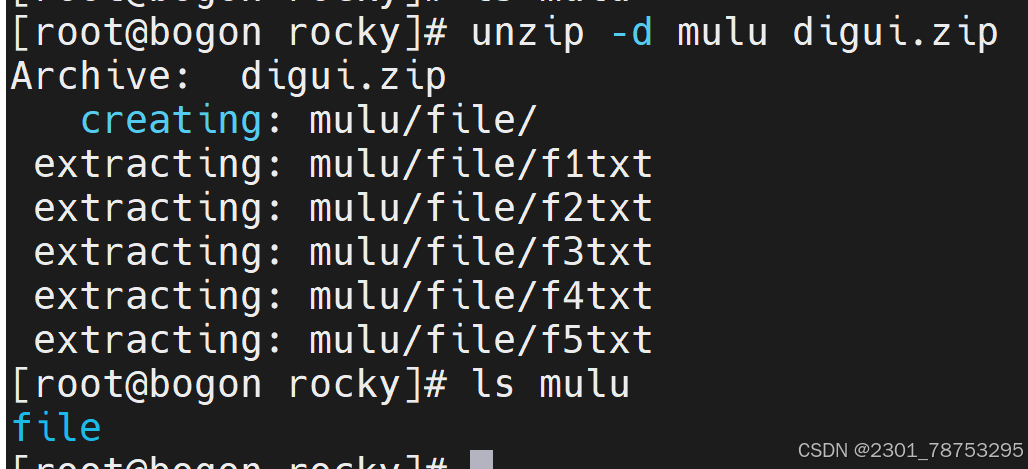
解压场景有专属选项 -C 我要解压到那个目录下
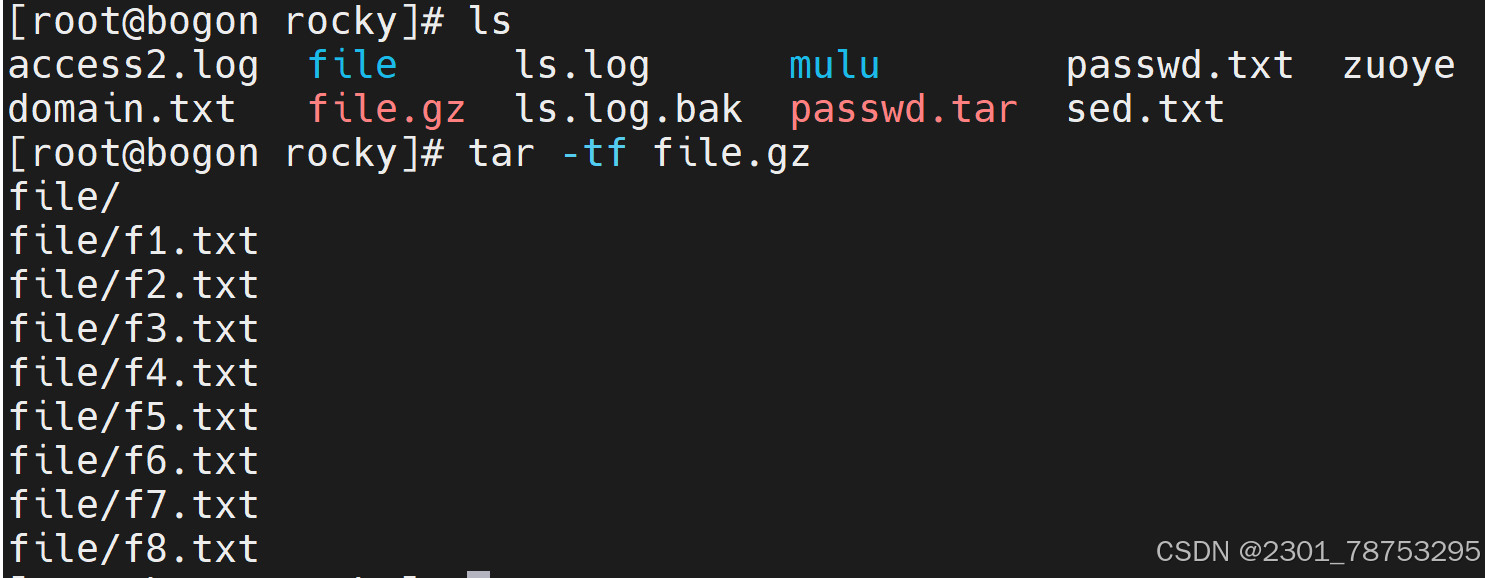
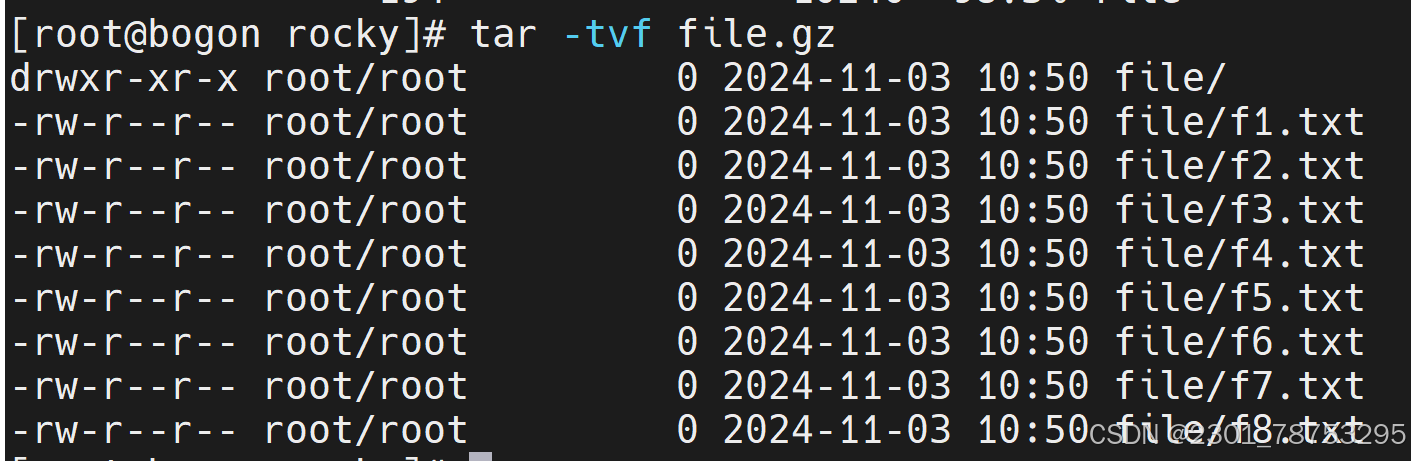
tar -tf 压缩为文件名 在不解压的情况下查看文件目录


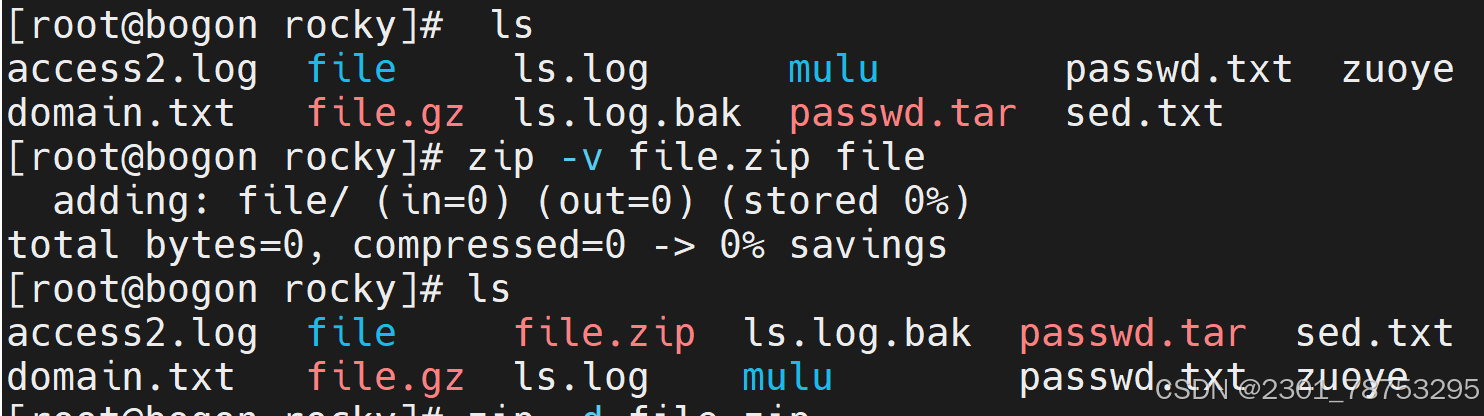
zip包
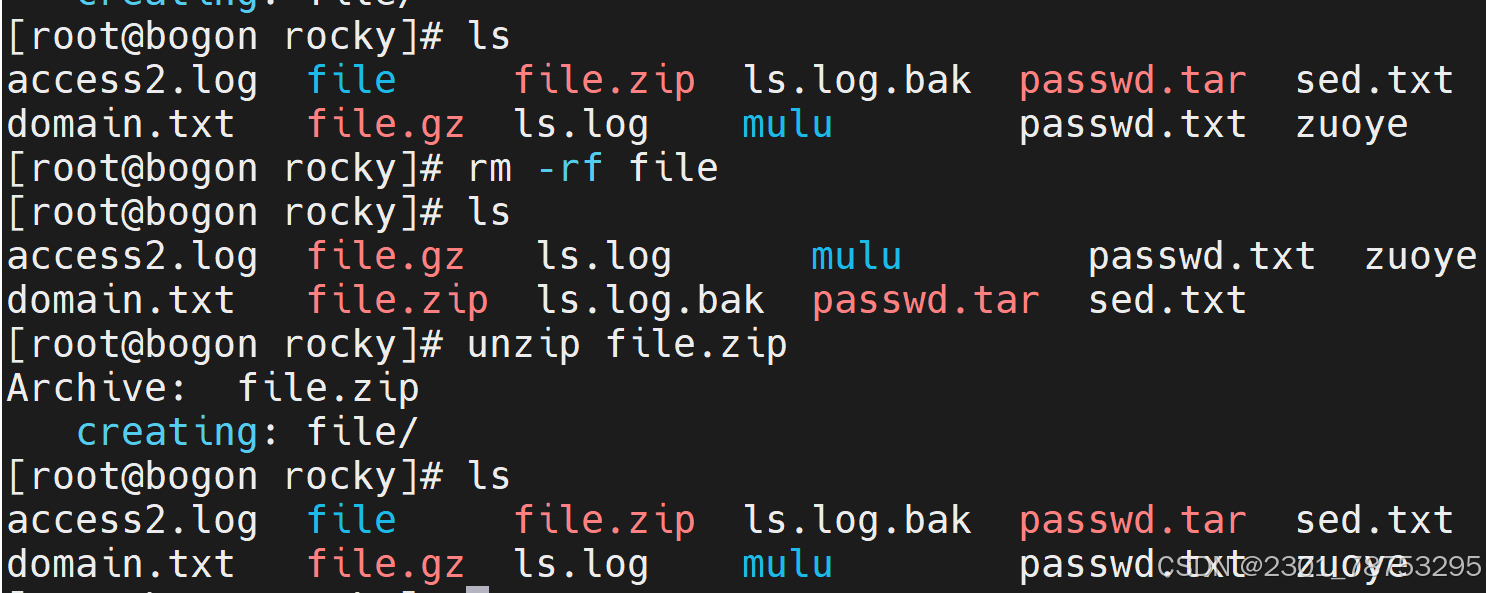
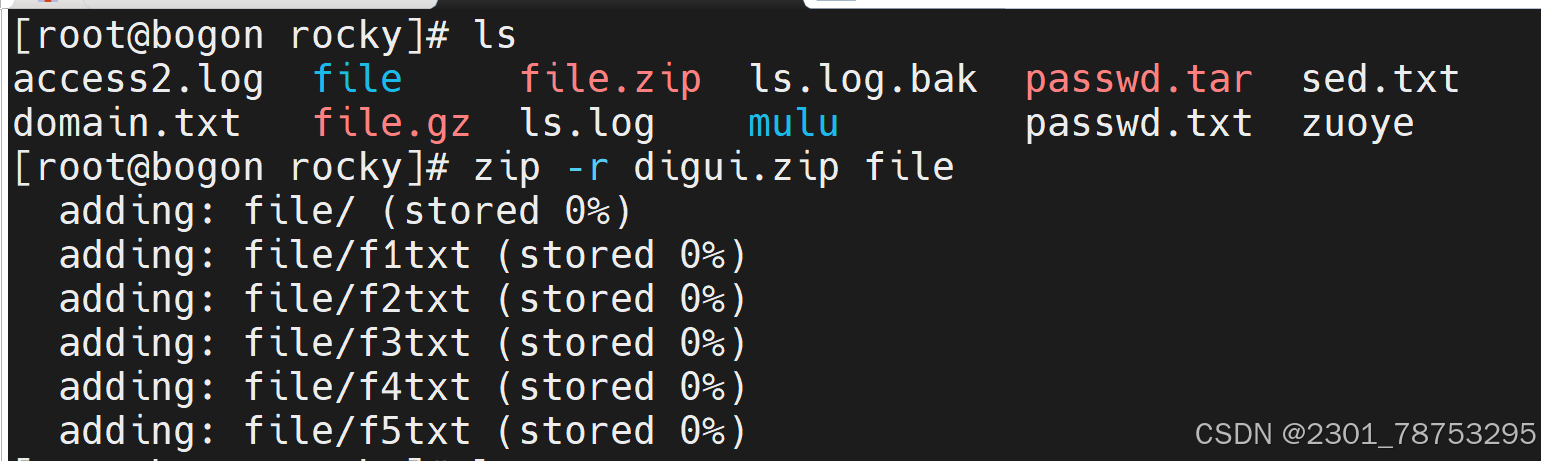
使用方法:zip 选项 (指定名字。zip) 要压缩的文件名
选项:
-d 指定解压到哪里
-v 压缩文件
-r 递归压缩
unzip 解压文件
zcat查看压缩内容
使用方法 zcat 选项 要查看的压缩文件
选项:
- l 查看压缩包的基本情况
tar -tvf 查看压缩文件详情

6.2shell基础
6.2.1 脚本执行
方法1:
bash /path/to/script-name 或 /bin/bash /path/to/script-name (强烈推荐使 用)
方法2:
/path/to/script-name 或 https://blog.csdn.net/2301_/article/details/script-name (当前路径下执行脚本)
方法3:
source script-name 或 . script-name (注意“.“点号)
方法1变种:
cat /path/to/script-name | bash
bash /path/to/script-name
方法1:
[root@rocky9 ~]# /bin/bash get_netinfo.sh
IP: 10.0.0.12
NetMask: 255.255.255.0
Broadcast: 10.0.0.255
MAC Address: 00:0c:29:23:23:8c
方法2:
[root@rocky9 ~]# https://blog.csdn.net/2301_/article/details/get_netinfo.sh
bash: https://blog.csdn.net/2301_/article/details/get_netinfo.sh: 权限不够
[root@rocky9 ~]# ll get_netinfo.sh
-rw-r–r– 1 root root 521 6月 7 20:41 get_netinfo.sh
[root@rocky9 ~]# chmod +x get_netinfo.sh
[root@rocky9 ~]# https://blog.csdn.net/2301_/article/details/get_netinfo.sh
IP: 10.0.0.12
NetMask: 255.255.255.0
Broadcast: 10.0.0.255
MAC Address: 00:0c:29:23:23:8c
方法3:
[root@rocky9 ~]# source get_netinfo.sh
IP: 10.0.0.12
NetMask: 255.255.255.0
Broadcast: 10.0.0.255
MAC Address: 00:0c:29:23:23:8c
[root@rocky9 ~]# chmod -x get_netinfo.sh
[root@rocky9 ~]# ll get_netinfo.sh
-rw-r–r– 1 root root 521 6月 7 20:41 get_netinfo.sh
[root@rocky9 ~]# source get_netinfo.sh
IP: 10.0.0.12
NetMask: 255.255.255.0
Broadcast: 10.0.0.255
MAC Address: 00:0c:29:23:23:8c
6.2.2 脚本调试
使用方法 /bin/bash 选项 要执行的文件
-n 检查脚本中的语法错误
-v 先显示脚本所有内容,然后执行脚本,结果输出,如果执行遇到错误,将错误输出。
-x 将执行的每一条命令和执行结果都打印出来
记住x就好
[root@rocky9 ~]# /bin/bash -x get_netinfo-error.sh
+ :
+ ifconfig eth0 + awk ‘{print \(2}'</p> <p>+ grep -w inet</p> <p>+ xargs echo 'IP: ' IP: 10.0.0.12</p> <p>+ ifconfig eth0</p> <p>+ grep -w inet</p> <p>+ awk '{print \)4}’
+ xargs echo ‘NetMask: ’ NetMask: 255.255.255.0
+ ifconfig eth0
+ grep -w inet
+ xargs echo ‘Broadcast: ’
+ awk ‘{print \(6}' Broadcast: 10.0.0.25</p> </blockquote> <h5>6.2.3脚本开发规范</h5> <blockquote> <p><span style="color:#fe2c24;">1、脚本命名要有意义,文件后缀是.sh </span></p> <p><span style="color:#fe2c24;">2、脚本文件首行是而且必须是脚本解释器 #!/bin/bash</span></p> <p><span style="color:#fe2c24;">3、脚本文件解释器后面要有脚本的基本信息等内容 脚本文件中尽量不用中文注释; 尽量用英文注释,防止本机或切换系统环境后中文乱码的困扰 常见的注释信息:脚本名称、脚本功能描述、脚本版本、脚本作者、联系方式等 </span></p> <p><span style="color:#fe2c24;">4、脚本文件常见执行方式:bash 脚本名 </span></p> <p><span style="color:#fe2c24;">5、脚本内容执行:从上到下,依次执行 </span></p> <p><span style="color:#fe2c24;">6、代码书写优秀习惯; </span></p> <p><span style="color:#fe2c24;">1)成对内容的一次性写出来,防止遗漏。 </span></p> <p><span style="color:#fe2c24;">如:()、{}、[]、''、``、"" </span></p> <p><span style="color:#fe2c24;">2)[]中括号两端要有空格,书写时即可留出空格[ ],然后再退格书写内容。 </span></p> <p><span style="color:#fe2c24;">3)流程控制语句一次性书写完,再添加内容 </span></p> <p><span style="color:#fe2c24;">7、通过缩进让代码易读;(即该有空格的地方就要有空格)</span></p> <p>shell脚本开发规范重点 2,4, 5</p> <p>shell开发小技巧 3,6,7</p> </blockquote> <h5>6.2.4 shell 变量</h5> <blockquote> <p>变量场景: 用过变量名,快速获取对应的值</p> <p>变量定义: 变量名=变量值</p> <p></p> <p>基本操作:</p> <p>1,创建变量</p> <p>2,查看变量:\)变量名 “\(变量名" <span style="color:#fe2c24;">\){变量名} ”\({变量名}" 标红这两个最标准 脚本里的环境变量最好使用最后这两个标红的</span></p> <p></p> <p><span style="color:#fe2c24;">删除变量: unset 变量名</span></p> </blockquote> <h6><span style="color:#fe2c24;">变量分类</span></h6> <blockquote> <p>shell 中的变量分为三大类:</p> <p><span style="color:#fe2c24;">本地变量 变量名仅仅在当前终端有效 自定义变量</span></p> <p><span style="color:#fe2c24;">全局变量 变量名在当前操作系统的所有终端都有效 系统级变量</span></p> <p><span style="color:#fe2c24;">shell内置变量 shell解析器内部的一些功能参数变量 man bash 自己创建了一些变量,我们可以直接拿过来用</span></p> </blockquote> <h4><span style="color:#fe2c24;">定义全局变量</span></h4> <blockquote> <p><span style="color:#fe2c24;">全局变量是什么</span></p> <p><span style="color:#fe2c24;"> 全局变量就是:在当前系统的所有环境下都能生效的变量</span></p> <p></p> <p><span style="color:#fe2c24;">定义全局变量:</span></p> <p><span style="color:#fe2c24;"> export 变量名=变量值</span></p> <p></p> <p><span style="color:#fe2c24;">查看全局变量</span></p> <p><span style="color:#fe2c24;"> echo \)变量名
删除变量名
unset 变量名
嵌套shell
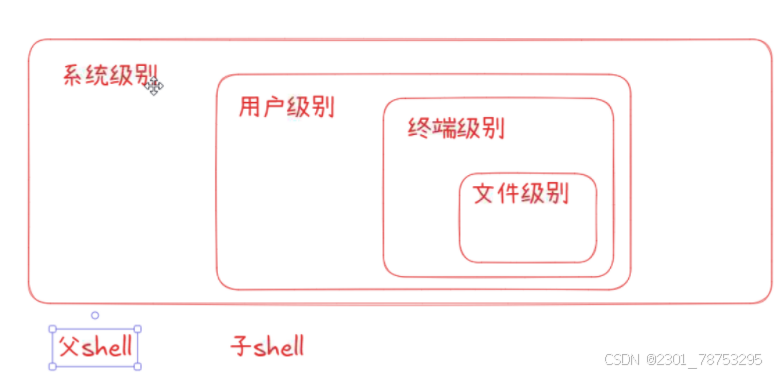
父shell可以给子用 子shell只能自己用
脚本相关
\(0 脚本文件名 \)1第一个参数 \(#所有参数的总数 </p> <p><img alt="" height="318" src="https://i-blog.csdnimg.cn/direct/eeba899eb9974d059f38c7a7a51493d4.png" width="806" /></p> </blockquote> <h5><span style="color:#fe2c24;">字符串相关</span></h5> <blockquote> <p>字符串计数</p> <p>\){#file} 获取字符串的长度
字符串截取
- 语法为\({var:pos:length} 表示对变量var从pos开始截取length个字符,pos为空标示0 \){file:0:5} 从0开始,截取5个字符
\({file:5:5} 从5开始,截取5个字符 </p> <p>\){file::5} 从0开始,截取5个字符
\({file:0-6:3} 从倒数第6个字符开始,截取之后的3个字符 </p> <p>\){file: -4} 返回字符串最后四个字节,-前面是“空格”

默认值相关
格式一:\({变量名:-默认值} </span></p> <p><span style="color:#fe2c24;">变量a如果有内容,那么就输出a的变量值 </span></p> <p><span style="color:#fe2c24;">变量a如果没有内容,那么就输出默认的内容 </span></p> <p></p> <p><span style="color:#fe2c24;">格式二:\){变量名+默认值}
无论变量a是否有内容,都输出默认值
实践1 - 有条件的默认值
购买手机的时候选择套餐:
如果我输入的参数为空,那么输出内容是 “您选择的套餐是: 套餐 1”
如果我输入的参数为n,那么输出内容是 “您选择的套餐是: 套餐 n”
子shell基础
临时shell
临时shell环境 - 启动子shell
(命令列表),在子shell中执行命令列表,退出子shell后,不影响后续环境操作。 临时shell环境 - 不启动子shell {命令列表}, 在当前shell中运行命令列表,会影响当前shell环境的后续操作。
7.1运算符
7.1.1运算符基础
表达式
语法格式
格式
真实值 操作符 真实值 比较运算符 预期值
示例
3 + 4 > 6
要点:
表达式应该具有判断的功能
样式1:
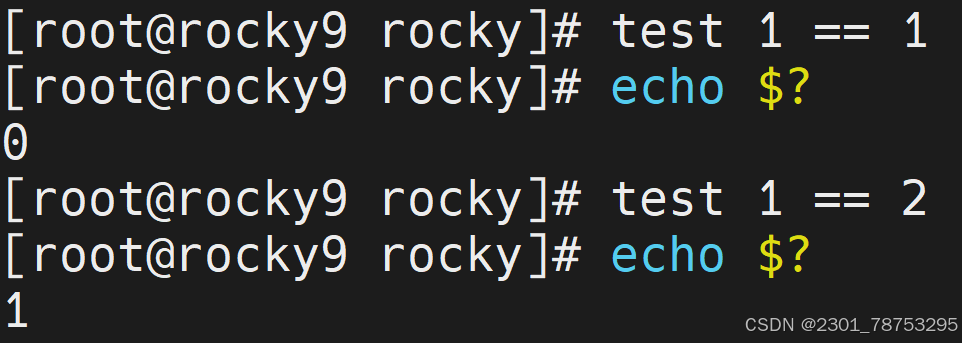
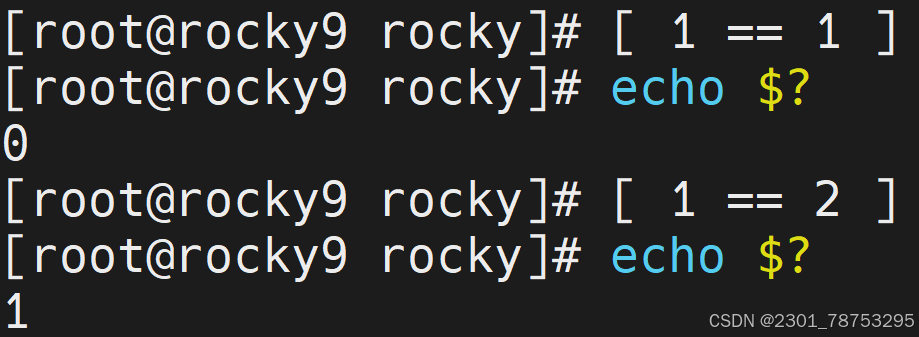
test 条件表达式
样式2: [ 条件表达式 ]
注意:
以上两种方法的作用完全一样,后者为常用。
但后者需要注意方括号[、]与条件表达式之间至少有一个空格。
test跟 [] 的意思一样
条件成立,状态返回值是0
条件不成立,状态返回值是
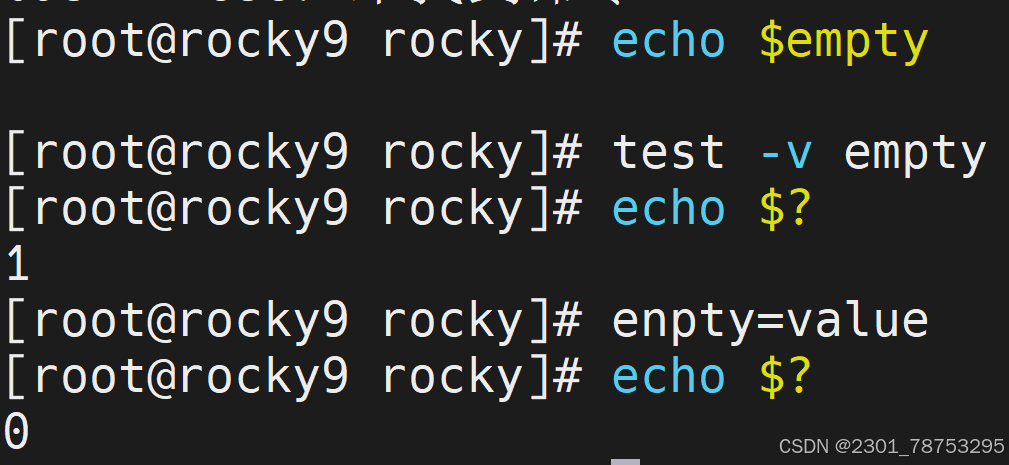
test -v 语法测试变量有没有被设置值,亦可理解为变量是否为空。
7.1.1简单计算
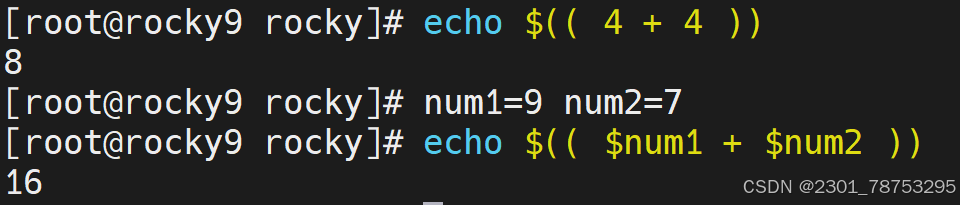
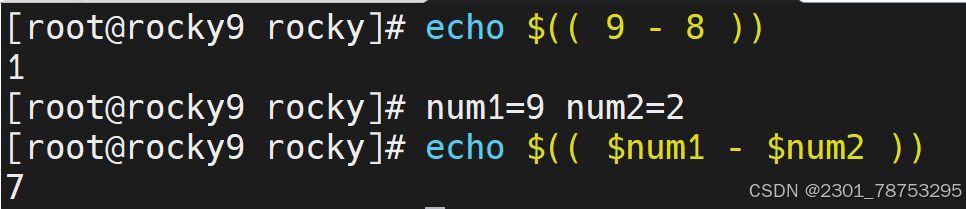
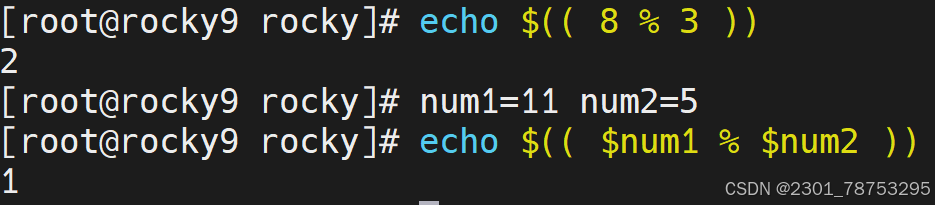
简介:
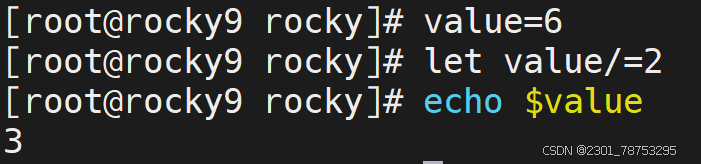
\([]方法,常用于整数计算场景,适合不太复杂的计算,运算结果是小数的也会自动取整。 后面的几种也是一样</span></p> <p></p> <p><span style="color:#fe2c24;">格式</span></p> <p><span style="color:#fe2c24;"> 方法1: </span></p> <p><span style="color:#fe2c24;"> \)[计算表达式]
方法2:
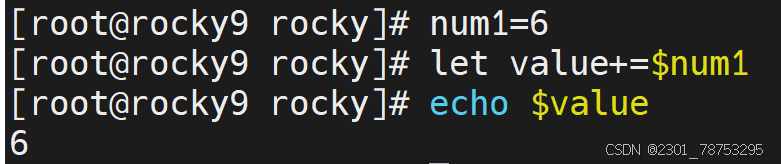
a=\([变量名a+1] </span></p> <p><span style="color:#fe2c24;">注意: </span></p> <p><span style="color:#fe2c24;"> 这里的表达式可以不是一个整体</span></p> </blockquote> <p></p> <figure class="image"> <img alt="" height="161" src="https://i-blog.csdnimg.cn/direct/cb9bd850cf2845c286e0a55bd301c31b.png" width="678" /> <figcaption> 简单加减乘除用法都一样 </figcaption> </figure> <p> </p> <figure class="image"> <img alt="" height="79" src="https://i-blog.csdnimg.cn/direct/4d86cbcee65c4958afd34d2d648ef7ca.png" width="643" /> <figcaption> 运算结果取整 </figcaption> </figure> <h6> let 简介</h6> <blockquote> <p><span style="color:#fe2c24;">简介</span></p> <p><span style="color:#fe2c24;"> let是另外一种相对来说比较简单的数学运算符号了</span></p> <p></p> <p><span style="color:#fe2c24;">格式</span></p> <p><span style="color:#fe2c24;">let 变量名a=变量名a+1 </span></p> <p></p> <p><span style="color:#fe2c24;">注意: </span></p> <p><span style="color:#fe2c24;"> 表达式必须是一个整体,中间不能出现空格等特殊字符</span></p> <p>简介</p> <p>(())的操作与let基本一致,相当于let替换成了 (())</p> <p>格式</p> </blockquote> <figure class="image"> <img alt="" height="189" src="https://i-blog.csdnimg.cn/direct/813e007118ee45b68fcad16d59b66981.png" width="705" /> <figcaption> 定义i=1 let i=1+7 \)i=7
(())简介
简介
(())的操作与let基本一致,相当于let替换成了 (())
格式
((变量计算表达式))
注意:
对于 \((())中间的表达式,可以不是一个整体,不受空格的限制</span></p> </blockquote> <figure class="image"> <img alt="" height="147" src="https://i-blog.csdnimg.cn/direct/f9f9d74da3c549dcbfb57dbd2bb8b5d0.png" width="671" /> <figcaption> 定义num1=85 num2=num1+56 mum2=141 </figcaption> </figure> <h6> <span style="color:#fe2c24;">\)(()) 简介
简介
\((())的操作,相当于 (()) + echo \)变量名 的组合
格式
echo \(((变量计算表达式)) </span></p> <p></p> <p><span style="color:#fe2c24;">注意: </span></p> <p><span style="color:#fe2c24;"> 对于 \)(())中间的表达式,可以不是一个整体,不受空格的限制
定义num1等于34 那么num2等于num1加34就等于68 7.1.2 赋值运算进阶
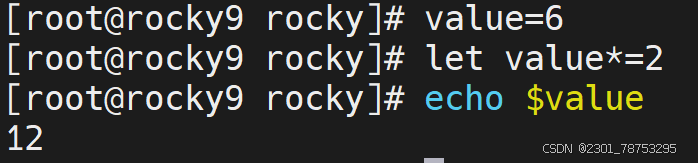
二元运算
简介
所谓的二元运算,指的是 多个数字进行+-/%等运算
加减乘除格式都一样
取余运算 赋值运算
这里的赋值运算,是一种进阶版本的复制操作,常见的样式如下:
样式1:+=、-=、=、/=
- 在自身的基础上进行二元运算,结果值还是自己
样式2:++、–
- 在自身的基础上进行递增和递减操作,结果值还是自己
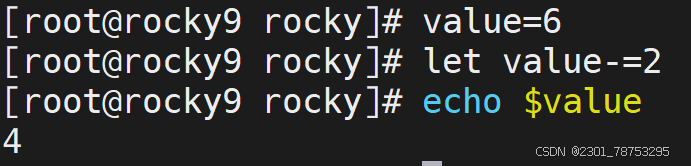
+=运算 相当于 let value=value+$num1 -=运算 # 相当于 let value=value-2 *=运算 # 相当于 let value=value*2 /=运算 # 相当于 let value=value/2 i++运算 # 相当于 let value=value+1 ++i运算 相当于 let value=value+1 i–运算 # 相当于 let value=value-1 –i运算 # 相当于 let value=value-1 7.1.3 基础知识
表达式
语法格式
格式
真实值 操作符 真实值 比较运算符 预期值
示例
3 + 4 > 6
要点:
表达式应该具有判断的功能
样式1:
test 条件表达式
样式2: [ 条件表达式 ]
注意:
以上两种方法的作用完全一样,后者为常用。
但后者需要注意方括号[、]与条件表达式之间至少有一个空格。
test跟 [] 的意思一样
条件成立,状态返回值是0
条件不成立,状态返回值是
test -v 语法测试变量有没有被设置值,亦可理解为变量是否为空。
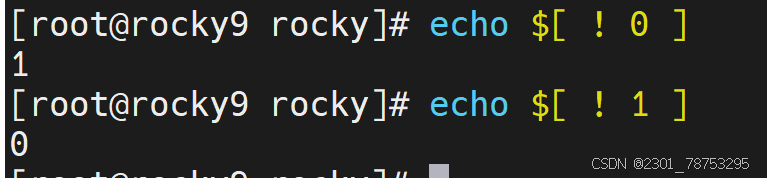
1=1条件成立 1=2条件不成立
test -v 查看变量是否为空 不成立1 成立为0 7.1.4逻辑表达式
&&
示例:命令1 && 命令2
如果命令1执行成功,那么我才执行命令2 – 夫唱妇随
如果命令1执行失败,那么命令2也不执行
||
示例:命令1 || 命令2
如果命令1执行成功,那么命令2不执行 – 对着干
如果命令1执行失败,那么命令2执行
!
示例:! 命令
如果命令执行成功,则整体取反状态
使用样式:
命令1 && 命令2 || 命令3
方便理解的样式 ( 命令1 && 命令2 ) || 命令3
功能解读:
命令1执行成功的情况下,执行
命令2 命令2执行失败的情况下,执行命令3
注意:
&& 必须放到前面,|| 放到后面
命令一为真才会主星第二个 命令以为假不会i执行
命令一为真命令二不输出 命令一为假命令二才输出
取反成功为假 不成功为真 如果命令一为真输出目录存在 目录存在为假输出目录不存在 如果命令一为假不输出目录存在 目录存在为假 输出目录不存在 7.1.5字符串表达式
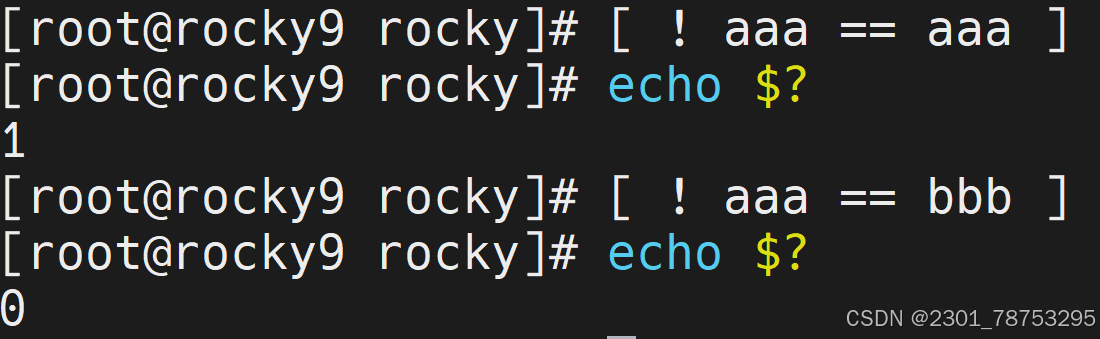
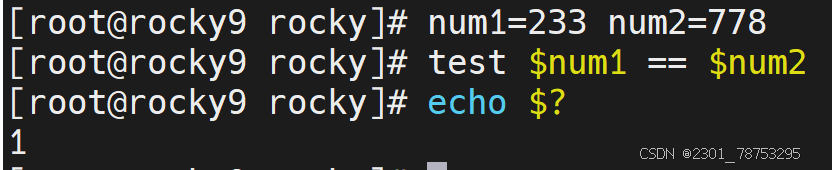
所谓的字符串表达式,主要是判断 比较运算符 两侧的值的内容是否一致,由于bash属于弱类型语言, 所以,默认情况下,无论数字和字符,都会可以被当成字符串进行判断。
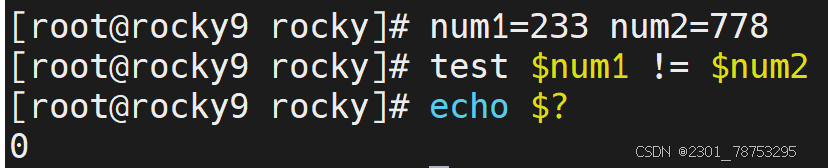
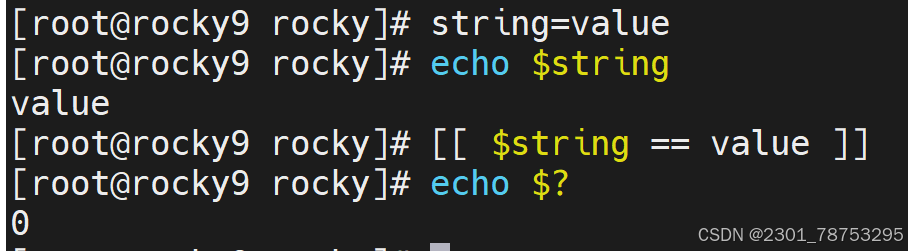
符号解读
内容比较判断
str1 == str2 str1和str2字符串内容一致
str1 != str2 str1和str2字符串内容不一致,!表示相反的意思
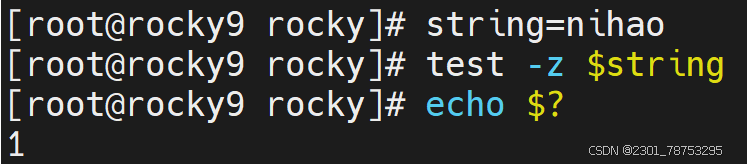
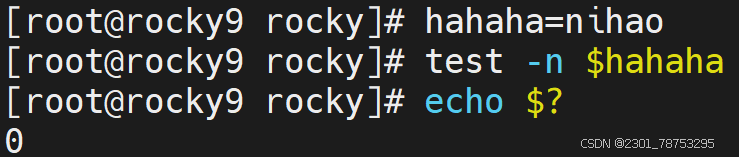
内容空值判断
-z str 空值判断,获取字符串长度,长度为0,返回真
-n “str” 非空值判断,获取字符串长度,长度不为0,返回真
注意:str外侧必须携带“”,否则无法判断
1为假不成立 aaa 不等于 bbb 成立为真 !=不等于的意思 num1等于num2判断为假 num1不等于num2判断为真 空判断获取字符串长度不为零判断为假 空判断获取字符串长度为零判断为真 判断内容是否为不空,可以理解为变量是否被设置 不为空为真 反之为假 7.1.6 文件表达式
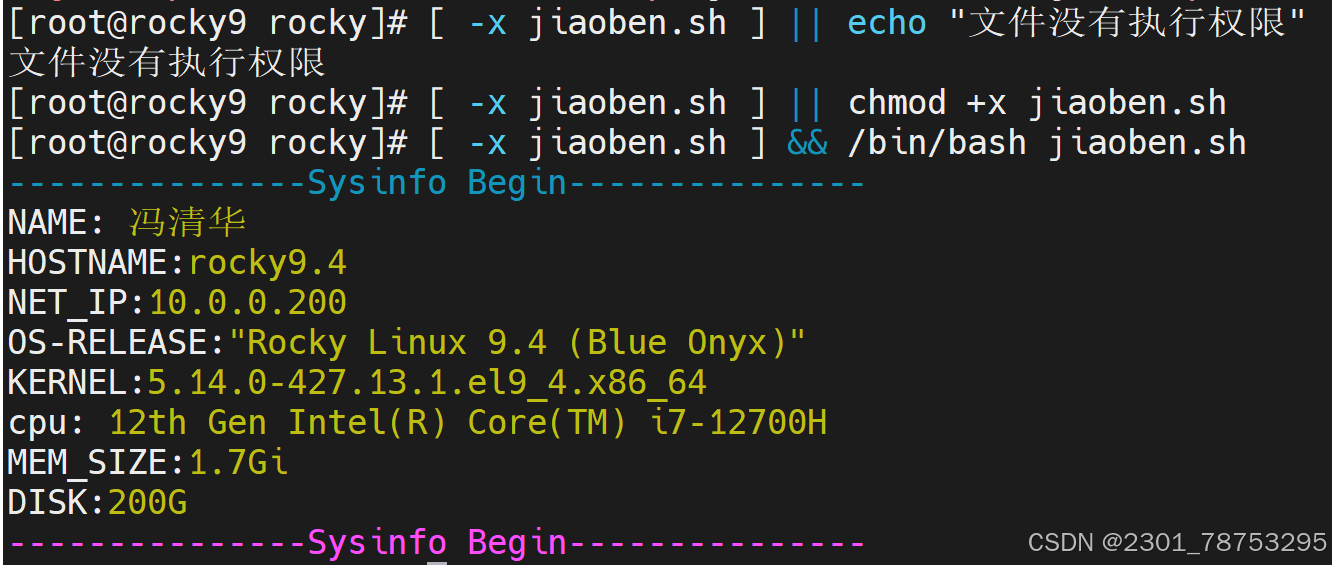
文件属性判断
-d 检查文件是否存在且为目录文件
-f 检查文件是否存在且为普通文件
-S 检查文件是否存在且为socket文件
-L 检查文件是否存在且为链接文件
-O 检查文件是否存在并且被当前用户拥有
-G 检查文件是否存在并且默认组为当前用户组
文件权限判断
-r 检查文件是否存在且可读
-w 检查文件是否存在且可写
-x 检查文件是否存在且可执行
文件存在判断
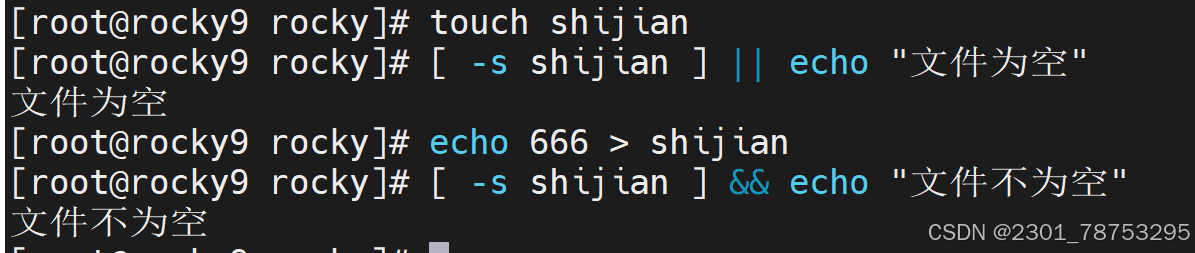
-e 检查文件是否存在
-s 检查文件是否存在且不为空
文件新旧判断
file1 -nt file2 检查file1是否比file2新
file1 -ot file2 检查file1是否比file2旧
file1 -ef file2 检查file1是否与file2是同一个文件,判定依据的是i节点
&&命令一为真才会输出命令二 ||命令一为假才会输出命令二 所以weizhi.sh不是文件 &&命令一为真才会输出命令二 ||命令一为假才会输出命令二 所以weizhi.sh不是目录 一判断文件有没有执行权限 二判断文件有没有权限如果没有就加权限 三判断有没有权限有就执行脚本 判断文件中是否有内容 判断文件是否存在 7.1.7 数字表达式
简介:
主要根据给定的两个值,判断第一个与第二个数的关系,如是否大于、小于、等于第二个数。
语法解读
n1 -eq n2 相等 n1 -ne n2 不等于 n1 -ge n2 大于等于
n1 -gt n2 大于 n1 -lt n2 小于 n1 -le n2 小于等于
等于 大于 7.1.8 表达式进阶
简介:
我们之前学习过 test 和 [ ] 测试表达式,这些简单的测试表达式,仅仅支持单条件的测试。如果需 要针对多条件测试场景的话,我们就需要学习[[ ]] 测试表达式了。
我们可以将 [[ ]] 理解为增强版的 [ ],它不仅仅支持多表达式,还支持扩展正则表达式和通配符。
基本格式:
[[ 源内容 操作符 匹配内容 ]]
操作符解析:
== 左侧源内容可以被右侧表达式精确匹配
=~ 左侧源内容可以被右侧表达式模糊匹配
定制默认变量 [[]]支持通配符 使用“”取消正则,则内容匹配失败 使用取消正则,则内容匹配失败 7.1.9集合基础
表现样式:
两个条件
1 - 真 0 - 假
三种情况:
与 - & 或 - | 非 - !
注意:
这里的 0 和 1 ,千万不要与条件表达式的状态值混淆 !!!!!!!!!!!!!!
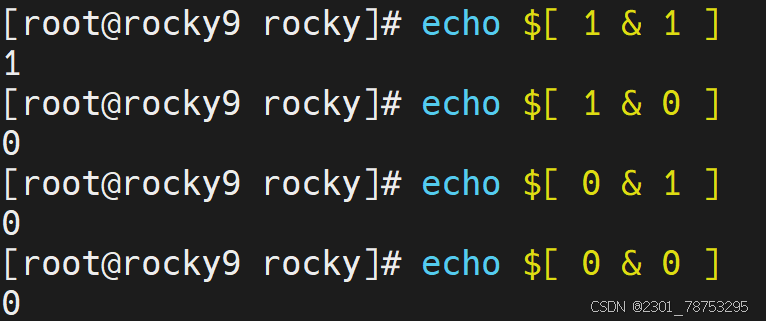
与关系:
0 与 0 = 0 0 & 0 = 0
0 与 1 = 0 0 & 1 = 0
1 与 0 = 0 1 & 0 = 0
1 与 1 = 1 1 & 1 = 1
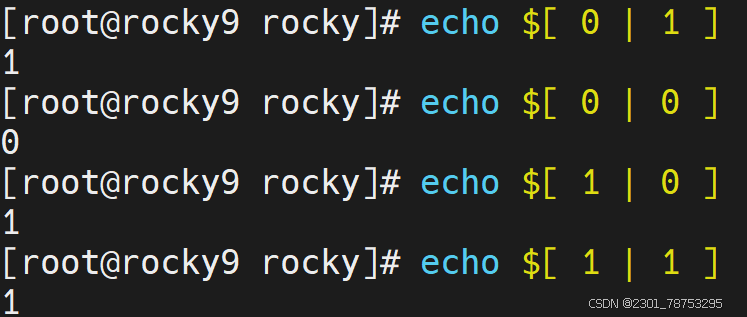
或关系:
0 或 0 = 0 0 | 0 = 0
0 或 1 = 1 0 | 1 = 1
1 或 0 = 1 1 | 0 = 1
1 或 1 = 1 1 | 1 = 1
非关系:
非 1 = 0 ! true = false
非 0 = 1 ! false = true
或 与 默认是零所以!0是真 !1是假 7.2.1 逻辑组合
简介:
所谓的条件组合,指的是在同一个场景下的多个条件的综合判断效果
语法解析:
方法1:
[ 条件1 -a 条件2 ] - 两个条件都为真,整体为真,否则为假
[ 条件1 -o 条件2 ] - 两个条件都为假,整体为假,否则为真
方法2:
[[ 条件1 && 条件2 ]] - 两个条件都为真,整体为真,否则为假
[[ 条件1 || 条件2 ]] - 两个条件都为假,整体为假,否则为真
-a 两个条件都为真所以结果为真 -a 有一个为假所以结果为假 -o 两个条件一个为真一个为假 结果为真 -o 两个条件都为假结果才为假 8.1.1获取软件包
软件官网、github、第三方软件镜像站
系统发版的光盘或官方网站
CentOS镜像:
https://www.centos.org/download/
http://mirrors.aliyun.com
http://mirrors.sohu.com
http://mirrors.163.com
Ubuntu镜像:
http://cdimage.ubuntu.com/releases/
http://releases.ubuntu.com
第组织提供
Fedora-EPEL:Extra Packages for Enterprise Linux
https://fedoraproject.org/wiki/EPEL
https://mirrors.aliyun.com/epel/?spm=a2c6h..0.0.3bc47dfaZpesAr
Rpmforge:RHEL推荐,包很全,即将关闭
http://repoforge.org/
Community Enterprise Linux Repository:支持最新的内核和硬件相关包
http://www.elrepo.or
软件项目官方站点
http://yum.mariadb.org/10.4/centos8-amd64/rpms/
http://repo.mysql.com/yum/mysql-8.0-community/el/8/x86_64/
搜索引擎
注意:第三方包建议要检查其合法性,来源合法性,程序包的完整性 http://pkgs.org http://rpmfifind.net
http://rpm.pbone.net
https://sourceforge.net/
8.1.2包管理器rpm
安装
命令格式
rpm {-i|–install} [install-options] PACKAGE_FILE…
常用选项
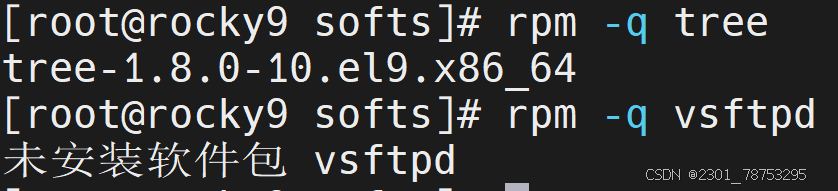
-q # 检查安装软件
-ivh # 安装软件
-evh # 卸载软件
-Uvh # 有旧版程序包,则“升级”,如果不存在旧版程序包,则“安装”
-Fvh # 有旧版程序包,则“升级”,如果不存在旧版程序包,则不执行安装操作
安装软件不需要依赖 安装软件需要依赖 升级新版本vsftpd 升级旧版本vsftpd 注意:如果已安装版本高,待安装版本低,默认不安装 卸载软件包 查看软件包是否安装 查看是否安装vsftpd软件包 如果安装了就卸载vsftpd软件 -Uvh 有旧版程序包,则“升级”,如果不存在旧版程序包,则“安装” 8.1.3 查询
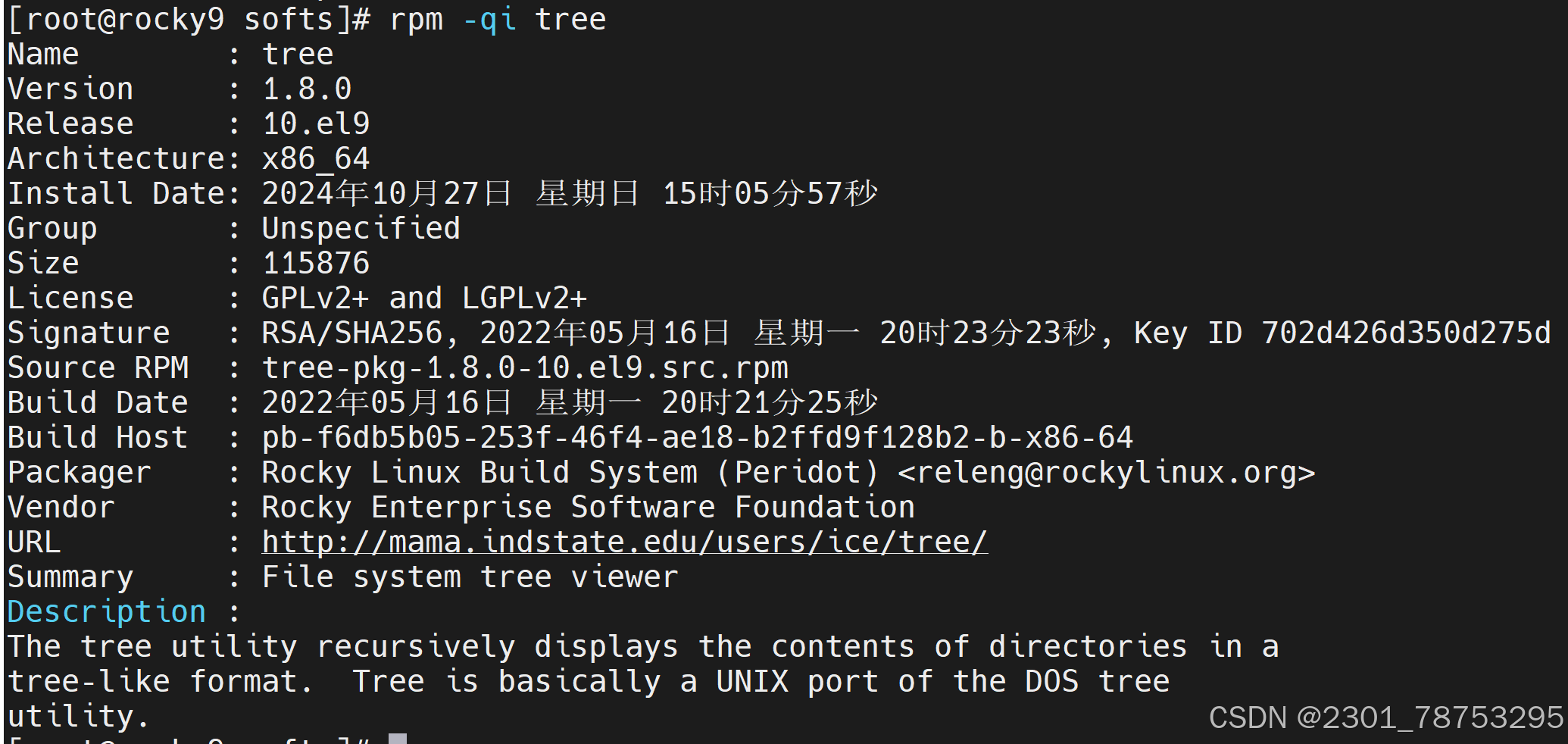
命令格式:
rpm {-q|–query} [select-options] [query-options]
常用选项
-i #information
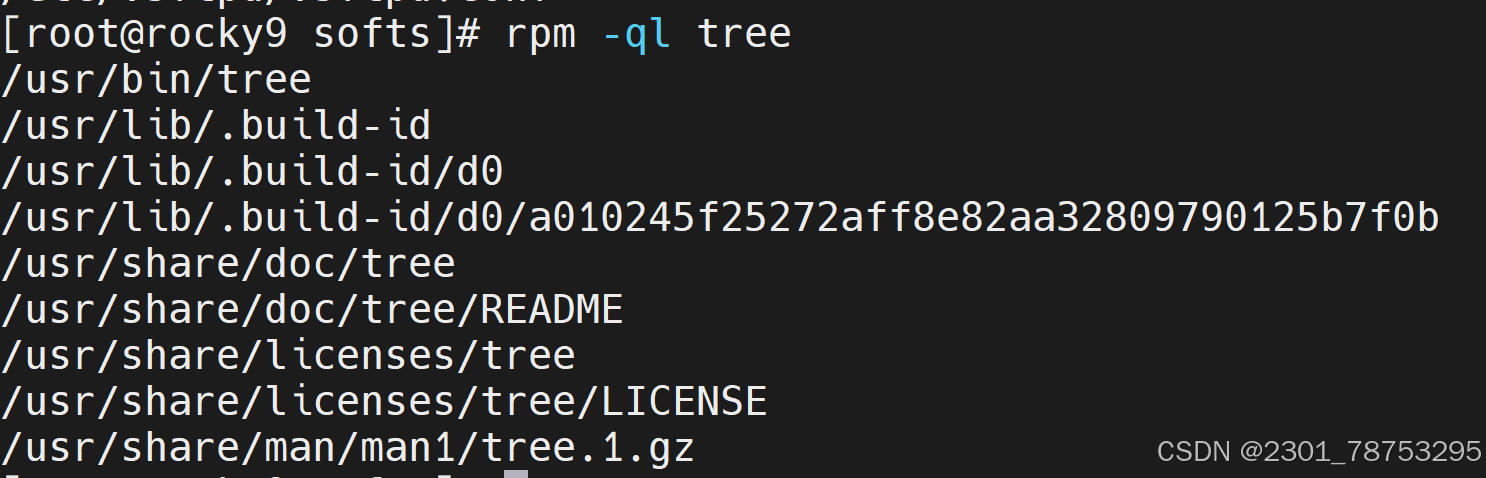
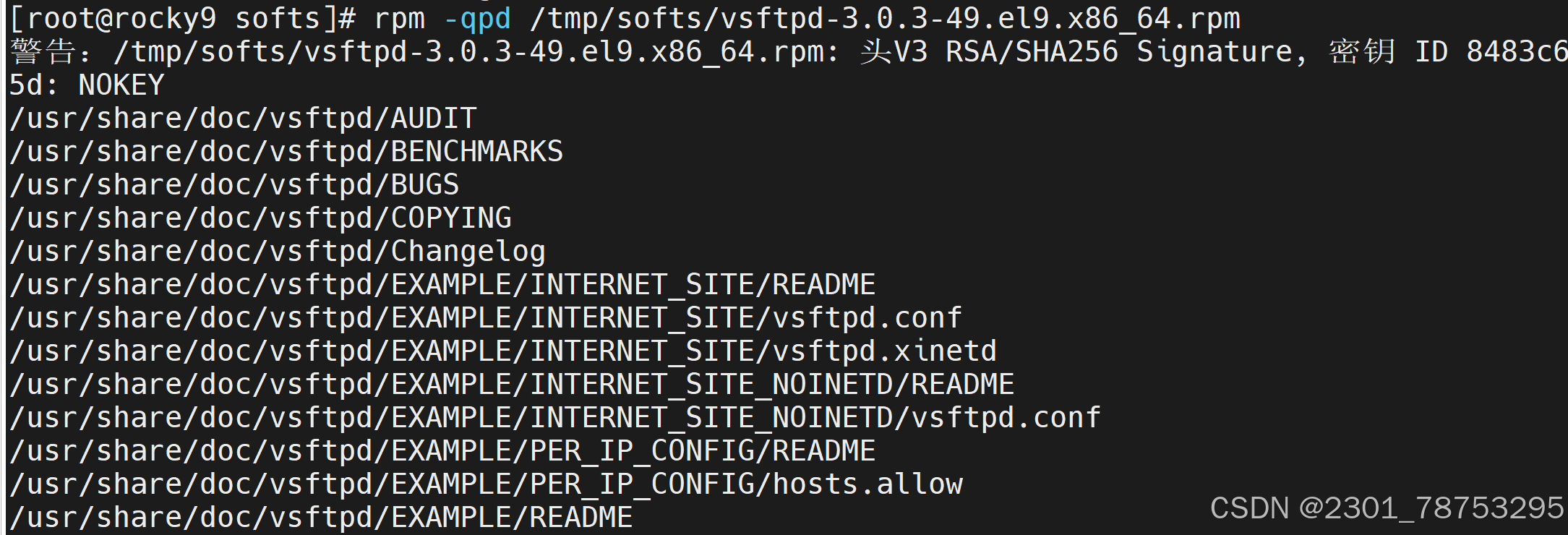
-l #查看指定的程序包安装后生成的所有文件
-f #查看指定的文件由哪个程序包安装生成
-a #所有包
-d #查询程序的文档
常用组合:-qi、-qf、-ql、-qa
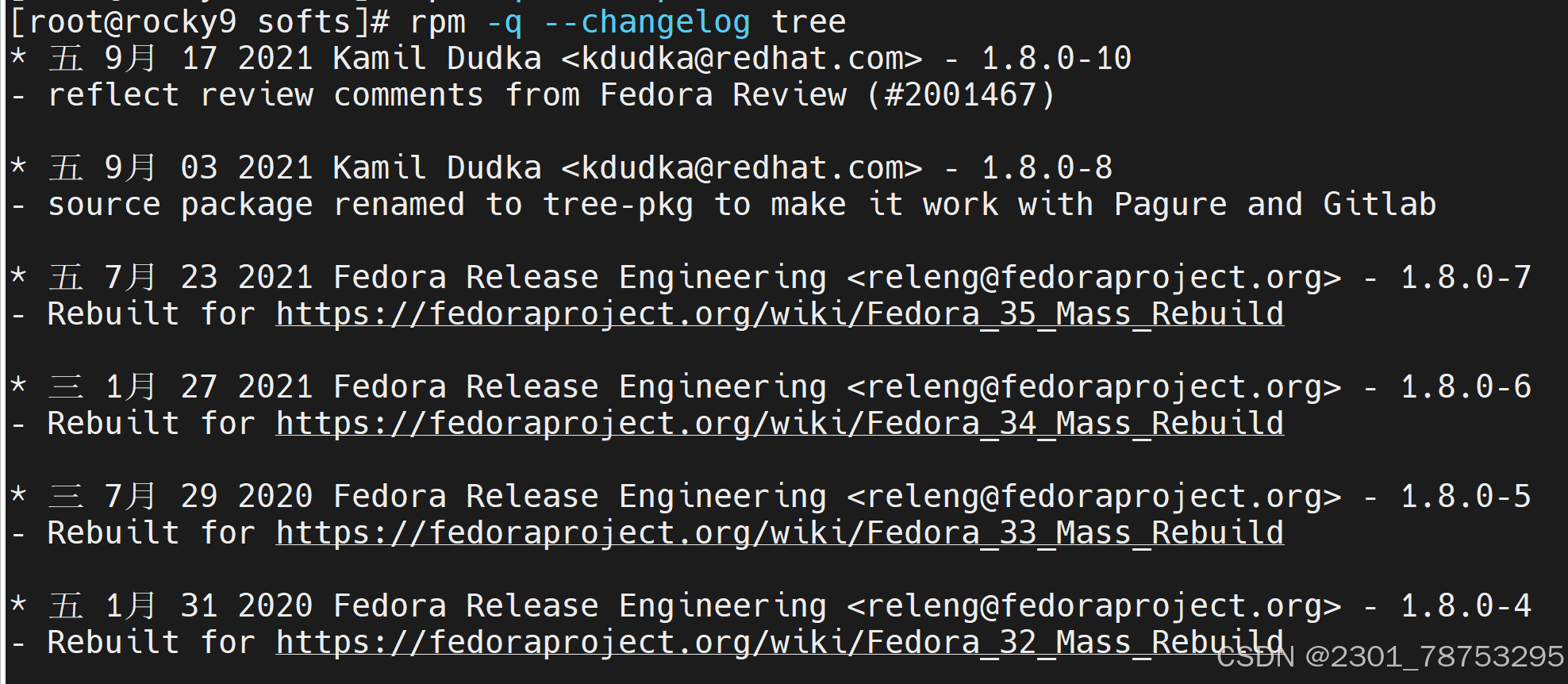
查看所有安装的包 查看所有包从中过滤出passwd的包 查看软件是否安装 查看包详细信息 查看以安装软件的文件 查看未安装的包文件来源于哪里 查看已安装软件的配置文件 没安装的指定包文件 列出已安装软件的所有文件 查看已安装软件的文档文件 查看未安装文件的文档文件 查看安装脚本 查看软件的更新记录信息 8.1.4yum和dnf
架构模式
yum/dnf 是基于C/S 模式
- yum 服务器存放rpm包和相关包的元数据库
- yum 客户端访问yum服务器进行安装或查询等
yum实现过程
先在yum服务器上创建 yum repository(仓库),在仓库中事先存储了众多rpm包,以及包的相关的 元数据文件(放置于特定目录repodata下),当yum客户端利用yum/dnf工具进行安装包时,会自动下载 repodata中的元数据,查询元数据是否存在相关的包及依赖关系,自动从仓库中找到相关包下载并安装。
配置环境
客户端配置
yum客户端配置文件
/etc/yum.conf #为所有仓库提供公共配置
/etc/yum.repos.d/*.repo #为每个仓库的提供配置文件
查看帮助
man 5 yum.conf
获取软件源信息 同步软件源基本信息
yum makecache
清理软件源信息
yum clean all
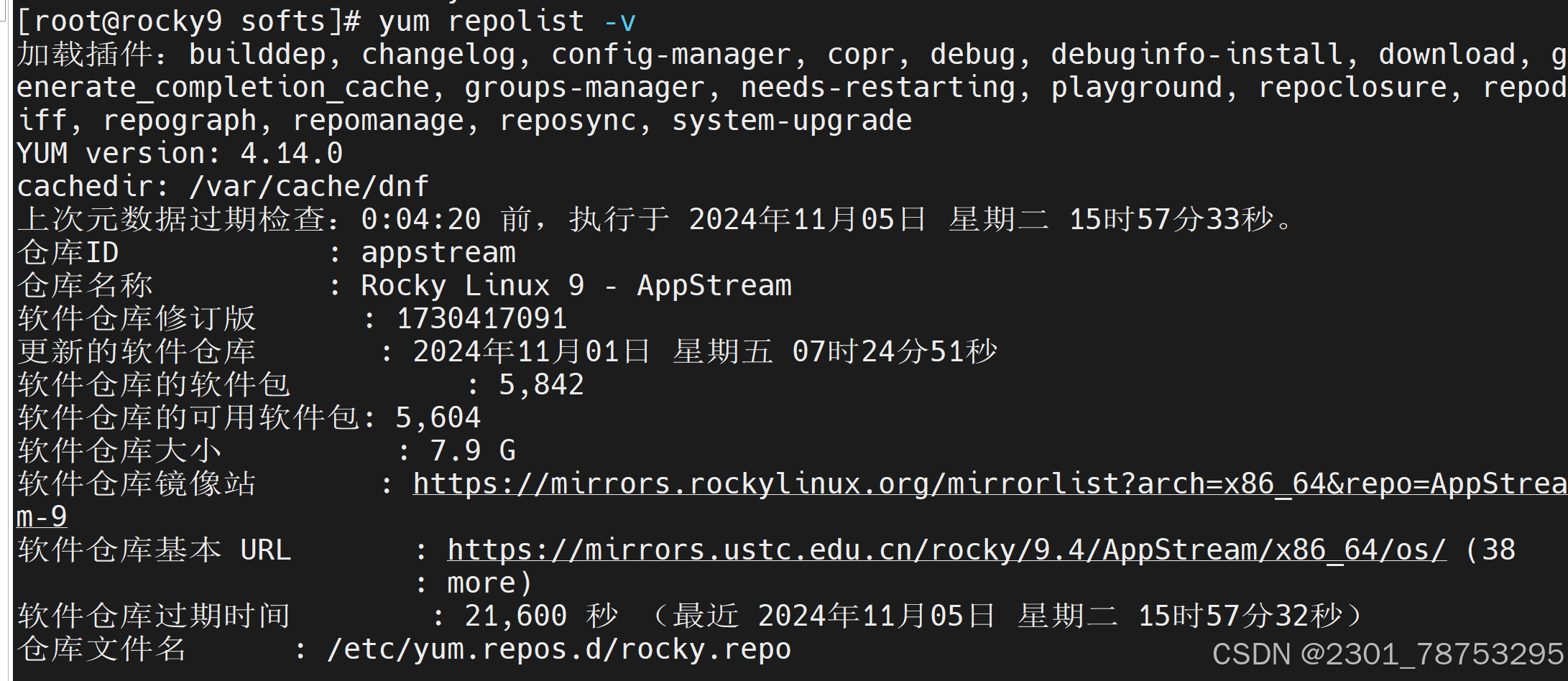
查看仓库的信息
yum repolist
yum repolist -v # 查看更多信息
同步软件源基本信息 查看厂库列表 查看仓库列表详细信息 清理软件源信息
定制软件源
Rocky9.4上配置aliyun的repo源
1, cd /etc/yum.repos.d/ 切换到 /etc/yum.repos.d/ 下
2, mkdir bak 创建一个文件夹
3, mv *.repo bak/ 将所有以 .repo后缀的文件转移到bak目录中
4, yum clean all 清理软件源信息
5, yum makecache 获取软件源信息 看看还有没有仓库
6, vim aliyun-baseos.repo 创建文件并在里面编写内容内容如下:
[aliyun-baseos]
name=aliyun baseos
baseurl=https://mirrors.aliyun.com/rockylinux/9.4/BaseOS/x86_64/os/
gpgcheck=0
[aliyun-Appstream]
name=aliyun appstream
baseurl=https://mirrors.aliyun.com/rockylinux/9.4/AppStream/x86_64/os/
gpgcheck=07,yum makecache 同步软件源
本地源配置
保证关盘是挂载的 设备状态 已连接 启动时连接
1, mount /dev/cdrom /mnt 将光盘文件挂载到mnt目录下
2 vim local-image.repo 创建文件并在里面编写内容内容和aliyun一样改名字
3 开启一个新终端 ls /mnt/AppStream/ ls /mnt/BaseOS/
分别对应 file///mnt/AppStream/ file///mnt/BaseOS/ 网址
其他与上面一样
8.1.5yum命令
命令格式: yum [options] COMMAND
常用子命令
autoremove #卸载包,同时卸载依赖 个别配置文件可能不会被删除
clean #清除本地缓存
install #包安装
list #列出所有包 list –updates 可以让那些软件更新到最新版本
list –showduplicates 加软件名 可以查看有哪些可以安装的软件
makecache #重建缓存
search #包搜索,包括包名和描述
一般子命令
check-update #检查可用更新
downgrade #包降级 命令实践 显示仓库列表
group #包组相关
help #显示帮助信息
history #显示history
info #显示包相关信息
reinstall #重装
remove #卸载
repolist #显示或解析repo源 search
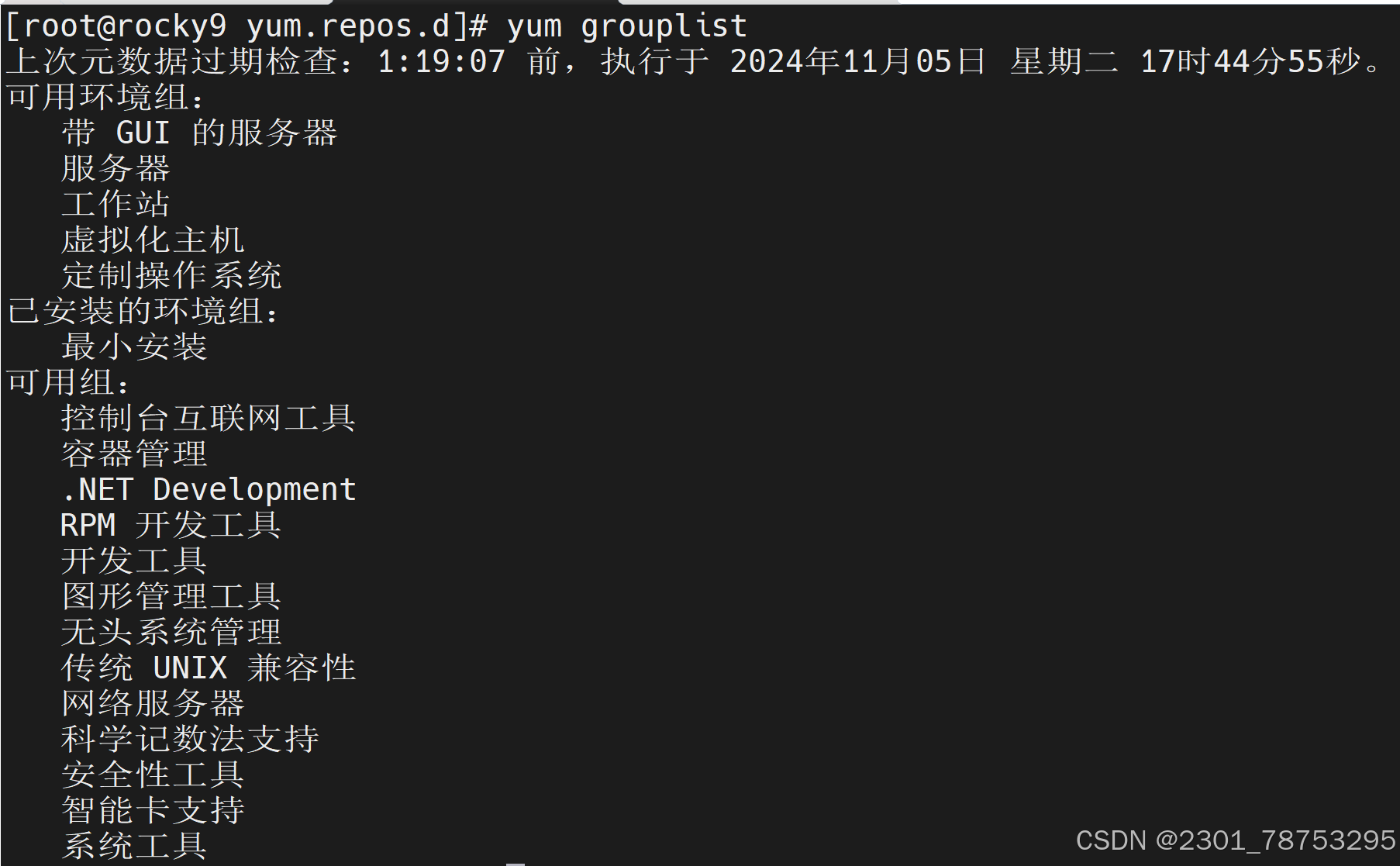
查看已安装到的所有包 查看可以让那些软件更新到最新版本 查看nginx有哪些可以安装的软件 软件组管理
常用:
yum grouplist #列出所有包组
yum groupinstall #包组安装
一般命令:
yum groupupdate [options] group1 […] #包组升级
yum groupremove [options] group1 […] #包组卸载
yum groupinfo [options] group1 […] #包组查询
yum grouplist #列出所有包组操作 安装组
1, echo $LANG
2 LANG=NG
3 yum groupinstall “Development Tools” “Security Tools” “System Tools”
查看所有组 8.1.6自建yum仓库
准备
1, 准备web环境
2, 准备rpm软件———-从互联网获取——-从本地光盘获取
3, 创建repodate数据库
4, 测试 ——客户端准备软件源配置为文件———-测试
操作流程
1,yum install -y httpd 下载httpd
2,systemctl disabled –now firewalld.service 关闭防火墙
3,systemctl enable –now httpd.service 开启
4,yum reposync –repoid=nju-extras –download-metadata -p /var/www/html/ 将阿里云的extras源的相关数据下载到本地 给客户端使用
5,cd /etc/yum.repos.d/ 创建文件
文件内容:
[private-extras1]
name=private extras1
baseurl=http://10.0.0.13/nju-extras/
gpgcheck=0
6,yum makecache 更新软件源
7, yum list –repo=“private-extras2” anaconda-live
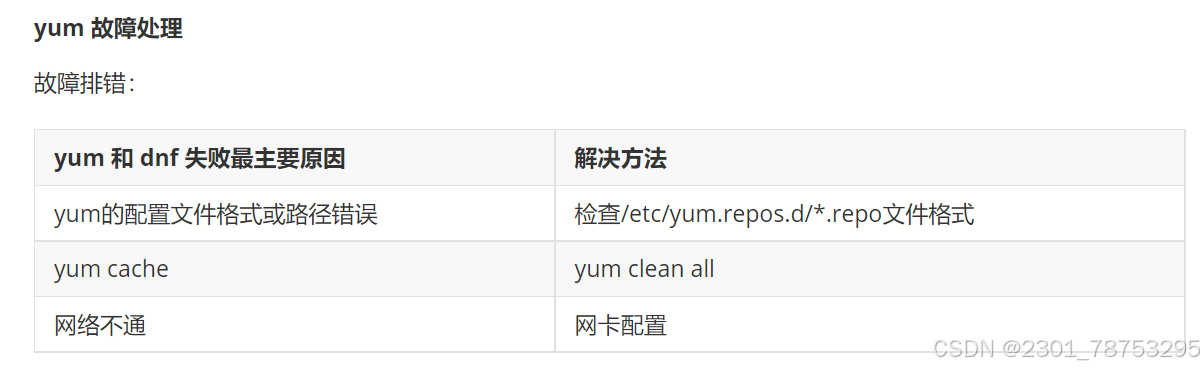
yum 故障处理
面试题:我在创建用户的时候,如何为新创建的用户,提供一个通用的提示文件
在 /etc/skel/ 目录下提供一个提示文件,这样每个新创建用户,都会在自动包含该文件。
Linux中的目录和文件的权限区别?分别说明读,写和执行权限的区别
目录初始权限是755 文件初始权限是644 权限与umask默认值022(用户文件创建掩码)紧密相关
新文件的权限为666 - 022 = 644,
新目录的权限为777 - 022 = 755。
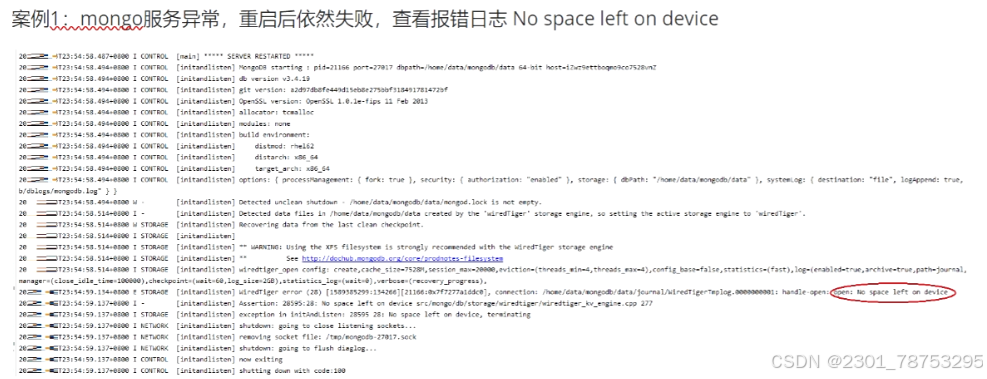
MongoDB服务启动异常
磁盘空间有但是显示没内存了 是inode号用完了
df -h 查看存储空间使用情况
df -i 查看inode号使用情况
1 Linux下一个每一个文件就会占用一个inode资源
2 inode资源数量是在格式化磁盘的时候就指定的(不指定的话,会有默认值)
3 如果某个磁盘的inode资源用尽,即便磁盘有空间,也不能进行任何文件或者文件夹的新增 4 删除一个文件夹或者文件就能释放一个inode资源 根据上面的过程分析,应该是/dev/vdb1在进行格式化的时候,用户不小心指定了一个比较小的inode 的范围值,导致明明有400G的存储空间,但是因为inode值过小,才65万个,导致inode空间没有了,从而无 法再该块空间进行文件增加了 – 因为MongoDB服务启动的时候,应用到了该目录
解决方法:
1 删除不用的文件和文件夹,释放被占用的inode
2 格式化新的磁盘,指定一个大一点的inode值
3 迁移部分数据到新的磁盘上。
4 根据服务配置文件的属性配置,对新磁盘的目录结构进行软连接配置,避免大规模数据迁移导致的配置路径 异常。
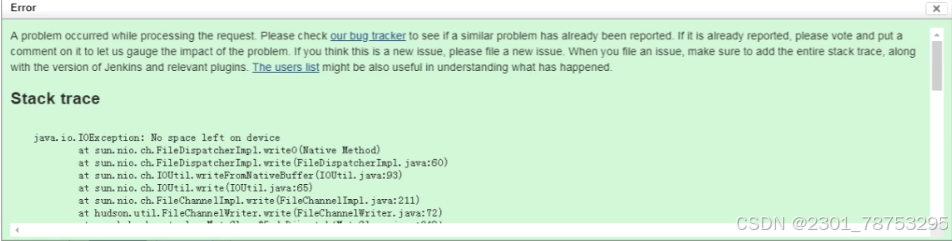
Jeenkins应用异常
jenkins运行的时候发现jenkins执行项目任务报错No space left on device
杀程序
1 df -h 查看磁盘占用空间大小
2 cd /var/log/jenkins 检查jenkins日志数据
3 du -sh https://blog.csdn.net/2301_/article/details/*
4 rm -f 删除相关日志文件
5 df -h 再次查看磁盘占用空间大小
如果空间任被占用是因为是虽然文件删除了,但是服务程序运行的时候,依然在使用这些文件,也就 是说,这些文件的inode文件一直被占用,可以通过 lsof 来检测死文件效果
6 lsof | gerg delete 删除大量jenkins占用的进程id
7 ki11 -9 2397
8 systemctl restart jenkins 成功起jenkins服务
问题改善
对于jenkins服务器上,产生非常多日志问题的原因就找到了,因为程序上启用了DNS解析的功能,我们 只需要直接进入jenkins 系统日志管理页面,将javax.jmdns日志级别调整为 OFF即可。 这样,后期的设备没有空间的问题就彻底解决了。
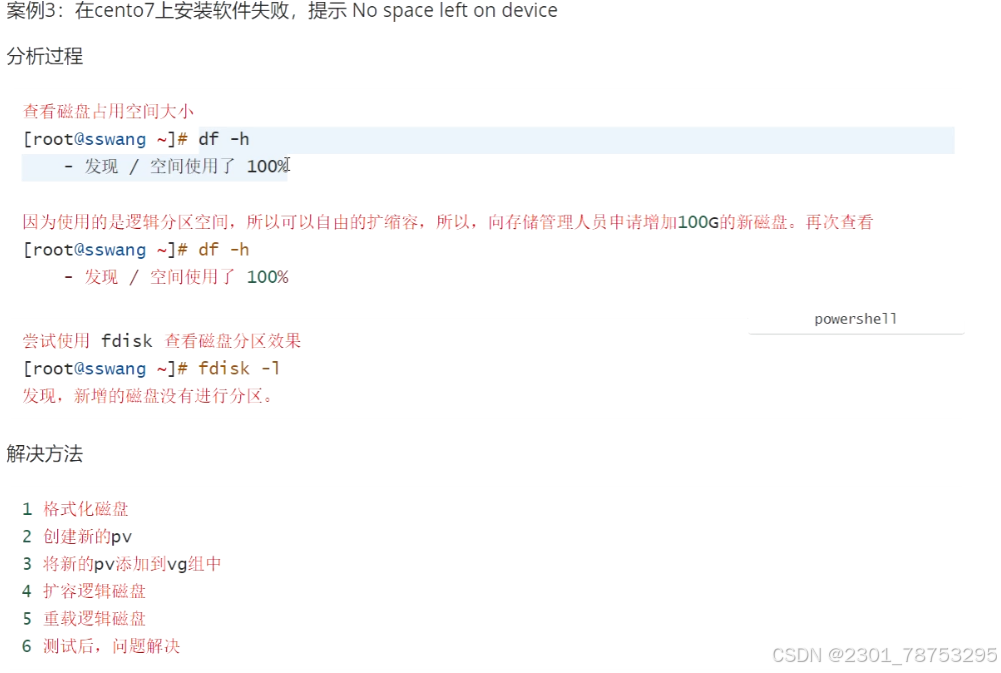
软件安装失败
df -h 查看磁盘占用空间大小 如果满了的话
因为使用的是逻辑分区空间,所以可以自由的扩缩容,所以,向存储管理人员申请增加100G的新磁盘。再次查看
df -h 查看磁盘占用空间大小 还满的话
fdisk -i 查看磁盘分区效果 发现,新增的磁盘没有进行分区。对的话
解决办法
1 格式化磁盘
2 创建新的pv
3 将新的pv添加到vg组中
4 扩容逻辑磁盘
5 重载逻辑磁盘
6 测试后,问题解决
leiclei’c

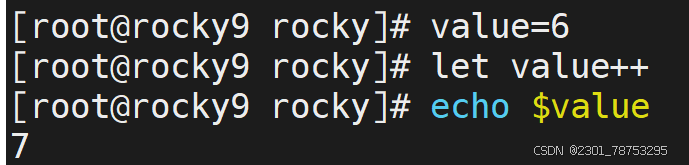
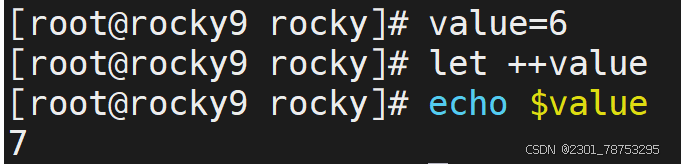
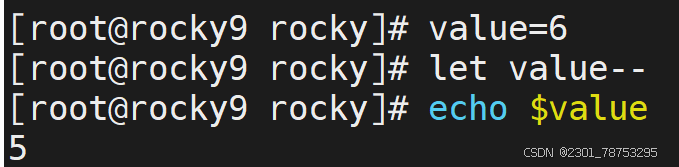
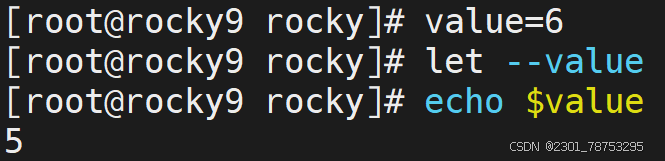
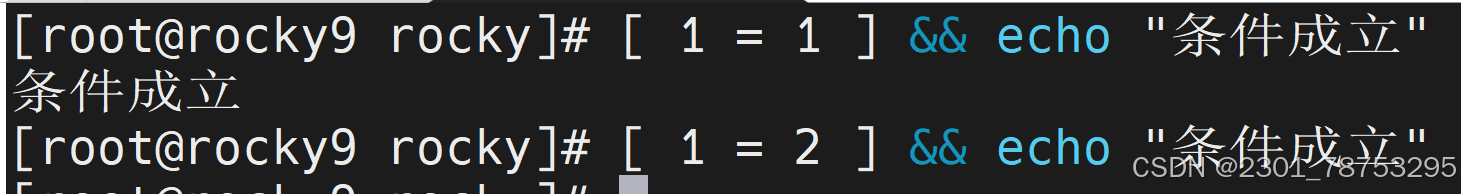
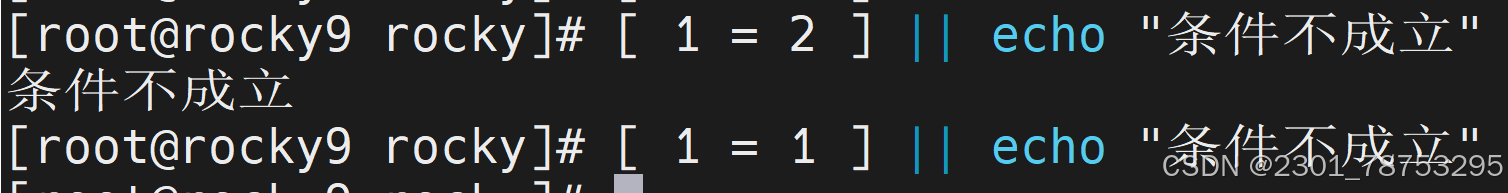


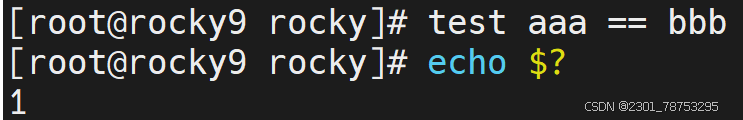




































版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/146604.html