
发表动态这个业务本身也许是不需要DDD的。
DDD常见在一些微服务系统或者大型单体进行分层设计的时候使用。
一个最基本的实践经验是,DDD一般会划分应用层和(一个甚至多个)领域层,每个应用的边界围绕领域(通常是业务定义的)而不是表或者API这些具体的定义。
我这两周设计的DDD的例子:
为了方便Flutter多应用开发时复用跨平台UI,我把Flutter项目分为App应用、领域UI组件库、通用响应式和自适应组件库、原始组件库四层。其中,App应用就是我们直接上线的;领域UI组件以场景划分,比如Admin是一类,文档是一类,等等;通用层主要解决一些我们关心的响应式问题,比如在手机端和电脑端不同方式的主导航栏和侧边导航栏,用不同的基本组件实现;再下面一层是Flutter的原始UI库,包括官方、社区、自建三类。
Django项目有类似的划分,分为应用服务层、公共服务层、公共依赖层。第一层即是对应Flutter App的Django服务,第二层是系统内共用的服务,比如鉴权和用户信息、消息推送、支付等;第三层是公共依赖,通常是一些共同的Django包和Python包,用来开发Django服务。
对于用户服务内部,我同样以Django App为单位做了两层划分。其中一层负责对不同类型的用户建模,比如基本用户、微信用户、员工用户,等等。另外一层暴露鉴权API和用户信息API,根据不同鉴权协议划分应用,比如OpenID Connect协议。
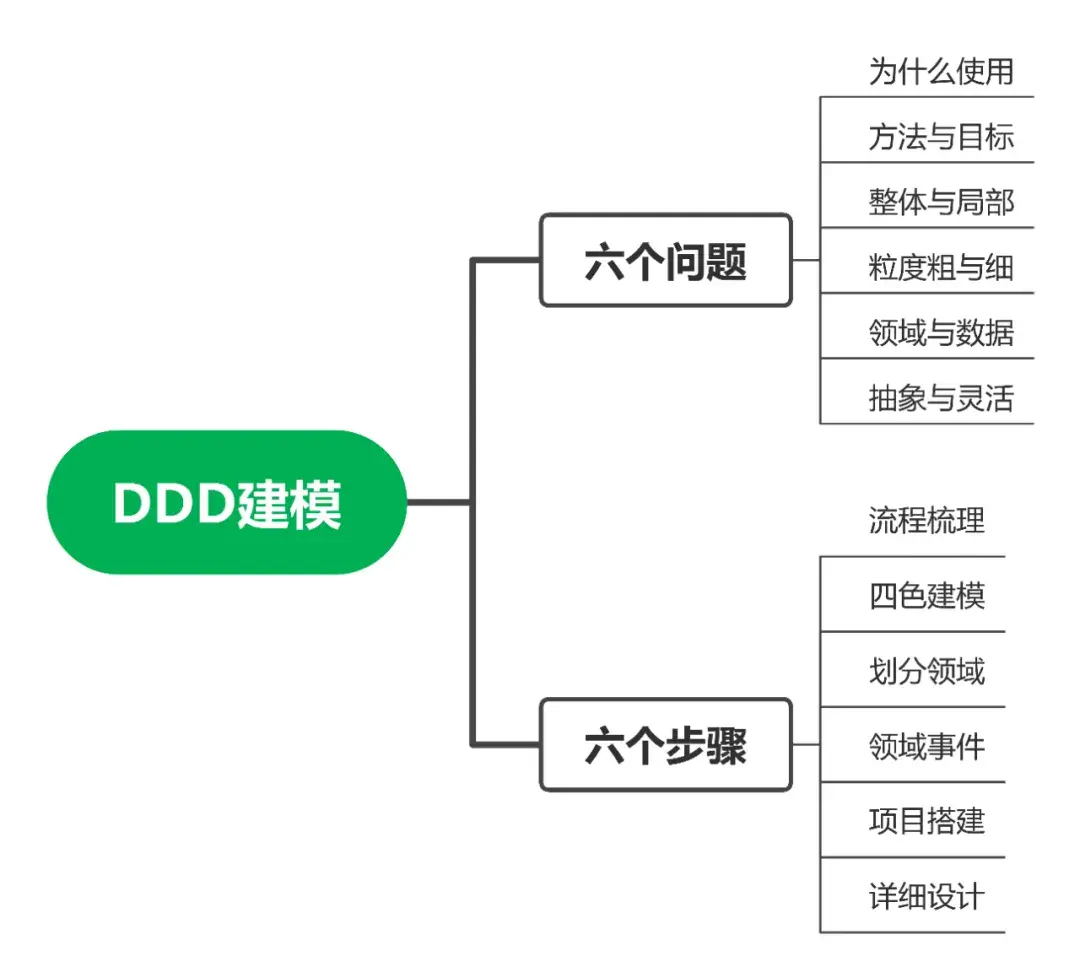
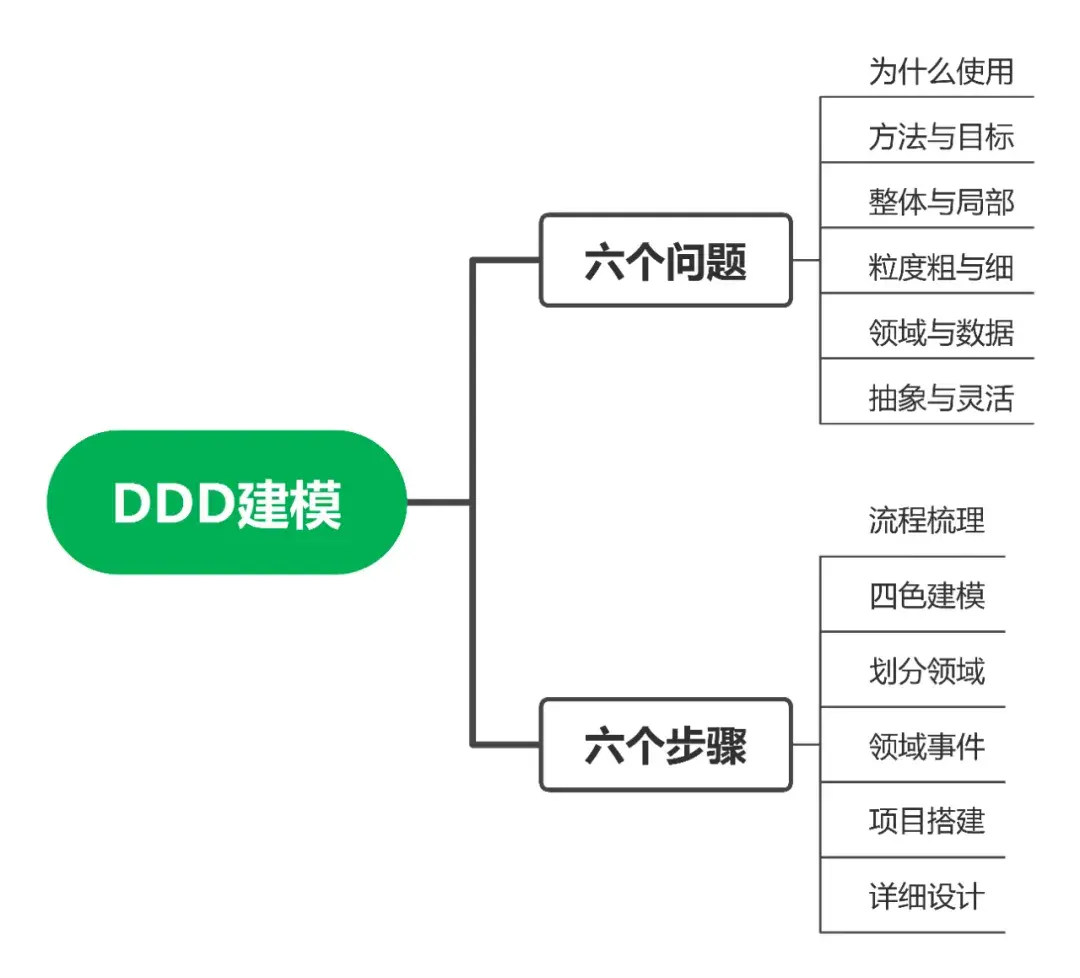
领域驱动设计DDD是一段时间以来比较流行的概念,刚开始接触时觉得概念很多,并且比较难以落地。本文就来分析探讨DDD落地时需要关注的六个问题,并通过一个足球运动员信息管理系统案例分析落地的六个步骤。
讯享网
DDD方法论的核心是将问题不断分解,把大问题分解为小问题,大业务分解小领域,简而言之就是分而治之,各个击破。
分而治之是指直接面对大业务我们无从下手,需要按照一定方法进行分解,分解为高内聚的小领域,使得业务有边界清晰,而这些小领域是我们有能力处理的,这就是领域驱动设计的核心。
各个击破是指当问题被拆分为小领域后,因为小领域业务内聚,其子领域高度相关,我们在技术维度可以对其进行详细设计,在管理维度可以按照领域对项目进行分工。需要指出DDD不能替代详细设计,DDD是为了更清晰地详细设计。
在微服务流行的互联网行业,当业务逐渐复杂时,技术人员需要解决如何划分微服务边界的问题,DDD这种清晰化业务边界的特性正好可以用来解决这个问题。
我们的目标是将业务划分清晰的边界,而DDD是达成目标的有效方法之一,这一点是需要格外注意的。DDD是方法不是目标,不需要为了使用而使用。例如业务模型比较简单可以很容易分析的业务就不需要使用DDD,还有一些目标是快速验证类型的项目,追求短平快,前期可能也不需要使用领域驱动设计。
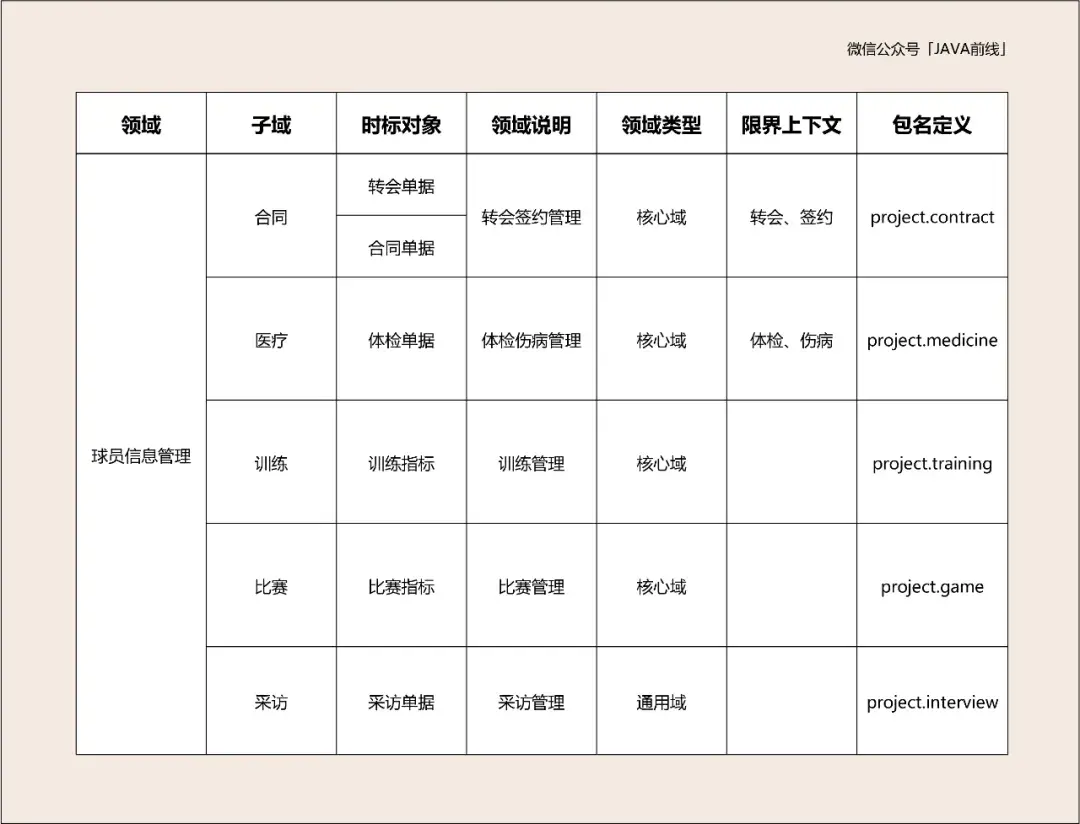
领域可以划分多个子领域,子域可以再划分多个子子域,限界上下文本质上也是一种子子域,那么在业务分解时一个业务模块到底是领域、子域还是子子域?
我认为不用纠结在这个问题,因为这取决于看待这个模块的角度。你认为整体可能是别人的局部,你认为的局部可能是别人的整体,叫什么名字不重要,最重要的是按照高内聚的原则将业务高度相关的模块收敛在一起。
业务划分粒度的粗细并没有统一的标准,还是要根据业务需要、开发资源、技术实力等因素综合考量。例如微服务拆分过细反而会增加开发、部署和维护的复杂度,但是拆分过粗可能会导致大量业务高度耦合,开发部署起来是挺快的,但是缺失可维护性和可扩展性,这需要根据实际情况做出权衡。
领域对象与数据对象一个重要的区别是值对象存储方式。在讨论领域对象和数据对象之前,我们首先讨论实体和值对象这一组概念。实体是具有唯一标识的对象,而唯一标识会伴随实体对象整个生命周期并且不可变更。值对象本质上是属性的集合,并没有唯一标识。
领域对象在包含值对象的同时也保留了值对象的业务含义,而数据对象可以使用更加松散的结构保存值对象,简化数据库设计。
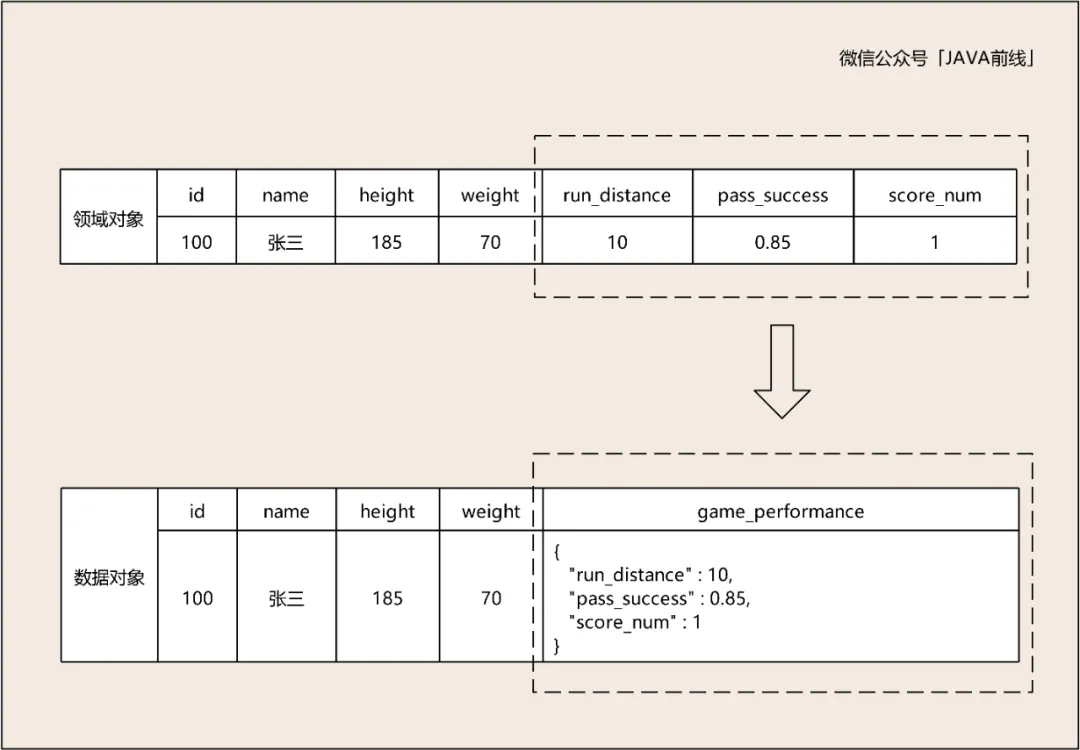
现在假设我们需要管理足球运动员信息,对应的领域模型和数据模型应该如何设计?姓名、身高、体重是一名运动员本质属性,加上唯一编号可以对应实体对象。跑动距离,传球成功率,进球数是运动员比赛中的表现,这些属性的集合可以对应值对象。
值对象在数据对象中可以用松散的数据结构进行存储,而值对象在领域对象中需要保留其业务含义如下图所示:
根据图示编写领域对象与数据对象代码:
// 数据对象 public class FootballPlayerDO {讯享网<span class="kd">private</span> <span class="n">Long</span> <span class="n">id</span><span class="o">;</span> <span class="kd">private</span> <span class="n">String</span> <span class="n">name</span><span class="o">;</span> <span class="kd">private</span> <span class="n">Integer</span> <span class="n">height</span><span class="o">;</span> <span class="kd">private</span> <span class="n">Integer</span> <span class="n">weight</span><span class="o">;</span> <span class="kd">private</span> <span class="n">String</span> <span class="n">gamePerformance</span><span class="o">;</span>
} // 领域对象 public class FootballPlayerDMO { <span class="kd">private</span> <span class="n">Long</span> <span class="n">id</span><span class="o">;</span> <span class="kd">private</span> <span class="n">String</span> <span class="n">name</span><span class="o">;</span> <span class="kd">private</span> <span class="n">Integer</span> <span class="n">height</span><span class="o">;</span> <span class="kd">private</span> <span class="n">Integer</span> <span class="n">weight</span><span class="o">;</span> <span class="kd">private</span> <span class="n">GamePerformanceVO</span> <span class="n">gamePerformanceVO</span><span class="o">;</span>
} public class GamePerformanceVO { 讯享网<span class="kd">private</span> <span class="n">Double</span> <span class="n">runDistance</span><span class="o">;</span> <span class="kd">private</span> <span class="n">Double</span> <span class="n">passSuccess</span><span class="o">;</span> <span class="kd">private</span> <span class="n">Integer</span> <span class="n">scoreNum</span><span class="o">;</span>
}讯享网
抽象的核心是找相同,对不同事物提取公因式。实现的核心是找不同,扩展各自的属性和特点,体现了灵活性。例如模板方法设计模式正是用抽象构建框架,用实现扩展细节。
我们再回到数据模型的讨论,可以发现脚本化是一种拓展灵活性的方式,脚本化不仅指使用groovy、QLExpress脚本增强系统灵活性,还包括松散可扩展的数据结构。数据模型抽象出了姓名、身高、体重这些基本属性,对于频繁变化的比赛表现属性,这些属性值可能经常变化,甚至属性本身也是经常变化,例如可能会加上射门次数,突破次数等,所以采用松散的JSON数据结构进行存储。
工程理论总是要落地的,落地也是需要一些步骤和方法的。本文我们一起分析一个足球运动员信息管理系统,目标是管理运动员从转会到上场比赛整条链路信息,这个系统大家应该也都没有接触过,我们一起来分析。需要说明本实例着重演示DDD方法论如何落地,业务细节可能并不能面面俱到。
梳理流程有两个问题需要考虑,第一个问题是从什么视角去梳理?因为不同的人看到的流程是不一样的。答案是取决于系统需要解决的是什么问题,因为我们要管理运动员从转会到上场比赛整条链路信息,所以从运动员视角出发是一个合适的选择。
第二个问题是对业务不熟悉怎么办?因为我们不是体育和运动专家,并不清楚整条链路的业务细节。答案是梳理流程时一定要有业务专家在场,因为没有真实业务细节,无法领域驱动设计。同理在互联网梳理复杂业务流程时,一定要有对相关业务熟悉的产品经理或者运营一起参与。
四色建模第一种颜色是红色,表示时标对象。时标对象是四色建模最重要的对象,可以理解为核心业务单据。在业务进行过程中一定要对关键业务留下单据,通过这些单据可以追溯出整个业务流程。
时标对象具有两个特点:第一是事实不可变性,记录了过去某个时间点或时间段内发生的事实。第二是责任可追溯性,记录了管理者关注的信息。现在我们分析本系统时标对象有哪些,需要留下哪些核心业务单据。
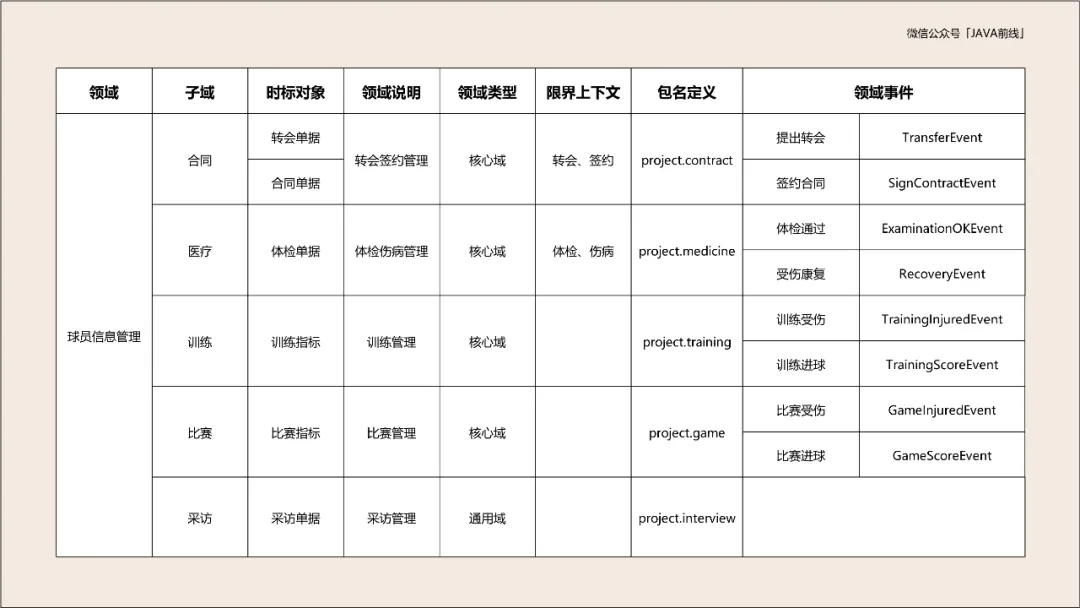
转会对应转会单据,体检对应体检单据,签合同对应合同单据,训练对应训练指标单据,比赛对应比赛指标单据,新闻发布会对应采访单据。根据分析绘制如下时标对象:

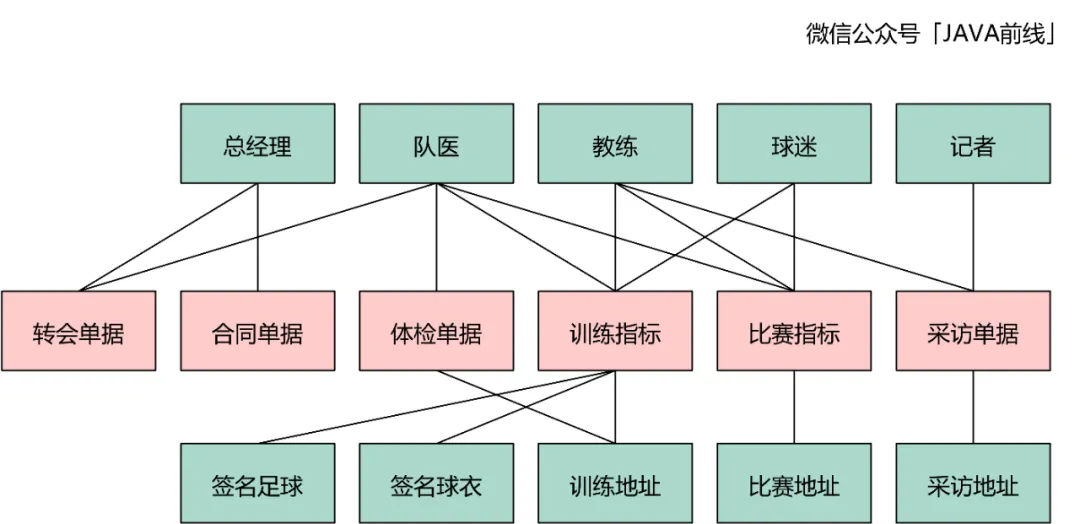
这三类对象在四色建模中用绿色表示,我们以电商场景为例进行说明。用户支付购买商家的商品时,用户和商家是参与方。物流系统发货时配送单据需要有配送地址对象,地址对象就是地。订单需要商品对象,物流配送需要有货品,商品和货品就是物。
我们分析本例可以知道参与方包含总经理、队医、教练、球迷、记者,地包含训练地址、比赛地址、采访地址,物包含签名球衣和签名足球:
在四色建模中用黄色表示,这类对象表示参与方、地、物是以什么角色参与到业务流程:
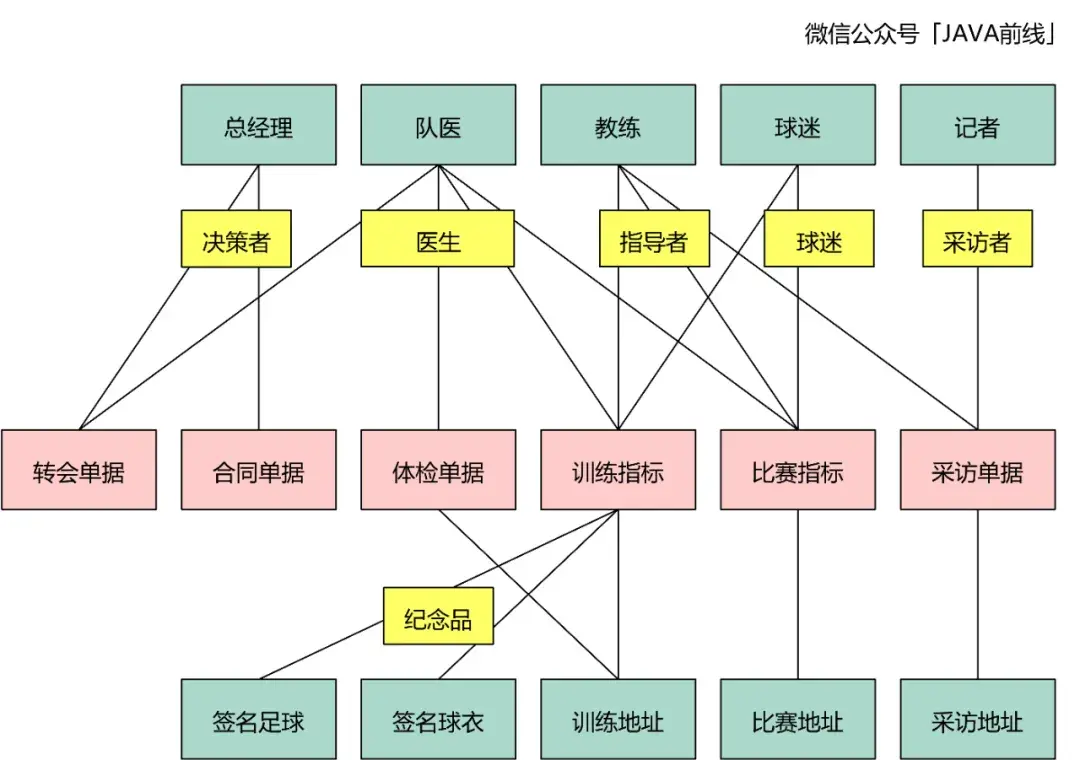
我们可以为对象增加相关描述信息,在四色建模中用蓝色表示:
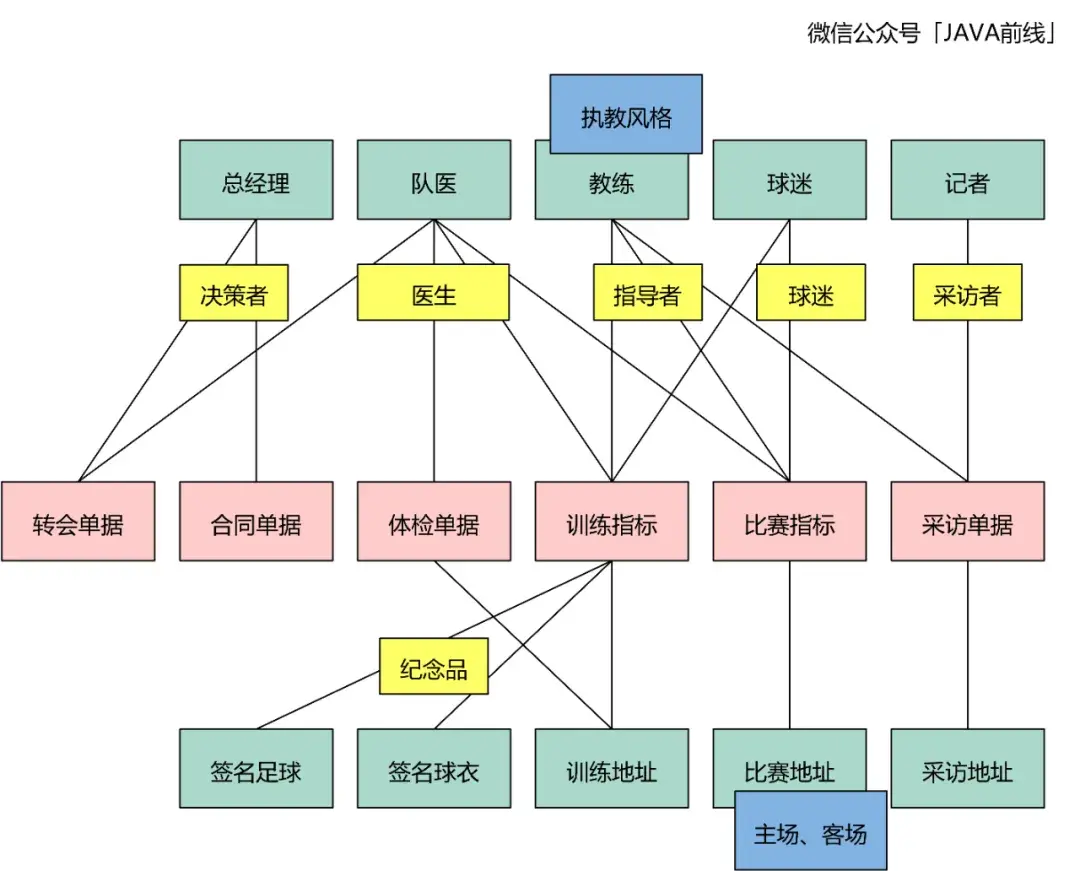
在四色建模过程中我们体会到时标对象是最重要的对象,因为其承载了业务系统核心单据。在划分领域时我们同样离不开时标对象,通过收敛相关时标对象划分领域。
当业务系统发生一件事情时,如果本领域或其它领域有后续动作跟进,那么我们把这件事情称为领域事件,这个事件需要被感知。
例如球员比赛受伤了,这是比赛子域事件,但是医疗和训练子域是需要感知的,那么比赛子域就发出一个事件,医疗和训练子域会订阅。
例如球员比赛取得进球,这也是比赛子域事件,但是训练和合同子域也会关注这个事件,所以比赛子域也会发出一个比赛进球事件,训练和合同子域会订阅。
通过事件交互有一个问题需要注意,通过事件订阅实现业务只能采用最终一致性,需要放弃强一致性,这一点可能会引入新的复杂度需要权衡。
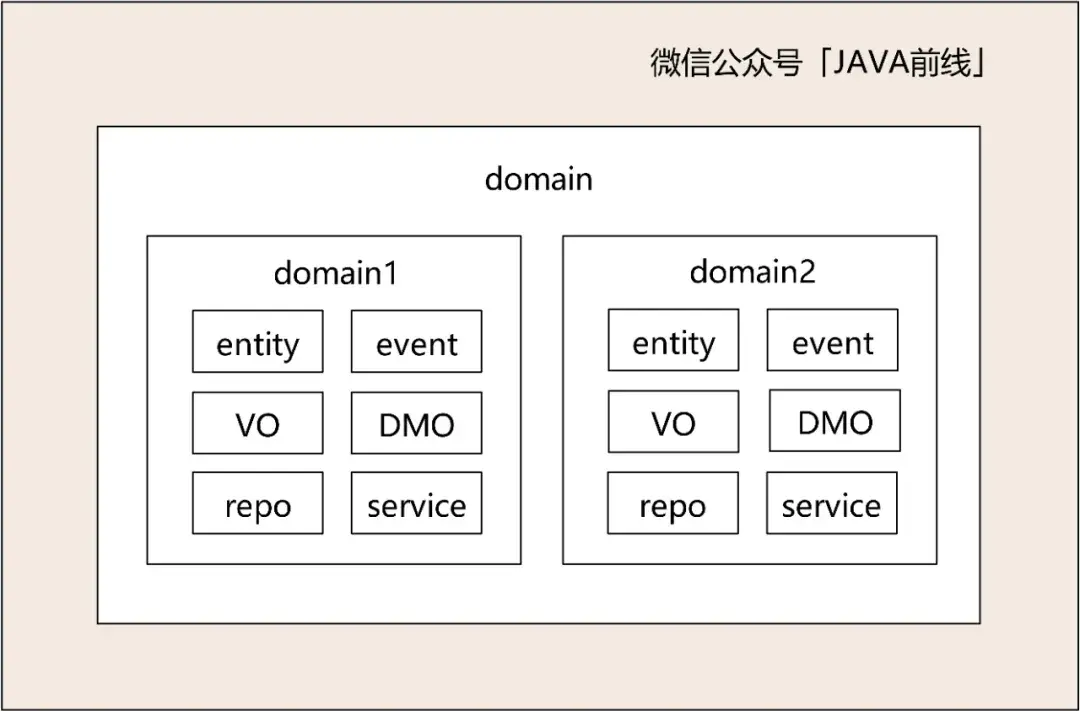
接口层:提供面向外部接口声明和DTO对象
访问层:提供HTTP访问入口
业务层:领域层和业务层都包含业务,但是用途不同。业务层可以组合不同领域业务,并且可以增加流控、监控、日志、权限控制切面,相较于领域层更为丰富,提供BO对象
领域层:提供DMO(DomainObject)、VO、事件、数据访问对象,核心是按照领域进行分包,领域内高内聚,领域间低耦合
外部访问层:在这个模块中调用外部RPC服务,解析返回码和返回数据
基础层:包含基础功能,例如缓存工具,消息队列,分布式锁,消息发送等功能
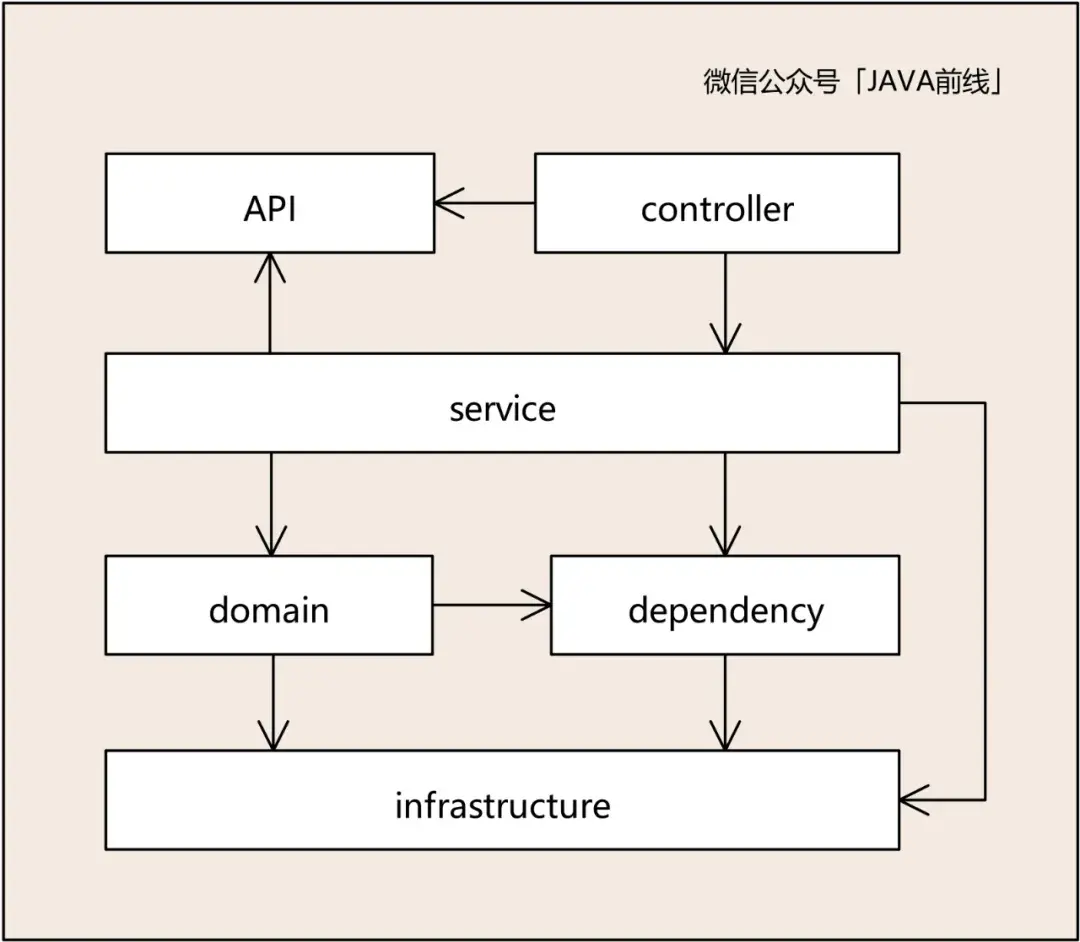
我们展开领域层进行分析。领域层的核心是按照领域进行分包,并且提供DMO、VO、事件、数据访问对象,领域内高内聚,领域间低耦合,例如domain1对应合同子域,domain2对应训练子域,domain3对应合同子域。
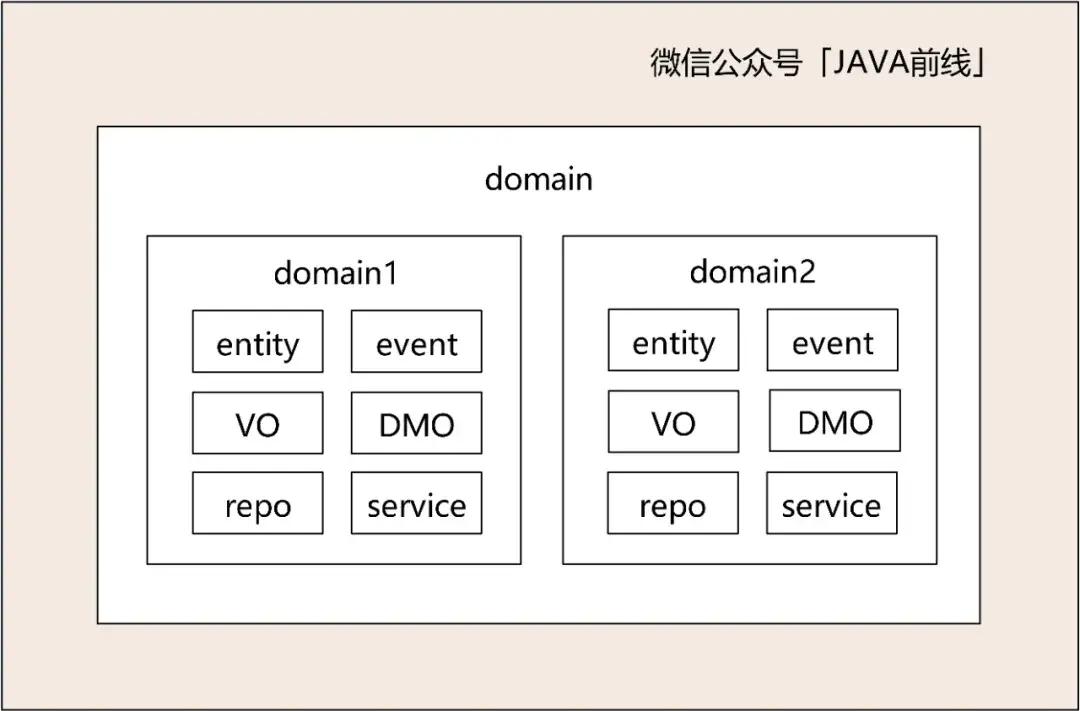
目前为止领域已经确定了,现在可以根据领域划分任务了,组内成员分别负责一个或多个领域进行详细设计,这个阶段就是大家非常熟悉的用例图,活动图,时序图,数据库设计,接口设计的用武之地。需要说明的是领域驱动设计不是取代详细设计,而是为了更清晰地详细设计。
本文探讨了DDD落地时需要关注的六个问题,并通过一个足球运动员信息管理系统案例落地了六个步骤。在实际应用中各业务形态千差万别,但是方法论却可以通用,我们需要明确DDD核心是分而治之各个击破,并配合一些经过检验的有效方法进行建模,希望本文对大家有所帮助。
欢迎大家关注公众号「JAVA前线」查看更多精彩分享文章,主要包括源码分析、实际应用、架构思维、职场分享、产品思考
软件开发不是一蹴而就的事情,我们不可能在不了解产品(或行业领域)的前提下进行软件开发,在开发前,通常需要进行大量的业务知识梳理,而后到达软件设计的层面,最后才是开发。而在业务知识梳理的过程中,我们必然会形成某个领域知识,根据领域知识来一步步驱动软件设计,就是领域驱动设计的基本概念。
一般软件设计或者说软件开发分两种:瀑布式,敏捷式。
前者一般是项目经理经过大量的业务分析后,会基于现有需求整理出一个基本模型,再将结果传递给开发人员,这就是开发人员的需求文档,他们只需要照此开发便是。这种模式下,是很难频繁的从用户那里得到反馈,因此在前期分析时就已经默认了这个业务模型是正确的,那么结果可想而之,数月甚至数年后交付的时候,必然和客户的预期差距较大。
后者在此基础上进行了改进,它也需要大量的分析,范围会设计到更精细的业务模块,它是小步迭代,周期**付,那么获取客户的反馈也就比较频繁和及时。可敏捷也不能够将业务中的方方面面都考虑到,并且敏捷是拥抱变化的,大量的需求或者业务模型变更必将带来不小的维护成本,同时,对人(Developer)的要求也必然会更高。
DDD则不同:它像是更小粒度的迭代设计,它的最小单元是领域模型(Domain Model),所谓领域模型就是能够精确反映领域中某一知识元素的载体,这种知识的获取需要通过与领域专家(Domain Expert)进行频繁的沟通才能将专业知识转化为领域模型。领域模型无关技术,具有高度的业务抽象性,它能够精确的描述领域中的知识体系;同时它也是独立的,我们还需要学会如何让它具有表达性,让模型彼此之间建立关系,形成完整的领域架构。通常我们可以用象形图或一种通用的语言(Ubiquitous Language)去描述它们之间的关系。在此之上,我们就可以进行领域中的代码设计(Domain Code Design)。如果将软件设计比做是造一座房子,那么领域代码设计就好比是贴壁纸。前者已经将房子的蓝图框架规划好,而后者只是一个小部分的设计:如果墙纸贴错了,我们可以重来,可如果房子结构设计错了,那可就悲剧了。
说了这么多领域模型的概念,到底什么是领域模型呢?以飞机航行为例子:
现要为航空公司开发一款能够为飞机提供导航,保证无路线冲突监控软件。那我们应该从哪里开始下手呢?根据DDD的思路,我们第一步是建立领域知识:作为平时管理和维护机场飞行秩序的工作人员来说,他们自然就是这个领域的专家,我们第一个目标就是与他们沟通,也许我们并不能从中获取所有想要的知识,但至少可以筛选出主要的内容和元素。你可能会听到诸如起飞,着陆,飞行冲突,延误等领域名词,让们从一个简单的例子开始(就算是错误的也没关系):
- 起点->飞机->终点
- 飞机->路线->起点/终点
- 飞机->路线->points(含起点,终点)
这个过程,是我们不断建立领域知识的过程,其中的重点就是寻找领域专家频繁沟通,从中提炼必要领域元素。
尽管看起来还是很简单,但我们已经开始一步步的在建立领域对象和领域模型了。
a)UML
利用UML可以清晰的表现类,并且展示它们之间的关系。但是一旦聚合关系复杂,UML叶子节点将会变的十分庞大,可能就没有那么直观易懂了。最重要的是,它无法精确的描述类的行为。为了弥补这种缺陷,可以为具体的行为部分补充必要说明(可以是标签或者文档),但这往往又很耗时,而且更新维护起来十分不便。
b)伪代码
极限编程是推荐这么做的,这个办法对程序猿来说固然好,可立刻就要将现有模型映射到代码层面,这对人的要求也是不低,并不容易实现。
还有一篇关于DDD写的不错的一篇文大家可以去参考一下:
终端研发部:什么是DDD(领域驱动设计)? 这是我见过最容易理解的一篇关于DDD 的文章了软件架构模式发展到现在可以主要经历了三个阶段:
1、UI+DataBase的两层架构、
2、UI+Service+DataBase的多层SOA架构、
3、分布式微服务架构
在前两种架构中,系统分析、设计和开发往往是独立、分阶段割裂进行的。
1、两层架构是面向数据库的架构,根本没有灵活性。
2、微服务盛行的今天,多层SOA架构已经完全不能满足微服务架构应用的需求,它存在这么一些问题
- 臃肿的servcie
- 三层分层后文件的随意组装方式
- 技术导向分层,导致业务分离,不能快速定位。
比如,在系统建设过程中,我们经常会看到这样的情形:A 负责提出需求,B 负责需求分析,C 负责系统设计,D 负责代码实现,这样的流程很长,经手的人也很多,很容易导致信息丢失。最后,就很容易导致需求、设计与代码实现的不一致,往往到了软件上线后,我们才发现很多功能并不是自己想要的,或者做出来的功能跟自己提出的需求偏差太大。
在这两种模式下,软件无法快速响应需求和业务的迅速变化,最终错失发展良机。此时,分布式微服务的出现就有点恰逢其时的意思了。
虽说分布式微服务有这么好的优点,但也不是适合所有的系统,而且也会有许多问题。
微服务的粒度应该多大呀?微服务到底应该如何拆分和设计呢?微服务的边界应该在哪里?这些都是微服务设计要解决的问题,但是很久以来都没有一套系统的理论和方法可以指导微服务的拆分,综合来看,我认为微服务拆分困境产生的根本原因就是不知道业务或者微服务的边界到底在什么地方。换句话说,确定了业务边界和应用边界,这个困境也就迎刃而解了。
DDD 核心思想是通过领域驱动设计方法定义领域模型,从而确定业务和应用边界,保证业务模型与代码模型的一致性。
领域驱动设计是一种以业务为导向的软件设计方法和思路。我们在开发前,通常需要进行大量的业务知识梳理,而后到达软件设计的层面,最后才是开发。而在业务知识梳理的过程中,我们必然会形成某个领域知识,根据领域知识来一步步驱动软件设计,就是领域驱动设计的基本概念。而领域驱动设计的核心就在于建立正确的领域驱动模型。
a、战略设计主要从业务视角出发,建立业务领域模型,划分领域边界,建立通用语言的限界上下文,限界上下文可以作为微服务设计的参考边界。
b、战术设计则从技术视角出发,侧重于领域模型的技术实现,完成软件开发和落地,包括:聚合根、实体、值对象、领域服务、应用服务和资源库等代码逻辑的设计和实现。
很多 DDD 初学者,学习 DDD 的主要目的,可能是为了开发微服务,因此更看重 DDD 的战术设计实现。殊不知 DDD 是一种从领域建模到微服务落地的全方位的解决方案。
战略设计时构建的领域模型,是微服务设计和开发的输入,它确定了微服务的边界、聚合、代码对象以及服务等关键领域对象。领域模型边界划分得清不清晰,领域对象定义得明不明确,会决定微服务的设计和开发质量。没有领域模型的输入,基于 DDD 的微服务的设计和开发将无从谈起。因此我们不仅要重视战术设计,更要重视战略设计。
- 接触到需求第一步就是考虑领域模型,而不是将其切割成数据和行为,然后数据用数据库实现,行为使用服务实现,最后造成需求的首肢分离。DDD让你首先考虑的是业务语言,而不是数据。重点不同导致编程世界观不同。
- DDD可以更加领域模型界限上下文边界快速拆分微服务,实现系统架构适应业务的快速变化,例如:系统的用户量并发量增长得很快,单体应用很快就支持不了,如果我们一开始就采用DDD领域驱动设计,那我们就能很快的把服务拆分成多个微服务,以适应快速增长的用户量。
- DDD 是一套完整而系统的设计方法,它能带给你从战略设计到战术设计的标准设计过程,使得你的设计思路能够更加清晰,设计过程更加规范。
- 使用DDD可以降低服务的耦合性,让系统设计更加规范,即使是刚加入团队的新人也可以根据业务快速找到对应的代码模块,降低维护成本。
- DDD 善于处理与领域相关的拥有高复杂度业务的产品开发,通过它可以建立一个核心而稳定的领域模型,有利于领域知识的传递与传承。
- DDD 强调团队与领域专家的合作,能够帮助你的团队建立一个沟通良好的氛围,构建一致的架构体系。
- DDD 的设计思想、原则与模式有助于提高你的架构设计能力。
- 无论是在新项目中设计微服务,还是将系统从单体架构演进到微服务,都可以遵循 DDD 的架构原则。
- 要领域驱动设计,而不是数据驱动设计,也不是界面驱动设计。
- 要边界清晰的微服务,而不是泥球小单体。
- 要职能清晰的分层,而不是什么都放的大箩筐。
- 要做自己能 hold 住的微服务,而不是过度拆分的微服务。
理论上一个限界上下文内的领域模型可以被设计为微服务,但是由于领域建模主要从业务视角出发,没有考虑非业务因素,比如需求变更频率、高性能、安全、团队以及技术异构等因素,而这些非业务因素对于领域模型的系统落地也会起到决定性作用,因此在微服务拆分时我们需要重点考虑它们。我列出了以下主要因素供你参考。
基于领域模型进行拆分,围绕业务领域按职责单一性、功能完整性拆分。
识别领域模型中的业务需求变动频繁的功能,考虑业务变更频率与相关度,将业务需求变动较高和功能相对稳定的业务进行分离。这是因为需求的经常性变动必然会导致代码的频繁修改和版本发布,这种分离可以有效降低频繁变动的敏态业务对稳态业务的影响。
识别领域模型中性能压力较大的功能。因为性能要求高的功能可能会拖累其它功能,在资源要求上也会有区别,为了避免对整体性能和资源的影响,我们可以把在性能方面有较高要求的功能拆分出去。
除非有意识地优化组织架构,否则微服务的拆分应尽量避免带来团队和组织架构的调整,避免由于功能的重新划分,而增加大量且不必要的团队之间的沟通成本。拆分后的微服务项目团队规模保持在 10~12 人左右为宜。
有特殊安全要求的功能,应从领域模型中拆分独立,避免相互影响。
领域模型中有些功能虽然在同一个业务域内,但在技术实现时可能会存在较大的差异,也就是说领域模型内部不同的功能存在技术异构的问题。由于业务场景或者技术条件的限制,有的可能用.NET,有的则是 Java,有的甚至大数据架构。对于这些存在技术异构的功能,可以考虑按照技术边界进行拆分。
DDD 战术设计对设计和开发人员的要求相对较高,实现起来相对复杂。不同企业的研发管理能力和个人开发水平可能会存在差异。尤其对于传统企业而言,在战术设计落地的过程中,可能会存在一定挑战和困难,我建议你和你的公司如果有这方面的想法,就一定要谨慎评估自己的能力,选择最合适的方法落地 DDD。
参考
https://blog.csdn.net/w1lgy/article/details/ https://juejin.cn/post/0 httpss://http://www.jianshu.com/p/b6ec06d6b594
补充:
关于都在聊DDD, 哪里超越了MVC: https://zhuanlan.zhihu.com/p/
以上这些东西如果在学习了DDD之后再去学习会对DDD有更深入的了解,但我觉得DDD相对比较基础,如果我们在已经了解了DDD的基础之上再去学习这些东西会更加有效和容易掌握。
我是架构师小于哥 @终端研发部 ,偶尔出来聊聊天,写写代码,经常分享开发经验与技术技巧哦
本文首发于微信公众号:前沿技墅(Edge-Book)
本文作者 VaughnVernon
一位经验丰富的软件工匠,也是追求简化软件设计和实现的思想领袖。他是畅销书《实现领域驱动设计》和《响应式架构:消息模式Actor实现与Scala,Akka应用集成》的作者。他在全球面向数百位开发者教授过IDDD课程,并经常在行业会议上发表演讲。他对分布式计算、消息机制、特别是Actor模型非常有兴趣。Vaughn擅长领域驱动设计和使用Scala、Akka实现DDD方面的咨询。
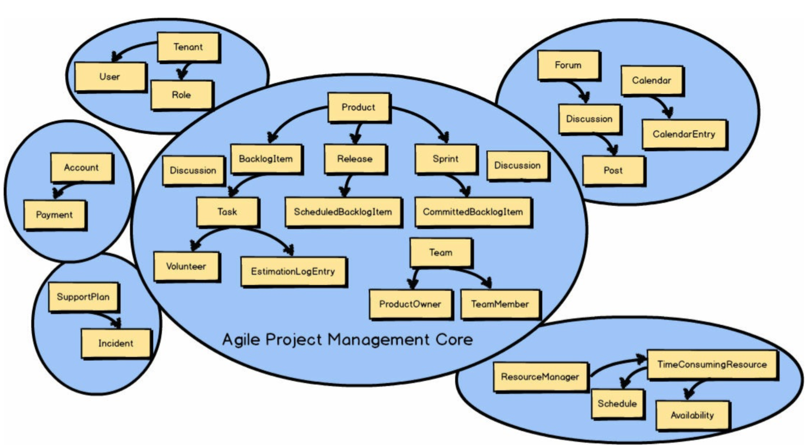
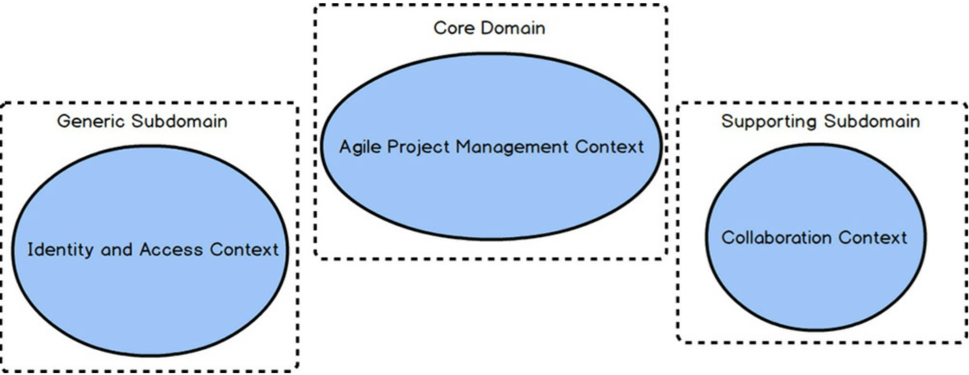
DDD项目中总会碰到很多限界上下文(Bounded Contexts)。这些上下文中一定有一个即将成为核心域(CoreDomain),而其他的限界上下文之中也会存在着许多不同的子域(Sub Domain)。图1中有六个限界上下文与六个子域。正是因为采用了DDD的战略设计,团队方能实现**的建模成果:限界上下文与子域之间一一对应。换句话说,敏捷项目管理核心即是一个清晰的限界上下文,也是一个清晰的子域。在某些情况下,一个限界上下文中有可能存在多个子域,但这并非是最理想的建模结果。
- 什么是子域?
简单地说,子域是整个业务领域的一部分。你可以认为子域代表的是一个单一的、有逻辑的领域模型。通常,大多数的业务领域都过于庞大和复杂,难以作为整体来分析,因此我们一般只关心那些必须在单个项目中涉及的子域。子域可以用来逻辑地拆分整个业务领域,这样你才能理解存在于大型复杂项目中的问题空间。
你也可以认为子域是一个明确的专业领域,假设它负责为核心业务提供解决方案。这意味着特定的子域将会有一位或多位领域专家领衔,他们非常了解由这些特定子域促成的业务的方方面面。对你的业务而言,子域也有或多或少的战略意义。
如果通过DDD来创建子域,它将会被实现成一个清晰的限界上下文。特定业务的领域专家将会成为共建限界上下文的团队中的一员。虽然使用DDD来建立一个清晰的限界上下文是**选择,但有时这只是我们一厢情愿的想法。
- 子域类型
项目中有三种主要的子域类型:
- 核心域(Sub Domain):它是一个唯一的、定义明确的领域模型,你要在这里进行战略投资,并在一个明确的限界上下文中投入大量资源去精心打磨通用语言。它是组织中最重要的项目,因为这将是你与其他竞争者的区别所在。正是因为你的组织无法在所有领域都出类拔萃,所以你必须把核心域打造成组织的核心竞争力。做出这样的决定需要对核心域进行深入地学习与理解,而这需要承诺、协作与试验。这是组织最需要在软件中倾斜其投资的方向。
- 支撑子域(Supporting Subdomain):这类建模方式提倡的是“定制开发”,因为找不到现成的解决方案。你对它的投入无论如何也达不到与核心域相同的程度。你也许会考虑使用外包的方式实现此类限界上下文,以避免因错误的认为其具有战略意义而进行巨额的投资。这类软件模型仍旧非常重要,核心域的成功离不开它。
- 通用子域(Generic Subdomain):通用子域的解决方案可以采购现成的,也可以采用外包的方式,亦或是由内部团队实现,但我们不用为其分配与核心域同样优质的研发资源,甚至都不如支撑子域。请注意不要把通用子域误认为是核心域。你并不希望对其投资过甚。当讨论一个正在实施DDD的项目时,我们最有可能讨论的是核心域。
- 应对复杂性
业务领域中的某些系统边界将非常可能是遗留系统,它们也许是由你的组织构建的,也许是通过购买软件许可的方式获得的。此时,你可能无法对这些遗留系统进行任何改造,但当它们对核心域产生影响时,仍旧需要我们认真对待。为此,子域可以作为讨论问题空间的工具。
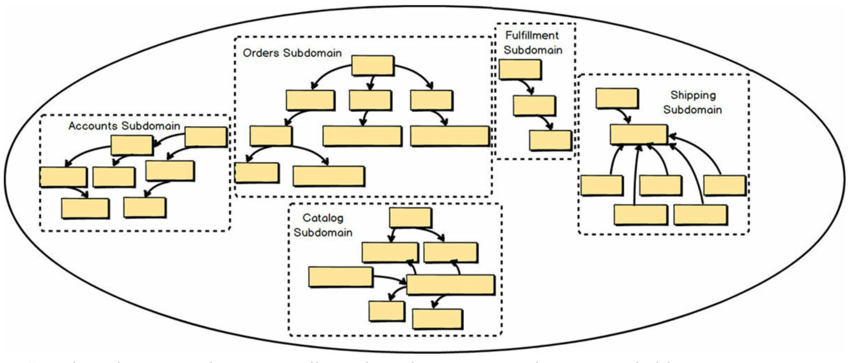
换言之,当我们在讨论某个遗留系统时,其中可能会包含一些,甚至许多逻辑领域模型,我们要将每个逻辑域模型当作一个子域对待。图2中,无边界遗留单体大泥球中,每个逻辑子域都已经被虚线框标识出来。共有五个逻辑模型或子域。这样处理逻辑子域的方式有助于我们应对大型系统的复杂性。这很有意义,因为我们可以像使用DDD和多个限界上下文应对问题空间一样,为其提供解决方案。
如果使用独立的通用语言思考,可能遗留系统就不会成为单体大泥球,这至少也可以帮助我们理解如何与它进行集成。使用子域来思考和讨论此类遗留系统有助于我们应对大型错综复杂模型的残酷现实。当使用这类工具时,我们可以明确那些对业务更有价值、对项目更重要的子域,而其他子域可以降低到次要位置。
考虑到这一点,你甚至可以通过同样的简单图表展示团队正在或正准备构建的核心域。这将帮助你了解子域间的关联与依赖。
当使用DDD时,限界上下文应该与子域一一对应(1:1)。也就是说,如果存在一个限界上下文,那么它的目标就应该是对应且只对应一个子域模型。想要始终做到这一点很难,但在可能的前提下,尽量以这种方式去建模很重要。这样可以使限界上下文清晰并且始终专注于核心战略举措。
如果必须在同一个限界上下文(你的核心域之中)中创建第二个模型,应该使用一个完全独立的模块将该模型从核心域中分离出来。(DDD的模块基本上等同于Scala和Java中的包,或者是F#和C#的命名空间)。DDD通过清晰的语言声明了一个模型是核心,而另一个只是它的支撑。你可以在解决方案空间中使用分离子域这种特殊方法。
本文节选自《领域驱动精粹》(Domain-Driven DesignDistilled)一书。作者:Vaughn Vernon,译者:ThoughtWorks笪磊、覃宇。
本书中文版预计将于年中面世,适用于对快速学习 DDD 核心概念和主要工具感兴趣的人。最主要的读者是软件架构师和开发者,他们将在项目中实践 DDD。通常,软件开发者会很快发现 DDD 的美妙之处,并被其强大的工具深深地吸引。尽管如此,本书也可以帮助高管、领域专家、经理人、业务分析师、信息架构师和测试人员理解这一主题。阅读原文将带你领略DDD大师Vernon的成名作,它是国内众多DDD实践者的启蒙读物。

活动推荐:2018领域驱动设计中**会DDD-China
许多同学在读了我有关领域驱动设计的文章之后,都会咨询同一个问题,就是具体怎么学习领域驱动设计,有没有什么比较好的学习路径。以我自己的经验而言,其实领域驱动设计并不是什么高深的学问,而编程本身作为一项实践性很强的工作,追求的也是 Show me your code 这种形式。所以在掌握了一定的理论知识之后,结合自己的工作,参考一些开源代码,多写代码,多反思,掌握领域驱动设计自然水到渠成。
但是在自己动手之前掌握一些必要的理论知识,也是必需的。「子曰: 学而不思则罔,思而不学则殆」,没有经过系统的学习就盲目编写代码,容易陷入到自己的思维误区,游离在领域驱动设计的大门之外。所以掌握领域驱动设计的基本概念,了解它的核心思想,看一些具体的示例代码是学习领域驱动设计的第一步,而阅读高质量的图书则是迈出这第一步的最好方式。所以本次会推荐一些适合大家阅读的,有关领域驱动设计的书籍,按照我自己觉得恰当的阅读顺序排列,并简单的做一些评价。
在学习领域驱动设计之前,最好对软件架构,设计模式有一定程度的了解。领域驱动设计中有许多软件架构相关的术语及上下文的描述,还提供了大量可供参考的模式,如果对相关知识一无所知的话很容易不知所云,无法理解领域驱动设计的重要概念。所以在真正学习领域驱动设计相关的知识之前,不妨先学习一些软件架构和模式的相关知识作为热身。以下是我推荐的相关入门书籍。
企业应用架构模式 (豆瓣)分析模式 (豆瓣)这两本书的作者是被国内开发者亲切的称呼为老马的 Martin Fowler。可能是因为他的<<重构>>名气太大,导致这两本书鲜少被人提及,特别是 <<分析模式>>。先看<<企业应用架构模式>>,这本书中罗列了「企业软件开发」中可能面临的问题,以及处理方式,并提供了大量的架构模式。特别是其中对于数据层访问的部分,列出了三种不同的解决方案,示例代码,更主要的是详细分析了各自的优缺点。而这一特点贯穿了全书,老马不仅告诉你了如何解决问题,也告诉了你不同解决方案之间的差异,大部分时候并不存在着完美的解决方案,架构的关键在于权衡。
如果说<<企业应用架构模式>>偏向于系统架构,那么<<分析模式>>更加倾向于业务。许多开发者或是架构师的问题往往不在于技术,而是对于业务的理解。如何更好的理解业务,能够用面向对象的方式设计合理的业务模型是系统架构的核心之一。<<分析模式>>中列出了大量在项目遇到的业务场景,例如如何设计一个账户结构;如果要支持多币种,如何设计一个支持多种货币的结构;更难能可贵的是老马在书中都是从一个简单的模型开始,然后指出其中的缺点,接着给出一个更近一步的模型,再以此反复,最终给出一个相对完善的模型(当然也是最复杂的)。
这两本书对于任何一个企业软件的开发者而言我觉得都应该是必读的,书中不仅提供了许多参考的方案与模式,更重要的是对于各种方案的分析与梳理,在开始学习领域驱动设计之前强烈建议先读一读这两本书。
领域驱动设计 (豆瓣)首先推荐的肯定是领域驱动设计的开山之作,也是领域驱动设计发明者 Eric Evans 的著作。这本书对于学习领域驱动设计的必读,书中介绍了领域驱动设计的背景,术语,基本概念,并使用了作者参与的几个项目作为示例,每一个重要的概念,名词,术语都能在书中找到。但是我个人觉得这本书并不是完美无缺的,最大的问题在于思路跨度较大,几个章节之间的衔接比较松散,如果没有一些架构或是模式的知识很难跟上作者的节奏。
这本书犹如一幅宏大的画卷,为我们展现了磅礴的气势,但是当我们需要去追究细节时却发现很多地方需要我们更多的思考。很多人也是通过这本书了解了领域驱动设计,但是大部分人读完之后却仿佛似懂非懂,可能明白了概念,但是无法落实到具体的代码上,抑或是对于领域驱动设计中的一些做法持怀疑态度,并没有理解作者的用心。
所以在读完这本书之后你需要继续学习。
实现领域驱动设计 (豆瓣)领域驱动设计精粹 (豆瓣)曾经听过一种说法,要学习某个领域的知识时,第一本书虽然很重要,可以帮助你更有效的入门,但是最重要的却是第二本书,因为它可以帮助你更为全面的了解这个领域。至少在学习领域驱动设计这件事上,这种说法有一定的道理。我建议你的第二,第三本书领域驱动的书可以<<实现领域驱动设计>> 和 <<领域驱动设计精粹>>。这两本书的作者是同一个人,个人感觉精粹更像是一本<<领域驱动设计>>的笔记,对于<<领域驱动设计>>中的核心概念,例如限界上下文,聚合,实体做了更加详细的解释。这本书非常薄,中文版总共才 150 页不到,一个周末看完都绰绰有余。我建议你可以话一个周末,把精粹和之前<<领域驱动设计>>对照的看,把自己之前不明白的概念重新思考一遍,我想一定会有所收获。
当概念逐渐清晰后,你关心的应该是如何将领域驱动设计的思想落实到代码上。正如书名所示,<<实现领域驱动设计>>聚焦在具体的代码实现上。作者借助一个实际项目的例子,用代码将大部分领域驱动设计的概念,模式展现在读者面前。这本书相对而言就厚多了,甚至要比原书都厚,所以你不妨花些时间,不仅重温一遍这些知识,也细细的品味一下作者的代码。完整的代码作者都放在 Github 上,供你参考。
其实撇开这两本书还有一本 领域驱动设计模式、原理与实践 (豆瓣),国外评价也不错,但是因为其中大部分示例是用 .Net 技术,而我对 .Net 也不是很在行,所以也没有读过这本书,具体如何就留给读者你自己探索吧。
函数响应式领域建模 (豆瓣)之前写过两篇有关函数式编程在领域驱动设计中应用的文章,其实里面大部分的思想也是来源一本书 —— <<函数响应式领域建模>> 。当你对领域驱动设计逐渐找到感觉,进而慢慢的得心应手,那么不妨看看这本 <<函数响应式领域建模>>。从函数式编程的角度出发,你一定会发现一片新的天地。在面向对象中一些领域驱动设计的实现可能并不优雅,而你也苦于找不到什么太好的解决方法,函数式编程很可能会给你惊喜。
<<函数响应式领域建模>>介绍了函数式编程的一些特定,例如抽象代数类型,不变性,高阶函数等,同时也把这些特性和领域驱动设计结合在一起,用具体的代码展示了如何解决领域驱动设计中遇到的各种问题,而代码也显得更加优雅,易于维护,非常值得推荐。
以上就是我推荐的有关领域驱动设计的书单。虽然阅读并不能使你成为一个领域驱动设计的专家,但是在概念都没有搞清的情况下就一股脑的扎进代码里,最终可能也是白白浪费了时间。对于编程与架构而言,学习与实践是不可偏废的,再强大的理论还是要落实在代码上,希望你能够阅读更多的书籍,编写更多的代码,找到自己的领域驱动设计学习之道。
欢迎关注我的微信号「且把金针度与人」,获取更多高质量文章

总结
少个分号:DDD 就是把面向对象做好相关
少个分号:API 设计的原则在事件风暴工作坊中,常用的划分限界上下文的方法是:
对前一步(事件风暴)产生的聚合进行分组,通过业务的内聚性和关联度划分边界,结合限界上下文的定义进行判断,并给出上下文名称。
[服务化设计阶段路径方案]
我将其称之为“聚合分组法”。然而面对一堆聚合,要得出一套合理的分组是非常困难的:
- “相关性”全凭经验
相关性是一个过于抽象的规则,非常依赖经验。
举个例子。在一个活动运营系统中,有“注册奖励活动”、“注册奖励规则”、“任务奖励活动”、“任务奖励规则”等概念。是把所有的“活动”分为一组,所有“规则”分为一组,还是把“注册”相关的分为一组,把“任务”相关的分为一组?这是个让人头疼的问题。也许你会说需要业务人员的输入,但是业务人员很可能只会告诉你这些概念之间都有关系。 - 不健康的聚合上下文
聚合分组法很容易导向一种按照聚合划分的架构。服务围绕聚合建设,而非针对某个业务价值,也就无法提供正确的业务价值。围绕聚合建设的服务,看上去可以复用,但是会造成服务间的紧耦合,容易成为最糟糕的分布式单体架构:
当架构是分布式单体时,往往需要同时修改多个服务,同时部署多个服务、服务之间调用非常频繁。
[You’re Not Actually Building Microservices]
聚合分组法也无法很好的识别“重复的概念”问题([领域驱动设计]14.1,指某一个概念,应该被设计成多个模型,因为它们有不同的规则,甚至有不同的数据)。使用聚合分组法往往导致把带着这样的聚合简单的放到某个限界上下文中。 - 隐藏的划分方案
还很可能是这种情况:在使用聚合分组法时,架构师已经有一个隐藏在心里的模糊的划分方案,在划分限界上下文时都是往该方案上靠。但是由于这个划分方案只是模糊存在于架构师的脑中,并没有拿出来讨论,很可能经不起推敲,最终无法言说,沦为“by experience”。
如何划分限界上下文?在回答这个问题前,让我们先看看限界上下文到底是什么。
在[领域驱动设计]第14章提出了著名的限界上下文。限界上下文是为了分解大型模型:
然而在几乎所有这种规模的组织中,整个业务模型太大且过于复杂以至于难以管理,甚至很难把它作为一个整体来理解。我们必须把系统分解为较小的组成部分,无论在概念还是在实现上。
有时,企业系统会集成各种不同来源的子系统,或者包含诸多属于完全不同领域的应用程序。要把这些不同部分中隐含的模型统一起来是不可能的。通过为每个模型显式地定义一个限界上下文,然后在必要的情况下定义它与其他上下文的关系,建模人员就可以避免模型变得混乱。
领域驱动设计 第四部分
bounded-context
限界上下文告诉我们,同一个概念,不必总是对应于一个单一模型,也可以对应于多个模型。用限界上下文明确模型要解决的问题,可以保持每个模型的清晰。限界上下文是领域模型的边界,也就是领域知识的边界。和上下文主题紧密相关的模型内聚在上下文内,而其他模型被会分到其他限界上下文中。限界上下文内的领域知识是高内聚低耦合的。
bounded-context-2
限界上下文的主题是什么呢?我认为是子域。每个限界上下文专注于解决某个特定的子域的问题。每个子域都对应一个明确的问题,提供独立的价值,所以每个子域都相对独立。子域及其对应的限界上下文中的模型会因为其要解决的问题变化而变化,不会因为其他子域的变化而变化,即低耦合;当一个子域发生变化时,只需要修改其对应限界上下文中的模型,不需要变动其他子域的模型,即高内聚。
Evans也谈论了限界上下文和子域的关系:
One confusion that Evans sometimes notices in teams is differentiating between bounded contexts and subdomains. In an ideal world they coincide, but in reality they are often misaligned.
Evans有时会在团队中发现的一个困惑,就是如何区分限界上下文和子域。在理想的世界中它们是重合的,但在现实世界中它们常常是错位的。
[Defining Bounded Contexts — Eric Evans at DDD Europe]
当我们设计一个新系统或者设计遗留系统的目标架构时,我们往往会按照理想的方式进行设计。而在理想情况下,子域和限界上下文是重合的。
[领域驱动设计精粹]中也讲述了一个通过寻找核心域相关的概念来识别限界上下文的方法。
根据子域来识别限界上下文,那么子域如何得到呢?我们通过分解问题域的方式,将整个问题域分解成若干个更小、更简单、更容易解决的问题子域。
我们需要某种方法,将领域分解成逻辑上相互独立且没有交叉的子域。在这里的方法是通过产品愿景,识别核心域,进而识别核心域周边的子域。
由于核心域是最明显、最容易识别出来的子域,所以我们先从核心域开始。
每一个子域甚至每一个领域模型都是为了产品愿景而存在的。我们分解子域的第一步,就是从产品愿景中获取核心域。产品愿景包含“相对抽象的产品价值”,以及“实现该价值的主要功能”。其中,主要功能就是我们寻找核心域的依据。想象一下,如果要做MVP的话,我们会挑选最能够提供其核心价值的功能来开发,以验证产品价值。MVP往往就是核心域。
以上述活动运营系统为例,其产品愿景是通过各种吸引用户的优惠活动,以帮助客户通过活动提升用户量和知名度。其核心域是给客户提供吸引用户的多样的灵活的活动,包括活动形式、活动规则和多种奖励。
核心域识别出来了,接下来就是识别核心域周边的子域。核心域往往不会独立存在,会有其他子域同核心域一起才能达成业务目标。这里需要回答的问题是:
- 有哪些子域是用来支撑核心域的?
这些子域是帮助核心域更好的工作。例如提供审批流程以配置核心域,提供各种辅助功能更好的为核心域提供内容。 - 有哪些子域是核心域衍生出来的?
核心域经常会产生一些数据,这些数据也有其价值。比如产生各种报表,活动奖励的发放记录。 - 有哪些子域是用来支撑或衍生自这些新识别出的子域的?
用来支撑核心域的子域、以及核心域衍生的子域,也有各自的支撑子域和衍生子域。
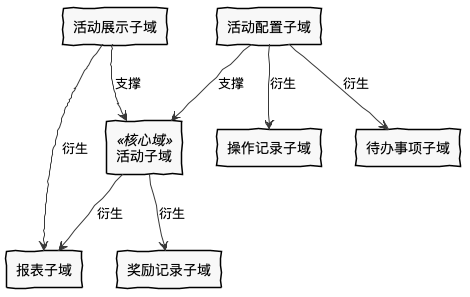
活动运营系统
识别出来的每个子域只对应一个问题,子域之间是相互独立的,没有交叉,不是包含关系。所以子域加起来就是整个领域。
也可以通过角色、时间等因素分解子域。解决不同角色的问题可能分属不同子域,比如用户参与活动、运营人员配置活动分属不同子域,两个子域的变化原因不同;不同时间使用的功能可能属于不到子域,比如先有运营人员配置活动,再有用户参与活动,配置活动和参与活动分属不同子域。
如果按照聚合分组划分限界上下文,很可能出现“活动上下文”,同时活动模型,即承担运营人员配置的职责,又承担用户参与规则校验的职责,这会导致职责过多,违背了单一职责。另外活动规则校验的模块需要支持高并发,需要使用和配置模块不同的技术架构。如果这些相似的概念和不同的技术实现属于不同的上下文,就可以保持各自模型的完整,技术上也可以做到独立演进。
理论上子域仍然可以被分解。例如活动子域可以分解为活动参与规则子域、奖励子域等。那么子域粒度多大是合适的呢?
我们希望每个子域可以解决某个特定的问题,让这个问题的解决方案都内聚在子域对应的限界上下文内,所以如果问题的再分解没有的边界并不清晰,建议先不分解。随意的拆分会导致成为“分布式单体”。
一个限界上下文封装了一个相对独立子领域的领域模型和服务。
子域subdomain和限界上下文某种意义上是互相印证的
DDD战术篇:领域模型的应用
这个时候我们通过事件风暴得到的领域模型就可以出场了。领域模型和子域都是从业务知识里分析得到的,将两者匹配起来可以再次验证我们对于业务的理解、子域的分解和领域模型是否合理。
为每个子域创建一个解决其问题的限界上下文,然后为每个领域模型找到其归属的限界上下文。每个领域事件都是为了解决某个问题,它和它相关的领域模型就应该放在这个问题子域对应的限界上下文里。
比如“活动已上线“这个事件,由运营人员在配置时触发,会导致用户可以开始参与活动。那么这个事件及其对应的“活动”概念应该被分为两个模型,分别归属于活动配置子域对应的“活动配置上下文”和活动子域对应的“活动上下文”。
为领域模型寻找归属完成后,我们会发现这么几个情况。
- 同一个概念可能会出现在多个限界上下文中。发生这种情况很正常,说明这多个子域都需要这个概念,而且很可能不同子域的领域模型不完全相同。
比如刚才说到“活动”既存在于“活动上下文”中,又在“活动配置上下文”中。这里我们就很好的识别出了“重复的概念”问题。 - 也有一些概念重复在多个限界上下文中,这些概念和该上下文的主题并没有紧密的关系。这些模型可以单独出一个限界上下文,用以同时支撑多个限界上下文,以减轻限界上下文的负担。
- 有时候某个模型找不到合适的限界上下文,说明很可能是遗漏了一个子域,那就需要回到“分解子域”步骤,重新审视产品愿景。
聚合分组法采用“相关性”来划分限界上下文,其问题在于缺少一个主题,而子域恰好可以用来提供这个主题。本文的“愿景”-“核心域”-“周边子域”方法,不是唯一分解问题域的方法,任何可以将领域分解成高内聚低耦合的子域的方法都是可行的方法。
- 领域驱动设计
- 实现领域驱动设计
- 微服务设计
- 微服务 | Martin Fowler
- Pattern: Decompose by subdomain
- DDD & Microservices
- DDD战术篇:领域模型的应用
- 当Subdomain遇见Bounded Context
- 【博客】使用 DDD 指导微服务拆分的逻辑
- 领域驱动设计实践(战略篇)
- PROBLEM SPACE vs SOLUTION SPACE
- You’re Not Actually Building Microservices
- 利用事件风暴发现限界上下文
- Pattern: Saga
- 精益价值树
- Complicated
- Defining Bounded Contexts — Eric Evans at DDD Europe
- 领域驱动设计精粹
文/祁兮 更多精彩洞见,请关注微信公众号:ThoughtWorks洞见
作者:Einar Landre
译者:徐培
校审:钱平、伍斌
从这到那,又回来了。——Bilbo Baggins
本文解释什么是动态领域建模(dynamic domain modelling),为何需要它,以及使其成为领域驱动设计一等公民的价值。首先,我要感谢Eric对软件社区的开创性贡献,还要感谢他和我在下面两项工作中所进行的精彩讨论——参与挪威跨国能源公司Equinor(前身是Statoil公司)的石油贸易投资组合项目,并为OOPSLA技术大会撰写论文。与Eric讨论是一段很棒的经历。
《领域驱动设计》这本书出版已经有15年了。那时候,没有iPhone,没有Facebook,没有Netflix,亚马逊刚刚盈利两年。 Windows 2000还是微软的旗舰操作系统,Sun Microsystems还是一家领先的科技公司,Java已有9年历史,而关系数据库统治着企业的数据中心。
从那时起,云计算、大数据、移动应用、物联网、边缘计算、机器学习和人工智开始成为我们专业词汇的一部分。 诸如Swift、Scala和Go之类的新编程语言开始登上舞台,而Python之类的旧语言开始复活,并在数据科学中占主导地位。
显而易见,我们的行业经历了深刻的变化。这些变化,使得领域驱动设计变得更加重要,同时也要求领域驱动设计本身进行改变,以适应软件定义世界的需求。

领域复杂性
英国系统思想家Derek Hitchins认为,复杂性是多变性、连接性和无序性的函数。如果组件之间的差异越大,组件之间的连接更多,并且连接相互纠缠(而非有序),那么我们认为事物会越复杂。
复杂性的挑战,在于其中涉及了两种类型的连接,即能导致结构复杂性的稳定连接,和能导致动态复杂性的任意连接。
领域的结构复杂性常见于嵌套结构,例如下面事物中的组件层次架构——产品(飞机,船舶)、零售分类或项目计划。让这些对象变得复杂的因素,包括其内部状态模型、规则及对象之间的连通性和可变性的深度。
领域的动态复杂性,源于自治组件或自治对象之间的交互。这就是在动态系统中所见到的复杂性。对象内部可能具有高度的复杂性,而对象之间不断变化的交互作用和任意连接性,造就了动态复杂性。
来去匆匆的对象们,可能因对方行为或沟通的缺失而迷路,可能会相互协作、竞争、组建团队。一个对象所采取的行为,会直接影响其他对象的可选项。
领域驱动设计解决了结构复杂性的问题。其中的实体、值对象、聚合、存储库和服务等概念,是结构性构建块,有助于创建有序性,减少耦合性,从而简化限界上下文内部及之间可变性的管理。
而动态复杂性的问题则完全没有解决。Vernon在他的书中引入了领域事件的概念,这是一个良好的开端。但我们需要的不仅仅是事件,还需要在企业消息软件上下文中管理事件的方式。
现实世界由动态系统所组成。领域的动态复杂性源于异步、并发、竞争和协作的过程。
创建面向对象编程的目的,原本是为了通过仿真技术研究和分析一个系统中各个过程,当时的仿真编程语言Simula提供了必要的支持。但不知为何,面向对象的软件社区失去了对动态系统的兴趣,却将关注点转向了编程语言。而动态系统的研究,则留给了控制论(cybernetics)和人工智能(AI)社区。
值得一提的是,控制论和人工智两者之间亲如手足。它们都是在1940年代后期的研讨会上构思出来的。两者的差异点在于,控制论学者倾向于使用微积分和矩阵代数作为工具,来解决适合这些工具的问题,比如由固定的连续变量集所描述的系统。而AI社群则没有这些限制,而是选择了逻辑推断与计算工具。这使他们能够处理语言、视觉和规划等问题。
在AI社区中,理性行动的思想催生了理性代理(agent,源自拉丁语agere,意为做事),也称智能代理,例如可工作的计算机程序。当然,所有程序都能工作,但代理应该做得更多——包括能自主运行、持续运行、适应环境、做出改变、创造和追求目标。理性代理是能为实现**结果而采取行动的代理(此定义出自Russel和Norvig)。
智能代理是一种能通过观察环境解决问题,并针对该环境执行操作的程序。在这期间,代理可以扮演角色,与其他代理(包括人类)协作并互动。
智能软件(Software wise)是智能代理的对象,能控制自身的执行线程,自主运作,并能做有趣的事情。但问题是,几乎无人将代理视为领域对象,我认为这必须改变。
为了说明代理也是领域对象,下面提供一段能概括代理的结构Java代码:

智能代理是人工智能的基石。其种类繁多,小到机器人,大到宇宙飞船。智能代理是理解其自主性(与代理的学习能力密切相关)的关键。
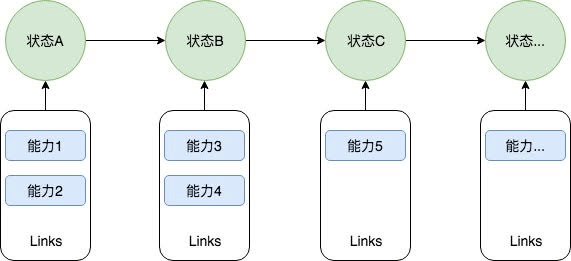
智能代理的难题,是代理推理方法(或称作代理功能)的实现,即将给定的感知或目标与可能的**动作进行映射。代理功能可以非常简单,也可能非常复杂,我尝试使用能力栈来说明这些功能:
- 使用诸如智能代理软件模型BDI和认知架构Soar之类的工具,实现基于推理的行为
- 使用数字滤波器、数学控制系统,模糊逻辑和神经网络,用以发现连续的行为
- 使用有限状态机,构建状态驱动的行为
- 使用无记忆能力的函数(例如读取测量值),表示的简单行为
要实现最复杂的代理功能,意味着要将诸如Soar和BDI这样的认知架构,与工具箱中的所有其他的可用工具结合起来使用。Soar由John Laired和Allen Newell于1983年创建,现由密歇根大学Laird的研究小组所维护。BDI(全称Beliefs-Desires-Intentions 信念-期望-意图)是由Michael Bratman于1991年在他的人类实用推理理论中创建。目前正在进行的有关Soar和BDI的研究,都受到美国国防部门对智能代理自主能力的需求的推动。
Soar和BDI这两种领域模型,都是对人类大脑如何推理并将感知转化为行动所进行的建模。这两种架构都获得开源和商业实现的支持,例如JACK、BDI4Jade、Gorite和SOAR。
在教授面向对象编程时,已故教授Kristen Nygaard使用了咖啡馆里的人物作为他的系统隐喻。在观察咖啡馆里的人物时,我们会发现做有趣事情的对象,如服务员、顾客、门卫和收银员,以及定义和描述事物的对象,如菜单、食物、账单和餐桌等。

行为建模面向那些做有趣事情的对象。这种建模从任务环境开始,并引出更详细的事件和任务模型。任务环境定义了上下文,并且定义了有哪些代理(如服务员),代理的绩效指标(如良好的用餐体验),代理的操作环境(如餐厅)以及代理的执行器(如言语、手和脚)和传感器(如眼睛和耳朵)。
事件和任务模型会使用一系列问题,以此将高层次的目标分解为更详细的任务:要执行的任务是什么?什么事件触发了某项任务?任务的预期成效是什么?发送了什么消息?以及谁是接收者?谁执行了这项任务?在执行任务时会创建哪些事件?
在开发事件和任务模型时,需要考虑两个重要因素:首先,哪些任务将同时执行?并且它们是否会争用相同的资源?如果是,那么就会面临竞态条件和可能的死锁,所以需要并发编程技能。其次,如果任务的执行时间有限,即必须在给定的时间范围内完成任务,那么我们需要有实时系统的技能。
为了支持动态系统的建模,我们需要在领域驱动设计工具箱中添加4个概念:
- 任务,即代理要执行的工作。
- 代理,即感知其环境并执行任务的对象。
- 代理功能,即代理如何将其感知映射到其所要执行的任务的能力。
- 事件,即发生了的事情,且因此触发了要执行的任务。
只要把这4个概念打造为领域驱动设计的一等公民,那么我们就有把握去构建更丰富和更强大的领域模型,从而构建物联网、工业4.0、人工智能和一个可用软件无处不在的世界。
对于那些想要更进一步钻研的人来说,Douglas、Russel和Norvig以及Jarvis等人的著作都是很好的读物(详见下文)。Hitchins的书则是为特别感兴趣的人而准备的。我期望所有人都已经读了Eric或Vernon的书。
有人可能会问,代理和微服务有什么不同?我的答案是粒度。代理是对象,它们最终由所选语言中的构造函数来定义。
如果领域问题最需要使用认知架构来解决,那么建议去找一个成熟的框架,而不用自己构建。
为什么现在要提“领域对象的极致就是代理”?
- 物联网以及软件定义世界的趋势,改变了商业软件的规则。后台进程必须能够响应边缘事件,还必须能够向边缘进程和设备实时发送新指令。
自动化工作始于捕获任务。 - 希望你现在可以理解这一点——代理是许多领域的一等公民,是领域对象发展的极致。
参考文献
- Douglas, Doing hard time, Developing real-time systems with UML, Objects, Frameworks and Patterns.
- Evans, Domain-Driven Design, Tackling the complexity at the heart of software.
- Hitchins, Advanced systems, thinking, engineering and management.
- Jarvis et al, Multiagent Systems and Applications: Volume 2: Development Using the GORITE
- BDI Framework.
- Russel, Norvig, Artificial intelligence, A modern approach, third edition.
- Vernon, Implementing Domain Driven Design.
- 最近公司开始推行DDD(领域驱动设计),基于充血模型的面向对象开发模式是DDD的特点之一,而在平时开发中我们都使用的是MVC 架构是基于贫血模型的面向过程开发风格,也许有同学就会问了,贫血模型和充血模型是的什么呢?
贫血模型:
- 定义对象的简单的属性值,没有业务逻辑上的方法(个人理解)没有找到官方解释
充血模型
- 充血模型也就是我们在定义属性的同时也会定义方法,我们的属性是可以通过某些方式直接得到属性值,那我们也就可以在对象中嵌入方法直接创建出一个具有属性值的对象。也就是说这个对象不再需要我们在进行进一步的操作,这也就复合了OOP的三大特性之一的封装(个人理解)
我们在平时进行web开发的时候,就是定义DTO,定义数据库Model,BO等,对其进行get set方法,然后通过service 对Bo对象进行操作,最后通过copy属性持久化数据库和DTO传输。但是如果是充血模型的话,就不用在service进行属性赋值,而是在创建这个对象的时候,进行业务操作,赋予其属性值。这里也就是DDD的思想,这个对象也就是DDD所定义的Entity 或者 value 。Service也就是domianService,由多个Entity 和value 组成,构造最终的领域模型。
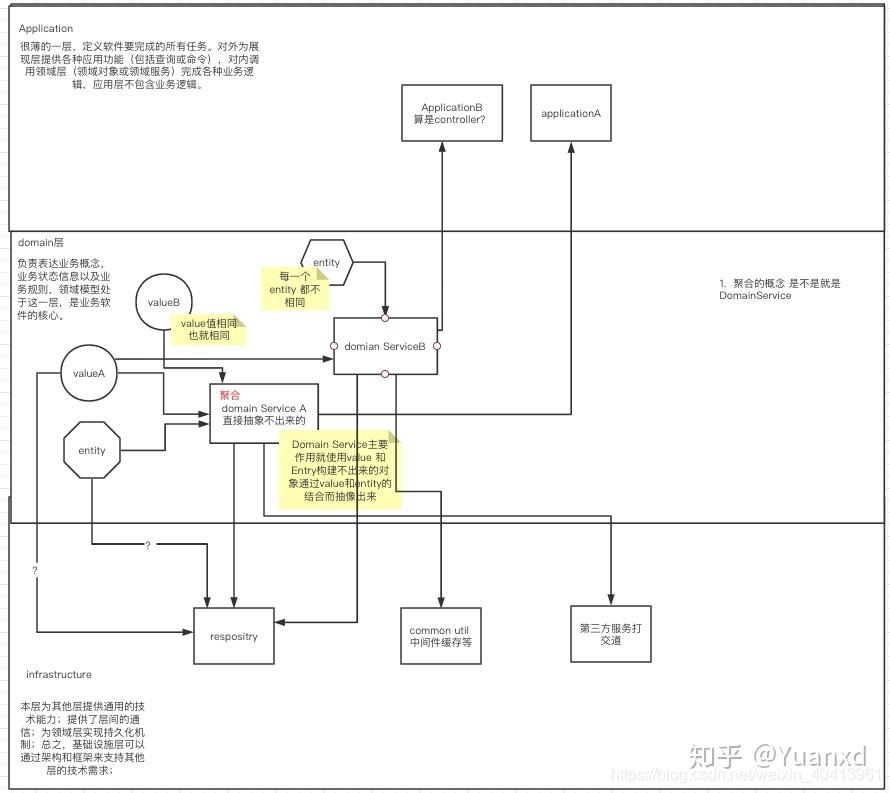
- 使用贫血模型的传统开发模式,将数据与业务逻辑彻底分离,通过get set方法改变对象属性,对象属性可以随意被修改,这也就如上面所说违反了OOP的三大特性之封装特性。这样的编程方式也就是面向过程的编程方式,面向过程的编程方式是符合人类大脑逻辑的,不用使用太多的设计模式和过多的设计。还有就是在开发中大家经常说的一句及其不负责任的一句话:“怎么方便怎么来”,就一直在堆代码,完全不像以后的可拓展性。也就是说基于贫血模型的编程方式是面向过程编程,人类的思考逻辑方式很符合,在编程过程️也很方便,所以大家都很愿意接受这种编程方式。
- 综上所述:
- 充血模型的设计要比贫血模型更加有难度
- 大家一致使用基于贫血模型的面向过程编程已经成为习惯,比较难转换思想
- 还有就是对代码不负责任的态度。(这是大数程序员的通病吧)
- 使用充血模型也就是使用基于充血模型的DDD的开发模式,上文也一再强调,充血模型也是定义模式复杂,设计难等,代码开发量也许时其他模型的多,其主要原因还是设计起来难。那就是说如果我们设计一个很简单的业务逻辑,那我们还需要这么复杂的设计思想吗? 并且这个业务在后续的迭代也不变复杂,那我个人认为我们就使用我们的基于贫血模型的面向过程的编程思想。简单的东西何必复杂化呢。这里突然想到我同时讲的一个段子:
- 普通程序员写hello word 直接print
- 高级程序员写hello word 各种设计模式各种可拓展最后输出hello word
- 技术专家写hello word ,直接打印hello word
- 当然我们在进行一个复杂的业务场景,那就需要进行基于充血模型的DDD(领域驱动模型)开发模式了。其实DDD的开发模式也就是充分的遵循OOP发三大特性(或者四大特性,封装,继承,多态,(抽象)),如果是贫血模型的面向过程编程那到最后的结果就是点练成线,由线变成网,密密麻麻不可维护。所以说复杂业务逻辑基于充血模型的进行开发。但是也会是有问题的那就是类膨胀,一个类有很多代码。这个还是可以解决的,那就是通过设计模式,喝业务逻辑细分进行解决。
- 贫血模型和充血模型的简单解释
- 以及DDD开发模式和面向过程编程与充血和贫血模型的关系
- 对比了基于贫血模型的MVC层的面向过程编程范式和基于充血模型的面向对象编程范式的对比
- 两种模型分别适用于那种场景
- https://time.geekbang.org/column/article/ 设计模式之美
- https://zh.wikipedia.org/wiki/%E5%8F%8D%E9%9D%A2%E6%A8%A1%E5%BC%8F 反面模式
- http://www.cnblogs.com/netfocus/archive/2011/10/10/2204949.html DDD的基础理论
本文从需求分析到API设计,试图描述领域驱动设计的过程及思想。同时也能看的出领域驱动设计并不是孤立存在的,它为解决开发团队和业务人员之间沟通而生,进而驱动微服务的划分以及API的设计。
作为一个领域驱动设计的实践者,我切实感受到了领域驱动为软件开发带来的好处,同时在实践领域驱动的过程中也感受到了困难,这种困难体现在工程实践的方方面面,例如什么是领域驱动的**设计?如何把书本上的设计灵活的应用在自己的项目上?如何跟团队成员就设计达成一致?
本文尝试从领域驱动设计的目的出发,试图通过简单的描述来说明领域驱动设计的思想。
作为一个软件开发者,多数人以为自己的职责就是编写代码,然而软件开发不是工厂流水线,如果所有的软件开发者不停的开发新功能而不关心设计,那么软件开发过程将会变得越来越复杂,关于这一点大家应该都有不同程度的感受。
软件开发工程师的工作是通过软件来解决问题,编写代码只是其中的一部分工作,设计和交流同样重要。而领域驱动设计就是一个让软件开发工程师交流和共享领域知识的途径。
作为一个问题的解决者,能否理解和认识问题的前因后果至关重要。很明显,如果你只看到了问题的表面,或者对事实有曲解,你显然不会找到一个有效的解决方案。对于开发者,如果你编写的代码只是你的理解,而不是领域专家的理解,你如何保证线上产品的质量?
那么如何保证开发者编写的代码就是领域专家的想法?最简单的办法就是让领域专家来编写代码,但是这种方案可遇不可求,还有没有别的办法呢?
如果领域专家,开发团队以及代码能够共享一个模型,这将有效减少不同利益相关者的沟通及交流,并且会确保所有人都在解决同一个问题。
这个想法要求开发者能够把代码设计为一个反映业务的模型,而这正是领域驱动设计的核心思想。
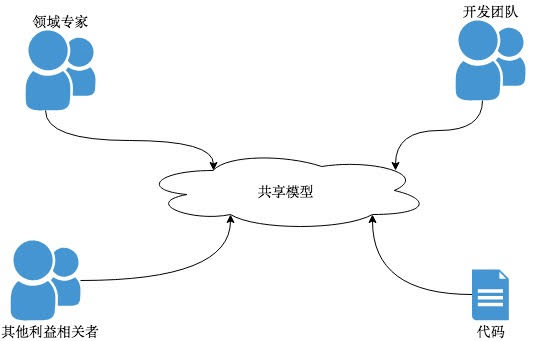
为了在领域专家和开发者之间建立一个共享模型,收集需求并理解业务是第一步。收集需求和理解业务的方式多种多样,而事件风暴经常被用来达到这一目的。业务逻辑可以看做是一系列状态的转换过程,而这些过程转换又被称为领域事件。比如“订单已提交”就是一个领域事件,如果把这个领域事件看做是订单业务的开始,通过梳理”订单已支付”以及”订单已出库”等后续的领域事件,就可以理解整个订单业务。此时对业务的理解被称为“问题域”。

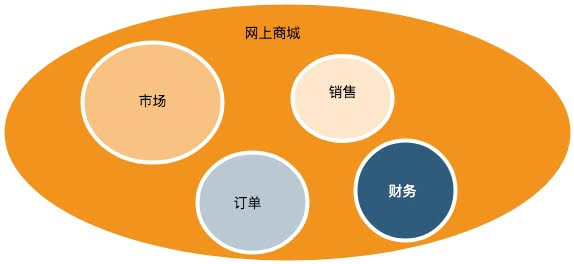
通过事件风暴,开发团队和领域专家已经对整个”问题域”有了理解,但是现在着手解决“问题域”还有点早。当我们在面对一个大的问题时,自然而然会想到先将大的问题划分成若干个小问题,然后再考虑各个击破。接下来的一步就是把大的问题域划分为若干个小的问题域。我们有一个网上商城的问题域,能不能把它分割为更小的问题域?
答案肯定的,我们把网上商城的问题分为:“订单”,“销售”,“市场”,“财务”,“采购”等若干个小问题域,再针对小的问题域分而治之。小的问题域在领域驱动设计中被称为“问题子域”。
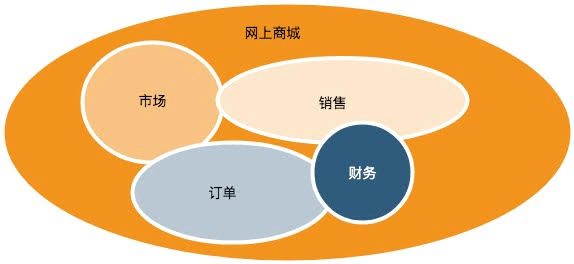
理解了问题域并划分为问题子域并不意味着你就能创建出一个好的方案,你无法针对问题子域的所有信息设计出一个解决方案,你的解决方案只会专注于那些有助于解决该问题子域的信息,对于不相关的信息则会人为的屏蔽掉。
为什么叫限界?
在现实世界中,领域的边界很模糊,但是要设计一个好的解决方案,我们需要对问题子域加上一个边界,将不重要的信息排除在边界外。让解决方案专心解决重点问题。
为什么叫上下文?
每个上下文都代表着该解决方案的专业知识。在同一个上下文里,我们共享统一的语言和一致的设计。
通过界限上下文人为将问题子域限制在有限的界限内,你才可以着手创建解决方案。
团队之间共享的术语和词汇被称为统一语言。统一语言用来定义业务领域的共享模型,当然可以用在项目的任何地方,包括需求分析和设计,最重要的是统一语言还需要出现在代码中。另外,统一语言在不同的界限上下文中往往不能够通用,例如在“认证上下文”中提到“用户”,在“机票订单上下文”中叫做“乘客”。
有了界限上下文,让解决方案聚焦在最有用的信息里,你才可以着手建立共享模型。
如何才能建立一个不错的共享模型呢?
使用可视化的图示似乎是一个不错的想法,但实际上画出一个能够表达所有领域知识的图示并不是一个简单的工作;如果你有数据库开发相关的经验,你可能会想到通过表和主外键来表达领域知识,如果你有这样的想法那你就错了,在领域驱动设计中讲究通过领域逻辑来驱动设计和开发工作,而不是通过数据库模型来驱动开发。
在领域驱动设计中这一步叫做”领域建模“,你应该用代码建立一个反映领域知识的模型,这个模型跟领域专家口中的领域知识是一致的。领域模型是提供业务能力的核心部件,也是整个应用程序提供业务能力的核心。

对于开发者而言领域建模至关重要,也是最考验开发者功底的一个环节。一方面开发者需要抽象出一个跟领域专家口中一致的模型,另一方面开发者还需要通过代码将这个模型表达出来。你需要恰如其分的使用一些面向对象的技巧把领域知识抽象到一个代码模型中,在这个过程中你需要了解”值对象”,”实体“,”聚合根“等概念,在此不再细说。
在领域建模以及之前的步骤中,我们都没有提及数据库,因为领域驱动设计的核心是用代码建立一个共享模型,而数据库设计根本就不是领域驱动设计关心的内容。
但是终究我们还是要把领域模型的状态持久化到数据库中,有没有办法在不关心数据库表结构的情况下,将已经建立好的领域模型持久化?主流ORM的Code First恰好匹配我们现在的处境,已经有一点为领域驱动设计而生的味道了。
但是即便是ORM的Code First也会对领域模型有侵入,你可能需要根据不同的ORM为模型加上一些注解或者配置之类的代码,这跟领域驱动设计其实是相互违背的,我们希望用代码创建一个纯净的领域模型,这个模型封装着领域专家的领域知识,除此之外的代码都跟领域模型是无关。
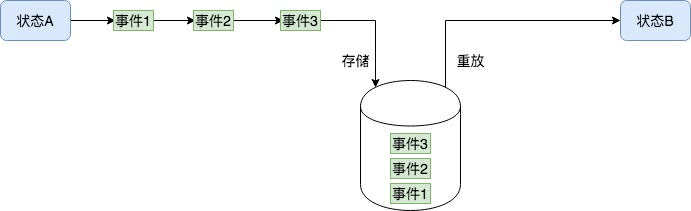
解决上面问题的思路是引入领域事件和事件溯源。领域模型在提供业务能力的过程,就是领域模型状态发生变化的过程。一旦领域模型的状态发生了变化,就会产生一个事件,这跟事件风暴中提到的业务事件是一致的,例如”用户已下单“。订单模型在提供”用户已下单“的业务能力后发生了状态变化。事件溯源的思路就是只持久化领域事件,然后通过还原事件的方式将领域模型还原在最新的状态。
通过采取事件溯源,就可以将领域模型持久化跟数据库完全解耦。
我们通过领域驱动设计的思路来分析和发现问题域,通过分解把问题域划分为问题子域,通过人为加限制的方式将问题子域转换为限界上下文。而这个过程就是我们分解微服务的过程,一般来说每一个限界上下文都可以映射为一个微服务,但也不是绝对的,具体情况具体分析。
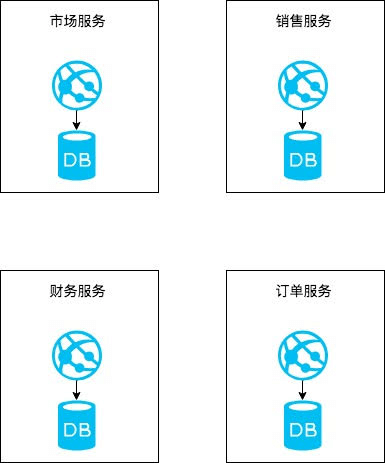
每一个微服务专注于解决对应的限界上下文中的问题,并不代表微服务之间没有交流。单个微服务的领域模型在提供服务的过程中会产生领域事件,领域事件为基于事件驱动(Event based)的微服务集成提供了基础,如果在微服务之间架设一条消息总线(不同于ESB,ESB被认为是反模式)。不同的微服务将自己产生的领域事件广播在消息总线上,微服务之间通过订阅自己感兴趣的事件就能完成微服务的集成。
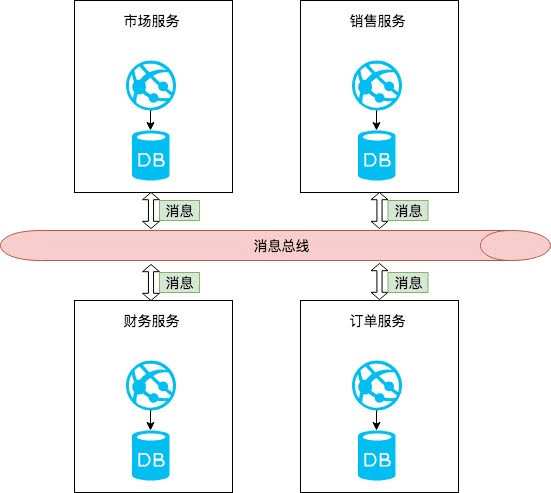
迄今为止我们已经建立了领域模型,创建了微服务,通过消息和领域事件完成了微服务的集成。还需要把微服务的能力通过REST API展现出来,微服务在对外提供能力的过程就是领域模型状态发生变化的过程,如果将领域模型理解为一个设计精良的状态机也一点不为过。如果设法将领域模型在某个状态下能够提供的能力通过REST API的的返回结果表达出来,这就是HATEOAS的核心思想。REST API不但可以提供某种能力,还可以告诉消费者此时领域模型能够提供的其他能力。
本文从需求分析到API设计,试图描述领域驱动设计的过程及思想。同时也能看的出领域驱动设计并不是孤立存在的,它为解决开发团队和业务人员之间沟通而生,进而驱动微服务划分以及API的设计,领域驱动设计并不是遥不可及的方法论,每一个专业术语和思想都是为了解决基本的问题而定义,希望本篇博客能够带你走入领域驱动设计。
文/ThoughtWorks张阳
说到DDD难,我觉得主要是两点:建模难、代码落地难。前者需要业务熟、功力深,难以快速提升;后者难在缺乏简单易行的可参考的代码结构,一旦有了这样的参考结构,就可以快速大幅降低DDD的实践难度。本文从后者的诸多难点中选择一个最常见的问题进行探讨:如何优雅地实现聚合的持久化?
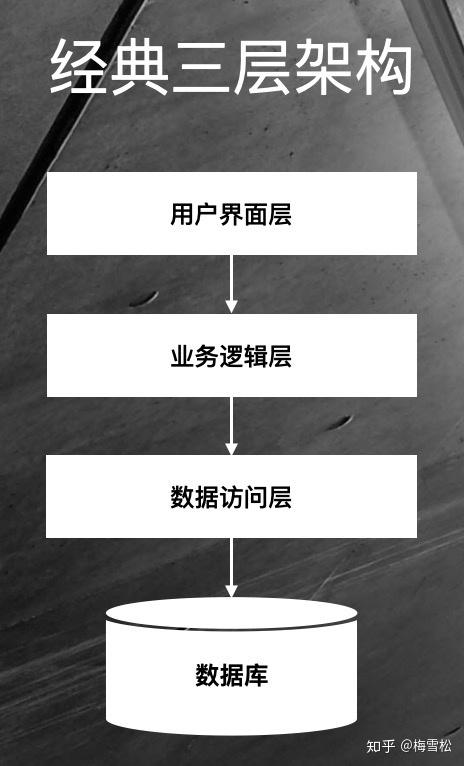
我们先来看一下,以前我们是怎么做持久化的。下图是一个非常典型的三层架构,业务逻辑层相当于Service层,完成业务处理。持久化主要通过数据访问层完成,这一层会有ORM、DAO等。这时候的实体类是一个JavaBean, 没有行为,它是一个贫血模型。我们会在实体类上加上注解,用来做数据库的持久化。这是非常典型的以数据为中心的编程方式,可能大家开始学编程时就是这么做的,非常成熟,没有什么挑战。
但系统复杂度达到一定程度时,以数据为中心的编程方式就会导致业务逻辑散布在各个地方,系统变得很难维护,响应力越来越低。因此Eric提出了领域驱动设计方法。其中一个重要的手段就是分离关注点,将技术复杂度与业务复杂度分离。也就是说,业务代码应该只关注业务逻辑的实现,不需要关心对象如何被持久化到数据库。持久化属于技术实现,与业务无关,它不需要知道业务是如何处理的。因此Eric提出了DDD的分层架构,如下图。其中一个主要的区别在于,我们将业务逻辑从Service中移出来,放在了Domain model中,变成了充血模型,封装在聚合中,应用层Service只是起协调作用。同时,将数据访问层不见了,都放在基础设施层了。
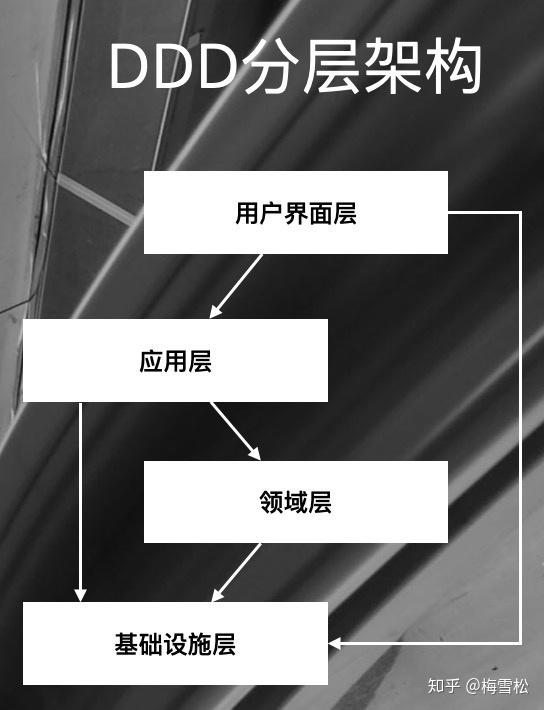
那么这时候我们聊持久化的时候,我们持久化的是什么,谁来做持久化?Eric帮我们给出了定义。我们持久化的是聚合。
聚合(Aggregate)就是一组相关对象的集合,我们把它作为 数据修改的单元。每个聚合都有一个根(Root)和一个边界( Boundary) ——Eric Evans
为什么数据修改的单元是聚合而不是实体或者其它东西呢?因为聚合封装了业务规则,也就是“不变性(Invariants)”,因此我们要把它作为一个整体而不是拆开来,以确保业务规则不被破坏。所以我们要以聚合为单元进行持久化。谁来做这个持久化的工作呢?资源库Repository。以订单为例,这是一个典型的Repository接口定义。
讯享网public interface OrderRepository { public Order findById(String id); public void save(Order order); public void remove(Order order); }
当我们做持久化的时候,问题来了,我们需要单独的持久化模型吗?或者说,领域模型和持久化模型要分离吗?当你做持久化时,是直接拿领域模型做持久化,还是转换成持久化模型后做数据库保存。我遇到很多团队在这个问题上有分歧。有的说我这个系统的领域模型和持久化模型基本是一样的,没必要分离。另一部分观点说,这两种模型的职责是不一样的,应该分离,这样它们才能够分别独立演进。这两种听起来都很有道理。怎么选择?
我认为,应该分离这两种模型。原因非常简单,如果不分离,你的领域模型必然要为了持久化而妥协。比如说,你在设计领域模型时,要考虑如何保存到数据库中。更为糟糕的是,你还要满足ORM框架的要求,你要有空的构造方法,还要加上各种Setter。当你妥协完了后,你如何确保值对象是只读的?当你的属性很容易就被Set方法改变时,你如何封装你的业务规则?所以,通常我们都需要把领域模型和持久化模型分离。
但是,有没有例外呢?有,因此我们有了第2个问题:NoSQL是最适合的聚合持久化方案吗?我们知道NoSQL数据库以文档的方式保存数据,而聚合就可以作为一个文档,它天然就满足了聚合作为一个数据修改的单元,并且在一个事务中完成持久化的需求。我们根本不需要持久化对象,聚合本身就可以做持久化,看起来非常完美。
但是,通常NoSQL不支持ACID,不支持多文档的事务。例如当你有一个聚合要保存,并且同时还要保存领域事件时,他们作为不同的文档分别保存,你如何将它们放到同一个事物中当中?你可能说MongoDB已经支持ACID了,可以让这两个文档在同一个事物中,但是它毕竟才推出不久,而且性能怎么办?所以你在选型时,肯定会谨慎一些。另外,技术选型是个综合权衡的过程,要考虑多方面的因素。你肯定不会仅仅因为它更容易做聚合的持久化而选择NoSQL。所以我们还是要寻找一个更通用的解决方案。
让我们回到问题的本源。以订单支付这个场景为例,如下图所示。订单有订单头,有订单行,都保存在数据库中,它们构成了订单聚合。当我要做订单支付业务时,首先我们通过Repository,从数据库中得到聚合,传给Service。Service调用order.pay()方法完成业务逻辑的处理,这时候订单的状态发生了变化。然后再由Repository将变化后的聚合保存到数据库中。
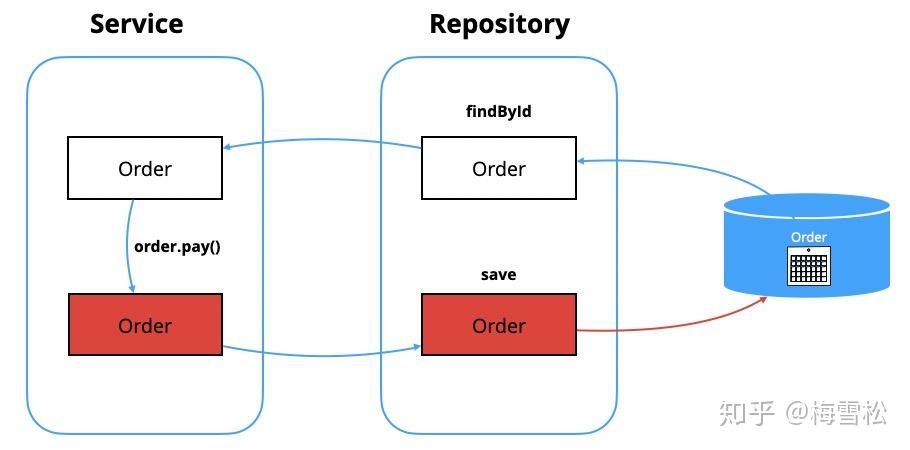
但是这时候我们只有聚合的最新状态,不知道聚合发生了什么变化。因为我们前面提到分离领域模型和持久化模型。所以这时候没有Hibernate之类的框架帮我们维护状态。聚合之前的状态在哪里?在数据库里。如果从数据库再查询一遍,不仅有性能损耗,而且代码也不好看。所以现在的问题变成了,我们怎么得到聚合的原始状态,这样我们才能够去做对比,从而更高效地修改数据。我们可以参照Hibernate搞个一级缓存吗。这又会引入另一个复杂度。我们不想为了解决一个问题引入另一个问题。有没有轻量级的解决办法呢?
我们设想一下,如果我们从Repository返回的不是聚合,而是一个聚合的容器。在这个容器中,不仅有聚合,还有聚合的历史快照,是不是就解决这个问题了。当你把聚合放到容器中时,它会自动创建一个快照。因此保存的时候,我们就能够通过对比快照知道聚合发生了什么变化。
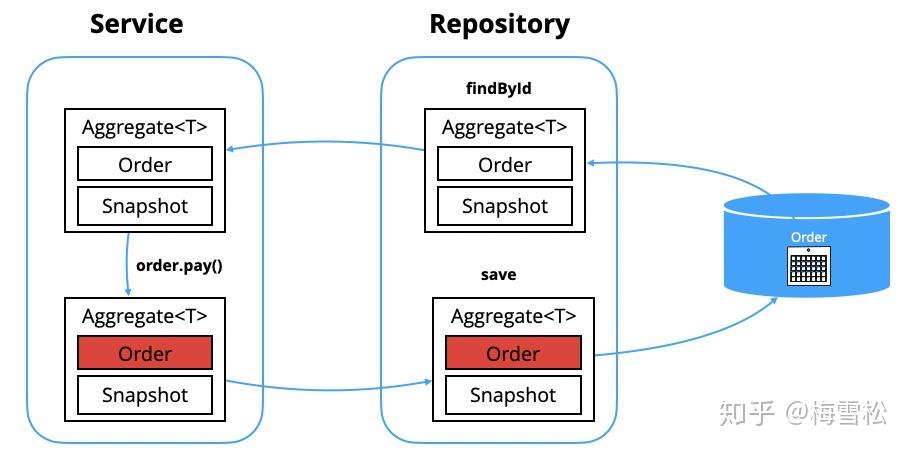
我们来看下相应的代码。Repository接口稍稍做一点调整,它的返回类型和参数变成了Aggregate泛型。
public interface OrderRepository { Aggregate<Order> findById(String orderId); void save(Aggregate<Order> orderAggregate); void remove(Aggregate<Order> orderAggregate); }我们再看Service代码示例,先从Repository拿到Aggregate,再取出聚合根Order,调用order的checkout方法完成业务处理,最后调用Repository保存Aggregate.
讯享网public class OrderService { public void checkout(String orderId, CheckoutRequest request) {<span class="n">Aggregate</span><span class="o"><</span><span class="n">Order</span><span class="o">></span> <span class="n">aggregate</span> <span class="o">=</span> <span class="n">orderRepository</span><span class="o">.</span><span class="na">findById</span><span class="o">(</span><span class="n">orderId</span><span class="o">);</span> <span class="n">Order</span> <span class="n">order</span> <span class="o">=</span> <span class="n">aggregate</span><span class="o">.</span><span class="na">getRoot</span><span class="o">();</span> <span class="n">Payment</span> <span class="n">payment</span> <span class="o">=</span> <span class="k">new</span> <span class="n">Payment</span><span class="o">(</span><span class="n">request</span><span class="o">.</span><span class="na">getAmount</span><span class="o">());</span> <span class="n">order</span><span class="o">.</span><span class="na">checkout</span><span class="o">(</span><span class="n">payment</span><span class="o">);</span> <span class="n">orderRepository</span><span class="o">.</span><span class="na">save</span><span class="o">(</span><span class="n">aggregate</span><span class="o">);</span>
} }
整个方案本质上通过引入一个快照,从而可以对比数据的变化,然后做相应的数据库修改操作。虽然这个方案修改了Repository的接口定义,但是影响范围是有限的,因为这个接口只在Service和Repository之间使用。所以影响范围有限,方案是可行的。
Aggregate-Persistence 正是基于此方案开发的持久化工具,它非常的轻量,本身不做数据库操作,它做的事情就是帮助你构建这个聚合容器,你可以用它来跟踪状态的变化:
- 识别出哪些属性发生了变化,这样你就可以很容易只修改发生变化的数据库字段,而不是所有字段;
- 识别出实体集合的变化,例如它能帮你识别出订单聚合中的订单行的增加、修改和删除,因此你做相应的数据库修改操作。
同时,它提供了基于Version的乐观锁支持,确保聚合作为一个工作单元整体被持久化。订单聚合持久化示例 展示了基于Aggregate-Persistence,使用Mybatis实现订单持久化的例子。
该工具经过1年多的不断完善,已经日渐成熟,日前发布了1.2版本,更多详情请访问Aggregate-Persistence。
这是“领域驱动设计实践之路”系列的第四篇文章,从单体架构的弊端引入微服务,结合领域驱动的概念介绍了如何做微服务划分、设计领域模型并展示了整体的微服务化的系统架构设计。结合分层架构、六边形架构和整洁架构的思想,以实际使用场景为背景,展示了一个微服务的程序结构设计。
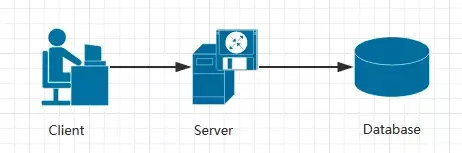
一般在业务发展的初期,整个应用涉及的功能需求较少,相对比较简单,单体架构的应用比较容易部署、测试,横向扩展也比较易实现。
然而,随着需求的不断增加, 越来越多的人加入开发团队,代码库也在飞速地膨胀。慢慢地,单体应用变得越来越臃肿,可维护性、灵活性逐渐降低,维护成本越来越高。
下面分析下单体架构应用存在的一些弊端:
在项目初期应该有人可以做到对应用各个功能和实现了如指掌,随着业务需求的增多,各种业务流程错综复杂的揉在一起,整个系统变得庞大且复杂,以至于很少有开发者清楚每一个功能和业务流程细节。
这样会使得新业务的需求评估或者异常问题定位会占用较多的时间,同时也蕴含着未知风险。更糟糕的是,这种极度的复杂性会形成一种恶性循环,每一次更改都会使得系统变得更复杂,更难懂。
随着时间推移、需求变更和人员更迭,会逐渐形成应用程序的技术债务,并且越积越多。比如,团队必须长期使用一套相同的技术栈,很难采用新的框架和编程语言。有时候想引入一些新的工具时,就会使得项目中需要同时维护多套技术框架,比如同时维护Hibernate和Mybatis,使得成本变高。
由于业务项目的所有功能模块都在一个应用上承担,包括核心和非核心模块,任何一个模块或者一个小细节的地方,因为设计不合理、代码质量差等原因,都有可能造成应用实例的崩溃,从而使得业务全面受到影响。其根本原因就是核心和非核心功能的代码都运行在同一个环境中。
多个类似的业务项目之间势必会存在类似的功能模块,如果都采用单体模式,就会带来重复功能建设和维护。而且,有时候还需要互相产生交互,打通单体系统之间的交互集成和协作的成本也需要额外付出。
再者,当项目大到一定程度,不同的模块可能是不同的团队来维护,迭代联调的冲突,代码合并分支的冲突都会影响整个开发进度,从而使得业务响应速度越来越慢。
随着业务的发展,系统在出现业务处理瓶颈的时候,往往是由于某一个或几个功能模块负载较高造成的,但因为所有功能都打包在一起,在出现此类问题时,只能通过增加应用实例的方式分担负载,没办法对单独的几个功能模块进行服务能力的扩展,从而带来资源额外配置的消耗,成本较高。
针对以上痛点,近年来越来越多的互联网公司采用“微服务”架构构建自身的业务平台,而“微服务”也获得了越来越多技术人员的肯定。
微服务其实是SOA的一种演变后的形态,与SOA的方法和原则没有本质区别。SOA理念的核心价值是,松耦合的服务带来业务的复用,按照业务而不是技术的维度,结合高内聚、低耦合的原则来划分微服务,这正好与领域驱动设计所倡导的理念相契合。
从广义上讲,领域即是一个组织所做的事情以及其中包含的一切。每个组织都有它自己的业务范围和做事方式,这个业务范围以及在其中所进行的活动便是领域。
DDD的子域和限界上下文的概念,可以很好地跟微服务架构中的服务进行匹配。而且,微服务架构中的自治化团队负责服务开发的概念,也与DDD中每个领域模型都由一个独立团队负责开发的概念吻合。DDD倡导按业务领域来划分系统,微服务架构更强调从业务维度去做分治来应对系统复杂度,跳过业务架构设计出来的架构关注点不在业务响应上,可能就是个大泥球,在面临需求迭代或响应市场变化时就很痛苦。
DDD的核心诉求就是将业务架构映射到系统架构上,在响应业务变化调整业务架构时,也随之变化系统架构。而微服务追求业务层面的复用,设计出来的系统架构和业务一致;在技术架构上则系统模块之间充分解耦,可以自由地选择合适的技术架构,去中心化地治理技术和数据。
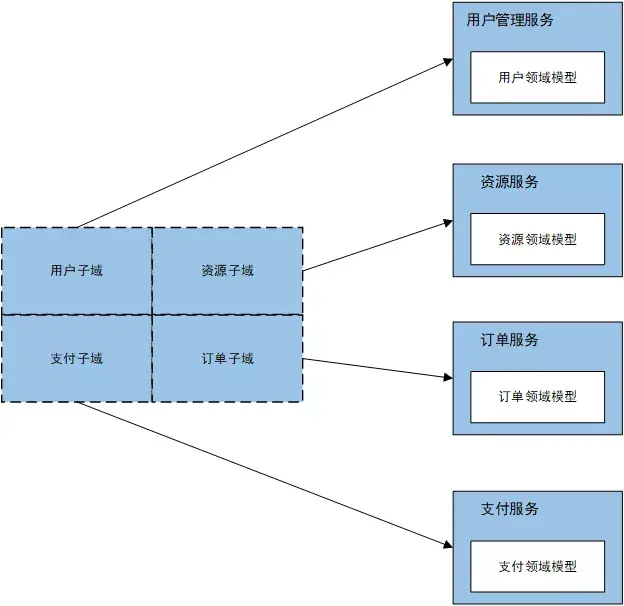
以电商的资源订购系统为例,典型业务用例场景包括查看资源,购买资源,查询用户已购资源等。
领域驱动为每一个子域定义单独的领域模型,子域是领域的一部分,从业务的角度分析我们需要覆盖的业务用例场景,以高内聚低耦合的思想,结合单一职责原则(SRP)和闭包原则(CCP),从业务领域的角度,划分出用户管理子域,资源管理子域,订单子域和支付子域共四个子域。
每个子域对应一个限界上下文。限界上下文是一种概念上的边界,领域模型便工作于其中,每个限界上下文都有自己的通用语言。限界上下文使得你在领域模型周围加上了一个显式的、清晰的边界。当然,限界上下文不仅仅包含领域模型。当使用微服务架构时,每个限界上下文对应一个微服务。
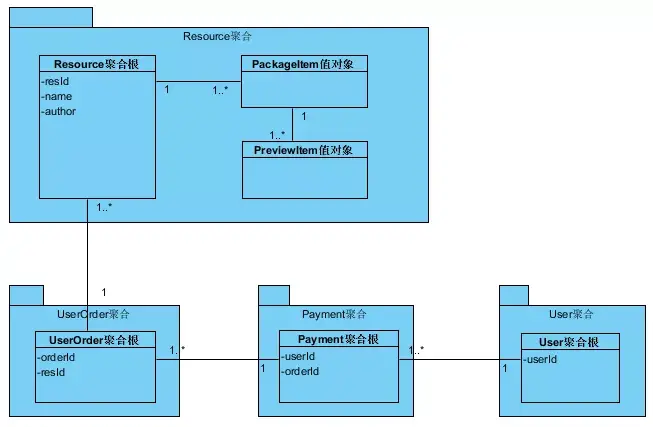
聚合是一个边界内领域对象的集群,可以将其视为一个单元,它由根实体和可能的一个或多个其他实体和值对象组成。聚合将领域模型分解为块,每个聚合都可以作为一个单元进行处理。
聚合根是聚合中唯一可以由外部类引用的部分,客户端只能通过调用聚合根上的方法来更新聚合。
聚合代表了一致的边界,对于一个设计良好的聚合来说,无论由于何种业务需求而发生改变,在单个事务中,聚合中的所有不变条件都是一致的。聚合的一个很重要的经验设计原则是,一个事务中只修改一个聚合实例。更新聚合时需要更新整个聚合而不是聚合中的一部分,否则容易产生一致性问题。
比如A和B同时在网上购买东西,使用同一张订单,同时意识到自己购买的东西超过预算,此时A减少点心数量,B减少面包数量,两个消费者并发执行事务,那么订单总额可能会低于最低订单限额要求,但对于一个消费者来说是满足最低限额要求的。所以应该站在聚合根的角度执行更新操作,这会强制执行一致性业务规则。
另外,我们不应该设计过大的聚合,处理大聚合构成的“巨无霸”对象时,容易出现不同用例同时需要修改其中的某个部分,因为聚合设计时考虑的一致性约束是对整个聚合产生作用的,所以对聚合的修改会造成对聚合整体的变更,如果采用乐观并发,这样就容易产生某些用例会被拒绝的场景,而且还会影响系统的性能和可伸缩性。
使用大聚合时,往往为了完成一项基本操作,需要将成百上千个对象一同加载到内存中,造成资源的浪费。所以应尽量采用小聚合,一方面使用根实体来表示聚合,其中只包含最小数量的属性或值类型属性,这里的最小数量表示所需的最小属性集合,不多也不少。必须与其他属性保持一致的属性是所需的属性。
在聚合中,如果你认为有些被包含部分应该建模成一个实体,此时,思考下这个部分是否会随着时间而改变,或者该部分是否能被全部替换。如果可以全部替换,那么可以建模成值对象,而非实体。因为值对象本身是不可变的,只能进行全部替换,使用起来更安全,所以,一般情况下优先使用值对象。很多情况下,许多建模成实体的概念都可以重构成值对象。小聚合还有助于事务的成功执行,即它可以减少事务提交冲突,这样不仅可以提升系统的性能和可伸缩性,另外系统的可用性也得到了增强。
另外聚合直接的引用通过唯一标识实现,而不是通过对象引用,这样不仅减少聚合的使用空间,更重要的是可以实现聚合直接的松耦合。如果聚合是另一个服务的一部分,则不会出现跨服务的对象引用问题,当然在聚合内部对象之间是可以相互引用的。
上述关于聚合的主要使用原则总结起来可以归纳为以下几点:
- 只引用聚合根。
- 通过唯一标识引用其他聚合。
- 一个事务中只能创建或修改一个聚合。
- 聚合边界之外使用最终一致性。
当然在实际使用的过程中,比如某一个业务用例需要获取到聚合中的某个领域对象,但该领域对象的获取路径较繁琐,为了兼容该特殊场景,可以将聚合中的属性(实体或值对象)直接返回给应用层,使得应用层直接操作该领域对象。
我们经常会遇到在一个聚合上执行命令方法时,还需要在其他聚合上执行额外的业务规则,尽量使用最终一致性,因为最终一致性可以按聚合维度分步骤处理各个环节,从而提升系统的吞吐量。对于一个业务用例,如果应该由执行该用例的用户来保证数据的一致性,那么可以考虑使用事务一致性,当然此时依然需要遵循其他聚合原则。如果需要其他用户或者系统来保证数据一致性,那么使用最终一致性。实际上,最终一致性可以支持绝大部分的业务场景。
基于上面对电商的资源订购系统业务子域的划分,设计出资源聚合,订单聚合,支付聚合和用户聚合,资源聚合与订单聚合之间通过资源ID进行关联,订单聚合与支付聚合之间通过订单ID和用户ID进行关联,支付聚合和用户聚合之间通过用户ID进行关联。资源聚合根中包含多个资源包值对象,一个资源包值对象又包含多个预览图值对象。当然在实际开发的过程中,根据实际情况聚合根中也可以包含实体对象。每个聚合对应一个微服务,对于特别复杂的系统,一个子域可能包含多个聚合,也就包含多个微服务。
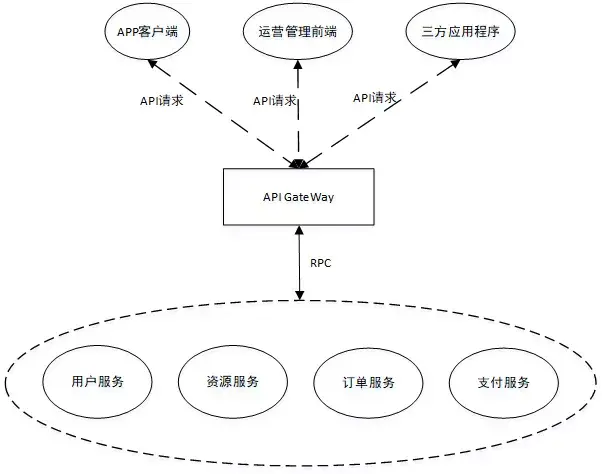
基于上面对电商的资源订购系统子域的分析,服务器后台使用用户服务,资源服务,订单服务和支付服务四个微服务实现。上图中的API Gateway也是一种服务,同时可以看成是DDD中的应用层,类似面向对象设计中的外观(Facade)模式。
作为整个后端架构的统一门面,封装了应用程序内部架构,负责业务用例的任务协调,每个用例对应了一个服务方法,调用多个微服务并将聚合结果返回给客户端。它还可能有其他职责,比如身份验证,访问授权,缓存,速率限制等。以查询已购资源为例,API Gateway需要查询订单服务获取当前用户已购的资源ID列表,然后根据资源ID列表查询资源服务获取已购资源的详细信息,最终将聚合结果返回给客户端。
当然在实际应用的过程中,我们也可以根据API请求的复杂度,从业务角度,将API Gateway划分为多个不同的服务,防止又回归到API Gateway的单体瓶颈。
另外,有时候从业务领域角度划分出来的某些子域比较小,从资源利用率的角度,单独放到一个微服务中有点单薄。这个时候我们可以打破一个限界上下文对应一个微服务的理念,将多个子域合并到同一个微服务中,由微服务自己的应用层实现多子域任务的协调。
所以,在我们的系统架构中可能会出现微服务级别的小应用层和API Gateway级别的大应用层使用场景,理论固然是理论,还是需要结合实际情况灵活应用。
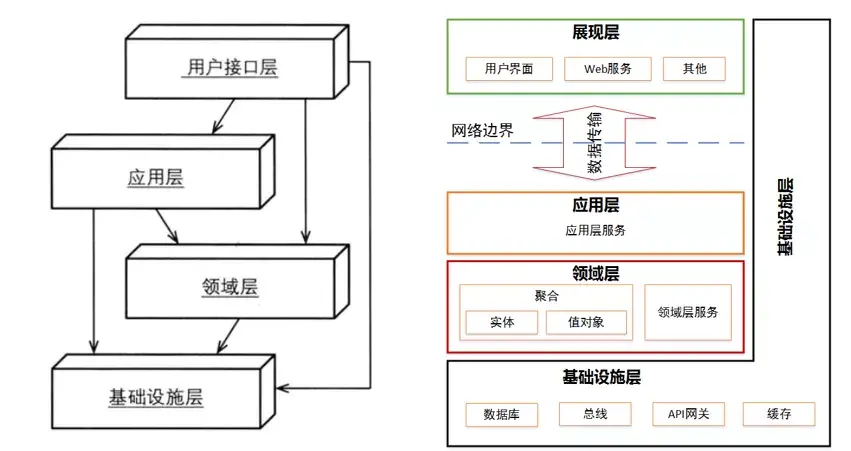
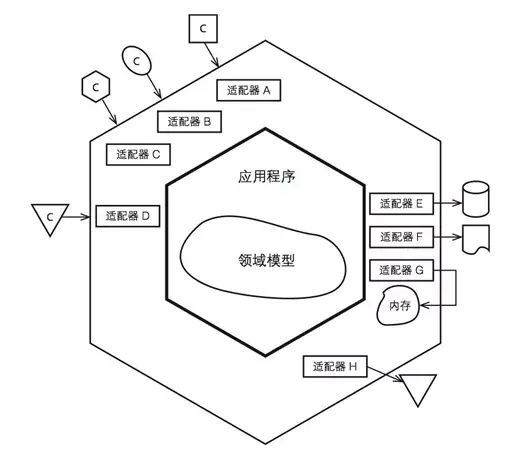
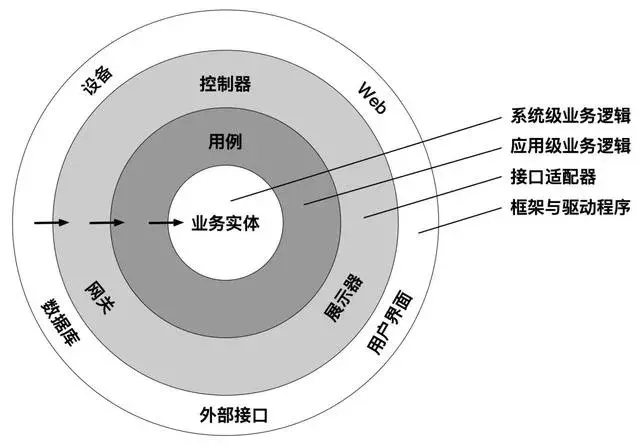
上面整洁架构图中的同心圆分别代表了软件系统中的不同层次,通常越靠近中心,其所在的软件层次就越高。
整洁架构的依赖关系规则告诉我们,源码中的依赖关系必须只指向同心圆的内层,即由低层机制指向高层策略。换句话说,任何属于内层圆中的代码都不应该牵涉外层圆中的代码,尤其是内层圆中的代码不应该引用外层圆中代码所声明的名字,包括函数、类、变量以及一切其他有命名的软件实体。同样,外层圆使用的数据格式也不应该被内层圆中的代码所使用,尤其是当数据格式由外层圆的框架所生成时。
总之,不应该让外层圆中发生的任何变更影响到内层圆的代码。业务实体这一层封装的是整个业务领域中最通用、最高层的业务逻辑,它们应该属于系统中最不容易受外界影响而变动的部分,也就是说一般情况下我们的核心领域模型部分是比较稳定的,不应该因为外层的基础设施比如数据存储技术选型的变化,或者UI展示方式等的变化受影响,从而需要做相应的改动。
在以往的项目经验中,大多数同学习惯也比较熟悉分层架构,一般包括展示层、应用层,领域层和基础设施层。六边形架构的一个重要好处是它将业务逻辑与适配器中包含的表示层和数据访问层的逻辑分离开来,业务逻辑不依赖于表示层逻辑或数据访问层逻辑,由于这种分离,单独测试业务逻辑要容易得多。
另一个好处是,可以通过多个适配器调用业务逻辑,每个适配器实现特定的API或用户界面。业务逻辑还可以调用多个适配器,每个适配器调用不同的外部系统。所以六边形架构是描述微服务架构中每个服务的架构的好方法。
根据我们具体的实践经验,比如在我们平时的项目中最常见的就是MySQL和Redis存储,而且也很少改变为其他存储结构。这里将分层架构和六边形架构进行思想融合,目的是一方面希望我们的微服务设计结构更优美,另一方面希望在已有编程习惯的基础上,更容易接受新的整洁架构思想。
我们项目中微服务的实现结合分层架构,六边形架构和整洁架构的思想,以实际使用场景为背景,采用的应用程序结构图如下。
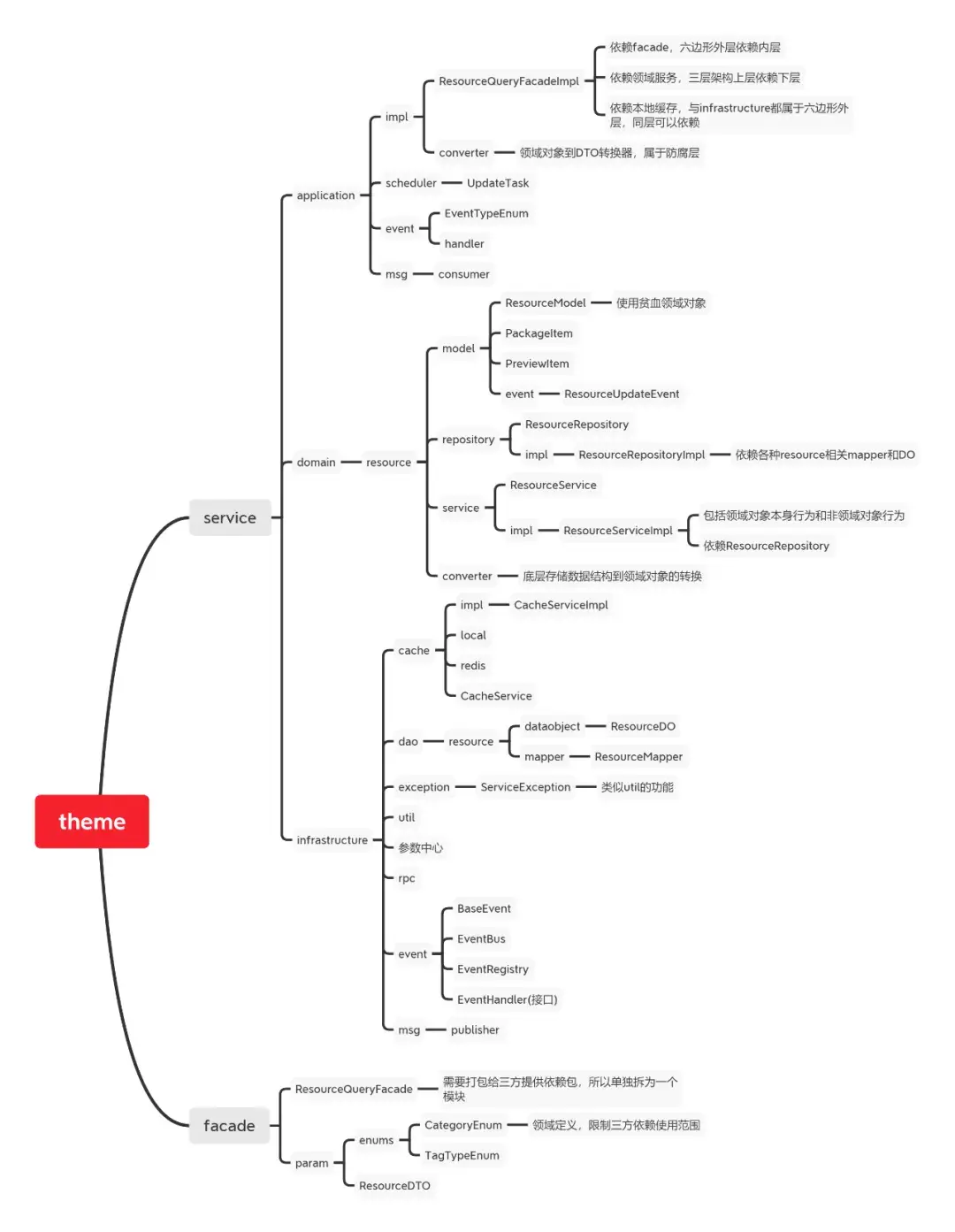
从上图可以看到,我们一个应用总共包含应用层application,领域层domain和基础设施层infrastructure。领域服务的facade接口需要暴露给其他三方系统,所以单独封装为一个模块。因为我们一般习惯于分层架构模式构建系统,所以按照分层架构给各层命名。
站在六边形架构的角度,应用层application等同于入站适配器,基础设施层infrastructure等同于出站适配器,所以实际上应用层和基础设施层同属外层,可以认为在同一层。
facade模块其实是从领域层domain剥离出来的,站在整洁架构的角度,领域层就是内核业务实体,这里封装的是整个业务领域中最通用、最高层的业务逻辑,一般情况下核心领域模型部分是比较稳定的,不受外界影响而变动。facade是微服务暴露给外界的领域服务能力,一般情况下接口的设定应符合当前领域服务的边界界定,所以facade模块属于内核领域层。

facade接口的实现在应用层application的impl部分,符合整洁架构外层依赖内层的思想,对于impl输入端口和入站适配器,可以采用不同的协议和技术框架实现,比如dubbo或HSF等。下面对各个模块的构成进行逐一解释。
对象的创建本身是一个主要操作,但被创建的对象并不适合承担复杂的装配操作。将这些职责混在一起可能会产生难以理解的拙劣设计。让客户直接负责创建对象又会使客户的设计陷入混乱,并且破坏装配对象的封装,而且导致客户与被创建对象的实现之间产生过于紧密的耦合。
复杂对象的创建是领域层的职责,但这项任务并不属于那些用于表示模型的对象。所以一般使用一个单独的工厂类或者在领域服务中提供一个构造领域对象的接口来负责领域对象的创建。
这里,我们选择给领域服务增加一个领域对象创建接口来承担工厂的角色。
讯享网/ * description: 资源领域服务 * * @author Gao Ju * @date 2020/7/27 */ public class ResourceServiceImpl implements ResourceService {/ * 创建资源聚合模型 * * @param resourceCreateCommand 创建资源命令 * @return */ @Override public ResourceModel createResourceModel(ResourceCreateCommand resourceCreateCommand) { <span class="n">ResourceModel</span> <span class="n">resourceModel</span> <span class="o">=</span> <span class="k">new</span> <span class="n">ResourceModel</span><span class="o">();</span> <span class="n">Long</span> <span class="n">resId</span> <span class="o">=</span> <span class="n">SequenceUtil</span><span class="o">.</span><span class="na">generateUuid</span><span class="o">();</span> <span class="n">resourceModel</span><span class="o">.</span><span class="na">setResId</span><span class="o">(</span><span class="n">resId</span><span class="o">);</span> <span class="n">resourceModel</span><span class="o">.</span><span class="na">setName</span><span class="o">(</span><span class="n">resourceCreateCommand</span> <span class="o">.</span><span class="na">getName</span><span class="o">());</span> <span class="n">resourceModel</span><span class="o">.</span><span class="na">setAuthor</span><span class="o">(</span><span class="n">resourceCreateCommand</span> <span class="o">.</span><span class="na">getAuthor</span><span class="o">());</span> <span class="n">List</span><span class="o"><</span><span class="n">PackageItem</span><span class="o">></span> <span class="n">packageItemList</span> <span class="o">=</span> <span class="k">new</span> <span class="n">ArrayList</span><span class="o"><>();</span> <span class="o">...</span> <span class="n">resourceModel</span><span class="o">.</span><span class="na">setPackageItemList</span><span class="o">(</span><span class="n">packageItemList</span><span class="o">);</span> <span class="k">return</span> <span class="n">resourceModel</span><span class="o">;</span>
} }
通常将聚合实例存放在资源库中,之后再通过该资源库来获取相同的实例。
如果修改了某个聚合,那么这种改变将被资源库持久化,如果从资源库中移除了某个实例,则将无法从资源库中重新获取该实例。
资源库是针对聚合维度创建的,聚合类型与资源库存在一对一的关系。
简单来说,资源库是对聚合的CRUD操作的封装。资源库内部采用哪种存储设施MySQL,MongoDB或者Redis等,对领域层来说其实是不感知的。
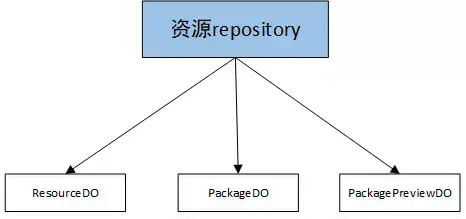
在我们的项目中采用MySQL作为资源repository的持久化存储,上图中每个DO对应一个数据库表,当然你也可以采用其他存储结构或设计为其他表结构,具体的处理流程均由repository进行封装,对领域服务来说只感知Resource聚合维度的CRUD操作,示例代码如下。
讯享网/ * description: 资源仓储 * * @author Gao Ju * @date 2020/08/23 */ @Repository(“resourceRepository”) public class ResourceRepositoryImpl implements ResourceRepository {/ * 资源Mapper */ @Resource private ResourceMapper resourceMapper; / * 资源包Mapper */ @Resource private PackageMapper packageMapper; / * 资源包预览图Mapper */ @Resource private PackagePreviewMapper packagePreviewMapper; / * 创建订单信息 * * @param resourceModel 资源聚合模型 * @return */ @Override public void add(ResourceModel resourceModel) { <span class="n">ResourceDO</span> <span class="n">resourceDO</span> <span class="o">=</span> <span class="k">new</span> <span class="n">ResourceDO</span><span class="o">();</span> <span class="n">resourceDO</span><span class="o">.</span><span class="na">setName</span><span class="o">(</span><span class="n">resourceModel</span><span class="o">.</span><span class="na">getName</span><span class="o">());</span> <span class="n">resourceDO</span><span class="o">.</span><span class="na">setAuthor</span><span class="o">(</span><span class="n">resourceModel</span><span class="o">.</span><span class="na">getAuthor</span><span class="o">());</span> <span class="n">List</span><span class="o"><</span><span class="n">PackageDO</span><span class="o">></span> <span class="n">packageDOList</span> <span class="o">=</span> <span class="k">new</span> <span class="n">ArrayList</span><span class="o"><>();</span> <span class="n">List</span><span class="o"><</span><span class="n">PackagePreviewDO</span><span class="o">></span> <span class="n">packagePreviewDOList</span> <span class="o">=</span> <span class="k">new</span> <span class="n">ArrayList</span><span class="o"><>();</span> <span class="k">for</span> <span class="o">(</span><span class="n">PackageItem</span> <span class="n">packageItem</span> <span class="o">:</span> <span class="n">resourceModel</span><span class="o">.</span><span class="na">getPackageItemList</span><span class="o">())</span> <span class="o">{</span> <span class="n">PackageDO</span> <span class="n">packageDO</span> <span class="o">=</span> <span class="k">new</span> <span class="n">PackageDO</span><span class="o">();</span> <span class="n">packageDO</span><span class="o">.</span><span class="na">setResId</span><span class="o">(</span><span class="n">resourceModel</span><span class="o">.</span><span class="na">getResId</span><span class="o">());</span> <span class="n">Long</span> <span class="n">packageId</span> <span class="o">=</span> <span class="n">SequenceUtil</span><span class="o">.</span><span class="na">generateUuid</span><span class="o">();</span> <span class="n">packageDO</span><span class="o">.</span><span class="na">setPackageId</span><span class="o">(</span><span class="n">packageId</span><span class="o">);</span> <span class="k">for</span> <span class="o">(</span><span class="n">PreviewItem</span> <span class="n">previewItem</span><span class="o">:</span> <span class="n">packageItem</span><span class="o">.</span><span class="na">getPreviewItemList</span><span class="o">())</span> <span class="o">{</span> <span class="n">PackagePreviewDO</span> <span class="n">packagePreviewDO</span> <span class="o">=</span> <span class="k">new</span> <span class="n">PackagePreviewDO</span><span class="o">();</span> <span class="o">...</span> <span class="n">packagePreviewDOList</span><span class="o">.</span><span class="na">add</span><span class="o">(</span><span class="n">packagePreviewDO</span><span class="o">);</span> <span class="o">}</span> <span class="n">packageDOList</span><span class="o">.</span><span class="na">add</span><span class="o">(</span><span class="n">packageDO</span><span class="o">);</span> <span class="o">}</span> <span class="n">resourceMapper</span><span class="o">.</span><span class="na">insert</span><span class="o">(</span><span class="n">resourceDO</span><span class="o">);</span> <span class="n">packageMapper</span><span class="o">.</span><span class="na">insertBatch</span><span class="o">(</span><span class="n">packageDOList</span><span class="o">);</span> <span class="n">packagePreviewMapper</span><span class="o">.</span><span class="na">insertBatch</span><span class="o">(</span><span class="n">packagePreviewDOList</span><span class="o">);</span>
} }
你可能有疑问,按照整洁架构的思想,repository的接口定义在领域层,repository的实现应该定义在基础设施层,这样就符合外层依赖稳定度较高的内层了。
结合我们实际开发过程,一般存储结构选定或者表结构设定后,一般不太容易做很大的调整,所以就按照习惯的分层结构使用,领域层直接依赖基础设施层实现,降低编码时带来的额外习惯上的成本。
领域驱动强调我们应该创建充血领域模型,将数据和行为封装在一起,将领域模型与现实世界中的业务对象相映射。各类具备明确的职责划分,将领域逻辑分散到各个领域对象中。
领域中的服务表示一个无状态的操作,它用于实现特定于某个领域的任务。当某个操作不适合放在领域对象上时,最好的方式是使用领域服务。
简单总结领域服务本身所承载的职责,就是通过串联领域对象、资源库,生成并发布领域事件,执行事务控制等一系列领域内的对象的行为,为上层应用层提供交互的接口。
讯享网/ * description: 订单领域服务 * * @author Gao Ju * @date 2020/8/24 */ public class UserOrderServiceImpl implements UserOrderService {/ * 订单仓储 */ @Autowired private OrderRepository orderRepository; / * 消息发布器 */ @Autowired private MessagePublisher messagePublisher; / * 订单逻辑处理 * * @param userOrder 用户订单 */ @Override public void createOrder(UserOrder userOrder) { <span class="n">orderRepository</span><span class="o">.</span><span class="na">add</span><span class="o">(</span><span class="n">userOrder</span><span class="o">);</span> <span class="n">OrderCreatedEvent</span> <span class="n">orderCreatedEvent</span> <span class="o">=</span> <span class="k">new</span> <span class="n">OrderCreatedEvent</span><span class="o">();</span> <span class="n">orderCreatedEvent</span><span class="o">.</span><span class="na">setUserId</span><span class="o">(</span><span class="n">userOrder</span><span class="o">.</span><span class="na">getUserId</span><span class="o">());</span> <span class="n">orderCreatedEvent</span><span class="o">.</span><span class="na">setOrderId</span><span class="o">(</span><span class="n">userOrder</span><span class="o">.</span><span class="na">getOrderId</span><span class="o">());</span> <span class="n">orderCreatedEvent</span><span class="o">.</span><span class="na">setPayPrice</span><span class="o">(</span><span class="n">userOrder</span><span class="o">.</span><span class="na">getPayPrice</span><span class="o">());</span> <span class="n">messagePublisher</span><span class="o">.</span><span class="na">send</span><span class="o">(</span><span class="n">orderCreatedEvent</span><span class="o">);</span>
} }
在实践的过程中,为了简单方便,我们仍然采用贫血领域模型,将领域对象自身行为和不属于领域对象的行为都放在领域服务中实现。
大部分场景领域服务返回聚合根或者简单类型,某些特殊场景也可以将聚合根中包含的实体或值对象返回给调用方。领域服务也可以同时操作多个领域对象,多个聚合,将其转换为另外的输出。
介于我们实际的使用场景,领域比较简单,领域服务只操作一个领域的对象,只操作一个聚合,由应用服务来协调多个领域对象。
在领域驱动设计的上下文中,聚合在被创建时,或发生其他重大更改时发布领域事件,领域事件是聚合状态更改时所触发的。
领域事件命名时,一般选择动词的过去分词,因为状态改变时就代表当前事件已经发生,领域事件的每个属性都是原始类型值或值对象,比如事件ID和创建时间等,事件ID也可以用来做幂等用。
从概念上讲,领域事件由聚合负责发布,聚合知道其状态何时发生变化,从而知道要发布的事件。
由于聚合不能使用依赖注入,需要通过方法参数的形式将消息发布器传递给聚合,但这将基础设施和业务逻辑交织在一起,有悖于我们解耦设计的原则。
更好的方法是将事件发布放到领域服务中,因为服务可以使用依赖注入来获取对消息发布器的引用,从而轻松发布事件。只要状态发生变化,聚合就会生成事件,聚合方法的返回值中包括一个事件列表,并将它们返回给领域服务。
Saga是一种在微服务架构中维护数据一致性的机制,Sage由一连串的本地事务组成,每一个本地事务负责更新它所在服务的私有数据库,通过异步消息的方式来协调一系列本地事务,从而维护多个服务之间数据的最终一致性。Saga包括协同式和编排式,
我们采用协同式来实现分布式事务,发布的领域事件以命令式消息的方式发送给Saga参与方。如果领域事件是自我发布自我消费,不依赖消息中间件实现,则可以使用事件总线模式来进行管理。下面以购买资源的过程为例进行说明。
- 提交创建订单请求,OrderService创建一个处于PAYING状态的UserOrder,并发布OrderCreated事件。
- UserService消费OrderCreated事件,验证用户是否可以下单,并发布UserVerified事件。
- PaymentService消费UserVerified事件,进行实际的支付操作,并发布PaySuccess事件。
- OrderService接收PaySuccess事件,将UserOrder状态改为PAY_SUCCESS。
补偿过程
- PaymentService消费UserVerified事件,进行实际的支付操作,若支付失败,并发布PayFailed事件。
- OrderService接收PayFailed事件,将UserOrder状态改为PAY_FAILED。
在Saga的概念中,
第1步叫可补偿性事务,因为后面的步骤可能会失败。
第3步叫关键性事务,因为它后面跟着不可能失败的步骤。第4步叫可重复性事务,因为其总是会成功。
讯享网/ * description: 领域事件基类 * * @author Gao Ju * @date 2020/7/27 */ public class BaseEvent { / * 消息唯一ID */ private String messageId;/ * 事件类型 */ private Integer eventType; / * 事件创建时间 */ private Date createTime; / * 事件修改时间 */ private Date modifiedTime; } / * description: 订单创建事件 * * @author Gao Ju * @date 2020/8/24 */ public class OrderCreatedEvent extends BaseEvent { <span class="cm">/
* 用户ID */ 讯享网<span class="kd">private</span> <span class="n">String</span> <span class="n">userId</span><span class="o">;</span> <span class="cm">/
* 订单ID */ <span class="kd">private</span> <span class="n">String</span> <span class="n">orderId</span><span class="o">;</span> <span class="cm">/
* 支付价格 */ 讯享网<span class="kd">private</span> <span class="n">Integer</span> <span class="n">payPrice</span><span class="o">;</span>
}
facade和domain属于同一层,某些提供给三方使用的类定义在facade,比如资源类型枚举CategoryEnum限制三方资源使用范围,然后domain依赖facade中enum定义。
另外,根据迪米特法则和告诉而非询问原则,客户端应该尽量少地知道服务对象内部结构,通过调用服务对象的公共接口的方式来告诉服务对象所要执行的操作。
所以,我们不应该把领域模型泄露到微服务之外,对外提供facade服务时,根据领域对象包装出一个数据传输对象DTO(Data Transfer Object),来实现和外部三方系统的交互,比如上图中的ResourceDTO。
应用层是业务逻辑的入口,由入站适配器调用。facade的实现,定时任务的执行和消息监听处理器都属于入站适配器,所以他们都位于应用层。
正常情况下一个微服务对应一个聚合,实践过程中,某些场景下一个微服务可以包含多个聚合,应用层负责用例流的任务协调。领域服务依赖注入应用层,通过领域服务执行领域业务规则,应用层还会处理授权认证,缓存,DTO与领域对象之间的防腐层转换等非领域操作。
/ * description: 订单facade * * @author Gao Ju * @date 2020/8/24 */ public class UserOrderFacadeImpl implements UserOrderFacade {讯享网<span class="cm">/
* 订单服务 */ <span class="nd">@Resource</span> <span class="kd">private</span> <span class="n">UserOrderService</span> <span class="n">userOrderService</span><span class="o">;</span> <span class="cm">/
* 创建订单信息 * * @param orderPurchaseParam 订单交易参数 * @return */ 讯享网<span class="nd">@Override</span> <span class="kd">public</span> <span class="n">FacadeResponse</span><span class="o"><</span><span class="n">UserOrderPurchase</span><span class="o">></span> <span class="nf">createOrder</span><span class="o">(</span><span class="n">OrderPurchaseParam</span> <span class="n">orderPurchaseParam</span> <span class="o">)</span> <span class="o">{</span> <span class="n">UserOrder</span> <span class="n">userOrder</span> <span class="o">=</span> <span class="k">new</span> <span class="n">UserOrder</span><span class="o">();</span> <span class="n">userOrder</span><span class="o">.</span><span class="na">setUserId</span><span class="o">(</span><span class="n">request</span><span class="o">.</span><span class="na">getUserId</span><span class="o">());</span> <span class="n">userOrder</span><span class="o">.</span><span class="na">setResId</span><span class="o">(</span><span class="n">request</span><span class="o">.</span><span class="na">getResId</span><span class="o">());</span> <span class="n">userOrder</span><span class="o">.</span><span class="na">setPayPrice</span><span class="o">(</span><span class="n">request</span><span class="o">.</span><span class="na">getPayAmount</span><span class="o">());</span> <span class="n">userOrder</span><span class="o">.</span><span class="na">setOrderStatus</span><span class="o">(</span><span class="n">OrderStatusEnum</span><span class="o">.</span><span class="na">Create</span><span class="o">.</span><span class="na">getCode</span><span class="o">());</span> <span class="n">userOrderService</span><span class="o">.</span><span class="na">handleOrder</span><span class="o">(</span><span class="n">userOrder</span><span class="o">);</span> <span class="n">userOrderPurchase</span><span class="o">.</span><span class="na">setOrderId</span><span class="o">(</span><span class="n">userOrderDO</span><span class="o">.</span><span class="na">getId</span><span class="o">());</span> <span class="n">userOrderPurchase</span><span class="o">.</span><span class="na">setCreateTime</span><span class="o">(</span><span class="k">new</span> <span class="n">Date</span><span class="o">());</span> <span class="k">return</span> <span class="n">FacadeResponseFactory</span><span class="o">.</span><span class="na">getSuccessInstance</span><span class="o">(</span><span class="n">userOrderPurchase</span><span class="o">);</span> <span class="o">}</span>
}基础设施的职责是为应用程序的其他部分提供技术支持。与数据库的交互dao模块,与Redis缓存,本地缓存交互的cache模块,与参数中心,三方rpc服务的交互,消息框架消息发布者都封装在基础设施层。
另外,程序中用到的工具类util模块和异常类exception也统一封装在基础设施层。
从分层架构的角度,领域层可以依赖基础设施层实现与其他外设的交互。另外,无论从分层架构的上层application层还是从六边形架构的角度的输入端口和适配器application,都可以依赖作为底层或处于同层的输出端口和适配器的infrastructure层,比如调用util或者exception模块。
其实,无论是面向服务架构SOA,微服务,领域驱动,还是中台,其目的都是在说,我们做架构设计的时候,应该从业务视角出发,对所涉及的业务领域,基于高内聚、低耦合的思想进行划分,最大限度且合理的实现业务重用。
这样不仅方便提供专业且稳定的业务服务,更有利于业务的沉淀和可持续发展。业务之下是基于技术的系统实现,技术造就业务,业务引领技术,两者相辅相成,共同为社会进步做出贡献。
- [1] 《领域驱动设计软件核心复杂性应对之道》Eric Evans著, 赵俐 盛海燕 刘霞等译,人民邮电出版社
- [2] 《实现领域驱动设计》Vaughn Vernon著, 滕云译, 张逸审,电子工业出版社
- [3] 《微服务架构设计模式》[美]克里斯.理查森(Chris Richardson) 著, 喻勇译,机械工业出版社
- [4] 《架构整洁之道》[美]Robert C.Martin 著,孙宇聪 译,电子工业出版社
- [5] 《企业IT架构转型之道阿里巴巴中台战略思想与架构实践》钟华编著,机械工业出版社
- [6] 领域驱动设计(DDD)实践之路(二):事件驱动与CQRS,vivo互联网技术
- [7] 领域驱动设计在互联网业务开发中的实践,美团技术团队
作者:Angel Gao
ABP是一个开源且文档友好的应用程序框架。ABP不仅仅是一个框架,它还提供了一个最徍实践的基于领域驱动设计(DDD)的体系结构模型,可以支持.net framework和.net core两种技术流派。
- 依赖注入,这个部分使用 Castle windsor (依赖注入容器)来实现依赖注入,这个也是我们经常使用IOC来处理的方式;
- Repository仓储模式,已实现了Entity Framework、NHibernate、MangoDB、内存数据库等,仓储模式可以快速实现对数据接口的调用;
- 身份验证与授权管理,可以使用声明特性的方式对用户是否登录,或者接口的权限进行验证,可以通过一个很细粒度的方式,对各个接口的调用权限进行设置;
- 数据有效性验证,ABP自动对接口的输入参数对象进行非空判断,并且可以根据属性的申请信息对属性的有效性进行校验;
- 审计日志记录,也就是记录我们对每个接口的调用记录,以及对记录的创建、修改、删除人员进行记录等处理;
- Unit Of Work工作单元模式,为应用层和仓储层的方法自动实现数据库事务,默认所有应用服务层的接口,都是以工作单元方式运行,即使它们调用了不同的存储对象处理,都是处于一个事务的逻辑里面;
- 异常处理,ABP框架提供了一整套比较完善的流程处理操作,可以很方便的对异常进行进行记录和传递;
- 日志记录,我么可以利用Log4Net进行常规的日志记录,方便我们跟踪程序处理信息和错误信息;
- 多语言/本地化支持,ABP框架对多语言的处理也是比较友好的,提供了对XML、JSON语言信息的配置处理;
- Auto Mapping自动映射,这个是ABP的很重要的对象隔离概念,通过使用AutoMaper来实现域对象和DTO对象的属性映射,可以隔离两者的逻辑关系,但是又能轻松实现属性信息的赋值;
- 动态Web API层,利用这个动态处理,可以把Application Service 直接发布为Web API层,而不需要在累赘的为每个业务对象手工创建一个Web API的控制器,非常方便;
- 动态JavaScript的AJax代理处理,可以自动创建Javascript 的代理层来更方便使用Web Api,这个在Web层使用。
- 多租户支持(每个租户的数据自动隔离,业务模块开发者不需要在保存和查询数据时写相应代码;
- 软删除支持(继承相应的基类或实现相应接口,会自动实现软删除)
- 系统设置存取管理(系统级、租户级、用户级,作用范围自动管理)
- EventBus实现领域事件(Domain Events)
- 模块以及模块的依赖关系实现插件化的模块处理等等
前后端分离的思想,不仅仅可以应用在Web的B/S开发,同时适用于C/S开发
- 前端Web端可以使用Ant-Design(React)、IView(VUE)、Angular等不同的前端技术来承载界面呈现层
- 前端Client 桌面端可以使用MaterialDesign 设计规范,按照Prism或者MVMMLight 的MVMVM框架结合应用起来
ABP 框架的核心主要以.NET的后端技术栈为主线,虽然ASP.NET CORE MVC和 Web API 分成了两部分,但是他的动态发布为Web API有限的架构提供了更好的便利。
在当今流行的展现层中,越来越不依赖于后端的技术实现,而侧重于Web API标准化的对接,基于JSON数据的交互处理。不管是以Ant-Design(React)、IView(VUE)、Angular等技术应用的Web前端,我们可以看到这些架构很容易实现对Web API的标准接口对接,在我较早提供的Winform混合框架里面,也是以Web API优先的策略进行云端应用的部署
ABP 框架包含了两个部分,一个基础的ABP框架,一个ABP基础框架上的扩展应用。提供了人员人员、角色、权限、会话、身份验证、多租户、日志记录等等内容,我们一般指的ABP框架应用就是这个基础上扩展自己的业务项目。这个部分,我们可以根据官网上进行一定的选项配置,然后下载使用。
基础结构组成部分
扩展应用模板样式如下,需到官网下载
下载.net core 项目后,其中后端部分的项目视图如下所示
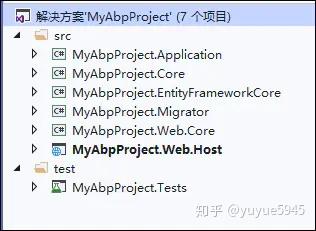
我们从这个项目里面可以看到,它主要是分为下面几个项目分层。
- Application应用层:应用层提供一些应用服务(Application Services)方法供展现层调用。一个应用服务方法接收一个DTO(数据传输对象)作为输入参数,使用这个输入参数执行特定的领域层操作,并根据需要可返回另一个DTO。
- Core领域核心层,领域层就是业务层,是一个项目的核心,所有业务规则都应该在领域层实现。这个项目里面,除了定义所需的领域实体类外,其实可以定义我们自己的自定义的仓储对象(类似DAL/IDAL),以及定义自己的业务逻辑层(类似BLL/IBLL),以及基于AutoMapper映射规则等内容。
- EntityFrameworkCore 实体框架核心层,这个项目不需要修改太多内容,只需要在DbContext里面加入对应领域对象的仓储对象即可。
- Migrator数据迁移层,这个是一个辅助创建的控制台程序项目,如果基于DB First,我们可以利用它来创建我们项目的初始化数据库。
- Web.Core Web核心层,基于Web或者Web API的核心层,提供了对身份登陆验证的基础处理,没有其他内容。
- Web.Core.Host Web API的宿主层,也是动态发布Web API的核心内容,另外在Web API里面整合了Swagger,使得我们可以方便对Web API的接口进行调试。
- Tests 单元测试层,这个提供了一些应用层对象的模拟测试,其中测试的数据库使用的是Entity Framework 的内存数据库,不影响实际数据库内容。
欢迎大家关注公众号「JAVA前线」查看更多精彩分享文章,主要包括源码分析、实际应用、架构思维、职场分享、产品思考

领域驱动设计DDD是一段时间以来比较流行的概念,刚开始接触时觉得概念很多,并且比较难以落地。本文就来分析探讨DDD落地时需要关注的六个问题,并通过一个足球运动员信息管理系统案例分析落地的六个步骤。
DDD方法论的核心是将问题不断分解,把大问题分解为小问题,大业务分解小领域,简而言之就是分而治之,各个击破。
分而治之是指直接面对大业务我们无从下手,需要按照一定方法进行分解,分解为高内聚的小领域,使得业务有边界清晰,而这些小领域是我们有能力处理的,这就是领域驱动设计的核心。
各个击破是指当问题被拆分为小领域后,因为小领域业务内聚,其子领域高度相关,我们在技术维度可以对其进行详细设计,在管理维度可以按照领域对项目进行分工。需要指出DDD不能替代详细设计,DDD是为了更清晰地详细设计。
在微服务流行的互联网行业,当业务逐渐复杂时,技术人员需要解决如何划分微服务边界的问题,DDD这种清晰化业务边界的特性正好可以用来解决这个问题。
我们的目标是将业务划分清晰的边界,而DDD是达成目标的有效方法之一,这一点是需要格外注意的。DDD是方法不是目标,不需要为了使用而使用。例如业务模型比较简单可以很容易分析的业务就不需要使用DDD,还有一些目标是快速验证类型的项目,追求短平快,前期可能也不需要使用领域驱动设计。
领域可以划分多个子领域,子域可以再划分多个子子域,限界上下文本质上也是一种子子域,那么在业务分解时一个业务模块到底是领域、子域还是子子域?
我认为不用纠结在这个问题,因为这取决于看待这个模块的角度。你认为整体可能是别人的局部,你认为的局部可能是别人的整体,叫什么名字不重要,最重要的是按照高内聚的原则将业务高度相关的模块收敛在一起。
业务划分粒度的粗细并没有统一的标准,还是要根据业务需要、开发资源、技术实力等因素综合考量。例如微服务拆分过细反而会增加开发、部署和维护的复杂度,但是拆分过粗可能会导致大量业务高度耦合,开发部署起来是挺快的,但是缺失可维护性和可扩展性,这需要根据实际情况做出权衡。
领域对象与数据对象一个重要的区别是值对象存储方式。在讨论领域对象和数据对象之前,我们首先讨论实体和值对象这一组概念。实体是具有唯一标识的对象,而唯一标识会伴随实体对象整个生命周期并且不可变更。值对象本质上是属性的集合,并没有唯一标识。
领域对象在包含值对象的同时也保留了值对象的业务含义,而数据对象可以使用更加松散的结构保存值对象,简化数据库设计。
现在假设我们需要管理足球运动员信息,对应的领域模型和数据模型应该如何设计?姓名、身高、体重是一名运动员本质属性,加上唯一编号可以对应实体对象。跑动距离,传球成功率,进球数是运动员比赛中的表现,这些属性的集合可以对应值对象。
值对象在数据对象中可以用松散的数据结构进行存储,而值对象在领域对象中需要保留其业务含义如下图所示:
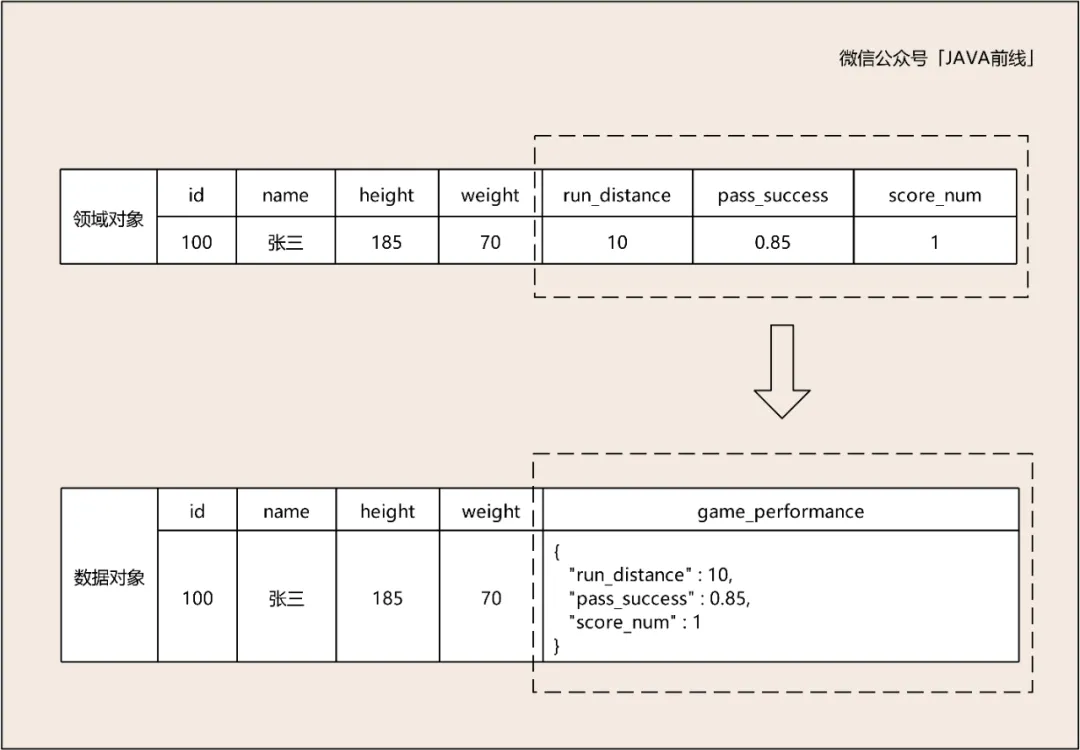
我们根据图示编写领域对象与数据对象代码:
// 数据对象 public class FootballPlayerDO {讯享网<span class="kd">private</span> <span class="n">Long</span> <span class="n">id</span><span class="o">;</span> <span class="kd">private</span> <span class="n">String</span> <span class="n">name</span><span class="o">;</span> <span class="kd">private</span> <span class="n">Integer</span> <span class="n">height</span><span class="o">;</span> <span class="kd">private</span> <span class="n">Integer</span> <span class="n">weight</span><span class="o">;</span> <span class="kd">private</span> <span class="n">String</span> <span class="n">gamePerformance</span><span class="o">;</span>
} // 领域对象 public class FootballPlayerDMO { <span class="kd">private</span> <span class="n">Long</span> <span class="n">id</span><span class="o">;</span> <span class="kd">private</span> <span class="n">String</span> <span class="n">name</span><span class="o">;</span> <span class="kd">private</span> <span class="n">Integer</span> <span class="n">height</span><span class="o">;</span> <span class="kd">private</span> <span class="n">Integer</span> <span class="n">weight</span><span class="o">;</span> <span class="kd">private</span> <span class="n">GamePerformanceVO</span> <span class="n">gamePerformanceVO</span><span class="o">;</span>
} public class GamePerformanceVO { 讯享网<span class="kd">private</span> <span class="n">Double</span> <span class="n">runDistance</span><span class="o">;</span> <span class="kd">private</span> <span class="n">Double</span> <span class="n">passSuccess</span><span class="o">;</span> <span class="kd">private</span> <span class="n">Integer</span> <span class="n">scoreNum</span><span class="o">;</span>
}抽象的核心是找相同,对不同事物提取公因式。实现的核心是找不同,扩展各自的属性和特点,体现了灵活性。例如模板方法设计模式正是用抽象构建框架,用实现扩展细节。
我们再回到数据模型的讨论,可以发现脚本化是一种拓展灵活性的方式,脚本化不仅指使用groovy、QLExpress脚本增强系统灵活性,还包括松散可扩展的数据结构。数据模型抽象出了姓名、身高、体重这些基本属性,对于频繁变化的比赛表现属性,这些属性值可能经常变化,甚至属性本身也是经常变化,例如可能会加上射门次数,突破次数等,所以采用松散的JSON数据结构进行存储。
工程理论总是要落地的,落地也是需要一些步骤和方法的。本文我们一起分析一个足球运动员信息管理系统,目标是管理运动员从转会到上场比赛整条链路信息,这个系统大家应该也都没有接触过,我们一起来分析。需要说明本实例着重演示DDD方法论如何落地,业务细节可能并不能面面俱到。
梳理流程有两个问题需要考虑,第一个问题是从什么视角去梳理?因为不同的人看到的流程是不一样的。答案是取决于系统需要解决的是什么问题,因为我们要管理运动员从转会到上场比赛整条链路信息,所以从运动员视角出发是一个合适的选择。
第二个问题是对业务不熟悉怎么办?因为我们不是体育和运动专家,并不清楚整条链路的业务细节。答案是梳理流程时一定要有业务专家在场,因为没有真实业务细节,无法领域驱动设计。同理在互联网梳理复杂业务流程时,一定要有对相关业务熟悉的产品经理或者运营一起参与。
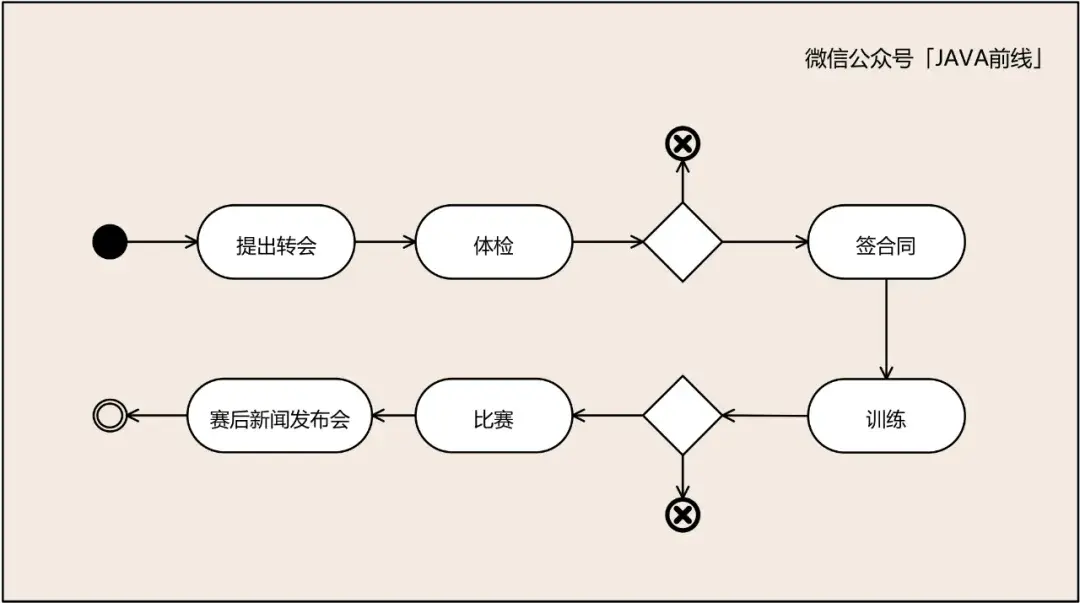
假设足球业务专家梳理出了业务流程,运动员提出转会,协商一致后到新俱乐部体检,体检通过就进行签约。进入新俱乐部后进行训练,训练指标达标后上场比赛,赛后参加新闻发布会。
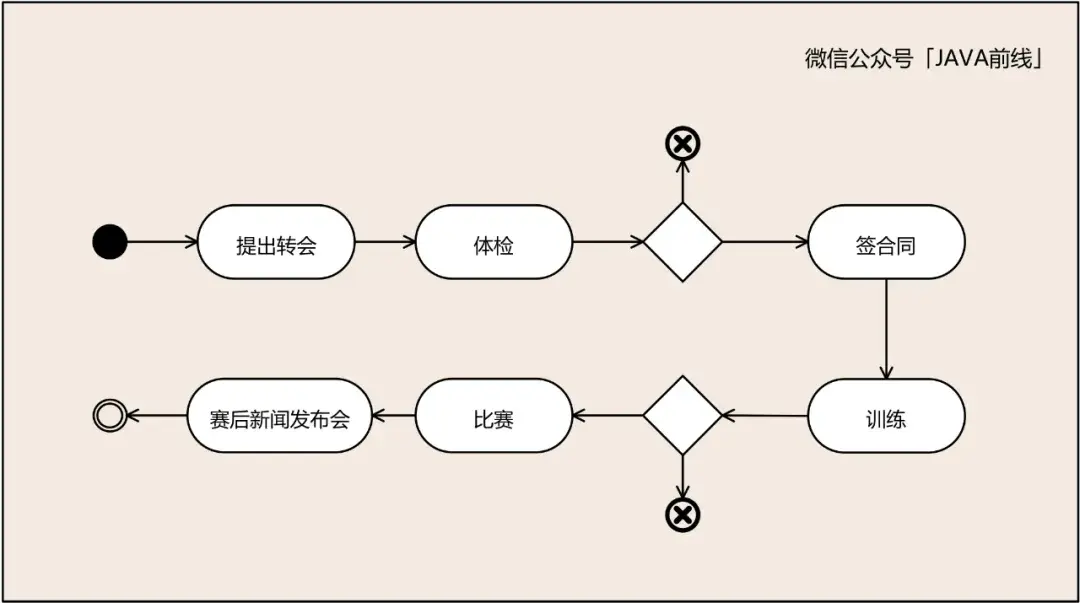
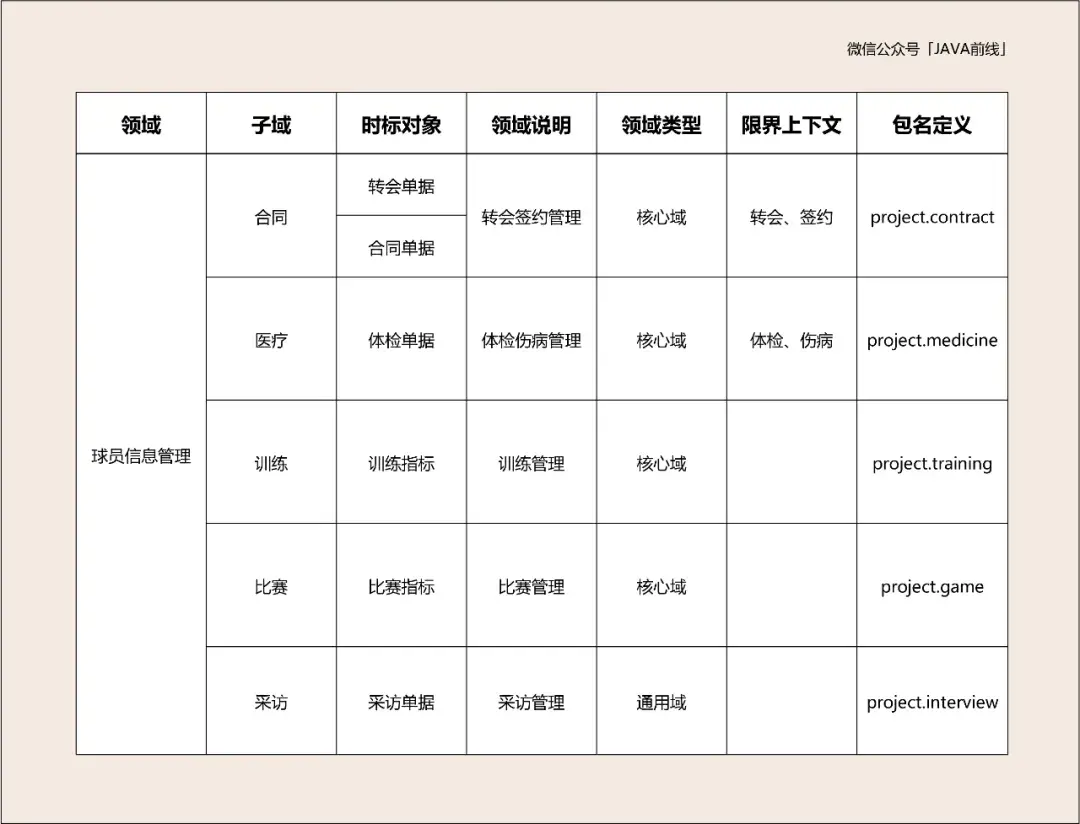
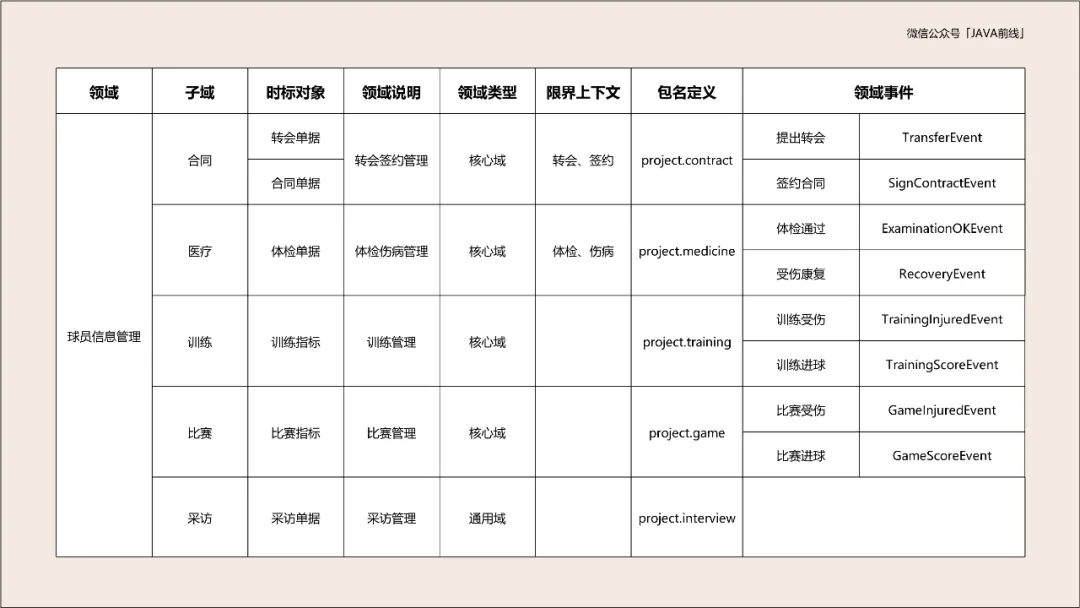
四色建模第一种颜色是红色,表示时标对象。时标对象是四色建模最重要的对象,可以理解为核心业务单据。在业务进行过程中一定要对关键业务留下单据,通过这些单据可以追溯出整个业务流程。
时标对象具有两个特点:第一是事实不可变性,记录了过去某个时间点或时间段内发生的事实。第二是责任可追溯性,记录了管理者关注的信息。现在我们分析本系统时标对象有哪些,需要留下哪些核心业务单据。
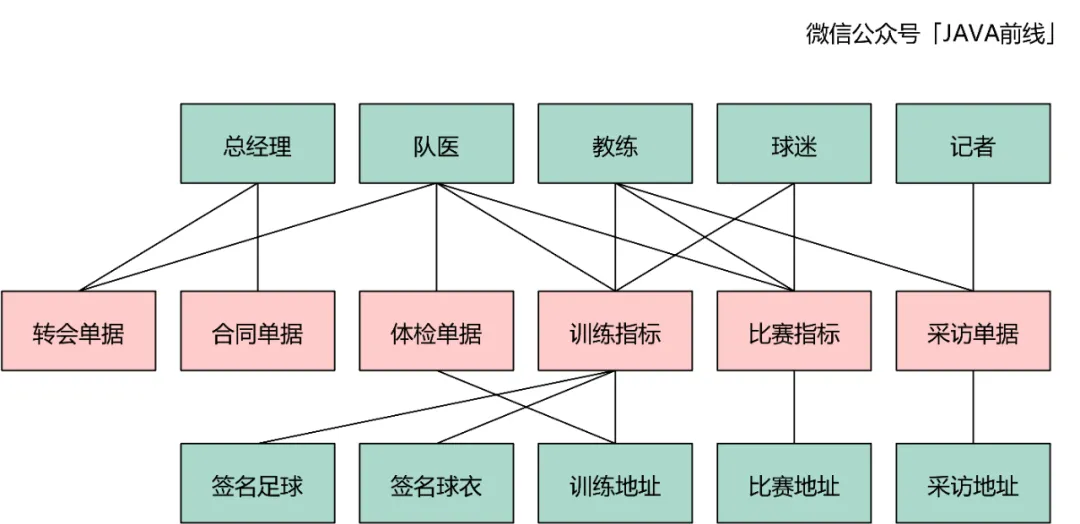
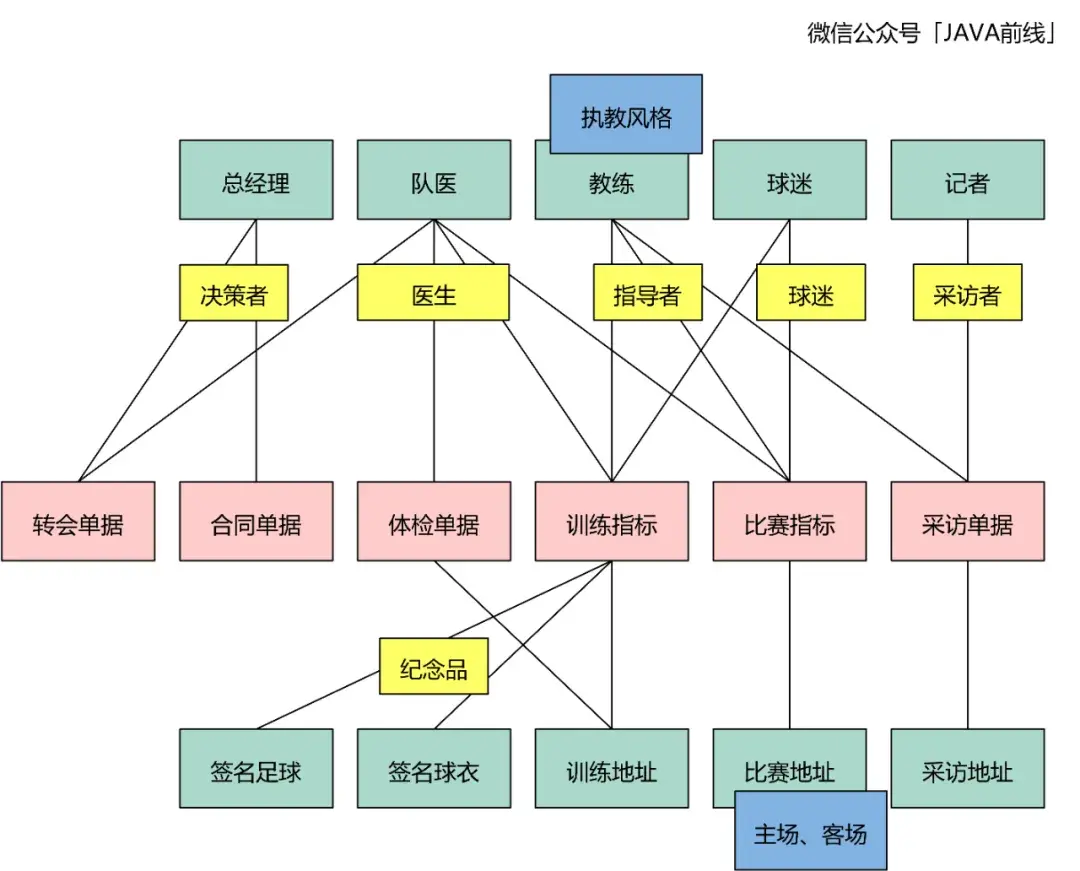
转会对应转会单据,体检对应体检单据,签合同对应合同单据,训练对应训练指标单据,比赛对应比赛指标单据,新闻发布会对应采访单据。根据分析绘制如下时标对象:

这三类对象在四色建模中用绿色表示,我们以电商场景为例进行说明。用户支付购买商家的商品时,用户和商家是参与方。物流系统发货时配送单据需要有配送地址对象,地址对象就是地。订单需要商品对象,物流配送需要有货品,商品和货品就是物。
我们分析本例可以知道参与方包含总经理、队医、教练、球迷、记者,地包含训练地址、比赛地址、采访地址,物包含签名球衣和签名足球:
在四色建模中用黄色表示,这类对象表示参与方、地、物是以什么角色参与到业务流程:
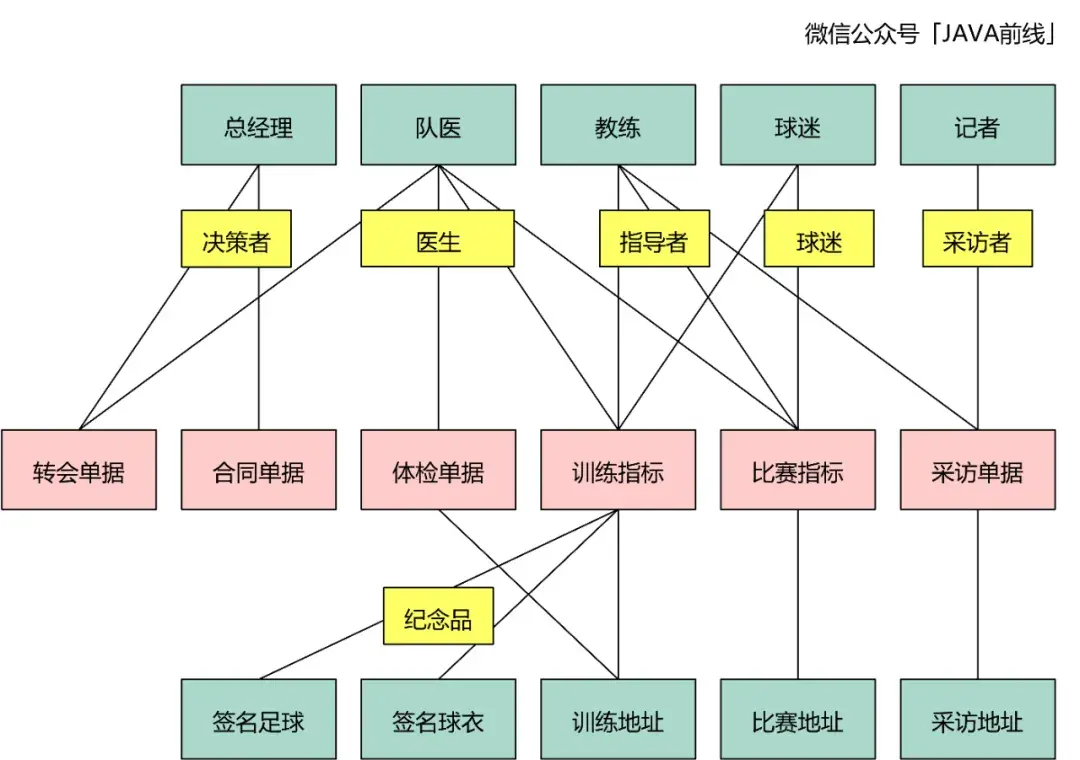
我们可以为对象增加相关描述信息,在四色建模中用蓝色表示:
在四色建模过程中我们体会到时标对象是最重要的对象,因为其承载了业务系统核心单据。在划分领域时我们同样离不开时标对象,通过收敛相关时标对象划分领域。
当业务系统发生一件事情时,如果本领域或其它领域有后续动作跟进,那么我们把这件事情称为领域事件,这个事件需要被感知。
例如球员比赛受伤了,这是比赛子域事件,但是医疗和训练子域是需要感知的,那么比赛子域就发出一个事件,医疗和训练子域会订阅。
例如球员比赛取得进球,这也是比赛子域事件,但是训练和合同子域也会关注这个事件,所以比赛子域也会发出一个比赛进球事件,训练和合同子域会订阅。
通过事件交互有一个问题需要注意,通过事件订阅实现业务只能采用最终一致性,需要放弃强一致性,这一点可能会引入新的复杂度需要权衡。
接口层:提供面向外部接口声明和DTO对象
访问层:提供HTTP访问入口
业务层:领域层和业务层都包含业务,但是用途不同。业务层可以组合不同领域业务,并且可以增加流控、监控、日志、权限控制切面,相较于领域层更为丰富,提供BO对象
领域层:提供DMO(DomainObject)、VO、事件、数据访问对象,核心是按照领域进行分包,领域内高内聚,领域间低耦合
外部访问层:在这个模块中调用外部RPC服务,解析返回码和返回数据
基础层:包含基础功能,例如缓存工具,消息队列,分布式锁,消息发送等功能
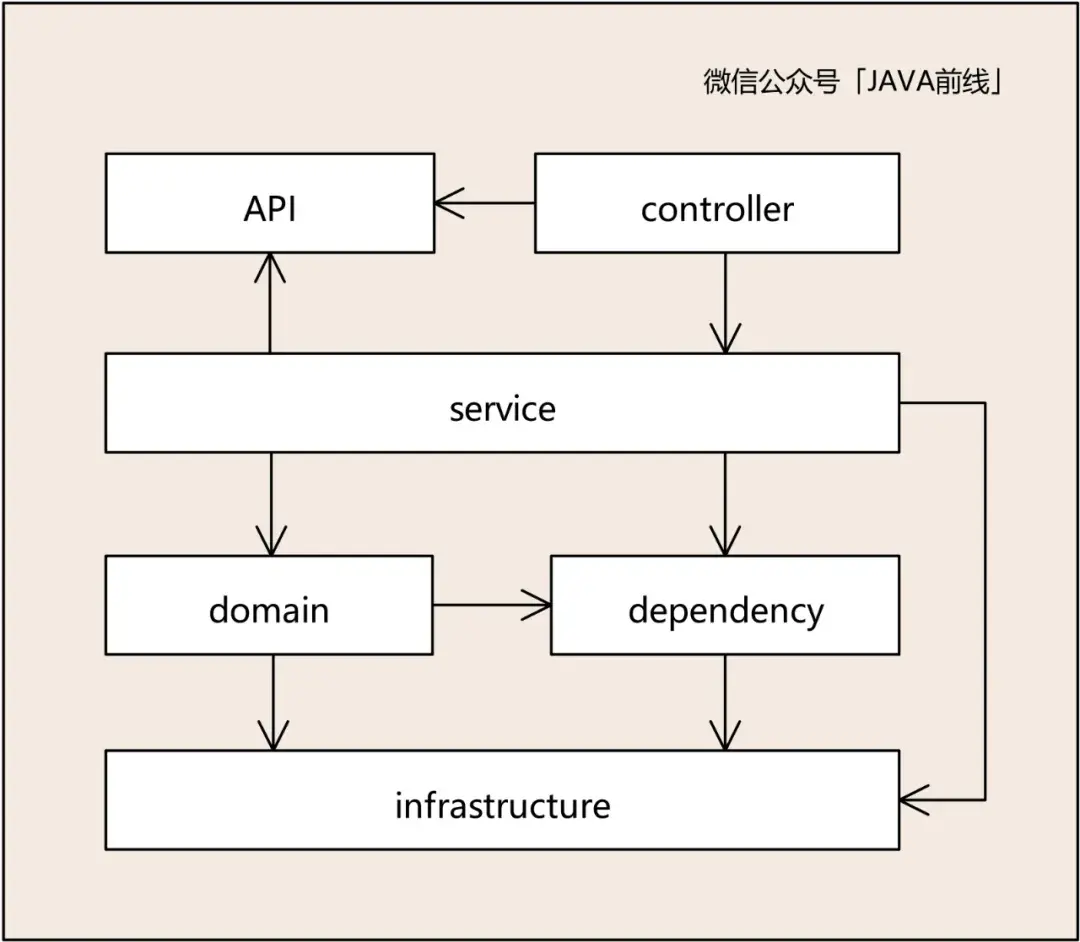
我们展开领域层进行分析。领域层的核心是按照领域进行分包,并且提供DMO、VO、事件、数据访问对象,领域内高内聚,领域间低耦合,例如domain1对应合同子域,domain2对应训练子域,domain3对应合同子域。
目前为止领域已经确定了,现在可以根据领域划分任务了,组内成员分别负责一个或多个领域进行详细设计,这个阶段就是大家非常熟悉的用例图,活动图,时序图,数据库设计,接口设计的用武之地。需要说明的是领域驱动设计不是取代详细设计,而是为了更清晰地详细设计。
本文探讨了DDD落地时需要关注的六个问题,并通过一个足球运动员信息管理系统案例落地了六个步骤。在实际应用中各业务形态千差万别,但是方法论却可以通用,我们需要明确DDD核心是分而治之各个击破,并配合一些经过检验的有效方法进行建模,希望本文对大家有所帮助。
欢迎大家关注公众号「JAVA前线」查看更多精彩分享文章,主要包括源码分析、实际应用、架构思维、职场分享、产品思考
你好,我是徐昊。今天我们来聊聊领域驱动设计(Domain Driven Design,即DDD)。
说起业务建模,领域驱动设计是一个绕不过去的话题。自从Eric Evans在千禧年后发布他的名著“Domain Driven Design:Tackling the Complexity in the Heart of Software”,领域驱动设计这一理念迅速被行业采纳,时至今日仍是绝大多数人进行业务建模的首要方法。
有意思的是,可能因为成书年代过于久远,大多数人并没有读过Eric的书,而是凭直觉本能地接受了领域驱动这一说法,或是在实践中跟随周围的实践者学习使用它。但是对于Eric到底在倡导一种什么样的做法并不了然。
所以今天这节课,我们要回顾一下领域驱动设计的要点和大致做法,从而可以更好地理解DDD从何处而来,以及DDD在其创始人的构想中是如何操作的。
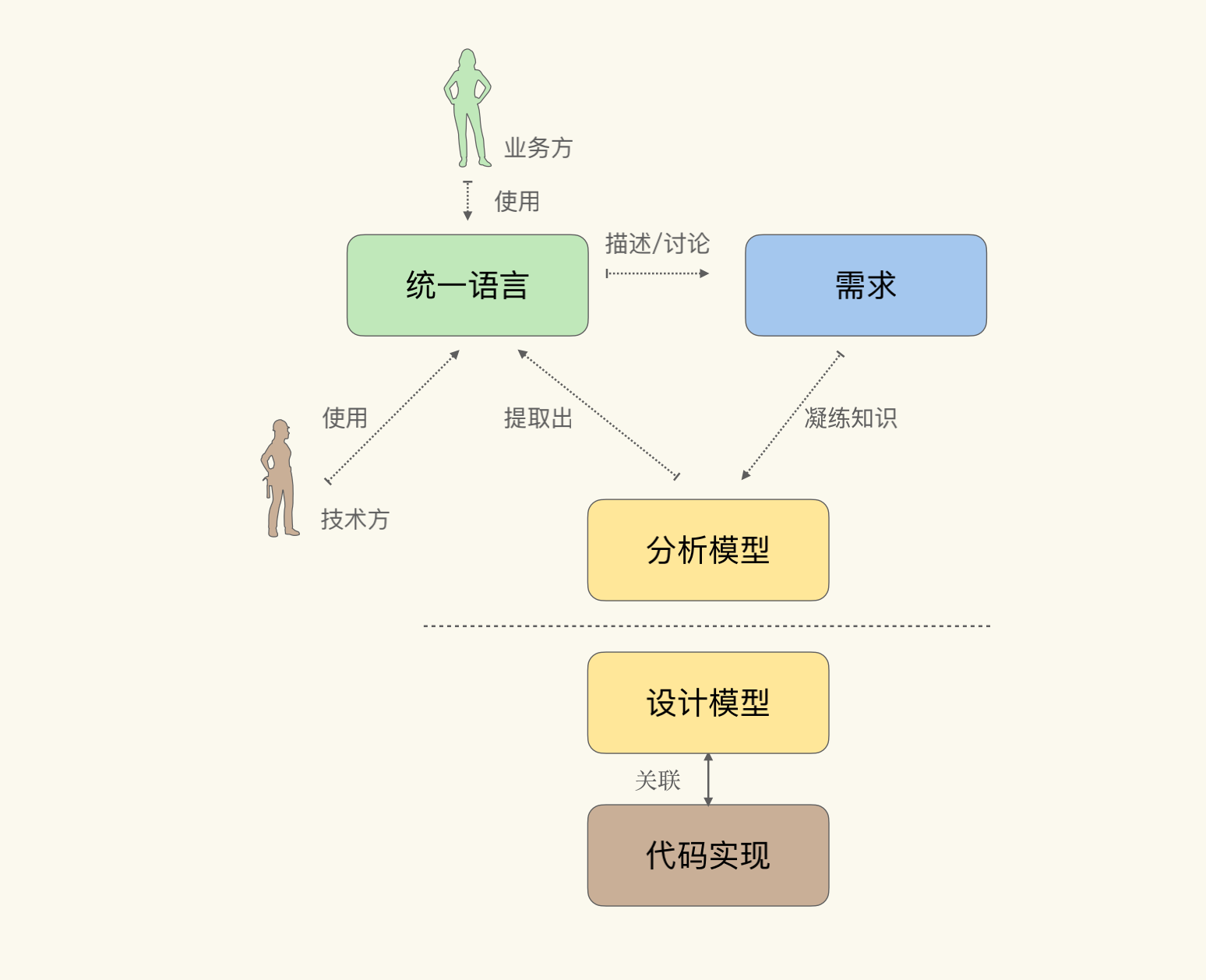
我们都知道,软件开发的核心难度在于处理隐藏在业务知识中的复杂度,那么模型就是对这种复杂度的简化与精炼。所以从某种意义上说,Eric倡导的领域驱动设计是一种模型驱动的设计方法:通过领域模型(Domain Model)捕捉领域知识,使用领域模型构造更易维护的软件。
模型在领域驱动设计中,其实主要有三个用途:
- 通过模型反映软件实现(Implementation)的结构;
- 以模型为基础形成团队的统一语言(Ubiquitous Language);
- 把模型作为精粹的知识,以用于传递。
这样做的好处是显而易见的:
- 理解了模型,你就会大致理解代码的结构;
- 在讨论需求的时候,研发人员可以很容易明白需要改动的代码,并对风险与进度有更好的评估;
- 模型比代码更简洁,毕竟模型是抽象出来的,因而有更低的传递成本。
模型驱动本身并不是什么新方法,像被所有人都视为编程基本功的数据结构,其实也是一系列的模型。我们都知道有一个著名的公式“程序 = 算法 + 数据结构”,实际上这也是一种模型驱动的思路,指的是从数据结构出发构造模型以描述问题,再通过算法解决问题。
在软件行业发展的早期,堆、栈、链表、树、图等与领域无关的模型,确实帮我们解决了从编译器、内存管理到数据库索引等大量的基础问题。因此,无数的成功案例让从业人员形成了一种习惯:将问题转化为与具体领域无关的数据结构,即构造与具体领域无关的模型。
而领域驱动则是对这种习惯的挑战,它实际讲的是:对于业务软件而言,从业务出发去构造与业务强相关的模型,是一种更好的选择。那么模型是从业务出发还是与领域无关,关键差异体现在人,而不是机器对模型的使用上。
构造操作系统、数据库等基础软件的团队,通常都有深厚的开发背景,对于他们而言,数据结构是一种常识。更重要的是,这种常识并不仅仅体现在对数据结构本身的理解上(如果仅仅是结构那还不能算难以理解),还体现在与数据结构配合的算法,这些算法产生的行为,以及这些行为能解决什么问题。
比如树(Tree)这种非常有用的数据结构,它可以配合深度优先(Depth-First)、广度优先(Breadth-First)遍历,产生不同的行为模式。那么当开发人员谈论树的时候,它们不仅仅指代这种数据结构,还暗指了背后可能存在的算法与行为模式,以及这种行为与我们当前要解决的业务功能上存在什么样的关联。
但是,如果我们构造的是业务系统,那么团队中就会引入并不具有开发背景的业务方参与。那么这个时候,与领域无关的数据结构及其关联算法,由于业务方并不了解,那么在他们的头脑中也就无法直观地映射为业务的流程和功能。这种认知上的差异,会造成团队沟通的困难,从而破坏统一语言的形成,加剧知识传递的难度。
于是在业务系统中,构造一种专用的模型(领域模型),将相关的业务流程与功能转化成模型的行为,就能避免开发人员与业务方的认知差异。这也是为什么我们讲,领域模型对于业务系统是一种更好的选择。
或许在今天看起来,这种选择是天经地义的。但事实是,这一理念的转变开始于面向对象技术的出现,而最终的完成,则是以行业对DDD的采纳作为标志的。
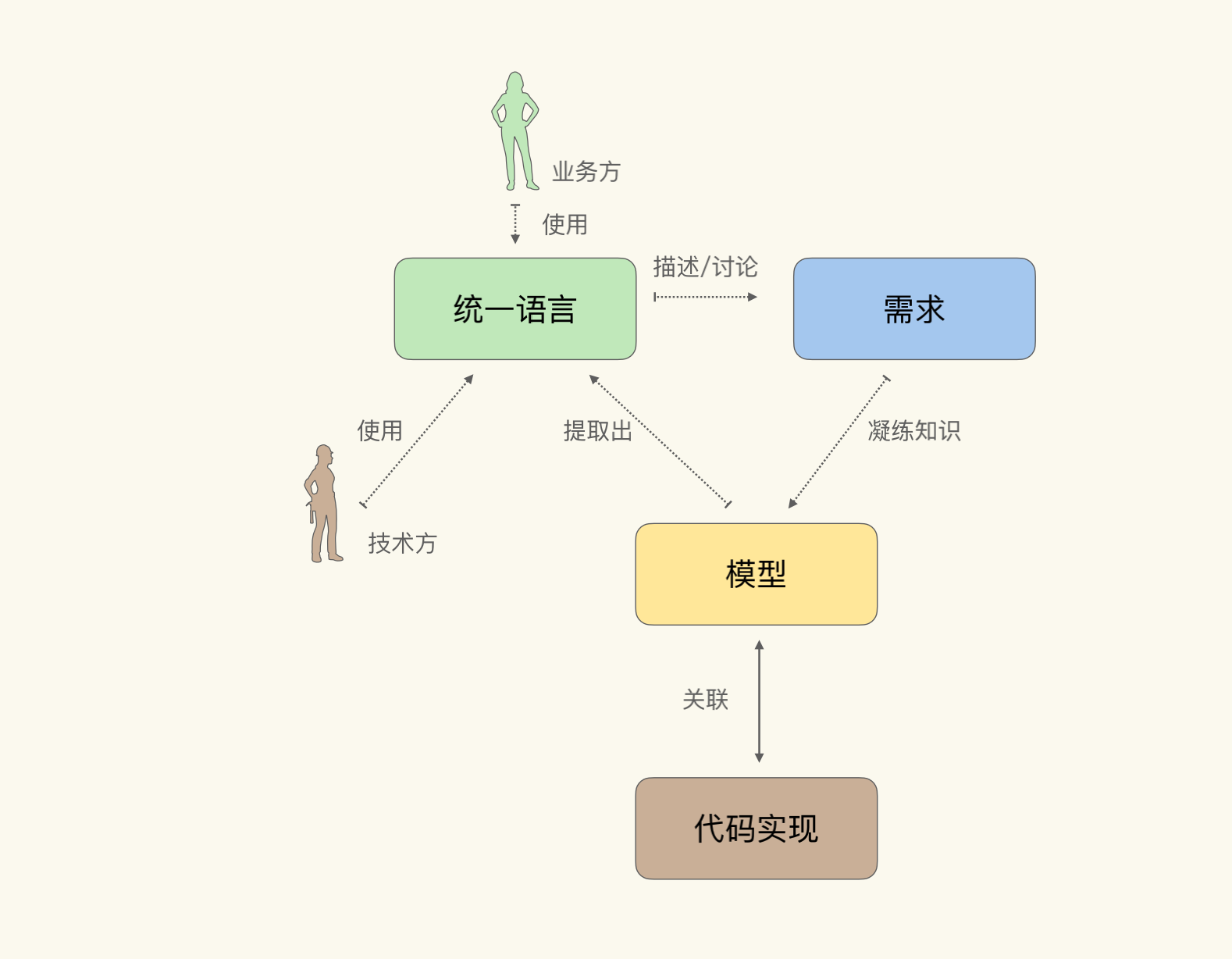
不同于软件行业对数据结构的长时间研究与积累,在不同的领域中该使用什么样的领域模型,其实并没有一个现成的做法。因而在DDD中,Eric Evans提倡了一种叫做知识消化(Knowledge Crunching)的方法帮助我们去提炼领域模型。这么多年过去了,也产生了很多新的提炼领域模型的方法,但它们在宏观上仍然遵从知识消化的步骤。
知识消化法具体来说有五个步骤,分别是:
- 关联模型与软件实现;
- 基于模型提取统一语言;
- 开发富含知识的模型;
- 精炼模型;
- 头脑风暴与试验。
在知识消化的五步中,关联模型与软件实现,是知识消化可以顺利进行的前提与基础。它将模型与代码统一在一起,使得对模型的修改,就等同于对代码的修改。
而根据模型提取统一语言,则会将业务方变成模型的使用者。那么通过统一语言进行需求讨论,实际就是通过模型对需求进行讨论。
后面三步呢,构成了一个提炼知识的循环:通过统一语言讨论需求;发现模型中的缺失或者不恰当的概念,精炼模型以反映业务的实践情况;对模型的修改引发了统一语言的改变,再以试验和头脑风暴的态度,使用新的语言以验证模型的准确。
如此循环往复,不断完善模型与统一语言。因其整体流程与重构(Refactoring)类似,也有人称之为重构循环。示意图如下:
说句题外话,目前很多人把 Knowledge Crunching 翻译为“知识消化”。不过在我看来,应该直译为“知识吧唧嘴”更好些,Crunching 就是吃薯片时发出的那种难以忽略的咔嚓咔嚓声。
你看,Knowledge Crunching 是一个如此有画面感的词汇,这就意味着当我们获取领域知识的时候,要大声地、引人注意地去获得反馈,哪怕这个反馈是负面的。
而且如果我们把它叫做“知识吧唧嘴”,我们很容易就能从宏观上理解 Knowledge Crunching 的含义了:吸收知识、接听反馈——正如你吃薯片时在吧唧嘴一样。
好了,言归正传,通过以上的分析,我们其实可以把“知识消化”这五步总结为“两关联一循环”:
- “两关联”即:模型与软件实现关联;统一语言与模型关联;
- “一循环”即:提炼知识的循环。
今天我们先介绍模型与软件实现关联。后面两节课,再关注统一语言与提炼知识的循环。
我们已经知道,领域驱动设计是一种模型驱动的设计方法。那么很自然地,我们可以得到这样一个结论:
- 模型的好坏直接影响了软件的实现;
- 模型的好坏直接影响了统一语言;
- 模型的好坏直接影响了传递效率与成本。
但Eric Evans在知识消化中并没有强调模型的好坏,反而非常强调模型与软件实现间的关联,这是一种极度违反直觉的说法。
这种反直觉的选择,背后的原因有两个:一是知识消化所倡导的方法,它本质上是一种迭代改进的试错法;第二则是一些历史原因。
所谓迭代改进试错法,就是不求一步到位,但求一次比一次好。正如我们刚才总结的,知识消化是“两关联一循环”。通过提炼知识的循环,技术方与业务方在不断地交流与反馈中,逐步完成对模型的淬炼。
无论起点多么低,只要能够持续改进,总有一天会有好结果的。而能够支撑持续改进基础的,则是实现方式与模型方式的一致。所以比起模型的好坏(总是会改好的),关联模型与软件实现就变得更为重要了。
历史原因则有两点:一是因为在当时,领域模型通常被认为是一种分析模型(Analysis Model),用以定义问题的,而无需与实现相关。这样做的坏处呢,我们下面再细讲。
二是因为当时处在面向对象技术大规模普及的前夕,由于行业对面向对象技术的应用不够成熟,将模型与实现关联需要付出额外的巨大成本,因而通常会选择一个相对容易、但与模型无关联的实现方式。这个相对容易的方式,往往是过程式的编程风格。
而与模型关联的实现方法,也就是被称作“富含知识的模型(Knowledge Rich Model)”,是一种面向对象的编程风格。因此,我们强调模型与实现关联,实际上也就在变相强调面向对象技术在表达领域模型上的优势。接下来我们具体分析。
在DDD出版的年代,Hibernate(一种Object Relationship Mapping框架,可以将对象模型与其存储模型映射,从而以对象的角度去操作存储)还是个新鲜事物。大量的业务逻辑实际存在于数据访问对象中,或者干脆还在存储过程(Store Procedure)里。
如果把时光倒回到2003年前后,程序的“常规”写法和DDD提倡的关联模型与实现的写法,在逻辑组织上还是有显而易见的差异的。
我们现在考虑一个简单的例子,比如极客时间的用户订阅专栏。我们很容易在头脑中建立起它的模型:
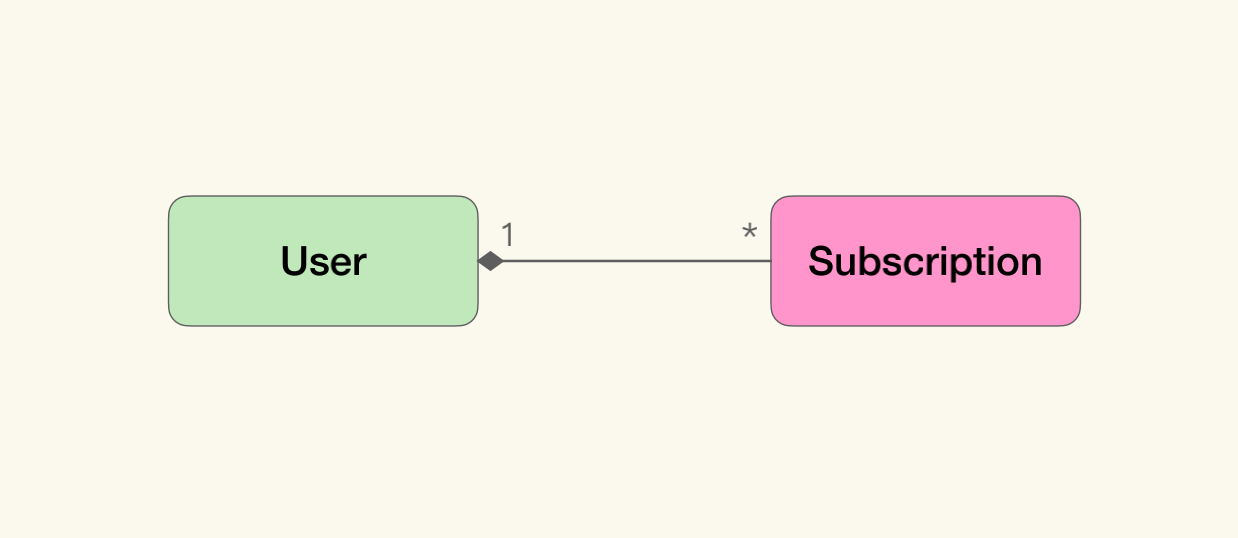
在ORM流行起来之前的2003年(当然那时候没有try-close语法),如下的代码并不是不可接受:
class UserDAO {… public User find(long id) { 讯享网try(PreparedStatement query = connection.createStatement(...)) { ResultSet result = query.executeQuery(....); if (rs.next) return new User(rs.getLong(1), rs.getString(2), ....); .... } catch(SQLException e) { ... }
} } class SubscriptionDAO { … // 根据用户Id寻找其所订阅的专栏 public List<Subscription> findSubscriptionsByUserId(long userId) { ...
} // 根据用户Id,计算其所订阅的专栏的总价 public double calculateTotalSubscriptionFee(long userId) { 讯享网 ...
} } 这样的实现方式就是被我司首席科学家Martin Fowler称作“贫血对象模型”(Anemic Model)的实现风格,即:对象仅仅对简单的数据进行封装,而关联关系和业务计算都散落在对象的范围之内。这种方式实际上是在沿用过程式的风格组织逻辑,而没有发挥面向对象技术的优势。
与之相对的则是“充血模型”,也就是与某个概念相关的主要行为与逻辑,都被封装到了对应的领域对象中。“充血模型”也就是DDD中强调的“富含知识的模型“。不过作为经历那个时代的程序员,以及Martin Fowler的同事来说,“充血模型”是我更习惯的一个叫法。
Eric在DDD中总结了构造“富含知识的模型”的一些关键元素:实体(Entity)与值对象(Value Object)对照、通过聚合(Aggregation)关系管理生命周期等等。按照DDD的建议,刚才那段代码可以被改写为:
class User {// 获取用户订阅的所有专栏 public List<Subscription> getSubscription() { 讯享网 ...
} // 计算所订阅的专栏的总价 public double getTotalSubscriptionFee() { ...
} } class UserRepository { … public User findById(long id) { 讯享网...
} } 从这段代码很容易就可以看出:User(用户)是聚合根(Aggregation Root);Subscription(订阅)是无法独立于用户存在的,而是被聚合到用户对象中。
不同于第一段代码中单纯的数据封装,改写后这段代码里的User,具有更多的逻辑。Subscription的生命周期被User管理,无法脱离User的上下文独立存在,我们也无法构造一个没有User的Subscription对象。
而在之前的代码示例中,我们其实可以很容易地脱离User,直接从数据库中查询出Subscription对象(通过调用findSubscriptionsByUserId)。所有与Subscription相关的计算,其实也被封装在User上下文中。
这样做有什么好处呢?首先我们需要明白,在建模中,聚合关系代表了什么含义,然后才能看出“贫血模型”与“富含知识的模型”的差异。我们还是以极客时间的专栏为例。
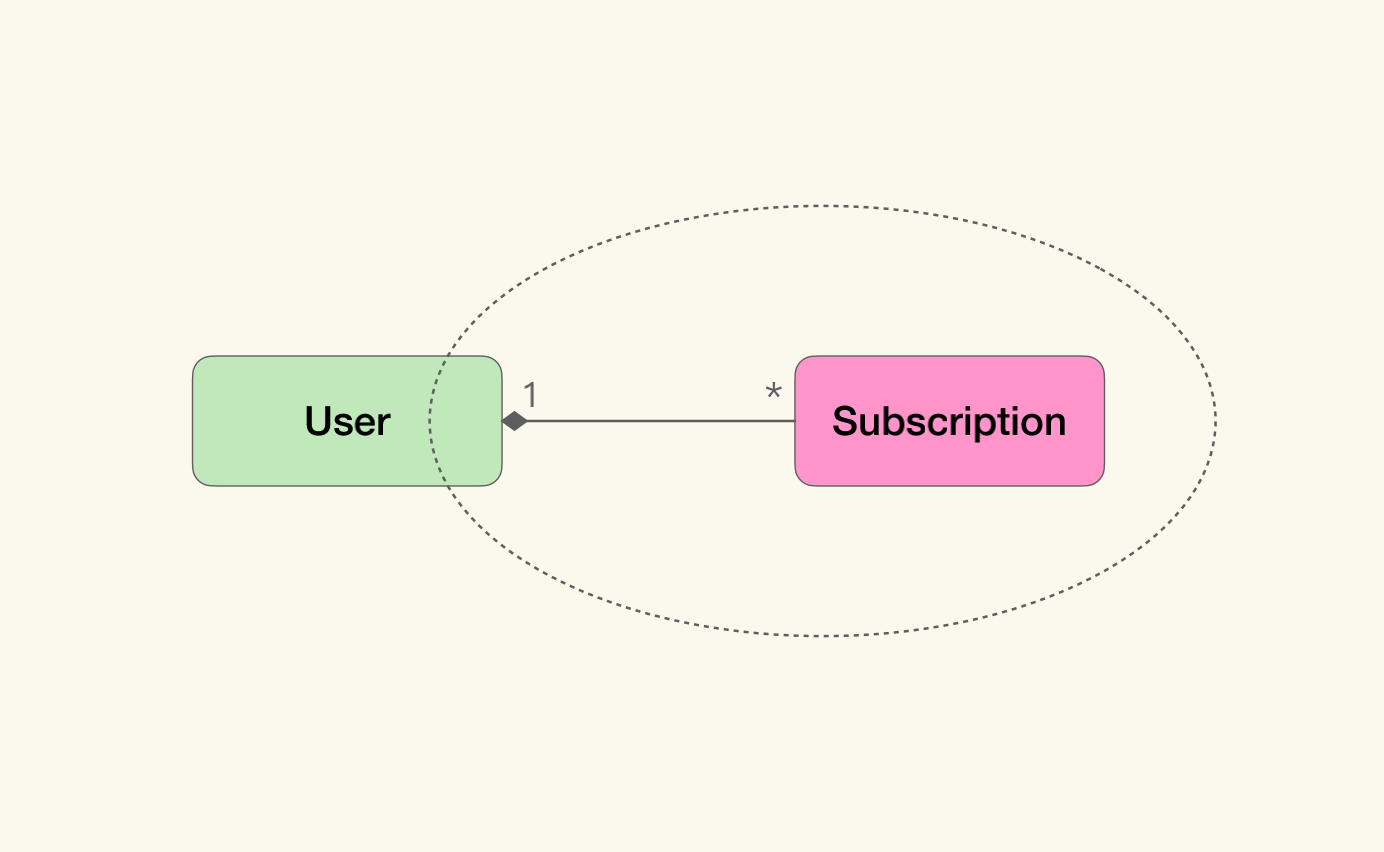
为了表示用户订阅了某个专栏,我们需要同时使用“用户”与“订阅”两个概念。因为一旦脱离了“订阅”,“用户”只能单纯地表示用户个人的信息;而脱离了“用户”,“订阅”也只能表示专栏信息。那么只有两个放在一起,才能表达我们需要的含义:用户订阅的专栏。
也就是说,在我们的概念里,与业务概念对应的不仅仅是单个对象。通过关联关系连接的一组对象,也可以表示业务概念,而一部分业务逻辑也只对这样的一组对象起效。但是在所有的关联关系中,聚合是最重要的一类。它表明了通过聚合关系连接在一起的对象,从概念上讲是一个整体。
以此来看,当我们在这个例子里,谈到User是Subscription的聚合根时,实际上我们想说的是,在表达“用户订阅的专栏”时,User与Subscription是一个整体。如果将它们拆分,则无法表示这个概念了。同样,计算订阅专栏的总价,也只是适用于这个整体的逻辑,而不是Subscription或User独有的逻辑。
总结来说,我们无法构造一个没有User的Subscription对象,也就是说这种概念在软件实现上的映射,比起“贫血模型”的实现方式,“富含知识的模型”将我们头脑中的模型与软件实现完全对应在一起了——无论是结构还是行为。
这显然简化了理解代码的难度。只要我们在概念上理解了模型,就会大致理解代码的实现方法与结构。同样,也简化了我们实现业务逻辑的难度。通过模型可以解说的业务逻辑,大致也知道如何使用“富含知识的模型”在代码中实现它。
关联模型与软件实现,最终的目的是为了达到这样一种状态:修改模型就是修改代码;修改代码就是修改模型。
在知识消化中,提炼知识的重构是围绕模型展开的。如果对于模型的修改,无法直接映射到软件的实现上(比如采用贫血模型),那么凝练知识的重构循环就必须停下来,等待这个同步的过程。
如果不停下来等待,模型与软件间的割裂,就会将模型本身分裂为更接近业务的分析模型,以及更接近实现的设计模型(Design Model)。这个时候,分析模型就会逐渐退化成纯粹的沟通需求的工具,而一旦脱离了实现的约束,分析模型会变得天马行空,不着边际。如下所示,分析模型参与需求,设计模型关联实现:
事实上,这套做法在上世纪90年代就被无数案例证明难以成功,于是才在21世纪初有了模型驱动架构(Model-Driven Architecture)、领域驱动设计等一系列使用统一模型的方法。那么,在模型割裂的情况下,统一语言与提炼知识循环也就不会发生了,所以我们才必须将模型与软件实现关联在一起,这也是为什么我们称它是知识消化的基础与前提。
你或许会有疑惑,“富含知识的模型”的代码貌似就是我们平常写的代码啊!是的,随着不同模式的ORM在21世纪初期相继成熟,以及面向对象技术大规模普及,将领域模型与软件实现关联,在技术上已经没有多大难度了。虽然寻找恰当的聚合边界仍然是充满挑战的一件事,但总体而言,我们对这样的实现方式并不陌生了。
由此我们可以更好地理解,DDD并不是一种编码技术,或是一种特定的编码风格。有很多人曾这样问我:怎么才能写得DDD一点?
我一般都会告诉他,只要模型与软件实现关联了,就够了。
毕竟“DDD的编码”的主要目的是不影响反馈的效率,保证凝练知识的重构循环可以高效地进行。如果不配合统一语言与提炼知识循环,那么它就只是诸多编码风格之一,难言好坏。
而如果想“更加DDD”的话,则应该更加关注统一语言与提炼知识循环,特别是提炼知识循环。事实上,它才是DDD的核心过程,也是DDD真正发挥作用的地方。
领域驱动设计是一种领域模型驱动的设计方法,它强调了在业务系统中应该使用与问题领域相关的模型,而不是用通用的数据结构去描述问题。这一点已被行业广泛采纳。
Eric Evans提倡的知识消化,总结起来是“两关联一循环”:模型与软件实现关联;统一语言与模型关联;提炼知识的循环。
知识消化是一种迭代改进试错法,它并不追求模型的好坏,而是通过迭代反馈的方式逐渐提高模型的有效性。这个过程的前提是将模型与软件实现关联在一起。
这种做法在21世纪初颇有难度,不过随着工具与框架的成熟,也成为了行业熟知的一种做法。于是,通过迭代反馈凝练知识就变成了实施DDD的重点。
不过,在进入这部分之前,我们还要看看如何将统一语言与模型关联起来,这个我们下节课再深入讨论。
既然领域驱动设计是一种模型驱动的设计方法,为什么不能让业务方直接去使用模型,而要通过统一语言?这是不是有点多余?

领域驱动设计(Domain-Driven Design,简称 DDD)是一种软件开发设计思想,其旨在以领域为核心,让软件系统在实现时准确地基于对真实业务过程的建模,专注于业务问题域的需要。
DDD将软件系统设计分为了2个部分:战略设计和战术设计,战略设计用于提炼问题域并塑造应用程序的架构,战术设计用于帮助创建用于复杂有界上下文的有效模型。基于此,DDD强调专注于核心领域,通过协作对公共语言和知识进行提炼,并且持续致力于领域的知识提炼,让模型持续发展。
本文基于DDD思想,在携程国际火车票中台预订系统项目进行实践。
本文以国际火车票中台预订系统项目的创单流程为例,其服务结构下图所示:
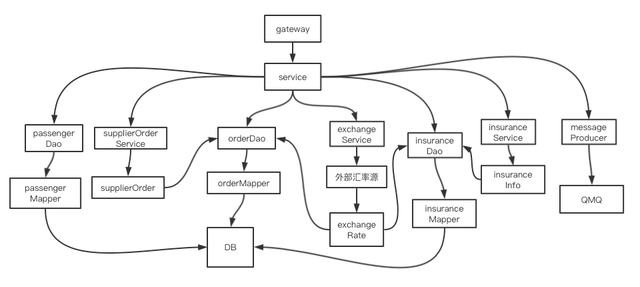
伪代码如下所示:
@Override protected CreateOrderResponse execute(CreateOrderRequest request) {讯享网// 1、参数校验 if (!validate(request)) { throw new BusinessException(P2pBookingResultCode.PARAM); } if (orderMapper.select(request.getOrderId()) != null) { throw new BusinessException(P2pBookingResultCode.ORDER_EXISTS); } // 2、初始化订单 OrderDao orderDao = new OrderDao(); orderDao.setOrderId(request.getOrderId()); orderDao.setOrderStatus(100); orderMapper.insert(orderDao); // 初始化乘客信息 PassengerDao passengerDao = new PassengerDao(); ... passengerMapper.insert(passengerDao); // 3、转换汇率 ExchangeRate exchangeRate = exchangeService.getExchangeRate(originCurrency, targetCurrency); // 4、购买保险 if (isBuyInsurance(request)) { // 调用保险服务 InsuranceInfo insuranceInfo = insuranceService.buyInsurance(request); // 保存保险信息 InsuranceDao insuranceDao = new InsuranceDao(); ... insuranceMapper.insert(insuranceDao); } // 5、供应商创单 SupplierOrder supplierOrder = supplierService.createOrder(request, exchangeRate); // 保存供应商订单信息 SupplierOrderDao supplierOrderDao = new SupplierOrderDao(); ... supplierOrderMapper.insert(SupplierOrderDao); // 6、保存订单信息 orderDao = new orderDao(); orderDao.setOrderId(request.getOrderId); orderDao.setOrderStatus(OrderStatusEnum.WAIT_FOR_PAY.getCode()); ... orderMapper.update(orderDao); // 7、发送超时支付取消消息 messageProducer.push(MessageQueueConstants.TOPIC_TIMEOUT_CANCEL, "orderId", String.valueOf(orderDao.getOrderId()), appSettingProp.getTimeoutMinutes(), TimeUnit.MINUTES); // 8、返回结果 return mappingResponse(orderDao, orderInsuranceEntity, exchangeRateResponse);
}2.1 控制层臃肿
在传统的互联网软件架构中,通常都会采用MVC三层架构,其是一种古老且经典的软件设计模式,基于分层架构的思想,将整个程序分为了Model、View和Controller三层:
- Model(模型层):最底下一层,是核心的数据,也就是程序需要操作的数据或信息;
- View(视图层):最上面一层,直接面向最终用户的视图,它是提供给用户的操作界面,是程序的外壳;
- Controller(控制层):中间的一层,就是整个程序的逻辑控制核心,它负责根据视图层输入的指令选取数据层的数据,然后对其进行相应操作产生最终结果;
MVC三层架构模式,将软件架构分为了三层,就可以让软件实现模块化,使三层相互独立,修改外观或者变更数据都不需要修改其他层,方便了维护和升级。但是这种软件架构中模型层只关注数据,控制层只关注行为,随着迭代的不断演化,业务逻辑越来越复杂,便会导致整个控制层的代码量越来越多,而模型层和视图层的变更却很少,最终导致整个控制层变得十分臃肿,从而失去了分层的意义。
2.2 过度耦合
在业务初期,程序的功能都非常简单,此时系统结构逻辑是清晰的,但是随着程序的不断迭代,一方面会导致业务逻辑越来越复杂,系统逐渐冗余,模块之间彼此关联,软件架构设计模式逐渐向“大泥球”模式(BBoM,Big Ball of Mud)发展;另一方面系统会调用越来越多的第三方服务,从而导致数据格式不兼容,业务逻辑无法复用。
在出票系统中,除了订单相关的功能外,还包括了保险、汇率、供应商订单等多个服务接口,同时包括保险、供应商订单、乘客等多个模块的功能及存储均耦合在出票流程的控制层中,使得我们在维护代码时,修改一个模块的功能可能会影响到其他功能模块。
另一方面,如汇率服务这种第三方接口也会存在结构不稳定的情况,当其API签名发生变化或者服务不可靠需要寻找其他可替代的服务时,整个核心逻辑都会随之更改,迁移成本也是巨大的。
2.3 失血模型
失血模型是指领域对象里只有get和set方法的POJO,所有业务逻辑都不包含在内而是放在控制层中,该模型对象的缺点就是不够面向对象,对象只是数据的载体,几乎只做传输介质之用,它是没有生命、没有行为的。
与失血模型相对应的就是充血模型,充血模型就是会包含此领域相关的业务逻辑等,同时也可以包含持久化操作,它的优点对象自洽程度很高,表达能力很强,可复用性很高,更加符合面向对象的思想。
对于创单流程中的对象几乎都是使用的失血模型,虽然可以完成功能的实现,但是在系统逐渐迭代,业务逻辑逐渐复杂后,采用失血模型会导致业务逻辑。状态散落在大量的方法中,使得代码的意图渐渐不够明确,代码的复用性下降。
通过上文的背景介绍,我们基于DDD思想对携程国际火车票中台预订系统做出了一定的重构,使系统实现高内聚、低耦合。
3.1 系统设计
Evic Evans将软件系统的设计分为2个部分:战略设计和战术设计。战略设计提出了域、子域、限界上下文等概念,主要用于指导我们如何拆分一个复杂的系统,战术设计提出了实体、值对象、聚合、工厂、仓储。领域事件等概念,主要用于指导我们对于拆分出来的单个域如何进行落地,以及落地过程中需要遵循的原则。
3.1.1 战略设计
通用语言
对于国际火车票中台预定系统,我们定义了预定的通用语言:
- 通过用户搜索条件调用供应商下单;
- 记录供应商相关数据用于财务统计;
- 根据用户选定币种做汇率转换;
- 根据用户选择购买保险;
领域

在通过软件实现一个业务系统时,建立一个领域模型是非常重要和必要的。因为领域模型是整个软件的核心,其是对某个边界的领域的一个抽象,反映了领域内用户业务需求的本质,开发者便可以仅关注领域边界内所需关注的部分。同时领域对象与技术实现无关,仅反映业务,领域模型贯穿软件分析、设计,以及开发的整个过程。领域专家、设计人员、开发人员通过领域模型进行交流,彼此共享知识与信息。因为大家面向的都是同一个模型,所以可以防止需求走样,可以让软件设计开发人员做出来的软件真正满足需求。
基于此,我们将预定系统划分为了对客订单和对供应商订单两个子域,对客订单负责处理客户需要,对供应商订单负责记录供应商侧的相关数据用于财务统计。
限界上下文
划分限界上下文主要是想传达一种领域设计的思考方式,通过建模来划分清楚业务领域的边界,划分关系如下所示:
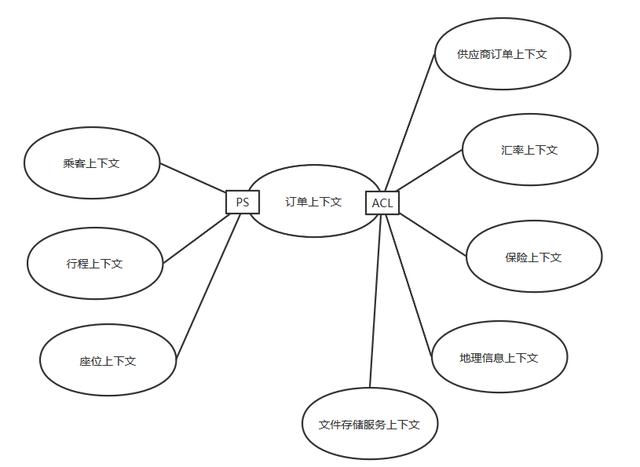
在上图左侧的PS代表合作关系(Partner Ship),右侧的ACL表示防腐层(Anticorruption Layer),即右侧几个上下文均是外部领域,需要通过防腐层来转换交互,以隔离业务。
3.1.2 战术设计
上文提到的失血模型,绝大多数来自于数据库的Dao对象,因为Dao对象仅仅是数据库结构的映射,没有包含业务逻辑,这样就会导致业务逻辑、校验逻辑散落在各个service层,不易维护。为了解决这个问题,DDD将领域模型与数据模型做了区分,前者用于内聚自身行为,后者用于业务数据的持久化,仓储就是用来链接这两层的对象,数据模型又可以分为实体和值对象。
实体
实体(Entity)是指领域中可以由唯一标识进行区分的,且具有生命周期的对象,例如上文中的订单就是一个实体,其可以通过订单号进行唯一标识,且订单在整个预定系统中状态会发生改变。
值对象
值对象(Value Object)是指没有唯一标识的对象,也就是我们不需要关心对象是哪个,只需要关心对象是什么,例如上文中的行程上下文,故我们不能提供其set方法,行程如果需要改变应该整个对象更新掉。
聚合根
聚合(Aggregate)是指通过定义对象之间清晰的所属关系和边界来实现领域模型的内聚,并避免了错综复杂的难以维护的对象关系网的形成。聚合是一组相关对象的集合,每个聚合有一个根和边界,聚合根(Aggregate Root)是这个聚合的根节点,其必须是一个实体,边界定义了聚合内部有哪些实体或值对象。聚合内部的对象可以相互引用,对外通过聚合根进行交互。
仓储
仓储(repository)就是对领域的存储和访问进行统一管理的对象,聚合根被创建出来后进行持久化都需要跟数据库打交道,这样我们就需要一个类似数据库访问层的东西来管理领域对象。
3.2 架构设计
DDD有多种分层架构模式,包括四层架构模式、五层架构模式、六层架构模式等,其核心均是定义一层领域层对领域对象及其关系进行建模,从传统的MVC三层架构中将领域抽出,但是依然是高层组件依赖低层组件,不同层次之间的耦合无法消除,故本文采用的是一种改进的分层架构模型:六边形架构,其结构如下所示:
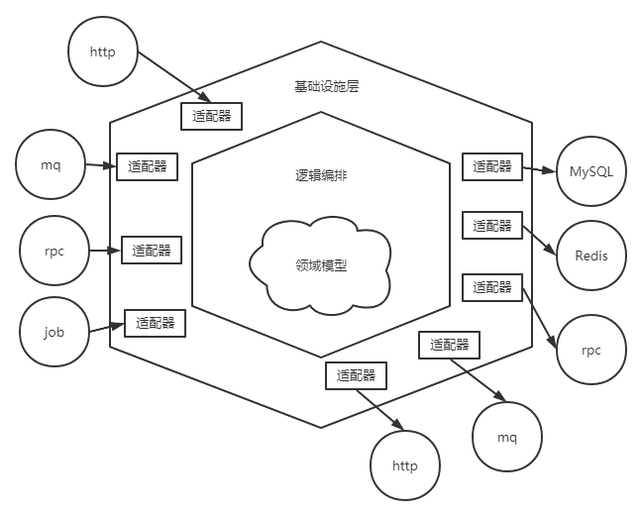
六边形架构采用依赖倒置原则优化了传统的分层架构,低层组件应该依赖于高层组件提供的接口,即无论高层还是低层都依赖于抽象,这样使得整个架构变平。六边形中每条不同的边代表了不同类型的端口,端口要么处理输入,要么处理输出,这样就将外界与系统内部进行了隔离,对于每种外部类型,都需要一个适配器与之对应。
六边形架构的最大特点就是将技术与业务进行分离,六边形内部核心就是领域模型及不同领域的逻辑编排,领域模型外部的基础设施层就是为领域模型提供技术实现以及外部系统的适配,因为技术选型在项目之初就已经选定完成并且随着项目迭代也很少会发生更改,所以业务人员可以将更多的精力放在领域模型的更新上面。
如上文介绍的三方接口结构不稳定情况,也可以通过适配器转化为内部模型,防止修改成本过高。同时,对于外部请求,无论是通过rpc,REST、HTTP还是通过MQ等方式,均可通过适配器对输入进行转化,控制权由此交给内部区域进行处理。同时,上文战术设计中的仓储(repository)的实现也可以看作是持久化适配器,该适配器用于访问先前存储的聚合实例或者保存新的聚合实例,我们可以通过不同方式实现仓储适配器,如MySQL、Redis等。
通过上文分析,本文以国际火车票中台预订系统项目作为DDD实践落地。
4.1 项目架构
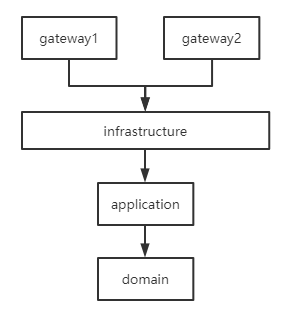
根据DDD六边形架构原理,系统架构如上图所示,总共分为了4层:
- gateway:项目入口,其中包括rpc、mq等不同入口;
- infrastructure:基础设施层,一方面用作防腐,提供不同入口、出口的适配,另一方面实现领域层的接口提供技术实现;
- application:应用层,用于逻辑编排、管理、调度,突出核心逻辑,尽可能轻薄;
- domain:领域层,定义领域模型,对领域模型进行建模;
4.2 领域对象
前文提到DDD要解决的一个重要问题就是对象的失血问题,即对象不能仅作为数据的载体而没有行为,如上文代码中的参数校验应该是其自身的行为而非外部进行校验,通过适配器转换为内部对象就可以完成自身参数校验的行为,代码如下所示:
public class CreateOrderRequest extends CommonRequest {讯享网private List<SolutionOfferPair> outSolutionOfferPairList; private List<SolutionOfferPair> returnSolutionOfferPairList; private String transactionNo; ... private Contact contact; private List<Passenger> passengerInfoList; private boolean isSplitOrder; private boolean randomAssigned; private List<ExtraInfo> extraInfos; @Override public void requestCheck() { if (StringUtils.isEmpty(splitPlanId) && CollectionUtil.isEmpty(outSolutionOfferPairList)) { throw new BusinessException(ResponseCodeEnum.PARAM_ERROR); } ... }
}4.3 战术设计实现
本文以订单聚合根为例具体说明战术设计的实现。
聚合根
聚合根中包含了实体和值对象,同时聚合根与仅有getter、setter的业务对象不同,其将业务逻辑也封装在内,提高了内聚性,同时将仓储封装在内,为聚合根提供持久化操作。
public class P2pOrder {讯享网private P2pOrderRepository repository; @Getter private long orderId; @Getter private OrderMasterModel orderMasterModel; @Getter private List<OrderItemModel> orderItemModels; public P2pOrder(P2pOrderRepository repository, long orderId) { this.repository = repository; this.orderId = orderId; orderInfoModel = new OrderInfoModel(); orderItemModels = new ArrayList<>(); } public boolean find() { return repository.find(this); } public void createOrder(CreateOrderRequest request) { if (find()) { throw new BusinessException(ResponseCodeEnum.ORDER_EXISTED); } this.orderMasterModel.createOrderMaster(request); repository.createP2pOrder(this); // 发送超时支付取消消息 pushDelayMessage(this); }
}实体
实体是指会存在状态变更的类,比如order,其可以提供订单的变更状态等。
@Getter public class OrderMasterModel {讯享网private OrderStatusEnum orderStatus; private LocalDateTime ticketTime; private LocalDateTime expirationTime; private String lang; ... public void init(CreateOrderRequest request) { this.channelName = request.getChannelMetaInfo().getChannel(); this.orderStatus = OrderStatusEnum.SEAT_BOOKING; ... } public void ticketing() { if (this.orderStatus != OrderStatusEnum.WAIT_FOR_PAY) { throw new BusinessException(ResponseCodeEnum.ORDER_STATUS_ERROR); } this.orderStatus = OrderStatusEnum.TICKETING; }
}值对象
而值对象是指仅作为描述没有唯一标识的类,比如行程信息,行程信息变更应该是整个行程信息进行变更而不是提供方法进行修改,故本文针对值对象的构造方法进行私有化处理,并仅提供静态方法用于重新创建对象。
@Getter public class OrderSegmentModel {讯享网private long orderSegmentId; private short sequence; private TravelTypeEnum direction; private String segmentType; private String departureLocationCode; private String departureLocationName; private String arriveLocationCode; private String arriveLocationName; ... private OrderSegmentModel() {} public static OrderSegmentModel init(OrderSegment orderSegment, short sequence) { OrderSegmentModel model = new OrderSegmentModel(); model.orderSegmentId = Long.valueOf(orderFareId + "0" + orderSegment.getSegmentId()); model.sequence = sequence; if (Objects.nonNull(orderSegment.getDepartureLocation())) { model.departureLocationCode = orderSegment.getDepartureLocation().getLocationCode(); model.departureLocationName = ConvertUtil.getLocationName(orderSegment.getDepartureLocation()); } if (Objects.nonNull(orderSegment.getArrivalLocation())) { model.arriveLocationCode = orderSegment.getArrivalLocation().getLocationCode(); model.arriveLocationName = ConvertUtil.getLocationName(orderSegment.getArrivalLocation()); } model.departureTime = DateUtil.parseStringToDateTime(orderSegment.getDepartureDateTime(), DateUtil.YYYY_MM_DDHHmm); model.arriveTime = DateUtil.parseStringToDateTime(orderSegment.getArrivalDateTime(), DateUtil.YYYY_MM_DDHHmm); ... return model; }</code></pre></div><p data-pid="OFIGy7zB"><b>仓储</b></p><p data-pid="EEfHKA0n">仓储封装于聚合根内部,不用于外部调用,故通过工厂方法将仓储注入聚合根中。</p><div class="highlight"><pre><code class="language-text">@Slf4j
@Component public class OrderFactory { @Autowired private OrderIdGenerator orderIdGenerator; @Autowired private P2pOrderRepository repository; public P2pOrder create(CreateOrderRequest request) { long orderId = orderIdGenerator.generateOrderId(); if (orderId < 1) { log.error("fail to gen order id"); throw new BusinessException(ResponseCodeEnum.FAIL_GEN_ORDER_ID); } return new P2pOrder(repository, orderId); }
}仓储用于链接领域层与数据层,使领域对象与DAO隔离,使我们软件更加健壮。
讯享网@Slf4j @Component public class P2pOrderRepositoryImpl implements P2pOrderRepository {@Autowired private OrderMapper orderMapper; @Override public boolean createP2pOrder(P2pOrder p2pOrder) { OrderMasterEntity orderMasterEntity = new OrderMasterEntity; orderMasterEntity.setOrderId(p2pOrder.getOrderId()); orderMasterEntity.setOrderStatus( p2pOrder.getOrderMasterModel().getOrderStatus().getCode()); ... return orderMapper.insert(orderMasterEntity) > 0; }
}
防腐层
防腐层,又称为适配层,在对外部上下文的访问中,就需要引入防腐层对外部上下文进行一次转义,这样就可以将外部上下文转化为内部模型,防止因为外部更改导致改动影响过大。仓储也是防腐层的一种,因为其隔离了数据库的DAO对象,转化为了内部的实体和值对象。在本系统中,也需要对外部的汇率服务、保险服务等引入防腐层的概念。
4.4 服务结构
通过DDD思想进行建模,并采用DDD的六边形架构,重构后的服务结构如下:
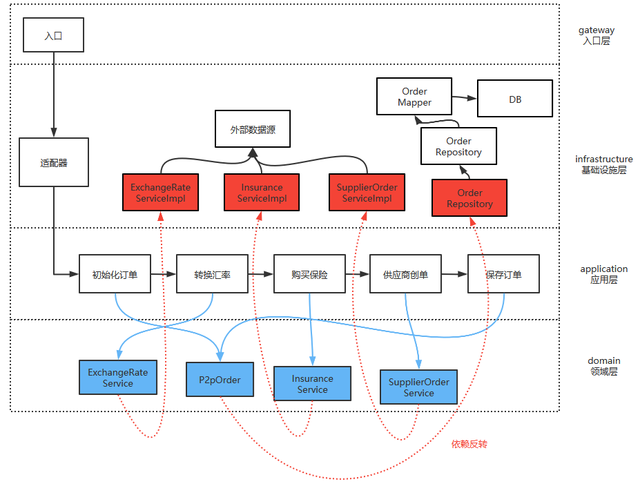
本文基于携程国际火车票出票系统对领域驱动设计进行实践,通过对出票系统中多个领域的划分使业务逻辑更加清晰,使得代码易于维护和迭代;并通过领域驱动设计的六边形架构将业务与技术进行了隔离,突出业务重点,使代码易于阅读;加入防腐层使外部上下文与内部模型进行隔离,防止外部对象侵蚀;将迭代需求转化为各个领域模型的更新,以领域来驱动后续功能开发,使其变得可控,避免了软件架构设计模式变成“大泥球”模式。
鉴于作者经验有限,对领域驱动的理解难免会有不足之处,欢迎大家共同探讨,共同提高。
参考文献
[1] Scott Millett 等著, 蒲成 译; 领域驱动设计模式、原理与实践(Patterns, Principles, and Practices of Domain-Driven Design); 清华大学出版社, 2016
[2] Evic Evans 著, 赵俐 等译; 领域驱动设计:软件核心复杂性应对之道; 人民邮电出版社, 2010
[3] 领域驱动设计在互联网业务开发中的实践
[4] 阿里技术专家详解DDD系列 第二讲 - 应用架构
[5] 基于 DDD 思想的酒店报价重构实践
[6] DDD(领域驱动设计)总结
[7] 谈谈MVC模式
[8] 阿里技术专家详解DDD系列 第三讲 - Repository模式
[9] 领域驱动设计详解:是什么、为什么、怎么做?
[10] 领域建模在有赞客户领域的实践
[11] DDD分层架构的三种模式
团队招聘信息
我们是携程火车票研发团队,负责火车票业务的开发以及创新。火车票研发在多种交通线路联程联运算法、多种交通工具一站式预定、高并发方向不断地深入探索和创新,持续优化用户体验,提高效率,致力于为全球人民买全球火车票。
在火车票研发团队,你可以和众多技术大牛一起,真实地让亿万用户享受你的产品和代码,提升全球旅行者出行体验和幸福指数。
如果你也热爱技术,并渴望不断成长,火车票研发团队期待与你一起高速前行。目前我们前端、后台、算法、大数据、测试等技术岗位均有职位。
简历投递: 邮件标题:【姓名】-【携程火车票】-【投递职位】
【作者简介】Ma Ning,携程国际火车票后端开发工程师,关注系统架构、微服务、高可用等技术领域。
COLA 是 Clean Object-Oriented and Layered Architecture的缩写,代表“整洁面向对象分层架构”,是来自阿里技术专家的开源项目。目前COLA已经发展到COLA 4.0。
COLA既是架构,也是框架。COLA框架继承了DDD的设计思想。
COLA 开源地址:https://github.com/alibaba/COLA
在架构设计上,COLA主张像六边形架构那样,使用端口-适配器去解耦技术细节;主张像洋葱架构那样,以领域为核心,并通过依赖倒置反转领域层的依赖方向。
从COLA应用处理响应一个请求的过程来看,COLA使用了CQRS来分离命令和查询的职责,使用扩展点和元数据来提供更高应用的可扩展性。
下图是COLA架构示意图,供参考:
COLA架构的核心职责就是定义良好的应用结构,提供**应用架构的**实践。通过不断探索,发现良好的分层结构,良好的包结构定义,可以帮助我们治理和应对复杂的业务逻辑。
是因为开源COLA应用中还提供了一些非常有用的通用组件,这些组件可以帮助我们提升研发效率。
这些功能组件被收拢在cola-components目录下面。
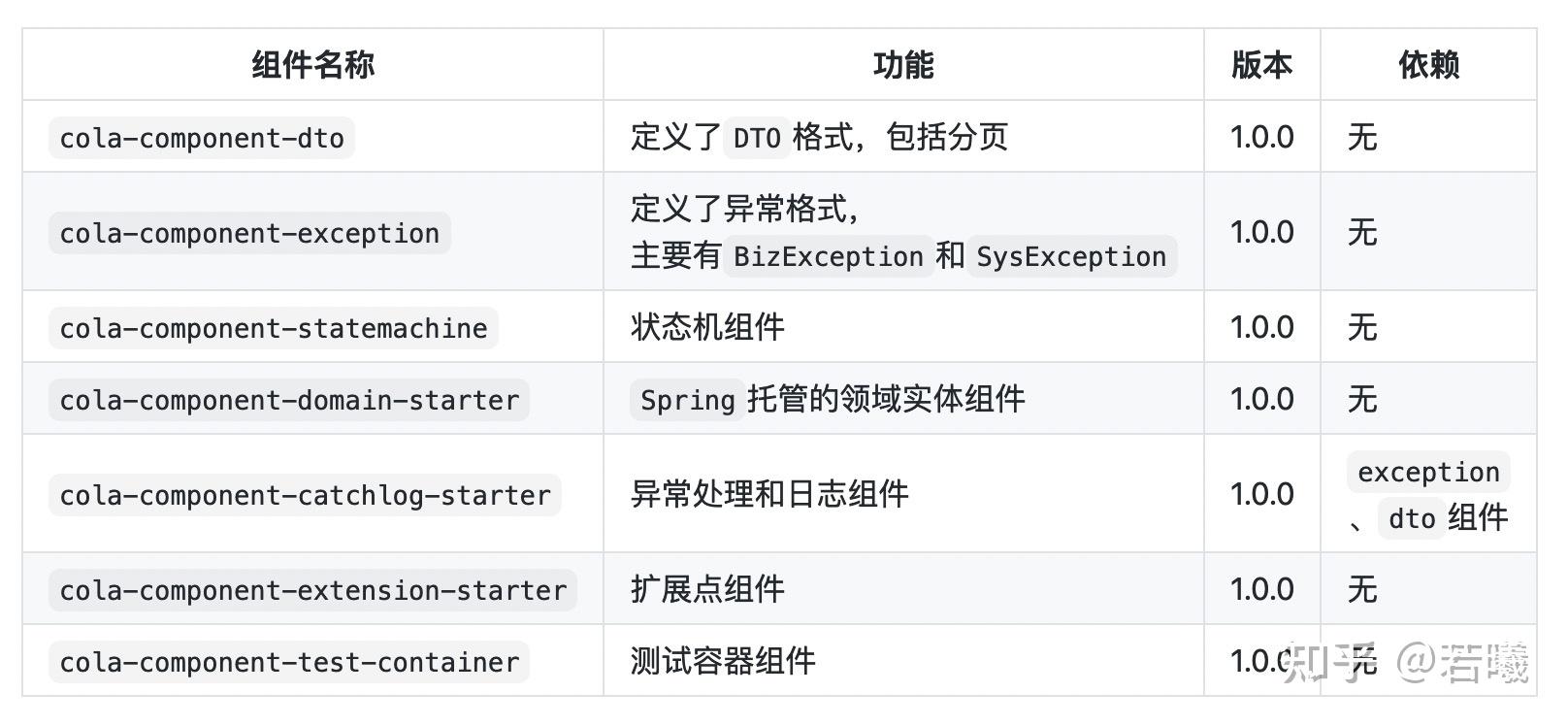
下图是基于COLA 架构建的DDD经典示例应用-货物运输系统(Cargo Tracker Application)的代码结构:
《COLA 4.x架构入门和项目实践》技术专栏详细讲解COLA架构的使用,领域驱动设计DDD中领域模型的开发,以及DDD经典示例项目-货物运输系统(Cargo Tracker Application)代码实现细节。

学习如何在Go应用程序中使用DDD的简单方法。
在本文,我将从头开始构建一个在线酒店应用来一步步地探索DDD的各种概念。希望每实现一部分,对理解DDD会更容易。采用这种方法的原因是,每次我在阅读DDD资料时都很头疼。有这么多的概念,很宽泛和不清楚,不清楚什么是什么。如果你不知道为什么我在研究DDD时头疼,下面的图可能会让你认识到这一点。
从上面的图片可以看得出来,为什么Eric Evans在他的《领域驱动设计:解决软件核心的复杂性》要用500页来解释什么是领域驱动设计。如果你对学习DDD有兴趣可以阅读本书。
首先,我想指出的是,本文描述了我对DDD的理解,我在本文中展示的实现是基于我对go相关项目的经验得出的**实践。我们将创建的实现绝不是社区所接受的**实践。我还将在项目中以DDD方法命名文件夹,以使其易于理解,但我不确定这是否是我想要的代码框架的样子。基于此,我将创建另一个分支来修正代码结构,这个重构将在其他文章解释。
我在网上看到很多关于DDD和如何正确实现的激烈讨论。让我印象深刻的是,多数时候人们似乎忘记了DDD背后的目的,都以讨论一些小的实现细节而告终。我认为重要的是遵循Evan提出的方法,而不是命名为X或Y。
DDD是一个很大的领域,我们将主要关注它的实现,但在我们实现任何东西之前,我将对DDD中的一些概念做一个快速的概述。
领域驱动设计是在软件所属领域之后对软件进行结构化和建模的一种方法。这意味着必须首先考虑所编写的软件的领域。领域是软件将处理的主题或问题。软件的编写应该反映该领域。
DDD主张工程团队必须与主题专家(SME)交谈,他们是领域内的专家。这样做的原因是SME拥有关于领域的知识,这些知识应该反映在软件中。想想看,如果我要做一个股票交易平台,作为一名工程师,我对这个领域的了解够不够去做一个好的股票交易平台?如果我能和沃伦·巴菲特谈谈这个领域,这个平台可能会好得多。
代码中的架构也应该反映领域。当我们开始编写我们的酒店应用时,我们将体会到领域内涵。
让我们开始学习如何实现DDD,在开始之前我将给你讲述一个Gopher和Dante的故事,他们想创建一个在线酒店应用。Dante知道如何写代码,但是对如何运营一个酒店一无所知。
在Dante决定开始创建酒店应用的那天,他遇到了一个问题,从哪里开始,如何开始?他出去散步,思考这个问题。在公交站标志前等待的时候,一个戴大礼帽的男人走近Dante说:
“看起来你好像在担心什么事情,年轻人,需要帮忙建一个酒店应用吗?”
Dante和大礼帽男一起散步,他们讨论了酒店以及如何经营。Dante问如何处理酒徒(drinker),大礼帽男纠正说是客户(Customer)不是酒徒(drinker)。大礼帽男还向Dante解释了酒店还需要一些东西来运作,比如顾客、员工、银行和供应商。
我希望你们喜欢Dante的故事,我写它是有原因的。我们可以用这个故事来解释DDD中使用的一些概念,这些词如果没有上下文很难解释,比如一个短篇故事。
Dante和大礼帽男已经讨论了一个领域模型会话。大礼帽男作为该方面的专家而Dante作为工程师讨论了领域空间并找到了共同点。这样做是为了学习模型,模型是处理领域所需组件的抽象。当Dante和大礼帽男在讨论酒店,他们正是在讨论相关领域。该领域是软件运行的关注点,我将把酒店(Tavern)称为核心/根领域。
大礼帽男还指出,它不叫饮酒徒,而叫顾客。这说明了在SMO和开发人员之间找到一种通用语言是多么重要。如果不是项目中的每个人都有通用语言,那将会非常令人困惑。我们还得到了一些子领域,这是大礼帽男提到的酒店应用所需要的东西。子领域是一个单独的领域,用于解决根领域内的相关东西。

我们已经了解了酒店应用的相关东西,是时候编写酒店系统代码了。通过创建go module来配制本项目。
讯享网mkdir ddd-go go mod init github.com/percybolmer/ddd-go
我们将创建一个domain目录,存放所有的子领域,但在实现领域之前,我们需要在根目录下创建另一个目录。出于说明的目的,我们将其命名为entity,因为它将保存DDD方法中所谓的实体。一个实体是一个结构体包含标志符,其状态可能会变,改变状态的意思是实体的值可以改变。
首先我们将创建两个实体,Person和Item。我喜欢将实体保存在一个单独的包中,以便它们可以被所有其他领域使用。

为了保持代码整洁,我喜欢小文件,并使文件夹结构易于浏览。因此,我建议创建两个文件,每个文件对应一个实体,并以实体命名。现在,仅仅包含结构体定义,稍后会添加一些其他逻辑。
为领域创建第一个实体
//entities包保存所有子领域共享的所有实体 package entityimport ( 讯享网<span class="s">"github.com/google/uuid"</span>
) // Person 在所有领域中代表人 type Person struct { <span class="c1">// ID是实体的标识符,该ID为所有子领域共享
ID uuid.UUID json:"id" bson:"id" 讯享网<span class="c1">//Name就是人的名字
Name string json:"name" bson:"name" <span class="c1">// 人的年龄
Age int json:"age" name:"age" } package entity import ”github.com/google/uuid“ // Item表示所有子领域的Item type Item struct { 讯享网<span class="nx">ID</span> <span class="nx">uuid</span><span class="p">.</span><span class="nx">UUID</span> <span class="s">`json:"id" bson:"id"`</span> <span class="nx">Name</span> <span class="kt">string</span> <span class="s">`json:"name" bson:"name"`</span> <span class="nx">Description</span> <span class="kt">string</span> <span class="s">`json:"description" bson:"description"`</span>
} ok,现在我们已经定义了一些实体并了解了什么是实体。一个结构体具有唯一标识符来引用,状态可变。
有些结构体是不可变的,不需要唯一标识符,这些结构体被称为值对象。所以结构体在创建后没有标识符和持久化值。值对象通常位于领域内,用于描述该领域中的某些方面。我们现在将创建一个值对象,它是Transaction,一旦事务被执行,它就不能改变状态。
在真实的应用程序中,通过ID跟踪事务是一个好主意,这里只是为了演示
package valueobjectimport ( 讯享网<span class="s">"time"</span>
) // Transaction表示双方用于支付 type Transaction struct { <span class="nx">Amount</span> <span class="kt">int</span> <span class="s">`json:"amount" bson:"amount"`</span> <span class="nx">From</span> <span class="nx">uuid</span><span class="p">.</span><span class="nx">UUID</span> <span class="s">`json:"from" bson:"from"`</span> <span class="nx">To</span> <span class="nx">uuid</span><span class="p">.</span><span class="nx">UUID</span> <span class="s">`json:"to" bson:"to"`</span> <span class="nx">CreatedAt</span> <span class="nx">time</span><span class="p">.</span><span class="nx">Time</span> <span class="s">`json:"createdAt" bson:"createdAt"`</span>
} 
现在我们来看看DDD的下一个组件,聚合。聚合是一组实体和值对象的组合。因此,在本例中,我们可以首先创建一个新的聚合,即Customer。
DDD聚合是领域概念(例如订单、诊所访问、播放列表)——Martin Fowler
聚合(aggregate)的原因是业务逻辑将应用于Customer聚合,而不是每个持有该逻辑的实体。聚合不允许直接访问底层实体。在现实生活中,也经常需要多个实体来正确表示数据,例如Customer。它是一个Person,但是他/她可以持有Products并执行事务。
DDD聚合中的一个重要规则是,它们应该只有一个实体作为根实体。这意味着根实体的引用也用于引用聚合。对于我们的customer聚合,这意味着Person ID是惟一标识符。
让我们创建一个aggregate文件夹,然后在里面创建一个名为customer.go的文件。
讯享网mkdir aggregate cd aggregate touch customer.go
在该文件中,我们将添加一个名为Customer的新结构,它将包含表示Customer所需的所有实体。注意,所有字段都以大写字母开头,这在Go中使它们可以从包外部访问。这与我们所说的聚合不允许访问底层实体的说法相违背,但是我们需要它来使聚合可序列化。另一种方法是添加自定义序列化,但我发现有时跳过一些规则是有意义的。
// Package aggregates holds aggregates that combines many entities into a full object package aggregateimport ( 讯享网<span class="s">"github.com/percybolmer/ddd-go/entity"</span> <span class="s">"github.com/percybolmer/ddd-go/valueobject"</span>
) // Customer 聚合包含了代表一个客户所需的所有实体 type Customer struct { <span class="c1">// Person是客户的根实体
// person.ID是聚合的主标识符 Person *entity.Person bson:"person" 讯享网<span class="c1">//一个客户可以持有许多产品
Products []*entity.Item bson:"products" <span class="c1">// 一个客户可以执行许多事务
Transactions []valueobject.Transaction bson:"transactions" } 我将所有实体设置为指针,这是因为实体可以改变状态,我想让它反映在运行时所有访问它的实例中。值对象被保存为非指针,因为它们不能改变状态。

到目前为止,我们只定义了不同的实体、值对象和聚合。现在开始实现一些实际业务逻辑,我们从工厂函数开始。工厂模式是一种设计模式,用于在创建所需实例的函数中封装复杂逻辑,调用者不知道任何实现细节。
工厂模式是一种非常常见的模式,您甚至可以在DDD应用程序之外使用它,而且您可能已经使用过很多次了。官方Go Elasticsearch客户端就是一个很好的例子。您将一个配置传入到NewClient函数中,该函数是一个工厂函数,返回客户端连接到弹性集群,可以插入/删除文档。对于其他开发人员来说很容易使用,在NewClient中做了很多事情:
讯享网func NewClient(cfg Config) (*Client, error) {<span class="kd">var</span> <span class="nx">addrs</span> <span class="p">[]</span><span class="kt">string</span> <span class="k">if</span> <span class="nb">len</span><span class="p">(</span><span class="nx">cfg</span><span class="p">.</span><span class="nx">Addresses</span><span class="p">)</span> <span class="o">==</span> <span class="mi">0</span> <span class="o">&&</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">CloudID</span> <span class="o">==</span> <span class="s">""</span> <span class="p">{</span> <span class="nx">addrs</span> <span class="p">=</span> <span class="nf">addrsFromEnvironment</span><span class="p">()</span> <span class="p">}</span> <span class="k">else</span> <span class="p">{</span> <span class="k">if</span> <span class="nb">len</span><span class="p">(</span><span class="nx">cfg</span><span class="p">.</span><span class="nx">Addresses</span><span class="p">)</span> <span class="p">></span> <span class="mi">0</span> <span class="o">&&</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">CloudID</span> <span class="o">!=</span> <span class="s">""</span> <span class="p">{</span> <span class="k">return</span> <span class="kc">nil</span><span class="p">,</span> <span class="nx">errors</span><span class="p">.</span><span class="nf">New</span><span class="p">(</span><span class="s">"cannot create client: both Addresses and CloudID are set"</span><span class="p">)</span> <span class="p">}</span> <span class="k">if</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">CloudID</span> <span class="o">!=</span> <span class="s">""</span> <span class="p">{</span> <span class="nx">cloudAddr</span><span class="p">,</span> <span class="nx">err</span> <span class="o">:=</span> <span class="nf">addrFromCloudID</span><span class="p">(</span><span class="nx">cfg</span><span class="p">.</span><span class="nx">CloudID</span><span class="p">)</span> <span class="k">if</span> <span class="nx">err</span> <span class="o">!=</span> <span class="kc">nil</span> <span class="p">{</span> <span class="k">return</span> <span class="kc">nil</span><span class="p">,</span> <span class="nx">fmt</span><span class="p">.</span><span class="nf">Errorf</span><span class="p">(</span><span class="s">"cannot create client: cannot parse CloudID: %s"</span><span class="p">,</span> <span class="nx">err</span><span class="p">)</span> <span class="p">}</span> <span class="nx">addrs</span> <span class="p">=</span> <span class="nb">append</span><span class="p">(</span><span class="nx">addrs</span><span class="p">,</span> <span class="nx">cloudAddr</span><span class="p">)</span> <span class="p">}</span> <span class="k">if</span> <span class="nb">len</span><span class="p">(</span><span class="nx">cfg</span><span class="p">.</span><span class="nx">Addresses</span><span class="p">)</span> <span class="p">></span> <span class="mi">0</span> <span class="p">{</span> <span class="nx">addrs</span> <span class="p">=</span> <span class="nb">append</span><span class="p">(</span><span class="nx">addrs</span><span class="p">,</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">Addresses</span><span class="o">...</span><span class="p">)</span> <span class="p">}</span> <span class="p">}</span> <span class="nx">urls</span><span class="p">,</span> <span class="nx">err</span> <span class="o">:=</span> <span class="nf">addrsToURLs</span><span class="p">(</span><span class="nx">addrs</span><span class="p">)</span> <span class="k">if</span> <span class="nx">err</span> <span class="o">!=</span> <span class="kc">nil</span> <span class="p">{</span> <span class="k">return</span> <span class="kc">nil</span><span class="p">,</span> <span class="nx">fmt</span><span class="p">.</span><span class="nf">Errorf</span><span class="p">(</span><span class="s">"cannot create client: %s"</span><span class="p">,</span> <span class="nx">err</span><span class="p">)</span> <span class="p">}</span> <span class="k">if</span> <span class="nb">len</span><span class="p">(</span><span class="nx">urls</span><span class="p">)</span> <span class="o">==</span> <span class="mi">0</span> <span class="p">{</span> <span class="nx">u</span><span class="p">,</span> <span class="nx">_</span> <span class="o">:=</span> <span class="nx">url</span><span class="p">.</span><span class="nf">Parse</span><span class="p">(</span><span class="nx">defaultURL</span><span class="p">)</span> <span class="c1">// errcheck exclude
urls = append(urls, u) 讯享网<span class="p">}</span> <span class="c1">// TODO(karmi): Refactor
if urls[0].User != nil { <span class="nx">cfg</span><span class="p">.</span><span class="nx">Username</span> <span class="p">=</span> <span class="nx">urls</span><span class="p">[</span><span class="mi">0</span><span class="p">].</span><span class="nx">User</span><span class="p">.</span><span class="nf">Username</span><span class="p">()</span> <span class="nx">pw</span><span class="p">,</span> <span class="nx">_</span> <span class="o">:=</span> <span class="nx">urls</span><span class="p">[</span><span class="mi">0</span><span class="p">].</span><span class="nx">User</span><span class="p">.</span><span class="nf">Password</span><span class="p">()</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">Password</span> <span class="p">=</span> <span class="nx">pw</span> <span class="p">}</span> <span class="nx">tp</span><span class="p">,</span> <span class="nx">err</span> <span class="o">:=</span> <span class="nx">estransport</span><span class="p">.</span><span class="nf">New</span><span class="p">(</span><span class="nx">estransport</span><span class="p">.</span><span class="nx">Config</span><span class="p">{</span> <span class="nx">URLs</span><span class="p">:</span> <span class="nx">urls</span><span class="p">,</span> <span class="nx">Username</span><span class="p">:</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">Username</span><span class="p">,</span> <span class="nx">Password</span><span class="p">:</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">Password</span><span class="p">,</span> <span class="nx">APIKey</span><span class="p">:</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">APIKey</span><span class="p">,</span> <span class="nx">ServiceToken</span><span class="p">:</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">ServiceToken</span><span class="p">,</span> <span class="nx">Header</span><span class="p">:</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">Header</span><span class="p">,</span> <span class="nx">CACert</span><span class="p">:</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">CACert</span><span class="p">,</span> <span class="nx">RetryOnStatus</span><span class="p">:</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">RetryOnStatus</span><span class="p">,</span> <span class="nx">DisableRetry</span><span class="p">:</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">DisableRetry</span><span class="p">,</span> <span class="nx">EnableRetryOnTimeout</span><span class="p">:</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">EnableRetryOnTimeout</span><span class="p">,</span> <span class="nx">MaxRetries</span><span class="p">:</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">MaxRetries</span><span class="p">,</span> <span class="nx">RetryBackoff</span><span class="p">:</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">RetryBackoff</span><span class="p">,</span> <span class="nx">CompressRequestBody</span><span class="p">:</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">CompressRequestBody</span><span class="p">,</span> <span class="nx">EnableMetrics</span><span class="p">:</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">EnableMetrics</span><span class="p">,</span> <span class="nx">EnableDebugLogger</span><span class="p">:</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">EnableDebugLogger</span><span class="p">,</span> <span class="nx">DisableMetaHeader</span><span class="p">:</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">DisableMetaHeader</span><span class="p">,</span> <span class="nx">DiscoverNodesInterval</span><span class="p">:</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">DiscoverNodesInterval</span><span class="p">,</span> <span class="nx">Transport</span><span class="p">:</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">Transport</span><span class="p">,</span> <span class="nx">Logger</span><span class="p">:</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">Logger</span><span class="p">,</span> <span class="nx">Selector</span><span class="p">:</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">Selector</span><span class="p">,</span> <span class="nx">ConnectionPoolFunc</span><span class="p">:</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">ConnectionPoolFunc</span><span class="p">,</span> <span class="p">})</span> <span class="k">if</span> <span class="nx">err</span> <span class="o">!=</span> <span class="kc">nil</span> <span class="p">{</span> <span class="k">return</span> <span class="kc">nil</span><span class="p">,</span> <span class="nx">fmt</span><span class="p">.</span><span class="nf">Errorf</span><span class="p">(</span><span class="s">"error creating transport: %s"</span><span class="p">,</span> <span class="nx">err</span><span class="p">)</span> <span class="p">}</span> <span class="nx">client</span> <span class="o">:=</span> <span class="o">&</span><span class="nx">Client</span><span class="p">{</span><span class="nx">Transport</span><span class="p">:</span> <span class="nx">tp</span><span class="p">}</span> <span class="nx">client</span><span class="p">.</span><span class="nx">API</span> <span class="p">=</span> <span class="nx">esapi</span><span class="p">.</span><span class="nf">New</span><span class="p">(</span><span class="nx">client</span><span class="p">)</span> <span class="k">if</span> <span class="nx">cfg</span><span class="p">.</span><span class="nx">DiscoverNodesOnStart</span> <span class="p">{</span> <span class="k">go</span> <span class="nx">client</span><span class="p">.</span><span class="nf">DiscoverNodes</span><span class="p">()</span> <span class="p">}</span> <span class="k">return</span> <span class="nx">client</span><span class="p">,</span> <span class="kc">nil</span>
}
DDD建议使用工厂来创建复杂的聚合、仓库和服务。我们将实现一个工厂函数,该函数将创建一个新的Customer实例。将创建一个名为NewCustomer的函数,它接受一个name参数,函数内部发生的事情不需要创建新customer的领域所知。
NewCustomer将验证输入是否包含创建Customer所需的所有参数:
在实际的应用程序中,我可能会建议在领域/客户中包含聚合的Customer和工厂。
讯享网package aggregateimport ( <span class="s">"errors"</span> <span class="s">"github.com/google/uuid"</span> <span class="s">"github.com/percybolmer/ddd-go/entity"</span> <span class="s">"github.com/percybolmer/ddd-go/valueobject"</span>
) var ( 讯享网<span class="c1">// 当person在newcustom工厂中无效时返回ErrInvalidPerson
ErrInvalidPerson = errors.New(”a customer has to have an valid person“) ) type Customer struct { <span class="c1">// Person是客户的根实体
// person.ID是aggregate的主标志符 Person *entity.Person bson:"person" 讯享网<span class="c1">// 一个客户可以持有许多产品
Products []*entity.Item bson:"products" <span class="c1">// 一个客户可以执行许多事务
Transactions []valueobject.Transaction bson:"transactions" } // NewCustomer是创建新的Customer聚合的工厂 // 它将验证名称是否为空 func NewCustomer(name string) (Customer, error) { 讯享网<span class="c1">// 验证Name不是空的
if name == ”“ { <span class="k">return</span> <span class="nx">Customer</span><span class="p">{},</span> <span class="nx">ErrInvalidPerson</span> <span class="p">}</span> <span class="c1">// 创建一个新person并生成ID
person := &entity.Person{ 讯享网 <span class="nx">Name</span><span class="p">:</span> <span class="nx">name</span><span class="p">,</span> <span class="nx">ID</span><span class="p">:</span> <span class="nx">uuid</span><span class="p">.</span><span class="nf">New</span><span class="p">(),</span> <span class="p">}</span> <span class="c1">// 创建一个customer对象并初始化所有的值以避免空指针异常
return Customer{ <span class="nx">Person</span><span class="p">:</span> <span class="nx">person</span><span class="p">,</span> <span class="nx">Products</span><span class="p">:</span> <span class="nb">make</span><span class="p">([]</span><span class="o">*</span><span class="nx">entity</span><span class="p">.</span><span class="nx">Item</span><span class="p">,</span> <span class="mi">0</span><span class="p">),</span> <span class="nx">Transactions</span><span class="p">:</span> <span class="nb">make</span><span class="p">([]</span><span class="nx">valueobject</span><span class="p">.</span><span class="nx">Transaction</span><span class="p">,</span> <span class="mi">0</span><span class="p">),</span> <span class="p">},</span> <span class="kc">nil</span>
}
讯享网package aggregate_testimport ( <span class="s">"testing"</span> <span class="s">"github.com/percybolmer/ddd-go/aggregate"</span>
) func TestCustomer_NewCustomer(t *testing.T) { 讯享网<span class="c1">// 构建我们需要的测试用例数据结构
type testCase struct { <span class="nx">test</span> <span class="kt">string</span> <span class="nx">name</span> <span class="kt">string</span> <span class="nx">expectedErr</span> <span class="kt">error</span> <span class="p">}</span> <span class="c1">//创建新的测试用例
testCases := []testCase{ 讯享网 <span class="p">{</span> <span class="nx">test</span><span class="p">:</span> <span class="s">"Empty Name validation"</span><span class="p">,</span> <span class="nx">name</span><span class="p">:</span> <span class="s">""</span><span class="p">,</span> <span class="nx">expectedErr</span><span class="p">:</span> <span class="nx">aggregate</span><span class="p">.</span><span class="nx">ErrInvalidPerson</span><span class="p">,</span> <span class="p">},</span> <span class="p">{</span> <span class="nx">test</span><span class="p">:</span> <span class="s">"Valid Name"</span><span class="p">,</span> <span class="nx">name</span><span class="p">:</span> <span class="s">"Percy Bolmer"</span><span class="p">,</span> <span class="nx">expectedErr</span><span class="p">:</span> <span class="kc">nil</span><span class="p">,</span> <span class="p">},</span> <span class="p">}</span> <span class="k">for</span> <span class="nx">_</span><span class="p">,</span> <span class="nx">tc</span> <span class="o">:=</span> <span class="k">range</span> <span class="nx">testCases</span> <span class="p">{</span> <span class="c1">// Run Tests
t.Run(tc.test, func(t *testing.T) { <span class="c1">//创建新的customer
_, err := aggregate.NewCustomer(tc.name) 讯享网 <span class="c1">//检查错误是否与预期的错误匹配
if err != tc.expectedErr { <span class="nx">t</span><span class="p">.</span><span class="nf">Errorf</span><span class="p">(</span><span class="s">"Expected error %v, got %v"</span><span class="p">,</span> <span class="nx">tc</span><span class="p">.</span><span class="nx">expectedErr</span><span class="p">,</span> <span class="nx">err</span><span class="p">)</span> <span class="p">}</span> <span class="p">})</span> <span class="p">}</span>
}
我们不会在创造新customer方面深入,现在开始寻找我所知道的**设计模式的时候了。
DDD描述了应该使用仓库来存储和管理聚合。这是其中一种模式,一旦我学会了,我就知道我永远不会停止使用它。这种模式依赖于通过接口隐藏存储/数据库解决方案的实现。这允许我们定义一组必须使用的方法,如果它们被实现了,就可以被用作一个仓库。
这种设计模式的优点是,它允许我们在不破坏任何东西的情况下切换解决方案。我们可以在开发阶段使用内存存储,然后在生产阶段将其切换到MongoDB存储。它不仅有助于在不破坏任何利用仓库的东西的情况下更改所使用的底层技术,而且在测试中也非常有用。您可以简单地为单元测试等实现一个新的仓库。
我们将首先创建一个名为repository的文件。进入domain/customer包。在该文件中,我们将定义仓库所需的函数。我们需要Get、Add和Update函数处理customers。我们不会删除任何客户,一旦有客户在酒店,就永远是客户。我们还将在客户包中实现一些通用错误,不同的仓库实现可以使用这些错误。
讯享网// Customer包保存了客户领域的所有域逻辑 import (<span class="s">"github.com/google/uuid"</span> <span class="s">"github.com/percybolmer/ddd-go/aggregate"</span>
) var ( 讯享网<span class="c1">// 当没有找到客户时返回ErrCustomerNotFound。
ErrCustomerNotFound = errors.New(”the customer was not found in the repository“) <span class="c1">// ErrFailedToAddCustomer在无法将客户添加到存储库时返回。
ErrFailedToAddCustomer = errors.New(”failed to add the customer to the repository“) 讯享网<span class="c1">// 当无法在存储库中更新客户时,将返回ErrUpdateCustomer。
ErrUpdateCustomer = errors.New(”failed to update the customer in the repository“) ) // CustomerRepository是一个接口,它定义了围绕客户仓库的规则 // 必须实现的函数 type CustomerRepository interface { <span class="nf">Get</span><span class="p">(</span><span class="nx">uuid</span><span class="p">.</span><span class="nx">UUID</span><span class="p">)</span> <span class="p">(</span><span class="nx">aggregate</span><span class="p">.</span><span class="nx">Customer</span><span class="p">,</span> <span class="kt">error</span><span class="p">)</span> <span class="nf">Add</span><span class="p">(</span><span class="nx">aggregate</span><span class="p">.</span><span class="nx">Customer</span><span class="p">)</span> <span class="kt">error</span> <span class="nf">Update</span><span class="p">(</span><span class="nx">aggregate</span><span class="p">.</span><span class="nx">Customer</span><span class="p">)</span> <span class="kt">error</span>
}
接下来,我们需要实现接口的实际业务逻辑,我们将从内存存储方式开始。在本文的最后,我们将了解如何在不破坏其他任何东西的情况下将其更改为MongoDB存储方案。
我喜欢将每个实现保存在它的目录中,只是为了让团队中的新开发人员更容易找到正确的代码位置。让我们创建一个名为memory的文件夹,表示仓库将内存用作存储。
另一种方式是在customer包中创建memory.go, 但我发现在更大的系统中,它会很快变得混乱
讯享网mkdir memory touch memory/memory.go
让我们首先在memory.go文件中设置正确的结构,我们希望创建一个具有实现CustomerRepository接口的结构,并且不要忘记创建新仓库的工厂函数。
// memory包是客户仓库的内存中实现 package memoryimport ( 讯享网<span class="s">"sync"</span> <span class="s">"github.com/google/uuid"</span> <span class="s">"github.com/percybolmer/ddd-go/aggregate"</span>
) // MemoryRepository实现了CustomerRepository接口 type MemoryRepository struct { <span class="nx">customers</span> <span class="kd">map</span><span class="p">[</span><span class="nx">uuid</span><span class="p">.</span><span class="nx">UUID</span><span class="p">]</span><span class="nx">aggregate</span><span class="p">.</span><span class="nx">Customer</span> <span class="nx">sync</span><span class="p">.</span><span class="nx">Mutex</span>
} // New是一个工厂函数,用于生成新的客户仓库 func New() *MemoryRepository { 讯享网<span class="k">return</span> <span class="o">&</span><span class="nx">MemoryRepository</span><span class="p">{</span> <span class="nx">customers</span><span class="p">:</span> <span class="nb">make</span><span class="p">(</span><span class="kd">map</span><span class="p">[</span><span class="nx">uuid</span><span class="p">.</span><span class="nx">UUID</span><span class="p">]</span><span class="nx">aggregate</span><span class="p">.</span><span class="nx">Customer</span><span class="p">),</span> <span class="p">}</span>
} // Get根据ID查找Customer func (mr *MemoryRepository) Get(uuid.UUID) (aggregate.Customer, error) { <span class="k">return</span> <span class="nx">aggregate</span><span class="p">.</span><span class="nx">Customer</span><span class="p">{},</span> <span class="kc">nil</span>
} // Add将向存储库添加一个新Customer func (mr *MemoryRepository) Add(aggregate.Customer) error { 讯享网<span class="k">return</span> <span class="kc">nil</span>
} // Update将用新的客户信息替换现有的Customer信息 func (mr *MemoryRepository) Update(aggregate.Customer) error { <span class="k">return</span> <span class="kc">nil</span>
} 我们需要添加一种从Customer聚合中检索信息的方法,例如来自根实体的ID。所以我们应该用一个获取ID的函数和一个更改名称的函数来更新聚合。
讯享网// GetID返回客户的根实体ID func (c *Customer) GetID() uuid.UUID {<span class="k">return</span> <span class="nx">c</span><span class="p">.</span><span class="nx">Person</span><span class="p">.</span><span class="nx">ID</span>
} // SetName更改客户的名称 func (c *Customer) SetName(name string) { 讯享网<span class="nx">c</span><span class="p">.</span><span class="nx">Person</span><span class="p">.</span><span class="nx">Name</span> <span class="p">=</span> <span class="nx">name</span>
}
让我们向内存仓库添加一些非常基本的功能,以便它能按预期工作。
// memory包是客户仓库的内存实现 package memoryimport ( 讯享网<span class="s">"fmt"</span> <span class="s">"sync"</span> <span class="s">"github.com/google/uuid"</span> <span class="s">"github.com/percybolmer/ddd-go/aggregate"</span> <span class="s">"github.com/percybolmer/ddd-go/domain/customer"</span>
) // MemoryRepository实现了CustomerRepository接口 type MemoryRepository struct { <span class="nx">customers</span> <span class="kd">map</span><span class="p">[</span><span class="nx">uuid</span><span class="p">.</span><span class="nx">UUID</span><span class="p">]</span><span class="nx">aggregate</span><span class="p">.</span><span class="nx">Customer</span> <span class="nx">sync</span><span class="p">.</span><span class="nx">Mutex</span>
} // New是一个工厂函数,用于生成新的客户存储库 func New() *MemoryRepository { 讯享网<span class="k">return</span> <span class="o">&</span><span class="nx">MemoryRepository</span><span class="p">{</span> <span class="nx">customers</span><span class="p">:</span> <span class="nb">make</span><span class="p">(</span><span class="kd">map</span><span class="p">[</span><span class="nx">uuid</span><span class="p">.</span><span class="nx">UUID</span><span class="p">]</span><span class="nx">aggregate</span><span class="p">.</span><span class="nx">Customer</span><span class="p">),</span> <span class="p">}</span>
} // Get根据ID查找Customer func (mr *MemoryRepository) Get(id uuid.UUID) (aggregate.Customer, error) { <span class="k">if</span> <span class="nx">customer</span><span class="p">,</span> <span class="nx">ok</span> <span class="o">:=</span> <span class="nx">mr</span><span class="p">.</span><span class="nx">customers</span><span class="p">[</span><span class="nx">id</span><span class="p">];</span> <span class="nx">ok</span> <span class="p">{</span> <span class="k">return</span> <span class="nx">customer</span><span class="p">,</span> <span class="kc">nil</span> <span class="p">}</span> <span class="k">return</span> <span class="nx">aggregate</span><span class="p">.</span><span class="nx">Customer</span><span class="p">{},</span> <span class="nx">customer</span><span class="p">.</span><span class="nx">ErrCustomerNotFound</span>
} // Add将向存储库添加一个新Customer func (mr *MemoryRepository) Add(c aggregate.Customer) error { 讯享网<span class="k">if</span> <span class="nx">mr</span><span class="p">.</span><span class="nx">customers</span> <span class="o">==</span> <span class="kc">nil</span> <span class="p">{</span> <span class="c1">// 安全检查如果Customer没创建,在使用工厂是不应该发生,但你永远不知道
mr.Lock() <span class="nx">mr</span><span class="p">.</span><span class="nx">customers</span> <span class="p">=</span> <span class="nb">make</span><span class="p">(</span><span class="kd">map</span><span class="p">[</span><span class="nx">uuid</span><span class="p">.</span><span class="nx">UUID</span><span class="p">]</span><span class="nx">aggregate</span><span class="p">.</span><span class="nx">Customer</span><span class="p">)</span> <span class="nx">mr</span><span class="p">.</span><span class="nf">Unlock</span><span class="p">()</span> <span class="p">}</span> <span class="c1">// 确保Customer不在仓库中
if _, ok := mr.customers[c.GetID()]; ok { 讯享网 <span class="k">return</span> <span class="nx">fmt</span><span class="p">.</span><span class="nf">Errorf</span><span class="p">(</span><span class="s">"customer already exists: %w"</span><span class="p">,</span> <span class="nx">customer</span><span class="p">.</span><span class="nx">ErrFailedToAddCustomer</span><span class="p">)</span> <span class="p">}</span> <span class="nx">mr</span><span class="p">.</span><span class="nf">Lock</span><span class="p">()</span> <span class="nx">mr</span><span class="p">.</span><span class="nx">customers</span><span class="p">[</span><span class="nx">c</span><span class="p">.</span><span class="nf">GetID</span><span class="p">()]</span> <span class="p">=</span> <span class="nx">c</span> <span class="nx">mr</span><span class="p">.</span><span class="nf">Unlock</span><span class="p">()</span> <span class="k">return</span> <span class="kc">nil</span>
} // Update 将用新的Customer信息替换现有Customer户信息 func (mr *MemoryRepository) Update(c aggregate.Customer) error { <span class="c1">// 确保Customer在存储库中
if _, ok := mr.customers[c.GetID()]; !ok { 讯享网 <span class="k">return</span> <span class="nx">fmt</span><span class="p">.</span><span class="nf">Errorf</span><span class="p">(</span><span class="s">"customer does not exist: %w"</span><span class="p">,</span> <span class="nx">customer</span><span class="p">.</span><span class="nx">ErrUpdateCustomer</span><span class="p">)</span> <span class="p">}</span> <span class="nx">mr</span><span class="p">.</span><span class="nf">Lock</span><span class="p">()</span> <span class="nx">mr</span><span class="p">.</span><span class="nx">customers</span><span class="p">[</span><span class="nx">c</span><span class="p">.</span><span class="nf">GetID</span><span class="p">()]</span> <span class="p">=</span> <span class="nx">c</span> <span class="nx">mr</span><span class="p">.</span><span class="nf">Unlock</span><span class="p">()</span> <span class="k">return</span> <span class="kc">nil</span>
} 和前面一样,我们应该为代码添加单元测试。我想从测试的角度指出仓库模式有多好。在单元测试中,使用仅为测试创建的仓库替换部分逻辑非常容易,这使得发现测试中的已知错误变得更加容易。
package memoryimport ( 讯享网<span class="s">"testing"</span> <span class="s">"github.com/google/uuid"</span> <span class="s">"github.com/percybolmer/ddd-go/aggregate"</span> <span class="s">"github.com/percybolmer/ddd-go/domain/customer"</span>
) func TestMemory_GetCustomer(t *testing.T) { <span class="kd">type</span> <span class="nx">testCase</span> <span class="kd">struct</span> <span class="p">{</span> <span class="nx">name</span> <span class="kt">string</span> <span class="nx">id</span> <span class="nx">uuid</span><span class="p">.</span><span class="nx">UUID</span> <span class="nx">expectedErr</span> <span class="kt">error</span> <span class="p">}</span> <span class="c1">//创建要添加到存储库中的模拟Customer
cust, err := aggregate.NewCustomer(”Percy“) 讯享网<span class="k">if</span> <span class="nx">err</span> <span class="o">!=</span> <span class="kc">nil</span> <span class="p">{</span> <span class="nx">t</span><span class="p">.</span><span class="nf">Fatal</span><span class="p">(</span><span class="nx">err</span><span class="p">)</span> <span class="p">}</span> <span class="nx">id</span> <span class="o">:=</span> <span class="nx">cust</span><span class="p">.</span><span class="nf">GetID</span><span class="p">()</span> <span class="c1">// 创建要使用的仓库,并添加一些测试数据进行测试
// 跳过工厂 repo := MemoryRepository{ <span class="nx">customers</span><span class="p">:</span> <span class="kd">map</span><span class="p">[</span><span class="nx">uuid</span><span class="p">.</span><span class="nx">UUID</span><span class="p">]</span><span class="nx">aggregate</span><span class="p">.</span><span class="nx">Customer</span><span class="p">{</span> <span class="nx">id</span><span class="p">:</span> <span class="nx">cust</span><span class="p">,</span> <span class="p">},</span> <span class="p">}</span> <span class="nx">testCases</span> <span class="o">:=</span> <span class="p">[]</span><span class="nx">testCase</span><span class="p">{</span> <span class="p">{</span> <span class="nx">name</span><span class="p">:</span> <span class="s">"No Customer By ID"</span><span class="p">,</span> <span class="nx">id</span><span class="p">:</span> <span class="nx">uuid</span><span class="p">.</span><span class="nf">MustParse</span><span class="p">(</span><span class="s">"f47ac10b-58cc-0372-8567-0e02b2c3d479"</span><span class="p">),</span> <span class="nx">expectedErr</span><span class="p">:</span> <span class="nx">customer</span><span class="p">.</span><span class="nx">ErrCustomerNotFound</span><span class="p">,</span> <span class="p">},</span> <span class="p">{</span> <span class="nx">name</span><span class="p">:</span> <span class="s">"Customer By ID"</span><span class="p">,</span> <span class="nx">id</span><span class="p">:</span> <span class="nx">id</span><span class="p">,</span> <span class="nx">expectedErr</span><span class="p">:</span> <span class="kc">nil</span><span class="p">,</span> <span class="p">},</span> <span class="p">}</span> <span class="k">for</span> <span class="nx">_</span><span class="p">,</span> <span class="nx">tc</span> <span class="o">:=</span> <span class="k">range</span> <span class="nx">testCases</span> <span class="p">{</span> <span class="nx">t</span><span class="p">.</span><span class="nf">Run</span><span class="p">(</span><span class="nx">tc</span><span class="p">.</span><span class="nx">name</span><span class="p">,</span> <span class="kd">func</span><span class="p">(</span><span class="nx">t</span> <span class="o">*</span><span class="nx">testing</span><span class="p">.</span><span class="nx">T</span><span class="p">)</span> <span class="p">{</span> <span class="nx">_</span><span class="p">,</span> <span class="nx">err</span> <span class="o">:=</span> <span class="nx">repo</span><span class="p">.</span><span class="nf">Get</span><span class="p">(</span><span class="nx">tc</span><span class="p">.</span><span class="nx">id</span><span class="p">)</span> <span class="k">if</span> <span class="nx">err</span> <span class="o">!=</span> <span class="nx">tc</span><span class="p">.</span><span class="nx">expectedErr</span> <span class="p">{</span> <span class="nx">t</span><span class="p">.</span><span class="nf">Errorf</span><span class="p">(</span><span class="s">"Expected error %v, got %v"</span><span class="p">,</span> <span class="nx">tc</span><span class="p">.</span><span class="nx">expectedErr</span><span class="p">,</span> <span class="nx">err</span><span class="p">)</span> <span class="p">}</span> <span class="p">})</span> <span class="p">}</span>
} func TestMemory_AddCustomer(t *testing.T) { 讯享网<span class="kd">type</span> <span class="nx">testCase</span> <span class="kd">struct</span> <span class="p">{</span> <span class="nx">name</span> <span class="kt">string</span> <span class="nx">cust</span> <span class="kt">string</span> <span class="nx">expectedErr</span> <span class="kt">error</span> <span class="p">}</span> <span class="nx">testCases</span> <span class="o">:=</span> <span class="p">[]</span><span class="nx">testCase</span><span class="p">{</span> <span class="p">{</span> <span class="nx">name</span><span class="p">:</span> <span class="s">"Add Customer"</span><span class="p">,</span> <span class="nx">cust</span><span class="p">:</span> <span class="s">"Percy"</span><span class="p">,</span> <span class="nx">expectedErr</span><span class="p">:</span> <span class="kc">nil</span><span class="p">,</span> <span class="p">},</span> <span class="p">}</span> <span class="k">for</span> <span class="nx">_</span><span class="p">,</span> <span class="nx">tc</span> <span class="o">:=</span> <span class="k">range</span> <span class="nx">testCases</span> <span class="p">{</span> <span class="nx">t</span><span class="p">.</span><span class="nf">Run</span><span class="p">(</span><span class="nx">tc</span><span class="p">.</span><span class="nx">name</span><span class="p">,</span> <span class="kd">func</span><span class="p">(</span><span class="nx">t</span> <span class="o">*</span><span class="nx">testing</span><span class="p">.</span><span class="nx">T</span><span class="p">)</span> <span class="p">{</span> <span class="nx">repo</span> <span class="o">:=</span> <span class="nx">MemoryRepository</span><span class="p">{</span> <span class="nx">customers</span><span class="p">:</span> <span class="kd">map</span><span class="p">[</span><span class="nx">uuid</span><span class="p">.</span><span class="nx">UUID</span><span class="p">]</span><span class="nx">aggregate</span><span class="p">.</span><span class="nx">Customer</span><span class="p">{},</span> <span class="p">}</span> <span class="nx">cust</span><span class="p">,</span> <span class="nx">err</span> <span class="o">:=</span> <span class="nx">aggregate</span><span class="p">.</span><span class="nf">NewCustomer</span><span class="p">(</span><span class="nx">tc</span><span class="p">.</span><span class="nx">cust</span><span class="p">)</span> <span class="k">if</span> <span class="nx">err</span> <span class="o">!=</span> <span class="kc">nil</span> <span class="p">{</span> <span class="nx">t</span><span class="p">.</span><span class="nf">Fatal</span><span class="p">(</span><span class="nx">err</span><span class="p">)</span> <span class="p">}</span> <span class="nx">err</span> <span class="p">=</span> <span class="nx">repo</span><span class="p">.</span><span class="nf">Add</span><span class="p">(</span><span class="nx">cust</span><span class="p">)</span> <span class="k">if</span> <span class="nx">err</span> <span class="o">!=</span> <span class="nx">tc</span><span class="p">.</span><span class="nx">expectedErr</span> <span class="p">{</span> <span class="nx">t</span><span class="p">.</span><span class="nf">Errorf</span><span class="p">(</span><span class="s">"Expected error %v, got %v"</span><span class="p">,</span> <span class="nx">tc</span><span class="p">.</span><span class="nx">expectedErr</span><span class="p">,</span> <span class="nx">err</span><span class="p">)</span> <span class="p">}</span> <span class="nx">found</span><span class="p">,</span> <span class="nx">err</span> <span class="o">:=</span> <span class="nx">repo</span><span class="p">.</span><span class="nf">Get</span><span class="p">(</span><span class="nx">cust</span><span class="p">.</span><span class="nf">GetID</span><span class="p">())</span> <span class="k">if</span> <span class="nx">err</span> <span class="o">!=</span> <span class="kc">nil</span> <span class="p">{</span> <span class="nx">t</span><span class="p">.</span><span class="nf">Fatal</span><span class="p">(</span><span class="nx">err</span><span class="p">)</span> <span class="p">}</span> <span class="k">if</span> <span class="nx">found</span><span class="p">.</span><span class="nf">GetID</span><span class="p">()</span> <span class="o">!=</span> <span class="nx">cust</span><span class="p">.</span><span class="nf">GetID</span><span class="p">()</span> <span class="p">{</span> <span class="nx">t</span><span class="p">.</span><span class="nf">Errorf</span><span class="p">(</span><span class="s">"Expected %v, got %v"</span><span class="p">,</span> <span class="nx">cust</span><span class="p">.</span><span class="nf">GetID</span><span class="p">(),</span> <span class="nx">found</span><span class="p">.</span><span class="nf">GetID</span><span class="p">())</span> <span class="p">}</span> <span class="p">})</span> <span class="p">}</span>
} 很好,我们有了第一个仓库。记住要保持仓库与它们的领域相关。在这种情况下,仓库只处理Customer聚合,它应该只这样做。永远不要让仓库与任何其他聚合耦合,我们想要松耦合。
那么我们如何处理酒店的逻辑流呢,我们不能简单地依赖客户仓库?我们将在某一点上开始耦合不同的仓库,并构建一个表示酒店逻辑的流。
进入Services,这是我们需要学习的最后一部分。
我们有这些实体,一个聚合,和一个仓库,但它还不像一个应用程序,不是吗?这就是为什么我们需要下一个组件Service。
Service将把所有松散耦合的仓库绑定到满足特定领域需求的业务逻辑中。在酒店应用中,我们可能有一个Order服务,负责将仓库链接在一起以执行订单。因此,服务将拥有对CustomerRepository和ProductRepository的访问权。
Service通常包含执行某个业务逻辑流(如Order、Api或Billing)所需的所有仓库。你甚至可以在一个服务中包含另一个服务。
我们将实现Order服务,它随后可以成为酒店(Tavern)服务的一部分。让我们创建一个名为services的新文件夹,该文件夹将保存我们实现的服务。我们首先创建一个名为order.go的文件将持有OrderService,我们将使用它来处理酒店中的新订单。我们仍然缺少一些领域,因此我们将只从CustomerRepository开始,但很快会添加更多领域。
我想从创建一个新的Service的Factory开始,并演示一个非常简单的技巧,这是我从Jon Calhoun的web开发书中学到的。我们将为一个函数创建一个别名,该函数接受一个Service指针并修改它,然后允许使用这些别名的可变参数。通过这种方式更改Service的行为或替换仓库非常容易。
// service包,包含将仓库连接到业务流的所有服务 package servicesimport ( 讯享网<span class="s">"github.com/percybolmer/ddd-go/domain/customer"</span>
) // OrderConfiguration是一个函数的别名,该函数将接受一个指向OrderService的指针并对其进行修改 type OrderConfiguration func(os *OrderService) error //OrderService是OrderService的一个实现 type OrderService struct { <span class="nx">customers</span> <span class="nx">customer</span><span class="p">.</span><span class="nx">CustomerRepository</span>
} // NewOrderService接受可变数量的OrderConfiguration函数,并返回一个新的OrderService // 将按照传入的顺序调用每个OrderConfiguration func NewOrderService(cfgs …OrderConfiguration) (*OrderService, error) { 讯享网<span class="c1">// 创建orderservice
os := &OrderService{} <span class="c1">// 应用所有传入的Configurations
for _, cfg := range cfgs { 讯享网 <span class="c1">// 将service传递到configuration函数
err := cfg(os) <span class="k">if</span> <span class="nx">err</span> <span class="o">!=</span> <span class="kc">nil</span> <span class="p">{</span> <span class="k">return</span> <span class="kc">nil</span><span class="p">,</span> <span class="nx">err</span> <span class="p">}</span> <span class="p">}</span> <span class="k">return</span> <span class="nx">os</span><span class="p">,</span> <span class="kc">nil</span>
} 看看我们如何在工厂方法中接受可变数量的OrderConfiguration?这是一种允许动态工厂,并允许开发人员配置代码结构的非常整洁的方法,前提是已经实现了相关函数。这个技巧对于单元测试非常有用,因为您可以用所需的仓库替换服务中的某些部分。
对于较小的服务,这种方法似乎有点复杂了。我想指出的是,在示例中,我们只使用configurations来修改仓库,但这也可以用于内部设置和选项。对于较小的服务,也可以创建一个简单的工厂函数,例如接受CustomerRepository。
让我们创建一个应用CustomerRepository的OrderConfiguration,这样我们就可以开始创建Order的业务逻辑。
讯享网// WithCustomerRepository将给定的客户仓库应用到OrderService func WithCustomerRepository(cr customer.CustomerRepository) OrderConfiguration {<span class="c1">// 返回一个与OrderConfiguration别名匹配的函数,
// 您需要返回这个,以便父函数可以接受所有需要的参数 return func(os *OrderService) error { 讯享网 <span class="nx">os</span><span class="p">.</span><span class="nx">customers</span> <span class="p">=</span> <span class="nx">cr</span> <span class="k">return</span> <span class="kc">nil</span> <span class="p">}</span>
} // WithMemoryCustomerRepository将内存客户仓库应用到OrderService func WithMemoryCustomerRepository() OrderConfiguration { <span class="c1">// 创建内存仓库,如果我们需要参数,如连接字符串,它们可以在这里输入
cr := memory.New() 讯享网<span class="k">return</span> <span class="nf">WithCustomerRepository</span><span class="p">(</span><span class="nx">cr</span><span class="p">)</span>
}
现在,要使用这个,您可以在创建服务时简单地链接所有configurations,从而使我们能够轻松地更换组件。
// 在开发中使用的内存示例 NewOrderService(WithMemoryCustomerRepository()) // 我们将来可以像这样切换到MongoDB NewOrderService(WithMongoCustomerRepository()) 让我们开始为Order服务添加功能,这样顾客就可以在酒店里购买东西。
讯享网// CreateOrder将所有仓库链接在一起,为客户创建订单 func (o *OrderService) CreateOrder(customerID uuid.UUID, productIDs []uuid.UUID) error {<span class="c1">// 获取customer
c, err := o.customers.Get(customerID) 讯享网<span class="k">if</span> <span class="nx">err</span> <span class="o">!=</span> <span class="kc">nil</span> <span class="p">{</span> <span class="k">return</span> <span class="nx">err</span> <span class="p">}</span> <span class="c1">// 获取每个产品,我们需要一个Product Repository
<span class="k">return</span> <span class="kc">nil</span>
}
哎呀,我们的酒店没有任何产品供应。你肯定知道怎么解决吧?让我们实现更多的仓库,并通过使用OrderConfiguration将它们应用到服务中。

可以参考customer Repository实现完成。
天的企业应用程序无疑是复杂的,并依赖一些专门技术(持久性,AJAX,Web服务等)来完成它们的工作。作为开发人员,我们倾向于关注这些技术细节是可以理解的。但事实是,一个不能解决业务需求的系统对任何人都没有用,无论它看起来多么漂亮或者如何很好地构建其基础设施。
领域驱动设计(DDD)的理念 - 首先由Eric Evans在他的同名书[1]中描述 - 是关于将我们的注意力放在应用程序的核心,关注业务领域固有的复杂性本身。我们还将核心域(业务独有)与支持子域(通常是通用的,如金钱或时间)区分开来,并将更多的设计工作放在核心上。
域驱动设计包含一组用于从域模型构建企业应用程序的模式。在您的软件生涯中,您可能已经遇到过许多这样的想法,特别是如果您是OO语言的经验丰富的开发人员。但将它们一起应用将允许您构建真正满足业务需求的系统。
在本文中,我将介绍DDD的一些主要模式,了解一些新手似乎很难解决的问题,并重点介绍一些工具和资源(特别是一个),以帮助您在工作中应用DDD。
使用DDD,我们希望创建问题域的模型。持久性,用户界面和消息传递的东西可以在以后出现,这是需要理解的领域,因为正在构建的系统中,可以区分公司的业务与竞争对手。(如果不是这样,那么考虑购买包装产品)。
按模型,我们不是指图表或一组图表;确定,图表很有用,但它们不是模型,只是模型的不同视图(参见图)。不,模型是我们选择在软件中实现的概念集,以代码和用于构建交付系统的任何其他软件工件表示。换句话说,代码就是模型。文本编辑器提供了一种使用此模型的方法,尽管现代工具也提供了大量其他可视化(UML类图,实体关系图,Spring beandocs [2],Struts / JSF流等)。
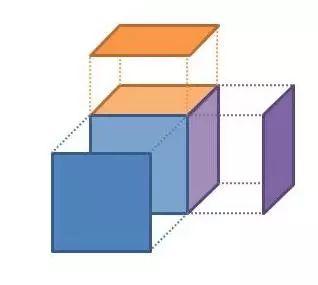
Figure 1: Model vs Views of the Model
这是DDD模式的第一个:模型驱动设计。这意味着能够将模型中的概念映射到设计/代码的概念(理想情况下)。模型的变化意味着代码的变化;更改代码意味着模型已更改。DDD并没有强制要求您使用面向对象来构建域 - 例如,我们可以使用规则引擎构建模型 - 但鉴于主流企业编程语言是基于OO的,大多数模型本质上都是OO。毕竟,OO基于建模范例。模型的概念将表示为类和接口,职责作为类成员。
现在让我们看一下域驱动设计的另一个基本原则。回顾一下:我们想要构建一个捕获正在构建的系统的问题域的域模型,并且我们将在代码/软件工件中表达这种理解。为了帮助我们做到这一点,DDD提倡领域专家和开发人员有意识地使用模型中的概念进行沟通。因此,域专家不会根据屏幕或菜单项上的字段描述新的用户故事,而是讨论域对象所需的基础属性或行为。类似地,开发人员不会讨论数据库表中的类或列的新实例变量。
严格要求我们开发一种无处不在的语言。如果一个想法不能轻易表达,那么它表明了一个概念,这个概念在领域模型中缺失,并且团队共同努力找出缺失的概念是什么。一旦建立了这个,那么数据库表中的屏幕或列上的新字段就会继续显示。
像DDD一样,这种开发无处不在的语言的想法并不是一个新想法:XPers称之为“名称系统”,多年来DBA将数据字典组合在一起。但无处不在的语言是一个令人回味的术语,可以出售给商业和技术人员。现在,“整个团队”敏捷实践正在成为主流,这也很有意义。
每当我们讨论模型时,它总是在某种情况下。通常可以从使用该系统的最终用户集推断出该上下文。因此,我们有一个部署到交易员的前台交易系统,或超市收银员使用的销售点系统。这些用户以特定方式与模型的概念相关,并且模型的术语对这些用户有意义,但不一定对该上下文之外的任何其他人有意义。DDD称之为有界上下文(BC)。每个域模型都只存在于一个BC中,而BC只包含一个域模型。
我必须承认,当我第一次读到关于BC时,我看不出这一点:如果BC与域模型同构,为什么要引入一个新术语?如果只有与BC相互作用的最终用户,则可能不需要这个术语。然而,不同的系统(BC)也相互交互,发送文件,传递消息,调用API等。如果我们知道有两个BC相互交互,那么我们知道我们必须注意在一个概念之间进行转换。领域和其他领域。
在模型周围设置明确的边界也意味着我们可以开始讨论这些BC之间的关系。实际上,DDD确定了BC之间的一整套关系,因此当我们需要将不同的BC链接在一起时,我们可以合理地确定应该做什么:
- 已发布的语言:交互式BCs就共同的语言(例如企业服务总线上的一堆XML模式)达成一致,通过它们可以相互交互;
- 开放主机服务:BC指定任何其他BC可以使用其服务的协议(例如RESTful Web服务);
- 共享内核:两个BC使用一个共同的代码内核(例如一个库)作为一个通用的通用语言,否则以他们自己的特定方式执行其他的东西;
- 消费者/提供者:一个BC使用另一个BC的服务,并且是另一个BC的利益相关者(客户)。因此,它可以影响该BC提供的服务;
- 顺从者:一个BC使用另一个BC的服务,但不是其他BC的利益相关者。因此,它使用“原样”(符合)BC提供的协议或API;
- 反腐败层:一个BC使用另一个服务并且不是利益相关者,但旨在通过引入一组适配器 - 一个反腐败层来最小化它所依赖的BC变化的影响。
你可以看到,在这个列表中,两个BC之间的合作水平逐渐降低(见图2)。使用已发布的语言,我们从BC建立一个他们可以互动的共同标准开始; 既不拥有这种语言,而是由他们所居住的企业所拥有(甚至可能是行业标准)。有了开放主机,我们仍然做得很好; BC提供其作为任何其他BC调用的运行时服务的功能,但是(可能)随着服务的发展将保持向后兼容性。
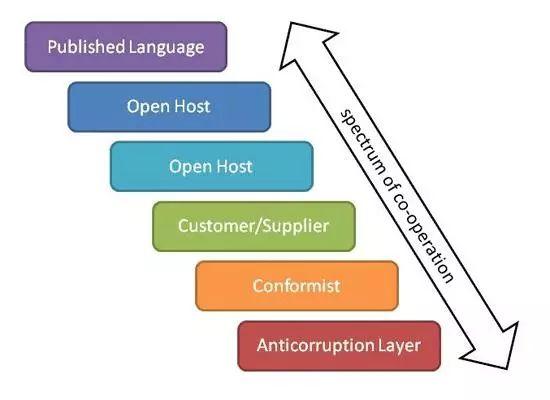
图2:有界上下文关系的光谱
然而,当我们走向顺从时,我们只是和我们一起生活; 一个BC明显屈服于另一个。如果我们必须与购买megabucks的总分类帐系统集成,那可能就是我们所处的情况。如果我们使用反腐败层,那么我们通常会与遗留系统集成,但是 额外的层将我们尽可能地隔离开来。当然,这需要花钱来实施,但它降低了依赖风险。反腐败层也比重新实现遗留系统便宜很多,这最多会分散我们对核心域的注意力,最坏的情况是以失败告终。
DDD建议我们制定一个背景图来识别我们的BC以及我们依赖或依赖的BC,以确定这些依赖关系的性质。图3显示了我过去5年左右一直在研究的系统的上下文映射。
Figure 3: Context Mapping Example
所有这些关于背景图和BC的讨论有时被称为战略性DDD,并且有充分的理由。毕竟,当你想到它时,弄清楚BC之间的关系是非常政治的:我的系统将依赖哪些上游系统,我是否容易与它们集成,我是否能够利用它们,我相信它们吗?下游也是如此:哪些系统将使用我的服务,我如何将我的功能作为服务公开,他们会对我有利吗?误解了这一点,您的应用程序可能很容易失败。
现在让我们转向内部并考虑我们自己的BC(系统)的架构。从根本上说,DDD只关心域层,实际上,它对其他层有很多话要说:表示,应用程序或基础架构(或持久层)。但它确实期望它们存在。这是分层架构模式(图4)。
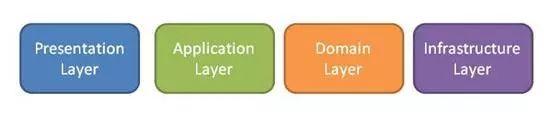
Figure 4: Layered Architecture
当然,我们多年来一直在构建多层系统,但这并不意味着我们必须擅长它。确实,过去的一些主流技术 - 是的,EJB 2,我正在看着你!- 对域模型可以作为有意义的层存在的想法产生了积极的影响。所有的业务逻辑似乎渗透到应用层或(更糟糕的)表示层,留下一组贫血的域类[3]作为数据持有者的空壳。这不是DDD的意思。
因此,要绝对清楚,应用程序层中不应存在任何域逻辑。相反,应用程序层负责事务管理和安全性等事务。在某些体系结构中,它还可能负责确保从基础结构/持久层中检索的域对象在与之交互之前已正确初始化(尽管我更喜欢基础结构层执行此操作)。
在表示层在单独的存储空间中运行的情况下,应用层也充当表示层和域层之间的中介。表示层通常处理域对象或域对象(数据传输对象或DTO)的可序列化表示,通常每个“视图”一个。如果这些被修改,那么表示层会将任何更改发送回应用程序层,而应用程序层又确定已修改的域对象,从持久层加载它们,然后转发对这些域对象的更改。
分层体系结构的一个缺点是它建议从表示层一直到基础结构层的依赖性的线性堆叠。但是,我们可能希望在表示层和基础结构层中支持不同的实现。如果(正如我认为的那样!)我们想要测试我们的应用程序就是这种情况:
例如,FitNesse [4]等工具允许我们从最终用户的角度验证我们系统的行为。但是这些工具通常不会通过表示层,而是直接进入下一层,即应用层。所以从某种意义上说,FitNesse就是另一种观察者。
同样,我们可能有多个持久性实现。我们的生产实现可能使用RDBMS或类似技术,但是对于测试和原型设计,我们可能有一个轻量级实现(甚至可能在内存中),因此我们可以模拟持久性。
我们可能还想区分“内部”和“外部”层之间的交互,其中内部我指的是两个层完全在我们的系统(或BC)内的交互,而外部交互跨越BC。
因此,不要将我们的应用程序视为一组图层,另一种方法是将其视为六边形[5],如图5所示。我们的最终用户使用的查看器以及FitNesse测试使用内部客户端API(或端口),而来自其他BC的调用(例如,RESTful用于开放主机交互,或来自ESB适配器的调用用于已发布的语言交互)命中外部客户端端口。对于后端基础架构层,我们可以看到用于替代对象存储实现的持久性端口,此外,域层中的对象可以通过外部服务端口调用其他BC。
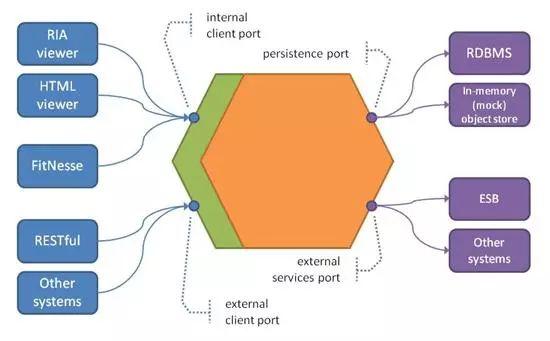
Figure 5: Hexagonal Architecture
但这足够大的东西; 让我们来看看DDD在煤炭面板上的样子。
正如我们已经注意到的,大多数DDD系统可能会使用OO范例。因此,我们的域对象的许多构建块可能很熟悉,例如实体,值对象和模块。例如,如果您是Java程序员,那么将DDD实体视为与JPA实体基本相同(使用@Entity注释)就足够安全了;值对象是字符串,数字和日期之类的东西;一个模块就是一个包。
但是,DDD倾向于更多地强调值对象,而不是过去习惯。所以,是的,您可以使用String来保存Customer的givenName属性的值,例如,这可能是合理的。但是一笔钱,例如产品的价格呢?我们可以使用int或double,但是(甚至忽略可能的舍入错误)1或1.0是什么意思?$ 1吗?€1?¥1?1分,甚至?相反,我们应该引入一个Money值类型,它封装了Currency和任何舍入规则(将特定于Currency)。
而且,值对象应该是不可变的,并且应该提供一组无副作用的函数来操作它们。我们应该写:
讯享网Money m1 = new Money(”GBP“, 10); Money m2 = new Money(”GBP“, 20); Money m3 = m1.add(m2);
将m2添加到m1不会改变m1,而是返回一个新的Money对象(由m3引用),它表示一起添加的两个Money。
值也应该具有值语义,这意味着(例如在Java和C#中)它们实现equals()和hashCode()。它们通常也可以序列化,可以是字节流,也可以是String格式。当我们需要持久化它们时,这很有用。
值对象常见的另一种情况是标识符。因此,(US)SocialSecurityNumber将是一个很好的例子,车辆的RegistrationNumber也是如此。URL也是如此。因为我们已经重写了equals()和hashCode(),所以这些都可以安全地用作哈希映射中的键。
引入值对象不仅扩展了我们无处不在的语言,还意味着我们可以将行为推向值本身。因此,如果我们确定Money永远不会包含负值,我们可以在Money内部实现此检查,而不是在使用Money的任何地方。如果SocialSecurityNumber具有校验和数字(在某些国家/地区就是这种情况),则该校验和的验证可以在值对象中。我们可以要求URL验证其格式,返回其方案(例如http),或者确定相对于其他URL的资源位置。
我们的另外两个构建块可能需要更少的解释。实体通常是持久的,通常是可变的并且(因此)倾向于具有一生的状态变化。在许多体系结构中,实体将作为行保存在数据库表中。同时,模块(包或命名空间)是确保域模型保持解耦的关键,并且不会成为泥浆中的一大块[6]。在他的书中,埃文斯谈到概念轮廓,这是一个优雅的短语,用于描述如何区分域的主要关注领域。模块是实现这种分离的主要方式,以及确保模块依赖性严格非循环的接口。我们使用诸如Uncle“Bob”Martin的依赖倒置原则[7]之类的技术来确保依赖关系是严格单向的。
实体,值和模块是核心构建块,但DDD还有一些不太熟悉的构建块。我们现在来看看这些。
如果您精通UML,那么您将记住,它允许我们将两个对象之间的关联建模为简单关联,聚合或使用组合。聚合根(有时缩写为AR)是通过组合组成其他实体(以及它自己的值)的实体。也就是说,聚合实体仅由根引用(可能是过渡的),并且可能不会被聚合外的任何对象(永久地)引用。换句话说,如果实体具有对另一个实体的引用,则引用的实体必须位于同一聚合内,或者是某个其他聚合的根。
许多实体是聚合根,不包含其他实体。对于不可变的实体(相当于数据库中的引用或静态数据)尤其如此。示例可能包括Country,VehicleModel,TaxRate,Category,BookTitle等。
但是,更复杂的可变(事务)实体在建模为聚合时确实会受益,主要是通过减少概念开销。我们不必考虑每个实体,而只考虑聚合根;聚合实体仅仅是聚合的“内部运作”。它们还简化了实体之间的相互作用;我们遵循以下规则:(持久化)引用可能只是聚合的根,而不是聚合中的任何其他实体。
另一个DDD原则是聚合根负责确保聚合实体始终处于有效状态。例如,Order(root)可能包含OrderItems的集合(聚合)。可能存在以下规则:订单发货后,任何OrderItem都无法更新。或者,如果两个OrderItem引用相同的产品并具有相同的运输要求,则它们将合并到同一个OrderItem中。或者,Order的派生totalPrice属性应该是OrderItems的价格总和。维护这些不变量是root的责任。
但是……只有聚合根才能完全在聚合中维护对象之间的不变量。OrderItem引用的Product几乎肯定不会在AR中,因为还有其他用例需要与Product进行交互,而不管是否有订单。因此,如果有一条规则不能对已停产的产品下达订单,那么订单将需要以某种方式处理。实际上,这通常意味着在订单交易更新时使用隔离级别2或3来“锁定”产品。或者,可以使用外部过程来协调交叉聚合不变量的任何破损(an out-of-band process can be used to reconcile any breakage of cross-aggregate invariants.)。
在我们继续前进之前退一步,我们可以看到我们有一系列粒度:
value <entity <aggregate <module <有界上下文
现在让我们继续研究一些DDD构建块。
在企业应用程序中,实体通常是持久的,其值表示这些实体的状态。但是,我们如何从持久性存储中获取实体呢?
存储库是持久性存储的抽象,返回实体 - 或者更确切地说是聚合根 - 满足某些标准。例如,客户存储库将返回Customer聚合根实体,订单存储库将返回Orders(及其OrderItems)。通常,每个聚合根有一个存储库。
因为我们通常希望支持持久性存储的多个实现,所以存储库通常由具有不同持久性存储实现的不同实现的接口(例如,CustomerRepository)组成(例如,CustomerRepositoryHibernate或CustomerRepositoryInMemory)。由于此接口返回实体(域层的一部分),因此接口本身也是域层的一部分。接口的实现(与一些特定的持久性实现耦合)是基础结构层的一部分。
我们搜索的标准通常隐含在名为的方法名称中。因此,CustomerRepository可能会提供findByLastName(String)方法来返回具有指定姓氏的Customer实体。或者我们可以让OrderRepository返回Orders,findByOrderNum(OrderNum)返回与OrderNum匹配的Order(请注意,这里使用值类型!)。
更复杂的设计将标准包装到查询或规范中,类似于findBy(Query <T>),其中Query包含描述标准的抽象语法树。然后,不同的实现解包查询以确定如何以他们自己的特定方式定位满足条件的实体。
也就是说,如果你是.NET开发人员,那么值得一提的是LINQ [8]。因为LINQ本身是可插拔的,所以我们通常可以使用LINQ编写存储库的单个实现。然后变化的不是存储库实现,而是我们配置LINQ以获取其数据源的方式(例如,针对Entity Framework或针对内存中的对象库)。
每个聚合根使用特定存储库接口的变体是使用通用存储库,例如Repository <Customer>。这提供了一组通用方法,例如每个实体的findById(int)。当使用Query <T>(例如Query <Customer>)对象指定条件时,这很有效。对于Java平台,还有一些框架,例如Hades [9],允许混合和匹配方法(从通用实现开始,然后在需要时添加自定义接口)。
存储库不是从持久层引入对象的唯一方法。如果使用对象关系映射(ORM)工具(如Hibernate),我们可以在实体之间导航引用,允许我们透明地遍历图形。根据经验,对其他实体的聚合根的引用应该是延迟加载的,而聚合中的聚合实体应该被急切加载。但与ORM一样,期望进行一些调整,以便为最关键的用例获得合适的性能特征。
在大多数设计中,存储库还用于保存新实例,以及更新或删除现有实例。如果底层持久性技术支持它,那么它们很可能存在于通用存储库中,但是从方法签名的角度来看,没有什么可以区分保存新客户和保存新订单。
最后一点……直接创建新的聚合根很少见。相反,它们倾向于由其他聚合根创建。订单就是一个很好的例子:它可能是通过客户调用一个动作来创建的。
这整齐地带给我们:
如果我们要求Order创建一个OrderItem,那么(因为毕竟OrderItem是其聚合的一部分),Order知道要实例化的具体OrderItem类是合理的。实际上,实体知道它需要实例化的同一模块(命名空间或包)中的任何实体的具体类是合理的。
假设客户使用Customer的placeOrder操作创建订单(参见图6)。如果客户知道具体的订单类,则意味着客户模块依赖于订单模块。如果订单具有对客户的反向引用,那么我们将在两个模块之间获得循环依赖。
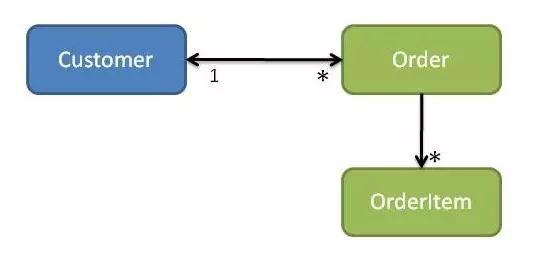
图6:客户和订单(循环依赖)
如前所述,我们可以使用依赖性反转原则来解决这类问题:从订单中删除依赖关系 - >客户模块我们将引入OrderOwner接口,使Order引用为OrderOwner,并使Customer实现OrderOwner(参见图7) )。
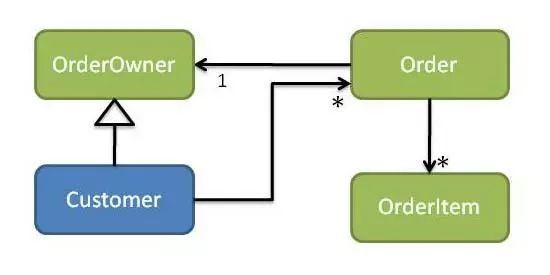
图7:客户和订单(客户取决于订单)
那么另一种方式呢:如果我们想要订单 - >客户?在这种情况下,需要在客户模块中有一个表示Order的接口(这是Customer的placeOrder操作的返回类型)。然后,订单模块将提供订单的实现。由于客户不能依赖订单,因此必须定义OrderFactory接口。然后,订单模块依次提供OrderFactory的实现(参见图8)。
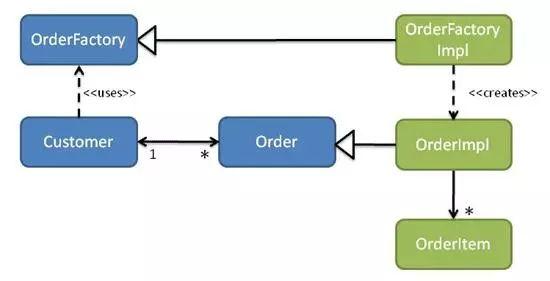
图8:客户和订单(订单取决于客户)
可能还有相应的存储库接口。例如,如果客户可能有数千个订单,那么我们可能会删除其订单集合。相反,客户将使用OrderRepository根据需要定位其订单(的一部分)。或者(如某些人所愿),您可以通过将对存储库的调用移动到应用程序体系结构的更高层(例如域服务或应用程序服务)来避免从实体到存储库的显式依赖性。
实际上,服务是我们需要探索的下一个话题。
域服务是在域层内定义的域服务,但实现可以是基础结构层的一部分。存储库是域服务,其实现确实在基础结构层中,而工厂也是域服务,其实现通常在域层内。特别是在适当的模块中定义了存储库和工厂:CustomerRepository位于客户模块中,依此类推。
更一般地说,域服务是任何不容易在实体中生存的业务逻辑。埃文斯建议在两个银行账户之间进行转账服务,但我不确定这是最好的例子(我会将转账本身建模为一个实体)。但另一种域服务是一种充当其他有界上下文的代理。例如,我们可能希望与暴露开放主机服务的General Ledger系统集成。我们可以定义一个公开我们需要的功能的服务,以便我们的应用程序可以将条目发布到总帐。这些服务有时会定义自己的实体,这些实体可能会持久化;这些实体实际上影响了在另一个BC中远程保存的显着信息。
我们还可以获得技术性更强的服务,例如发送电子邮件或SMS文本消息,或将Correspondence实体转换为PDF,或使用条形码标记生成的PDF。接口在域层中定义,但实现在基础架构层中非常明确。因为这些非常技术***的接口通常是根据简单的值类型(而不是实体)来定义的,所以我倾向于使用术语基础结构服务而不是域服务。但是如果你想成为一个“电子邮件”BC或“SMS”BC的桥梁,你可以想到它们。
虽然域服务既可以调用域实体也可以调用域实体,但应用服务位于域层之上,因此域层内的实体不能调用,只能反过来调用。换句话说,应用层(我们的分层架构)可以被认为是一组(无状态)应用服务。
如前所述,应用程序服务通常处理交叉和安全等交叉问题。他们还可以通过以下方式与表示层进行调解:解组入站请求;使用域服务(存储库或工厂)获取对与之交互的聚合根的引用;在该聚合根上调用适当的操作;并将结果编组回表示层。
我还应该指出,在某些体系结构中,应用程序服务调用基础结构服务。因此,应用服务可以直接调用PdfGenerationService,传递从实体中提取的信息,而不是实体调用PdfGenerationService将其自身转换为PDF。这不是我的特别偏好,但它是一种常见的设计。我很快就会谈到这一点。
好的,这完成了我们对主要DDD模式的概述。在Evans 500 +页面书中还有更多内容 - 值得一读 - 但我接下来要做的是突出显示人们似乎很难应用DDD的一些领域。
本文使用 文章同步助手 同步
资本家剥削劳动人民剩余价值,本来无可厚非他也是执行了资本规律。从2000年以来的java(j2se1.4稳定版出来后)企业级开发,无一例外倡导“贫血模型”,过程式开发。无论是sun的ejb 还是spring,apache开源项目等等均用无数例子证明了。做业务系统就是写crud,就是告诉工人阶级不要考虑太多,提高效率一般性工人的生产率才是当务之急。才可以赚取剩余价值,实现资本家的原始积累。
在这个时期很多it企业并不考虑业务是什么,都属于一锤子买卖居多。会crud又或者说低代码能生成crud那就是牛x。
2004年领域驱动设计就在这种格格不入的时代诞生了。在这个粗狂发展的it时代并不需要太多分析业务的人员。在前期需要大量投入,后期才有可能享受,且ooa ood各种设计模式及书籍还缺的年代。要搞ddd那就是一个笑话。那个资本家会考虑先投资后收益?“做的不快你就是笨”.
时间来到2014,随着分工更为精细化,业务领域随着时代的进步复杂化,资本家能赚钱的领域只能纵向深挖了。领域驱动设计才被又提起重视。如“银弹”一般被无数人奉为圣经遭到追捧。就连市面上最流行的togaf方法论,都以ddd为实现指导。
“反者道之动“.这种风气正盛之时,也暗藏着很多的坑。ddd不是玄学,但是也并不容易掌握。业务领域是什么?说到底是人类把技术升华的过程,如何抽象的看待自然的过程。无疑不透露着自然而然的道。
切勿因技术而技术,ddd本身值得尊重 就是他维护和尊重领域。以领域为本。以自然抽象为本。[微笑]
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/143919.html