
<p id="main-toc"><strong>目录</strong></p> 讯享网
一、安装d2l库
二、预处理数据集
三、transformer模型
四、开始训练
五、评估模型
数据集:
大概长这样
讯享网
这里图方便用d2l.DataModule父类
d2l源码:d2l-en/d2l at master · d2l-ai/d2l-en · GitHub
使用jieba分词
讯享网
绘制token数量大小的直方图
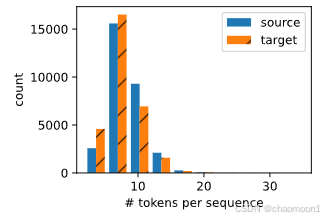
生成token字典,序列长度不足的用pad填充,如果是要预测的序列(不是标签,是decoder输入的序列)首位加bos

讯享网
将句子转化为序列示例
讯享网
先导入库
基于位置的前馈网络,就是个FC层
讯享网
层归一化和残差连接
编码器中重复的模块
一个多头自注意力,两个addnorm层和一个前馈网络
讯享网
完整的编码器
加上嵌入层,位置嵌入层,n个重复block
解码器与编码器类似
讯享网
讯享网
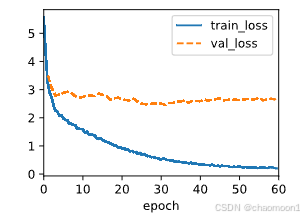
方差很大,我觉得是因为数据集还是太少,模型代码没什么问题,超参数调的也还可以,还是说中文的分词需要更改?
讯享网
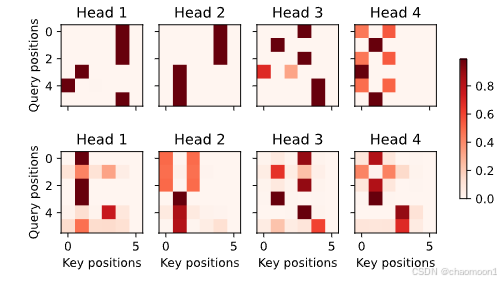
模型对短句子的推理效果不错,但是长句子就很差了
看看注意力矩阵
讯享网
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/140891.html