
AI 技术在音频领域发展十分迅速。除了之前介绍的降噪、回声消除以及丢包补偿等方向可以用 AI 模型来提升音质听感之外,AI 模型还有很多有趣的应用。其中比较常见的有 ASR(Automatic Speech Recognition)可以理解为语音转文字,TTS(Text To Speech)文字转语音和 VPR(Voice Print Recognition)声纹识别等。
在之前说的音效算法的时候了解到,要做到变声需要改变整个语音信号的基频,还需要改变语音的音色。传统算法是通过目标语音和原始语音,计算出基频差距和频谱能量分布的差异等特征,然后使用变调、EQ 等方法来对语音进行调整,从而实现变声(Voice Conversition,VC)。
但这些特征的差异,在发不同的音,不同的语境中可能都是不一样的。如果用一个平均值来进行整体语音的调整,你可能会发现有的音变声效果比较贴近目标语音,而有的音,可能会有比较大的偏离。整体听感上就会觉得变声效果时好时坏。
甚至由于某些发音在改变了频谱能量分布后,共振峰发生了较大改变,连原本想表达的语意都发生了变化。所以为了获得比较好的变声效果,需要实时对语音做动态的调整,而这使用传统算法显然是无法穷尽所有发音、语境的对应变化关系的。
如图 1 所示,如果可以做到语音转文字,文字也可以转语音,那么结合声纹识别(VPR)把人声的特性加入到 TTS 之中,是不是就可以实现变声的功能了?接下来就基于 AI 模型的变声算法的角度,来整体认识一下这些常见 AI 算法背后的原理,以及它们是如何组合、搭配实现变声功能的。

讯享网
先从 ASR 算法来看看如何实现语音转文字的。
ASR
结合图 2,可以看一下 ASR 算法的基本原理。语音信号需要转换为频谱信号或者之前讲过的 MFCC 来作为语音特征序列。然后根据特征序列推断出对应的音素序列,音素在不同的语言中有很多不同的表达形式,比如中文可以用汉语拼音来表示。最后根据音素和文字的映射字典(lexicon)就可以得到语言对应的文本了。

ASR 在音频领域的研究一直都是比较火热的方向。目前在工业界,使用的最多的是基于Kaldi 开源框架的算法,有兴趣的话可以通过链接了解一下。Kaldi 模型以及其改进版本有很多,这里主要介绍一下常见的 ASR 模型的构建方法。

如图 3 所示,为了实现比较准确的 ASR 系统,需要构建两个主要的模型:声学模型(Acoustic Model)和语言模型(Language model)。然后通过语言解码器和搜索算法(Ligusitic Decoding and search algorithm),结合声学模型和语言模型的结果,综合选择出概率最大的文字序列作为识别的输出。其中声学模型主要是通过语音数据库训练得到,而语言模型则主要是通过文本数据库训练得到。

为什么不能从音频的特征信息直接得到文字输出,而需要这么一套相对复杂的模型系统呢?
这是因为同音字、同音词、谐音、连读等发音特性,可能导致很多容易混淆的结果,从而同一段语音可能会得到多个备选的文字方案。比如图 2 中根据音素序列可以得到“今天是几号”,也可能是“今天十几号”或者“晴天是几号”等。这时除了声学模型音素读取需要较高的准确性外,还需要语言模型根据上下文的语境来对 ASR 的结果进行修正。
其实,最近这几年端到端的 ASR 的研究也有很多不错的进展。比如ESPNet 开源项目里就整合了许多基于 CTC、Transformer 等技术的端到端开源模型。
TTS
了解了 ASR 的基本原理后,再来看看文字转语音(TTS)是如何实现的。
其实语音合成作为 ASR 的逆过程,实现起来主要是先通过一个模型把文字转为语音的特征向量,比如 MFCC,或者基频、频谱包络、能量等特征组合的形式,然后再使用声码器(Vocoder)把语音特征转换为音频信号。
说到 TTS,就不得不提及 Google 发表的两篇重要论文,一个是WaveNet 声码器,另一个是声纹识别到多重声线语音合成的迁移学习。其中 WaveNet 声码器首次把语音合成的音频结果提升到了和真人说话一样的自然度,而 VPR 结合 WavNet 则是实现了端到端的文字到语音的生成。
WaveNet 的基本思想是利用因果空洞卷积这种自回归的 AI 模型,来逐点实现音频时域 Wave 信号的生成。用通俗一点的话来说就是,WaveNet 是逐个采样点生成音频信号的,也就是说生成出的第 k 个点是第 k+1 个点的输入。这种算法极其消耗算力,比如生成一秒 48kHz 采样的音频,需要循环调用 AI 模型计算 48000 次才能完成,但这样做得到的音频的效果自然度还是很不错的。
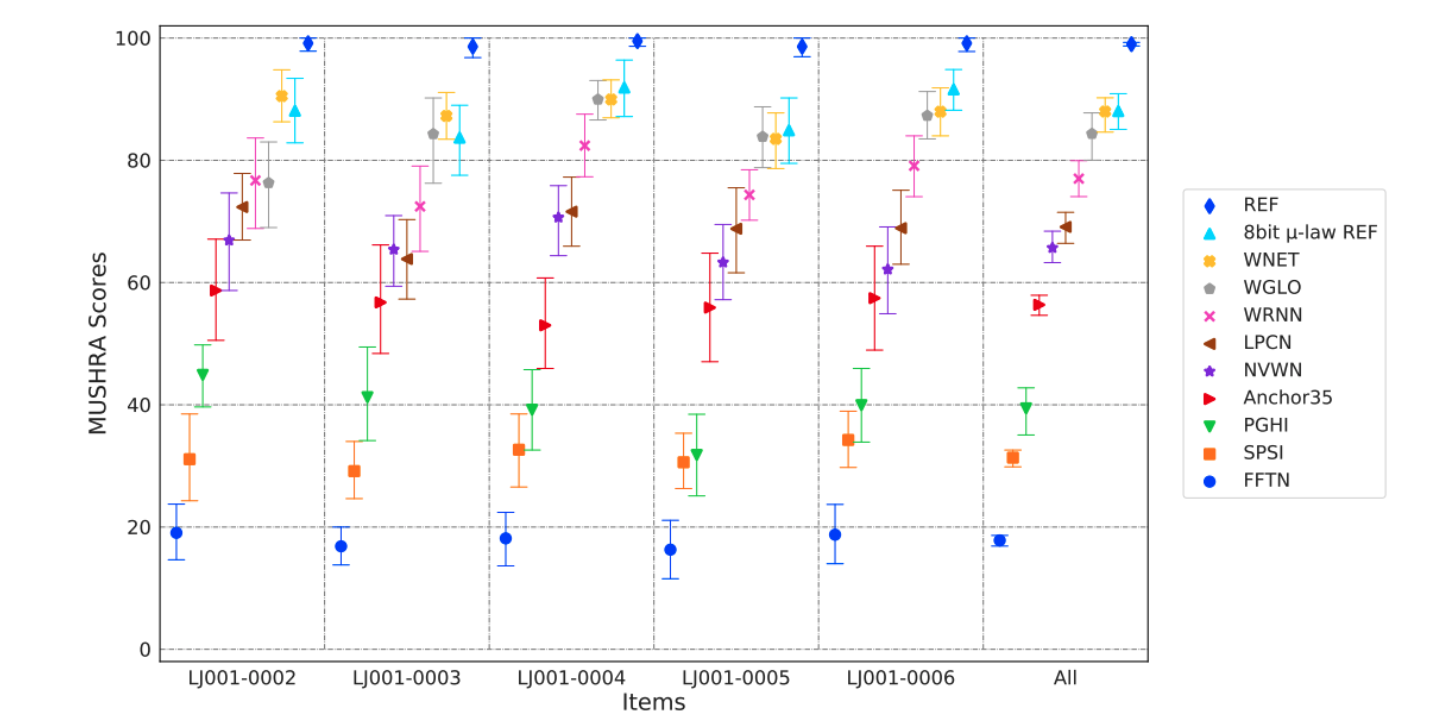
为了缩减算力,同时保持模型生成的计算速度,人们后续对其做了一系列的改进。于是就有了后来的 Fast WaveNet、Parallel WaveNet、WaveRNN、WaveGlow 和 LPCNet 等。如图 4 所示,Fraunhofer IIS 和 International Audio Laboratories Erlangen 就曾联合发布过一篇回顾的论文,主要分析了不同的 Vocoder 的 MUSHRA 评分。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/13109.html