
1. 计算图优化背景
深度学习在各种实际应用中取得了巨大成功,使许多应用发生了革命性的变化,包括视频分析、自然语言处理等。随着可用的数据增多,硬件的计算能力增强,为了在复杂问题中取得好的表现,目前DNN框架变得越来越复杂,神经网络层数越来越多,神经网络参数越来越大。ILSVRC2015分类挑战赢家ResNet网络层数涉及多达152层,大的BERT模型具有3.4亿个网络参数。
随着深度神经网络层数变得越来越多,模型变得越来越深,DNN的推理与训练时间显著提升。在DNN中每一回合的推理或训练中的每一次迭代通常可以表示为计算图(Computational graphs:a common way to represent programs in deep learning frameworks),通过计算图优化可以提高DNN训练和推理的速度。
2. 计算图优化方法
计算图优化方法有很多,有很多种图优化手段:
- Operator Fusion
- Constant Parameter Path Pre-Computation
- Static Memory Reuse Analysis
- Data Layout Transformation
- Alter Op Layout
- Simplify Inference
- Computation Graph Substitution
目前主流的框架Tensorflow、Pytorch、TVM等都是同时采用多种计算图优化手段进行加速计算,Tensorflow提供了图优化器的API,用户可以直接调用;TVM采用Op Fusion(Operator fusion:combine multiple operators together into a single kernel without saving the intermediate results back into global memory)等方法来进行计算优化。
本文将主要介绍computation graph substitution优化方法。
3. Computation graph substitution
computation graph substitution:source graph and target graph have equivalent calculation results
计算图替代就是找到另外一个计算图在功能上等效替代当前的计算图,在替代的同时可以减小计算时间以及计算量。下面是一个简单的图替代例子:
在图1中,计算图包含两个卷积运算(一个具有256个大小内核(3×3),另一个具有256个大小内核(1×1)),然后是连接操作。一个可能的图形替代序列是先将v3卷积的内核大小扩大到(3×3),然后将v2和v3的两个卷积合并为一个。
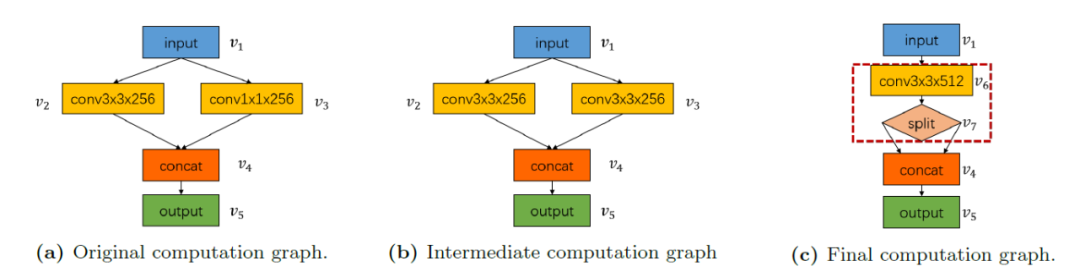
在NVIDIA Tesla P100 GPU输入一个张量为(1×256×14×14×14)的图像,由于放大卷积核,推理时间会增加0.04 ms,后续的卷积融合又会使推理时间减少0.07 ms,从而使图像的每个迭代的总运行时间降低0.03 ms。
本文主要介绍关于计算图替代的paper,使用不同方式来进行计算图替代优化。
3.1 With Relaxed Graph Substitutions
3.1.1 Abstract
现有的深度学习框架通过执行基于贪婪规则的图转换来优化DNN模型的计算图,该转换通常要严格保证提升运行时性能。通过放松严格改进性能的约束来探索复杂计算图的优化,大大增加了语义等价计算图的搜索空间。在计算图替代上使用回溯搜索算法来找到优化网络,并使用基于流的图拆分算法将原始计算图递归分解成更小的子图。在MetaFlow的系统中实现宽松条件计算图替代,比现有框架推理和训练性能分别提高了1.1-1.6倍和1.1-1.2倍。
3.1.2 Relaxed Graph Substitutions
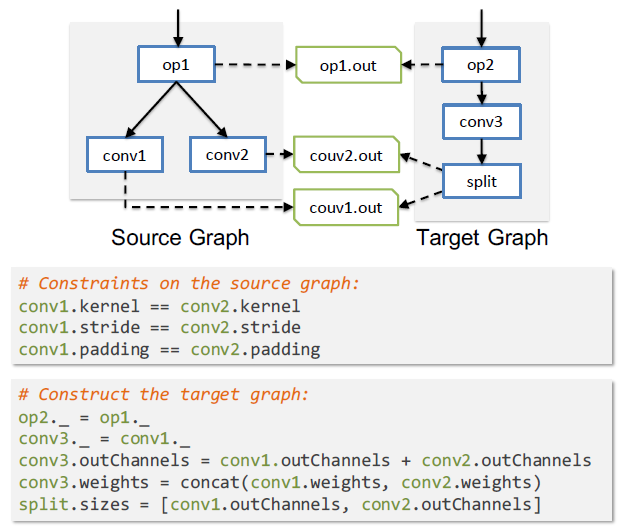
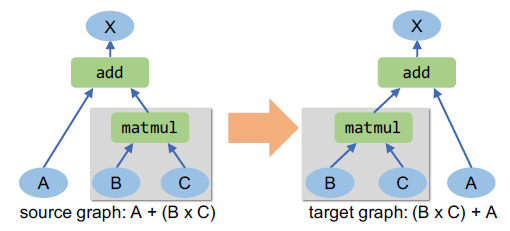
采用宽松条件去进行子图替代,可以给计算图带来更大的搜索空间,使计算图进行最大限度的子图替代,给训练和推理带来最大的优化。每个计算图替代都包括一个可以映射到DNN计算图中特定子图的源图和一个等效新子图替代映射子图的目标图。
Source graph:源图定义了用于替换的有效子图的结构。
Target graph:目标图描述了如何构造一个新的子图来替代映射的子图
源图中的边缘描述了算子之间的数据依赖关系。计算图替代需要映射的子图具有与源图相同的数据依赖性。每个算子都可以有一个外部边缘(图2中的虚线边缘),该边缘可以映射到零个、一个或多个边缘连接到计算图中的外部算子。外部边缘表示算子的输出可以被外部算子访问,并且必须在替代中保留。图2为卷积算子融合示例。
3.1.3 The Melaflow Search Algorithm
宽松条件的计算图替代产生了与原计算图等效的计算图但具有不同运行时性能的计算图搜索空间。实际上,用计算图替代来优化DNN计算图是一个很简单的任务,难度在于所有可能的图替代序列的巨大搜索空间。在搜索空间中寻找最优计算图具有挑战性,因为搜索空间可以是无限的,这取决于使用哪些替代规则,完全列举现在所有DNN模型的搜索空间当然是不可行的。
MetaFlow算法可以高效减小搜索空间并快速找到优化的计算图。MetaFlow算法使用了成本模型、回溯搜索以及基于流的递归计算图拆分的优化方法。
Cost Model
MetaFlow算法使用多维度来评估计算图的运行时性能。成本模型计算每个计算图中的算子指标,并将其适当组合以获得总成本。这些指标包括可以静态计算的指标(如FLOPs、内存使用情况和内核启动次数)以及需要在特定硬件上进行测量的动态指标(如在特定GPU或CPU上的执行时间)。成本模型可以优化单个成本维度(例如最小化整体FLOPs),并结合多个成本维度(例如在保持内存使用率限制的同时最小化执行时间)。
Backtracking Search
使用回溯搜索算法在成本模型下自动找到优化的计算图。图3显示了算法的伪代码。所有候选图都被排入全局优先级队列,并按其成本递增的顺序排列。对于每个排队的计算图G,搜索算法通过在计算图G上应用潜在的图替代来生成新的图并对其进行排队。搜索算法使用参数α(算法中的第13行)来在搜索时间和最优解之间进行权衡。α=1时,搜索算法变为简单的贪婪算法,只考虑严格降低成本的计算图替代。随着α的增加,搜索算法扩大其搜索空间。

Flow-Based Recursive Graph Split
许多最先进的DNN模型太大所以无法通过回溯搜索直接优化。使用基于流的计算图分割算法将计算图递归地划分为更小的不相交适用于回溯搜索算法的子图。将计算图拆分为两个不相交的子图,同时要使两个子图的图替换的数量最小。
Max-Flow算法通过最小化生成图替代将任意计算图拆分为两个不相交的子图。使用Max-Flow算法作为子程序,图4展示了一种计算图拆分算法,该算法将整个计算图递归地划分为小于阈值的单个子图。

在运行回溯搜索算法优化单个子图后,MetaFlow 将优化后的子图重新拼接在一起,构成一个完整的计算图。最后,围绕每个分裂点进行局部回溯搜索,以获取跨越分裂点的替换。
3.1.4 Experiment
End-to-end Inference Performance
在 NVIDIA V100 GPU 上比较了 MetaFlow 和现有深度学习框架(包括 TensorFlow、TensorFlow XLA 和 TensorRT)之间的端到端推理性能。MetaFlow 可以自动将优化的计算图转换为基线框架接受的标准格式,所以使用 MetaFlow 的优化计算图来评估基线框架的性能。图 5 显示了比较结果,蓝线显示了在不使用 MetaFlow 优化图的情况下在三个基线框架中实现的**性能,红线显示了 MetaFlow 性能。MetaFlow 优于现有的深度学习推理引擎,加速1.1到1.6倍。

Training Performance
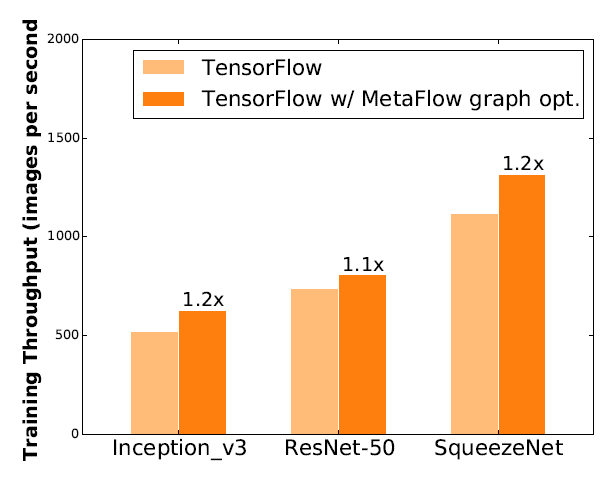
计算图替代优化适用于任意计算图,包括推理和训练。为了评估 MetaFlow 在不同 DNN 的训练性能,现对比在 TensorFlow 上同时运行原始计算图和 MetaFlow 的优化图,使用合成数据对训练性能进行基准测试。在单个计算节点上的四个 NVIDIA V100 GPU 上进行训练,global batch size为64。图6为训练性能对比结果。

3.2 Automatic Generation of Graph Substitutions
3.2.1 Abstract
现有的DNN框架通过应用人工设计的计算图转换来优化DNN的计算图。由于定期引入新的DNN算子,这种方法会错过可能的图优化并且难以扩展。TASO一个自动生成图替代的 DNN 计算图优化器。TASO将算子规范列表作为输入,并使用给定的算子作为基本构建块生成候选替代。所有生成的替代都使用自动定理证明器根据算子规范进行正式验证。为了优化给定的 DNN 计算图,TASO 执行基于成本的回溯搜索,应用替代来找到优化的计算图,该图可以被现有的DNN框架直接使用。
计算图每个节点都是数学张量运算符(矩阵乘法,卷积等)。TensorFlow,PyTorch,TensorRT和TVM使用基于greedy rule-based的优化策略,并直接对输入计算图执行所有适用的替代。目前主流DNN框架主要通过手动设计图替代:
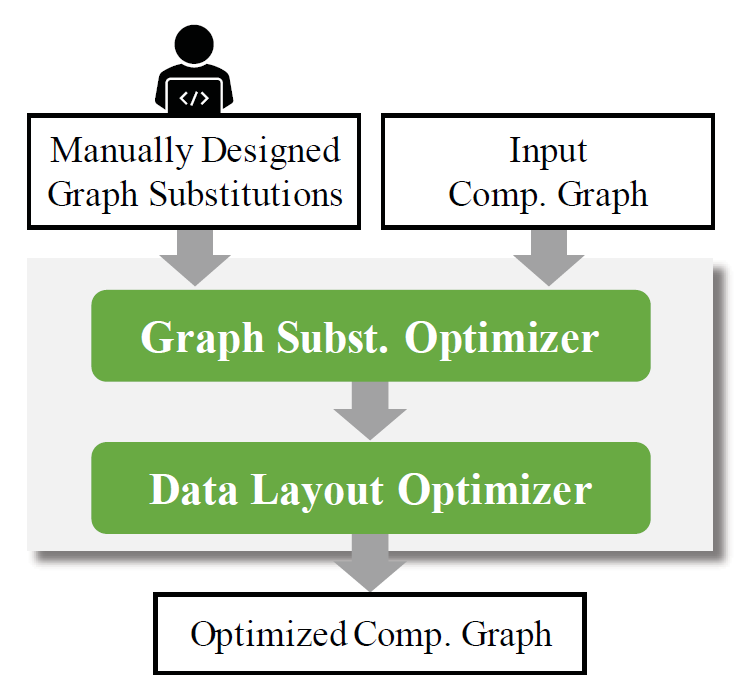
手动设计替代可以提高DNN计算的性能,但存在以下缺点:
1)可维护性差:手动设计图替代的方法工作量非常大。例如,TensorFlow 1.14包括大约53K行C++代码中实现的155个图替代。不断引入新的算子会加剧维护问题,每个新的卷积变体都需要类似的实现工作,每个变体的语义略有不同,并且无法使用现有替代直接进行优化;
2)优化时数据分布复杂:数据分布的选择对运行时性能影响很大。效果最好的数据分布由算子和硬件共同决定;
3)正确性难保证:手工设计的图替代容易出错,错误的图替代会产生错误的推理和训练结果。
TASO是一种自动生成图替代的DNN计算图优化器,主要特点在于:
1)TASO仅需要算子的definitions和specifications,会自动生成计算图替代,减少了工作量;
2)TASO使用形式验证来确保生成的图形替代的正确性;
3)TASO采用图替代和数据布局联合优化,显著提高了运行时性能。
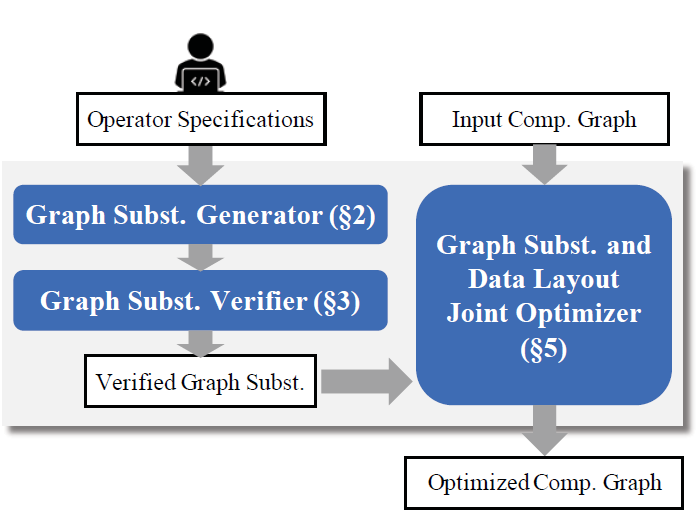
3.2.2 Graph Substitution Generator
TASO通过给定原始算子列表,自动生成潜在的替代图,生成算法可以找到所有有效的替代,直到达到目标大小。TASO借鉴编译器超级优化这篇文章,并为每个计算图计算一个finger print,它是一些特定输入上的计算图输出的哈希值。如果两个计算图的finger print不同,两个计算图是不等价的,所以通过比较具有相同指纹的计算图,TASO可以减少计算数量。
Generation Algorithm
对于给定的一组算子规范,TASO分两步生成潜在的图替代,如算法1所示。

step 1:枚举潜在计算图并获得finger print
step 2:计算具有相同finger print的计算图
3.2.3 Graph Substitution Verifier
验证替代的关键思想是使用一小组以一阶逻辑表示operator properties。为了进行验证,使用一阶逻辑对张量算子进行建模,其中使用参数和输入张量的函数表示算子。
给定算子的属性,使用一阶定理证明(Z3)来验证所有生成的替代。此验证相当于一阶逻辑中的必要性检查,检查运算符属性是否需要对每个生成的替代项的源图和目标图进行功能等效。
3.2.4 Pruning Redundant Substitutions
如果计算图包含于一个更一般的有效图则它是多余的。TASO 使用消除冗余图替代进行剪枝。TASO 还进行了消除源图和目标图具有公共子图的替代,确定了可以进行剪枝的两种形式的公共子图。
3.2.5 Joint Optimizer
TASO优化器使用数据布局和计算图替代的联合优化。不同硬件上对不同的数据分有不同的运算性能,需要对特定硬件进行特定的数据分布设计。例如,在P100上,卷积运算选择row-major layout 数据分布形式表现最好,矩阵乘法选择 column-major layout 数据分布形式表现最好;在有tensor cores Tesla V100支持4×4矩阵运算,将张量平铺为4×4块会获得**性能。
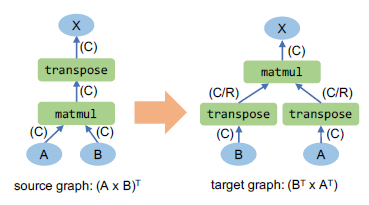
图 11显示了可以通过在具有默认列分布的源图上应用矩阵乘法的转置来导出的潜在计算图。
3.2.6 Experiment
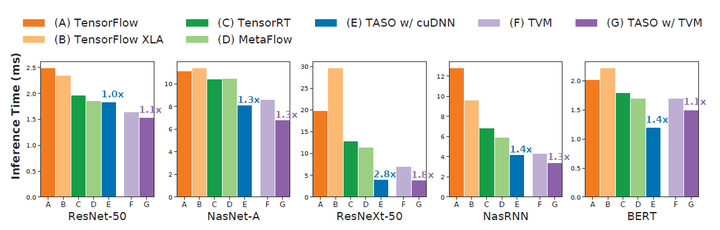
在 V100 GPU 上比较了 TensorFlow、TensorFlowXLA、TensorRT、TVM、MetaFlow和 TASO 的端到端推理性能,图12为对比结果。TensorFlow、TensorFlow XLA、TensorRT 和 MetaFlow 使用高度工程化的cuDNN 和 cuBLAS 库在 GPU 上执行DNN算子,而 TVM 为 DNN 算子生成定制的 GPU 内核。实验是使用单个推理样本进行的,所有结果都是通过在NVIDIA V100 GPU 上平均运行1,000 次来测试的。使用cuDNN和TVM后端评估了TASO 的性能。对于每个DNN 架构,TASO条形上方的数字显示了与具有相同后端的**现有方法相比的加速。
4. Future Work
从现有的论文来看,计算图替代可以起到一定的优化计算效果,需要将图形级和算子级优化结合起来。这种联合优化具有挑战性,因为这两个问题都涉及到庞大且复杂的搜索空间,而一个级别的优化会影响另一个级别的搜索空间。未来研究方向应该是在减小搜索空间的同时进行最大限度的图替代,并且将计算图替代优化与其他优化方法结合,这样会给DNN框架优化计算带来最大的收益。
参考资料
[1]: "Metaflow", https://cs.stanford.edu/~matei/papers/2019/sysml_relaxed_graph_substitutions.pdf
[2]: "TASO", https://cs.stanford.edu/~padon/taso-sosp19.pdf
[3]: "Optimizing DNN Computation Graph using Graph Substitutions", http://www.vldb.org/pvldb/vol13/p2734-fang.pdf
[4]: "TASO:GitHub", https://github.com/jiazhihao/TASO
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/13085.html