
将数据更精细地划分,FN和RN、IP和DP在importance sampling中做不同等处理
目标:更精细地划分数据:即时正样本、假负样本、真正样本、延迟正样本修正import weight;两步优化;双分布流式训练模型。
fnw、esdfm、defer并没有实现真正的无偏估计,importance sampling假设从p(x,y)到q(x,y)没有值发生改变,更具体和严格来说,若将观测label记为v,重新表示有偏分布q(x,v)为:
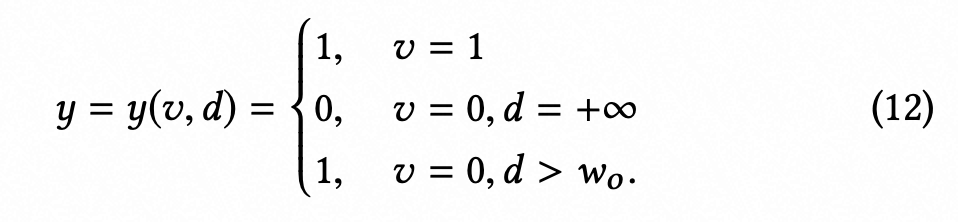
假负样本采样应该被写为
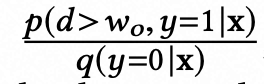
,而不是和实负样本一样进行处理。根据(5,12)可得(13)
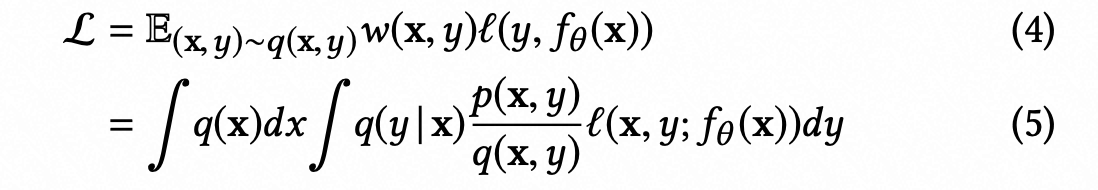
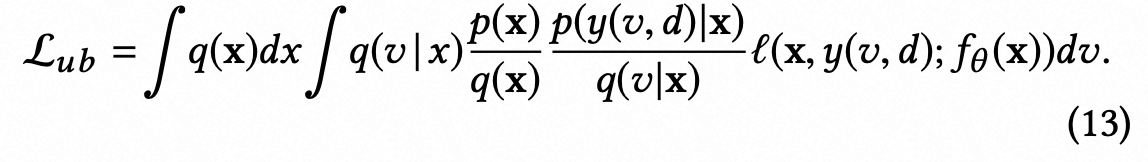
和之前聚焦于样本复制机制的方法不同,本方法聚焦于正确评估loss中的importance weight来建模无偏CVR。
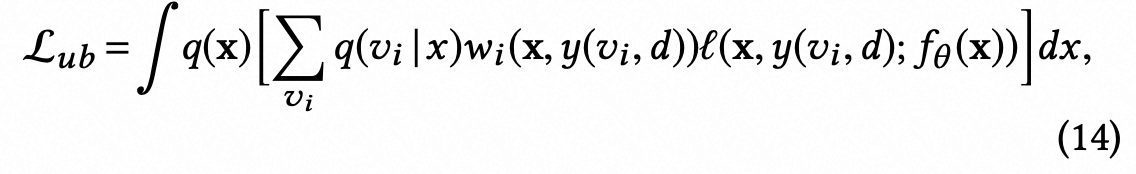
其中

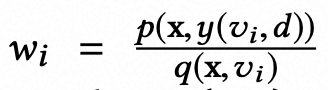
,
现有的方法仅仅建模了观测的正负样本,忽略了FN的影响,导致标签分布存在偏差,因此引入一个隐藏标签z,用来表示观测负样本是否是FN,然后分别建模四种数据的IW
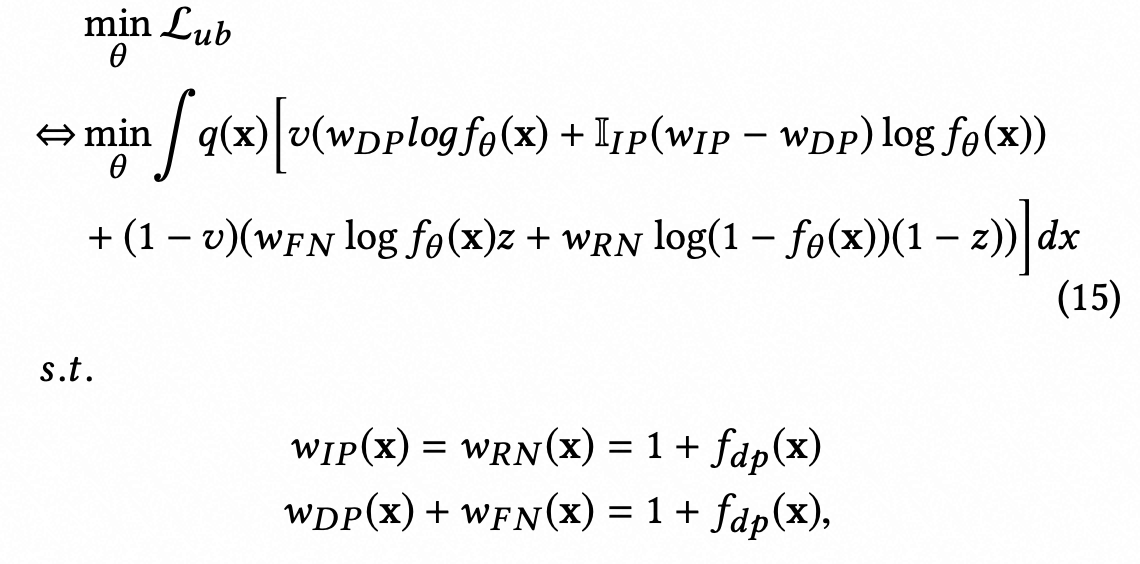
wip、wrn等是由推导证明得来,
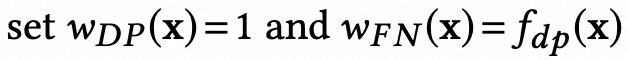
双分布模型结构:
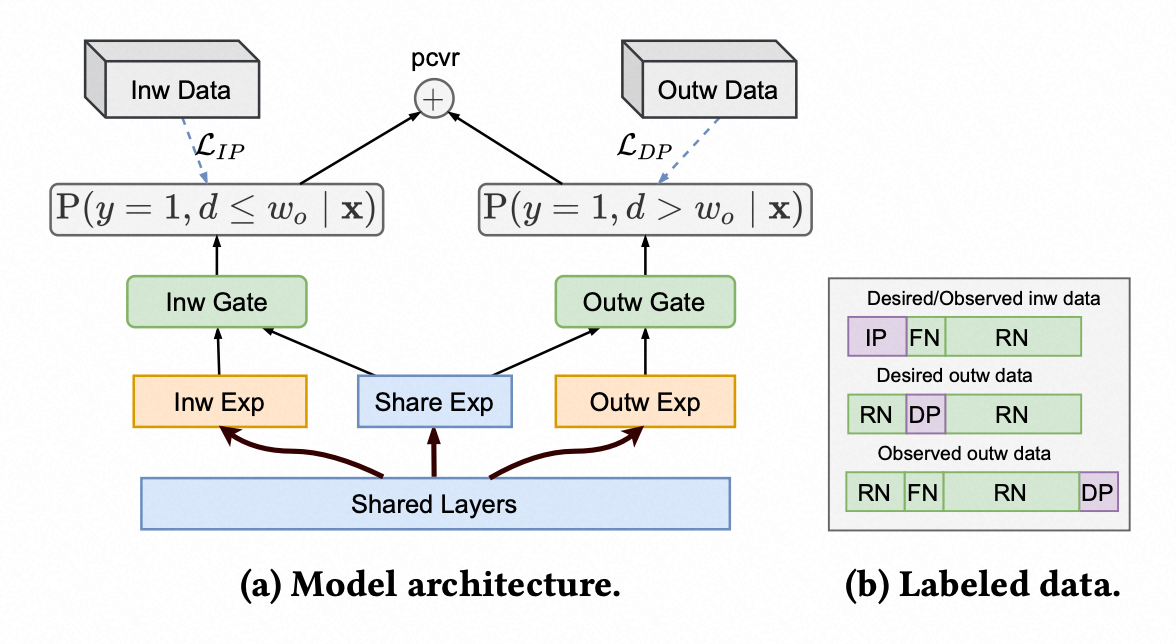
loss:
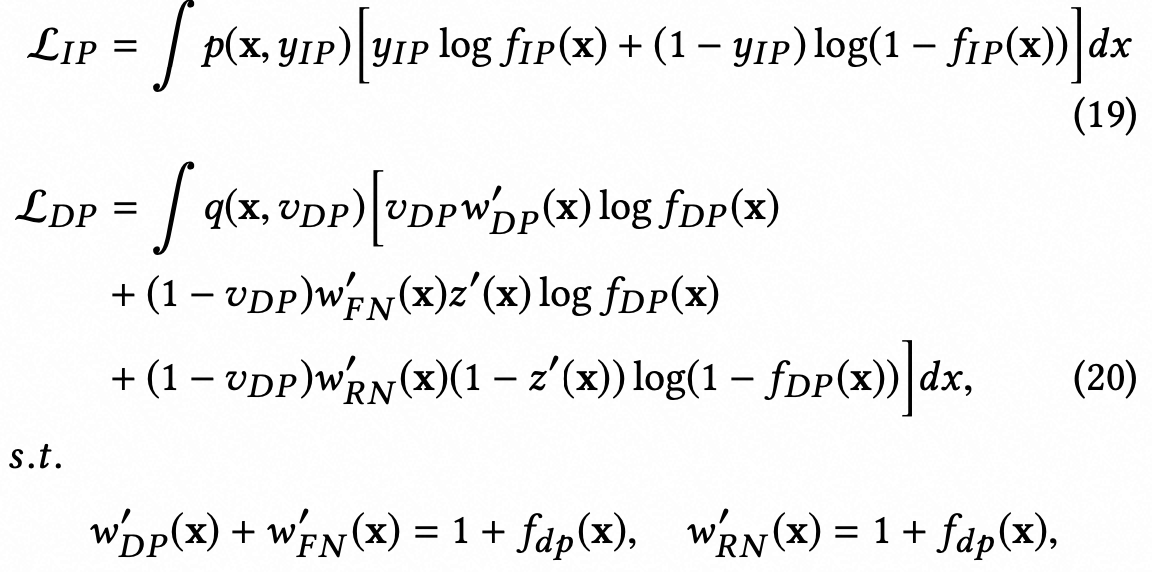
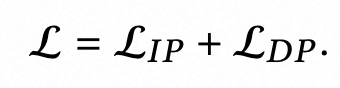
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/129812.html