
符号说明
🔥开发中较多使用,因文章多为干货,因此较难而且重要的才会标此符号
💧开发中较少使用
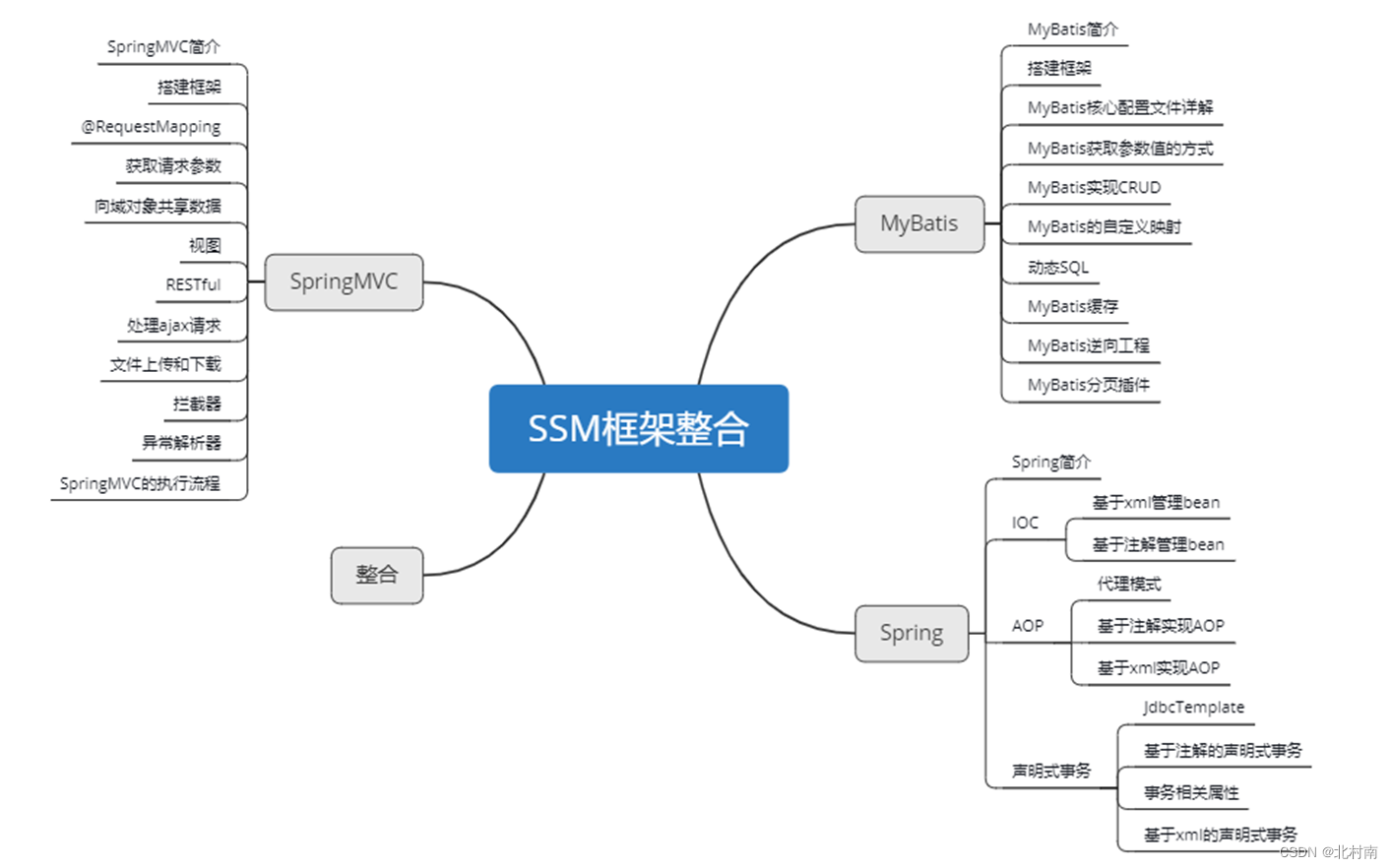
一、SSM
SSM是市面上最流行的Web开发框架,由SpringMVC、Spring、MyBatis整合而成。其中,SpringMVC负责接收浏览器发送的请求,并响应浏览器数据;Spring使用IOC思想管理服务器中各个组件,使用AOP思想面向切面编程,在不改变源码的基础上实现功能增强;MyBatis封装JDBC,负责访问数据库,完成持久化操作。
二、Mybatis--持久层框架
2.1 Introduction
Mybatis是支持定制化SQL、存储过程以及高级映射的优秀持久层框架,避免了JDBC和手动设置参数,使用XML文件进行配置

2.2 IDE
2.2.1 Empty project
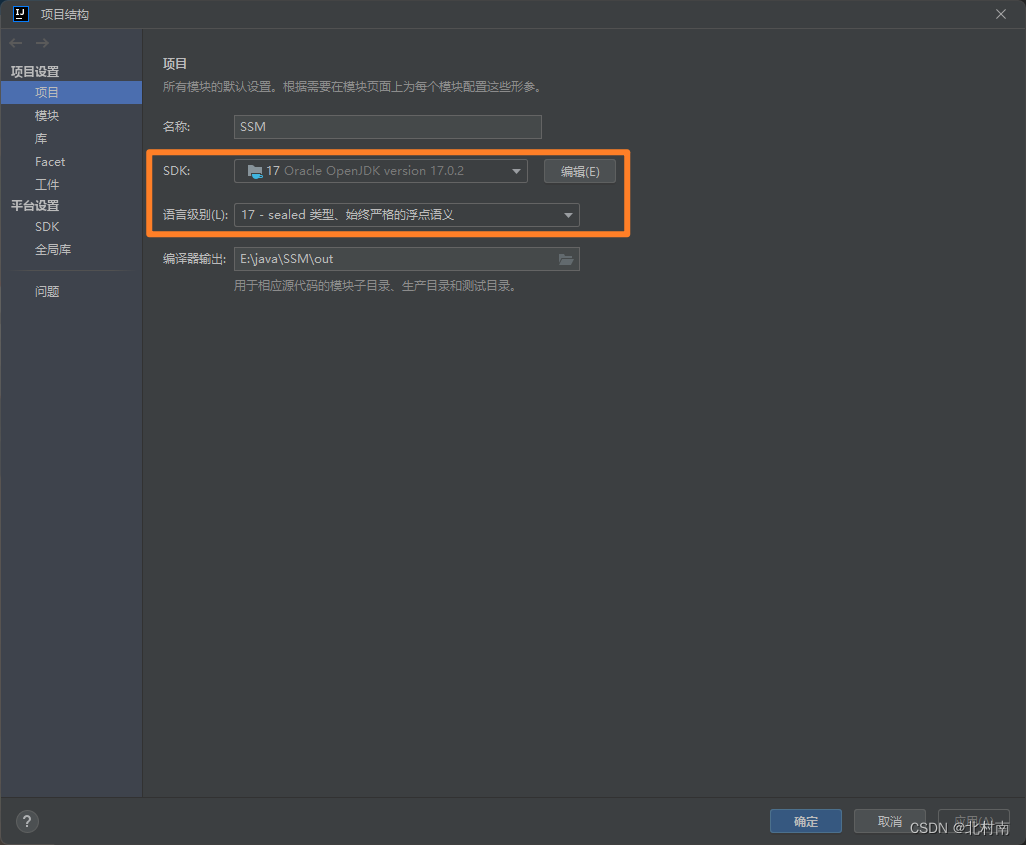
创建一个空项目,选择JDK和语言
配置Maven工具
设置打包方式和导入依赖类
讯享网安装MybatisX插件
这个可是宝藏插件了,为提高开发效率而生,其主要功能如下
- 红蓝小鸟图标,长得好看,点击图标快速跳转对应页面
- ⭐️提示快速生产xml、sql语句等信息
- ⭐️逆向工程,详看2.10
2.2.2 Pojo
创建实体类对象User
@Data:ToString()、Getter()、Setter()等一些常见方法
@AllArgsConstructor:全参构造方法
@NoArgsConstructor:无参构造方法
讯享网
2.2.3 Configuration File
一般叫做mybatis-config.xml,在整合Spring之后,这个配置文件可以直接省略了
主要用于配置数据库环境、pojo和mapper的映射文件
放置在src/main/resources目录下
2 transactionManager:事务管理方式,共两种,一个是JDBC也就是原生的,一个是MANAGED是被管理的,在Spring整合Mybatis的时候是使用这种方式
2.2.4 Mapper.xml
相关概念:ORM(Object Relationship Mapping)对象关系映射。
对象:Java的实体类对象
关系:关系型数据库
映射:二者之间的对应关系
所以~Mapper.xml是MyBatis的映射文件,主要功能是编写SQL语句,位于src/main/resources/com.bcn.mybatis.mapper目录下
注意:这里的创建com.bcn.mybatis.mapper文件夹时,输入的内容得是com/bcn/mybatis/mapper而不能是com.bcn.mybatis.mapper。该文件夹应该与java目录下的mapper文件夹的名字是一样的额
要想实现映射无非是关注我们调用了什么接口下的什么方法,因此需要保持两者一致
调用了什么接口?namespace
调用了什么方法?id
讯享网
2.2.5 log4j.xml
该文件的主要功能是在控制台获取日志信息,方便我们调试错误
log4j的配置文件名为log4j.xml,存放的位置是src/main/resources目录下,这里的log4j.xml的名字一定不能更改
2.2.6 Little Test
其实到了这里,我们已经复现了JSP中的三层架构模式,现在来测试一下
执行结果,这里的输出了log4j配置产生的日志信息。默认结果输出为1就是执行成功了

小灶知识点
1 SqlSession是Java Projct 和 Database之间的会话
2 代理模式:想访问一个正常情况下不能访问的对象,就创建一个该对象的代理对象,主要表现为接口实例化对象
2.3 Parameters Get
Mybatis获取参数主要有两种方式:${} 和 #{}
${}:本质是字符串拼接,因此若为字符串类型或日期类型的字段进行赋值时,需要手动加单引号
#{}:本质是占位符赋值,此时为字符串类型或日期类型的字段进行赋值时, 可以自动添加单引号,还能避免SQL注入问题,所以一般都是用#{}
非实体对象化的参数默认名字是param1,param2等等,如下
实体对象的参数得是实体对象的属性名,如下
非实体对象高级版-->@param,这样在mapper.xml文件中统一的命名都是#{属性名},在Mapper中的代码如下
2.4 CRUD
2.4.1 SqlSessionUtils
在开发过程中,如果我们遇到一些常用的操,可以创建对应的工具类,放到Utils包里面,随后使用委派模式使用该类对象
2.4.2 CRUD
UserMapper.java
UserMapper.xml
test.java
注意点
1 查询标签select必须设置属性resultType或resultMap,用于设置实体类和数据库表的映射关系
2 resultType:自动映射,用于属性名和表中字段名一致的情况
3 resultMap:自定义映射,用于一对多或多对一或字段名和属性名不一致的情况
4 因为在核心配置文件里我们写过了pojo的映射,因此在这里不需要写上类地址全名,写类名即可
2.5 Quary
查询一个实体类对象
查询一个list集合
查询单个数据
查询一条数据为map集合
查询多条数据为map的集合
模糊查询
2.6 Special SQL
批量删除
注意
1 所要删除对象表现不是用list或者map来表示,而是使用字符串的,格式如"1,2,3"
2 参数使用方式得是${},因为#{}会默认加上 ' 从而导致最终查询失败
动态设置java mvc基础 视频教程表名
注意
1 参数的表示只能是${},因为表名也是不能加单引号的
添加功能获取自增的主键(重点知识)
场景:在添加信息之后想获取它的主键
具体做法:使用useGeneratedKeys和keyProperty
🔥2.7 Custom Map
2.7.1 Custom setting
当数据库中的字段名和实体类中的属性名不一致时,可以使用resultMap来实现自定义映射
方式一
使用resultMap来获取映射标签
注意:
1 传统的Sql语句中我们使用的是resultType,而这里使用的是resultMap
方式二:
Mysql中的字段名的格式要求是_,Java中属性名的格式要求是驼峰,命名都规范的话直接使用一个setting全局配置即可
2.7.2 Many to one
遇到多对一的i情况如何查询?比如说查询一个员工的全部信息和它公司的全部信息
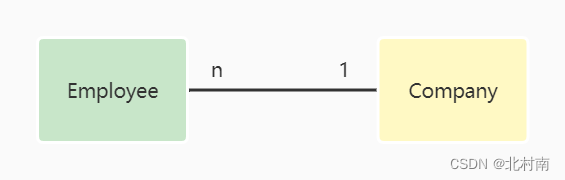

Employee实体类中的一个属性是Company对象,而不是Company的属性
方式一:级联
方式二:association
其实就是一个套娃,在resultMap里面再套上一个resultMap,只不过这里的resultMap换了名字叫做association
方式三:分布查询
就是将一个Sql语句拆分为多个Sql语句
Step1:查询员工的基本信息
Step2:查询公司的基本信息
2.7.3 One To Many
查询一对多的数据,比如说查询一个公司的信息和它所有员工的信息
Company对象的一个属性是 private List<Employee> Emps
方式一:collection
方式二:分布查询
Step1:查询公司信息
Sep2:查询所有员工信息
2.7.4 Lazy loeading
分布查询的优点是能够实现延迟加载(懒加载),简单的说就是分布是有多个Sql语句的,我想使用员工信息的时候它才会它,我想使用公司信息的时候它才会加载它。这样的按需加载就可以灵活的使用系统资源。
比如下面的例子,虽然我们中间有很多的Sql语句,但是我们最终使用到的就是员工的名字,因此它只会执行查找员工信息的语句
做法:在mybatis-config.xml核心配置文件中配置全局配置信息
2.8 Dynamic Sql
解决复杂Sql查询,来进行动态拼装Sql语句的功能,本质就是映射中的各种标签
2.8.1 if、where
if是通过test中的表达式来判断标签中的信息是否有效,有效则拼接到sql中
例:若输入的员工信息全部是非空的,则把他给找出来
where常和if一起使用
a) 若where中有标签成立,则自动生成where关键字,且会将多余的and去掉
b) 若a不成立,则无where
2.8.2 trim
有时候我们的and加在后面,where处理不了,就需要用到trim了
prefix、suffix:在标签的前面或后面添加指定内容
prefexOverrides、suffixOverrides:在标签的前面或后面删除指定内容
🔥2.8.3 foreach
批量操作,比如添加、删除多个用户
2.8.4 SQL
有时候我们想反复的用到sql语句,那么就可以将其封装成一个sql片段,从而提高代码的复用性
2.9 Cache
2.9.1 L1 Cache
Mybatis中的缓存主要针对查询
L1即1级缓存,L1是SqlSession级别的(可以理解为对象级别),通过同一个(如同一个sqlsession1)SqlSession查询的数据会被缓存下来,下次查询的时候也会先从缓存中进行查询。默认自动开启
L1失效(不能从Cache中查询,需要从Database中查询)主要有以下几种情况
- 同一个SqlSession,查询条件不同
- ~,两次查询之间出现了增删改
- ~,两次查询之间手动清空缓存
💧2.9.2 L2 Chche
L2,即2级缓存,L2是SqlSessionFactory级别的(可以理解为类级别),通过同一个(如sqlsession1和sqlsession2)SqlSessionFactory查询的数据被缓存,下次查询会先从L2中查询。开启的条件必须满足以下四个条件
- 核心配置文件中,使用cacheEnabled="true"
- xml映射文件中加一行<cache/>
- 每次SqlSession对象操作完之后进行关闭和提交
- 查询的实体对象加上 implements Serializable
每次执行完之后会有一个Cache Hit Ratio缓存命中率的信息,只要不是0就是查询成功啦
失效的条件:两次查询之间执行了增删改
💧2.9.3 Cache query policy
- 类似于OS中的MMU内存管理单元机制,L2就是TLB快表
- 程序首先查询的是L2,如果L2没有命中则查询L1,若还是没有命中则查询数据库
- SqlSession关闭之后,L1中的数据才会写入到L2中
- 只有L2可以使用第三方缓存如EHCache,有需要可以配置
🔥2.10 Reverse Engineering
RE逆向工程,即代码生成器,即你在开始一个新的项目的时候,它可以帮你自动生成如Mapper、Pojo之类的包和对象,减少一点的开发时间吧
网上有很多说用mybatis-generator-maven-plugin之类的插件,经过笔者测试使用MybatisX最好
使用方法
1 数据库建表
2 创建一个新的工程,连接到数据库
3 选择MybatisX-Generator
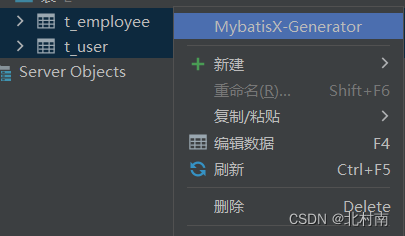
4 按照以下配置
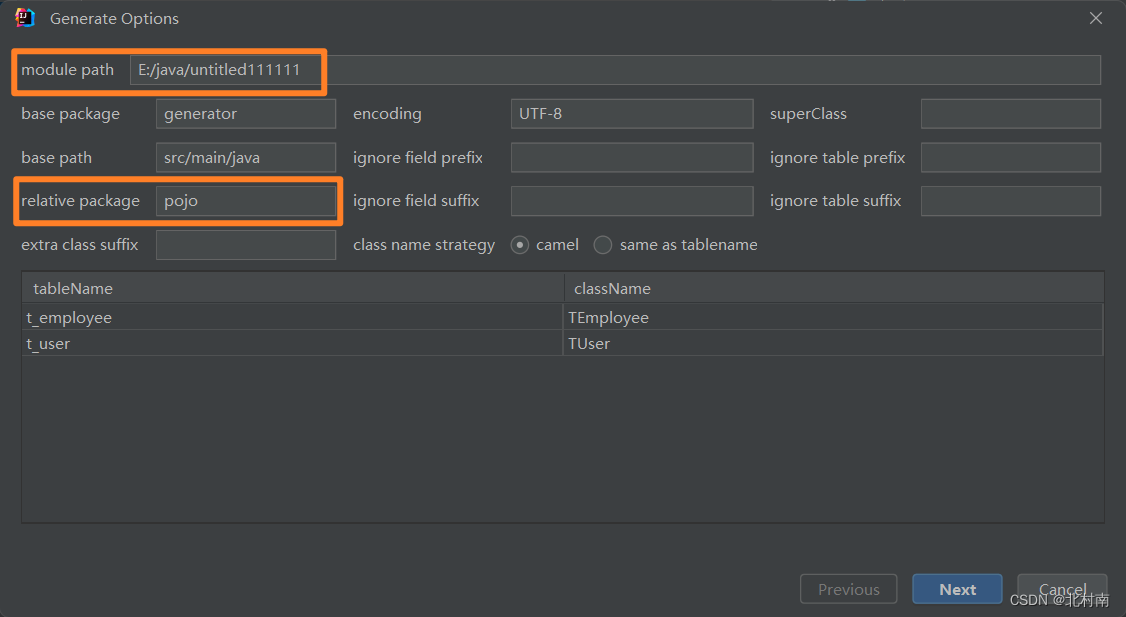
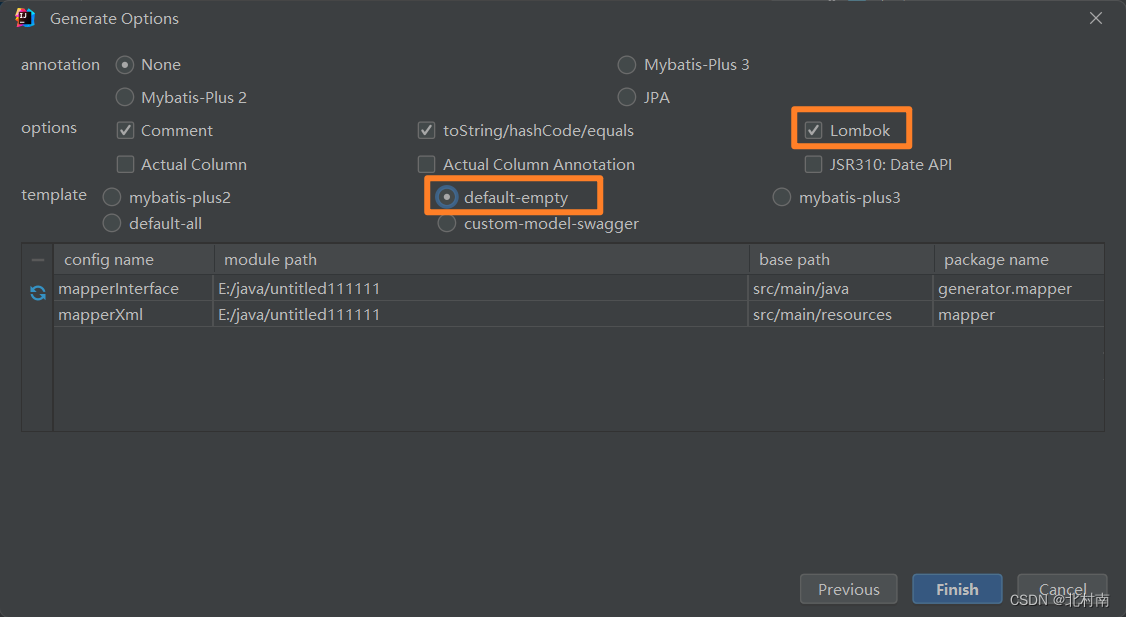
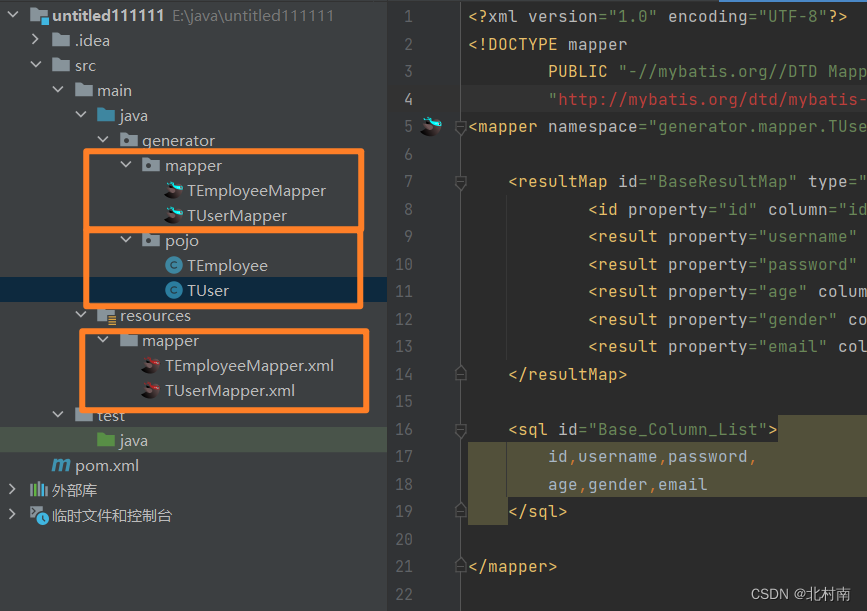
5 查看最终结果,MybatisX逆向工程创建成功,而且xml文件中自动帮我们建好了一个Map
2.11 Paging
分页即如图所示 ,具体做法是使用分页查询的一个插件,在每次查询功能之前开启PageHelper.startPage(int pageNum, int pageSize)
,具体做法是使用分页查询的一个插件,在每次查询功能之前开启PageHelper.startPage(int pageNum, int pageSize)
pageNum:总页面数
pageSize:每页记录的条数
依赖
在config-xml文件中配置分页插件
getUserList函数
测试类
运行结果
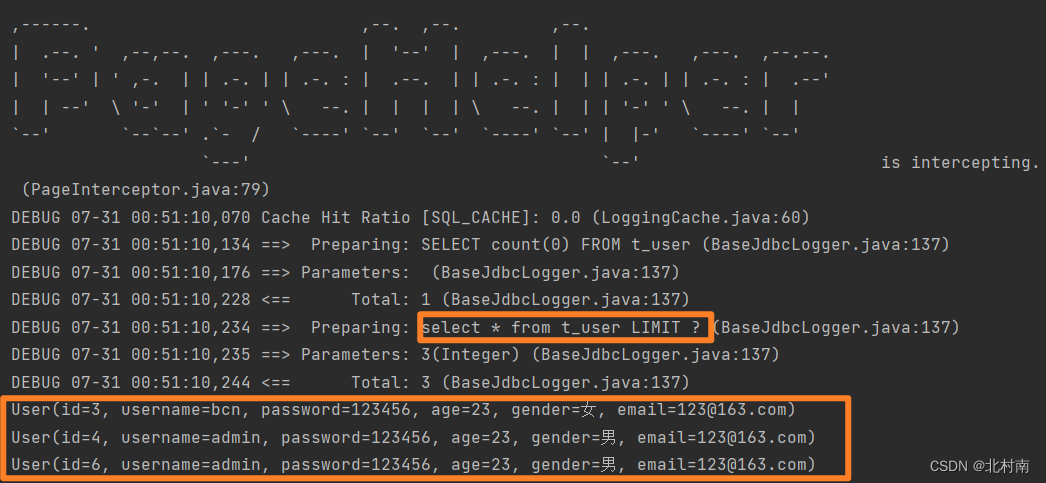
如果想获取分页的所有数据也可以
三、Spring--轻量级Java开发框架

3.1 Introduction
使用其核心思想IOC管理组件,使用AOP思想实现功能增强。
Spring全家桶

3.2 Spring Framework
3.2.1 properties
SpringFramework有以下特性
- 非侵入式:使用 Spring Framework 开发应用程序时,Spring 对应用程序本身的结构影响非常 小。对领域模型可以做到零污染;对功能性组件也只需要使用几个简单的注解进行标记,完全不会破坏原有结构,反而能将组件结构进一步简化。这就使得基于 Spring Framework 开发应用程序时结构清晰、简洁优雅。
- 控制反转:IOC——Inversion of Control,翻转资源获取方向。把自己创建资源、向环境索取资源变成环境将资源准备好,我们享受资源注入。
- 面向切面编程:AOP——Aspect Oriented Programming,在不修改源代码的基础上增强代码功能。
- 容器:Spring IOC 是一个容器,因为它包含并且管理组件对象的生命周期。组件享受到了容器化的管理,替程序员屏蔽了组件创建过程中的大量细节,极大的降低了使用门槛,大幅度提高了开发效率。
- 组件化:Spring 实现了使用简单的组件配置组合成一个复杂的应用。在 Spring 中可以使用 XML 和 Java 注解组合这些对象。这使得我们可以基于一个个功能明确、边界清晰的组件有条不紊的搭建超大型复杂应用系统。
- 声明式:很多以前需要编写代码才能实现的功能,现在只需要声明需求即可由框架代为实现。
- 一站式:在 IOC 和 AOP 的基础上可以整合各种企业应用的开源框架和优秀的第三方类库。而且 Spring 旗下的项目已经覆盖了广泛领域,很多方面的功能性需求可以在 Spring Framework 的基础上全部使用 Spring 来实现。
3.2.2 Five functional modules
Core Container
核心容器,在Spring环境下使用任何功能都必须基于IOC容器AOP&Aspects面向切面编程TestingJunit或TestNG测试框架Data Access/Integration
提供对数据访问/集成的功能Spring MVC提供面向Web程序的集成功能🔥 3.3 IOC
3.3.1 Ideology
IOC:Inversion of Control反转控制,是一种资源获取的方式,简单的理解为之前所有的资源都需要自己创建,现在是Spring为我们提供啥我们就用啥,不必关心资源是如何创建的
DI:Dependency Injection依赖注入,是IOC的具体实现方式,具体来说A依赖对象B,那么就会对B进行赋值
3.3.2 Achieve
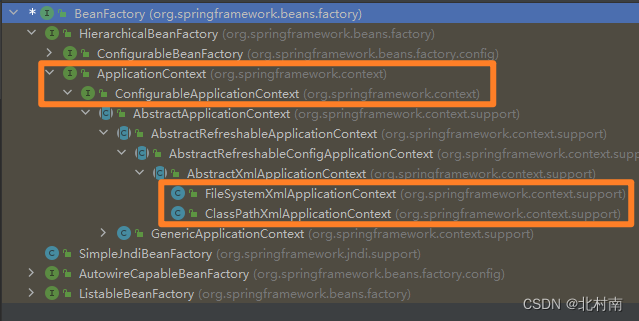
针对IOC思想,Spring中有一个专门的容器就叫做IOC容器,该容器中的管理的组件叫做Bean。注意,在创建bean之前一定是需要创建IOC容器。IOC容器的两种实现方式如下
- BeanFactory:Spring内部使用,不提供给开发者使用
- ApplicationContext:BeanFactory的子接口,有更多的特性。提供给开发者使用,开发中都需要用到这个
主要的实现类:搜索BeanFactory,再按ctrl+H
3.4 Bean
3.4.1 Tag and Scan
Bean主要可以通过XML和注解来管理,XML管理会非常的复杂,在实战中使用的比较少,一般都是使用注解来管理
注解:以@为标志符Tag,其主要是一个标记,当框架扫描Scan注解,就会按照注解的功能来具体执行
关键注解
联系:阅读源码后,我们发现@Controller,@Service和@Repositort都只是在@Component的基础上新起另一个名字,所以从IOC容器管理的角度看,这三个本质上无区别,只是让程序员看的更加清楚一点。
使用xml管理bean的时候,每个bean都有一个唯一的标志符,使用注解的时候每个bean也会有一个唯一的标志符,如UserController对应的bean就是userController,当然我们也可以自定义bean的id,方法如下
具体实现步骤如下
1. 创建各个对象,并给各个对象加上注释
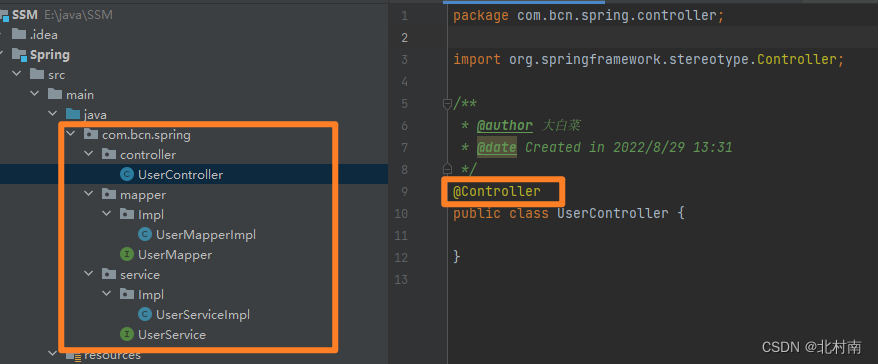
2.创建spring的xml文件,并向其中添加扫描组件
3. 测试
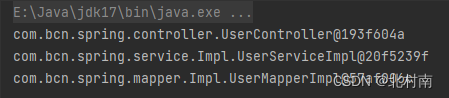
4. 测试结果
四、SpringMVC
接受浏览器发送的请求,并响应浏览器数据

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/1297.html