
EM算法(Expectation Maximization Algorithm)详解
- 主要内容
- EM算法简介
- 预备知识
- 极大似然估计
- Jensen不等式
- EM算法详解
- 问题描述
- EM算法推导
- EM算法流程
- EM算法优缺点以及应用
1、EM算法简介
EM算法是一种迭代优化策略,由于它的计算方法中每一次迭代都分两步,其中一个为期望步(E步),另一个为极大步(M步),所以算法被称为EM算法(Expectation Maximization Algorithm)。EM算法受到缺失思想影响,最初是为了解决数据缺失情况下的参数估计问题,其算法基础和收敛有效性等问题在Dempster,Laird和Rubin三人于1977年所做的文章Maximum likelihood from incomplete data via the EM algorithm中给出了详细的阐述。其基本思想是:首先根据己经给出的观测数据,估计出模型参数的值;然后再依据上一步估计出的参数值估计缺失数据的值,再根据估计出的缺失数据加上之前己经观测到的数据重新再对参数值进行估计,然后反复迭代,直至最后收敛,迭代结束。
EM算法作为一种数据添加算法,在近几十年得到迅速的发展,主要源于当前科学研究以及各方面实际应用中数据量越来越大的情况下,经常存在数据缺失或者不可用的的问题,这时候直接处理数据比较困难,而数据添加办法有很多种,常用的有神经网络拟合、添补法、卡尔曼滤波法等等,但是EM算法之所以能迅速普及主要源于它算法简单,稳定上升的步骤能非常可靠地找到“最优的收敛值”。随着理论的发展,EM算法己经不单单用在处理缺失数据的问题,运用这种思想,它所能处理的问题更加广泛。有时候缺失数据并非是真的缺少了,而是为了简化问题而采取的策略,这时EM算法被称为数据添加技术,所添加的数据通常被称为“潜在数据”,复杂的问题通过引入恰当的潜在数据,能够有效地解决我们的问题。

2、预备知识
介绍EM算法之前,我们需要介绍极大似然估计以及Jensen不等式。
2.1 极大似然估计
(1)举例说明:经典问题——学生身高问题
我们需要调查我们学校的男生和女生的身高分布。 假设你在校园里随便找了100个男生和100个女生。他们共200个人。将他们按照性别划分为两组,然后先统计抽样得到的100个男生的身高。假设他们的身高是服从正态分布的。但是这个分布的均值μμ和方差σ2σ2我们不知道,这两个参数就是我们要估计的。记作θ=[μ,σ]Tθ=[μ,σ]T。
问题:我们知道样本所服从的概率分布的模型和一些样本,需要求解该模型的参数。如图1

图1
我们已知的有两个:样本服从的分布模型、随机抽取的样本;我们未知的有一个:模型的参数。根据已知条件,通过极大似然估计,求出未知参数。总的来说:极大似然估计就是用来估计模型参数的统计学方法。
(2)如何估计
问题数学化:设样本集 X=x1,x2,…,xNX=x1,x2,…,xN,其中 N=100N=100 , p(xi|θ)p(xi|θ)为概率密度函数,表示抽到男生 xixi(的身高)的概率。由于100个样本之间独立同分布,所以我同时抽到这100个男生的概率就是他们各自概率的乘积,也就是样本集 XX中各个样本的联合概率,用下式表示:
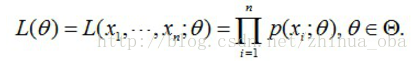
这个概率反映了,在概率密度函数的参数是 θθ时,得到 XX这组样本的概率。 我们需要找到一个参数 θθ,使得抽到 XX这组样本的概率最大,也就是说需要其对应的似然函数 L(θ)L(θ)最大。满足条件的 θθ叫做 θθ的最大似然估计量,记为
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/129078.html