
哈夫曼编码,又称为 Huffman Coding
是一种可变长编码( VLC, variable length coding))方式,比起定长编码的 ASCII 编码来说,哈夫曼编码能节省很多的空间,因为每一个字符出现的频率不是一致的;
是一种用于无损数据压缩的熵编码算法,通常用于压缩重复率比较高的字符数据。
如果我们通过转换成ASCII码对应的二进制数据将字符串 BCAADDDCCACACAC 通过二进制编码进行传输,那么一个字符传输的二进制位数为 8bits,那么总共需要 120 个二进制位;而如果使用哈夫曼编码,该串字符可压缩至 28位。

讯享网
哈夫曼编码方法

哈夫曼编码首先会使用字符的频率创建一棵树,然后通过这个树的结构为每个字符生成一个特定的编码,出现频率高的字符使用较短的编码,出现频率低的则使用较长的编码,这样就会使编码之后的字符串平均长度降低,从而达到数据无损压缩的目的。
1. 计算字符串中每个字符的频率:

2. 按照字符出现的频率进行排序,组成一个队列 Q
出现频率最低的在前面,出现频率高的在后面。

(1)首先创建一个空节点 z,将最小频率的字符分配给 z 的左侧,并将频率排在第二位的分配给 z 的右侧,然后将 z 赋值为两个字符频率的和;然后从队列 Q 中删除 B 和 D,并将它们的和添加到队列中,上图中 * 表示的位置。
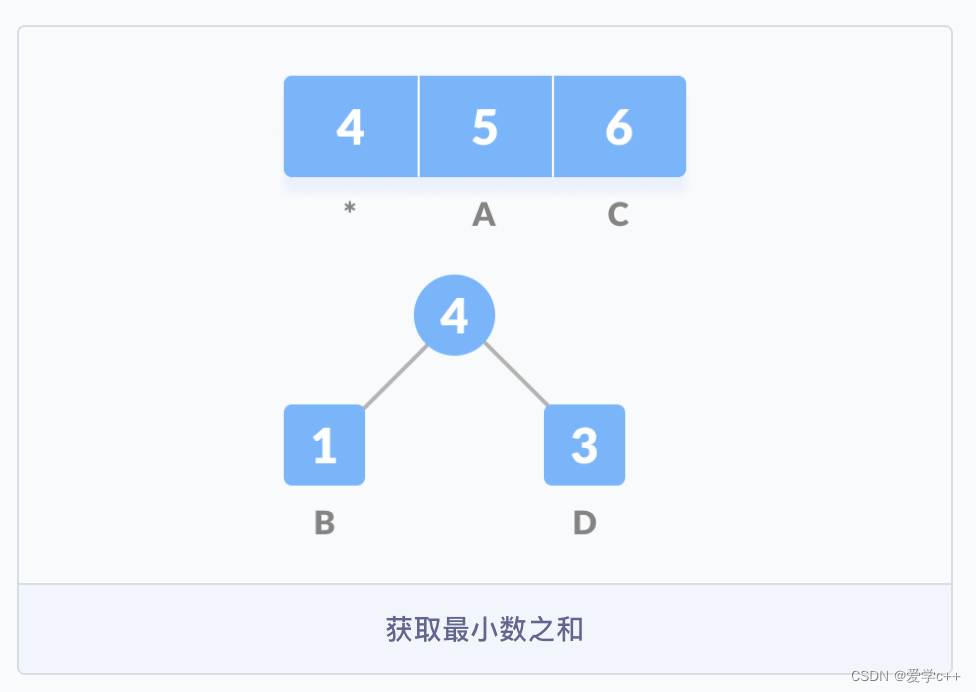
(2)紧接着,重新创建一个空的节点 z,并将 4 作为左侧的节点,频率为 5 的 A 作为右侧的节点,4 与 5 的和作为父节点,并把这个和按序加入到队列中,再根据频率从小到大构建树结构(小的在左)。

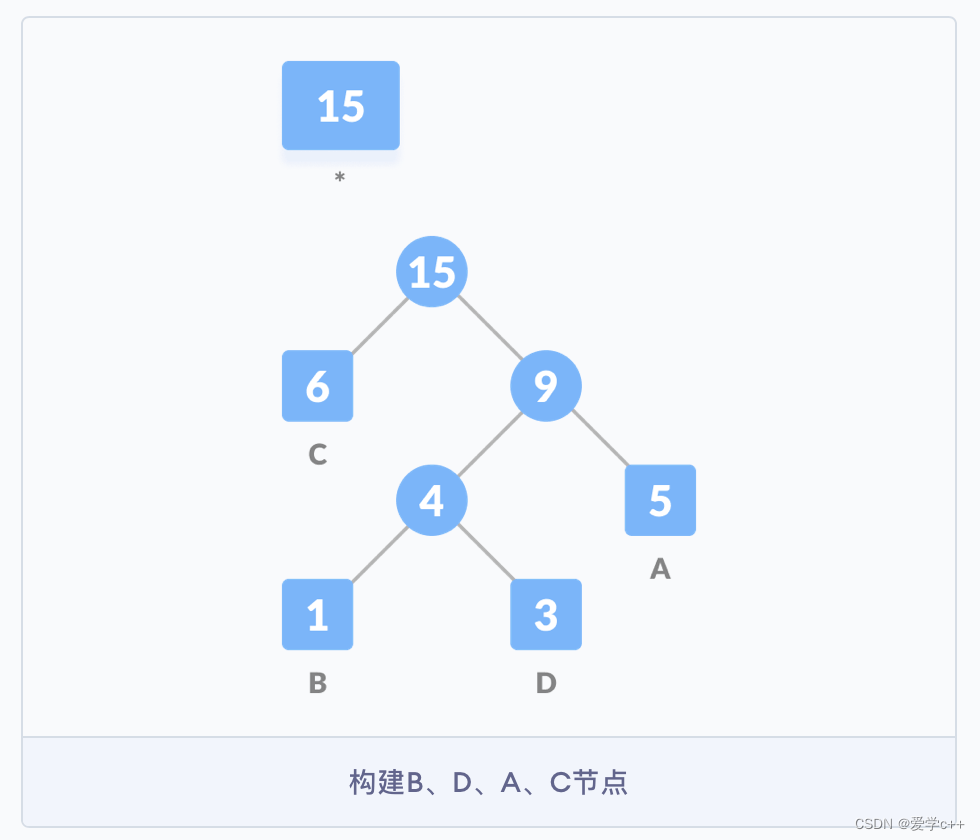
(3)继续按照之前的思路构建树,直到所有的字符都出现在树的节点中,哈弗曼树构建完成。
节点的带权路径长度为从根节点到该节点的路径长度与节点权值的乘积。
该二叉树的带权路径长度 WPL = 6 * 1 + 5 * 2 + 3 * 3 + 1 * 3 = 28。

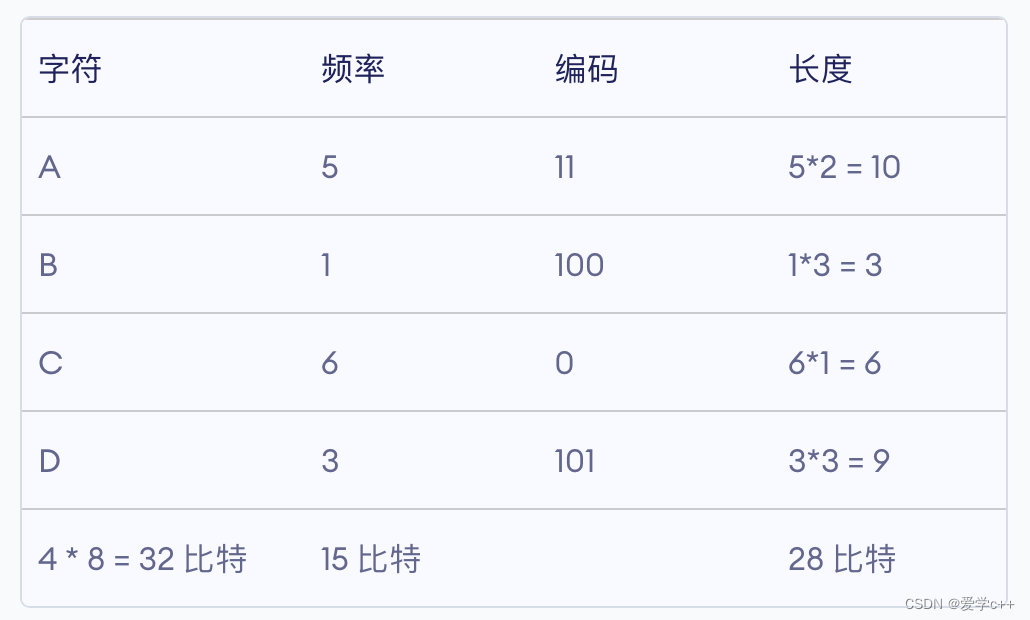
因此各个字母的编码分别为:
| A | B | C | D |
| 11 | 100 | 0 | 101 |
00000000000 讯享网

编码之后为:
讯享网
即字符占用的 32 比特和 频率占用的 15 比特也需要传递过去。
总体上,编码后比特数为32 + 15 + 28 = 75,比 120 比特少了 45 个,效率还是非常高的。
从本质上讲,哈夫曼编码是将最宝贵的资源(最短的编码)给出现概率最多的数据。
在上面的例子中,C 出现的频率最高,它的编码为 0,就省下了不少空间。
特点
哈夫曼树和编码都不唯一!只有树的WPL(带权路径长度)才是唯一的!
哈夫曼编码有两个特点:
带权路径长度WPL最短且唯一;
编码互不为前缀(一个编码不是另一个编码的开头)。
为什么通过哈夫曼编码后得到的二进制码不会有前缀的问题呢?
这是因为在哈夫曼树中,每个字母对应的节点都是叶子节点,而他们对应的二进制码是由根节点到各自节点的路径所决定的,正因为是叶子节点,每个节点的路径不可能和其他节点有前缀的关系。
哈夫曼编码(Huffman Coding)多图详细解析
哈夫曼编码的算法实现
算法描述:
void CreatHuffmanCode(HuffmanTree HT, HuffmanCode &HC, int n) { //从叶子到根逆向求每个字符的赫夫曼编码,存储在编码表HC中 int i, start, c, f; HC = new char*[n + 1]; // 分配n个字符编码的头指针矢量 char *cd = new char[n]; // 分配临时存放编码的动态数组空间 cd[n - 1] = '\0'; // 编码结束符 for (i = 1; i <= n; ++i) { // 逐个字符求赫夫曼编码 start = n - 1; // start开始时指向最后,即编码结束符位置 c = i; f = HT[i].parent; // f指向结点c的双亲结点 while (f != 0) { // 从叶子结点开始向上回溯,直到根结点 --start; // 回溯一次start向前指一个位置 if (HT[f].lchild == c) cd[start] = '0'; // 结点c是f的左孩子,则生成代码0 else cd[start] = '1'; // 结点c是f的右孩子,则生成代码1 c = f; f = HT[f].parent; // 继续向上回溯 } // 求出第i个字符的编码 HC[i] = new char[n - start]; // 为第i 个字符编码分配空间 strcpy(HC[i], &cd[start]); // 将求得的编码从临时空间cd复制到HC的当前行中 } delete cd; // 释放临时空间 }代码实现:
讯享网#include <iostream> #include <cstdlib> #include <string> using namespace std; typedef struct { int weight; int parent, lchild, rchild; }HTNode, *HuffmanTree; typedef char HuffmanCode; void Select(HuffmanTree HT, int len, int &s1, int &s2) { int i, min1 = 0x3f3f3f3f, min2 = 0x3f3f3f3f; // 先赋予最大值 for (i = 1; i <= len; i++) { if (HT[i].weight < min1 && HT[i].parent == 0) { min1 = HT[i].weight; s1 = i; } } int temp = HT[s1].weight; // 将原值存放起来,然后先赋予最大值,防止s1被重复选择 HT[s1].weight = 0x3f3f3f3f; for (i = 1; i <= len; i++) { if (HT[i].weight < min2 && HT[i].parent == 0) { min2 = HT[i].weight; s2 = i; } } HT[s1].weight = temp;// 恢复原来的值 } void CreatHuffmanTree(HuffmanTree &HT, int n) { //构造赫夫曼树HT int m, s1, s2, i; if (n <= 1) return; m = 2 * n - 1; HT = new HTNode[m + 1]; // 0号单元未用,所以需要动态分配m+1个单元,HT[m]表示根结点 for (i = 1; i <= m; ++i) // 将1~m号单元中的双亲、左孩子,右孩子的下标都初始化为0 { HT[i].parent = 0; HT[i].lchild = 0; HT[i].rchild = 0; } cout << "请输入叶子结点的权值:\n"; for (i = 1; i <= n; ++i) // 输入前n个单元中叶子结点的权值 cin >> HT[i].weight; /*――――――――――初始化工作结束,下面开始创建赫夫曼树――――――――――*/ // 通过n-1次的选择、删除、合并来创建赫夫曼树 for (i = n + 1; i <= m; ++i) { Select(HT, i - 1, s1, s2); // 在HT[k](1≤k≤i-1)中选择两个其双亲域为0且权值最小的结点,并返回它们在HT中的序号s1和s2 HT[s1].parent = i; HT[s2].parent = i; // 得到新结点i,从森林中删除s1,s2,将s1和s2的双亲域由0改为i HT[i].lchild = s1; HT[i].rchild = s2; // s1,s2分别作为i的左右孩子 HT[i].weight = HT[s1].weight + HT[s2].weight; //i 的权值为左右孩子权值之和 } } void CreatHuffmanCode(HuffmanTree HT, HuffmanCode &HC, int n) { //从叶子到根逆向求每个字符的赫夫曼编码,存储在编码表HC中 int i, start, c, f; HC = new char*[n + 1]; // 分配n个字符编码的头指针矢量 char *cd = new char[n]; // 分配临时存放编码的动态数组空间 cd[n - 1] = '\0'; // 编码结束符 for (i = 1; i <= n; ++i) { // 逐个字符求赫夫曼编码 start = n - 1; // start开始时指向最后,即编码结束符位置 c = i; f = HT[i].parent; // f指向结点c的双亲结点 while (f != 0) { // 从叶子结点开始向上回溯,直到根结点 --start; // 回溯一次start向前指一个位置 if (HT[f].lchild == c) cd[start] = '0'; // 结点c是f的左孩子,则生成代码0 else cd[start] = '1'; // 结点c是f的右孩子,则生成代码1 c = f; f = HT[f].parent; // 继续向上回溯 } // 求出第i个字符的编码 HC[i] = new char[n - start]; // 为第i 个字符编码分配空间 strcpy(HC[i], &cd[start]); // 将求得的编码从临时空间cd复制到HC的当前行中 } delete cd; // 释放临时空间 } void show(HuffmanTree HT, HuffmanCode HC) { for (int i = 1; i <= sizeof(HC) + 1; i++) cout << HT[i].weight << "编码为" << HC[i] << endl; } int main() { HuffmanTree HT; HuffmanCode HC; int n; cout << "请输入叶子结点的个数:\n"; cin >> n; //输入赫夫曼树的叶子结点个数 CreatHuffmanTree(HT, n); CreatHuffmanCode(HT, HC, n); show(HT, HC); system("pause"); return 0; }
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/128654.html