
一、查找的基本概念
1、列表:由同一类型的数据元素组成的集合。
2、关键码:数据元素中的某个数据项,可以标识列表中的一个或一组数据元素。
3、键值:关键码的值。
4、主关键码:可以唯一地标识一个记录的关键码。
5、次关键码:不能唯一地标识一个记录的关键码。
6、查找 :在具有相同类型的记录构成的集合中找出满足给定条件的记录。
7、查找的结果 :若在查找集合中找到了与给定值相匹配的记录,则称查找成功;否则,称查找失败。
(一)静态查找 :不涉及插入和删除操作的查找 。
静态查找适用于:查找集合一经生成,便只对其进行查找,而不进行插入和删除操作; 或经过一段时间的查找之后,集中地进行插入和删除等修改操作;
(二)动态查找 :涉及插入和删除操作的查找。
动态查找适用于:查找与插入和删除操作在同一个阶段进行,例如当查找成功时,要删除查找到的记录,当查找不成功时,要插入被查找的记录。
二、查找结构
查找结构 :面向查找操作的数据结构 ,即查找基于的数据结构。
线性表:适用于静态查找,主要采用顺序查找技术、折半查找技术。
树表:适用于动态查找,主要采用二叉排序树的查找技术。
散列表:静态查找和动态查找均适用,主要采用散列技术。
查找算法的性能 :
查找算法时间性能通过关键码的比较次数来度量。
平均查找长度:将查找算法进行的关键码的比较次数的数学期望值定义为平均查找长度。计算公式为:
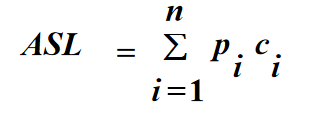
讯享网
三、线性表的查找技术
(一)顺序查找:
普通的顺序查找方法
带监视哨的顺序查找方法
#include using namespace std; const int MaxSize = 100; class LineSearch{
public: LineSearch(int a[ ], int n); //构造函数 ~LineSearch( ) {
} //析构函数为空 int SeqSearch(int k); //顺序查找 int BinSearch1(int k); //折半非递归查找 int BinSearch2(int low, int high, int k); //折半递归查找 private: int data[MaxSize]; //查找集合为整型 int length; //查找集合的元素个数 }; LineSearch :: LineSearch(int a[ ], int n){
for (int i = 0; i < n; i++) data[i+1] = a[i]; //查找集合从下标1开始存放 length = n; } 讯享网
顺序查找 (线性查找)
(二)基本思想:
从线性表的一端向另一端逐个将关键码与给定值进行比较,若相等,则查找成功,给出该记录在表中的位置;若整个表检测完仍未找到与给定值相等的关键码,则查找失败,给出失败信息。
讯享网int LineSearch :: SeqSearch(int k) {
i=n; while (i>0 && data[i]!=k) i--; return i; }
(二)改进的顺序查找
基本思想:设置“哨兵”。
哨兵就是待查值,将哨兵放在查找方向的尽头处,免去了在查找过程中每一次比较后都要判断查找位置是否越界,从而提高查找速度。

int LineSearch :: SeqSearch(int k) {
int i = length; //从数组高端开始比较 data[0] = k; //设置哨兵 while (data[i] != k) //不用判断下标i是否越界 i--; return i; } 1、记录每个数据的访问频率,把访问频率高的数据移向顺序表的右端
可以减少查找成功时所进行的比较次数,提高效率
2、构造有序的顺序表
减少查找失败时所进行的比较次数,提高查找效率
讯享网int LinkSearch::SeqSearch2(Node *first, int k){
Node *p; int count=0;//记录比较的次数 p=first->next; int j=1;//记录数据在表中的位置 while (p && p->data != k) {
p=p->next; j++; count++;} if (!p){
cout<<“查找失败,比较的次数为:"<<count<<endl; return 0; } else{
cout<<“\n”<<“查找成功,比较的次数为:"<<count<<endl; return j; } }
(三)顺序查找的优点:
算法简单而且使用面广。
对表中记录的存储结构没有任何要求,顺序存储和链接存储均可;
对表中记录的有序性也没有要求,无论记录是否按关键码有序均可。
顺序查找的缺点:
平均查找长度较大,特别是当待查找集合中元素较多时,查找效率较低。
四、折半查找
1、基本思想:
在有序表中(low, high,low<=high),
取中间记录作为比较对象,
若给定值与中间记录的关键码相等,则查找成功;
若给定值小于中间记录的关键码,则在中间记录的左半区继续查找;
若给定值大于中间记录的关键码,则在中间记录的右半区继续查找。
不断重复上述过程,直到查找成功,或所查找的区域无记录,查找失败。

int LineSearch :: BinSearch1(int k){
int mid, low = 1, high = length; //初始查找区间是[1, n] while (low <= high) {
//当区间存在时 mid = (low + high) / 2; if (k < data[mid]) high = mid - 1; else if (k > data[mid]) low = mid + 1; else return mid; //查找成功,返回元素序号 } return 0; //查找失败,返回0 } int LineSearch :: BinSearch2(int low, int high, int k){
if (low > high) return 0; //递归的边界条件 else {
int mid = (low + high) / 2; if (k < data[mid]) return BinSearch2(low, mid-1, k); else if (k > data[mid]) return BinSearch2(mid+1, high, k); else return mid; //查找成功,返回序号 } } 2、折半查找的判定树
判定树:折半查找的过程可以用二叉树来描述,
树中的每个结点对应有序表中的一个记录,
结点的值为该记录在表中的位置。
通常称这个描述折半查找过程的二叉树为折半查找判定树,简称判定树。
判定树的构造方法
⑴ 当n=0时,折半查找判定树为空;
⑵ 当n>0时,
折半查找判定树的根结点为mid=(n+1)/2,
根结点的左子树是与有序表r[1] ~ r[mid-1]相对应的折半查找判定树,
根结点的右子树是与r[mid+1] ~ r[n]相对应的折半查找判定树。
判定树的特点:
任意两棵折半查找判定树,若它们的结点个数相同,则它们的结构完全相同
具有n个结点的折半查找树的高度为
任意结点的左右子树中结点个数最多相差1
任意结点的左右子树的高度最多相差1
任意两个叶子所处的层次最多相差1
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/12836.html