
案例:
模拟学生成绩信息写入es数据库,包括姓名、性别、科目、成绩。
1、单线程使用helper
一次性写入10000*1000条数据,本人测试耗时680秒。
示例代码:
from elasticsearch import Elasticsearch from elasticsearch import helpers from datetime import datetime import random import time es = Elasticsearch(hosts='http://192.168.124.49:9200') # print(es) names = ['刘一', '陈二', '张三', '李四', '王五', '赵六', '孙七', '周八', '吴九', '郑十'] sexs = ['男', '女'] age = [25, 28, 29, 32, 31, 26, 27, 30] subjects = ['语文', '数学', '英语', '生物', '地理'] grades = [85, 77, 96, 74, 85, 69, 84, 59, 67, 69, 86, 96, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86] character = ['自信但不自负,不以自我为中心', '努力、积极、乐观、拼搏是我的人生信条', '抗压能力强,能够快速适应周围环境', '敢做敢拼,脚踏实地;做事认真负责,责任心强', '爱好所学专业,乐于学习新知识;对工作有责任心;踏实,热情,对生活充满激情', '主动性强,自学能力强,具有团队合作意识,有一定组织能力', '忠实诚信,讲原则,说到做到,决不推卸责任', '有自制力,做事情始终坚持有始有终,从不半途而废', '肯学习,有问题不逃避,愿意虚心向他人学习', '愿意以谦虚态度赞扬接纳优越者,权威者', '会用100%的热情和精力投入到工作中;平易近人', '为人诚恳,性格开朗,积极进取,适应力强、勤奋好学、脚踏实地', '有较强的团队精神,工作积极进取,态度认真'] create_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S') datas = [] start = time.time() # 开始批量写入es数据库 # 批量写入数据 for j in range(1000): print(j) action = [ { "_index": "grade", "_type": "doc", "_id": i, "_source": { "id": i, "name": random.choice(names), "sex": random.choice(sexs), "age": random.choice(age), "character": random.choice(character), "subject": random.choice(subjects), "grade": random.choice(grades), "create_time": create_time } } for i in range(10000 * j, 10000 * j + 10000) ] helpers.bulk(es, action) end = time.time() print('花费时间:', end - start) 讯享网
运行结果:

2、多线程使用helper
一次性写入10000*1000条数据,本人测试耗时489秒。一次性写入10000*2000条数据,测试耗时1002秒。
示例代码:
讯享网from elasticsearch import Elasticsearch from elasticsearch import helpers from datetime import datetime from queue import Queue import threading import random import time es = Elasticsearch(hosts='http://192.168.124.49:9200') # print(es) names = ['刘一', '陈二', '张三', '李四', '王五', '赵六', '孙七', '周八', '吴九', '郑十'] sexs = ['男', '女'] age = [25, 28, 29, 32, 31, 26, 27, 30] subjects = ['语文', '数学', '英语', '生物', '地理'] grades = [85, 77, 96, 74, 85, 69, 84, 59, 67, 69, 86, 96, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86] character = ['自信但不自负,不以自我为中心', '努力、积极、乐观、拼搏是我的人生信条', '抗压能力强,能够快速适应周围环境', '敢做敢拼,脚踏实地;做事认真负责,责任心强', '爱好所学专业,乐于学习新知识;对工作有责任心;踏实,热情,对生活充满激情', '主动性强,自学能力强,具有团队合作意识,有一定组织能力', '忠实诚信,讲原则,说到做到,决不推卸责任', '有自制力,做事情始终坚持有始有终,从不半途而废', '肯学习,有问题不逃避,愿意虚心向他人学习', '愿意以谦虚态度赞扬接纳优越者,权威者', '会用100%的热情和精力投入到工作中;平易近人', '为人诚恳,性格开朗,积极进取,适应力强、勤奋好学、脚踏实地', '有较强的团队精神,工作积极进取,态度认真'] create_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S') datas = [] def save_to_es(num): """批量写入数据到es数据库""" action = [ { "_index": "grade2", "_type": "doc", "_id": i, "_source": { "id": i, "name": random.choice(names), "sex": random.choice(sexs), "age": random.choice(age), "character": random.choice(character), "subject": random.choice(subjects), "grade": random.choice(grades), "create_time": create_time } } for i in range(10000 * num, 10000 * num + 10000) ] helpers.bulk(es, action) def run(): global queue while queue.qsize() > 0: num = queue.get() print(num) save_to_es(num) if __name__ == '__main__': start = time.time() queue = Queue() # 序号数据进队列 for num in range(1000): queue.put(num) # 多线程执行程序 consumer_lst = [] for _ in range(10): thread = threading.Thread(target=run) thread.start() consumer_lst.append(thread) for consumer in consumer_lst: consumer.join() end = time.time() print('花费时间:', end - start)
运行结果:

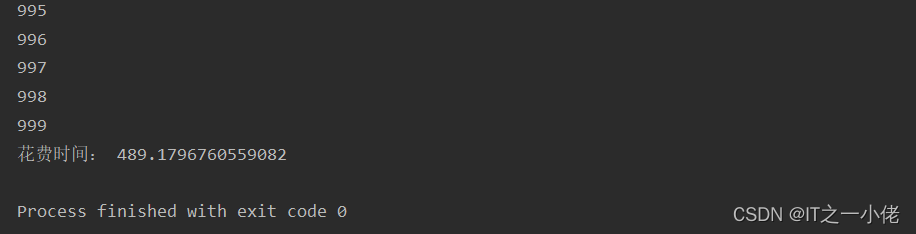
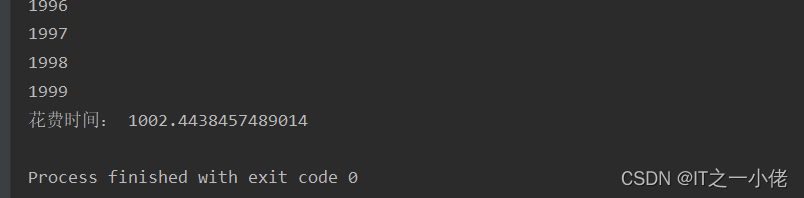
对比于单线程,开启多个线程并不是多倍的提高速度,只是比单线程稍微快点。
3、多进程使用helper
一次性写入10000*1000条数据,本人测试耗时515秒。
示例代码:
from elasticsearch import Elasticsearch from elasticsearch import helpers from multiprocessing import Pool from datetime import datetime import random import time es = Elasticsearch(hosts='http://192.168.124.49:9200') # print(es) names = ['刘一', '陈二', '张三', '李四', '王五', '赵六', '孙七', '周八', '吴九', '郑十'] sexs = ['男', '女'] age = [25, 28, 29, 32, 31, 26, 27, 30] subjects = ['语文', '数学', '英语', '生物', '地理'] grades = [85, 77, 96, 74, 85, 69, 84, 59, 67, 69, 86, 96, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86] character = ['自信但不自负,不以自我为中心', '努力、积极、乐观、拼搏是我的人生信条', '抗压能力强,能够快速适应周围环境', '敢做敢拼,脚踏实地;做事认真负责,责任心强', '爱好所学专业,乐于学习新知识;对工作有责任心;踏实,热情,对生活充满激情', '主动性强,自学能力强,具有团队合作意识,有一定组织能力', '忠实诚信,讲原则,说到做到,决不推卸责任', '有自制力,做事情始终坚持有始有终,从不半途而废', '肯学习,有问题不逃避,愿意虚心向他人学习', '愿意以谦虚态度赞扬接纳优越者,权威者', '会用100%的热情和精力投入到工作中;平易近人', '为人诚恳,性格开朗,积极进取,适应力强、勤奋好学、脚踏实地', '有较强的团队精神,工作积极进取,态度认真'] create_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S') datas = [] def save_to_es(num): """批量写入数据到es数据库""" action = [ { "_index": "grade3", "_type": "doc", "_id": i, "_source": { "id": i, "name": random.choice(names), "sex": random.choice(sexs), "age": random.choice(age), "character": random.choice(character), "subject": random.choice(subjects), "grade": random.choice(grades), "create_time": create_time } } for i in range(10000 * num, 10000 * num + 10000) ] helpers.bulk(es, action) def multi_run(num): for i in range(100 * num, 100 * num + 100): print(i) save_to_es(i) if __name__ == '__main__': start = time.time() # 多进程执行程序 p = Pool(processes=10, maxtasksperchild=10) for i in range(10): p.apply_async(func=multi_run, args=(i, )) # 进程池接收任务 p.close() # 关闭进程池 ==》 不接受任务 p.join() # 等待子进程执行完毕,父进程再执行 end = time.time() print('花费时间:', end - start) 运行结果:
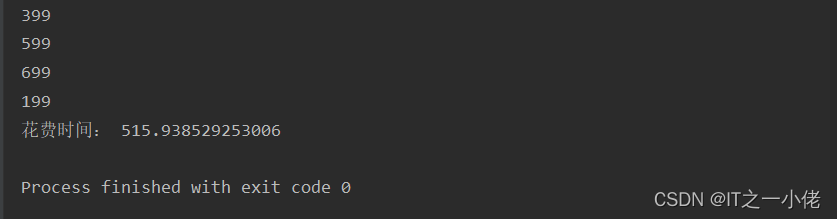
通过上述案例分析,es中的helper使用多线程或多进程并不能成倍的提高速度,只是比单线程速度有所提高!

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/128260.html