
Flink中如何判断需要几个slot以及任务链的划分
1. 设置全局的并发
object Flink01_WordCount_Chain_Scala {
def main(args: Array[String]): Unit = {
// 1.创建执行环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment // 设置并行度 env.setParallelism(1) // 2.从socket读取数据 val input: DataStream[String] = env.socketTextStream("hadoop01", 9999) // 3.将数据压平 val flatMapDS: DataStream[String] = input.flatMap(_.split(" ")) // 4.转换为元组 val lineToTupleDS: DataStream[(String, Int)] = flatMapDS.map((_, 1)) // 5.分组 val keyedDS: KeyedStream[(String, Int), String] = lineToTupleDS.keyBy(_._1) // 6.聚合 val result: DataStream[(String, Int)] = keyedDS.sum(1) // 7.打印测试 result.print() // 8.提交 env.execute() } } 讯享网
此时提交任务到Flink中,可以看到的是两个任务链,共用1个slot。
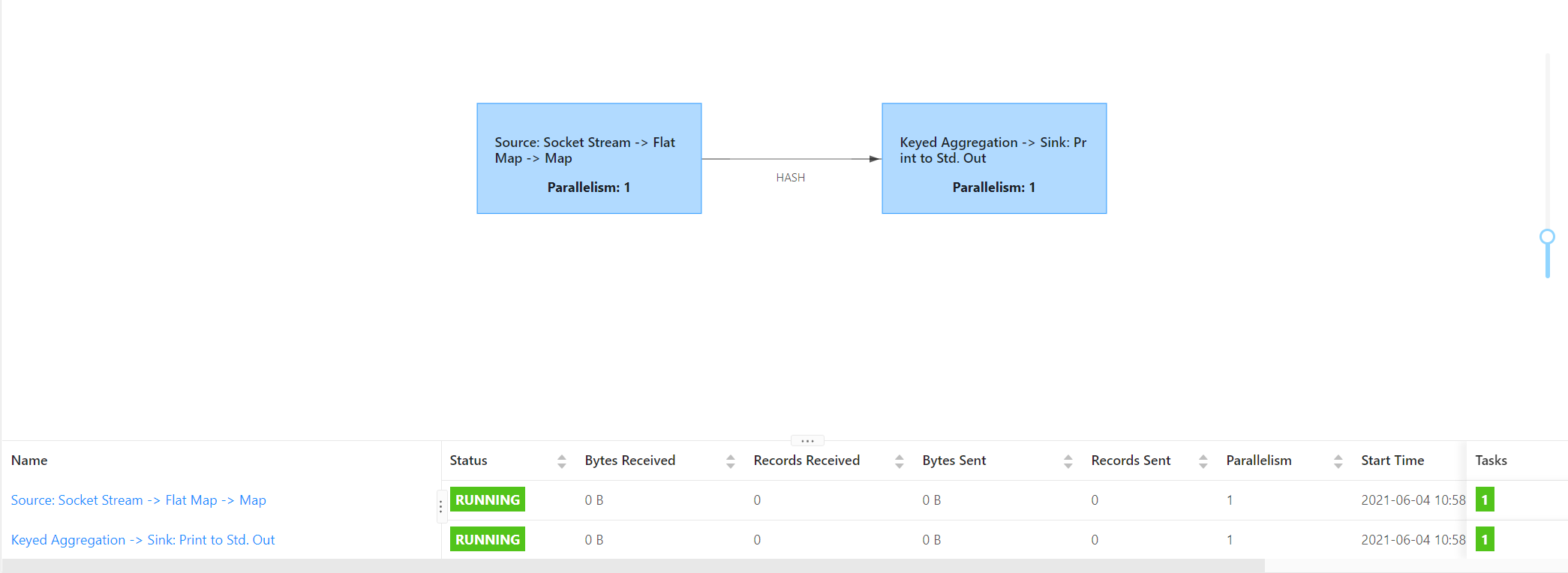
2. 给某个算子单独设置并发
讯享网object Flink01_WordCount_Chain_Scala {
def main(args: Array[String]): Unit = {
// 1.创建执行环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment // 设置并行度 env.setParallelism(1) // 2.从socket读取数据 val input: DataStream[String] = env.socketTextStream("hadoop01", 9999) // 3.将数据压平 val flatMapDS: DataStream[String] = input.flatMap(_.split(" ")).setParallelism(2) // 4.转换为元组 val lineToTupleDS: DataStream[(String, Int)] = flatMapDS.map((_, 1)) // 5.分组 val keyedDS: KeyedStream[(String, Int), String] = lineToTupleDS.keyBy(_._1) // 6.聚合 val result: DataStream[(String, Int)] = keyedDS.sum(1) // 7.打印测试 result.print() // 8.提交 env.execute() } }
全局并发为1,单独设置flatMap算子并发为2,此时提交任务到Flink集群中,可以看到4个任务链,共用2个slot。
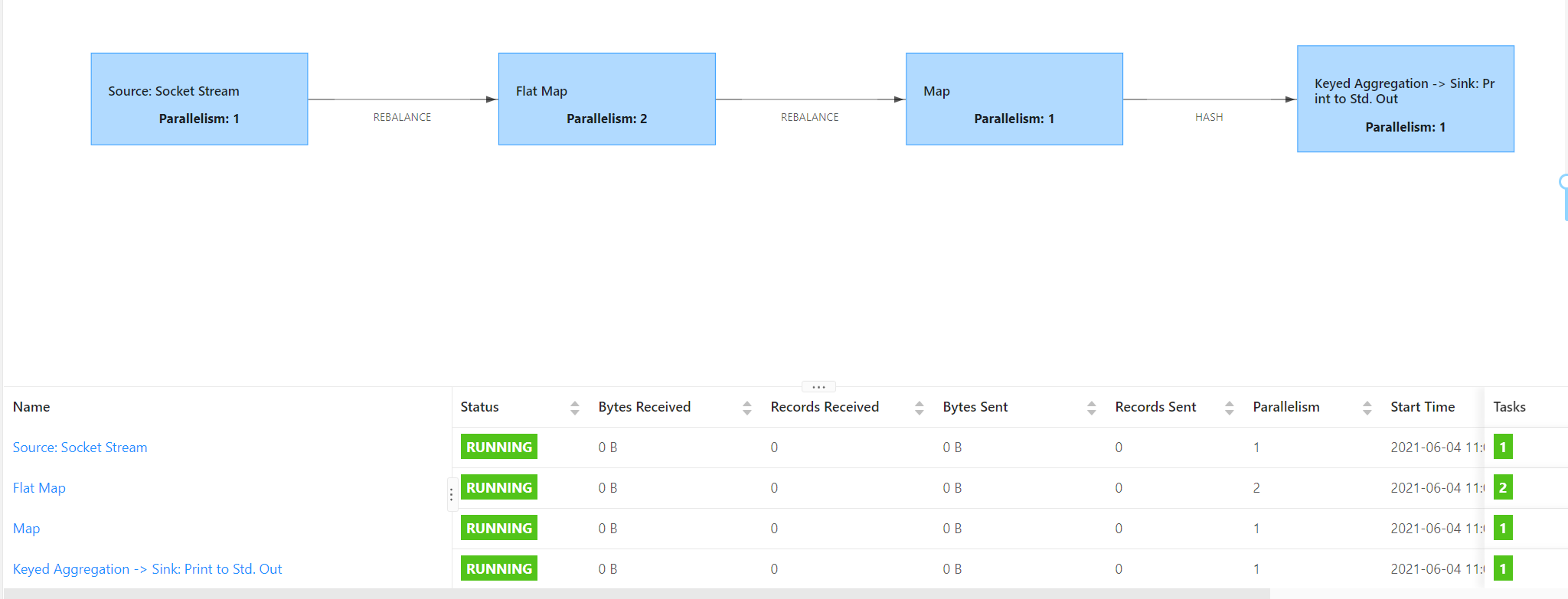
注意:也就是说任务链的划分和是否进行keyBy等shuffle操作有关,如果在并行度一致的情况下,只要进行了keyBy等shuffle操作,就会划分任务链。如果对于并行度不同的情况下,发生并行度改变时也会增加任务链个数。对于Slot而言,由于所有的任务都在同一个共享组中,所以说Slot的个数等于并行度最大的算子所使用的Slot。
3. 设置不同的共享组
object Flink01_WordCount_Chain_Scala {
def main(args: Array[String]): Unit = {
// 1.创建执行环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment // 设置并行度 env.setParallelism(1) // 2.从socket读取数据 val input: DataStream[String] = env.socketTextStream("hadoop01", 9999) // 3.将数据压平 val flatMapDS: DataStream[String] = input.flatMap(_.split(" ")).slotSharingGroup("group1") // 4.转换为元组 val lineToTupleDS: DataStream[(String, Int)] = flatMapDS.map((_, 1)) // 5.分组 val keyedDS: KeyedStream[(String, Int), String] = lineToTupleDS.keyBy(_._1) // 6.聚合 val result: DataStream[(String, Int)] = keyedDS.sum(1).slotSharingGroup("group2") // 7.打印测试 result.print() // 8.提交 env.execute() } } 给其中连个算子设置不同的共享组,由于共享组是下一个算子继承上一个算子的共享组,设置flatMap算子的共享组为group1,此时由于继承关系map算子的共享组也为group1,同理sum和print算子也是处于同一个共享组group2。由于共享组不同,所以要划分任务链,此时任务链个数为3,同时由于全局的并行度为1,共享组内最大的并行度为1,所以需要3个slot。

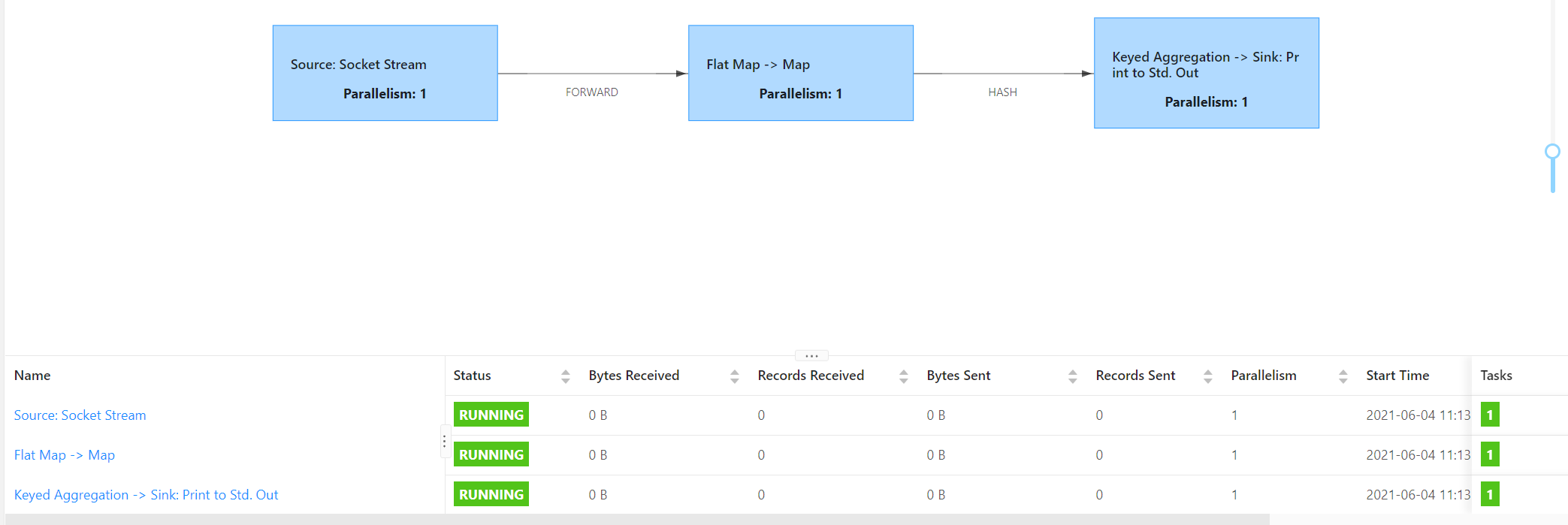
4. 设置不同的共享组,组内设置并行度
讯享网object Flink01_WordCount_Chain_Scala {
def main(args: Array[String]): Unit = {
// 1.创建执行环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment // 设置并行度 env.setParallelism(1) // 2.从socket读取数据 val input: DataStream[String] = env.socketTextStream("hadoop01", 9999) // 3.将数据压平 val flatMapDS: DataStream[String] = input.flatMap(_.split(" ")).slotSharingGroup("group1") // 4.转换为元组 val lineToTupleDS: DataStream[(String, Int)] = flatMapDS.map((_, 1)).setParallelism(2) // 5.分组 val keyedDS: KeyedStream[(String, Int), String] = lineToTupleDS.keyBy(_._1) // 6.聚合 val result: DataStream[(String, Int)] = keyedDS.sum(1).slotSharingGroup("group2") // 7.打印测试 result.print() // 8.提交 env.execute() } }
此时一共3个共享组,至少需要三个slot,由于共享组group1中的最大并行度算子是2,所以需要4个slot,同时也是4个任务链。
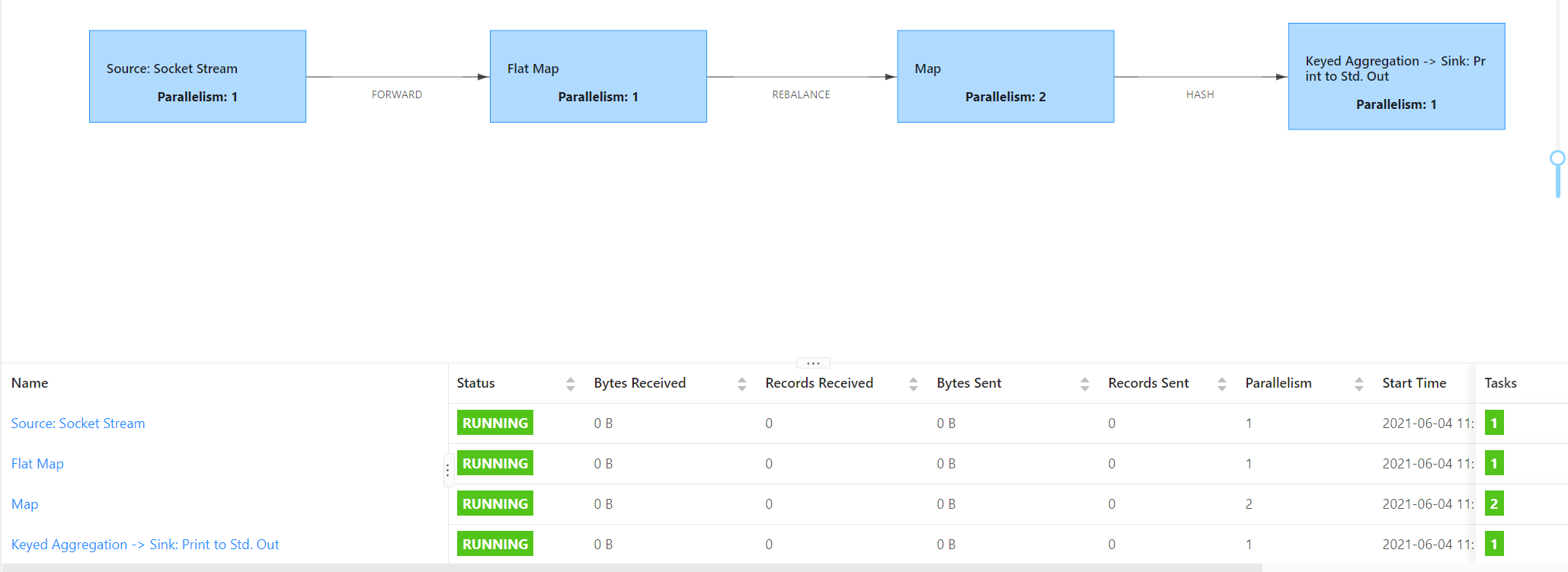
总结:从以上的示例可以看出,slot的任务等于共享组内最大并行度之和。任务链的切分和是否进行shuffle等操作以及并行度一致有关。并行度不一致切分任务链,进行keyBy等shuffle操作也会切分任务链。
5. 其它方式切分任务链
通过startNewChain或者disableOperatorChaining可以让某一个算子开启一个新的任务链或禁用任务链,也可以实现切分任务链。
bject Flink01_WordCount_Chain_Scala {
def main(args: Array[String]): Unit = {
// 1.创建执行环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment // 设置并行度 env.setParallelism(1) // 2.从socket读取数据 val input: DataStream[String] = env.socketTextStream("hadoop01", 9999) // 3.将数据压平 val flatMapDS: DataStream[String] = input.flatMap(_.split(" ")).startNewChain() // 4.转换为元组 val lineToTupleDS: DataStream[(String, Int)] = flatMapDS.map((_, 1)) // 5.分组 val keyedDS: KeyedStream[(String, Int), String] = lineToTupleDS.keyBy(_._1) // 6.聚合 val result: DataStream[(String, Int)] = keyedDS.sum(1) // 7.打印测试 result.print() // 8.提交 env.execute() } } 最后的结果是socket是一个任务链,flatMap和map合并成一个任务链,keyBy后合并成一个任务链。从flatMap重新开始一个新的任务链。如果使用disableOperatorChaining将会把flatMap单独切分一个任务链,不会和map以及socket合并。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/125913.html