
目录
整理此文的原因
从显卡驱动说起(这里只针对N卡)
然后再说cuda
再看cuDNN
再看看tensorRT
下边看下王鑫宇大佬的trtx:
然后看一下deepStream
整理此文的原因
因为模型部署优化涉及到的组件比如显卡驱动 cuda cuDNNtensorRT trtx deepStream等大多都会有互相之间的版本对应关系,每次都要查各种组件官网看版本适配,这里我们罗列一些组件对应关系,省的去各大官网查询了。
从显卡驱动说起(这里只针对N卡)
官网地址:NVIDIA 驱动程序下载

可以看到跟显卡型号和系统类别有关,跟系统版本无关,另外如果是linux系统,不区分你用的是centos还是ubuntu。
然后再说cuda
首先我们应该知道cuda Toolkit只和显卡驱动版本有关,详情请见:显卡和cuda版本、cuda驱动对应关系_RayChiu的博客-CSDN博客
然后比如我们想装cuda11.0,先到cuda版本选择页面:
CUDA Toolkit Archive | NVIDIA Developer

找到11.0,有几个小版本可以选,随便一个点进去:
CUDA Toolkit 11.0 Update 1 Downloads | NVIDIA Developer
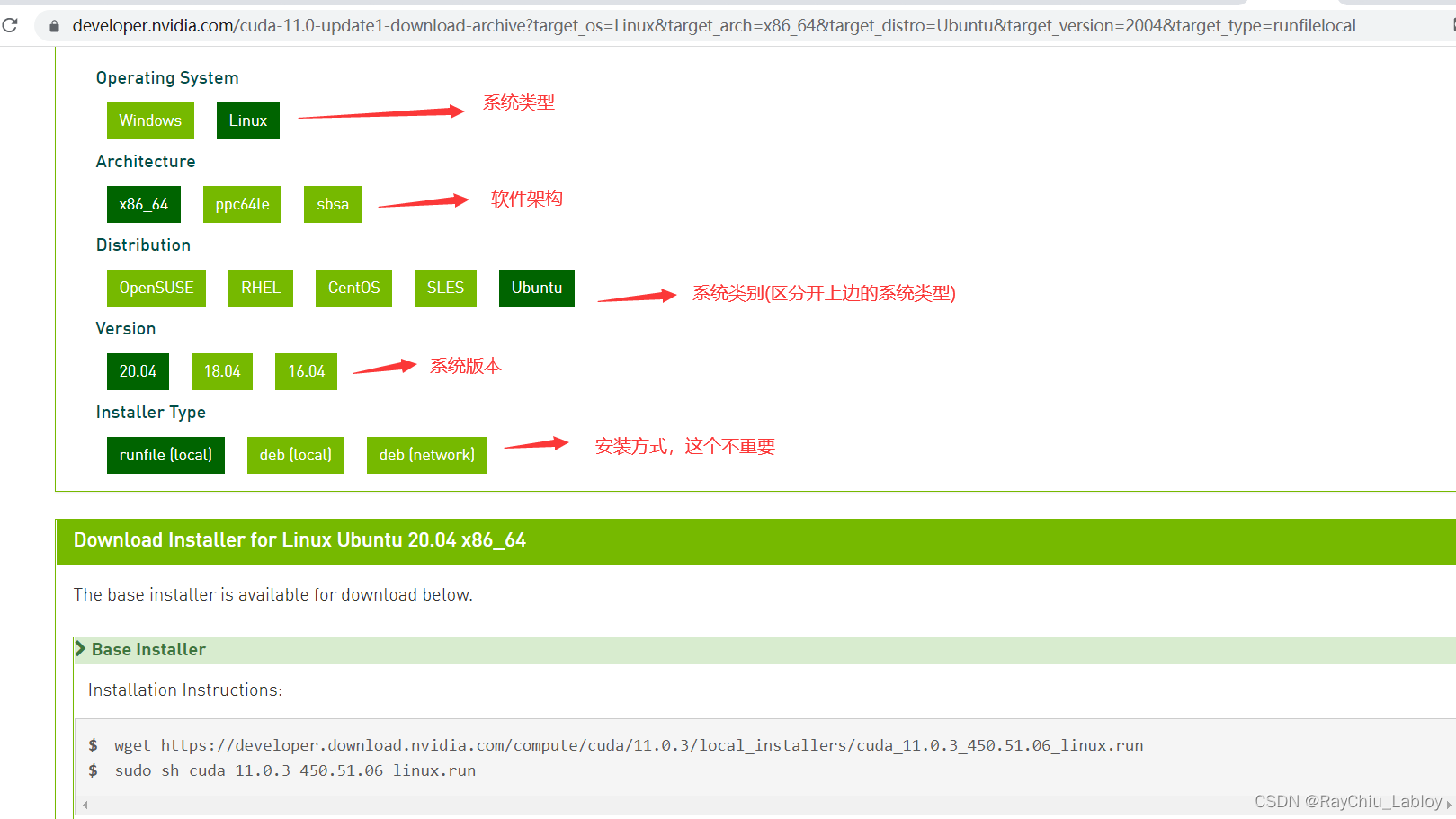
我们发现,cuda的选择要细致的多,细致到系统类型、架构、类别、版本。
再看cuDNN
cuDNN Archive | NVIDIA Developer

这里看到cuDNN只和cuda版本有关系,但是不是随便选的,因为后边还涉及到其他组件。。
再看看tensorRT
我们先进入版本选择页面:https://developer.nvidia.com/nvidia-tensorrt-download

看不出什么,那么随便选一个不激进的版本,7吧:https://developer.nvidia.com/nvidia-tensorrt-7x-download

也看不出什么来,选择不激进稳定的7.1

发现是和系统类型、类别、版本有关,和cuda比就差一个系统架构了,还是分的太细,差评
下边看下王鑫宇大佬的trtx:
GitHub - wang-xinyu/tensorrtx: Implementation of popular deep learning networks with TensorRT network definition API
trtx是tensorRT的封装,需要对各种网络逐个实现,因此首先是和网络及网络版本有关的:
这里我们以他的yolov5实现举例:
tensorrtx/yolov5 at master · wang-xinyu/tensorrtx · GitHub

看到选择trtx要小心再小心,对于yolov5他对应到了tag级别,还有最重要一点,敲黑板了啊。。。定了yolov5的tag一定要使用对应tag的预训练模型。
然后看一下deepStream
参考:ubuntu18.04配置deepstream5.0环境 - 知乎
官网给出版本如何选择:
Quickstart Guide — DeepStream 6.0 Release documentation
首先看你的平台是jetson

还是独立显卡dGPU平台:
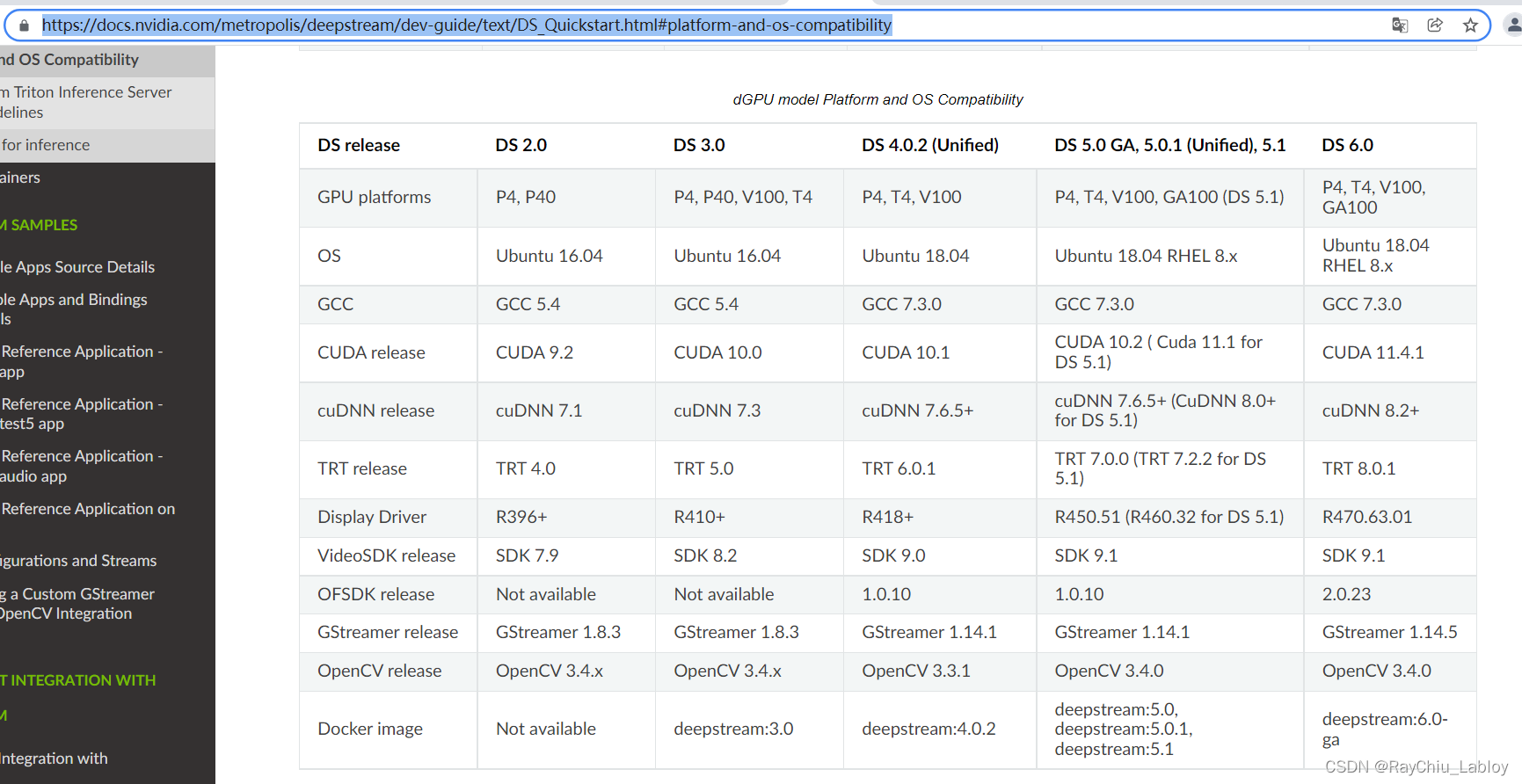
这里以独立显卡平台举例,上图可见,支持的更加细了,系统支持只有ubuntu16和18,看起来DS6.0对应的cuda和cuDNN 都是最新级别的,吓得我颤抖不止。
综合上述,我们可以最终敲定一些事情,假如像我一样平时玩独显GPU,那么显卡不是太高配的话(先进也尽量不要太激进),可以用ubuntu18.04、cuda11.1、cuDNN 8.0+、TRT7.2.2 deepStream5.1。
如果玩yolo,正好还是yolov5,那么deepStream大家都会用github上大佬们的实现,这些实现对yolov5的tag要求也是非常细的,比如这个案例:yolov5 3.1 使用deepStream5.0 - 知乎
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/125583.html