
把我们之前项目的相关规范做了个总结记录下来,仅供参考,望能有点帮助。
每个人的代码风格迥异,通过统一的编码风格使得代码可读性大大提高。
编程规约或者编码规范的的本质是提高了代码的可读性,最终目的是提高团队协作效率,降低工程维护成本。
一、项目的应用分层:
代码分层,让不同层次的代码做不同的动作。层次清晰的代码,提高可读性,从代码结构就大概能了解到代码是如何分层,每层大概功能是什么。例如常用的Controller、Service、Mapper/Dao三层代码结构,其各层的代码逻辑范围。
默认上层依赖于下层,箭头关系表示可直接依赖,如:开放接口层可以依赖于Web 层,也可以直接依赖于 Service 层,依此类推:
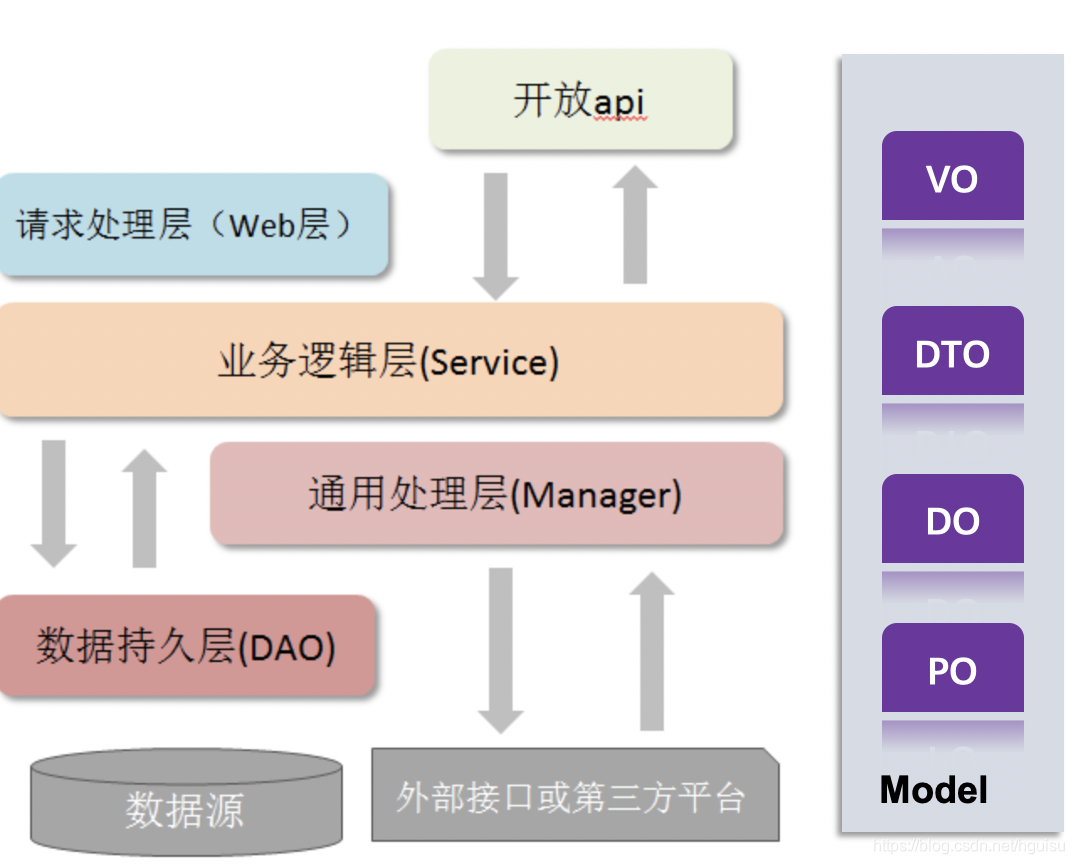
1、开放接口api层/controller: 可直接封装 Service 接口暴露成 RPC 接口; 通过 Web 封装成 http 接口; 网关控 制层等。
2、Web 层:主要是对访问控制进行转发,各类基本参数校验,或者不复用的业务简单处理等。
3、Service 层:相对具体的业务逻辑服务层。
4、Manager 层:通用业务处理层,它有如下特征
- 1)封装下沉通用能力: 对 Service 层通用能力的下沉,如缓存方案、 中间件通用处理;如mqMannager。
- 2)封装第三方接口:对第三方平台封装的层,预处理返回结果及转化异常信息,如rpcMannager。
- 3) 与 DAO 层交互,对 DAO 的业务通用能力的封装。
5、DAO 层:持久层,数据访问层,与底层 MySQL、 Oracle、 Hbase 进行数据交互,用来封装对数据库的访问(CRUD)
6、Model, 领域模型对象: (第二节专门讨论)
7、外部接口或第三方平台: 包括其它部门 RPC 开放接口,基础平台,其它公司的 HTTP 接口。
分层对于代码规范是比较重要,决定着以后的代码是否可复用,是否职责清晰,边界清晰。分层其实见仁见智,只要符合团队规范就可以。比如我们之前的团队工程规范:
api层/controller:轻业务逻辑,参数校验,异常兜底。通常这种接口可以轻易更换接口类型,所以业务逻辑必须要轻,甚至不做具体逻辑。该层的领域模型不允许传入DAO层。
Service:业务层,复用性较低,推荐每一个controller方法都得对应一个service,不要把业务编排放在controller中去做。允许操作DO数据领域模型Model。
在这一层设置事务:@Transactional(rollbackFor = Exception.class),防止事务混乱设置,导致一些不可控的事物异常。
Mannager:高可复用逻辑层。主要是做的是业务逻辑处理和数据组装。允许操作DO数据领域模型Model。在这一层是不允许设置事务,异常往外抛出,防止事务混乱设置,导致一些不可控的事物异常。
service层之间是否可以相互调用?
这个需要看项目规范,适合业务即可,软件最重要的还是是解决复杂度问题,如果service之间是通过接口依赖、IoC注入和自动事物机制,Service层可以互相调用。
二、领域模型
1、Model, 领域模型对象
领域模型POJO 一般是 DO/DTO/BO/VO 的统称,即POJO 专指只有 setter / getter / toString 的简单类,一般无业务逻辑代码,包括 DO/DTO/VO/PO 等。
- DO (Domain Object):主要用于定义与数据库对象应的属性(
ORM对象关系映射),实体bean的DO映射成一张表,通过 DAO 层向上传输数据源对象。看项目的编码规约,有的习惯使用命名为XxxEntity, 有的习惯命名为XxxDo, 比如UserEntity或者UserDO - DTO数据传输对象(Data Transfer Object):系统、服务之间交互传输用或者是传输类间数据, Service 或 Manager 向外传输的对象。 看项目的编码规约,比如我们习惯使用DTO来做rest 接口参数或者rpc参数。
- VO View Object: 视图对象,用于展示层, 前台(APP\WAP\PC)展示用;即返回给前端的对象,VO可以仅向前端传输,页面需展示字段,如pageList等。
- PO(Persistent Object): 持久化对象,就是对象是不是需要通过系列化持久化存储到数据库。 其作用就是项目的编码规约,比如我们把需要持久化保存的对象命名为PO.
- Entity实体: 也可以用作DO,看项目的编码规约,比如我们使用Entity来做service直接的对象传递。
领域模型的后缀命名也是要结合团队工程规范:比如还有
BO(Business Object)后缀:业务对象。由Service层输出的封装业务逻辑的对象。
Query/Filter/Param后缀:数据查询对象,各层接收上层的查询请求。
Form后缀:表单提交对象
领域模型类里面到底要不要写逻辑,还是只能用最普通的get/set方法。这就是讨论失血模型、贫血模型、充血模型的问题。
2、失血模型
失血模型:domain object只有属性的get set方法的纯数据类,所有的业务逻辑完全由Service层来完成的,由于没有dao,Service直接操作数据库,进行数据持久化。
service: 肿胀的服务逻辑
model:只包含get set方法
3、贫血模型
领域模型是指领域对象domain ojbect里只有get和set方法(POJO),所有的业务逻辑都不包含在内而是放在Service层。
service :组合服务,也叫事务服务
model:除包含get set方法,还包含原子服务(如获得关联model的id)
dao:数据持久化
贫血模型最早广泛应用源于EJB2,最强盛时期则是由Spring创造,将:
- “行为”(逻辑、过程);
- “状态”(数据,对应到语言就是对象成员变量)。
分离到不同的对象中:
- 只有状态的对象就是所谓的“贫血对象”;
- 只有行为的对象就是,我们常见的N层结构中的Logic/Service/Manager层(对应到EJB2中的Stateless Session Bean)。
——曾经Spring的作者Rod Johnson也承认,Spring不过是在沿袭EJB2时代的“事务脚本”,也就是面向过程编程。
贫血模型和面向对象设计背道而驰。但优点在于简单:
- 对于只有少量业务逻辑的应用来说,使用起来非常自然;
- 开发迅速,易于理解;
- 注意:也不能完全排斥这种方式。
缺点无法良好的应对复杂逻辑。《重构-改善既有代码的设计》提到的坏代码味道之一就是纯数据类的问题,要求数据和行为是在一起,而贫血模型恰恰就是纯数据类的问题呢。
4、充血模型
面向对象设计的本质是:“一个对象是拥有状态和行为的”。
充血模型:绝大多业务逻辑都应该被放在domain object里面,包括持久化逻辑,而Service层是很薄的一层,仅仅封装事务和少量逻辑,不和DAO层打交道。
service :组合服务 也叫事务服务
model:除包含get set方法,还包含原子服务和数据持久化的逻辑
它的优点是面向对象,Business Logic符合单一职责,不像在贫血模型里面那样包含所有的业务逻辑service太过沉重。
充血模型的问题也很明显,当model中包含了数据持久化的逻辑,实例化的时候可能会有很**烦,拿到了太多不一定需要的关联model。
三、项目顶层代码结构和调用链
1、 项目顶层代码结构

com
+- xxxCompany
+- myprojectApplication.java (应用启动主类)
|
+- myproject
|
+-common/base //公共/基础相关相关
| +- AppConst.java
| +- AppContext.java
|
+-module1
| +---controller 控制层
| | +- Userontroller.java
| |
| +---model //模型
| | +- domain 实体对象
| | | +-UserDO.java
| | |
| | +- dto 传输对象
| | | +-UserQueryDTO.java
| | |
| | +- vo 前端对象
| | | +-UserProfileVO.java
| |
| |
| +---service//业务逻辑层,处理数据逻辑,验证数据
| | +- impl
| | | +- UserServiceImpl.java
| | +- UserService.java
| |
| |
| +---dao //数据访问层,与底层 MySQL、 Oracle、 Hbase 等进行数据交互。
| | +- UserDao.java
|
+- util//工具包
| +- DateUtils.java //Utils后缀
2、调用链规约
我们项目编程规约,结合swaggger看:
1)controller层接收DTO请求参数 ,并进行简单参数校验。
2)controller层调用了Service层的接口方法。
3)Service层调用Dao层的方法,返回DO的entity对象。
4)Service层封装了前端需要VO对象,返回给controller层
5)controller层返回VO给前端。
四、常用命名原则和规约
规范命名约定目的是为了保持统一,减少沟通成本,提升团队研发效能。通过命名就能体现出代码的特征,含义或者是用途,让阅读者可以根据名称的含义快速厘清程序的脉络。做到见名知意,名副其实。
《Clean Code》这本书明确指出:
好的代码本身就是注释,我们要尽量规范和美化自己的代码来减少不必要的注释。
若编程语言足够有表达力,就不需要注释,尽量通过代码来阐述。
举个例子:
去掉下面复杂的注释,只需要创建一个与注释所言同一事物的函数即可
应替换为
1、首先遵循一定的原则:
好的命名风格应该是看到变量或者函数名字就能“望文生义”,做到名副其实。毕竟我们不能把自己写的所有代码都做注释。好的命名是不需要注释来补充的,达到代码自解释。
1)、编码规范统一:
在编写一个子模块或派生类的时候,要遵循其基类或整体模块的命名风格,保持命名风格在整个模块中的同一性。如骆驼命名法,大括号位置等。
2)、命名一致性原则:(命名的黄金原则)
命名一致性:如booleam变量,前缀最好是is、can,need。
函数取名最忌讳"名不副实"
比如一个 getXXX 的函数,结果里面还做了 add, update 的操作。对问题排查造成很大的困扰。因此命名一定要用实质内容相符。不论是类名,变量名,方法名都要有实际的意。 建议方法:先查查字典,找个通俗易懂而且比较贴近的名字。可以参考 jdk 的命名、通用词汇和行业词汇; 作用域小的采用短命名,作用域大的采用长命名。
再比如有个Cache类,里面有个函数判断key是否过期:
|
|
上面这个函数从函数字面意思看是判断key是否过期,但是!!它居然在函数里面隐藏了一段特殊逻辑:如果过期则删除掉key。这个就是典型的"名不副实",这个是最忌讳的,会给后续的开发人员留下"巨坑"。
有两种方式去优化这段代码:
- 方式一:将隐藏逻辑去掉
|
|
|

- 方式二:改变函数名字
|
|
3)、方法名字标识符组成:动词+名词
1、名字标识符采用英文单词,应当直观且可以拼读,可望文知意,用词应当准确。正确的英文拼写和语法可以让阅读者易于理解,避免歧义。
2、杜绝完全不规范的英文缩写,避免望文不知义。如Function“缩写”成 Fu,此类随意缩写严重降低了代码的可阅读性。
4、只要命名合理,不要担心方法名称太长
首先需要保证命名有意义,只要命名合理,不要担心方法名称太长,但方法名称过长常常又意味着该方法干的事太多了,则需要思考是否可以拆分方法,这也反映了"职责单一"设计原则。
保证命名有意义的前提之下,尽量保证命名的简短,删除一些不影响表达的单词,或者采用缩写。举几个例子:
- ActivityRuleRepository.findActivityRuleById() 可以简写成ActivityRuleRepository.findById(),因为上下文已经说明白了这个一个查询活动规则的Repository接口。
- void updateRuleForRevision(String ruleString) 简写成void updateRule4Revision(String ruleStr)
- ActivityRule convert2ActivityRule(String ruleStr) 借鉴toString的简写方式,简写成ActivityRule toActivityRule(String ruleStr)
3)最小化长度 && 最大化信息量原则
在足够描述用途的前提下,尽量以最小词汇量去描述事物,如staff就company_person_collection要简捷易记。
也可采用有广泛共识的缩写后缀,如msg,idx,cnt,btn,id ,***等,如果缩写共识度不高,请在取得同事们共识后用注释说明其含义。
变量/函数长度控制在4~18个字符内,有助于对代码的理解。
过长的变量:howLongDoesItTakeToOpenTheDoor, howBigIsTheMaterial…
简捷的变量:timeToOpenTheDoor, materialSize.
4)避免过于相似,也不要用双关语,避免歧义,比如add和append:
不要出现仅靠大小写区分的相似的标识符,例如“i”与“I”,“function”与“Function”等等。
正确命名具有互斥意义的标识符
用正确的反义词组命名具有互斥意义的标识符 ,如
add / remove begin / end create / destroy
insert / delete first / last get / set
increment / decrement put / get
add / delete lock / unlock open / close
min / max old / new start / stop
next / previous source / target show / hide
send / receive source / destination
cut / paste up / down
这些有助于理解成对的变量/函数的意义.
尽量避免名字中出现数字编号
尽量避免名字中出现数字编号,如value1,value2等,除非逻辑上的确需要编号。
5)少使用类型前缀
最好从名字上就能揣测出其类型。加后缀说明是可以的。
少单独使用含义广泛的词。如data,info,value等。
6)避免过度使用get作为方法前缀
应该用更精确的动词描述动作,如“请求”request,“获取”acquire,“查找”search/lookfor/find,“查询”inquire,“构建”build 或“创建”create, 执行某个动作如执行查询doGet
get和set和成对出现,是轻量的实现。
get这种方法命名一定是明确index,性能比较好,
query选择选择符合的。
- 找到数据:find/lookfor,肯定有数据。
- 搜索数据:search、搜索数据可能不存在。
- 查询数据:query 强调查询这个动作,返回的数据是比较原始。query返回的是
List<object>,find返回的才是List<Record>。
2.常见类名命名规范:
1、类应该是名词形式,通常由单个名词或名词短语组成,通常以名词结尾。而且在类名中要体现它是以保存数据为主还是提供功能为主。例如 ObjectBuilder 这个类我们都可以猜到它的主要功能是创建Object对象,
2、以动词-er/or 结尾的类名,至少应该包含一个以该动词开头的方法。例如 ObjectBuilder 这个类,它至少应该包含一个以 build- 开头的方法。有了这种规约,阅读者就能更方便地理解这个类。
| 前缀名 |
意义 |
举例 |
| Abstract 或者 Base 开头 | 抽象类 | BaseUserService |
| 后缀名 |
意义 |
举例 |
| Controller |
对外接口类 |
UserController |
| Service |
服务类,里面包含了给其他类提同业务服务的方法 |
UserService |
| Impl |
实现类,而不是接口 |
UserServiceImpl |
| Manager |
通用业务处理层 |
UserManager |
| Ixxx |
接口类 |
IUserDao |
| Dao |
数据访问方法类 |
OrderDao |
| Listener |
响应某种事件的类 |
PaymentSuccessListener |
| Event |
这个类代表了某种事件 |
PaymentSuccessEvent |
| Factory |
生成某种对象工厂的类 |
PaymentOrderFactory |
| Adapter |
用来连接某种以前不被支持的对象的类 |
DatabaseLogAdapter |
| Job |
某种按时间运行的任务 |
PaymentOrderCancelJob |
| Wrapper |
这是一个包装类,为了给某个类提供没有的能力 |
SelectableOrderListWrapper |
| DO |
定义与数据库对象应的属性(ORM对象关系映射 |
UserDO |
| DTO |
DTO数据传输对象 |
UserDTO |
| VO |
用于展示层, 前台(APP\WAP\PC)展示用 |
UserVO |
| Entity |
实体 |
| 属性 | 约束 |
举例 |
| 设计模式相关类 | Builder,Factory等 | 当使用到设计模式时,需要使用对应的设计模式作为后缀,如ThreadFactory。 Bridge:桥连模式 |
| Util类 | 一般是无状态的,只包含静态方法。使用时无需创建类的实例。 | |
| Helper类 | 可以有状态(类的成员变量),一般需要创建实例才能使用。 | |
| 处理特定功能的 | Handler,Predicate, Validator | 表示处理器,校验器,断言,这些类工厂还有配套的方法名如 handle,predicate,validate |
接口管理:XXXManagerPOJO 是 DO / DTO / BO / VO 的统称,禁止命名成 xxxPOJO。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/121184.html