
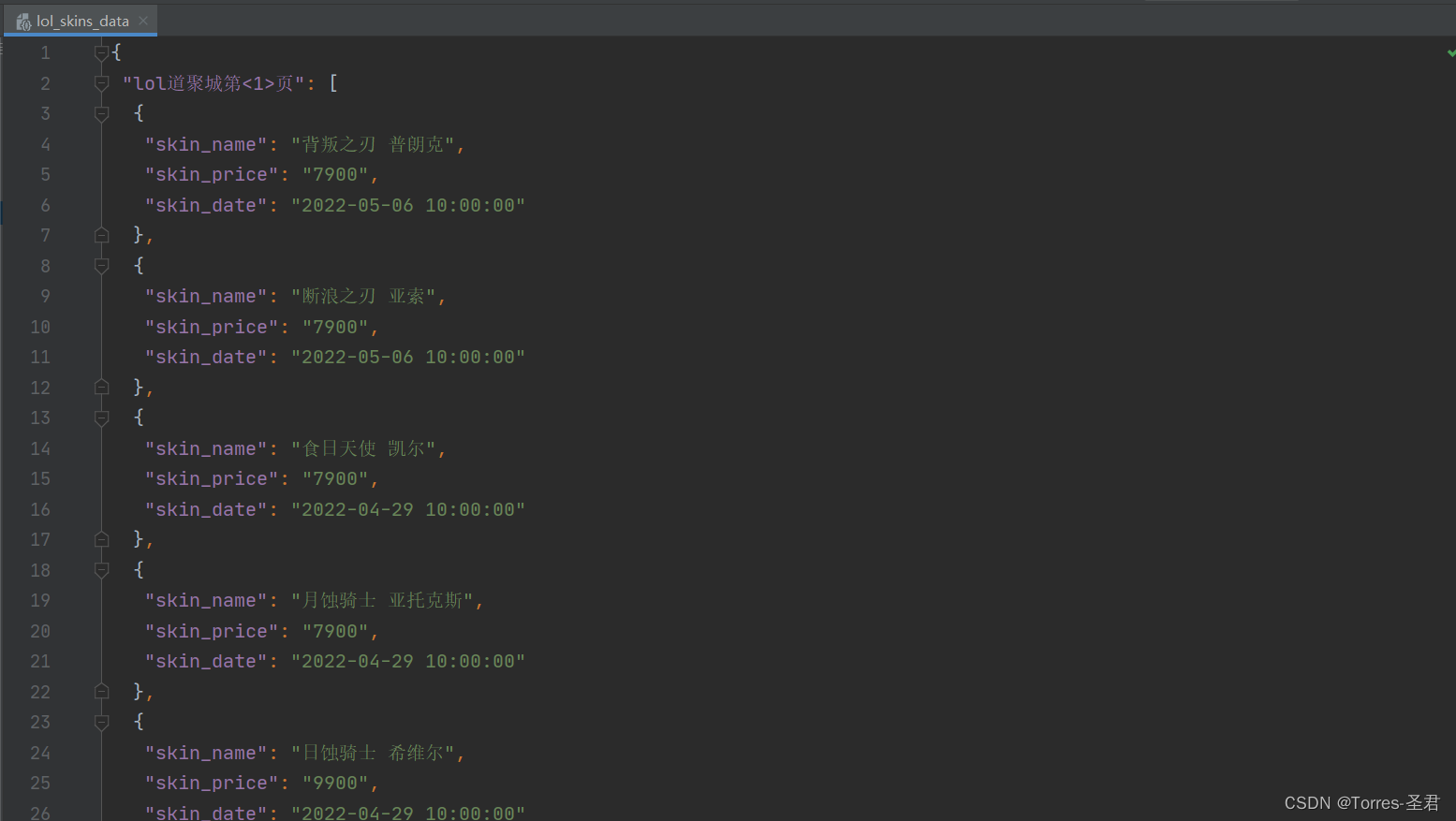
效果展示:
分析目标网站:
- LOL道聚城网址:https://daoju..com/lol/list/17-0-0-0-0-0-0-0-0-0-0-00-0-0-1-1.shtml
- 在进入网站后,右键网站任意位置点击
查看页面源代码,但在源代码中无法找到皮肤相关信息
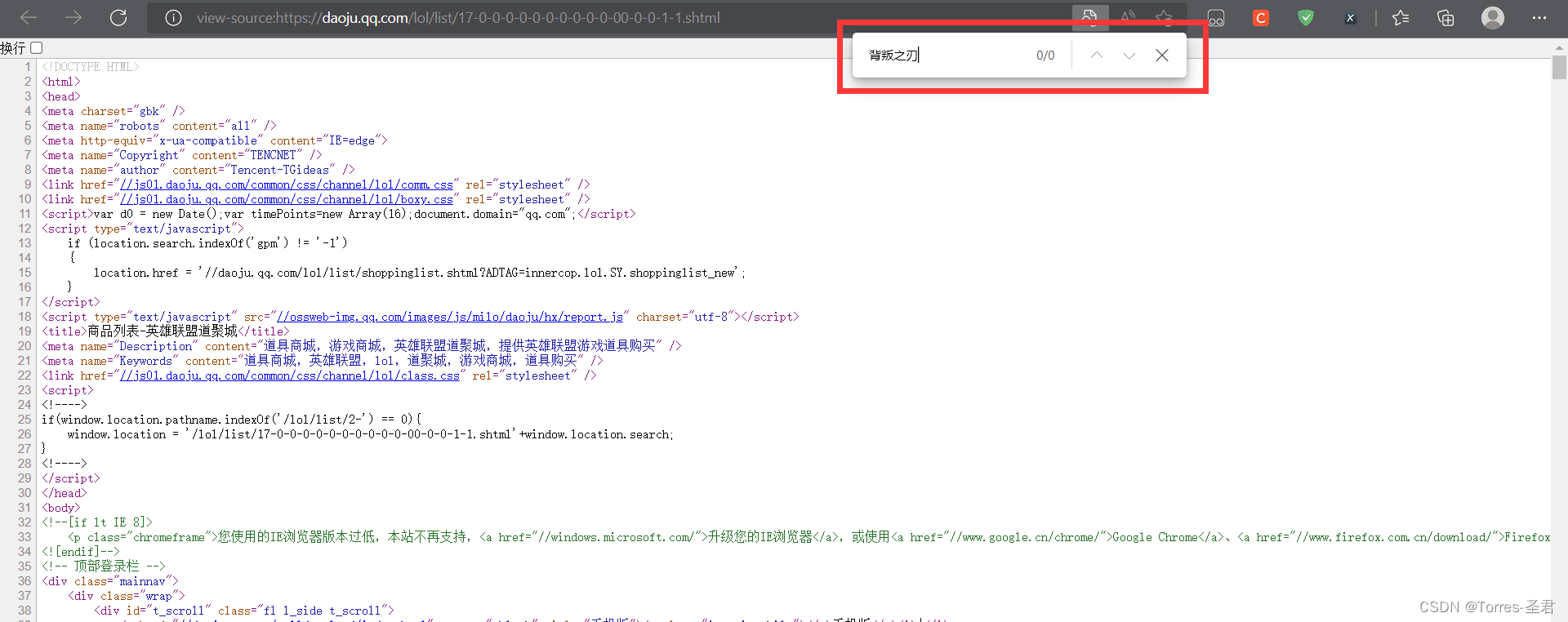
- 返回网站,右键点
检查或审查元素,在弹出的控制台中点网络或network,如果没有显示数据的话,刷新一下网页就有了
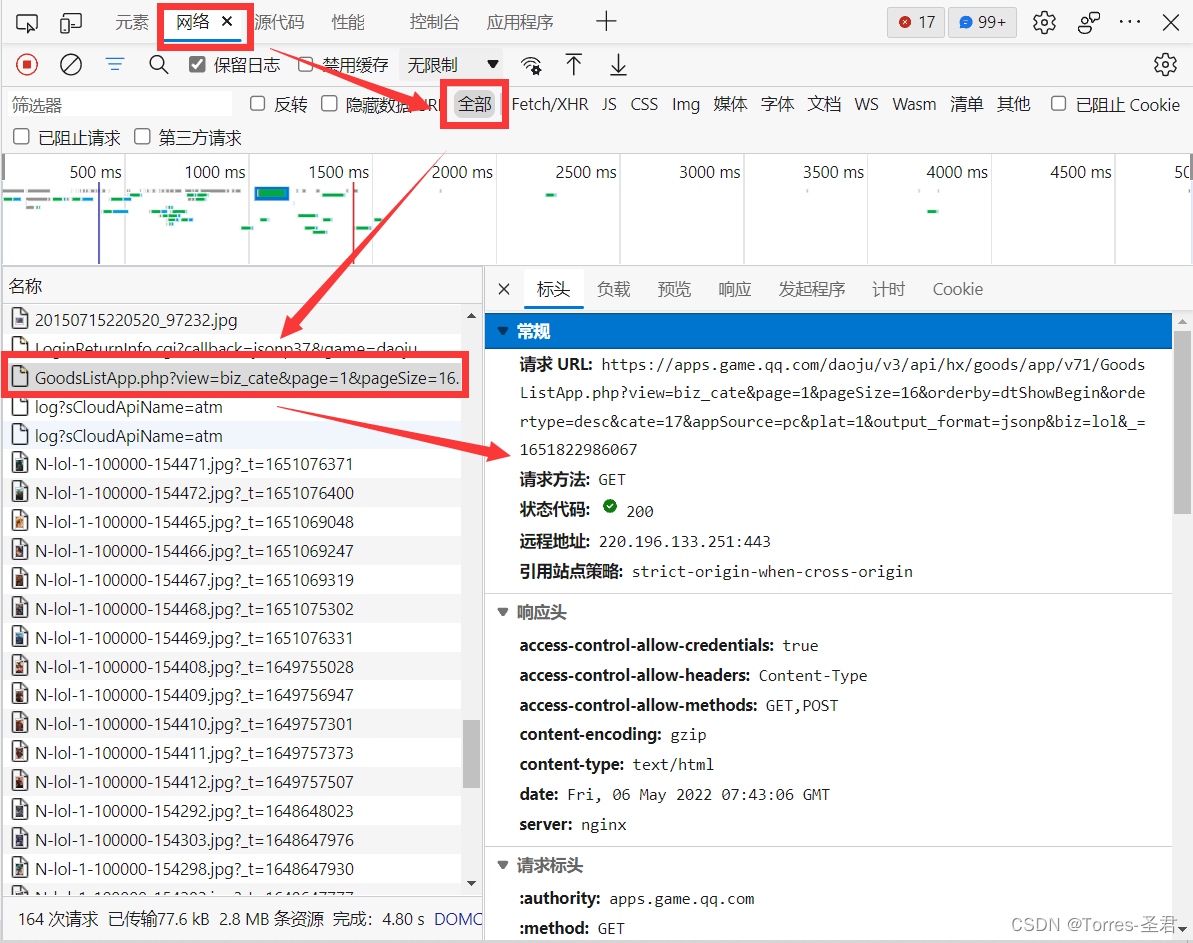

- 在网络栏下找到
GoodsListApp.php?.....开头的那个名称,然后点击右侧的预览,展开数据后发现其皮肤数据都在里面
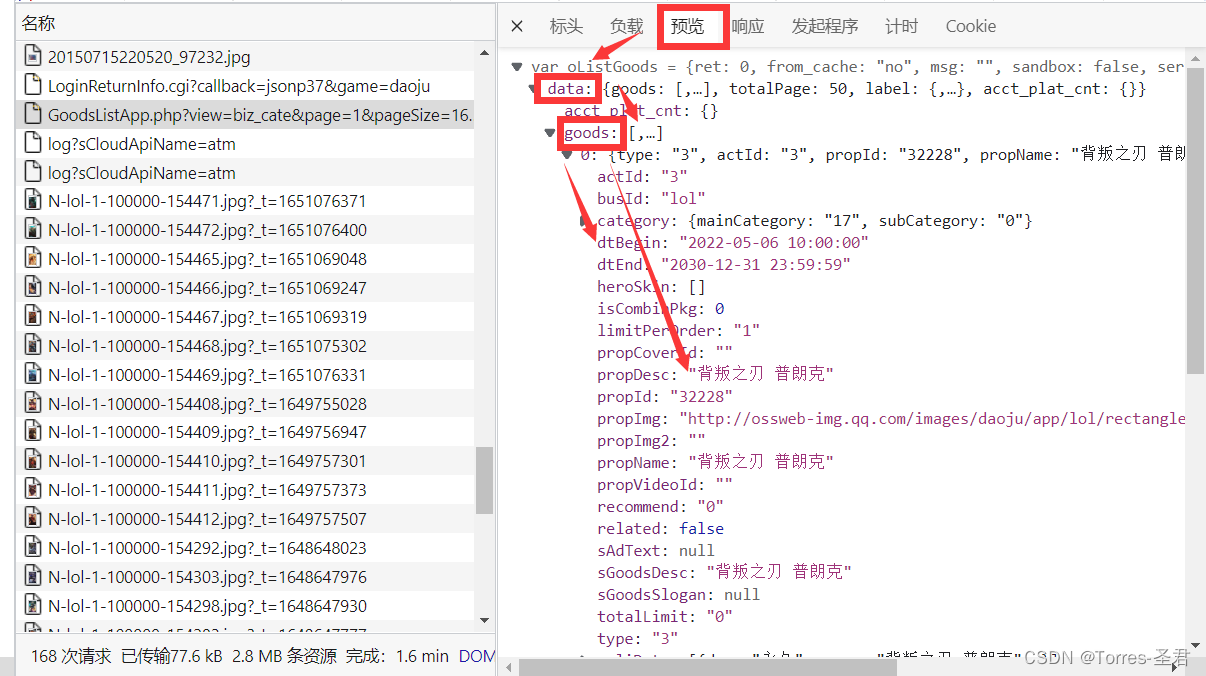
- 在确认数据的所在位置后,点击负载查看其发送请求时,需要携带的全部参数
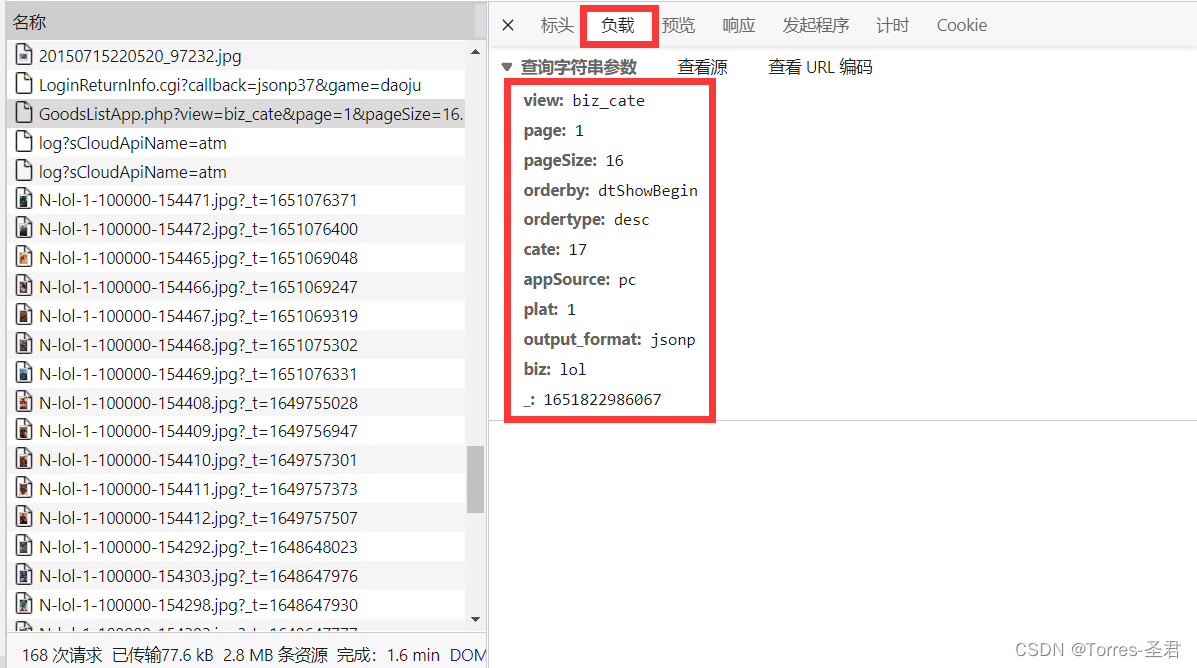
获取皮肤相关信息:
- 创建请求头,并分析所有需要携带的参数:
- 打开网站不同页码,对这些参数进行对比,可以发现参数:
page:不同页面对应的页码数,整型_:一个13位的时间戳,整型- 而其他参数则都相同
# 请求链接 self.url = "https://apps.game..com/daoju/v3/api/hx/goods/app/v71/GoodsListApp.php?" # 请求头 self.headers = {
"referer": "https://daoju..com/", "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.41 Safari/537.36 Edg/101.0.1210.32" } # 发送请求需要携带的参数 self.params = {
"view": "biz_cate", "page": int, "pageSize": 16, "orderby": "dtShowBegin", "ordertype": "desc", "cate": 17, "appSource": "pc", "plat": 1, "output_format": "jsonp", "biz": "lol", "_": int(time.time() * 1000) } 讯享网
- 找到参数的规律后,发送请求,并解析请求返回的数据,这里使用re正则表达式进行筛选
讯享网def get_data(self): # 初始化字典 all_skins_data = dict() # 循环请求页面 for i in range(1, 51): # 请求间隔 time.sleep(1) # 参数页码 self.params['page'] = i # 发送请求 res = requests.get(self.url, headers=self.headers, params=self.params) # 提取数据 skins_list = self.data_format(res.text) # 添加进字典 all_skins_data[f"lol道具城第<{
i}>页"] = skins_list # 保存数据 self.save_data(all_skins_data) def data_format(self, data): # 筛选当页所有皮肤名称 skin_name_list = re.findall(r'"propName":"(.*?)"', data) # 筛选当页所有皮肤价格 skin_price_list = re.findall(r'"iDqPrice":"(\d+)"', data) # 筛选当页所有上架日期 skin_date_list = re.findall(r'"dtBegin":"(.*?)"', data) skins_list = [] for i in range(0, len(skin_name_list)): item = dict() # 皮肤名称 item["skin_name"] = str(skin_name_list[i]).encode('utf8').decode('unicode_escape').replace("\\", "") # 皮肤价格(点券) item["skin_price"] = skin_price_list[i] # 皮肤上架日期 item["skin_date"] = skin_date_list[i] skins_list.append(item) # 展示数据 print(item) return skins_list
- 把筛选后的数据保存到本地,这里采用json格式:
def save_data(self, all_skins_data): # JSON序列化 json_data = json.dumps(all_skins_data, indent=1, ensure_ascii=False) with open("lol_skins_data.json", "w", encoding="utf-8") as w: w.write(json_data) 完整版代码:
- 这个是我平时做爬虫练习时,汇总的案例的其中之一,代码比较适合新手学习,该Github仓库的爬虫案例也会在以后不断更新,有兴趣学习爬虫的可以来捧捧场哦QwQ。仓库链接:https://github.com/cjladmin/spider_cases
讯享网import requests import time import re import json class LolSkins: def __init__(self): self.url = "https://apps.game..com/daoju/v3/api/hx/goods/app/v71/GoodsListApp.php?" self.headers = {
"referer": "https://daoju..com/", "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.41 Safari/537.36 Edg/101.0.1210.32" } self.params = {
"view": "biz_cate", "page": int, "pageSize": 16, "orderby": "dtShowBegin", "ordertype": "desc", "cate": 17, "appSource": "pc", "plat": 1, "output_format": "jsonp", "biz": "lol", "_": int(time.time() * 1000) } def get_data(self): # 初始化字典 all_skins_data = dict() # 循环请求页面 for i in range(1, 51): # 请求间隔 time.sleep(1) # 参数页码 self.params['page'] = i # 发送请求 res = requests.get(self.url, headers=self.headers, params=self.params) # 提取数据 skins_list = self.data_format(res.text) # 添加进字典 all_skins_data[f"lol道聚城第<{
i}>页"] = skins_list # 保存数据 self.save_data(all_skins_data) def data_format(self, data): # 皮肤名称 skin_name_list = re.findall(r'"propName":"(.*?)"', data) # 皮肤价格 skin_price_list = re.findall(r'"iDqPrice":"(\d+)"', data) # 上架日期 skin_date_list = re.findall(r'"dtBegin":"(.*?)"', data) skins_list = [] for i in range(0, len(skin_name_list)): item = dict() item["skin_name"] = str(skin_name_list[i]).encode('utf8').decode('unicode_escape').replace("\\", "") item["skin_price"] = skin_price_list[i] item["skin_date"] = skin_date_list[i] skins_list.append(item) # 展示数据 print(item) return skins_list def save_data(self, all_skins_data): # JSON序列化 json_data = json.dumps(all_skins_data, indent=1, ensure_ascii=False) with open("lol_skins_data.json", "w", encoding="utf-8") as w: w.write(json_data) if __name__ == '__main__': lol = LolSkins() lol.get_data()
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/118586.html