
SSVEP信号中含有自发脑电和大量外界干扰信号,属于典型的非线性非平稳信号。传统的滤波方法通常不满足对非线性非平稳分析的条件,1998年黄鄂提出希尔伯特黄变换(HHT)方法,其中包含经验模式分解(EMD)和希尔伯特变换(HT)两部分。EMD可以将原始信号分解成为一系列固有模态函数(IMF) [1],IMF分量是具有时变频率的震荡函数,能够反映出非平稳信号的局部特征,用它对非线性非平稳的SSVEP信号进行分解比较合适。
网友Aeo[2]提供了下面的算法过程分析。
算法过程分析
- 筛选(Sifting)
- 求极值点 通过Find Peaks算法获取信号序列的全部
极大值和极小值 - 拟合包络曲线 通过信号序列的
极大值和极小值组,经过三次样条插值法获得两条光滑的波峰/波谷拟合曲线,即信号的上包络线与下包络线 - 均值包络线 将两条极值曲线平均获得
平均包络线 - 中间信号 原始信号减均值包络线,得到
中间信号 - 判断本征模函数(IMF) IMF需要符合两个条件:1)在整个数据段内,极值点的个数和过零点的个数必须相等或相差最多不能超过一个。2)在任意时刻,由局部极大值点形成的上包络线和由局部极小值点形成的下包络线的平均值为零,即上、下包络线相对于时间轴局部对称。
- IMF 1 获得的第一个满足IMF条件的中间信号即为原始信号的第一个本征模函数分量
IMF 1(由原数据减去包络平均后的新数据,若还存在负的局部极大值和正的局部极小值,说明这还不是一个本征模函数,需要继续进行“筛选”。) - 使用上述方法得到第一个IMF后,用原始信号减IMF1,作为新的原始信号,再通过上述的筛选分析,可以得到IMF2,以此类推,完成EMD分解。
- 下面利用公式来说明上面的分析过程。
EMD算法步骤
任何复杂的信号均可视为多个不同的固有模态函数叠加之和,任何模态函数可以是线性的或非线性的,并且任意两个模态之间都是相互独立的。在这个假设 基础上,复杂信号x(t) 的EMD分解步骤如下:
步骤1:
寻找信号 全部极值点,通过三次样条曲线将局部极大值点连成上包络线,将局部极小值点连成下包络线。上、下包络线包含所有的数据点。
h1(t)=x(t)-m1(t);
若h1(t) 满足IMF的条件,则可认为h1(t) 是x(t) 的第一个IMF分量。
c1(t)=
讯享网;
r1=x(t)-c1(t);

将 r1(t)作为原始信号重复上述三个步骤,循环 n次,得到第二个IMF分量 c2(t)直到第n 个IMF分量 ,则会得出:
步骤5:
当 变成单调函数后,剩余的 成为残余分量。所有IMF分量和残余分量之和为原始信号x(t) :
;
1.求极大值点和极小值点
from scipy.signal import argrelextrema import matplotlib.pyplot as plt import numpy as np """ 通过Scipy的argrelextrema函数获取信号序列的极值点 """ # 构建100个随机数 data = np.random.random(100) # 获取极大值 max_peaks = argrelextrema(data, np.greater) #获取极小值 min_peaks = argrelextrema(data, np.less) # 绘制极值点图像 plt.figure(figsize = (18,6)) plt.plot(data) plt.scatter(max_peaks, data[max_peaks], c='r', label='Max Peaks') plt.scatter(min_peaks, data[min_peaks], c='b', label='Max Peaks') plt.legend() plt.xlabel('time (s)') plt.ylabel('Amplitude') plt.title("Find Peaks") plt.show()讯享网

2. 拟合包络函数
这一步是EMD的核心步骤,也是分解出本征模函数IMFs的前提。
讯享网from scipy.signal import argrelextrema import matplotlib.pyplot as plt import numpy as np #进行样条差值 import scipy.interpolate as spi data = np.random.random(100)-0.5 index = list(range(len(data))) # 获取极值点 max_peaks = list(argrelextrema(data, np.greater)[0]) min_peaks = list(argrelextrema(data, np.less)[0]) # 将极值点拟合为曲线 ipo3_max = spi.splrep(max_peaks, data[max_peaks],k=3) #样本点导入,生成参数 iy3_max = spi.splev(index, ipo3_max) #根据观测点和样条参数,生成插值 ipo3_min = spi.splrep(min_peaks, data[min_peaks],k=3) #样本点导入,生成参数 iy3_min = spi.splev(index, ipo3_min) #根据观测点和样条参数,生成插值 # 计算平均包络线 iy3_mean = (iy3_max+iy3_min)/2 # 绘制图像 plt.figure(figsize = (18,6)) plt.plot(data, label='Original') plt.plot(iy3_max, label='Maximun Peaks') plt.plot(iy3_min, label='Minimun Peaks') plt.plot(iy3_mean, label='Mean') plt.legend() plt.xlabel('time (s)') plt.ylabel('microvolts (uV)') plt.title("Cubic Spline Interpolation") plt.show()
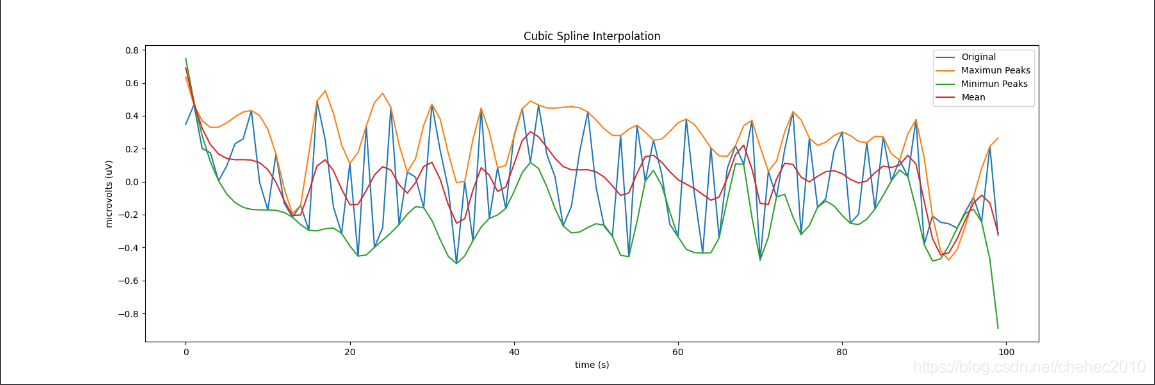
用原信号减去平均包络线即为所获得的新信号,若新信号中还存在负的局部极大值和正的局部极小值,说明这还不是一个本征模函数,需要继续进行“筛选”。
获取本征模函数(IMF)
def sifting(data): index = list(range(len(data))) max_peaks = list(argrelextrema(data, np.greater)[0]) min_peaks = list(argrelextrema(data, np.less)[0]) ipo3_max = spi.splrep(max_peaks, data[max_peaks],k=3) #样本点导入,生成参数 iy3_max = spi.splev(index, ipo3_max) #根据观测点和样条参数,生成插值 ipo3_min = spi.splrep(min_peaks, data[min_peaks],k=3) #样本点导入,生成参数 iy3_min = spi.splev(index, ipo3_min) #根据观测点和样条参数,生成插值 iy3_mean = (iy3_max+iy3_min)/2 return data-iy3_mean def hasPeaks(data): max_peaks = list(argrelextrema(data, np.greater)[0]) min_peaks = list(argrelextrema(data, np.less)[0]) if len(max_peaks)>3 and len(min_peaks)>3: return True else: return False # 判断IMFs def isIMFs(data): max_peaks = list(argrelextrema(data, np.greater)[0]) min_peaks = list(argrelextrema(data, np.less)[0]) if min(data[max_peaks]) < 0 or max(data[min_peaks])>0: return False else: return True def getIMFs(data): while(not isIMFs(data)): data = sifting(data) return data # EMD函数 def EMD(data): IMFs = [] while hasPeaks(data): data_imf = getIMFs(data) data = data-data_imf IMFs.append(data_imf) return IMFs # 绘制对比图 data = np.random.random(1000)-0.5 IMFs = EMD(data) n = len(IMFs)+1 # 原始信号 plt.figure(figsize = (18,15)) plt.subplot(n, 1, 1) plt.plot(data, label='Origin') plt.title("Origin ") # 若干条IMFs曲线 for i in range(0,len(IMFs)): plt.subplot(n, 1, i+2) plt.plot(IMFs[i]) plt.ylabel('Amplitude') plt.title("IMFs "+str(i+1)) plt.legend() plt.xlabel('time (s)') plt.ylabel('Amplitude')
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/116945.html